 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SR2CNN: Zero-Shot Learning for Signal Recognition
Apr 21, 2020




Signal recognition is one of significant and challenging tasks in the signal processing and communications field. It is often a common situation that there's no training data accessible for some signal classes to perform a recognition task. Hence, as widely-used in image processing field, zero-shot learning (ZSL) is also very important for signal recognition. Unfortunately, ZSL regarding this field has hardly been studied due to inexplicable signal semantics. This paper proposes a ZSL framework, signal recognition and reconstruction convolutional neural networks (SR2CNN), to address relevant problems in this situation. The key idea behind SR2CNN is to learn the representation of signal semantic feature space by introducing a proper combination of cross entropy loss, center loss and autoencoder loss, as well as adopting a suitable distance metric space such that semantic features have greater minimal inter-class distance than maximal intra-class distance. The proposed SR2CNN can discriminate signals even if no training data is available for some signal class. Moreover, SR2CNN can gradually improve itself in the aid of signal detection, because of constantly refined class center vectors in semantic feature space. These merits are all verified by extensive experiments.
FAMED-Net: A Fast and Accurate Multi-scale End-to-end Dehazing Network
Jul 07, 2019
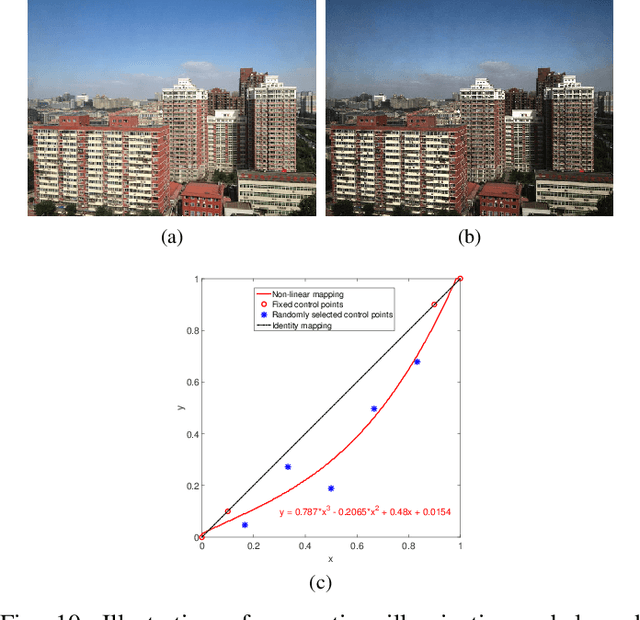

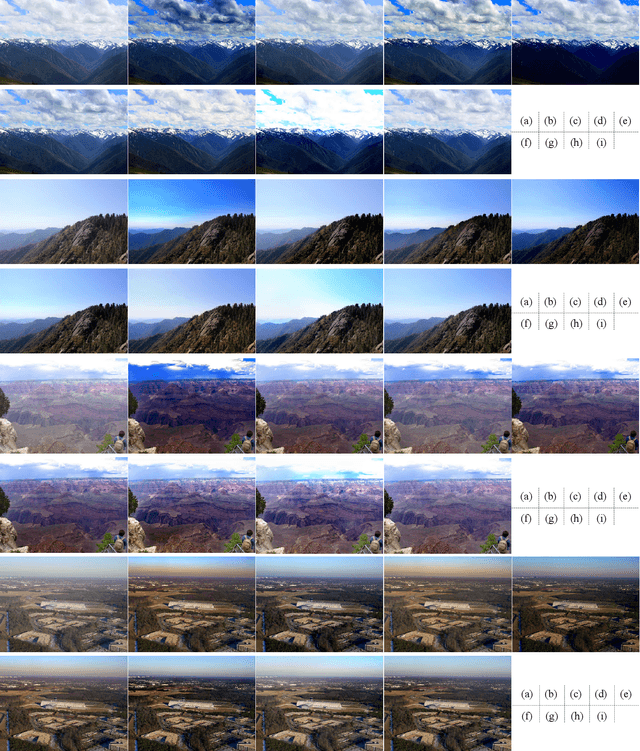
Single image dehazing is a critical image pre-processing step for subsequent high-level computer vision tasks. However, it remains challenging due to its ill-posed nature. Existing dehazing models tend to suffer from model overcomplexity and computational inefficiency or have limited representation capacity. To tackle these challenges, here we propose a fast and accurate multi-scale end-to-end dehazing network called FAMED-Net, which comprises encoders at three scales and a fusion module to efficiently and directly learn the haze-free image. Each encoder consists of cascaded and densely connected point-wise convolutional layers and pooling layers. Since no larger convolutional kernels are used and features are reused layer-by-layer, FAMED-Net is lightweight and computationally efficient. Thorough empirical studies on public synthetic datasets (including RESIDE) and real-world hazy images demonstrate the superiority of FAMED-Net over other representative state-of-the-art models with respect to model complexity, computational efficiency, restoration accuracy, and cross-set generalization. The code will be made publicly available.
Image Labeling and Segmentation using Hierarchical Conditional Random Field Model
Jan 16, 2012The use of hierarchical Conditional Random Field model deal with the problem of labeling images . At the time of labeling a new image, selection of the nearest cluster and using the related CRF model to label this image. When one give input image, one first use the CRF model to get initial pixel labels then finding the cluster with most similar images. Then at last relabeling the input image by the CRF model associated with this cluster. This paper presents a approach to label and segment specific image having correct information.
Generalizable Cone Beam CT Esophagus Segmentation Using In Silico Data Augmentation
Jun 28, 2020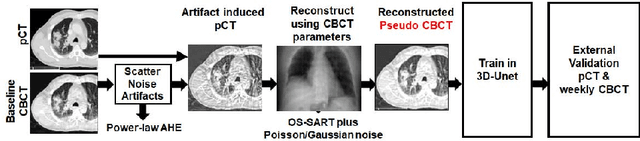
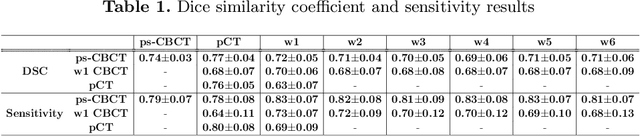
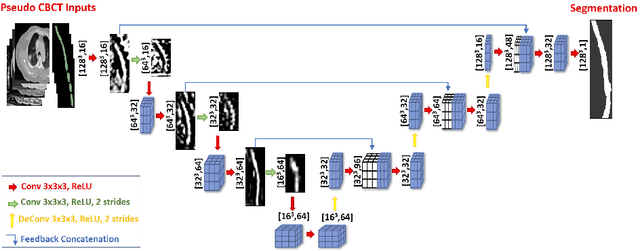

Lung cancer radiotherapy entails high quality planning computed tomography (pCT) imaging of the patient with radiation oncologist contouring of the tumor and the organs at risk (OARs) at the start of the treatment. This is followed by weekly low-quality cone beam CT (CBCT) imaging for treatment setup and qualitative visual assessment of tumor and critical OARs. In this work, we aim to make the weekly CBCT assessment quantitative by automatically segmenting the most critical OAR, esophagus, using deep learning and in silico (image-driven simulation) artifact induction to convert pCTs to pseudo-CBCTs (pCTs$+$artifacts). Specifically, for the in silico data augmentation, we make use of the critical insight that CT and CBCT have the same underlying physics and that it is easier to deteriorate the pCT to look more like CBCT (and use the accompanying high quality manual contours for segmentation) than to synthesize CT from CBCT where the critical anatomical information may have already been lost (which leads to anatomical hallucination with the prevalent generative adversarial networks for example). Given these pseudo-CBCTs and the high quality manual contours, we introduce a modified 3D-Unet architecture and a multi-objective loss function specifically designed for segmenting soft-tissue organs such as esophagus on real weekly CBCTs. The model achieved 0.74 dice overlap (against manual contours of an experienced radiation oncologist) on weekly CBCTs and was robust and generalizable enough to also produce state-of-the-art results on pCTs, achieving 0.77 dice overlap against the previous best of 0.72. This shows that our in silico data augmentation spans the realistic noise/artifact spectrum across patient CBCT/pCT data and can generalize well across modalities (without requiring retraining or domain adaptation), eventually improving the accuracy of treatment setup and response analysis.
Object Detection in Optical Remote Sensing Images: A Survey and A New Benchmark
Sep 22, 2019Substantial efforts have been devoted more recently to presenting various methods for object detection in optical remote sensing images. However, the current survey of datasets and deep learning based methods for object detection in optical remote sensing images is not adequate. Moreover, most of the existing datasets have some shortcomings, for example, the numbers of images and object categories are small scale, and the image diversity and variations are insufficient. These limitations greatly affect the development of deep learning based object detection methods. In the paper, we provide a comprehensive review of the recent deep learning based object detection progress in both the computer vision and earth observation communities. Then, we propose a large-scale, publicly available benchmark for object DetectIon in Optical Remote sensing images, which we name as DIOR. The dataset contains 23463 images and 192472 instances, covering 20 object classes. The proposed DIOR dataset 1) is large-scale on the object categories, on the object instance number, and on the total image number; 2) has a large range of object size variations, not only in terms of spatial resolutions, but also in the aspect of inter- and intra-class size variability across objects; 3) holds big variations as the images are obtained with different imaging conditions, weathers, seasons, and image quality; and 4) has high inter-class similarity and intra-class diversity. The proposed benchmark can help the researchers to develop and validate their data-driven methods. Finally, we evaluate several state-of-the-art approaches on our DIOR dataset to establish a baseline for future research.
Alleviating the Incompatibility between Cross Entropy Loss and Episode Training for Few-shot Skin Disease Classification
Apr 21, 2020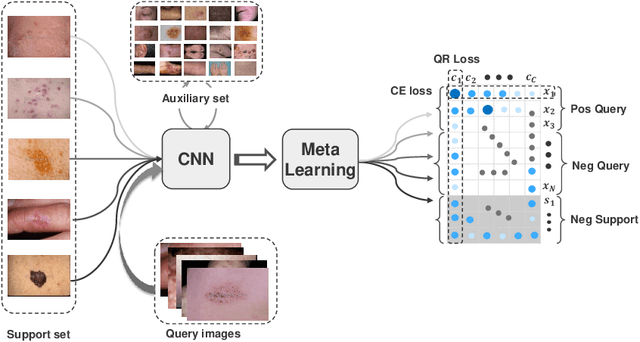
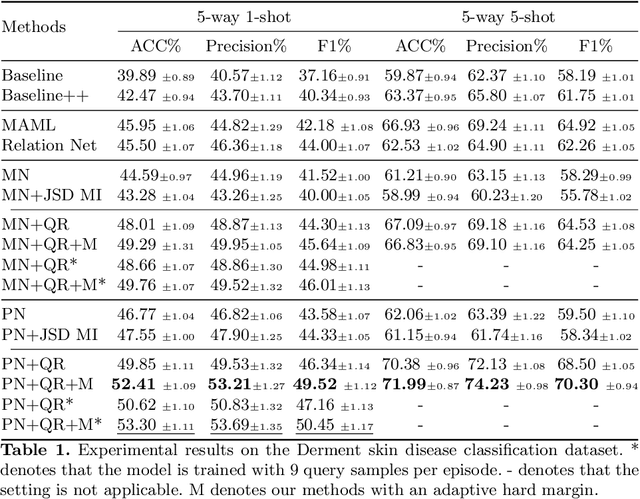

Skin disease classification from images is crucial to dermatological diagnosis. However, identifying skin lesions involves a variety of aspects in terms of size, color, shape, and texture. To make matters worse, many categories only contain very few samples, posing great challenges to conventional machine learning algorithms and even human experts. Inspired by the recent success of Few-Shot Learning (FSL) in natural image classification, we propose to apply FSL to skin disease identification to address the extreme scarcity of training sample problem. However, directly applying FSL to this task does not work well in practice, and we find that the problem can be largely attributed to the incompatibility between Cross Entropy (CE) and episode training, which are both commonly used in FSL. Based on a detailed analysis, we propose the Query-Relative (QR) loss, which proves superior to CE under episode training and is closely related to recently proposed mutual information estimation. Moreover, we further strengthen the proposed QR loss with a novel adaptive hard margin strategy. Comprehensive experiments validate the effectiveness of the proposed FSL scheme and the possibility to diagnosis rare skin disease with a few labeled samples.
AtLoc: Attention Guided Camera Localization
Sep 08, 2019
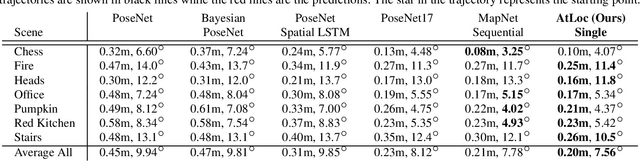
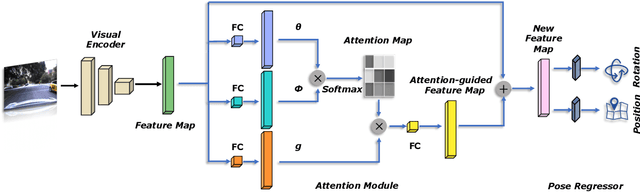
Deep learning has achieved impressive results in camera localization, but current single-image techniques typically suffer from a lack of robustness, leading to large outliers. To some extent, this has been tackled by sequential (multi-images) or geometry constraint approaches, which can learn to reject dynamic objects and illumination conditions to achieve better performance. In this work, we show that attention can be used to force the network to focus on more geometrically robust objects and features, achieving state-of-the-art performance in common benchmark, even if using only a single image as input. Extensive experimental evidence is provided through public indoor and outdoor datasets. Through visualization of the saliency maps, we demonstrate how the network learns to reject dynamic objects, yielding superior global camera pose regression performance. The source code is avaliable at https://github.com/BingCS/AtLoc.
Semi-supervised Learning using Adversarial Training with Good and Bad Samples
Oct 18, 2019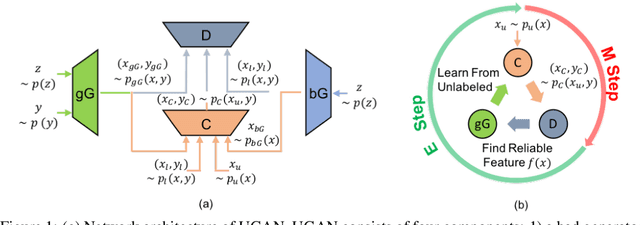



In this work, we investigate semi-supervised learning (SSL) for image classification using adversarial training. Previous results have illustrated that generative adversarial networks (GANs) can be used for multiple purposes. Triple-GAN, which aims to jointly optimize model components by incorporating three players, generates suitable image-label pairs to compensate for the lack of labeled data in SSL with improved benchmark performance. Conversely, Bad (or complementary) GAN, optimizes generation to produce complementary data-label pairs and force a classifier's decision boundary to lie between data manifolds. Although it generally outperforms Triple-GAN, Bad GAN is highly sensitive to the amount of labeled data used for training. Unifying these two approaches, we present unified-GAN (UGAN), a novel framework that enables a classifier to simultaneously learn from both good and bad samples through adversarial training. We perform extensive experiments on various datasets and demonstrate that UGAN: 1) achieves state-of-the-art performance among other deep generative models, and 2) is robust to variations in the amount of labeled data used for training.
Deep Variational Networks with Exponential Weighting for Learning Computed Tomography
Jun 13, 2019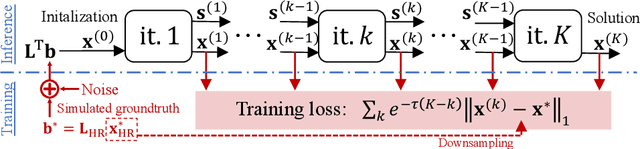

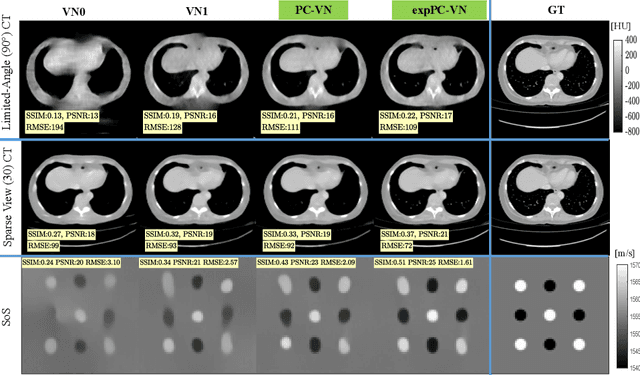
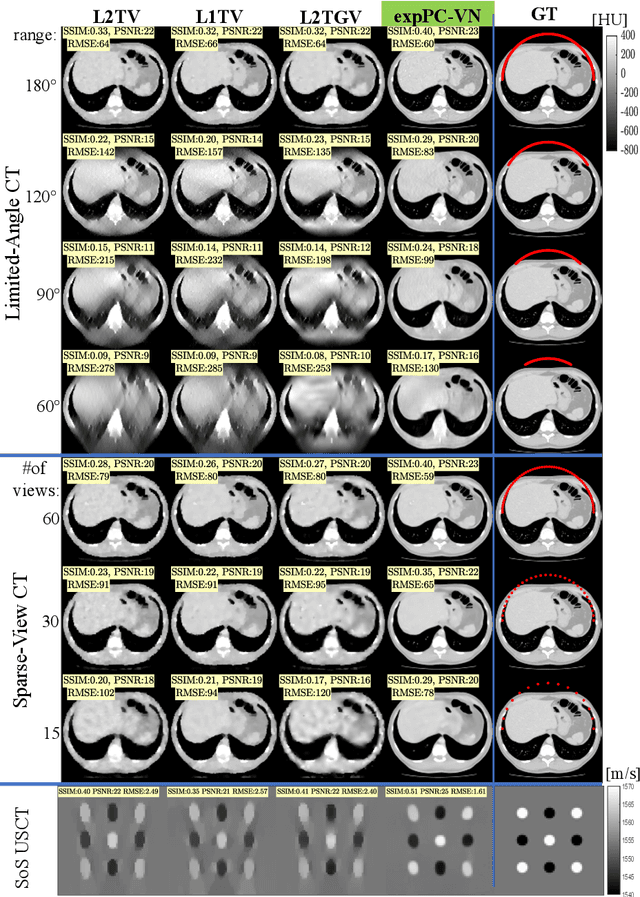
Tomographic image reconstruction is relevant for many medical imaging modalities including X-ray, ultrasound (US) computed tomography (CT) and photoacoustics, for which the access to full angular range tomographic projections might be not available in clinical practice due to physical or time constraints. Reconstruction from incomplete data in low signal-to-noise ratio regime is a challenging and ill-posed inverse problem that usually leads to unsatisfactory image quality. While informative image priors may be learned using generic deep neural network architectures, the artefacts caused by an ill-conditioned design matrix often have global spatial support and cannot be efficiently filtered out by means of convolutions. In this paper we propose to learn an inverse mapping in an end-to-end fashion via unrolling optimization iterations of a prototypical reconstruction algorithm. We herein introduce a network architecture that performs filtering jointly in both sinogram and spatial domains. To efficiently train such deep network we propose a novel regularization approach based on deep exponential weighting. Experiments on US and X-ray CT data show that our proposed method is qualitatively and quantitatively superior to conventional non-linear reconstruction methods as well as state-of-the-art deep networks for image reconstruction. Fast inference time of the proposed algorithm allows for sophisticated reconstructions in real-time critical settings, demonstrated with US SoS imaging of an ex vivo bovine phantom.
Image Resolution and Contrast Enhancement of Satellite Geographical Images with Removal of Noise using Wavelet Transforms
May 08, 2014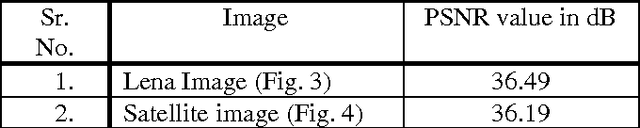
In this paper the technique for resolution and contrast enhancement of satellite geographical images based on discrete wavelet transform (DWT), stationary wavelet transform (SWT) and singular value decomposition (SVD) has been proposed. In this, the noise is added in the input low resolution and low contrast image. The median filter is used remove noise from the input image. This low resolution, low contrast image without noise is decomposed into four sub-bands by using DWT and SWT. The resolution enhancement technique is based on the interpolation of high frequency components obtained by DWT and input image. SWT is used to enhance input image. DWT is used to decompose an image into four frequency sub bands and these four sub-bands are interpolated using bicubic interpolation technique. All these sub-bands are reconstructed as high resolution image by using inverse DWT (IDWT). To increase the contrast the proposed technique uses DWT and SVD. GHE is used to equalize an image. The equalized image is decomposed into four sub-bands using DWT and new LL sub-band is reconstructed using SVD. All sub-bands are reconstructed using IDWT to generate high resolution and contrast image over conventional techniques. The experimental result shows superiority of the proposed technique over conventional techniques. Key words: Discrete wavelet transform (DWT), General histogram equalization (GHE), Median filter, Singular value decomposition (SVD), Stationary wavelet transform (SWT).
* 5 pages, 10 figures