 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semi-supervised Grasp Detection by Representation Learning in a Vector Quantized Latent Space
Jan 25, 2020
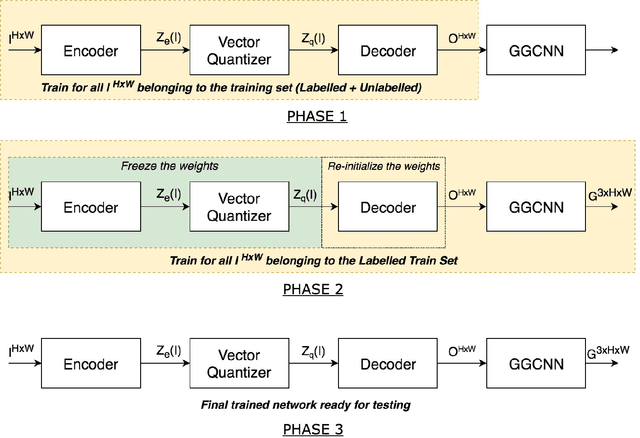
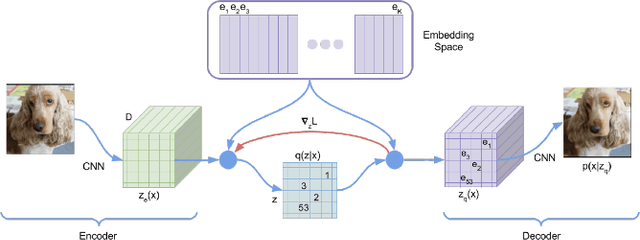
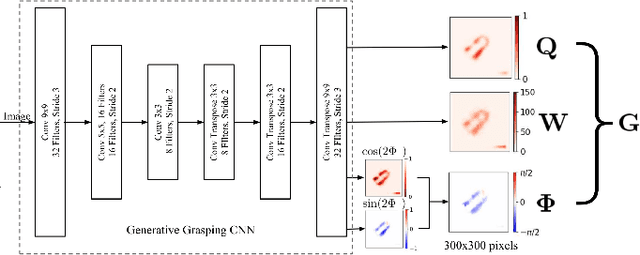
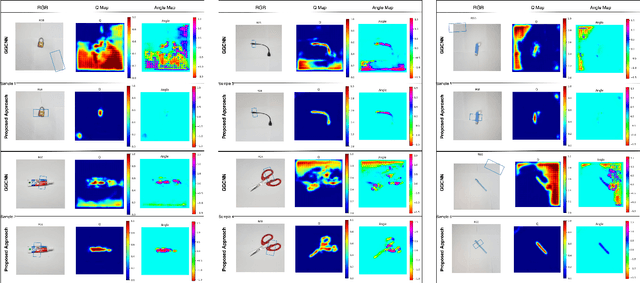
Determining quality grasps from an image is an important area of research. In this work, we present a semi-supervised learning based grasp detection approach which models a discrete latent space using a Vector Quantized Variational Autoencoder (VQ-VAE). To the best of our knowledge, this is the first time VAEs have been applied in the domain of robot grasp detection. The VAE helps the model in generalizing beyond the Cornell Grasping Dataset (CGD) despite having limited amount of labelled data. We validate this claim by testing the model on images not there in the CGD. Also, the model performs significantly better than existing approaches which do not make use of unlabeled images to improve the grasp.
Unsupervised Deep Metric Learning via Auxiliary Rotation Loss
Nov 16, 2019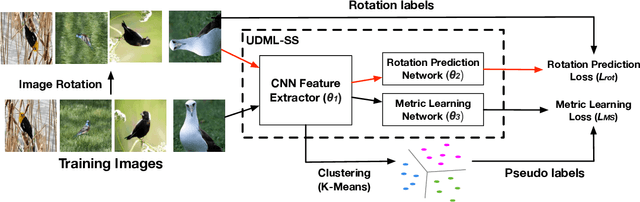
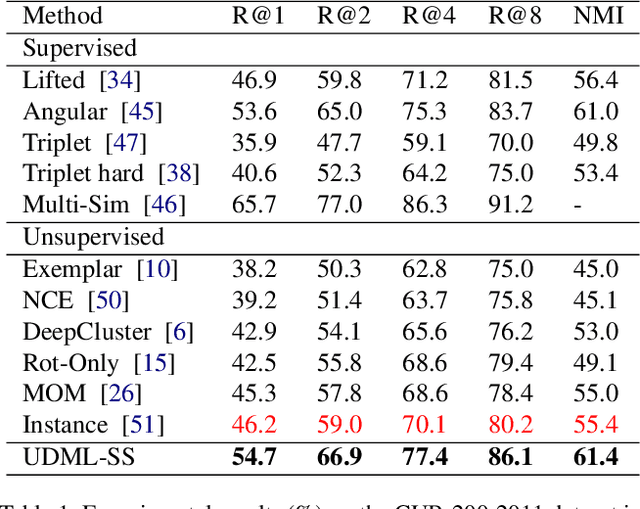

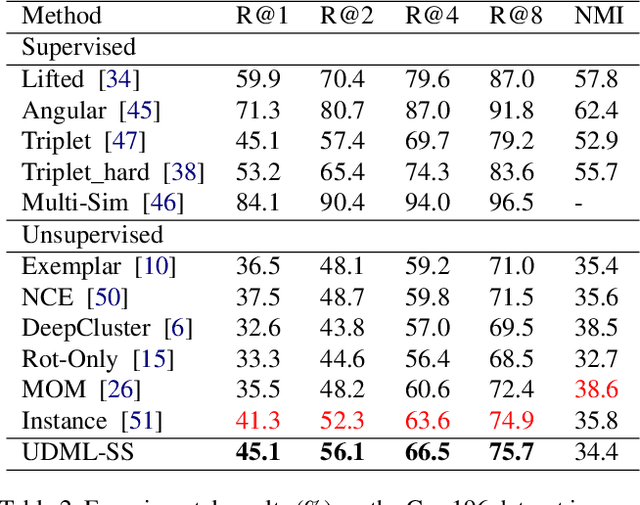
Deep metric learning is an important area due to its applicability to many domains such as image retrieval and person re-identification. The main drawback of such models is the necessity for labeled data. In this work, we propose to generate pseudo-labels for deep metric learning directly from clustering assignment and we introduce unsupervised deep metric learning (UDML) regularized by a self-supervision (SS) task. In particular, we propose to regularize the training process by predicting image rotations. Our method (UDML-SS) jointly learns discriminative embeddings, unsupervised clustering assignments of the embeddings, as well as a self-supervised pretext task. UDML-SS iteratively cluster embeddings using traditional clustering algorithm (e.g., k-means), and sampling training pairs based on the cluster assignment for metric learning, while optimizing self-supervised pretext task in a multi-task fashion. The role of self-supervision is to stabilize the training process and encourages the model to learn meaningful feature representations that are not distorted due to unreliable clustering assignments. The proposed method performs well on standard benchmarks for metric learning, where it outperforms current state-of-the-art approaches by a large margin and it also shows competitive performance with various metric learning loss functions.
On Feature Normalization and Data Augmentation
Mar 06, 2020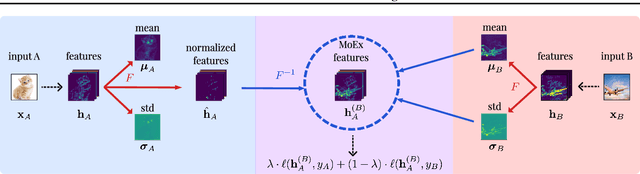
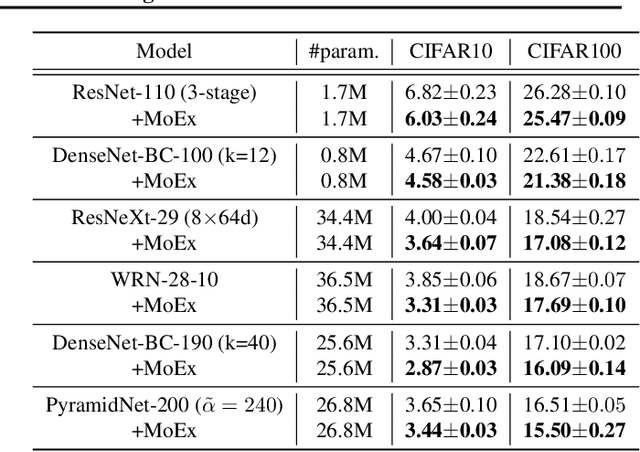
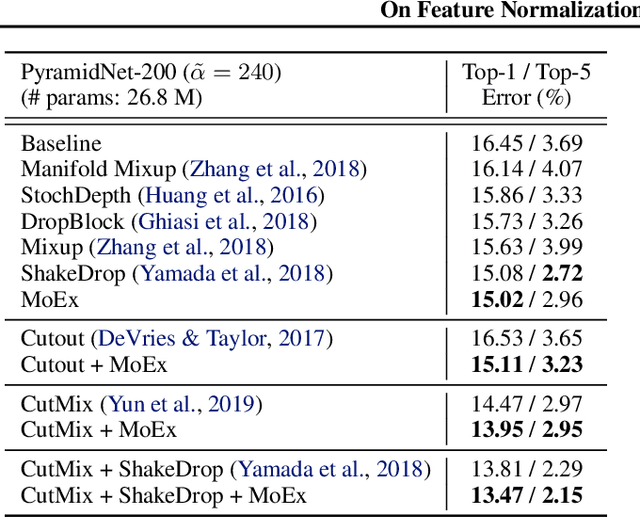
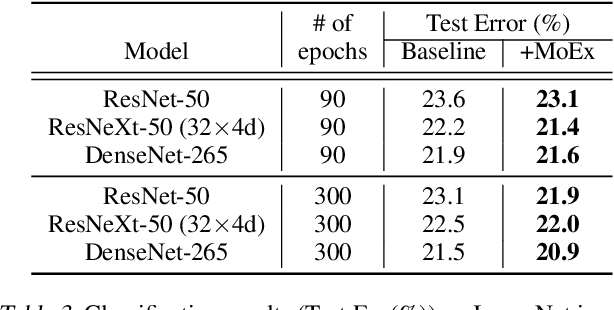
Modern neural network training relies heavily on data augmentation for improved generalization. After the initial success of label-preserving augmentations, there has been a recent surge of interest in label-perturbing approaches, which combine features and labels across training samples to smooth the learned decision surface. In this paper, we propose a new augmentation method that leverages the first and second moments extracted and re-injected by feature normalization. We replace the moments of the learned features of one training image by those of another, and also interpolate the target labels. As our approach is fast, operates entirely in feature space, and mixes different signals than prior methods, one can effectively combine it with existing augmentation methods. We demonstrate its efficacy across benchmark data sets in computer vision, speech, and natural language processing, where it consistently improves the generalization performance of highly competitive baseline networks.
SC-FEGAN: Face Editing Generative Adversarial Network with User's Sketch and Color
Feb 18, 2019

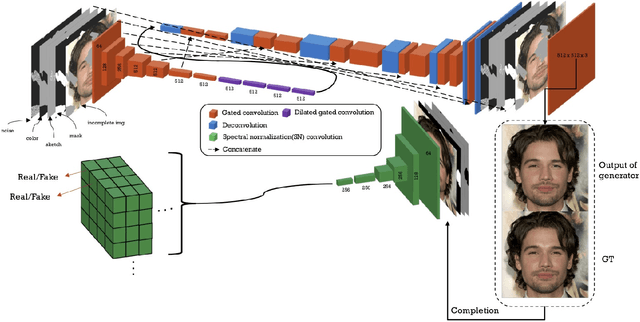

We present a novel image editing system that generates images as the user provides free-form mask, sketch and color as an input. Our system consist of a end-to-end trainable convolutional network. Contrary to the existing methods, our system wholly utilizes free-form user input with color and shape. This allows the system to respond to the user's sketch and color input, using it as a guideline to generate an image. In our particular work, we trained network with additional style loss which made it possible to generate realistic results, despite large portions of the image being removed. Our proposed network architecture SC-FEGAN is well suited to generate high quality synthetic image using intuitive user inputs.
Sparse Sinkhorn Attention
Feb 26, 2020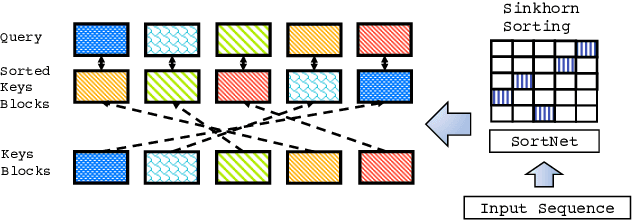
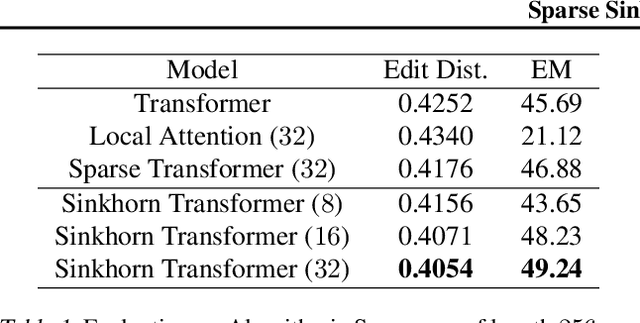
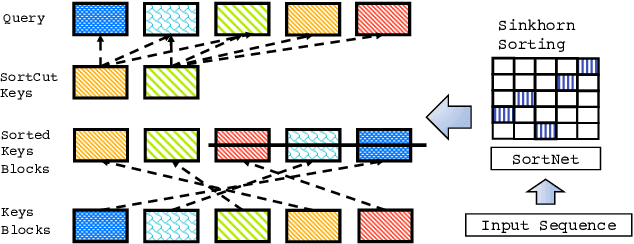
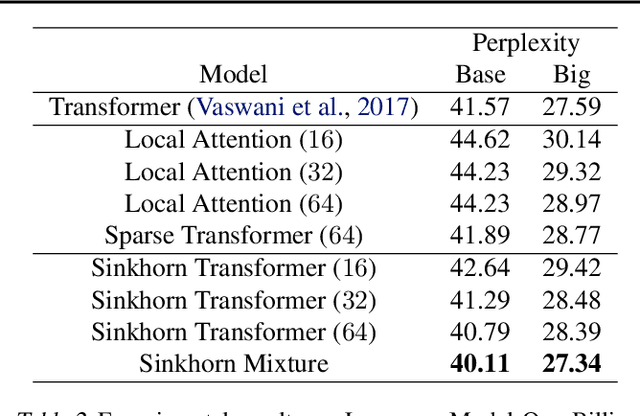
We propose Sparse Sinkhorn Attention, a new efficient and sparse method for learning to attend. Our method is based on differentiable sorting of internal representations. Concretely, we introduce a meta sorting network that learns to generate latent permutations over sequences. Given sorted sequences, we are then able to compute quasi-global attention with only local windows, improving the memory efficiency of the attention module. To this end, we propose new algorithmic innovations such as Causal Sinkhorn Balancing and SortCut, a dynamic sequence truncation method for tailoring Sinkhorn Attention for encoding and/or decoding purposes. Via extensive experiments on algorithmic seq2seq sorting, language modeling, pixel-wise image generation, document classification and natural language inference, we demonstrate that our memory efficient Sinkhorn Attention method is competitive with vanilla attention and consistently outperforms recently proposed efficient Transformer models such as Sparse Transformers.
Detector-SegMentor Network for Skin Lesion Localization and Segmentation
May 13, 2020
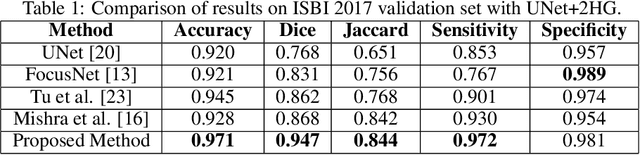
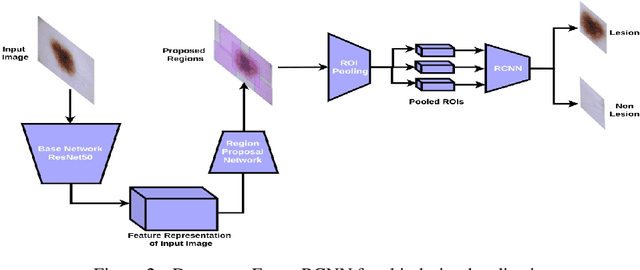

Melanoma is a life-threatening form of skin cancer when left undiagnosed at the early stages. Although there are more cases of non-melanoma cancer than melanoma cancer, melanoma cancer is more deadly. Early detection of melanoma is crucial for the timely diagnosis of melanoma cancer and prohibit its spread to distant body parts. Segmentation of skin lesion is a crucial step in the classification of melanoma cancer from the cancerous lesions in dermoscopic images. Manual segmentation of dermoscopic skin images is very time consuming and error-prone resulting in an urgent need for an intelligent and accurate algorithm. In this study, we propose a simple yet novel network-in-network convolution neural network(CNN) based approach for segmentation of the skin lesion. A Faster Region-based CNN (Faster RCNN) is used for preprocessing to predict bounding boxes of the lesions in the whole image which are subsequently cropped and fed into the segmentation network to obtain the lesion mask. The segmentation network is a combination of the UNet and Hourglass networks. We trained and evaluated our models on ISIC 2018 dataset and also cross-validated on PH\textsuperscript{2} and ISBI 2017 datasets. Our proposed method surpassed the state-of-the-art with Dice Similarity Coefficient of 0.915 and Accuracy 0.959 on ISIC 2018 dataset and Dice Similarity Coefficient of 0.947 and Accuracy 0.971 on ISBI 2017 dataset.
Relevant-features based Auxiliary Cells for Energy Efficient Detection of Natural Errors
Feb 26, 2020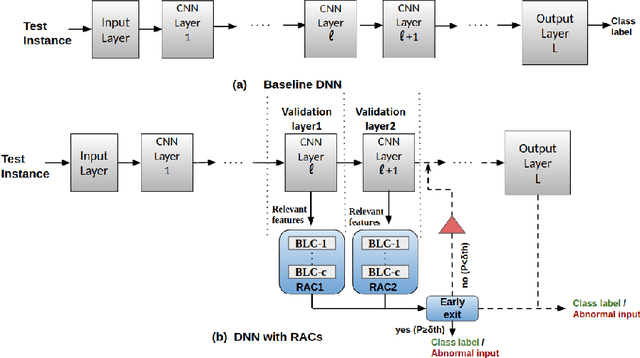
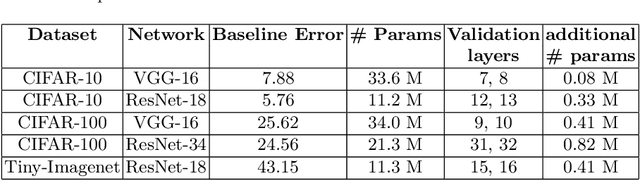
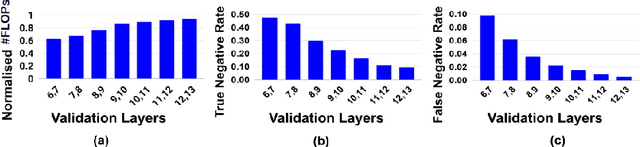
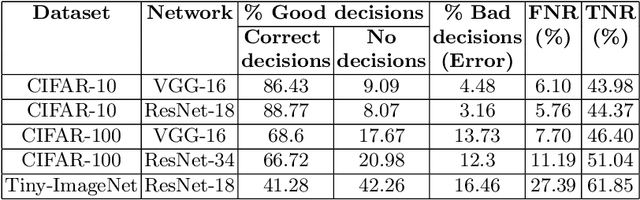
Deep neural networks have demonstrated state-of-the-art performance on many classification tasks. However, they have no inherent capability to recognize when their predictions are wrong. There have been several efforts in the recent past to detect natural errors but the suggested mechanisms pose additional energy requirements. To address this issue, we propose an ensemble of classifiers at hidden layers to enable energy efficient detection of natural errors. In particular, we append Relevant-features based Auxiliary Cells (RACs) which are class specific binary linear classifiers trained on relevant features. The consensus of RACs is used to detect natural errors. Based on combined confidence of RACs, classification can be terminated early, thereby resulting in energy efficient detection. We demonstrate the effectiveness of our technique on various image classification datasets such as CIFAR-10, CIFAR-100 and Tiny-ImageNet.
ARMA Nets: Expanding Receptive Field for Dense Prediction
Feb 15, 2020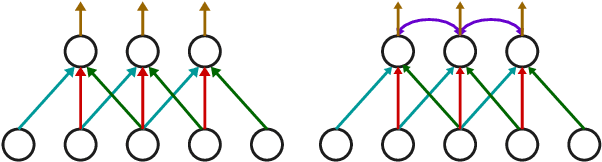

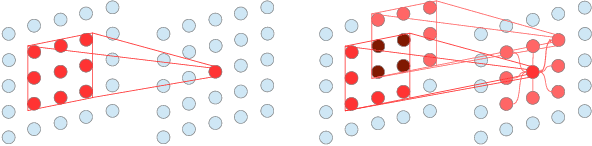
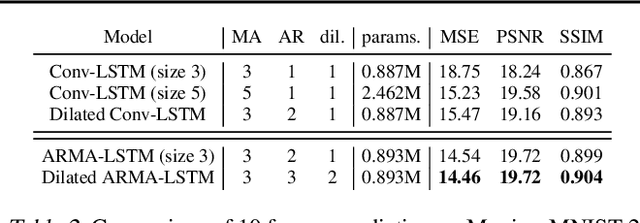
Global information is essential for dense prediction problems, whose goal is to compute a discrete or continuous label for each pixel in the images. Traditional convolutional layers in neural networks, originally designed for image classification, are restrictive in these problems since their receptive fields are limited by the filter size. In this work, we propose autoregressive moving-average (ARMA) layer, a novel module in neural networks to allow explicit dependencies of output neurons, which significantly expands the receptive field with minimal extra parameters. We show experimentally that the effective receptive field of neural networks with ARMA layers expands as autoregressive coefficients become larger. In addition, we demonstrate that neural networks with ARMA layers substantially improve the performance of challenging pixel-level video prediction tasks as our model enlarges the effective receptive field.
Personalized Taste and Cuisine Preference Modeling via Images
Feb 26, 2020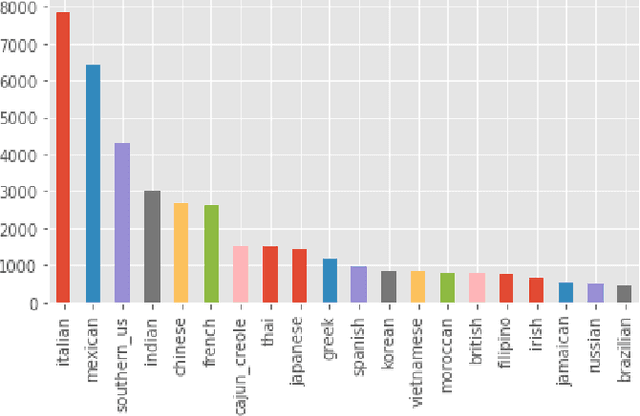
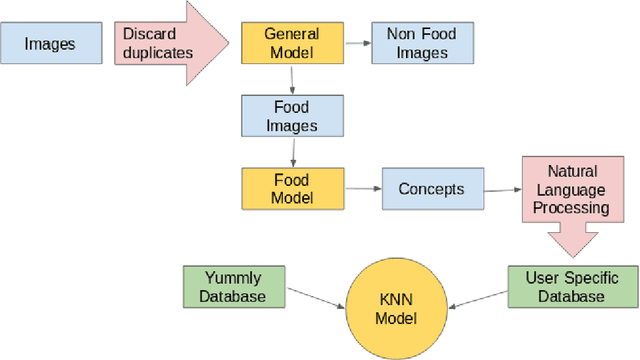
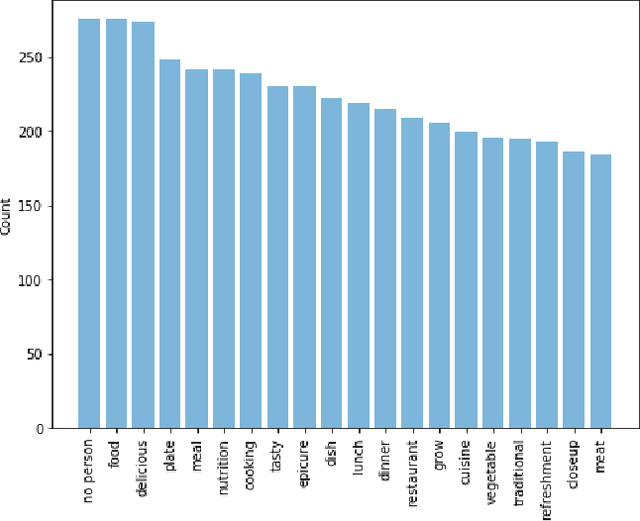
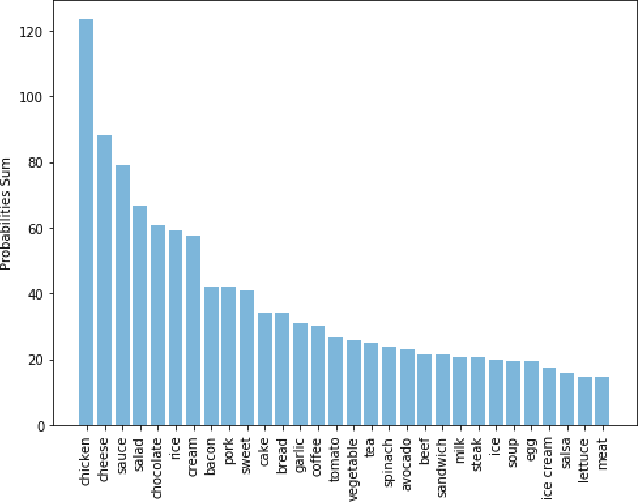
With the exponential growth in the usage of social media to share live updates about life, taking pictures has become an unavoidable phenomenon. Individuals unknowingly create a unique knowledge base with these images. The food images, in particular, are of interest as they contain a plethora of information. From the image metadata and using computer vision tools, we can extract distinct insights for each user to build a personal profile. Using the underlying connection between cuisines and their inherent tastes, we attempt to develop such a profile for an individual based solely on the images of his food. Our study provides insights about an individual's inclination towards particular cuisines. Interpreting these insights can lead to the development of a more precise recommendation system. Such a system would avoid the generic approach in favor of a personalized recommendation system.
Joint Detection and Tracking in Videos with Identification Features
May 25, 2020
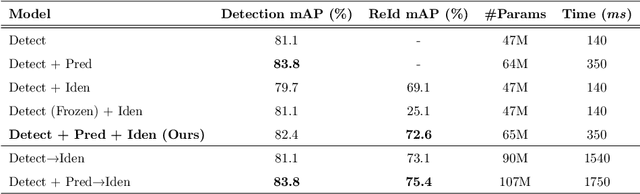
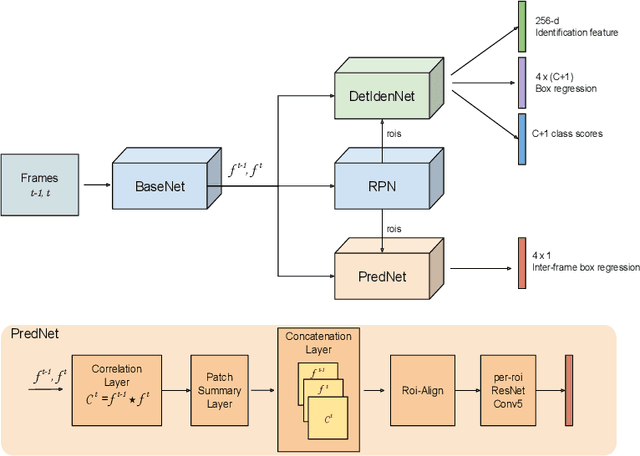
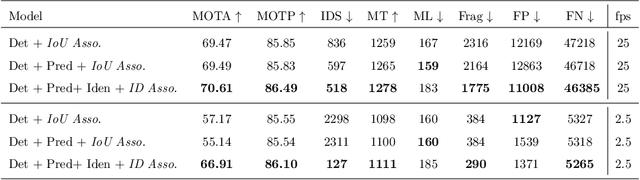
Recent works have shown that combining object detection and tracking tasks, in the case of video data, results in higher performance for both tasks, but they require a high frame-rate as a strict requirement for performance. This is assumption is often violated in real-world applications, when models run on embedded devices, often at only a few frames per second. Videos at low frame-rate suffer from large object displacements. Here re-identification features may support to match large-displaced object detections, but current joint detection and re-identification formulations degrade the detector performance, as these two are contrasting tasks. In the real-world application having separate detector and re-id models is often not feasible, as both the memory and runtime effectively double. Towards robust long-term tracking applicable to reduced-computational-power devices, we propose the first joint optimization of detection, tracking and re-identification features for videos. Notably, our joint optimization maintains the detector performance, a typical multi-task challenge. At inference time, we leverage detections for tracking (tracking-by-detection) when the objects are visible, detectable and slowly moving in the image. We leverage instead re-identification features to match objects which disappeared (e.g. due to occlusion) for several frames or were not tracked due to fast motion (or low-frame-rate videos). Our proposed method reaches the state-of-the-art on MOT, it ranks 1st in the UA-DETRAC'18 tracking challenge among online trackers, and 3rd overall.