 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Lightweight Mask R-CNN for Long-Range Wireless Power Transfer Systems
Apr 19, 2020
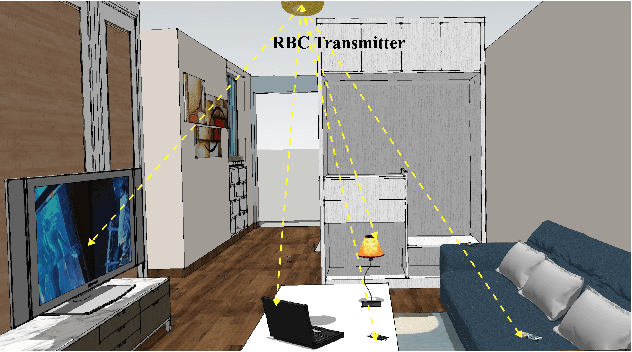
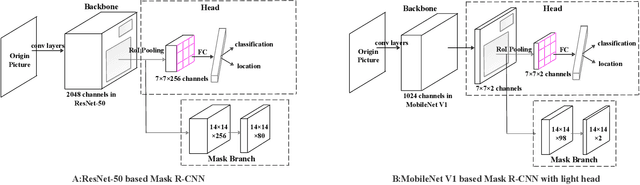


Resonant Beam Charging (RBC) is a wireless charging technology which supports multi-watt power transfer over meter-level distance. The features of safety, mobility and simultaneous charging capability enable RBC to charge multiple mobile devices safely at the same time. To detect the devices that need to be charged, a Mask R-CNN based dection model is proposed in previous work. However, considering the constraints of the RBC system, it's not easy to apply Mask R-CNN in lightweight hardware-embedded devices because of its heavy model and huge computation. Thus, we propose a machine learning detection approach which provides a lighter and faster model based on traditional Mask R-CNN. The proposed approach makes the object detection much easier to be transplanted on mobile devices and reduce the burden of hardware computation. By adjusting the structure of the backbone and the head part of Mask R-CNN, we reduce the average detection time from $1.02\mbox{s}$ per image to $0.6132\mbox{s}$, and reduce the model size from $245\mbox{MB}$ to $47.1\mbox{MB}$. The improved model is much more suitable for the application in the RBC system.
An Elastic Image Registration Approach for Wireless Capsule Endoscope Localization
Apr 23, 2015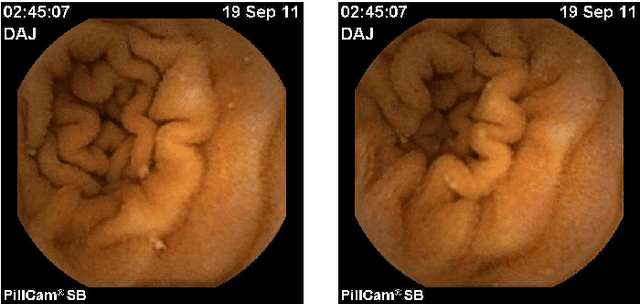

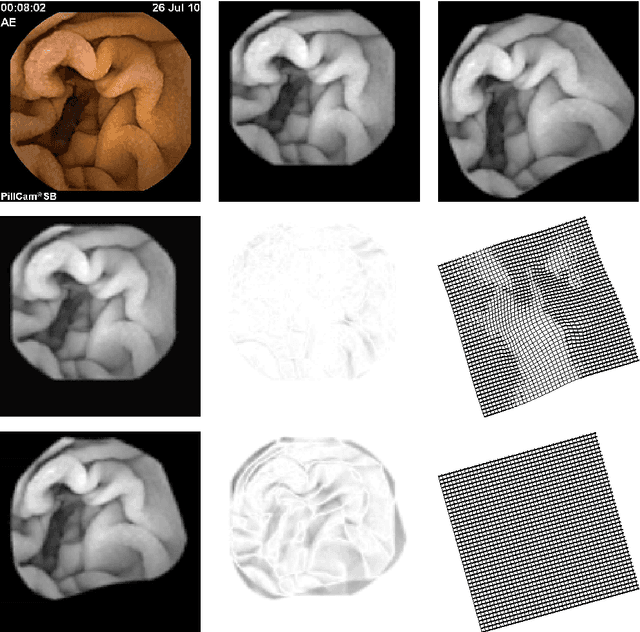
Wireless Capsule Endoscope (WCE) is an innovative imaging device that permits physicians to examine all the areas of the Gastrointestinal (GI) tract. It is especially important for the small intestine, where traditional invasive endoscopies cannot reach. Although WCE represents an extremely important advance in medical imaging, a major drawback that remains unsolved is the WCE precise location in the human body during its operating time. This is mainly due to the complex physiological environment and the inherent capsule effects during its movement. When an abnormality is detected, in the WCE images, medical doctors do not know precisely where this abnormality is located relative to the intestine and therefore they can not proceed efficiently with the appropriate therapy. The primary objective of the present paper is to give a contribution to WCE localization, using image-based methods. The main focus of this work is on the description of a multiscale elastic image registration approach, its experimental application on WCE videos, and comparison with a multiscale affine registration. The proposed approach includes registrations that capture both rigid-like and non-rigid deformations, due respectively to the rigid-like WCE movement and the elastic deformation of the small intestine originated by the GI peristaltic movement. Under this approach a qualitative information about the WCE speed can be obtained, as well as the WCE location and orientation via projective geometry. The results of the experimental tests with real WCE video frames show the good performance of the proposed approach, when elastic deformations of the small intestine are involved in successive frames, and its superiority with respect to a multiscale affine image registration, which accounts for rigid-like deformations only and discards elastic deformations.
Deep Fusion Siamese Network for Automatic Kinship Verification
Jun 07, 2020

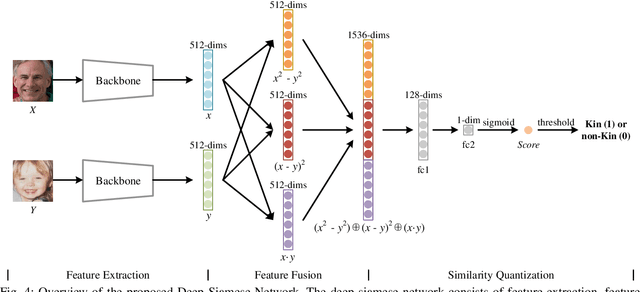
Automatic kinship verification aims to determine whether some individuals belong to the same family. It is of great research significance to help missing persons reunite with their families. In this work, the challenging problem is progressively addressed in two respects. First, we propose a deep siamese network to quantify the relative similarity between two individuals. When given two input face images, the deep siamese network extracts the features from them and fuses these features by combining and concatenating. Then, the fused features are fed into a fully-connected network to obtain the similarity score between two faces, which is used to verify the kinship. To improve the performance, a jury system is also employed for multi-model fusion. Second, two deep siamese networks are integrated into a deep triplet network for tri-subject (i.e., father, mother and child) kinship verification, which is intended to decide whether a child is related to a pair of parents or not. Specifically, the obtained similarity scores of father-child and mother-child are weighted to generate the parent-child similarity score for kinship verification. Recognizing Families In the Wild (RFIW) is a challenging kinship recognition task with multiple tracks, which is based on Families in the Wild (FIW), a large-scale and comprehensive image database for automatic kinship recognition. The Kinship Verification (track I) and Tri-Subject Verification (track II) are supported during the ongoing RFIW2020 Challenge. Our team (ustc-nelslip) ranked 1st in track II, and 3rd in track I. The code is available at https://github.com/gniknoil/FG2020-kinship.
* 8 pages, 8 figures
On adversarial patches: real-world attack on ArcFace-100 face recognition system
Oct 15, 2019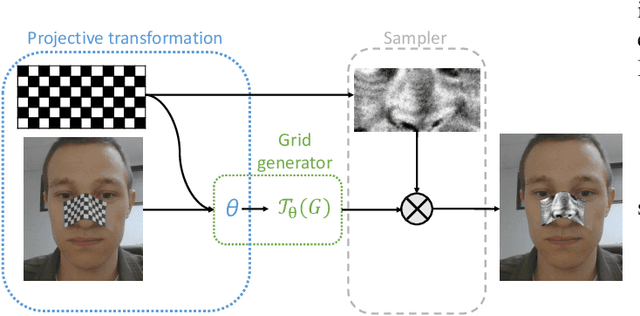
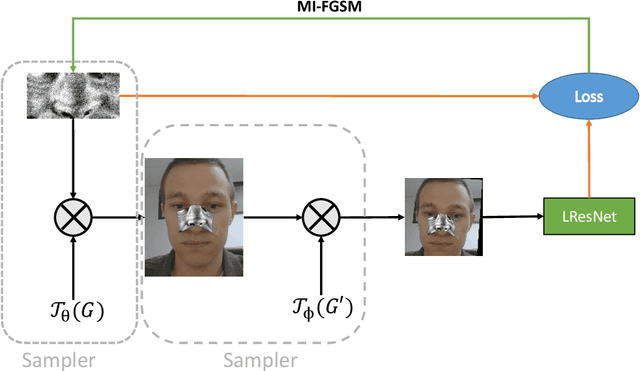


Recent works showed the vulnerability of image classifiers to adversarial attacks in the digital domain. However, the majority of attacks involve adding small perturbation to an image to fool the classifier. Unfortunately, such procedures can not be used to conduct a real-world attack, where adding an adversarial attribute to the photo is a more practical approach. In this paper, we study the problem of real-world attacks on face recognition systems. We examine security of one of the best public face recognition systems, LResNet100E-IR with ArcFace loss, and propose a simple method to attack it in the physical world. The method suggests creating an adversarial patch that can be printed, added as a face attribute and photographed; the photo of a person with such attribute is then passed to the classifier such that the classifier's recognized class changes from correct to the desired one. Proposed generating procedure allows projecting adversarial patches not only on different areas of the face, such as nose or forehead but also on some wearable accessory, such as eyeglasses.
Weakly Supervised Vessel Segmentation in X-ray Angiograms by Self-Paced Learning from Noisy Labels with Suggestive Annotation
May 27, 2020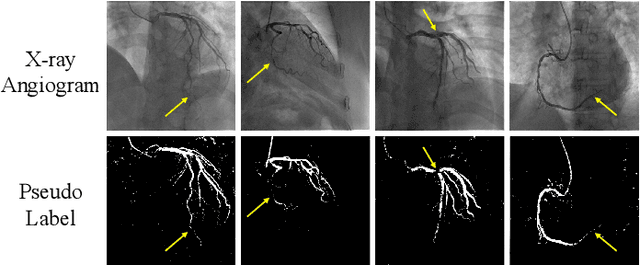
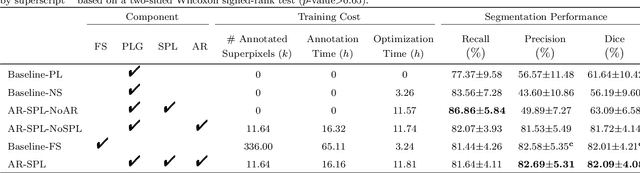
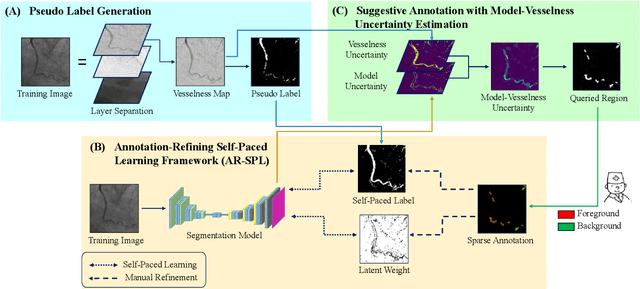
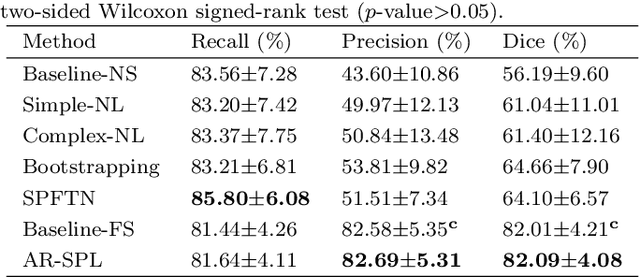
The segmentation of coronary arteries in X-ray angiograms by convolutional neural networks (CNNs) is promising yet limited by the requirement of precisely annotating all pixels in a large number of training images, which is extremely labor-intensive especially for complex coronary trees. To alleviate the burden on the annotator, we propose a novel weakly supervised training framework that learns from noisy pseudo labels generated from automatic vessel enhancement, rather than accurate labels obtained by fully manual annotation. A typical self-paced learning scheme is used to make the training process robust against label noise while challenged by the systematic biases in pseudo labels, thus leading to the decreased performance of CNNs at test time. To solve this problem, we propose an annotation-refining self-paced learning framework (AR-SPL) to correct the potential errors using suggestive annotation. An elaborate model-vesselness uncertainty estimation is also proposed to enable the minimal annotation cost for suggestive annotation, based on not only the CNNs in training but also the geometric features of coronary arteries derived directly from raw data. Experiments show that our proposed framework achieves 1) comparable accuracy to fully supervised learning, which also significantly outperforms other weakly supervised learning frameworks; 2) largely reduced annotation cost, i.e., 75.18% of annotation time is saved, and only 3.46% of image regions are required to be annotated; and 3) an efficient intervention process, leading to superior performance with even fewer manual interactions.
An End-to-end Framework For Low-Resolution Remote Sensing Semantic Segmentation
Mar 17, 2020



High-resolution images for remote sensing applications are often not affordable or accessible, especially when in need of a wide temporal span of recordings. Given the easy access to low-resolution (LR) images from satellites, many remote sensing works rely on this type of data. The problem is that LR images are not appropriate for semantic segmentation, due to the need for high-quality data for accurate pixel prediction for this task. In this paper, we propose an end-to-end framework that unites a super-resolution and a semantic segmentation module in order to produce accurate thematic maps from LR inputs. It allows the semantic segmentation network to conduct the reconstruction process, modifying the input image with helpful textures. We evaluate the framework with three remote sensing datasets. The results show that the framework is capable of achieving a semantic segmentation performance close to native high-resolution data, while also surpassing the performance of a network trained with LR inputs.
Towards Robust Learning with Different Label Noise Distributions
Dec 18, 2019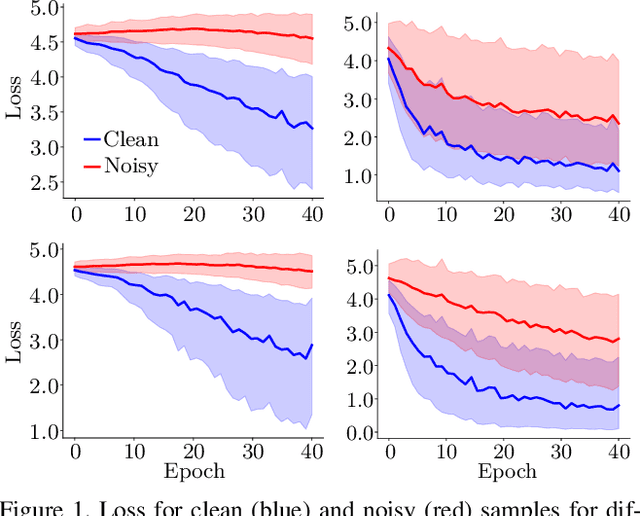

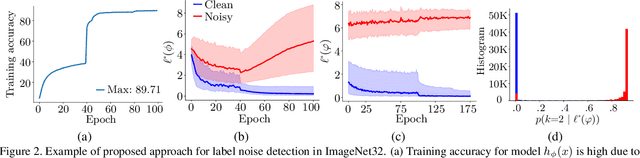
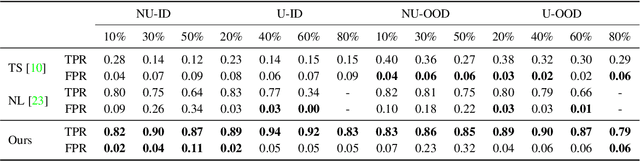
Noisy labels are an unavoidable consequence of automatic image labeling processes to reduce human supervision. Training in these conditions leads Convolutional Neural Networks to memorize label noise and degrade performance. Noisy labels are therefore dispensable, while image content can be exploited in a semi-supervised learning (SSL) setup. Handling label noise then becomes a label noise detection task. Noisy/clean samples are usually identified using the \textit{small loss trick}, which is based on the observation that clean samples represent easier patterns and, therefore, exhibit a lower loss. However, we show that different noise distributions make the application of this trick less straightforward. We propose to continuously relabel all images to reveal a loss that facilitates the use of the small loss trick with different noise distributions. SSL is then applied twice, once to improve the clean-noisy detection and again for training the final model. We design an experimental setup for better understanding the consequences of differing label noise distributions and find that non-uniform out-of-distribution noise better resembles real-world noise. We show that SSL outperforms other alternatives when using oracles and demonstrate substantial improvements across five datasets of our label noise Distribution Robust Pseudo-Labeling (DRPL). We further study the effects of label noise memorization via linear probes and find that in most cases intermediate features are not affected by label noise corruption. Code and details to reproduce our framework will be made available.
A New Model of Array Grammar for generating Connected Patterns on an Image Neighborhood
Jul 31, 2014Study of patterns on images is recognized as an important step in characterization and classification of image. The ability to efficiently analyze and describe image patterns is thus of fundamental importance. The study of syntactic methods of describing pictures has been of interest for researchers. Array Grammars can be used to represent and recognize connected patterns. In any image the patterns are recognized using connected patterns. It is very difficult to represent all connected patterns (CP) even on a small 3 x 3 neighborhood in a pictorial way. The present paper proposes the model of array grammar capable of generating any kind of simple or complex pattern and derivation of connected pattern in an image neighborhood using the proposed grammar is discussed.
LADN: Local Adversarial Disentangling Network for Facial Makeup and De-Makeup
Apr 25, 2019

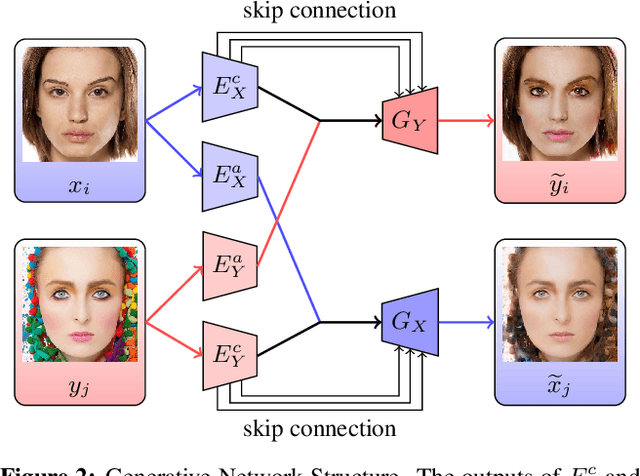
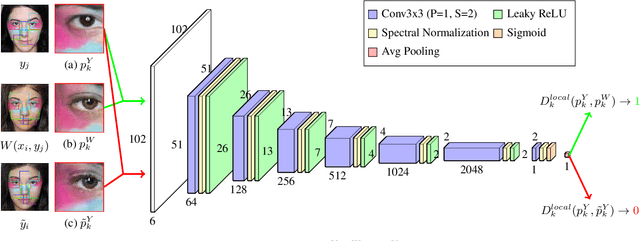
We propose a local adversarial disentangling network (LADN) for facial makeup and de-makeup. Central to our method are multiple and overlapping local adversarial discriminators in a content-style disentangling network for achieving local detail transfer between facial images, with the use of asymmetric loss functions for dramatic makeup styles with high-frequency details. Existing techniques do not demonstrate or fail to transfer high-frequency details in a global adversarial setting, or train a single local discriminator only to ensure image structure consistency and thus work only for relatively simple styles. Unlike others, our proposed local adversarial discriminators can distinguish whether the generated local image details are consistent with the corresponding regions in the given reference image in cross-image style transfer in an unsupervised setting. Incorporating these technical contributions, we achieve not only state-of-the-art results on conventional styles but also novel results involving complex and dramatic styles with high-frequency details covering large areas across multiple facial features. A carefully designed dataset of unpaired before and after makeup images will be released.
Wavelet Frame Based Image Restoration Using Sparsity, Nonlocal and Support Prior of Frame Coefficients
Oct 10, 2015
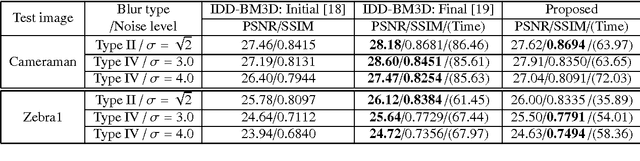
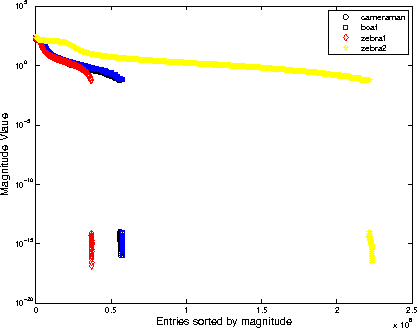

The wavelet frame systems have been widely investigated and applied for image restoration and many other image processing problems over the past decades, attributing to their good capability of sparsely approximating piece-wise smooth functions such as images. Most wavelet frame based models exploit the $l_1$ norm of frame coefficients for a sparsity constraint in the past. The authors in \cite{ZhangY2013, Dong2013} proposed an $l_0$ minimization model, where the $l_0$ norm of wavelet frame coefficients is penalized instead, and have demonstrated that significant improvements can be achieved compared to the commonly used $l_1$ minimization model. Very recently, the authors in \cite{Chen2015} proposed $l_0$-$l_2$ minimization model, where the nonlocal prior of frame coefficients is incorporated. This model proved to outperform the single $l_0$ minimization based model in terms of better recovered image quality. In this paper, we propose a truncated $l_0$-$l_2$ minimization model which combines sparsity, nonlocal and support prior of the frame coefficients. The extensive experiments have shown that the recovery results from the proposed regularization method performs better than existing state-of-the-art wavelet frame based methods, in terms of edge enhancement and texture preserving performance.