 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ChromaGAN: An Adversarial Approach for Picture Colorization
Jul 23, 2019

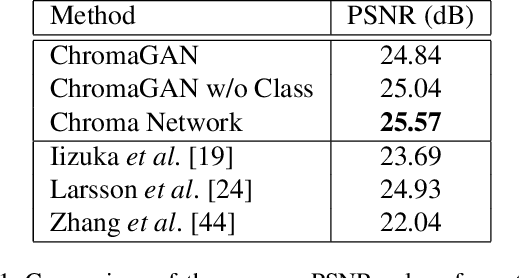
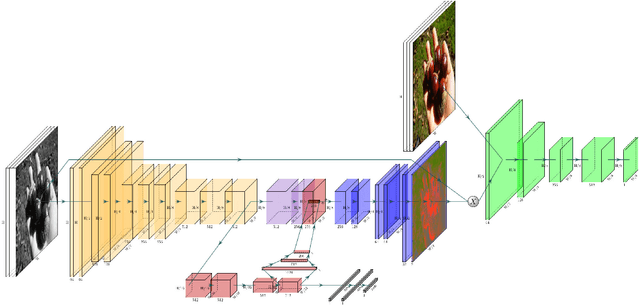

The colorization of grayscale images is an ill-posed problem, with multiple correct solutions. In this paper, an adversarial learning approach is proposed. A generator network is used to infer the chromaticity of a given grayscale image. The same network also performs a semantic classification of the image. This network is framed in an adversarial model that learns to colorize by incorporating perceptual and semantic understanding of color and class distributions. The model is trained via a fully self-supervised strategy. Qualitative and quantitative results show the capacity of the proposed method to colorize images in a realistic way, achieving top-tier performances relative to the state-of-the-art.
Multi-organ Segmentation over Partially Labeled Datasets with Multi-scale Feature Abstraction
Jan 01, 2020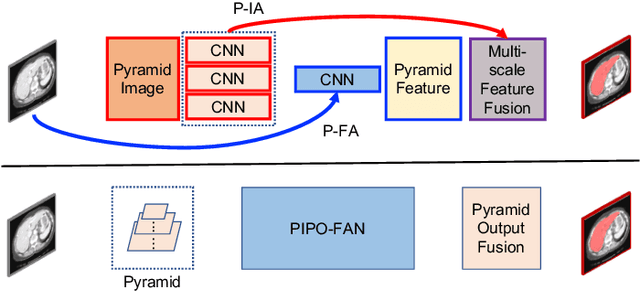
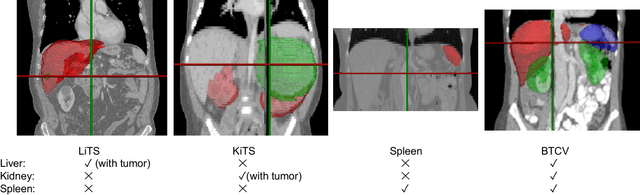
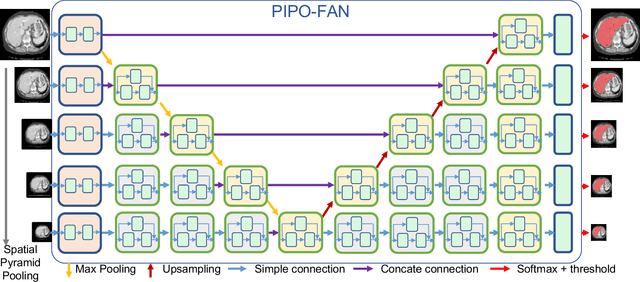
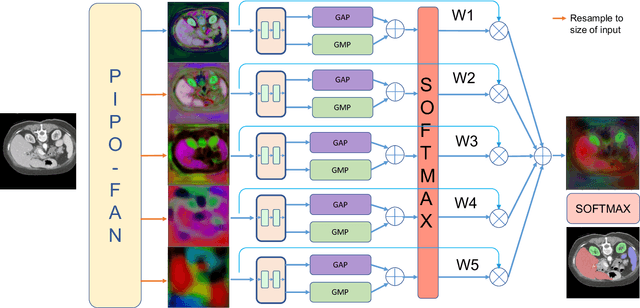
This paper presents a unified training strategy that enables a novel multi-scale deep neural network to be trained on multiple partially labeled datasets for multi-organ segmentation. Multi-scale contextual information is effective for pixel-level label prediction, i.e. image segmentation. However, such important information is only partially exploited by the existing methods. In this paper, we propose a new network architecture for multi-scale feature abstraction, which integrates pyramid feature analysis into an image segmentation model. To bridge the semantic gap caused by directly merging features from different scales, an equal convolutional depth mechanism is proposed. In addition, we develop a deep supervision mechanism for refining outputs in different scales. To fully leverage the segmentation features from different scales, we design an adaptive weighting layer to fuse the outputs in an automatic fashion. All these features together integrate into a pyramid-input pyramid-output network for efficient feature extraction. Last but not least, to alleviate the hunger for fully annotated data in training deep segmentation models, a unified training strategy is proposed to train one segmentation model on multiple partially labeled datasets for multi-organ segmentation with a novel target adaptive loss. Our proposed method was evaluated on four publicly available datasets, including BTCV, LiTS, KiTS and Spleen, where very promising performance has been achieved. The source code of this work is publicly shared at https://github.com/DIAL-RPI/PIPO-FAN for others to easily reproduce the work and build their own models with the introduced mechanisms.
Dense and Sparse Coding: Theory and Architectures
Jun 16, 2020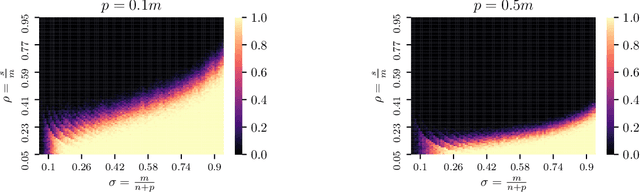
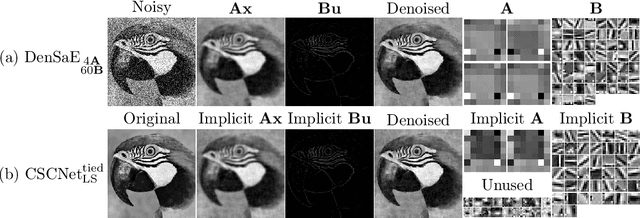
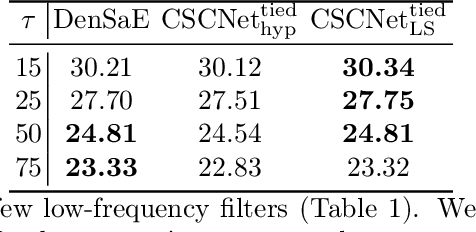
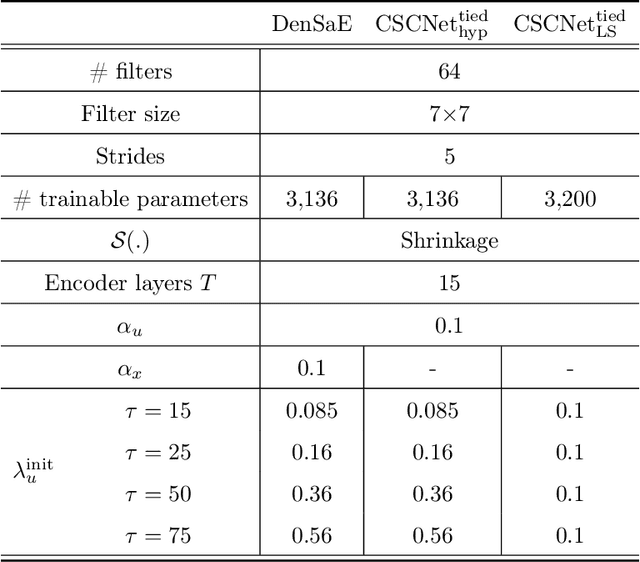
The sparse representation model has been successfully utilized in a number of signal and image processing tasks; however, recent research has highlighted its limitations in certain deep-learning architectures. This paper proposes a novel dense and sparse coding model that considers the problem of recovering a dense vector $\mathbf{x}$ and a sparse vector $\mathbf{u}$ given linear measurements of the form $\mathbf{y} = \mathbf{A}\mathbf{x}+\mathbf{B}\mathbf{u}$. Our first theoretical result proposes a new natural geometric condition based on the minimal angle between subspaces corresponding to the measurement matrices $\mathbf{A}$ and $\mathbf{B}$ to establish the uniqueness of solutions to the linear system. The second analysis shows that, under mild assumptions and sufficient linear measurements, a convex program recovers the dense and sparse components with high probability. The standard RIPless analysis cannot be directly applied to this setup. Our proof is a non-trivial adaptation of techniques from anisotropic compressive sensing theory and is based on an analysis of a matrix derived from the measurement matrices $\mathbf{A}$ and $\mathbf{B}$. We begin by demonstrating the effectiveness of the proposed model on simulated data. Then, to address its use in a dictionary learning setting, we propose a dense and sparse auto-encoder (DenSaE) that is tailored to it. We demonstrate that a) DenSaE denoises natural images better than architectures derived from the sparse coding model ($\mathbf{B}\mathbf{u}$), b) training the biases in the latter amounts to implicitly learning the $\mathbf{A}\mathbf{x} + \mathbf{B}\mathbf{u}$ model, and c) $\mathbf{A}$ and $\mathbf{B}$ capture low- and high-frequency contents, respectively.
Deep Partition Aggregation: Provable Defense against General Poisoning Attacks
Jun 26, 2020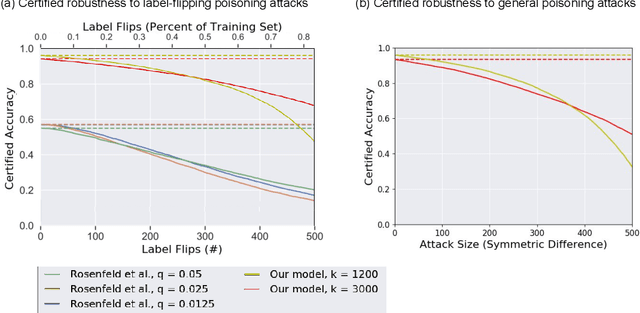
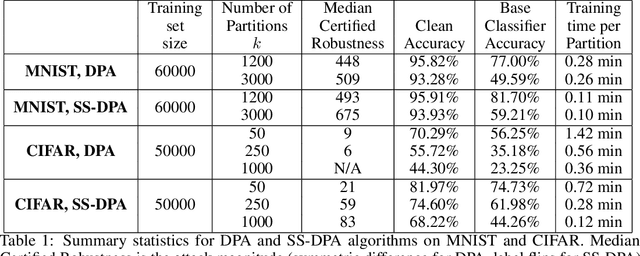
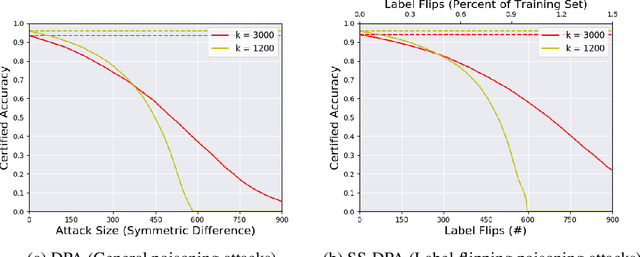
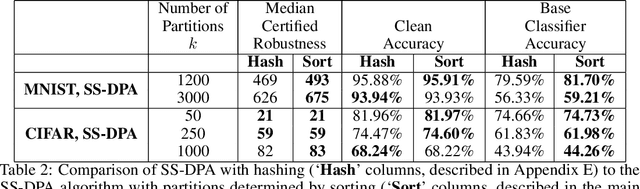
Adversarial poisoning attacks distort training data in order to corrupt the test-time behavior of a classifier. A provable defense provides a certificate for each test sample, which is a lower bound on the magnitude of any adversarial distortion of the training set that can corrupt the test sample's classification. We propose two provable defenses against poisoning attacks: (i) Deep Partition Aggregation (DPA), a certified defense against a general poisoning threat model, defined as the insertion or deletion of a bounded number of samples to the training set -- by implication, this threat model also includes arbitrary distortions to a bounded number of images and/or labels; and (ii) Semi-Supervised DPA (SS-DPA), a certified defense against label-flipping poisoning attacks. DPA is an ensemble method where base models are trained on partitions of the training set determined by a hash function. DPA is related to subset aggregation, a well-studied ensemble method in classical machine learning. DPA can also be viewed as an extension of randomized ablation (Levine & Feizi, 2020a), a certified defense against sparse evasion attacks, to the poisoning domain. Our label-flipping defense, SS-DPA, uses a semi-supervised learning algorithm as its base classifier model: we train each base classifier using the entire unlabeled training set in addition to the labels for a partition. SS-DPA outperforms the existing certified defense for label-flipping attacks (Rosenfeld et al., 2020). SS-DPA certifies >= 50% of test images against 675 label flips (vs. < 200 label flips with the existing defense) on MNIST and 83 label flips on CIFAR-10. Against general poisoning attacks (no prior certified defense), DPA certifies >= 50% of test images against > 500 poison image insertions on MNIST, and nine insertions on CIFAR-10. These results establish new state-of-the-art provable defenses against poison attacks.
Image Score: How to Select Useful Samples
Dec 02, 2018
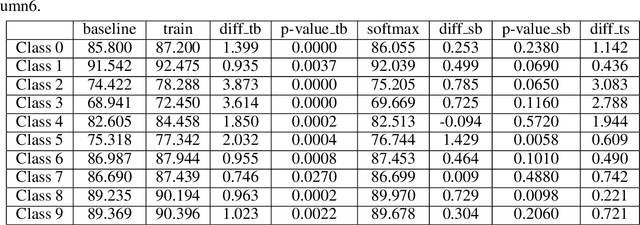
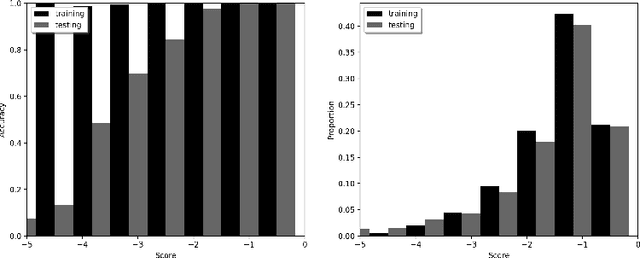
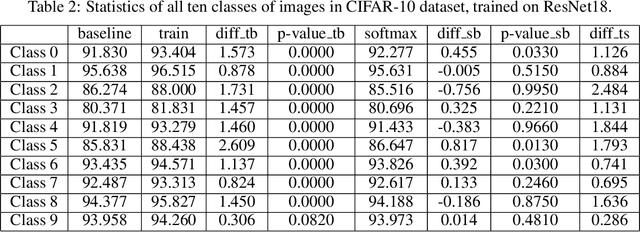
There has long been debates on how we could interpret neural networks and understand the decisions our models make. Specifically, why deep neural networks tend to be error-prone when dealing with samples that output low softmax scores. We present an efficient approach to measure the confidence of decision-making steps by statistically investigating each unit's contribution to that decision. Instead of focusing on how the models react on datasets, we study the datasets themselves given a pre-trained model. Our approach is capable of assigning a score to each sample within a dataset that measures the frequency of occurrence of that sample's chain of activation. We demonstrate with experiments that our method could select useful samples to improve deep neural networks in a semi-supervised leaning setting.
Incremental Learning Techniques for Semantic Segmentation
Sep 17, 2019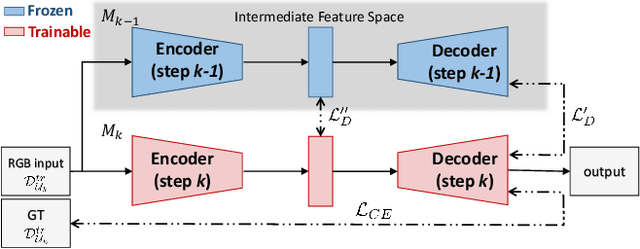
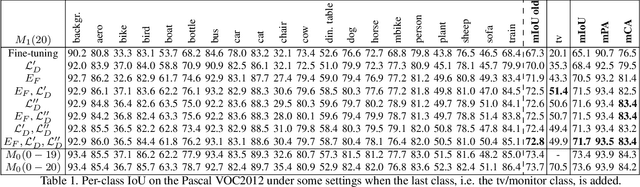
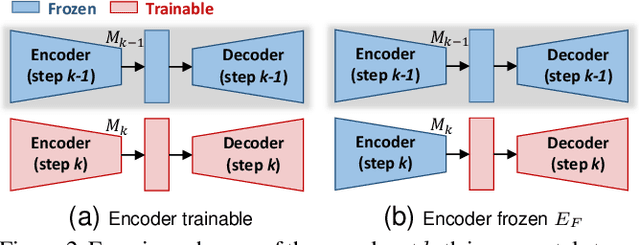
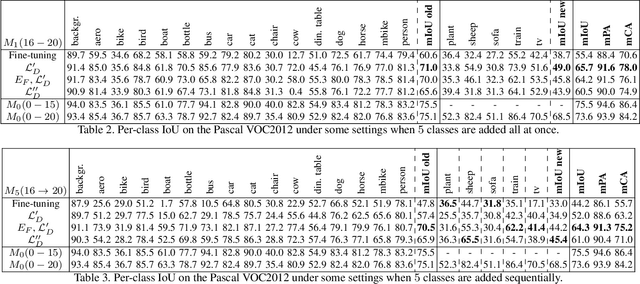
Deep learning architectures exhibit a critical drop of performance due to catastrophic forgetting when they are required to incrementally learn new tasks. Contemporary incremental learning frameworks focus on image classification and object detection while in this work we formally introduce the incremental learning problem for semantic segmentation in which a pixel-wise labeling is considered. To tackle this task we propose to distill the knowledge of the previous model to retain the information about previously learned classes, whilst updating the current model to learn the new ones. We propose various approaches working both on the output logits and on intermediate features. In opposition to some recent frameworks, we do not store any image from previously learned classes and only the last model is needed to preserve high accuracy on these classes. The experimental evaluation on the Pascal VOC2012 dataset shows the effectiveness of the proposed approaches.
* 8 pages, 3 figures, 4 tables
A DCT Approximation for Image Compression
Feb 25, 2014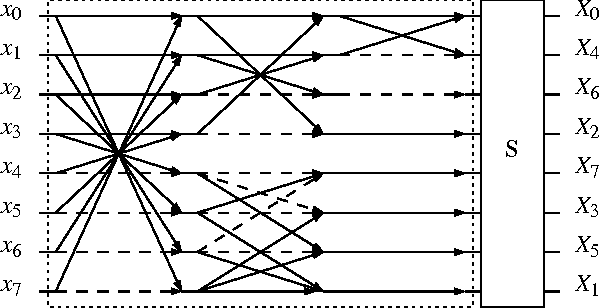
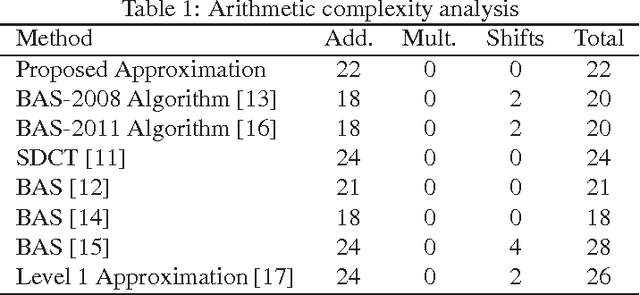
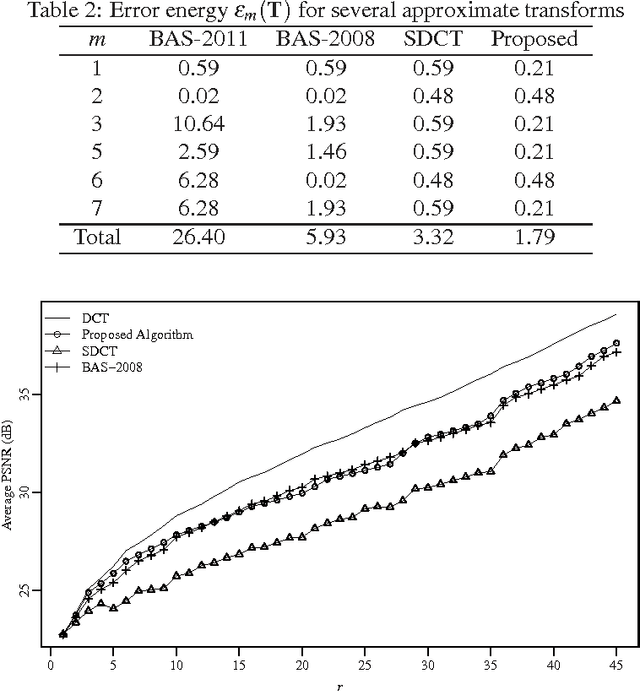
An orthogonal approximation for the 8-point discrete cosine transform (DCT) is introduced. The proposed transformation matrix contains only zeros and ones; multiplications and bit-shift operations are absent. Close spectral behavior relative to the DCT was adopted as design criterion. The proposed algorithm is superior to the signed discrete cosine transform. It could also outperform state-of-the-art algorithms in low and high image compression scenarios, exhibiting at the same time a comparable computational complexity.
* 10 pages, 6 figures
Towards Robust Learning with Different Label Noise Distributions
Dec 18, 2019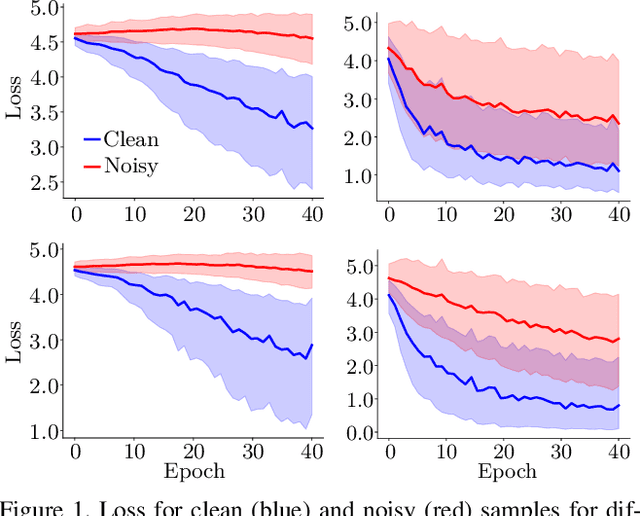

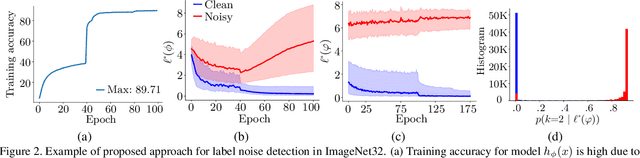
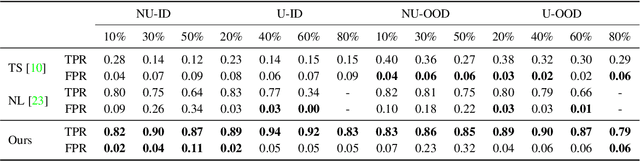
Noisy labels are an unavoidable consequence of automatic image labeling processes to reduce human supervision. Training in these conditions leads Convolutional Neural Networks to memorize label noise and degrade performance. Noisy labels are therefore dispensable, while image content can be exploited in a semi-supervised learning (SSL) setup. Handling label noise then becomes a label noise detection task. Noisy/clean samples are usually identified using the \textit{small loss trick}, which is based on the observation that clean samples represent easier patterns and, therefore, exhibit a lower loss. However, we show that different noise distributions make the application of this trick less straightforward. We propose to continuously relabel all images to reveal a loss that facilitates the use of the small loss trick with different noise distributions. SSL is then applied twice, once to improve the clean-noisy detection and again for training the final model. We design an experimental setup for better understanding the consequences of differing label noise distributions and find that non-uniform out-of-distribution noise better resembles real-world noise. We show that SSL outperforms other alternatives when using oracles and demonstrate substantial improvements across five datasets of our label noise Distribution Robust Pseudo-Labeling (DRPL). We further study the effects of label noise memorization via linear probes and find that in most cases intermediate features are not affected by label noise corruption. Code and details to reproduce our framework will be made available.
Dense Relational Captioning: Triple-Stream Networks for Relationship-Based Captioning
Apr 01, 2019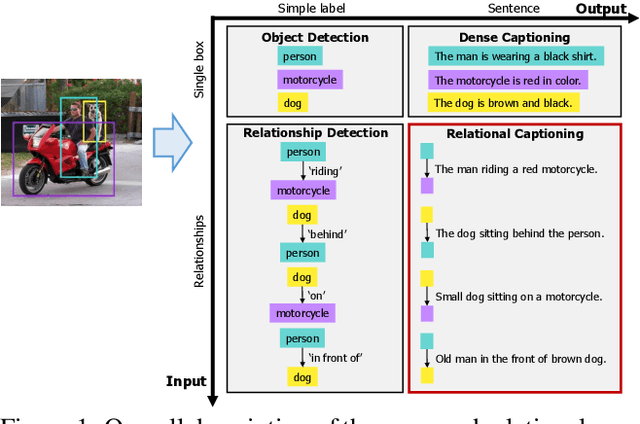
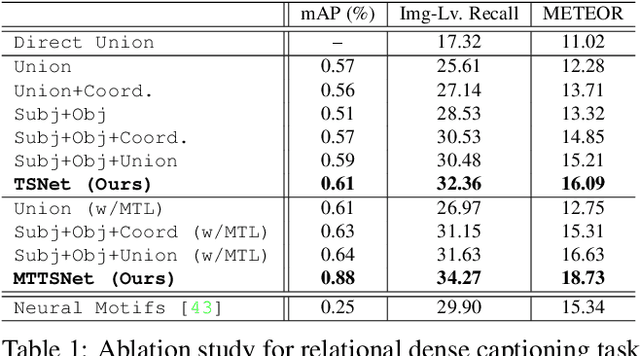
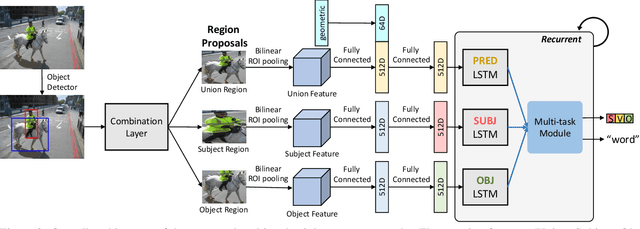
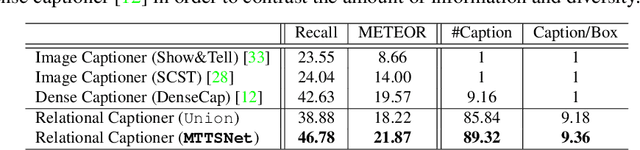
Our goal in this work is to train an image captioning model that generates more dense and informative captions. We introduce "relational captioning," a novel image captioning task which aims to generate multiple captions with respect to relational information between objects in an image. Relational captioning is a framework that is advantageous in both diversity and amount of information, leading to image understanding based on relationships. Part-of speech (POS, i.e. subject-object-predicate categories) tags can be assigned to every English word. We leverage the POS as a prior to guide the correct sequence of words in a caption. To this end, we propose a multi-task triple-stream network (MTTSNet) which consists of three recurrent units for the respective POS and jointly performs POS prediction and captioning. We demonstrate more diverse and richer representations generated by the proposed model against several baselines and competing methods.
Embodied Language Grounding with Implicit 3D Visual Feature Representations
Oct 02, 2019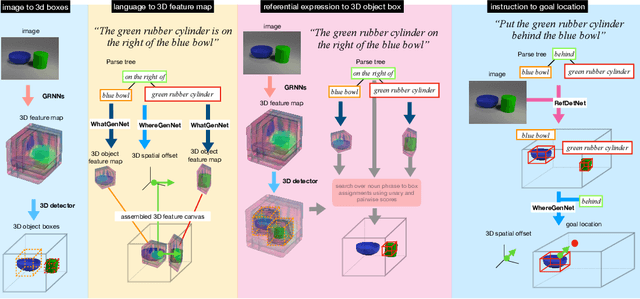



Consider the utterance "the tomato is to the left of the pot." Humans can answer numerous questions about the situation described, as well as reason through counterfactuals and alternatives, such as, "is the pot larger than the tomato ?", "can we move to a viewpoint from which the tomato is completely hidden behind the pot ?", "can we have an object that is both to the left of the tomato and to the right of the pot ?", "would the tomato fit inside the pot ?", and so on. Such reasoning capability remains elusive from current computational models of language understanding. To link language processing with spatial reasoning, we propose associating natural language utterances to a mental workspace of their meaning, encoded as 3-dimensional visual feature representations of the world scenes they describe. We learn such 3-dimensional visual representations---we call them visual imaginations--- by predicting images a mobile agent sees while moving around in the 3D world. The input image streams the agent collects are unprojected into egomotion-stable 3D scene feature maps of the scene, and projected from novel viewpoints to match the observed RGB image views in an end-to-end differentiable manner. We then train modular neural models to generate such 3D feature representations given language utterances, to localize the objects an utterance mentions in the 3D feature representation inferred from an image, and to predict the desired 3D object locations given a manipulation instruction. We empirically show the proposed models outperform by a large margin existing 2D models in spatial reasoning, referential object detection and instruction following, and generalize better across camera viewpoints and object arrangements.