 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Verification of Deep Convolutional Neural Networks Using ImageStars
May 14, 2020




Convolutional Neural Networks (CNN) have redefined the state-of-the-art in many real-world applications, such as facial recognition, image classification, human pose estimation, and semantic segmentation. Despite their success, CNNs are vulnerable to adversarial attacks, where slight changes to their inputs may lead to sharp changes in their output in even well-trained networks. Set-based analysis methods can detect or prove the absence of bounded adversarial attacks, which can then be used to evaluate the effectiveness of neural network training methodology. Unfortunately, existing verification approaches have limited scalability in terms of the size of networks that can be analyzed. In this paper, we describe a set-based framework that successfully deals with real-world CNNs, such as VGG16 and VGG19, that have high accuracy on ImageNet. Our approach is based on a new set representation called the ImageStar, which enables efficient exact and over-approximative analysis of CNNs. ImageStars perform efficient set-based analysis by combining operations on concrete images with linear programming (LP). Our approach is implemented in a tool called NNV, and can verify the robustness of VGG networks with respect to a small set of input states, derived from adversarial attacks, such as the DeepFool attack. The experimental results show that our approach is less conservative and faster than existing zonotope methods, such as those used in DeepZ, and the polytope method used in DeepPoly.
Accurate Tumor Tissue Region Detection with Accelerated Deep Convolutional Neural Networks
Apr 18, 2020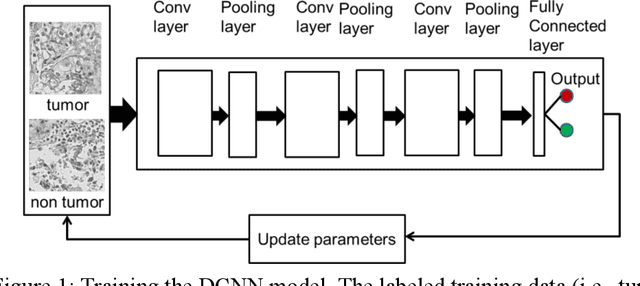
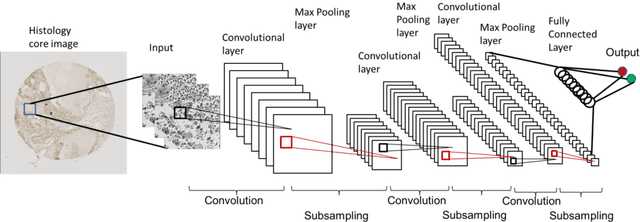

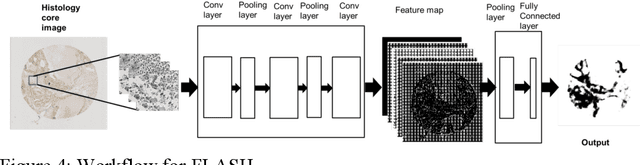
Manual annotation of pathology slides for cancer diagnosis is laborious and repetitive. Therefore, much effort has been devoted to develop computer vision solutions. Our approach, (FLASH), is based on a Deep Convolutional Neural Network (DCNN) architecture. It reduces computational costs and is faster than typical deep learning approaches by two orders of magnitude, making high throughput processing a possibility. In computer vision approaches using deep learning methods, the input image is subdivided into patches which are separately passed through the neural network. Features extracted from these patches are used by the classifier to annotate the corresponding region. Our approach aggregates all the extracted features into a single matrix before passing them to the classifier. Previously, the features are extracted from overlapping patches. Aggregating the features eliminates the need for processing overlapping patches, which reduces the computations required. DCCN and FLASH demonstrate high sensitivity (~ 0.96), good precision (~0.78) and high F1 scores (~0.84). The average time taken to process each sample for FLASH and DCNN is 96.6 seconds and 9489.20 seconds, respectively. Our approach was approximately 100 times faster than the original DCNN approach while simultaneously preserving high accuracy and precision.
Robust Federated Learning: The Case of Affine Distribution Shifts
Jun 16, 2020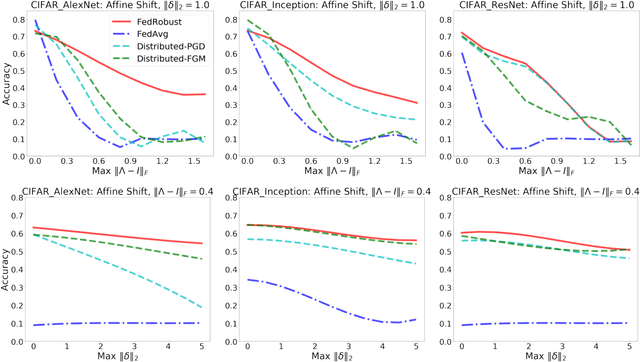

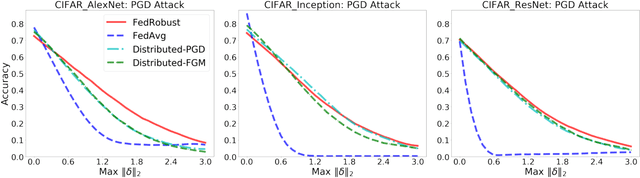
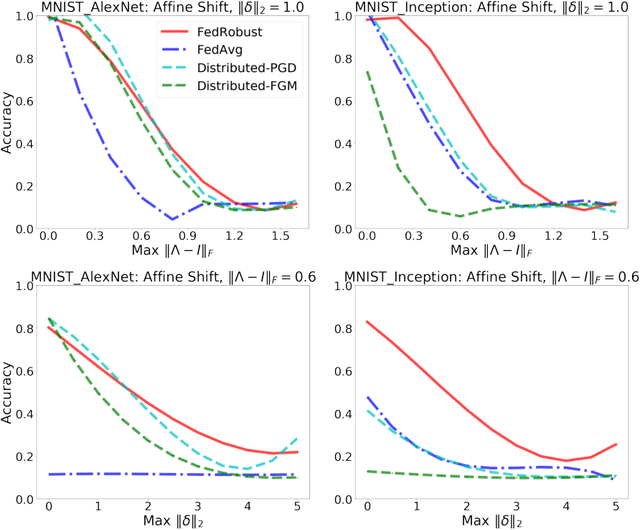
Federated learning is a distributed paradigm that aims at training models using samples distributed across multiple users in a network while keeping the samples on users' devices with the aim of efficiency and protecting users privacy. In such settings, the training data is often statistically heterogeneous and manifests various distribution shifts across users, which degrades the performance of the learnt model. The primary goal of this paper is to develop a robust federated learning algorithm that achieves satisfactory performance against distribution shifts in users' samples. To achieve this goal, we first consider a structured affine distribution shift in users' data that captures the device-dependent data heterogeneity in federated settings. This perturbation model is applicable to various federated learning problems such as image classification where the images undergo device-dependent imperfections, e.g. different intensity, contrast, and brightness. To address affine distribution shifts across users, we propose a Federated Learning framework Robust to Affine distribution shifts (FLRA) that is provably robust against affine Wasserstein shifts to the distribution of observed samples. To solve the FLRA's distributed minimax problem, we propose a fast and efficient optimization method and provide convergence guarantees via a gradient Descent Ascent (GDA) method. We further prove generalization error bounds for the learnt classifier to show proper generalization from empirical distribution of samples to the true underlying distribution. We perform several numerical experiments to empirically support FLRA. We show that an affine distribution shift indeed suffices to significantly decrease the performance of the learnt classifier in a new test user, and our proposed algorithm achieves a significant gain in comparison to standard federated learning and adversarial training methods.
Deep Unsupervised Common Representation Learning for LiDAR and Camera Data using Double Siamese Networks
Jan 03, 2020
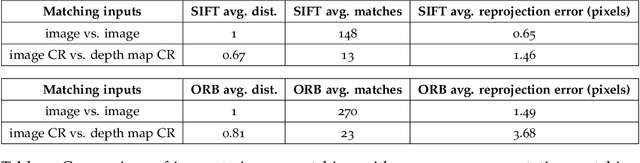

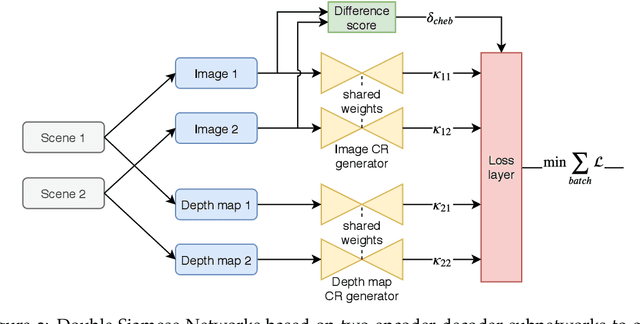
Domain gaps of sensor modalities pose a challenge for the design of autonomous robots. Taking a step towards closing this gap, we propose two unsupervised training frameworks for finding a common representation of LiDAR and camera data. The first method utilizes a double Siamese training structure to ensure consistency in the results. The second method uses a Canny edge image guiding the networks towards a desired representation. All networks are trained in an unsupervised manner, leaving room for scalability. The results are evaluated using common computer vision applications, and the limitations of the proposed approaches are outlined.
Multi-organ Segmentation over Partially Labeled Datasets with Multi-scale Feature Abstraction
Jan 01, 2020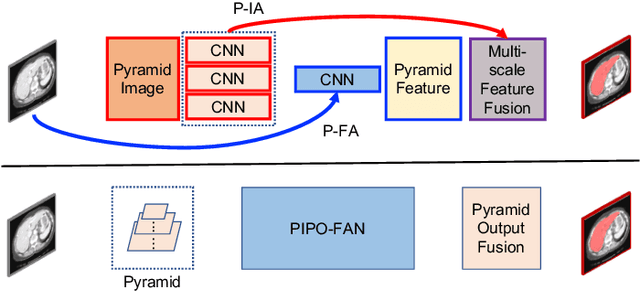
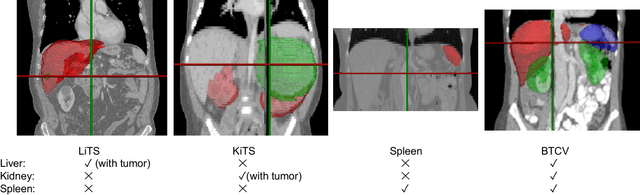
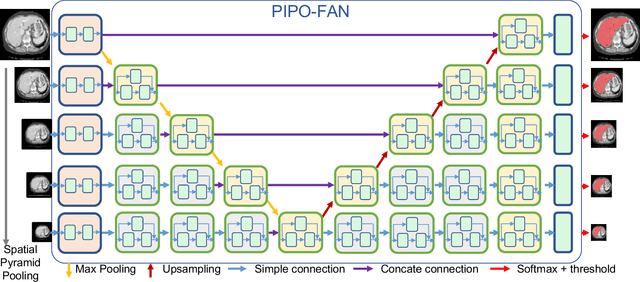
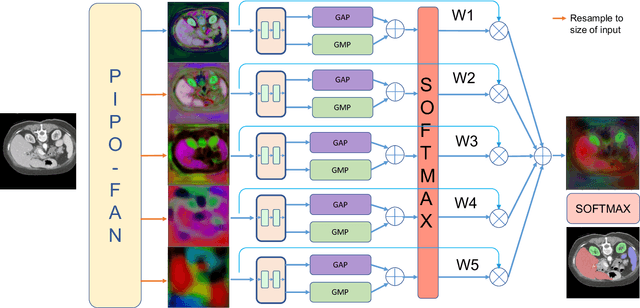
This paper presents a unified training strategy that enables a novel multi-scale deep neural network to be trained on multiple partially labeled datasets for multi-organ segmentation. Multi-scale contextual information is effective for pixel-level label prediction, i.e. image segmentation. However, such important information is only partially exploited by the existing methods. In this paper, we propose a new network architecture for multi-scale feature abstraction, which integrates pyramid feature analysis into an image segmentation model. To bridge the semantic gap caused by directly merging features from different scales, an equal convolutional depth mechanism is proposed. In addition, we develop a deep supervision mechanism for refining outputs in different scales. To fully leverage the segmentation features from different scales, we design an adaptive weighting layer to fuse the outputs in an automatic fashion. All these features together integrate into a pyramid-input pyramid-output network for efficient feature extraction. Last but not least, to alleviate the hunger for fully annotated data in training deep segmentation models, a unified training strategy is proposed to train one segmentation model on multiple partially labeled datasets for multi-organ segmentation with a novel target adaptive loss. Our proposed method was evaluated on four publicly available datasets, including BTCV, LiTS, KiTS and Spleen, where very promising performance has been achieved. The source code of this work is publicly shared at https://github.com/DIAL-RPI/PIPO-FAN for others to easily reproduce the work and build their own models with the introduced mechanisms.
Regularizing Neural Networks by Stochastically Training Layer Ensembles
Nov 21, 2019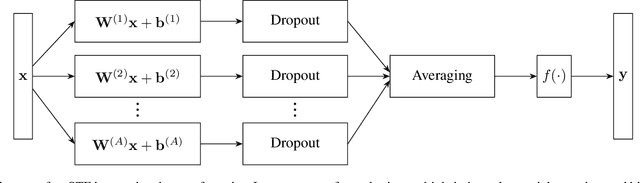



Dropout and similar stochastic neural network regularization methods are often interpreted as implicitly averaging over a large ensemble of models. We propose STE (stochastically trained ensemble) layers, which enhance the averaging properties of such methods by training an ensemble of weight matrices with stochastic regularization while explicitly averaging outputs. This provides stronger regularization with no additional computational cost at test time. We show consistent improvement on various image classification tasks using standard network topologies.
Unsupervised Projection Networks for Generative Adversarial Networks
Sep 30, 2019



We propose the use of unsupervised learning to train projection networks that project onto the latent space of an already trained generator. We apply our method to a trained StyleGAN, and use our projection network to perform image super-resolution and clustering of images into semantically identifiable groups.
Convolutional nets for reconstructing neural circuits from brain images acquired by serial section electron microscopy
Apr 29, 2019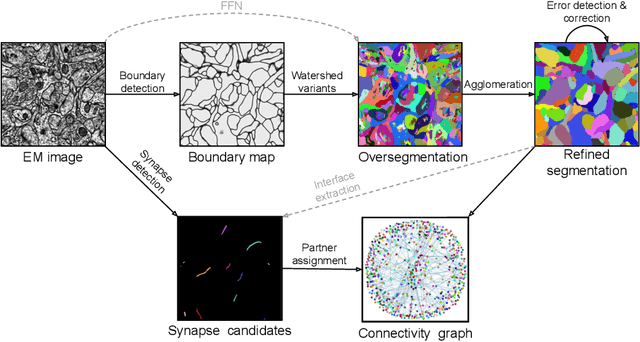
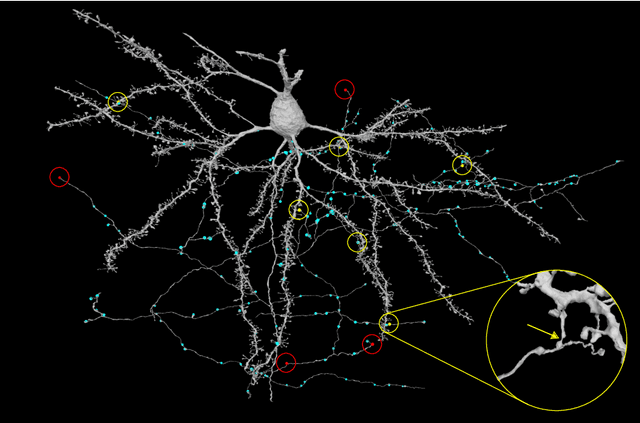

Neural circuits can be reconstructed from brain images acquired by serial section electron microscopy. Image analysis has been performed by manual labor for half a century, and efforts at automation date back almost as far. Convolutional nets were first applied to neuronal boundary detection a dozen years ago, and have now achieved impressive accuracy on clean images. Robust handling of image defects is a major outstanding challenge. Convolutional nets are also being employed for other tasks in neural circuit reconstruction: finding synapses and identifying synaptic partners, extending or pruning neuronal reconstructions, and aligning serial section images to create a 3D image stack. Computational systems are being engineered to handle petavoxel images of cubic millimeter brain volumes.
Deep Variational Networks with Exponential Weighting for Learning Computed Tomography
Jun 13, 2019

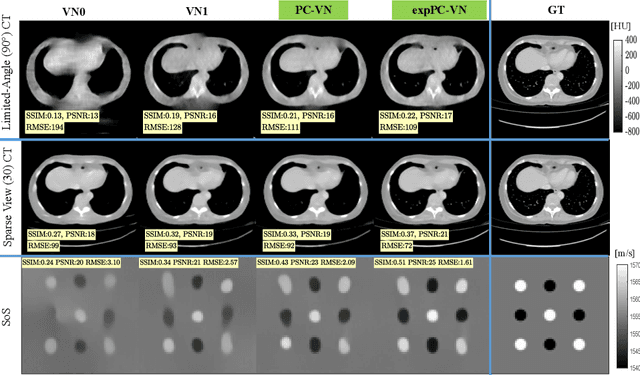
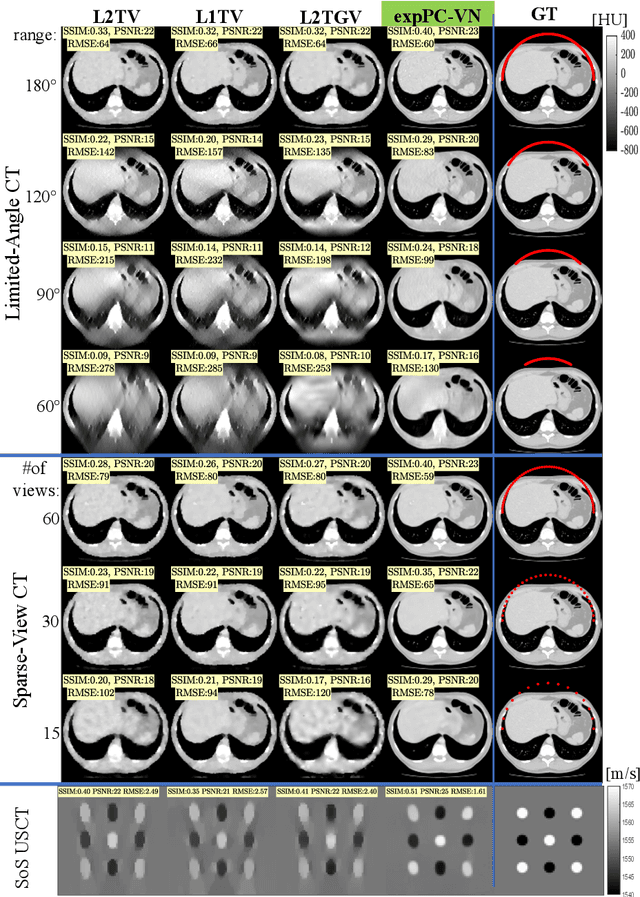
Tomographic image reconstruction is relevant for many medical imaging modalities including X-ray, ultrasound (US) computed tomography (CT) and photoacoustics, for which the access to full angular range tomographic projections might be not available in clinical practice due to physical or time constraints. Reconstruction from incomplete data in low signal-to-noise ratio regime is a challenging and ill-posed inverse problem that usually leads to unsatisfactory image quality. While informative image priors may be learned using generic deep neural network architectures, the artefacts caused by an ill-conditioned design matrix often have global spatial support and cannot be efficiently filtered out by means of convolutions. In this paper we propose to learn an inverse mapping in an end-to-end fashion via unrolling optimization iterations of a prototypical reconstruction algorithm. We herein introduce a network architecture that performs filtering jointly in both sinogram and spatial domains. To efficiently train such deep network we propose a novel regularization approach based on deep exponential weighting. Experiments on US and X-ray CT data show that our proposed method is qualitatively and quantitatively superior to conventional non-linear reconstruction methods as well as state-of-the-art deep networks for image reconstruction. Fast inference time of the proposed algorithm allows for sophisticated reconstructions in real-time critical settings, demonstrated with US SoS imaging of an ex vivo bovine phantom.
Visual search over billions of aerial and satellite images
Feb 07, 2020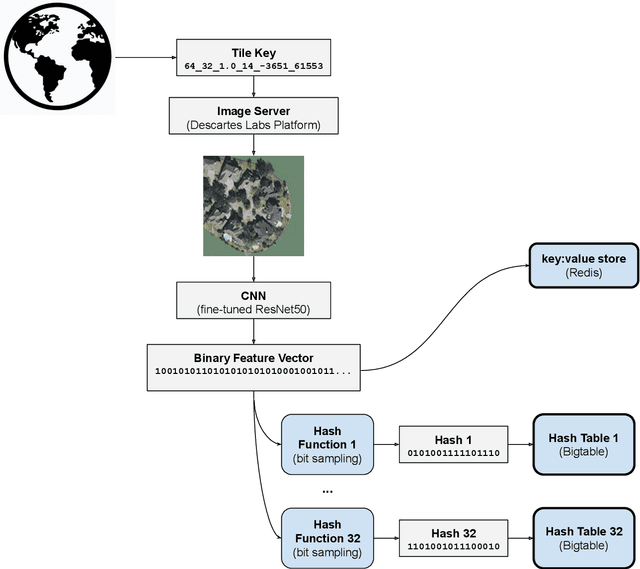
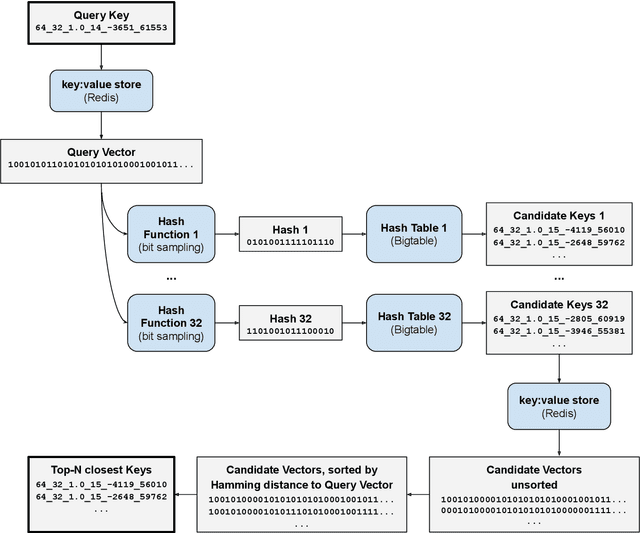


We present a system for performing visual search over billions of aerial and satellite images. The purpose of visual search is to find images that are visually similar to a query image. We define visual similarity using 512 abstract visual features generated by a convolutional neural network that has been trained on aerial and satellite imagery. The features are converted to binary values to reduce data and compute requirements. We employ a hash-based search using Bigtable, a scalable database service from Google Cloud. Searching the continental United States at 1-meter pixel resolution, corresponding to approximately 2 billion images, takes approximately 0.1 seconds. This system enables real-time visual search over the surface of the earth, and an interactive demo is available at https://search.descarteslabs.com.