 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-modal Sensor Fusion-Based Deep Neural Network for End-to-end Autonomous Driving with Scene Understanding
May 19, 2020
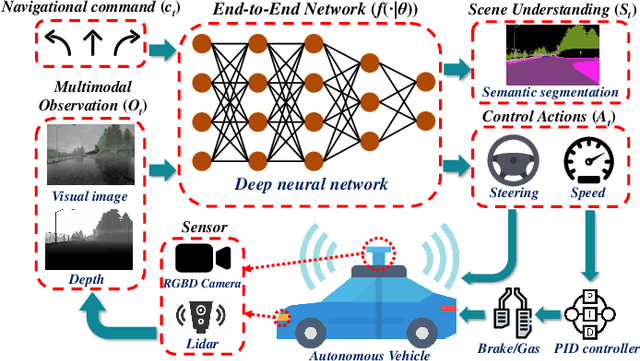
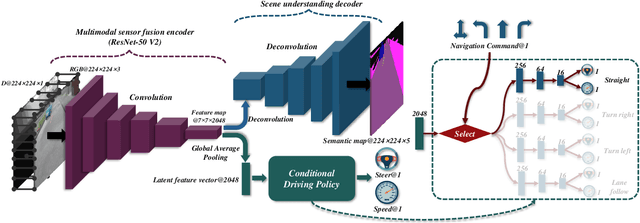
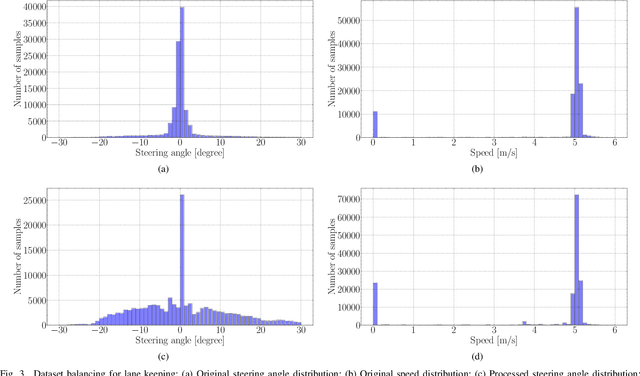

This study aims to improve the control performance and generalization capability of end-to-end autonomous driving with scene understanding leveraging deep learning and multimodal sensor fusion technology. The designed end-to-end deep neural network takes the visual image and associated depth information as inputs in an early fusion level and outputs the pixel-wise semantic segmentation as scene understanding and vehicle control commands concurrently. The end-to-end deep learning-based autonomous driving model is tested in high-fidelity simulated urban driving conditions and compared with the benchmark of CoRL2017 and NoCrash. The testing results show that the proposed approach is of better performance and generalization ability, achieving a 100\% success rate in static navigation tasks in both training and unobserved situations, as well as better success rates in other tasks than other existing models. A further ablation study shows that the model with the removal of multimodal sensor fusion or scene understanding pales in the new environment because of the false perception. The results verify that the performance of our model is improved by the synergy of multimodal sensor fusion with scene understanding subtask, demonstrating the feasibility and effectiveness of the developed deep neural network with multimodal sensor fusion.
Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model
Apr 20, 2020


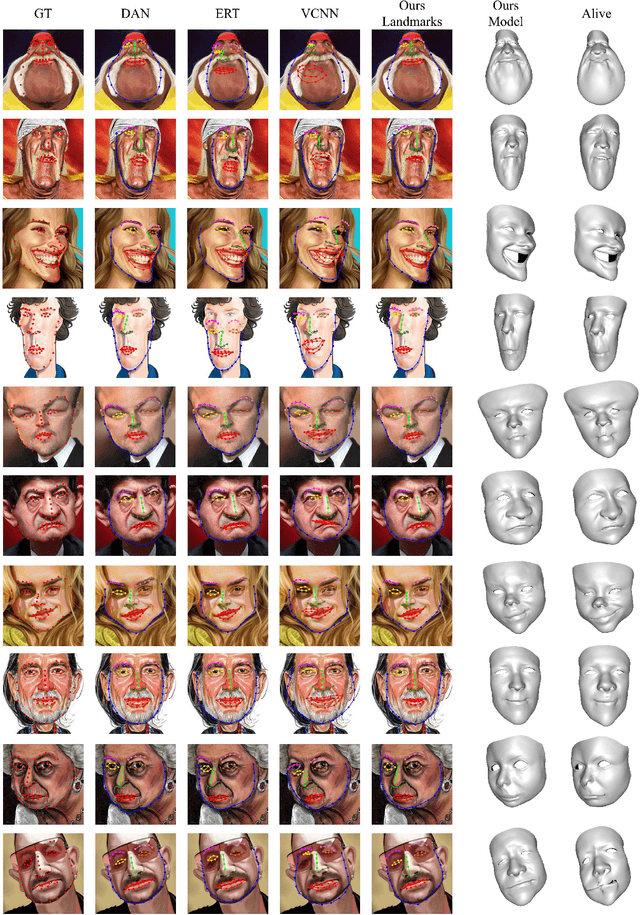
Caricature is an artistic abstraction of the human face by distorting or exaggerating certain facial features, while still retains a likeness with the given face. Due to the large diversity of geometric and texture variations, automatic landmark detection and 3D face reconstruction for caricature is a challenging problem and has rarely been studied before. In this paper, we propose the first automatic method for this task by a novel 3D approach. To this end, we first build a dataset with various styles of 2D caricatures and their corresponding 3D shapes, and then build a parametric model on vertex based deformation space for 3D caricature face. Based on the constructed dataset and the nonlinear parametric model, we propose a neural network based method to regress the 3D face shape and orientation from the input 2D caricature image. Ablation studies and comparison with baseline methods demonstrate the effectiveness of our algorithm design, and extensive experimental results demonstrate that our method works well for various caricatures. Our constructed dataset, source code and trained model are available at https://github.com/Juyong/CaricatureFace.
Introduction to Camera Pose Estimation with Deep Learning
Jul 08, 2019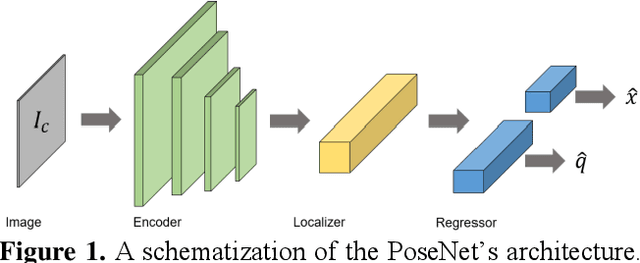
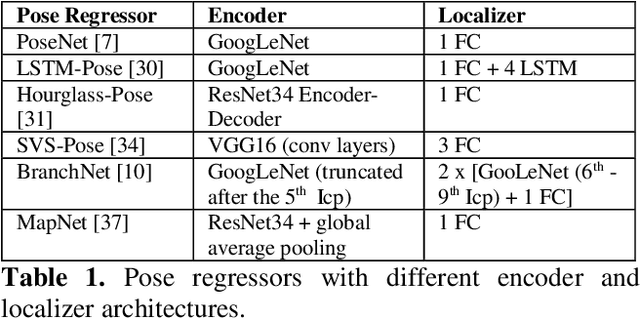
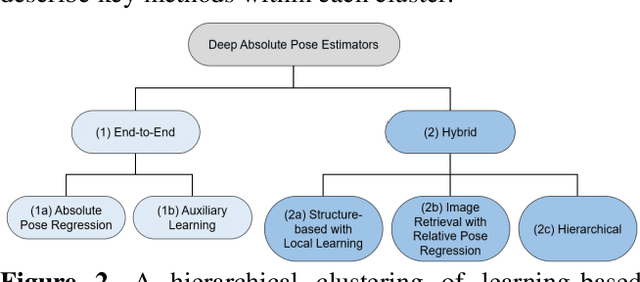
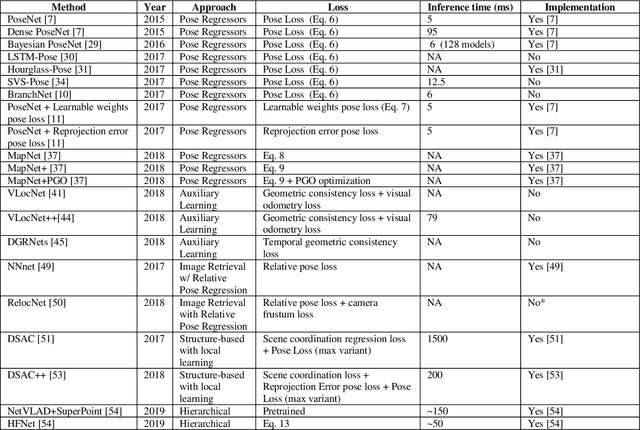
Over the last two decades, deep learning has transformed the field of computer vision. Deep convolutional networks were successfully applied to learn different vision tasks such as image classification, image segmentation, object detection and many more. By transferring the knowledge learned by deep models on large generic datasets, researchers were further able to create fine-tuned models for other more specific tasks. Recently this idea was applied for regressing the absolute camera pose from an RGB image. Although the resulting accuracy was sub-optimal, compared to classic feature-based solutions, this effort led to a surge of learning-based pose estimation methods. Here, we review deep learning approaches for camera pose estimation. We describe key methods in the field and identify trends aiming at improving the original deep pose regression solution. We further provide an extensive cross-comparison of existing learning-based pose estimators, together with practical notes on their execution for reproducibility purposes. Finally, we discuss emerging solutions and potential future research directions.
Pareto-optimal data compression for binary classification tasks
Aug 23, 2019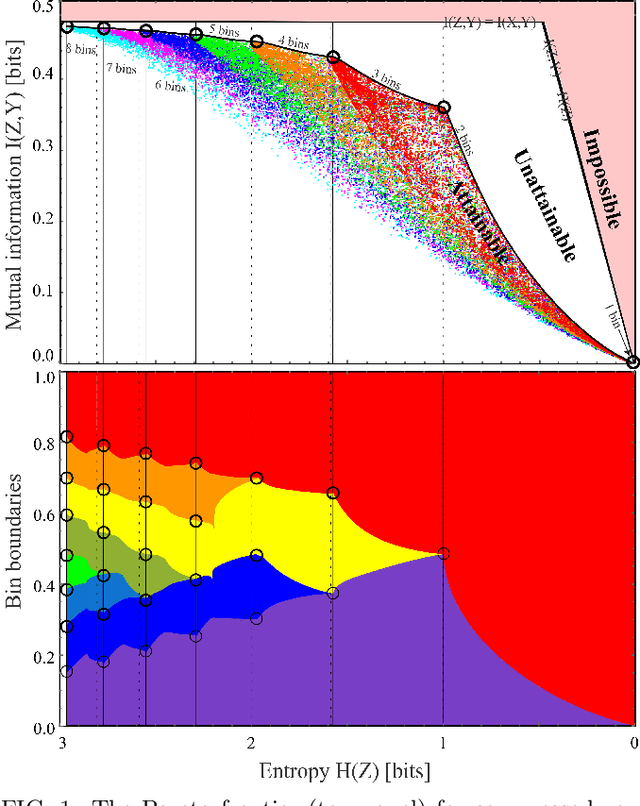

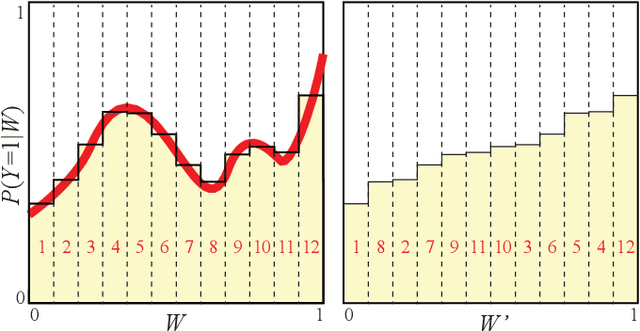
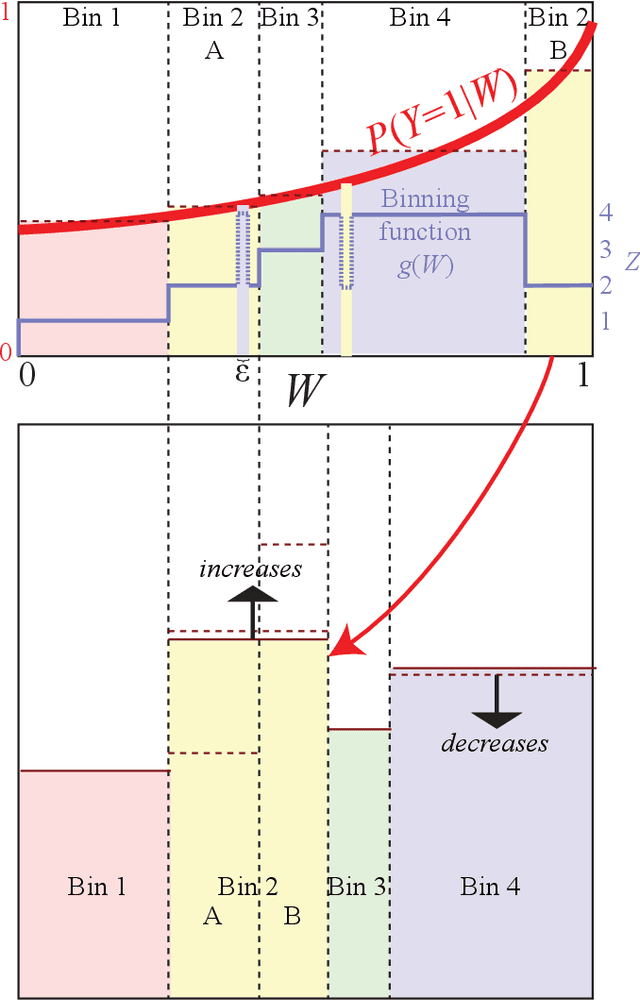
The goal of lossy data compression is to reduce the storage cost of a data set $X$ while retaining as much information as possible about something ($Y$) that you care about. For example, what aspects of an image $X$ contain the most information about whether it depicts a cat? Mathematically, this corresponds to finding a mapping $X\to Z\equiv f(X)$ that maximizes the mutual information $I(Z,Y)$ while the entropy $H(Z)$ is kept below some fixed threshold. We present a method for mapping out the Pareto frontier for classification tasks, reflecting the tradeoff between retained entropy and class information. We first show how a random variable $X$ (an image, say) drawn from a class $Y\in\{1,...,n\}$ can be distilled into a vector $W=f(X)\in \mathbb{R}^{n-1}$ losslessly, so that $I(W,Y)=I(X,Y)$; for example, for a binary classification task of cats and dogs, each image $X$ is mapped into a single real number $W$ retaining all information that helps distinguish cats from dogs. For the $n=2$ case of binary classification, we then show how $W$ can be further compressed into a discrete variable $Z=g_\beta(W)\in\{1,...,m_\beta\}$ by binning $W$ into $m_\beta$ bins, in such a way that varying the parameter $\beta$ sweeps out the full Pareto frontier, solving a generalization of the Discrete Information Bottleneck (DIB) problem. We argue that the most interesting points on this frontier are "corners" maximizing $I(Z,Y)$ for a fixed number of bins $m=2,3...$ which can be conveniently be found without multiobjective optimization. We apply this method to the CIFAR-10, MNIST and Fashion-MNIST datasets, illustrating how it can be interpreted as an information-theoretically optimal image clustering algorithm.
The Human Visual System and Adversarial AI
Jan 07, 2020


This paper applies theories about the Human Visual System to make Adversarial AI more effective. To date, Adversarial AI has modeled perceptual distances between clean and adversarial examples of images using Lp norms. These norms have the benefit of simple mathematical description and reasonable effectiveness in approximating perceptual distance. However, in prior decades, other areas of image processing have moved beyond simpler models like Mean Squared Error (MSE) towards more complex models that better approximate the Human Visual System (HVS). We demonstrate a proof of concept of incorporating HVS models into Adversarial AI.
Learning Physical Graph Representations from Visual Scenes
Jun 22, 2020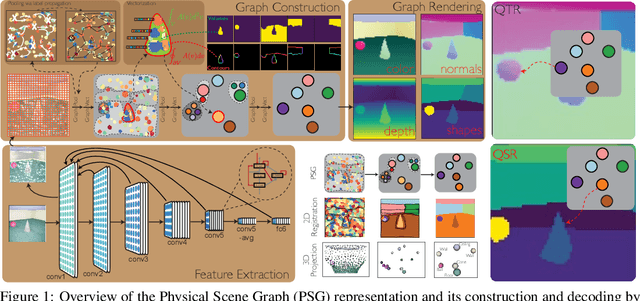
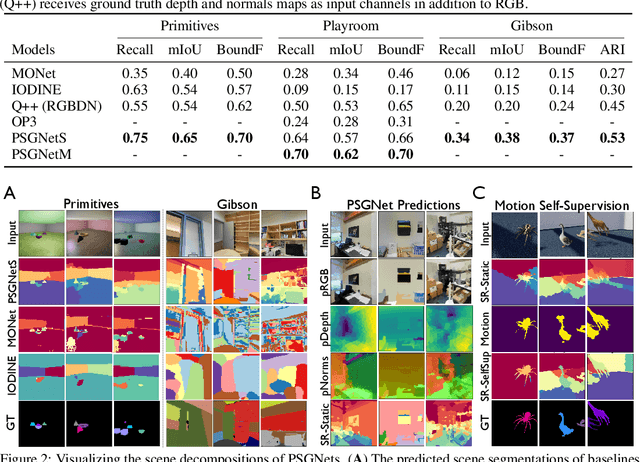
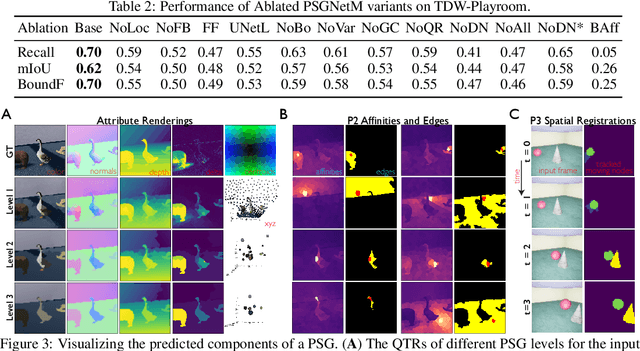

Convolutional Neural Networks (CNNs) have proved exceptional at learning representations for visual object categorization. However, CNNs do not explicitly encode objects, parts, and their physical properties, which has limited CNNs' success on tasks that require structured understanding of visual scenes. To overcome these limitations, we introduce the idea of Physical Scene Graphs (PSGs), which represent scenes as hierarchical graphs, with nodes in the hierarchy corresponding intuitively to object parts at different scales, and edges to physical connections between parts. Bound to each node is a vector of latent attributes that intuitively represent object properties such as surface shape and texture. We also describe PSGNet, a network architecture that learns to extract PSGs by reconstructing scenes through a PSG-structured bottleneck. PSGNet augments standard CNNs by including: recurrent feedback connections to combine low and high-level image information; graph pooling and vectorization operations that convert spatially-uniform feature maps into object-centric graph structures; and perceptual grouping principles to encourage the identification of meaningful scene elements. We show that PSGNet outperforms alternative self-supervised scene representation algorithms at scene segmentation tasks, especially on complex real-world images, and generalizes well to unseen object types and scene arrangements. PSGNet is also able learn from physical motion, enhancing scene estimates even for static images. We present a series of ablation studies illustrating the importance of each component of the PSGNet architecture, analyses showing that learned latent attributes capture intuitive scene properties, and illustrate the use of PSGs for compositional scene inference.
Super-resolution Reconstruction of SAR Image based on Non-Local Means Denoising Combined with BP Neural Network
Dec 14, 2016In this article, we propose a super-resolution method to resolve the problem of image low spatial because of the limitation of imaging devices. We make use of the strong non-linearity mapped ability of the back-propagation neural networks(BPNN). Training sample images are got by undersampled method. The elements chose as the inputs of the BPNN are pixels referred to Non-local means(NL-Means). Making use of the self-similarity of the images, those inputs are the pixels which are pixels gained from modified NL-means which is specific for super-resolution. Besides, small change on core function of NL-means has been applied in the method we use in this article so that we can have a clearer edge in the shrunk image. Experimental results gained from the Peak Signal to Noise Ratio(PSNR) and the Equivalent Number of Look(ENL), indicate that adding the similar pixels as inputs will increase the results than not taking them into consideration.
Field of View Extension in Computed Tomography Using Deep Learning Prior
Nov 04, 2019
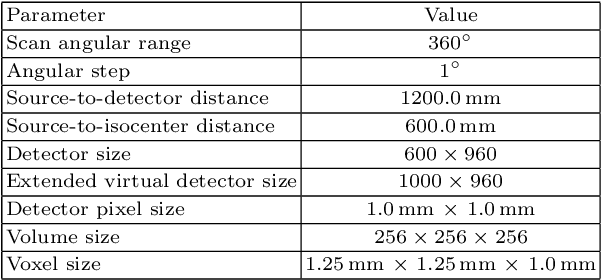
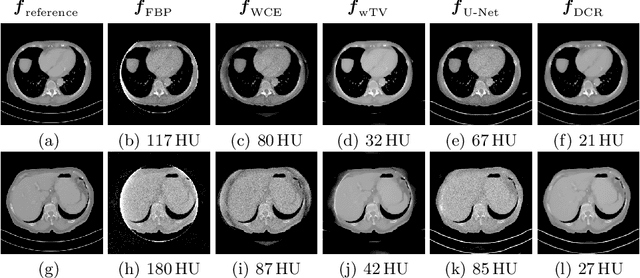
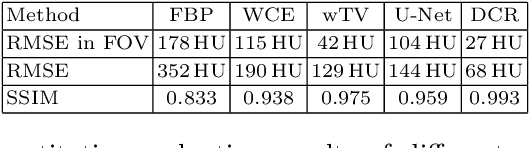
In computed tomography (CT), data truncation is a common problem. Images reconstructed by the standard filtered back-projection algorithm from truncated data suffer from cupping artifacts inside the field-of-view (FOV), while anatomical structures are severely distorted or missing outside the FOV. Deep learning, particularly the U-Net, has been applied to extend the FOV as a post-processing method. Since image-to-image prediction neglects the data fidelity to measured projection data, incorrect structures, even inside the FOV, might be reconstructed by such an approach. Therefore, generating reconstructed images directly from a post-processing neural network is inadequate. In this work, we propose a data consistent reconstruction method, which utilizes deep learning reconstruction as prior for extrapolating truncated projections and a conventional iterative reconstruction to constrain the reconstruction consistent to measured raw data. Its efficacy is demonstrated in our study, achieving small average root-mean-square error of 27 HU inside the FOV and a high structure similarity index of 0.993 for the whole body area on a test patient's CT data.
Singular points detection with semantic segmentation networks
Nov 04, 2019
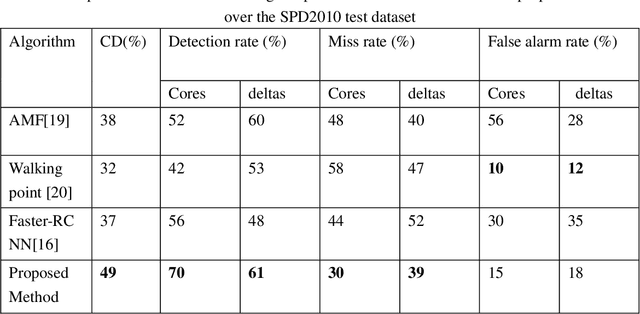

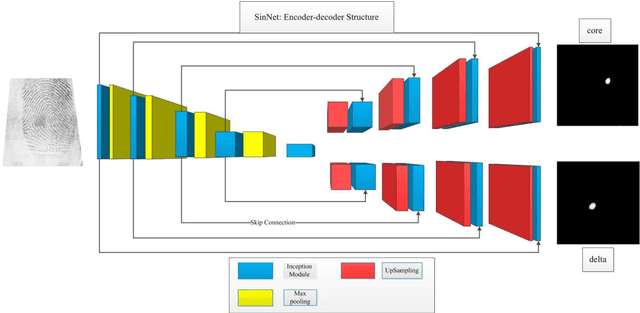
Singular points detection is one of the most classical and important problem in the field of fingerprint recognition. However, current detection rates of singular points are still unsatisfactory, especially for low-quality fingerprints. Compared with traditional image processing-based detection methods, methods based on deep learning only need the original fingerprint image but not the fingerprint orientation field. In this paper, different from other detection methods based on deep learning, we treat singular points detection as a semantic segmentation problem and just use few data for training. Furthermore, we propose a new convolutional neural network called SinNet to extract the singular regions of interest and then use a blob detection method called SimpleBlobDetector to locate the singular points. The experiments are carried out on the test dataset from SPD2010, and the proposed method has much better performance than the other advanced methods in most aspects. Compared with the state-of-art algorithms in SPD2010, our method achieves an increase of 11% in the percentage of correctly detected fingerprints and an increase of more than 18% in the core detection rate.
Nonlinear Filter Based Image Denoising Using AMF Approach
Mar 09, 2010
This paper proposes a new technique based on nonlinear Adaptive Median filter (AMF) for image restoration. Image denoising is a common procedure in digital image processing aiming at the removal of noise, which may corrupt an image during its acquisition or transmission, while retaining its quality. This procedure is traditionally performed in the spatial or frequency domain by filtering. The aim of image enhancement is to reconstruct the true image from the corrupted image. The process of image acquisition frequently leads to degradation and the quality of the digitized image becomes inferior to the original image. Filtering is a technique for enhancing the image. Linear filter is the filtering in which the value of an output pixel is a linear combination of neighborhood values, which can produce blur in the image. Thus a variety of smoothing techniques have been developed that are non linear. Median filter is the one of the most popular non-linear filter. When considering a small neighborhood it is highly efficient but for large window and in case of high noise it gives rise to more blurring to image. The Centre Weighted Median (CWM) filter has got a better average performance over the median filter [8]. However the original pixel corrupted and noise reduction is substantial under high noise condition. Hence this technique has also blurring affect on the image. To illustrate the superiority of the proposed approach by overcoming the existing problem, the proposed new scheme (AMF) Adaptive Median Filter has been simulated along with the standard ones and various performance measures have been compared.