 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-q Analysis of Image Patterns
Dec 29, 2011
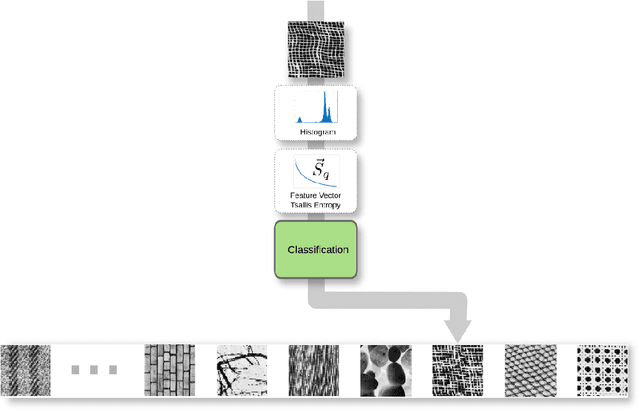
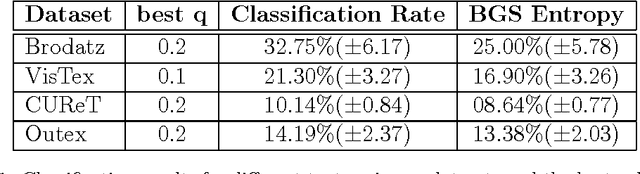
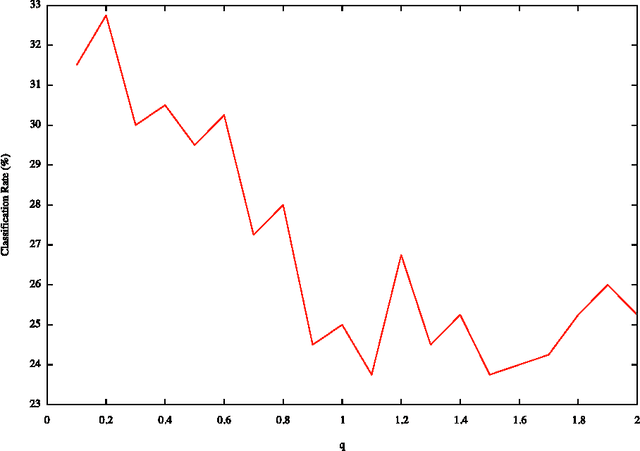
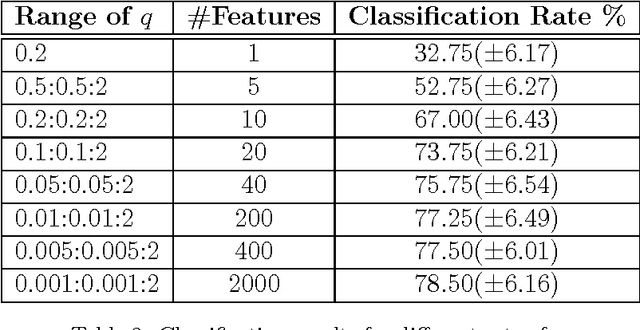
This paper studies the use of the Tsallis Entropy versus the classic Boltzmann-Gibbs-Shannon entropy for classifying image patterns. Given a database of 40 pattern classes, the goal is to determine the class of a given image sample. Our experiments show that the Tsallis entropy encoded in a feature vector for different $q$ indices has great advantage over the Boltzmann-Gibbs-Shannon entropy for pattern classification, boosting recognition rates by a factor of 3. We discuss the reasons behind this success, shedding light on the usefulness of the Tsallis entropy.
Deep Bayesian Active Learning for Multiple Correct Outputs
Dec 08, 2019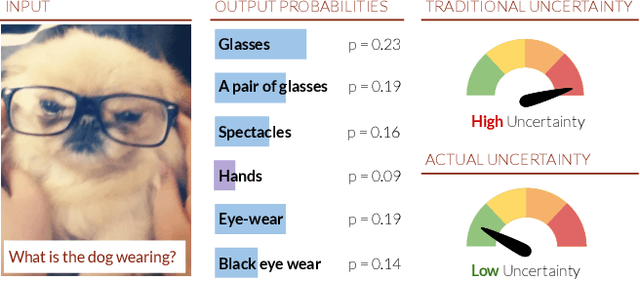
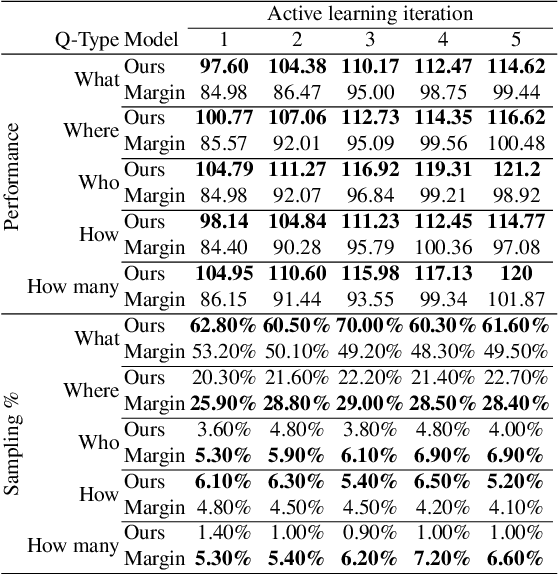
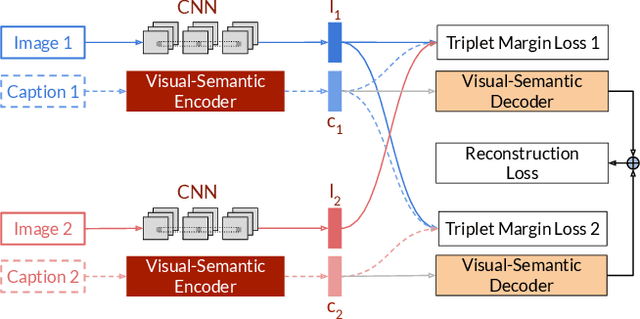
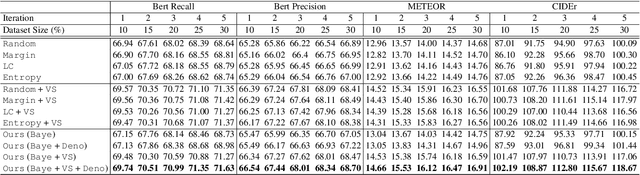
Typical active learning strategies are designed for tasks, such as classification, with the assumption that the output space is mutually exclusive. The assumption that these tasks always have exactly one correct answer has resulted in the creation of numerous uncertainty-based measurements, such as entropy and least confidence, which operate over a model's outputs. Unfortunately, many real-world vision tasks, like visual question answering and image captioning, have multiple correct answers, causing these measurements to overestimate uncertainty and sometimes perform worse than a random sampling baseline. In this paper, we propose a new paradigm that estimates uncertainty in the model's internal hidden space instead of the model's output space. We specifically study a manifestation of this problem for visual question answer generation (VQA), where the aim is not to classify the correct answer but to produce a natural language answer, given an image and a question. Our method overcomes the paraphrastic nature of language. It requires a semantic space that structures the model's output concepts and that enables the usage of techniques like dropout-based Bayesian uncertainty. We build a visual-semantic space that embeds paraphrases close together for any existing VQA model. We empirically show state-of-art active learning results on the task of VQA on two datasets, being 5 times more cost-efficient on Visual Genome and 3 times more cost-efficient on VQA 2.0.
Report on UG^2+ Challenge Track 1: Assessing Algorithms to Improve Video Object Detection and Classification from Unconstrained Mobility Platforms
Jul 26, 2019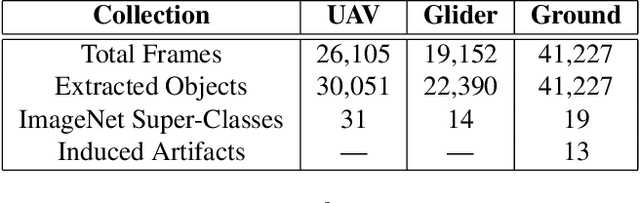
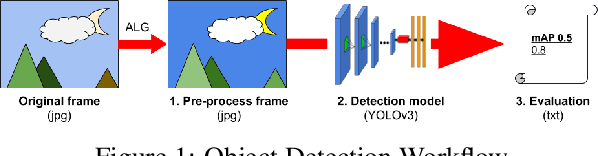
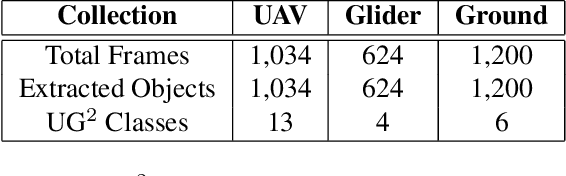
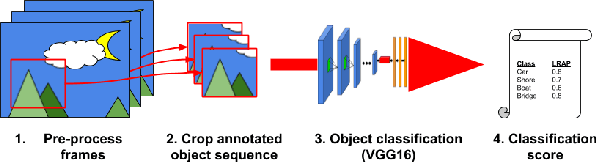
How can we effectively engineer a computer vision system that is able to interpret videos from unconstrained mobility platforms like UAVs? One promising option is to make use of image restoration and enhancement algorithms from the area of computational photography to improve the quality of the underlying frames in a way that also improves automatic visual recognition. Along these lines, exploratory work is needed to find out which image pre-processing algorithms, in combination with the strongest features and supervised machine learning approaches, are good candidates for difficult scenarios like motion blur, weather, and mis-focus --- all common artifacts in UAV acquired images. This paper summarizes the protocols and results of Track 1 of the UG^2+ Challenge held in conjunction with IEEE/CVF CVPR 2019. The challenge looked at two separate problems: (1) object detection improvement in video, and (2) object classification improvement in video. The challenge made use of the UG^2 (UAV, Glider, Ground) dataset, which is an established benchmark for assessing the interplay between image restoration and enhancement and visual recognition. 16 algorithms were submitted by academic and corporate teams, and a detailed analysis of how they performed on each challenge problem is reported here.
Multiple Human Association between Top and Horizontal Views by Matching Subjects' Spatial Distributions
Jul 26, 2019

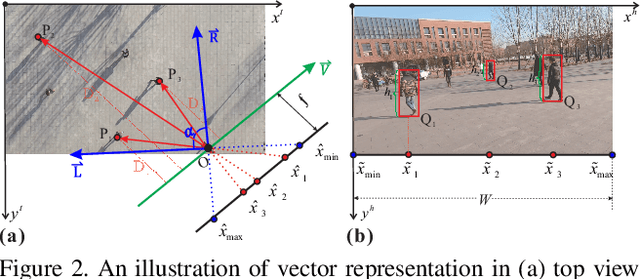
Video surveillance can be significantly enhanced by using both top-view data, e.g., those from drone-mounted cameras in the air, and horizontal-view data, e.g., those from wearable cameras on the ground. Collaborative analysis of different-view data can facilitate various kinds of applications, such as human tracking, person identification, and human activity recognition. However, for such collaborative analysis, the first step is to associate people, referred to as subjects in this paper, across these two views. This is a very challenging problem due to large human-appearance difference between top and horizontal views. In this paper, we present a new approach to address this problem by exploring and matching the subjects' spatial distributions between the two views. More specifically, on the top-view image, we model and match subjects' relative positions to the horizontal-view camera in both views and define a matching cost to decide the actual location of horizontal-view camera and its view angle in the top-view image. We collect a new dataset consisting of top-view and horizontal-view image pairs for performance evaluation and the experimental results show the effectiveness of the proposed method.
Partial Volume Segmentation of Brain MRI Scans of any Resolution and Contrast
Apr 21, 2020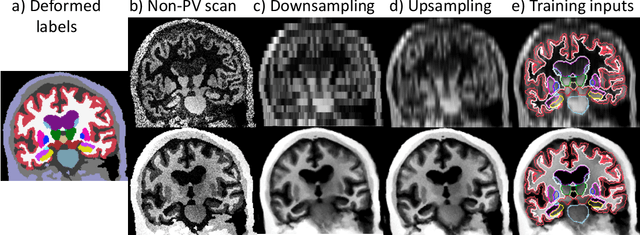

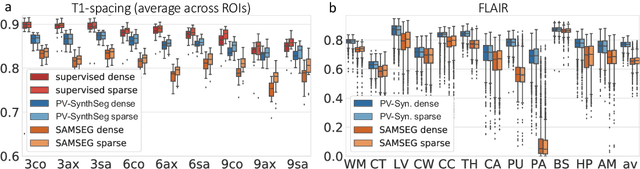
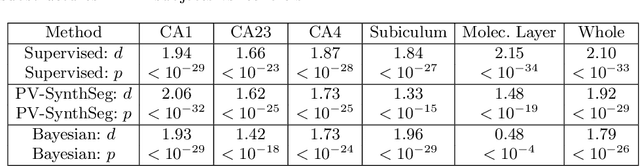
Partial voluming (PV) is arguably the last crucial unsolved problem in Bayesian segmentation of brain MRI with probabilistic atlases. PV occurs when voxels contain multiple tissue classes, giving rise to image intensities that may not be representative of any one of the underlying classes. PV is particularly problematic for segmentation when there is a large resolution gap between the atlas and the test scan, e.g., when segmenting clinical scans with thick slices, or when using a high-resolution atlas. In this work, we present PV-SynthSeg, a convolutional neural network (CNN) that tackles this problem by directly learning a mapping between (possibly multi-modal) low resolution (LR) scans and underlying high resolution (HR) segmentations. PV-SynthSeg simulates LR images from HR label maps with a generative model of PV, and can be trained to segment scans of any desired target contrast and resolution, even for previously unseen modalities where neither images nor segmentations are available at training. PV-SynthSeg does not require any preprocessing, and runs in seconds. We demonstrate the accuracy and flexibility of the method with extensive experiments on three datasets and 2,680 scans. The code is available at https://github.com/BBillot/SynthSeg.
Index Network
Aug 11, 2019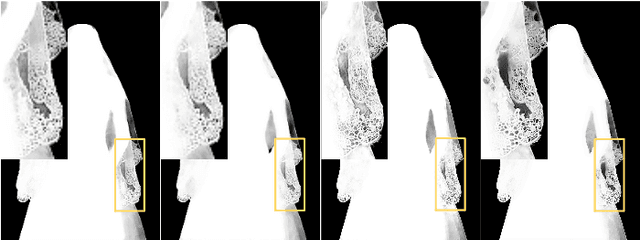
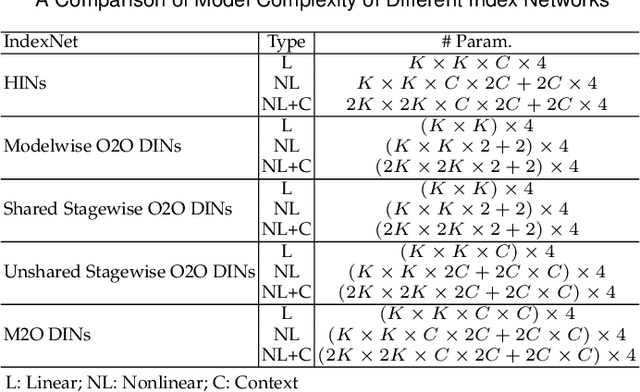
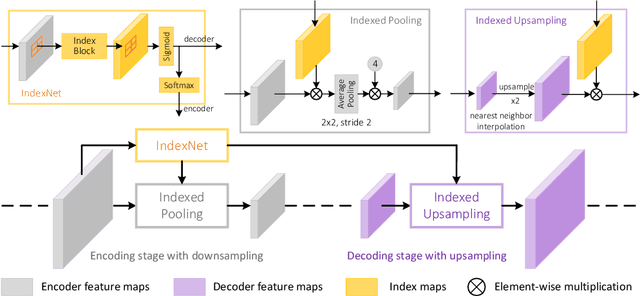
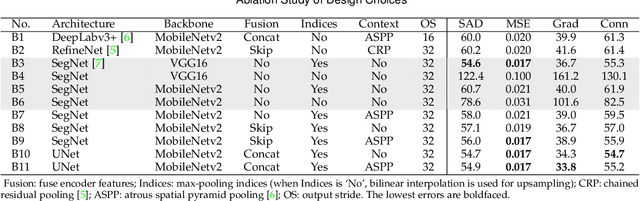
We show that existing upsampling operators can be unified using the notion of the index function. This notion is inspired by an observation in the decoding process of deep image matting where indices-guided unpooling can often recover boundary details considerably better than other upsampling operators such as bilinear interpolation. By viewing the indices as a function of the feature map, we introduce the concept of "learning to index", and present a novel index-guided encoder-decoder framework where indices are self-learned adaptively from data and are used to guide the downsampling and upsampling stages, without extra training supervision. At the core of this framework is a new learnable module, termed Index Network (IndexNet), which dynamically generates indices conditioned on the feature map itself. IndexNet can be used as a plug-in applying to almost all off-the-shelf convolutional networks that have coupled downsampling and upsampling stages, giving the networks the ability to dynamically capture variations of local patterns. In particular, we instantiate and investigate five families of IndexNet and demonstrate their effectiveness on four dense prediction tasks, including image denoising, image matting, semantic segmentation, and monocular depth estimation. Code and models have been made available at: https://tinyurl.com/IndexNetV1
Non-Determinism in TensorFlow ResNets
Jan 30, 2020
We show that the stochasticity in training ResNets for image classification on GPUs in TensorFlow is dominated by the non-determinism from GPUs, rather than by the initialisation of the weights and biases of the network or by the sequence of minibatches given. The standard deviation of test set accuracy is 0.02 with fixed seeds, compared to 0.027 with different seeds---nearly 74\% of the standard deviation of a ResNet model is non-deterministic. For test set loss the ratio of standard deviations is more than 80\%. These results call for more robust evaluation strategies of deep learning models, as a significant amount of the variation in results across runs can arise simply from GPU randomness.
A comparison of dense region detectors for image search and fine-grained classification
Apr 17, 2015



We consider a pipeline for image classification or search based on coding approaches like Bag of Words or Fisher vectors. In this context, the most common approach is to extract the image patches regularly in a dense manner on several scales. This paper proposes and evaluates alternative choices to extract patches densely. Beyond simple strategies derived from regular interest region detectors, we propose approaches based on super-pixels, edges, and a bank of Zernike filters used as detectors. The different approaches are evaluated on recent image retrieval and fine-grain classification benchmarks. Our results show that the regular dense detector is outperformed by other methods in most situations, leading us to improve the state of the art in comparable setups on standard retrieval and fined-grain benchmarks. As a byproduct of our study, we show that existing methods for blob and super-pixel extraction achieve high accuracy if the patches are extracted along the edges and not around the detected regions.
Generalizable Cone Beam CT Esophagus Segmentation Using In Silico Data Augmentation
Jun 28, 2020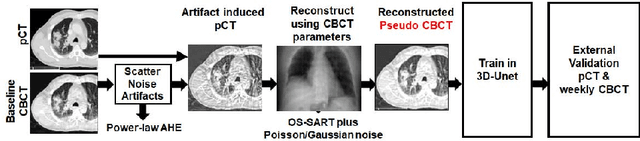
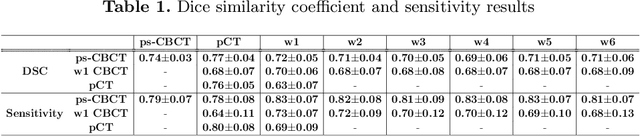
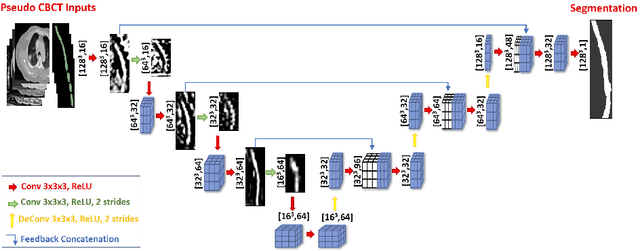

Lung cancer radiotherapy entails high quality planning computed tomography (pCT) imaging of the patient with radiation oncologist contouring of the tumor and the organs at risk (OARs) at the start of the treatment. This is followed by weekly low-quality cone beam CT (CBCT) imaging for treatment setup and qualitative visual assessment of tumor and critical OARs. In this work, we aim to make the weekly CBCT assessment quantitative by automatically segmenting the most critical OAR, esophagus, using deep learning and in silico (image-driven simulation) artifact induction to convert pCTs to pseudo-CBCTs (pCTs$+$artifacts). Specifically, for the in silico data augmentation, we make use of the critical insight that CT and CBCT have the same underlying physics and that it is easier to deteriorate the pCT to look more like CBCT (and use the accompanying high quality manual contours for segmentation) than to synthesize CT from CBCT where the critical anatomical information may have already been lost (which leads to anatomical hallucination with the prevalent generative adversarial networks for example). Given these pseudo-CBCTs and the high quality manual contours, we introduce a modified 3D-Unet architecture and a multi-objective loss function specifically designed for segmenting soft-tissue organs such as esophagus on real weekly CBCTs. The model achieved 0.74 dice overlap (against manual contours of an experienced radiation oncologist) on weekly CBCTs and was robust and generalizable enough to also produce state-of-the-art results on pCTs, achieving 0.77 dice overlap against the previous best of 0.72. This shows that our in silico data augmentation spans the realistic noise/artifact spectrum across patient CBCT/pCT data and can generalize well across modalities (without requiring retraining or domain adaptation), eventually improving the accuracy of treatment setup and response analysis.
SR2CNN: Zero-Shot Learning for Signal Recognition
Apr 21, 2020



Signal recognition is one of significant and challenging tasks in the signal processing and communications field. It is often a common situation that there's no training data accessible for some signal classes to perform a recognition task. Hence, as widely-used in image processing field, zero-shot learning (ZSL) is also very important for signal recognition. Unfortunately, ZSL regarding this field has hardly been studied due to inexplicable signal semantics. This paper proposes a ZSL framework, signal recognition and reconstruction convolutional neural networks (SR2CNN), to address relevant problems in this situation. The key idea behind SR2CNN is to learn the representation of signal semantic feature space by introducing a proper combination of cross entropy loss, center loss and autoencoder loss, as well as adopting a suitable distance metric space such that semantic features have greater minimal inter-class distance than maximal intra-class distance. The proposed SR2CNN can discriminate signals even if no training data is available for some signal class. Moreover, SR2CNN can gradually improve itself in the aid of signal detection, because of constantly refined class center vectors in semantic feature space. These merits are all verified by extensive experiments.