 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Corrupting Convolution-based Unlearnable Datasets with Pixel-based Image Transformations
Nov 30, 2023
Unlearnable datasets lead to a drastic drop in the generalization performance of models trained on them by introducing elaborate and imperceptible perturbations into clean training sets. Many existing defenses, e.g., JPEG compression and adversarial training, effectively counter UDs based on norm-constrained additive noise. However, a fire-new type of convolution-based UDs have been proposed and render existing defenses all ineffective, presenting a greater challenge to defenders. To address this, we express the convolution-based unlearnable sample as the result of multiplying a matrix by a clean sample in a simplified scenario, and formalize the intra-class matrix inconsistency as $\Theta_{imi}$, inter-class matrix consistency as $\Theta_{imc}$ to investigate the working mechanism of the convolution-based UDs. We conjecture that increasing both of these metrics will mitigate the unlearnability effect. Through validation experiments that commendably support our hypothesis, we further design a random matrix to boost both $\Theta_{imi}$ and $\Theta_{imc}$, achieving a notable degree of defense effect. Hence, by building upon and extending these facts, we first propose a brand-new image COrruption that employs randomly multiplicative transformation via INterpolation operation to successfully defend against convolution-based UDs. Our approach leverages global pixel random interpolations, effectively suppressing the impact of multiplicative noise in convolution-based UDs. Additionally, we have also designed two new forms of convolution-based UDs, and find that our defense is the most effective against them.
Enhanced Color Palette Modeling for Lossless Screen Content Compression
Dec 22, 2023Soft context formation is a lossless image coding method for screen content. It encodes images pixel by pixel via arithmetic coding by collecting statistics for probability distribution estimation. Its main pipeline includes three stages, namely a context model based stage, a color palette stage and a residual coding stage. Each subsequent stage is only employed if the previous stage can not be applied since necessary statistics, e.g. colors or contexts, have not been learned yet. We propose the following enhancements: First, information from previous stages is used to remove redundant color palette entries and prediction errors in subsequent stages. Additionally, implicitly known stage decision signals are no longer explicitly transmitted. These enhancements lead to an average bit rate decrease of 1.07% on the evaluated data. Compared to VVC and HEVC, the proposed method needs roughly 0.44 and 0.17 bits per pixel less on average for 24-bit screen content images, respectively.
Cross-Modal Object Tracking via Modality-Aware Fusion Network and A Large-Scale Dataset
Dec 22, 2023Visual tracking often faces challenges such as invalid targets and decreased performance in low-light conditions when relying solely on RGB image sequences. While incorporating additional modalities like depth and infrared data has proven effective, existing multi-modal imaging platforms are complex and lack real-world applicability. In contrast, near-infrared (NIR) imaging, commonly used in surveillance cameras, can switch between RGB and NIR based on light intensity. However, tracking objects across these heterogeneous modalities poses significant challenges, particularly due to the absence of modality switch signals during tracking. To address these challenges, we propose an adaptive cross-modal object tracking algorithm called Modality-Aware Fusion Network (MAFNet). MAFNet efficiently integrates information from both RGB and NIR modalities using an adaptive weighting mechanism, effectively bridging the appearance gap and enabling a modality-aware target representation. It consists of two key components: an adaptive weighting module and a modality-specific representation module......
PARDINUS: Weakly supervised discarding of photo-trapping empty images based on autoencoders
Dec 22, 2023Photo-trapping cameras are widely employed for wildlife monitoring. Those cameras take photographs when motion is detected to capture images where animals appear. A significant portion of these images are empty - no wildlife appears in the image. Filtering out those images is not a trivial task since it requires hours of manual work from biologists. Therefore, there is a notable interest in automating this task. Automatic discarding of empty photo-trapping images is still an open field in the area of Machine Learning. Existing solutions often rely on state-of-the-art supervised convolutional neural networks that require the annotation of the images in the training phase. PARDINUS (Weakly suPervised discARDINg of photo-trapping empty images based on aUtoencoderS) is constructed on the foundation of weakly supervised learning and proves that this approach equals or even surpasses other fully supervised methods that require further labeling work.
Receler: Reliable Concept Erasing of Text-to-Image Diffusion Models via Lightweight Erasers
Nov 29, 2023Concept erasure in text-to-image diffusion models aims to disable pre-trained diffusion models from generating images related to a target concept. To perform reliable concept erasure, the properties of robustness and locality are desirable. The former refrains the model from producing images associated with the target concept for any paraphrased or learned prompts, while the latter preserves the model ability in generating images for non-target concepts. In this paper, we propose Reliable Concept Erasing via Lightweight Erasers (Receler), which learns a lightweight Eraser to perform concept erasing and enhances locality and robustness with the proposed concept-localized regularization and adversarial prompt learning, respectively. Comprehensive quantitative and qualitative experiments with various concept prompts verify the superiority of Receler over the previous erasing methods on the above two desirable properties.
Universal Noise Annotation: Unveiling the Impact of Noisy annotation on Object Detection
Dec 21, 2023For object detection task with noisy labels, it is important to consider not only categorization noise, as in image classification, but also localization noise, missing annotations, and bogus bounding boxes. However, previous studies have only addressed certain types of noise (e.g., localization or categorization). In this paper, we propose Universal-Noise Annotation (UNA), a more practical setting that encompasses all types of noise that can occur in object detection, and analyze how UNA affects the performance of the detector. We analyzed the development direction of previous works of detection algorithms and examined the factors that impact the robustness of detection model learning method. We open-source the code for injecting UNA into the dataset and all the training log and weight are also shared.
Adversarial Item Promotion on Visually-Aware Recommender Systems by Guided Diffusion
Dec 25, 2023Visually-aware recommender systems have found widespread application in domains where visual elements significantly contribute to the inference of users' potential preferences. While the incorporation of visual information holds the promise of enhancing recommendation accuracy and alleviating the cold-start problem, it is essential to point out that the inclusion of item images may introduce substantial security challenges. Some existing works have shown that the item provider can manipulate item exposure rates to its advantage by constructing adversarial images. However, these works cannot reveal the real vulnerability of visually-aware recommender systems because (1) The generated adversarial images are markedly distorted, rendering them easily detectable by human observers; (2) The effectiveness of the attacks is inconsistent and even ineffective in some scenarios. To shed light on the real vulnerabilities of visually-aware recommender systems when confronted with adversarial images, this paper introduces a novel attack method, IPDGI (Item Promotion by Diffusion Generated Image). Specifically, IPDGI employs a guided diffusion model to generate adversarial samples designed to deceive visually-aware recommender systems. Taking advantage of accurately modeling benign images' distribution by diffusion models, the generated adversarial images have high fidelity with original images, ensuring the stealth of our IPDGI. To demonstrate the effectiveness of our proposed methods, we conduct extensive experiments on two commonly used e-commerce recommendation datasets (Amazon Beauty and Amazon Baby) with several typical visually-aware recommender systems. The experimental results show that our attack method has a significant improvement in both the performance of promoting the long-tailed (i.e., unpopular) items and the quality of generated adversarial images.
EyePreserve: Identity-Preserving Iris Synthesis
Dec 19, 2023Synthesis of same-identity biometric iris images, both for existing and non-existing identities while preserving the identity across a wide range of pupil sizes, is complex due to intricate iris muscle constriction mechanism, requiring a precise model of iris non-linear texture deformations to be embedded into the synthesis pipeline. This paper presents the first method of fully data-driven, identity-preserving, pupil size-varying s ynthesis of iris images. This approach is capable of synthesizing images of irises with different pupil sizes representing non-existing identities as well as non-linearly deforming the texture of iris images of existing subjects given the segmentation mask of the target iris image. Iris recognition experiments suggest that the proposed deformation model not only preserves the identity when changing the pupil size but offers better similarity between same-identity iris samples with significant differences in pupil size, compared to state-of-the-art linear and non-linear (bio-mechanical-based) iris deformation models. Two immediate applications of the proposed approach are: (a) synthesis of, or enhancement of the existing biometric datasets for iris recognition, mimicking those acquired with iris sensors, and (b) helping forensic human experts in examining iris image pairs with significant differences in pupil dilation. Source codes and weights of the models are made available with the paper.
PortraitBooth: A Versatile Portrait Model for Fast Identity-preserved Personalization
Dec 11, 2023

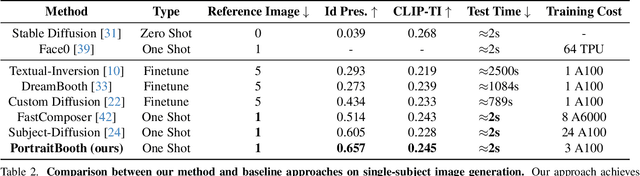
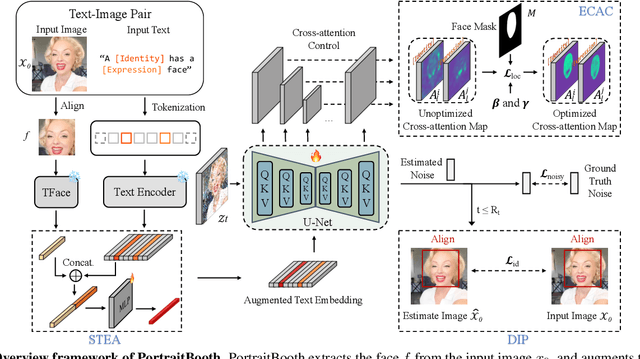
Recent advancements in personalized image generation using diffusion models have been noteworthy. However, existing methods suffer from inefficiencies due to the requirement for subject-specific fine-tuning. This computationally intensive process hinders efficient deployment, limiting practical usability. Moreover, these methods often grapple with identity distortion and limited expression diversity. In light of these challenges, we propose PortraitBooth, an innovative approach designed for high efficiency, robust identity preservation, and expression-editable text-to-image generation, without the need for fine-tuning. PortraitBooth leverages subject embeddings from a face recognition model for personalized image generation without fine-tuning. It eliminates computational overhead and mitigates identity distortion. The introduced dynamic identity preservation strategy further ensures close resemblance to the original image identity. Moreover, PortraitBooth incorporates emotion-aware cross-attention control for diverse facial expressions in generated images, supporting text-driven expression editing. Its scalability enables efficient and high-quality image creation, including multi-subject generation. Extensive results demonstrate superior performance over other state-of-the-art methods in both single and multiple image generation scenarios.
Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
Dec 13, 2023Contrastive Language-Image Pre-training (CLIP) plays an essential role in extracting valuable content information from images across diverse tasks. It aligns textual and visual modalities to comprehend the entire image, including all the details, even those irrelevant to specific tasks. However, for a finer understanding and controlled editing of images, it becomes crucial to focus on specific regions of interest, which can be indicated as points, masks, or boxes by humans or perception models. To fulfill the requirements, we introduce Alpha-CLIP, an enhanced version of CLIP with an auxiliary alpha channel to suggest attentive regions and fine-tuned with constructed millions of RGBA region-text pairs. Alpha-CLIP not only preserves the visual recognition ability of CLIP but also enables precise control over the emphasis of image contents. It demonstrates effectiveness in various tasks, including but not limited to open-world recognition, multimodal large language models, and conditional 2D / 3D generation. It has a strong potential to serve as a versatile tool for image-related tasks.