 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Separation of Dynamics from Pixels
Jul 20, 2019

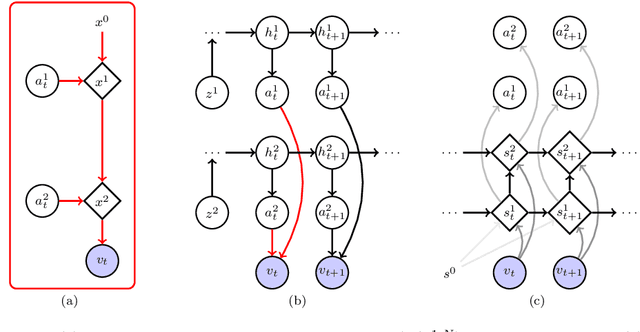
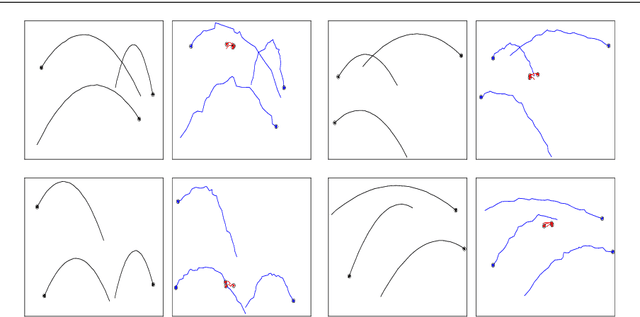
We present an approach to learn the dynamics of multiple objects from image sequences in an unsupervised way. We introduce a probabilistic model that first generate noisy positions for each object through a separate linear state-space model, and then renders the positions of all objects in the same image through a highly non-linear process. Such a linear representation of the dynamics enables us to propose an inference method that uses exact and efficient inference tools and that can be deployed to query the model in different ways without retraining.
DenoiSeg: Joint Denoising and Segmentation
May 06, 2020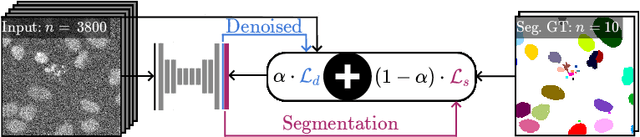

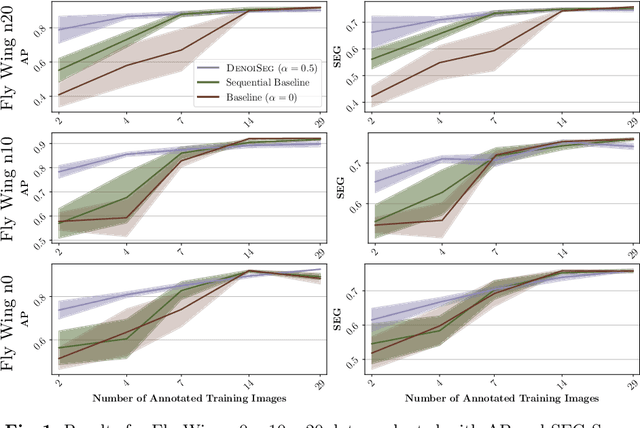
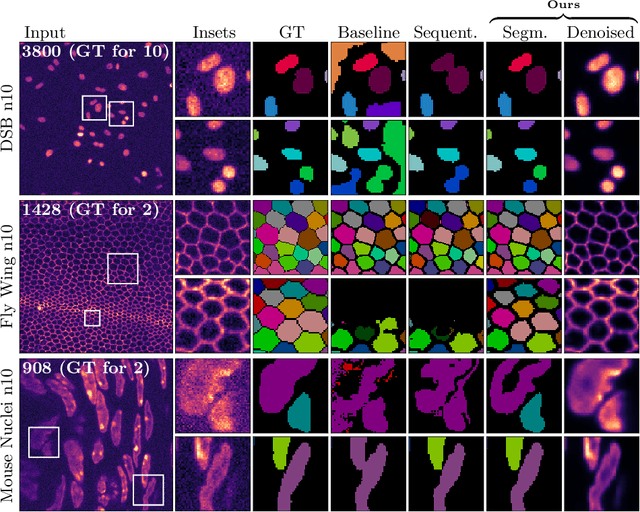
Microscopy image analysis often requires the segmentation of objects, but training data for this task is typically scarce and hard to obtain. Here we propose DenoiSeg, a new method that can be trained end-to-end on only a few annotated ground truth segmentations. We achieve this by extending Noise2Void, a self-supervised denoising scheme that can be trained on noisy images alone, to also predict dense 3-class segmentations. The reason for the success of our method is that segmentation can profit from denoising, especially when performed jointly within the same network. The network becomes a denoising expert by seeing all available raw data, while co-learning to segment, even if only a few segmentation labels are available. This hypothesis is additionally fueled by our observation that the best segmentation results on high quality (very low noise) raw data are obtained when moderate amounts of synthetic noise are added. This renders the denoising-task non-trivial and unleashes the desired co-learning effect. We believe that DenoiSeg offers a viable way to circumvent the tremendous hunger for high quality training data and effectively enables few-shot learning of dense segmentations.
Applications of the Streaming Networks
Mar 27, 2020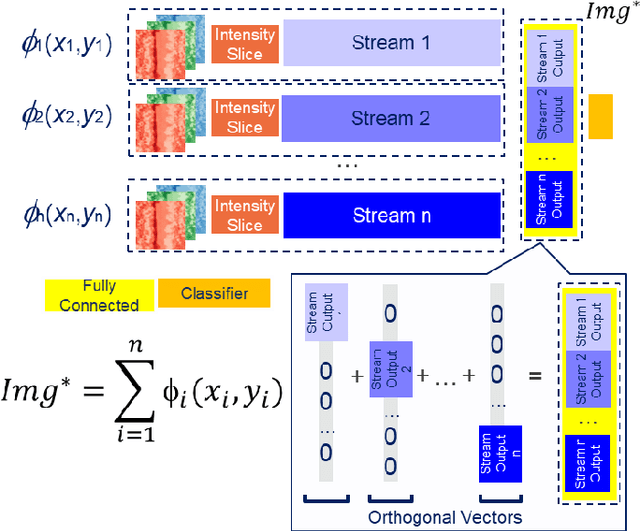
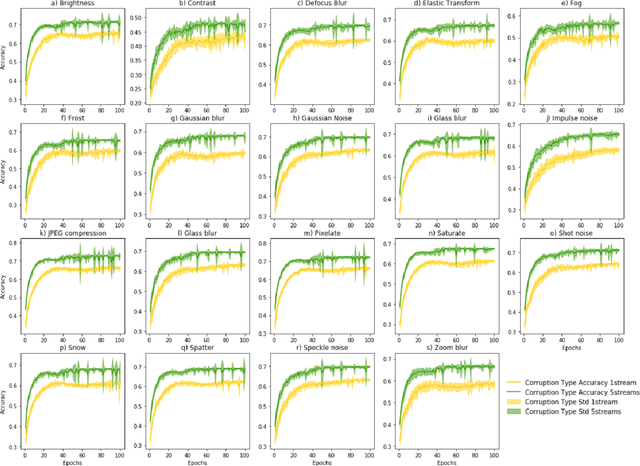
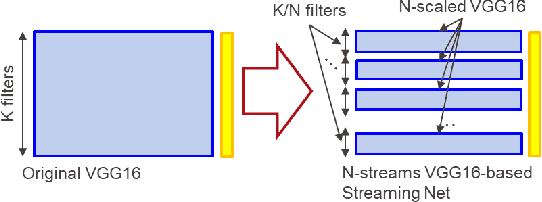
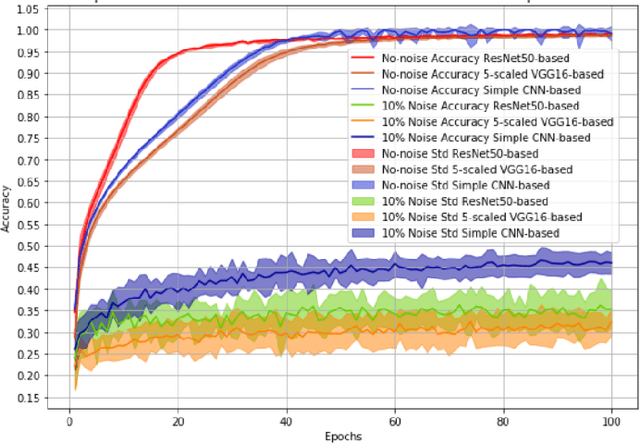
Most recently Streaming Networks (STnets) have been introduced as a mechanism of robust noise-corrupted images classification. STnets is a family of convolutional neural networks, which consists of multiple neural networks (streams), which have different inputs and their outputs are concatenated and fed into a single joint classifier. The original paper has illustrated how STnets can successfully classify images from Cifar10, EuroSat and UCmerced datasets, when images were corrupted with various levels of random zero noise. In this paper, we demonstrate that STnets are capable of high accuracy classification of images corrupted with Gaussian noise, fog, snow, etc. (Cifar10 corrupted dataset) and low light images (subset of Carvana dataset). We also introduce a new type of STnets called Hybrid STnets. Thus, we illustrate that STnets is a universal tool of image classification when original training dataset is corrupted with noise or other transformations, which lead to information loss from original images.
Getting to 99% Accuracy in Interactive Segmentation
Mar 17, 2020
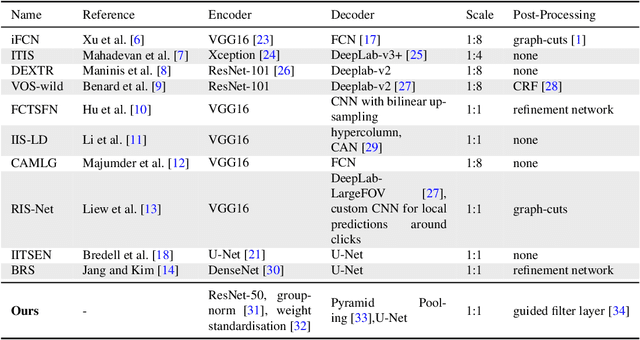

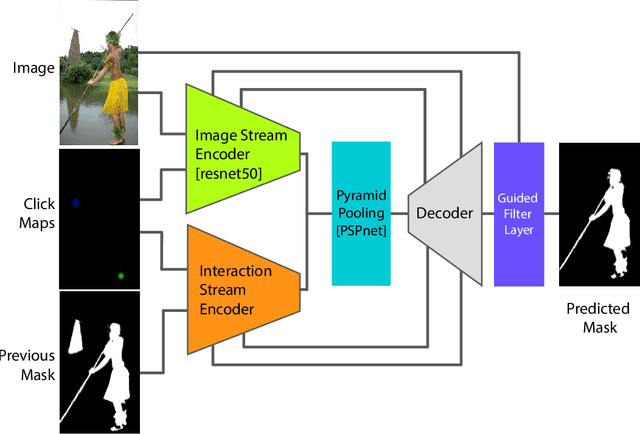
Interactive object cutout tools are the cornerstone of the image editing workflow. Recent deep-learning based interactive segmentation algorithms have made significant progress in handling complex images and rough binary selections can typically be obtained with just a few clicks. Yet, deep learning techniques tend to plateau once this rough selection has been reached. In this work, we interpret this plateau as the inability of current algorithms to sufficiently leverage each user interaction and also as the limitations of current training/testing datasets. We propose a novel interactive architecture and a novel training scheme that are both tailored to better exploit the user workflow. We also show that significant improvements can be further gained by introducing a synthetic training dataset that is specifically designed for complex object boundaries. Comprehensive experiments support our approach, and our network achieves state of the art performance.
A Novel Graphic Bending Transformation on Benchmark
Apr 21, 2020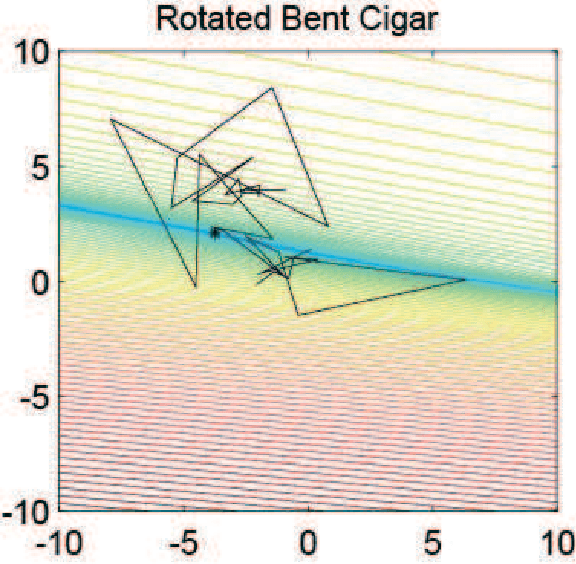

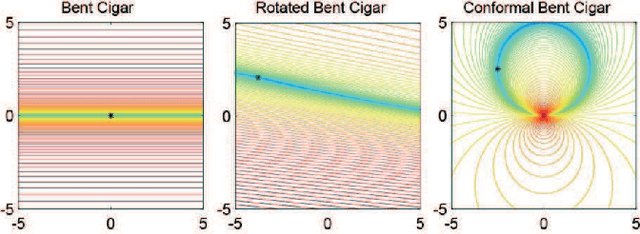
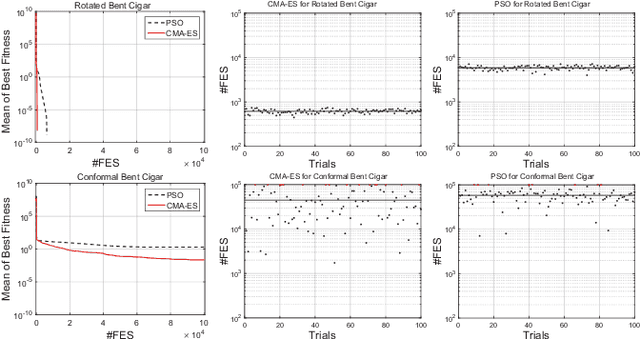
Classical benchmark problems utilize multiple transformation techniques to increase optimization difficulty, e.g., shift for anti centering effect and rotation for anti dimension sensitivity. Despite testing the transformation invariance, however, such operations do not really change the landscape's "shape", but rather than change the "view point". For instance, after rotated, ill conditional problems are turned around in terms of orientation but still keep proportional components, which, to some extent, does not create much obstacle in optimization. In this paper, inspired from image processing, we investigate a novel graphic conformal mapping transformation on benchmark problems to deform the function shape. The bending operation does not alter the function basic properties, e.g., a unimodal function can almost maintain its unimodality after bent, but can modify the shape of interested area in the search space. Experiments indicate the same optimizer spends more search budget and encounter more failures on the conformal bent functions than the rotated version. Several parameters of the proposed function are also analyzed to reveal performance sensitivity of the evolutionary algorithms.
Towards Generalization of 3D Human Pose Estimation In The Wild
Apr 21, 2020
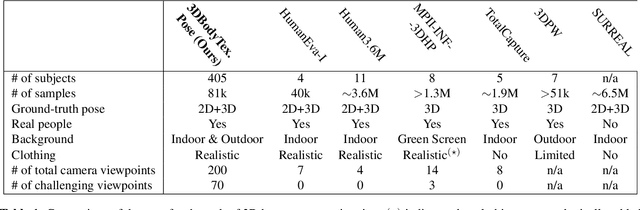
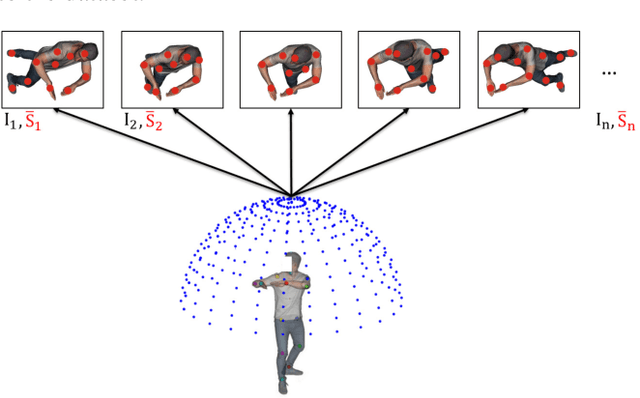

In this paper, we propose 3DBodyTex.Pose, a dataset that addresses the task of 3D human pose estimation in-the-wild. Generalization to in-the-wild images remains limited due to the lack of adequate datasets. Existent ones are usually collected in indoor controlled environments where motion capture systems are used to obtain the 3D ground-truth annotations of humans. 3DBodyTex.Pose offers high quality and rich data containing 405 different real subjects in various clothing and poses, and 81k image samples with ground-truth 2D and 3D pose annotations. These images are generated from 200 viewpoints among which 70 challenging extreme viewpoints. This data was created starting from high resolution textured 3D body scans and by incorporating various realistic backgrounds. Retraining a state-of-the-art 3D pose estimation approach using data augmented with 3DBodyTex.Pose showed promising improvement in the overall performance, and a sensible decrease in the per joint position error when testing on challenging viewpoints. The 3DBodyTex.Pose is expected to offer the research community with new possibilities for generalizing 3D pose estimation from monocular in-the-wild images.
Adaptive Periodic Averaging: A Practical Approach to Reducing Communication in Distributed Learning
Jul 13, 2020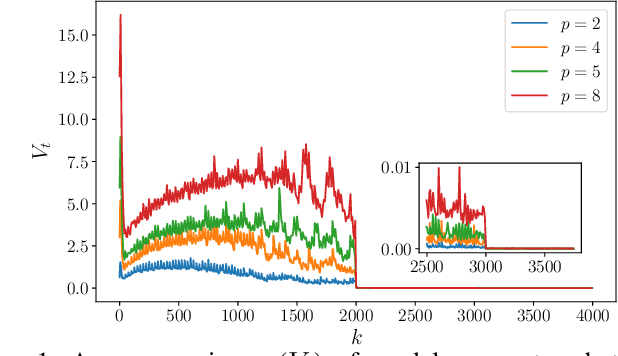
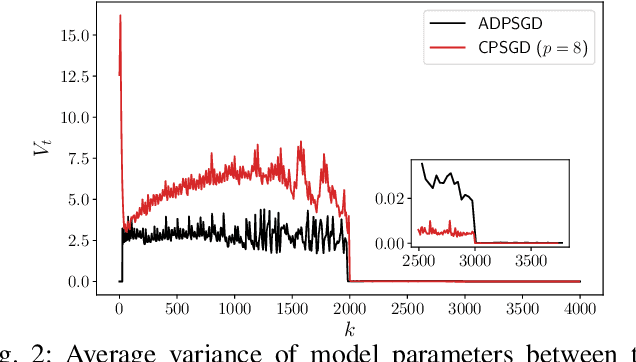
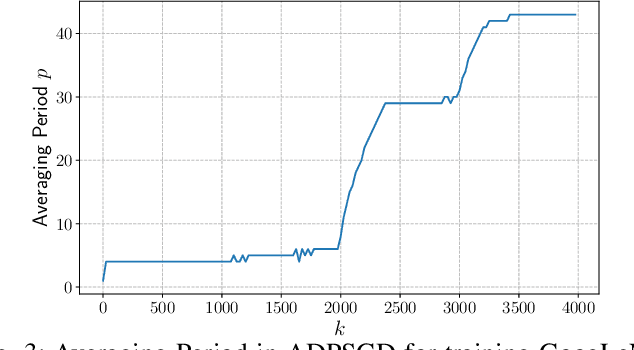
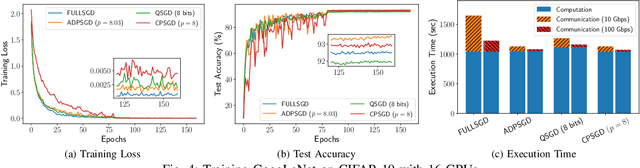
Stochastic Gradient Descent (SGD) is the key learning algorithm for many machine learning tasks. Because of its computational costs, there is a growing interest in accelerating SGD on HPC resources like GPU clusters. However, the performance of parallel SGD is still bottlenecked by the high communication costs even with a fast connection among the machines. A simple approach to alleviating this problem, used in many existing efforts, is to perform communication every few iterations, using a constant averaging period. In this paper, we show that the optimal averaging period in terms of convergence and communication cost is not a constant, but instead varies over the course of the execution. Specifically, we observe that reducing the variance of model parameters among the computing nodes is critical to the convergence of periodic parameter averaging SGD. Given a fixed communication budget, we show that it is more beneficial to synchronize more frequently in early iterations to reduce the initial large variance and synchronize less frequently in the later phase of the training process. We propose a practical algorithm, named ADaptive Periodic parameter averaging SGD (ADPSGD), to achieve a smaller overall variance of model parameters, and thus better convergence compared with the Constant Periodic parameter averaging SGD (CPSGD). We evaluate our method with several image classification benchmarks and show that our ADPSGD indeed achieves smaller training losses and higher test accuracies with smaller communication compared with CPSGD. Compared with gradient-quantization SGD, we show that our algorithm achieves faster convergence with only half of the communication. Compared with full-communication SGD, our ADPSGD achieves 1:14x to 1:27x speedups with a 100Gbps connection among computing nodes, and the speedups increase to 1:46x ~ 1:95x with a 10Gbps connection.
Optimized Generic Feature Learning for Few-shot Classification across Domains
Jan 22, 2020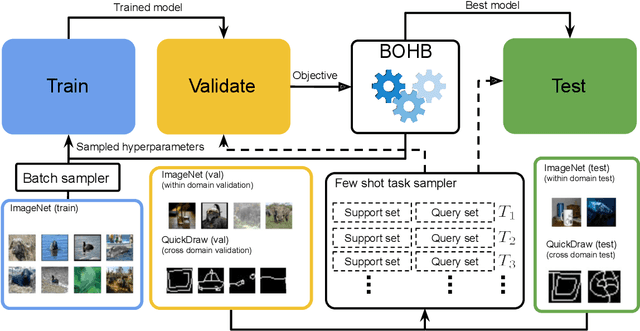

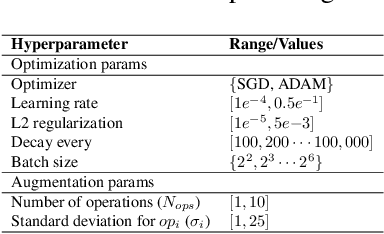
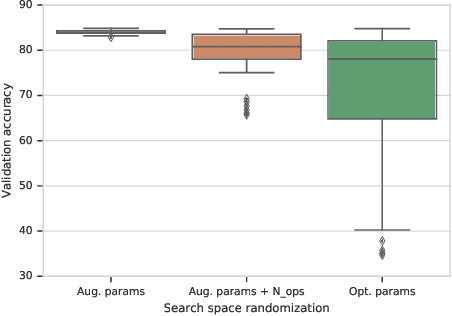
To learn models or features that generalize across tasks and domains is one of the grand goals of machine learning. In this paper, we propose to use cross-domain, cross-task data as validation objective for hyper-parameter optimization (HPO) to improve on this goal. Given a rich enough search space, optimization of hyper-parameters learn features that maximize validation performance and, due to the objective, generalize across tasks and domains. We demonstrate the effectiveness of this strategy on few-shot image classification within and across domains. The learned features outperform all previous few-shot and meta-learning approaches.
Super Resolution Convolutional Neural Network Models for Enhancing Resolution of Rock Micro-CT Images
Apr 16, 2019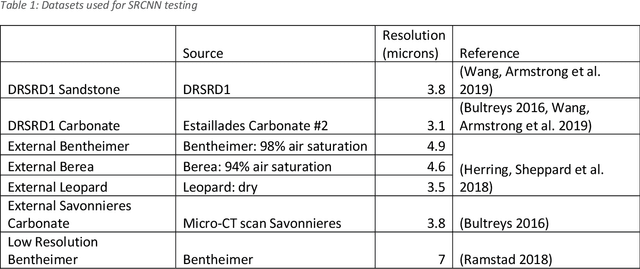
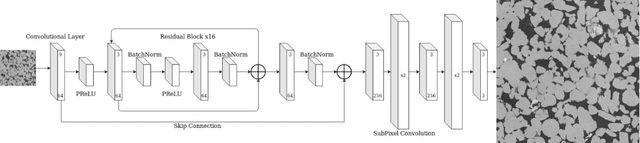
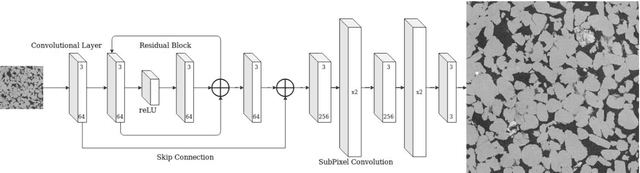
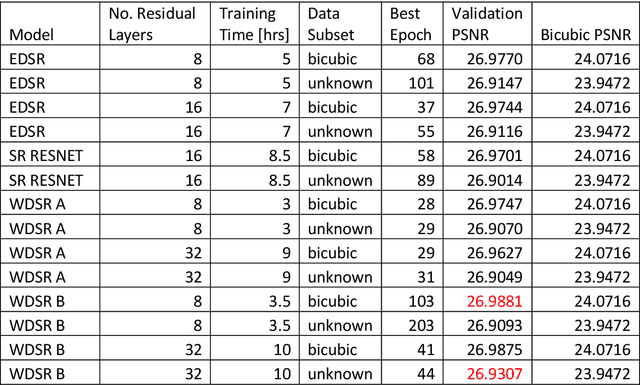
Single Image Super Resolution (SISR) techniques based on Super Resolution Convolutional Neural Networks (SRCNN) are applied to micro-computed tomography ({\mu}CT) images of sandstone and carbonate rocks. Digital rock imaging is limited by the capability of the scanning device resulting in trade-offs between resolution and field of view, and super resolution methods tested in this study aim to compensate for these limits. SRCNN models SR-Resnet, Enhanced Deep SR (EDSR), and Wide-Activation Deep SR (WDSR) are used on the Digital Rock Super Resolution 1 (DRSRD1) Dataset of 4x downsampled images, comprising of 2000 high resolution (800x800) raw micro-CT images of Bentheimer sandstone and Estaillades carbonate. The trained models are applied to the validation and test data within the dataset and show a 3-5 dB rise in image quality compared to bicubic interpolation, with all tested models performing within a 0.1 dB range. Difference maps indicate that edge sharpness is completely recovered in images within the scope of the trained model, with only high frequency noise related detail loss. We find that aside from generation of high-resolution images, a beneficial side effect of super resolution methods applied to synthetically downgraded images is the removal of image noise while recovering edgewise sharpness which is beneficial for the segmentation process. The model is also tested against real low-resolution images of Bentheimer rock with image augmentation to account for natural noise and blur. The SRCNN method is shown to act as a preconditioner for image segmentation under these circumstances which naturally leads to further future development and training of models that segment an image directly. Image restoration by SRCNN on the rock images is of significantly higher quality than traditional methods and suggests SRCNN methods are a viable processing step in a digital rock workflow.
A Smooth Representation of Belief over SO(3) for Deep Rotation Learning with Uncertainty
Jun 01, 2020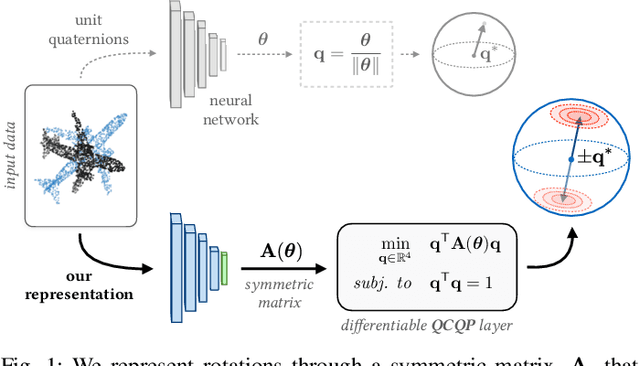

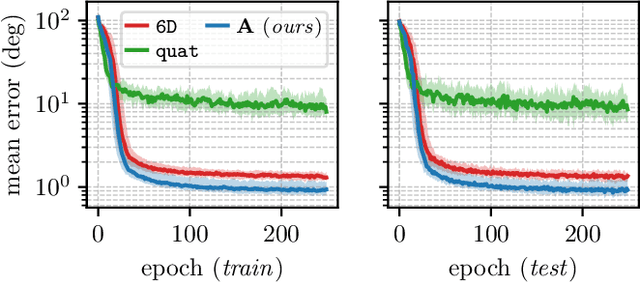
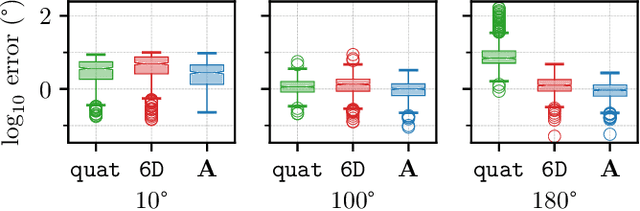
Accurate rotation estimation is at the heart of robot perception tasks such as visual odometry and object pose estimation. Deep neural networks have provided a new way to perform these tasks, and the choice of rotation representation is an important part of network design. In this work, we present a novel symmetric matrix representation of the 3D rotation group, SO(3), with two important properties that make it particularly suitable for learned models: (1) it satisfies a smoothness property that improves convergence and generalization when regressing large rotation targets, and (2) it encodes a symmetric Bingham belief over the space of unit quaternions, permitting the training of uncertainty-aware models. We empirically validate the benefits of our formulation by training deep neural rotation regressors on two data modalities. First, we use synthetic point-cloud data to show that our representation leads to superior predictive accuracy over existing representations for arbitrary rotation targets. Second, we use image data collected onboard ground and aerial vehicles to demonstrate that our representation is amenable to an effective out-of-distribution (OOD) rejection technique that significantly improves the robustness of rotation estimates to unseen environmental effects and corrupted input images, without requiring the use of an explicit likelihood loss, stochastic sampling, or an auxiliary classifier. This capability is key for safety-critical applications where detecting novel inputs can prevent catastrophic failure of learned models.