 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The perceptual boost of visual attention is task-dependent in naturalistic settings
Feb 22, 2020
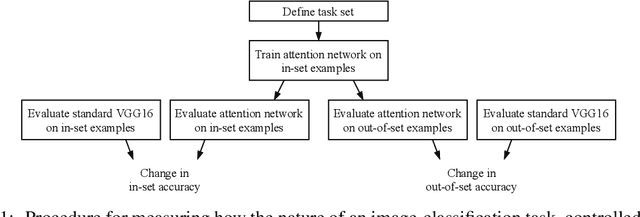
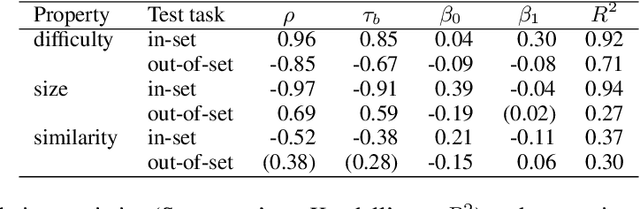
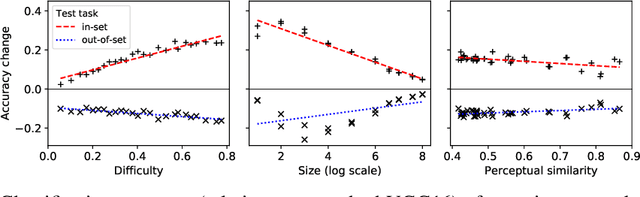
Attentional modulation of neural representations is known to enhance processing of task-relevant visual information. Is the resulting perceptual boost task-dependent in naturalistic settings? We aim to answer this with a large-scale computational experiment. First we design a series of visual tasks, each consisting of classifying images from a particular task set (group of image categories). The nature of a given task is determined by which categories are included in the task set. Then on each task we compare the accuracy of an attention-augmented neural network to that of an attention-free counterpart. We show that, all else being equal, the performance impact of attention is stronger with increasing task-set difficulty, weaker with increasing task-set size, and weaker with increasing perceptual similarity within a task set.
Image Prediction for Limited-angle Tomography via Deep Learning with Convolutional Neural Network
Jul 29, 2016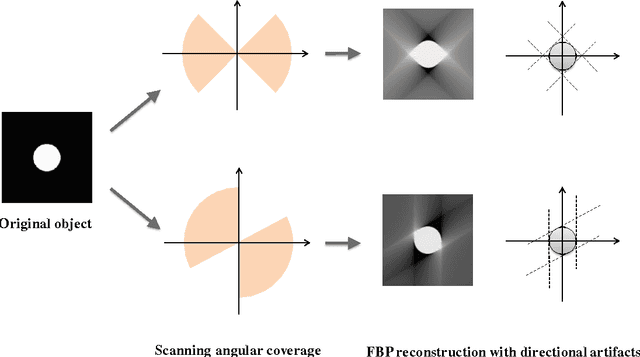

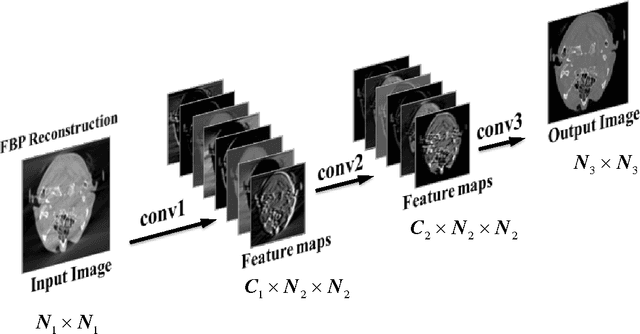
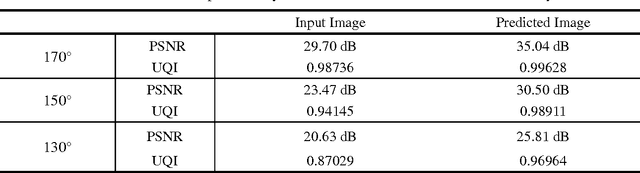
Limited angle problem is a challenging issue in x-ray computed tomography (CT) field. Iterative reconstruction methods that utilize the additional prior can suppress artifacts and improve image quality, but unfortunately require increased computation time. An interesting way is to restrain the artifacts in the images reconstructed from the practical filtered back projection (FBP) method. Frikel and Quinto have proved that the streak artifacts in FBP results could be characterized. It indicates that the artifacts created by FBP method have specific and similar characteristics in a stationary limited-angle scanning configuration. Based on this understanding, this work aims at developing a method to extract and suppress specific artifacts of FBP reconstructions for limited-angle tomography. A data-driven learning-based method is proposed based on a deep convolutional neural network. An end-to-end mapping between the FBP and artifact-free images is learned and the implicit features involving artifacts will be extracted and suppressed via nonlinear mapping. The qualitative and quantitative evaluations of experimental results indicate that the proposed method show a stable and prospective performance on artifacts reduction and detail recovery for limited angle tomography. The presented strategy provides a simple and efficient approach for improving image quality of the reconstruction results from limited projection data.
A Survey on Deep Learning Architectures for Image-based Depth Reconstruction
Jun 14, 2019
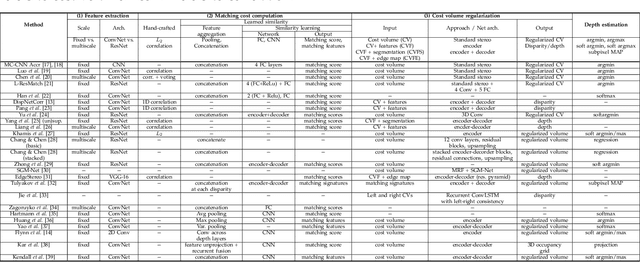
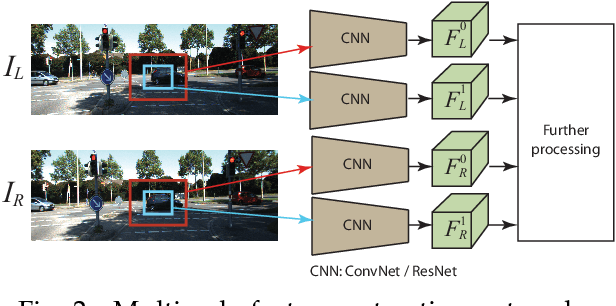
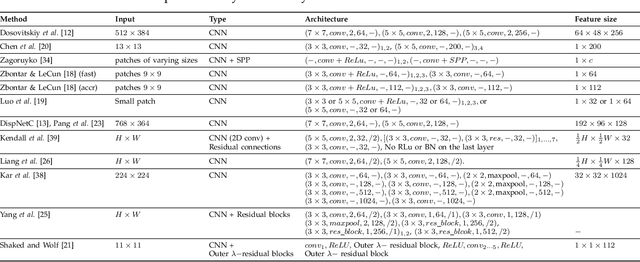
Estimating depth from RGB images is a long-standing ill-posed problem, which has been explored for decades by the computer vision, graphics, and machine learning communities. In this article, we provide a comprehensive survey of the recent developments in this field. We will focus on the works which use deep learning techniques to estimate depth from one or multiple images. Deep learning, coupled with the availability of large training datasets, have revolutionized the way the depth reconstruction problem is being approached by the research community. In this article, we survey more than 100 key contributions that appeared in the past five years, summarize the most commonly used pipelines, and discuss their benefits and limitations. In retrospect of what has been achieved so far, we also conjecture what the future may hold for learning-based depth reconstruction research.
Generalizable Cone Beam CT Esophagus Segmentation Using In Silico Data Augmentation
Jun 28, 2020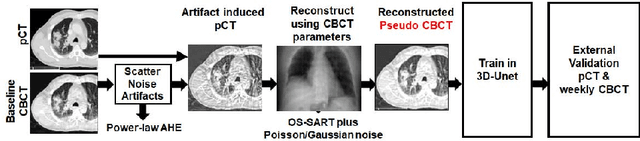
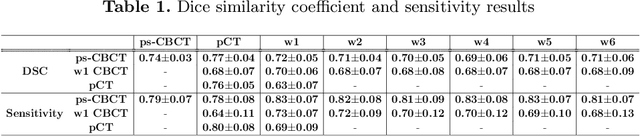
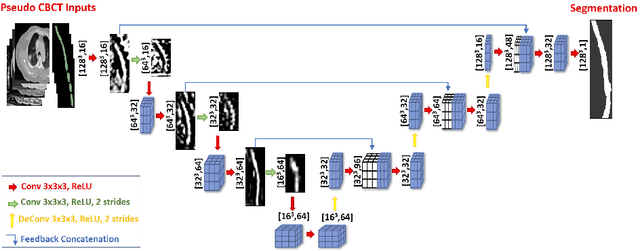

Lung cancer radiotherapy entails high quality planning computed tomography (pCT) imaging of the patient with radiation oncologist contouring of the tumor and the organs at risk (OARs) at the start of the treatment. This is followed by weekly low-quality cone beam CT (CBCT) imaging for treatment setup and qualitative visual assessment of tumor and critical OARs. In this work, we aim to make the weekly CBCT assessment quantitative by automatically segmenting the most critical OAR, esophagus, using deep learning and in silico (image-driven simulation) artifact induction to convert pCTs to pseudo-CBCTs (pCTs$+$artifacts). Specifically, for the in silico data augmentation, we make use of the critical insight that CT and CBCT have the same underlying physics and that it is easier to deteriorate the pCT to look more like CBCT (and use the accompanying high quality manual contours for segmentation) than to synthesize CT from CBCT where the critical anatomical information may have already been lost (which leads to anatomical hallucination with the prevalent generative adversarial networks for example). Given these pseudo-CBCTs and the high quality manual contours, we introduce a modified 3D-Unet architecture and a multi-objective loss function specifically designed for segmenting soft-tissue organs such as esophagus on real weekly CBCTs. The model achieved 0.74 dice overlap (against manual contours of an experienced radiation oncologist) on weekly CBCTs and was robust and generalizable enough to also produce state-of-the-art results on pCTs, achieving 0.77 dice overlap against the previous best of 0.72. This shows that our in silico data augmentation spans the realistic noise/artifact spectrum across patient CBCT/pCT data and can generalize well across modalities (without requiring retraining or domain adaptation), eventually improving the accuracy of treatment setup and response analysis.
Dense Crowds Detection and Surveillance with Drones using Density Maps
Mar 03, 2020



Detecting and Counting people in a human crowd from a moving drone present challenging problems that arisefrom the constant changing in the image perspective andcamera angle. In this paper, we test two different state-of-the-art approaches, density map generation with VGG19 trainedwith the Bayes loss function and detect-then-count with FasterRCNN with ResNet50-FPN as backbone, in order to comparetheir precision for counting and detecting people in differentreal scenarios taken from a drone flight. We show empiricallythat both proposed methodologies perform especially well fordetecting and counting people in sparse crowds when thedrone is near the ground. Nevertheless, VGG19 provides betterprecision on both tasks while also being lighter than FasterRCNN. Furthermore, VGG19 outperforms Faster RCNN whendealing with dense crowds, proving to be more robust toscale variations and strong occlusions, being more suitable forsurveillance applications using drones
Depth-wise Decomposition for Accelerating Separable Convolutions in Efficient Convolutional Neural Networks
Oct 21, 2019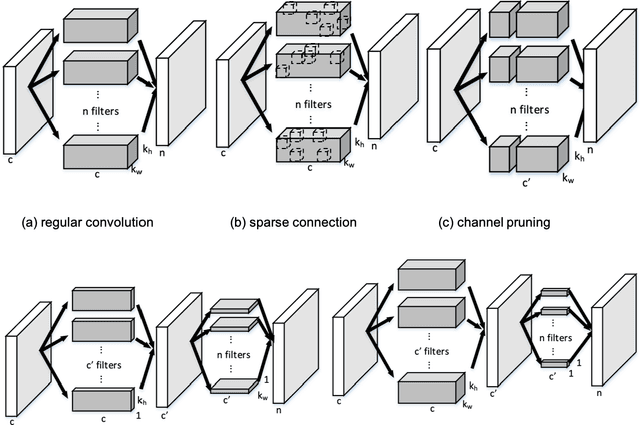
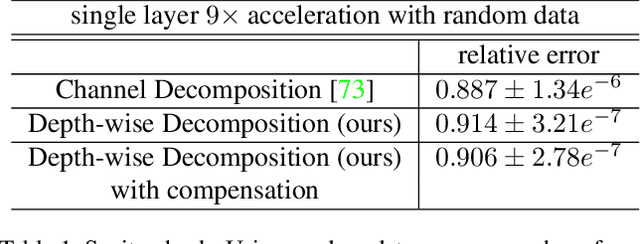


Very deep convolutional neural networks (CNNs) have been firmly established as the primary methods for many computer vision tasks. However, most state-of-the-art CNNs are large, which results in high inference latency. Recently, depth-wise separable convolution has been proposed for image recognition tasks on computationally limited platforms such as robotics and self-driving cars. Though it is much faster than its counterpart, regular convolution, accuracy is sacrificed. In this paper, we propose a novel decomposition approach based on SVD, namely depth-wise decomposition, for expanding regular convolutions into depthwise separable convolutions while maintaining high accuracy. We show our approach can be further generalized to the multi-channel and multi-layer cases, based on Generalized Singular Value Decomposition (GSVD) [59]. We conduct thorough experiments with the latest ShuffleNet V2 model [47] on both random synthesized dataset and a large-scale image recognition dataset: ImageNet [10]. Our approach outperforms channel decomposition [73] on all datasets. More importantly, our approach improves the Top-1 accuracy of ShuffleNet V2 by ~2%.
Background Matting
Feb 11, 2020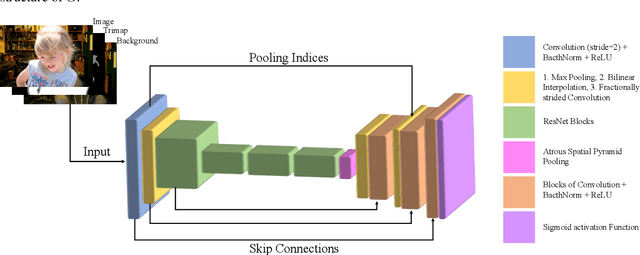
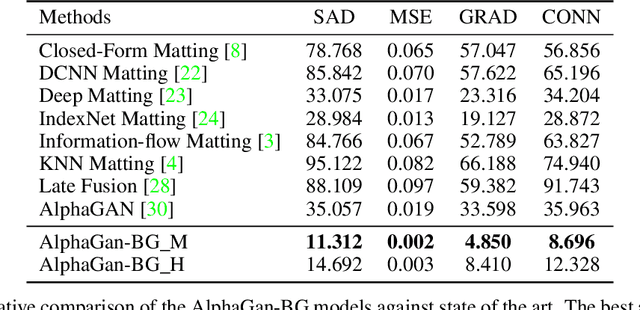


The current state of the art alpha matting methods mainly rely on the trimap as the secondary and only guidance to estimate alpha. This paper investigates the effects of utilising the background information as well as trimap in the process of alpha calculation. To achieve this goal, a state of the art method, AlphaGan is adopted and modified to process the background information as an extra input channel. Extensive experiments are performed to analyse the effect of the background information in image and video matting such as training with mildly and heavily distorted backgrounds. Based on the quantitative evaluations performed on Adobe Composition-1k dataset, the proposed pipeline significantly outperforms the state of the art methods using AlphaMatting benchmark metrics.
Self-supervised Recurrent Neural Network for 4D Abdominal and In-utero MR Imaging
Aug 28, 2019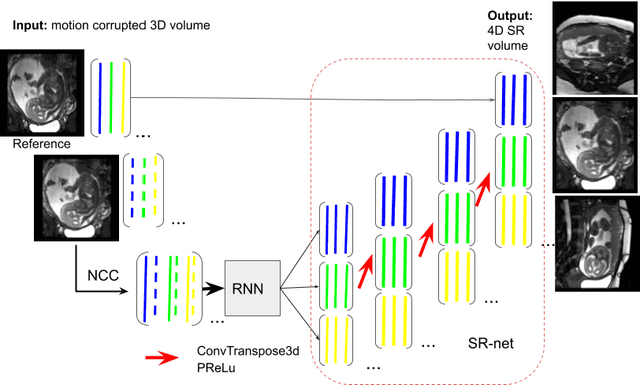

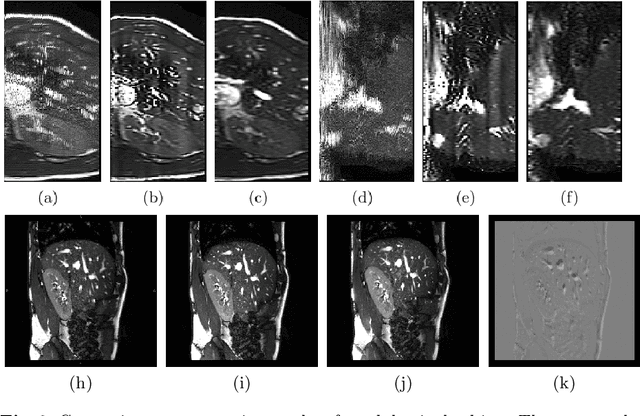
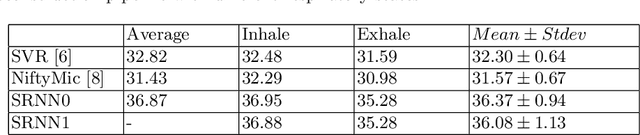
Accurately estimating and correcting the motion artifacts are crucial for 3D image reconstruction of the abdominal and in-utero magnetic resonance imaging (MRI). The state-of-art methods are based on slice-to-volume registration (SVR) where multiple 2D image stacks are acquired in three orthogonal orientations. In this work, we present a novel reconstruction pipeline that only needs one orientation of 2D MRI scans and can reconstruct the full high-resolution image without masking or registration steps. The framework consists of two main stages: the respiratory motion estimation using a self-supervised recurrent neural network, which learns the respiratory signals that are naturally embedded in the asymmetry relationship of the neighborhood slices and cluster them according to a respiratory state. Then, we train a 3D deconvolutional network for super-resolution (SR) reconstruction of the sparsely selected 2D images using integrated reconstruction and total variation loss. We evaluate the classification accuracy on 5 simulated images and compare our results with the SVR method in adult abdominal and in-utero MRI scans. The results show that the proposed pipeline can accurately estimate the respiratory state and reconstruct 4D SR volumes with better or similar performance to the 3D SVR pipeline with less than 20\% sparsely selected slices. The method has great potential to transform the 4D abdominal and in-utero MRI in clinical practice.
Putting visual object recognition in context
Dec 09, 2019


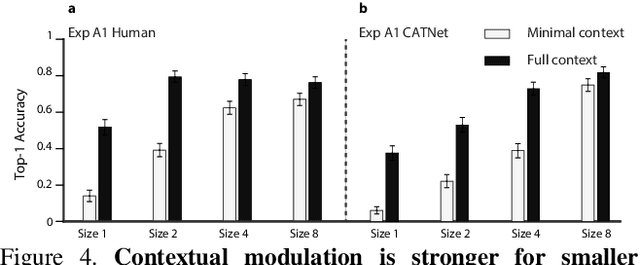
Context plays an important role in visual recognition. Recent studies have shown that visual recognition networks can be fooled by placing objects in inconsistent contexts (e.g. a cow in the ocean). To understand and model the role of contextual information in visual recognition, we systematically and quantitatively investigated ten critical properties of where, when, and how context modulates recognition including amount of context, context and object resolution, geometrical structure of context, context congruence, time required to incorporate contextual information, and temporal dynamics of contextual modulation. The tasks involve recognizing a target object surrounded with context in a natural image. As an essential benchmark, we first describe a series of psychophysics experiments, where we alter one aspect of context at a time, and quantify human recognition accuracy. To computationally assess performance on the same tasks, we propose a biologically inspired context aware object recognition model consisting of a two-stream architecture. The model processes visual information at the fovea and periphery in parallel, dynamically incorporates both object and contextual information, and sequentially reasons about the class label for the target object. Across a wide range of behavioral tasks, the model approximates human level performance without retraining for each task, captures the dependence of context enhancement on image properties, and provides initial steps towards integrating scene and object information for visual recognition.
Partial Volume Segmentation of Brain MRI Scans of any Resolution and Contrast
Apr 21, 2020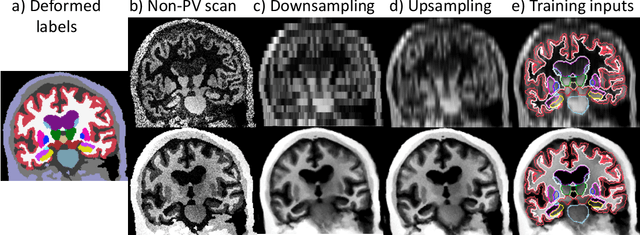

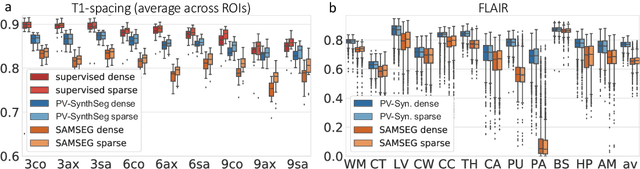
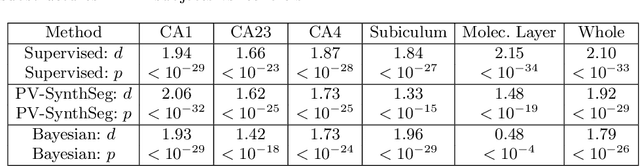
Partial voluming (PV) is arguably the last crucial unsolved problem in Bayesian segmentation of brain MRI with probabilistic atlases. PV occurs when voxels contain multiple tissue classes, giving rise to image intensities that may not be representative of any one of the underlying classes. PV is particularly problematic for segmentation when there is a large resolution gap between the atlas and the test scan, e.g., when segmenting clinical scans with thick slices, or when using a high-resolution atlas. In this work, we present PV-SynthSeg, a convolutional neural network (CNN) that tackles this problem by directly learning a mapping between (possibly multi-modal) low resolution (LR) scans and underlying high resolution (HR) segmentations. PV-SynthSeg simulates LR images from HR label maps with a generative model of PV, and can be trained to segment scans of any desired target contrast and resolution, even for previously unseen modalities where neither images nor segmentations are available at training. PV-SynthSeg does not require any preprocessing, and runs in seconds. We demonstrate the accuracy and flexibility of the method with extensive experiments on three datasets and 2,680 scans. The code is available at https://github.com/BBillot/SynthSeg.