 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sensor Fusion for Joint 3D Object Detection and Semantic Segmentation
Apr 25, 2019
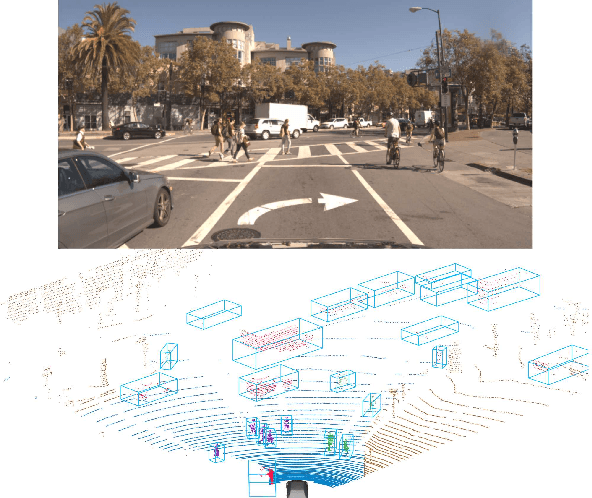

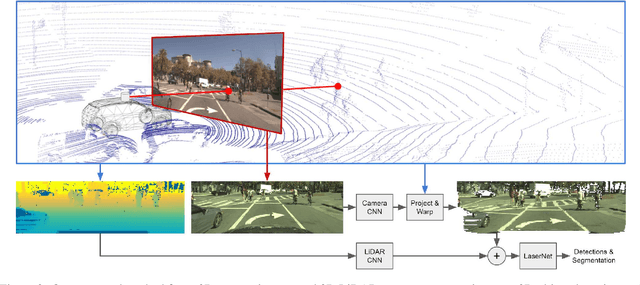
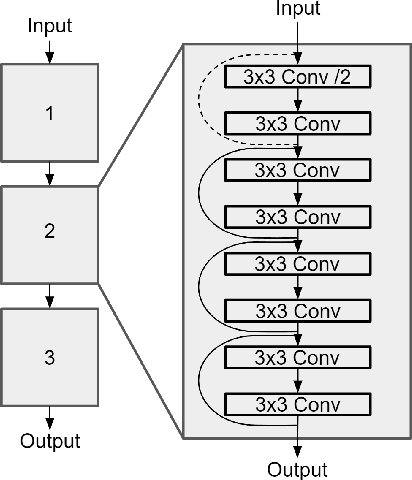
In this paper, we present an extension to LaserNet, an efficient and state-of-the-art LiDAR based 3D object detector. We propose a method for fusing image data with the LiDAR data and show that this sensor fusion method improves the detection performance of the model especially at long ranges. The addition of image data is straightforward and does not require image labels. Furthermore, we expand the capabilities of the model to perform 3D semantic segmentation in addition to 3D object detection. On a large benchmark dataset, we demonstrate our approach achieves state-of-the-art performance on both object detection and semantic segmentation while maintaining a low runtime.
Plug-and-play ISTA converges with kernel denoisers
Apr 07, 2020
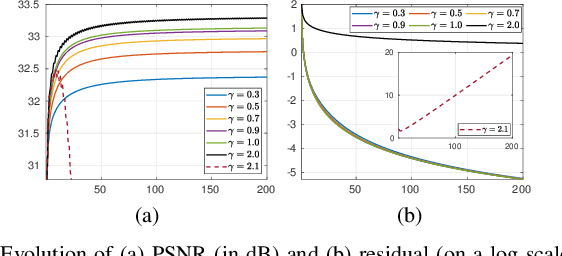
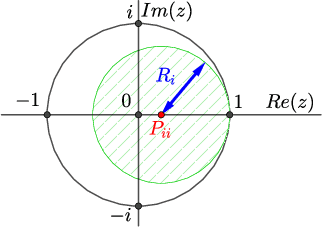
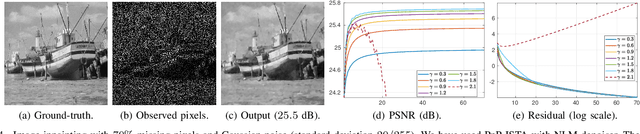
Plug-and-play (PnP) method is a recent paradigm for image regularization, where the proximal operator (associated with some given regularizer) in an iterative algorithm is replaced with a powerful denoiser. Algorithmically, this involves repeated inversion (of the forward model) and denoising until convergence. Remarkably, PnP regularization produces promising results for several restoration applications. However, a fundamental question in this regard is the theoretical convergence of the PnP iterations, since the algorithm is not strictly derived from an optimization framework. This question has been investigated in recent works, but there are still many unresolved problems. For example, it is not known if convergence can be guaranteed if we use generic kernel denoisers (e.g. nonlocal means) within the ISTA framework (PnP-ISTA). We prove that, under reasonable assumptions, fixed-point convergence of PnP-ISTA is indeed guaranteed for linear inverse problems such as deblurring, inpainting and superresolution (the assumptions are verifiable for inpainting). We compare our theoretical findings with existing results, validate them numerically, and explain their practical relevance.
SR2CNN: Zero-Shot Learning for Signal Recognition
Apr 22, 2020



Signal recognition is one of significant and challenging tasks in the signal processing and communications field. It is often a common situation that there's no training data accessible for some signal classes to perform a recognition task. Hence, as widely-used in image processing field, zero-shot learning (ZSL) is also very important for signal recognition. Unfortunately, ZSL regarding this field has hardly been studied due to inexplicable signal semantics. This paper proposes a ZSL framework, signal recognition and reconstruction convolutional neural networks (SR2CNN), to address relevant problems in this situation. The key idea behind SR2CNN is to learn the representation of signal semantic feature space by introducing a proper combination of cross entropy loss, center loss and autoencoder loss, as well as adopting a suitable distance metric space such that semantic features have greater minimal inter-class distance than maximal intra-class distance. The proposed SR2CNN can discriminate signals even if no training data is available for some signal class. Moreover, SR2CNN can gradually improve itself in the aid of signal detection, because of constantly refined class center vectors in semantic feature space. These merits are all verified by extensive experiments.
A New Framework for Retinex based Color Image Enhancement using Particle Swarm Optimization
Sep 14, 2014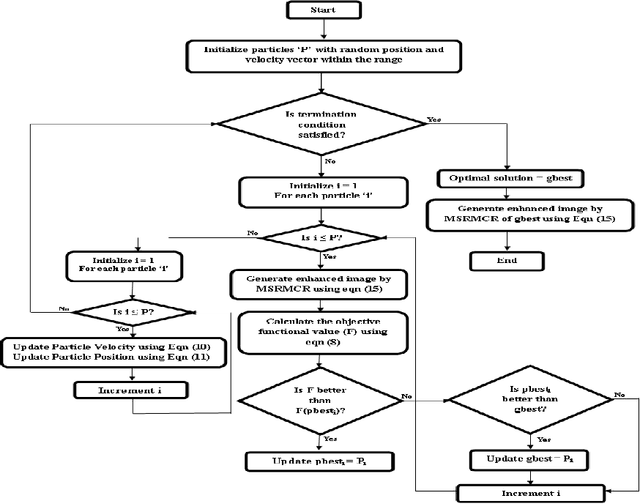
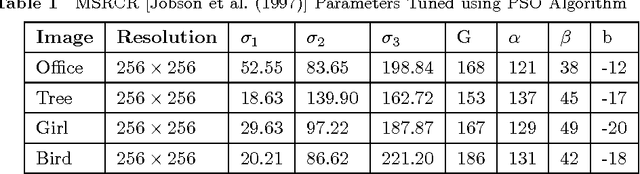
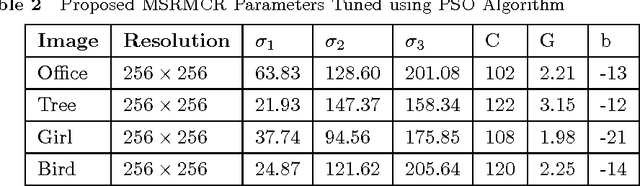

A new approach for tuning the parameters of MultiScale Retinex (MSR) based color image enhancement algorithm using a popular optimization method, namely, Particle Swarm Optimization (PSO) is presented in this paper. The image enhancement using MSR scheme heavily depends on parameters such as Gaussian surround space constant, number of scales, gain and offset etc. Selection of these parameters, empirically and its application to MSR scheme to produce inevitable results are the major blemishes. The method presented here results in huge savings of computation time as well as improvement in the visual quality of an image, since the PSO exploited maximizes the MSR parameters. The objective of PSO is to validate the visual quality of the enhanced image iteratively using an effective objective criterion based on entropy and edge information of an image. The PSO method of parameter optimization of MSR scheme achieves a very good quality of reconstructed images, far better than that possible with the other existing methods. Finally, the quality of the enhanced color images obtained by the proposed method are evaluated using novel metric, namely, Wavelet Energy (WE). The experimental results presented show that color images enhanced using the proposed scheme are clearer, more vivid and efficient.
The perceptual boost of visual attention is task-dependent in naturalistic settings
Feb 22, 2020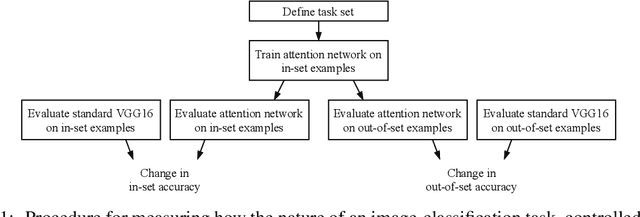
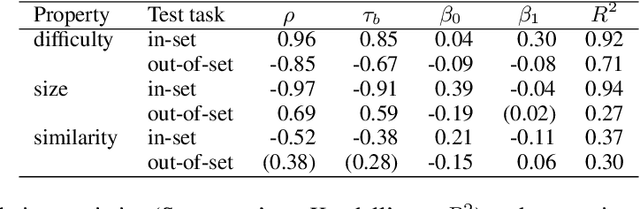
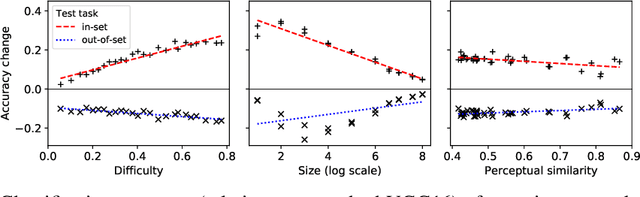
Attentional modulation of neural representations is known to enhance processing of task-relevant visual information. Is the resulting perceptual boost task-dependent in naturalistic settings? We aim to answer this with a large-scale computational experiment. First we design a series of visual tasks, each consisting of classifying images from a particular task set (group of image categories). The nature of a given task is determined by which categories are included in the task set. Then on each task we compare the accuracy of an attention-augmented neural network to that of an attention-free counterpart. We show that, all else being equal, the performance impact of attention is stronger with increasing task-set difficulty, weaker with increasing task-set size, and weaker with increasing perceptual similarity within a task set.
Generalizable Cone Beam CT Esophagus Segmentation Using In Silico Data Augmentation
Jun 28, 2020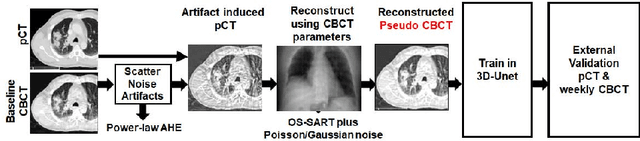
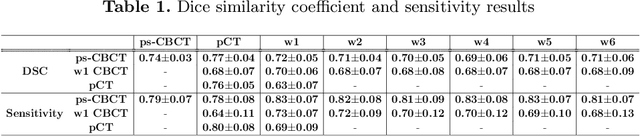
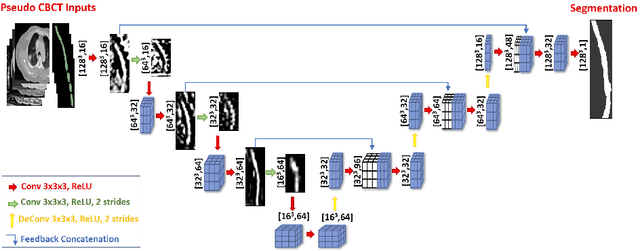

Lung cancer radiotherapy entails high quality planning computed tomography (pCT) imaging of the patient with radiation oncologist contouring of the tumor and the organs at risk (OARs) at the start of the treatment. This is followed by weekly low-quality cone beam CT (CBCT) imaging for treatment setup and qualitative visual assessment of tumor and critical OARs. In this work, we aim to make the weekly CBCT assessment quantitative by automatically segmenting the most critical OAR, esophagus, using deep learning and in silico (image-driven simulation) artifact induction to convert pCTs to pseudo-CBCTs (pCTs$+$artifacts). Specifically, for the in silico data augmentation, we make use of the critical insight that CT and CBCT have the same underlying physics and that it is easier to deteriorate the pCT to look more like CBCT (and use the accompanying high quality manual contours for segmentation) than to synthesize CT from CBCT where the critical anatomical information may have already been lost (which leads to anatomical hallucination with the prevalent generative adversarial networks for example). Given these pseudo-CBCTs and the high quality manual contours, we introduce a modified 3D-Unet architecture and a multi-objective loss function specifically designed for segmenting soft-tissue organs such as esophagus on real weekly CBCTs. The model achieved 0.74 dice overlap (against manual contours of an experienced radiation oncologist) on weekly CBCTs and was robust and generalizable enough to also produce state-of-the-art results on pCTs, achieving 0.77 dice overlap against the previous best of 0.72. This shows that our in silico data augmentation spans the realistic noise/artifact spectrum across patient CBCT/pCT data and can generalize well across modalities (without requiring retraining or domain adaptation), eventually improving the accuracy of treatment setup and response analysis.
Knowledge Distillation for Incremental Learning in Semantic Segmentation
Nov 08, 2019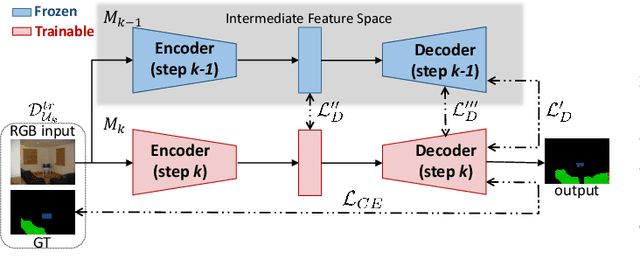
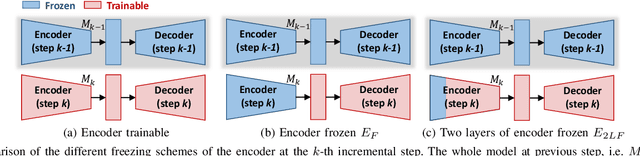


Although deep learning architectures have shown remarkable results in scene understanding problems, they exhibit a critical drop of overall performance due to catastrophic forgetting when they are required to incrementally learn to recognize new classes without forgetting the old ones. This phenomenon impacts on the deployment of artificial intelligence in real world scenarios where systems need to learn new and different representations over time. Current approaches for incremental learning deal only with the image classification and object detection tasks. In this work we formally introduce the incremental learning problem for semantic segmentation. To avoid catastrophic forgetting we propose to distill the knowledge of the previous model to retain the information about previously learned classes, whilst updating the current model to learn the new ones. We developed three main methodologies of knowledge distillation working on both the output layers and the internal feature representations. Furthermore, differently from other recent frameworks, we do not store any image belonging to the previous training stages while only the last model is used to preserve high accuracy on previously learned classes. Extensive results were conducted on the Pascal VOC2012 dataset and show the effectiveness of the proposed approaches in different incremental learning scenarios.
Dense Crowds Detection and Surveillance with Drones using Density Maps
Mar 03, 2020



Detecting and Counting people in a human crowd from a moving drone present challenging problems that arisefrom the constant changing in the image perspective andcamera angle. In this paper, we test two different state-of-the-art approaches, density map generation with VGG19 trainedwith the Bayes loss function and detect-then-count with FasterRCNN with ResNet50-FPN as backbone, in order to comparetheir precision for counting and detecting people in differentreal scenarios taken from a drone flight. We show empiricallythat both proposed methodologies perform especially well fordetecting and counting people in sparse crowds when thedrone is near the ground. Nevertheless, VGG19 provides betterprecision on both tasks while also being lighter than FasterRCNN. Furthermore, VGG19 outperforms Faster RCNN whendealing with dense crowds, proving to be more robust toscale variations and strong occlusions, being more suitable forsurveillance applications using drones
Face Image Analysis using AAM, Gabor, LBP and WD features for Gender, Age, Expression and Ethnicity Classification
Mar 29, 2016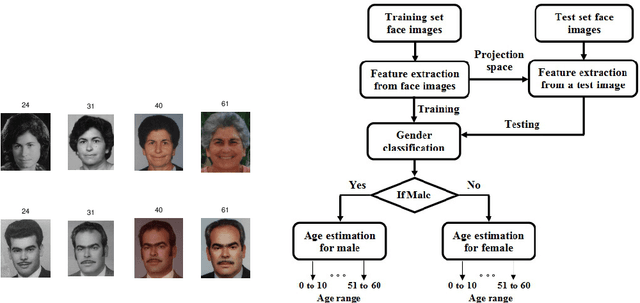
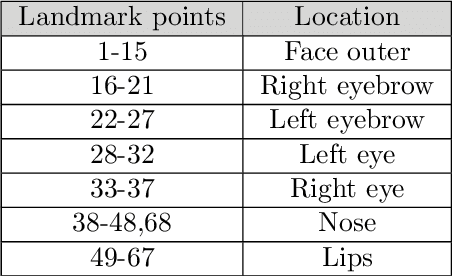
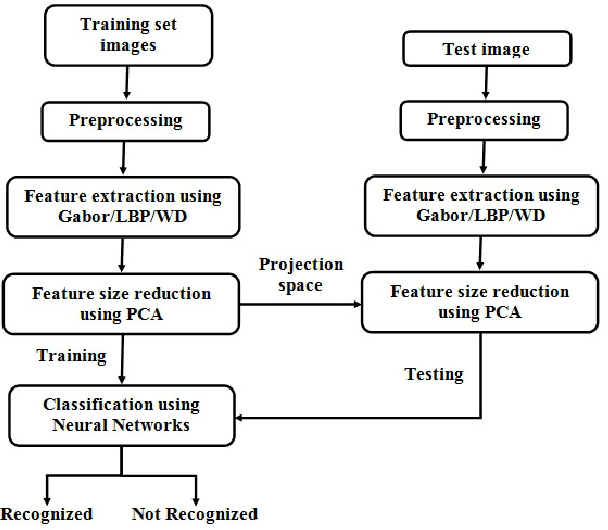
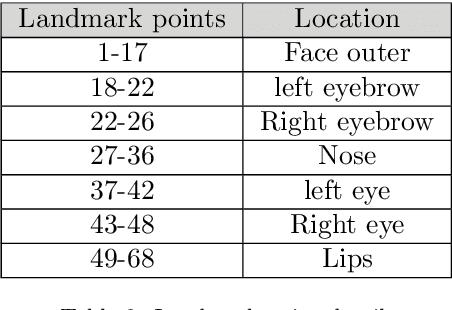
The growth in electronic transactions and human machine interactions rely on the information such as gender, age, expression and ethnicity provided by the face image. In order to obtain these information, feature extraction plays a major role. In this paper, retrieval of age, gender, expression and race information from an individual face image is analysed using different feature extraction methods. The performance of four major feature extraction methods such as Active Appearance Model (AAM), Gabor wavelets, Local Binary Pattern (LBP) and Wavelet Decomposition (WD) are analyzed for gender recognition, age estimation, expression recognition and racial recognition in terms of accuracy (recognition rate), time for feature extraction, neural training and time to test an image. Each of this recognition system is compared with four feature extractors on same dataset (training and validation set) to get a better understanding in its performance. Experiments carried out on FG-NET, Cohn-Kanade, PAL face database shows that each method has its own merits and demerits. Hence it is practically impossible to define a method which is best at all circumstances with less computational complexity. Further, a detailed comparison of age estimation and age estimation using gender information is provided along with a solution to overcome aging effect in case of gender recognition. An attempt has been made in obtaining all (i.e. gender, age range, expression and ethnicity) information from a test image in a single go.
DRAW: A Recurrent Neural Network For Image Generation
May 20, 2015

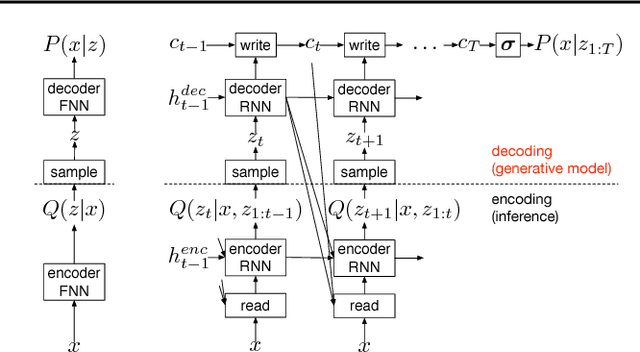
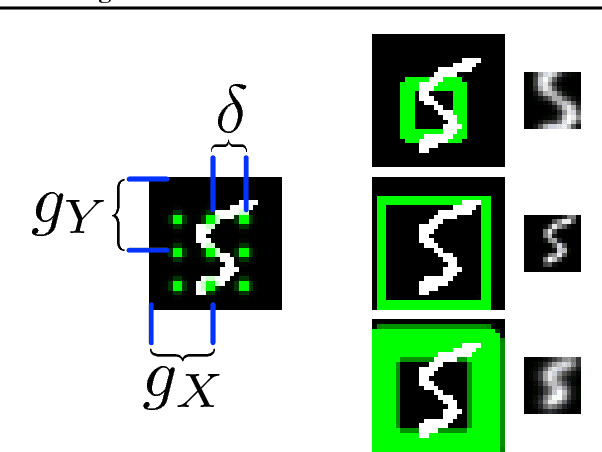
This paper introduces the Deep Recurrent Attentive Writer (DRAW) neural network architecture for image generation. DRAW networks combine a novel spatial attention mechanism that mimics the foveation of the human eye, with a sequential variational auto-encoding framework that allows for the iterative construction of complex images. The system substantially improves on the state of the art for generative models on MNIST, and, when trained on the Street View House Numbers dataset, it generates images that cannot be distinguished from real data with the naked eye.