 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust Vision-based Obstacle Avoidance for Micro Aerial Vehicles in Dynamic Environments
Feb 13, 2020

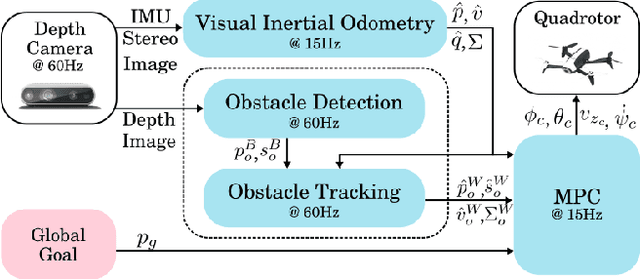
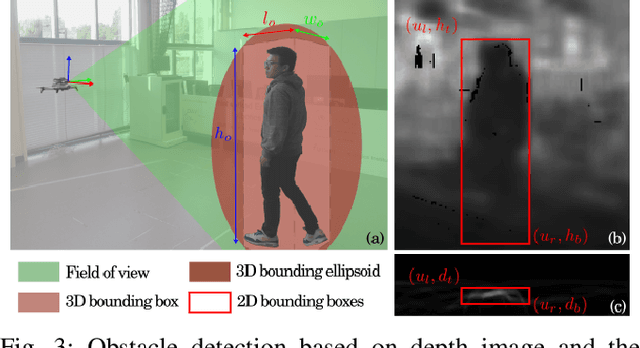

In this paper, we present an on-board vision-based approach for avoidance of moving obstacles in dynamic environments. Our approach relies on an efficient obstacle detection and tracking algorithm based on depth image pairs, which provides the estimated position, velocity and size of the obstacles. Robust collision avoidance is achieved by formulating a chance-constrained model predictive controller (CC-MPC) to ensure that the collision probability between the micro aerial vehicle (MAV) and each moving obstacle is below a specified threshold. The method takes into account MAV dynamics, state estimation and obstacle sensing uncertainties. The proposed approach is implemented on a quadrotor equipped with a stereo camera and is tested in a variety of environments, showing effective on-line collision avoidance of moving obstacles.
Semi-supervised Disentanglement with Independent Vector Variational Autoencoders
Mar 14, 2020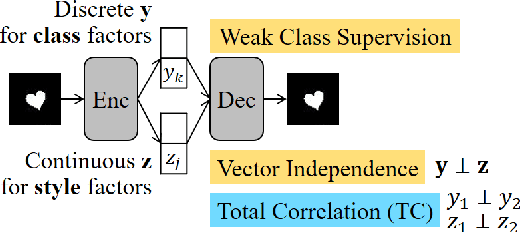
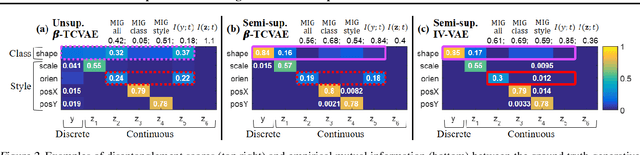

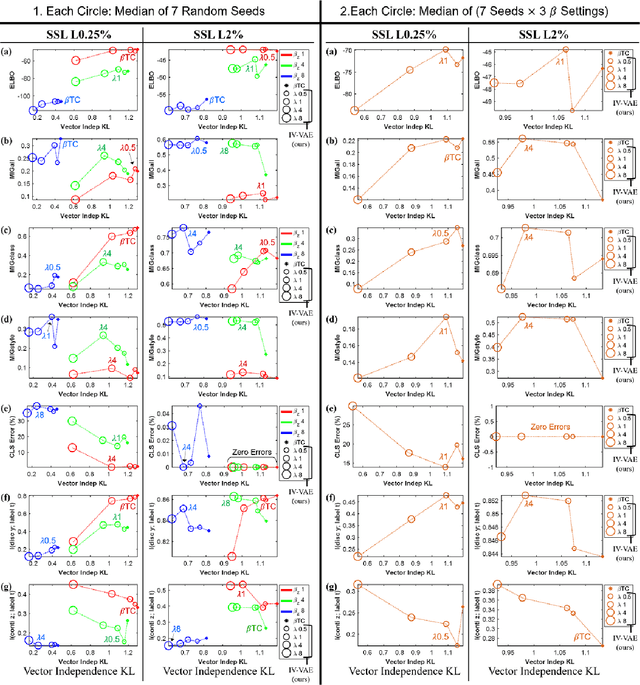
We aim to separate the generative factors of data into two latent vectors in a variational autoencoder. One vector captures class factors relevant to target classification tasks, while the other vector captures style factors relevant to the remaining information. To learn the discrete class features, we introduce supervision using a small amount of labeled data, which can simply yet effectively reduce the effort required for hyperparameter tuning performed in existing unsupervised methods. Furthermore, we introduce a learning objective to encourage statistical independence between the vectors. We show that (i) this vector independence term exists within the result obtained on decomposing the evidence lower bound with multiple latent vectors, and (ii) encouraging such independence along with reducing the total correlation within the vectors enhances disentanglement performance. Experiments conducted on several image datasets demonstrate that the disentanglement achieved via our method can improve classification performance and generation controllability.
Hierarchical Auxiliary Learning
Jun 03, 2019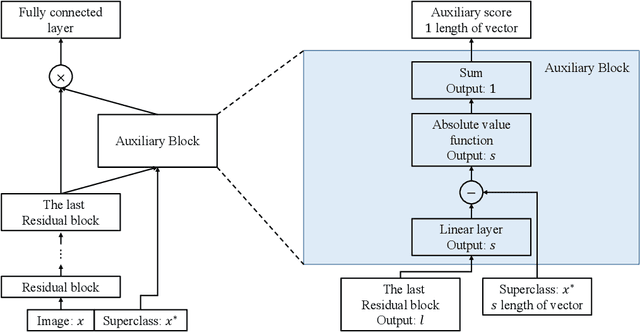
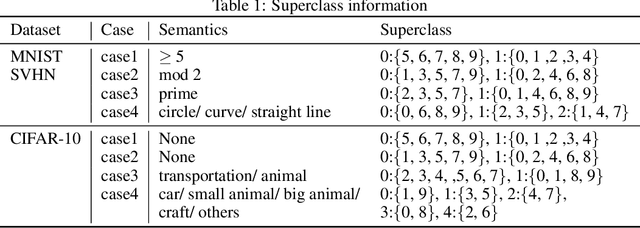
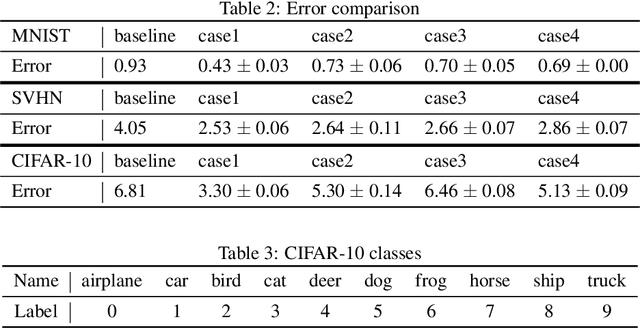
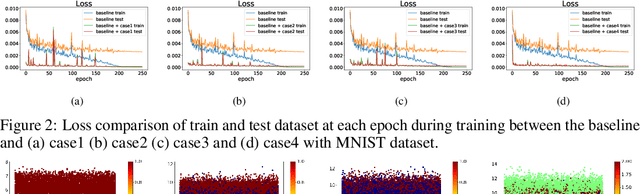
Conventional application of convolutional neural networks (CNNs) for image classification and recognition is based on the assumption that all target classes are equal(i.e., no hierarchy) and exclusive of one another (i.e., no overlap). CNN-based image classifiers built on this assumption, therefore, cannot take into account an innate hierarchy among target classes (e.g., cats and dogs in animal image classification) or additional information that can be easily derived from the data (e.g.,numbers larger than five in the recognition of handwritten digits), thereby resulting in scalability issues when the number of target classes is large. Combining two related but slightly different ideas of hierarchical classification and logical learning by auxiliary inputs, we propose a new learning framework called hierarchical auxiliary learning, which not only address the scalability issues with a large number of classes but also could further reduce the classification/recognition errors with a reasonable number of classes. In the hierarchical auxiliary learning, target classes are semantically or non-semantically grouped into superclasses, which turns the original problem of mapping between an image and its target class into a new problem of mapping between a pair of an image and its superclass and the target class. To take the advantage of superclasses, we introduce an auxiliary block into a neural network, which generates auxiliary scores used as additional information for final classification/recognition; in this paper, we add the auxiliary block between the last residual block and the fully-connected output layer of the ResNet. Experimental results demonstrate that the proposed hierarchical auxiliary learning can reduce classification errors up to 0.56, 1.6 and 3.56 percent with MNIST, SVHN and CIFAR-10 datasets, respectively.
Illumination-based Transformations Improve Skin Lesion Segmentation in Dermoscopic Images
Mar 23, 2020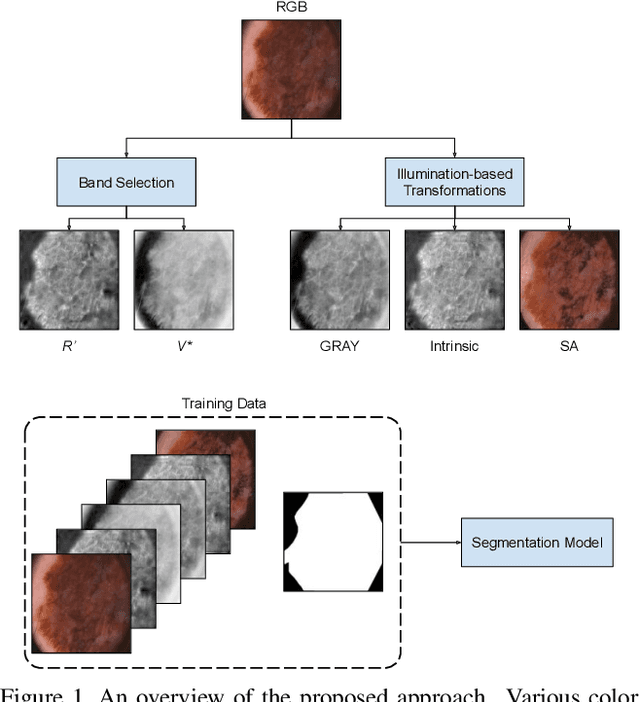
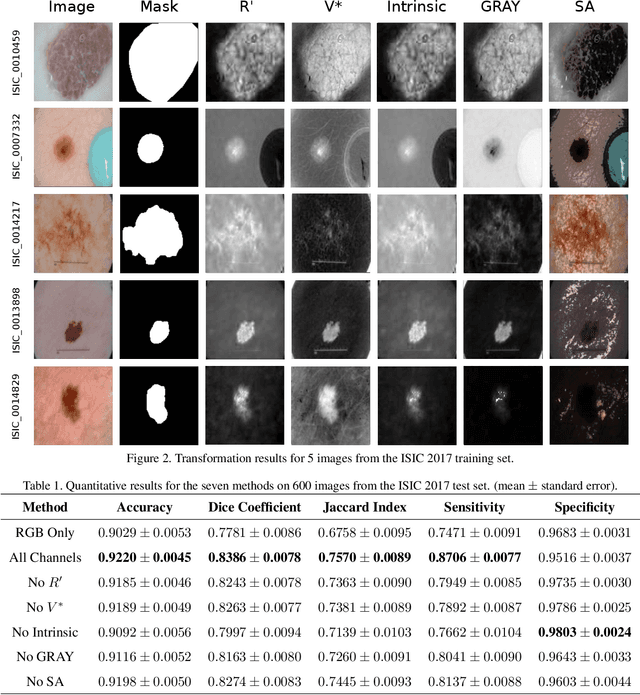

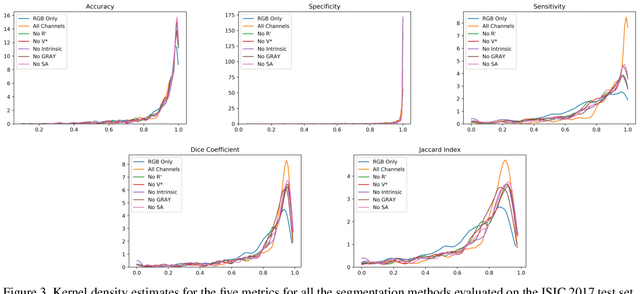
The semantic segmentation of skin lesions is an important and common initial task in the computer aided diagnosis of dermoscopic images. Although deep learning-based approaches have considerably improved the segmentation accuracy, there is still room for improvement by addressing the major challenges, such as variations in lesion shape, size, color and varying levels of contrast. In this work, we propose the first deep semantic segmentation framework for dermoscopic images which incorporates, along with the original RGB images, information extracted using the physics of skin illumination and imaging. In particular, we incorporate information from specific color bands, illumination invariant grayscale images, and shading-attenuated images. We evaluate our method on three datasets: the ISBI ISIC 2017 Skin Lesion Segmentation Challenge dataset, the DermoFit Image Library, and the PH2 dataset and observe improvements of 12.02%, 4.30%, and 8.86% respectively in the mean Jaccard index over a baseline model trained only with RGB images.
Visual Dialogue State Tracking for Question Generation
Nov 25, 2019
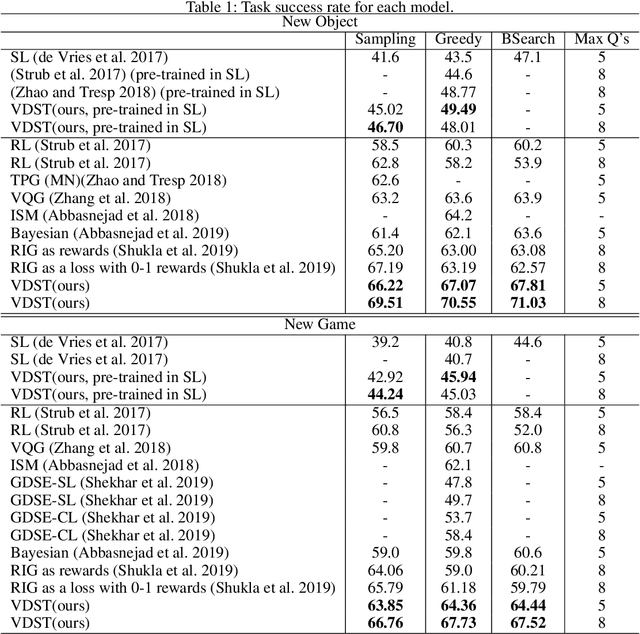
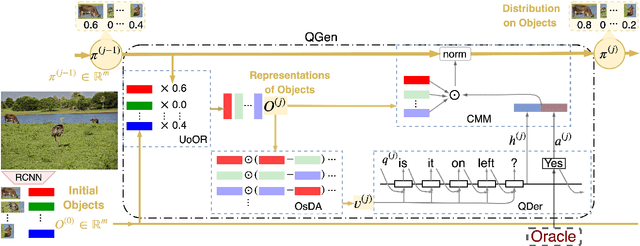
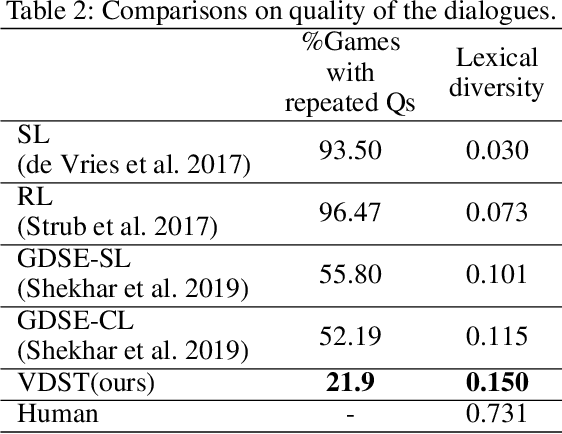
GuessWhat?! is a visual dialogue task between a guesser and an oracle. The guesser aims to locate an object supposed by the oracle oneself in an image by asking a sequence of Yes/No questions. Asking proper questions with the progress of dialogue is vital for achieving successful final guess. As a result, the progress of dialogue should be properly represented and tracked. Previous models for question generation pay less attention on the representation and tracking of dialogue states, and therefore are prone to asking low quality questions such as repeated questions. This paper proposes visual dialogue state tracking (VDST) based method for question generation. A visual dialogue state is defined as the distribution on objects in the image as well as representations of objects. Representations of objects are updated with the change of the distribution on objects. An object-difference based attention is used to decode new question. The distribution on objects is updated by comparing the question-answer pair and objects. Experimental results on GuessWhat?! dataset show that our model significantly outperforms existing methods and achieves new state-of-the-art performance. It is also noticeable that our model reduces the rate of repeated questions from more than 50% to 21.9% compared with previous state-of-the-art methods.
Multi-Kernel Prediction Networks for Denoising of Burst Images
Feb 05, 2019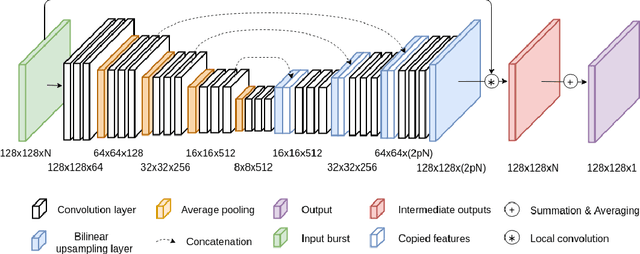
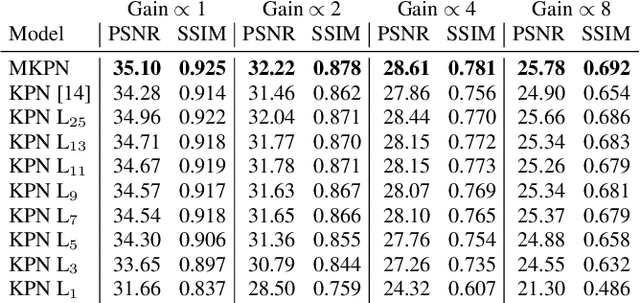
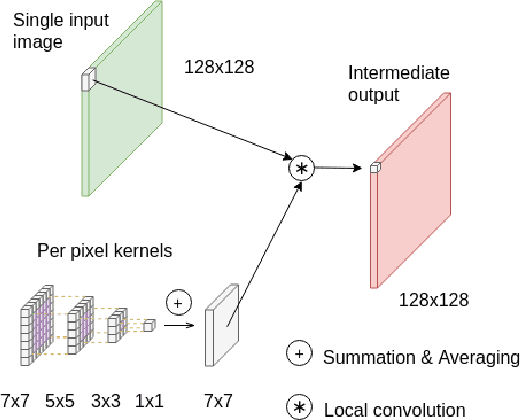

In low light or short-exposure photography the image is often corrupted by noise. While longer exposure helps reduce the noise, it can produce blurry results due to the object and camera motion. The reconstruction of a noise-less image is an ill posed problem. Recent approaches for image denoising aim to predict kernels which are convolved with a set of successively taken images (burst) to obtain a clear image. We propose a deep neural network based approach called Multi-Kernel Prediction Networks (MKPN) for burst image denoising. MKPN predicts kernels of not just one size but of varying sizes and performs fusion of these different kernels resulting in one kernel per pixel. The advantages of our method are two fold: (a) the different sized kernels help in extracting different information from the image which results in better reconstruction and (b) kernel fusion assures retaining of the extracted information while maintaining computational efficiency. Experimental results reveal that MKPN outperforms state-of-the-art on our synthetic datasets with different noise levels.
Predictive Sampling with Forecasting Autoregressive Models
Feb 23, 2020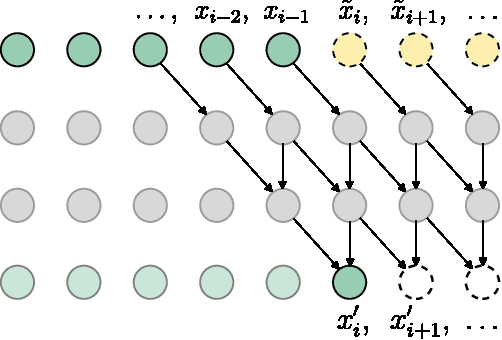
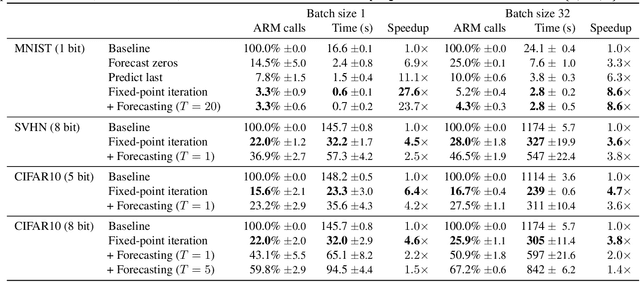
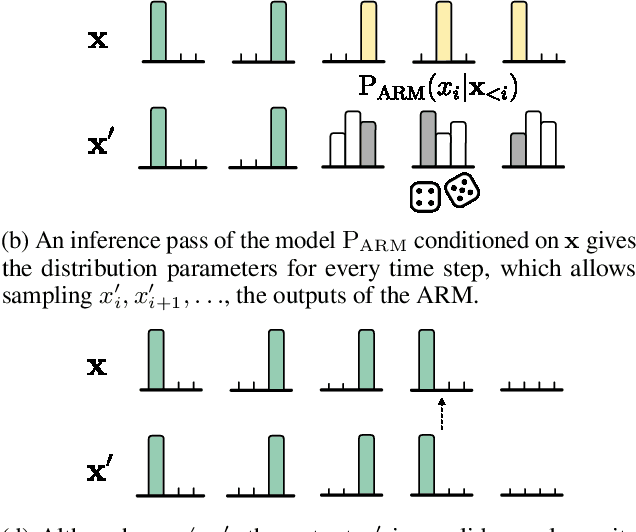
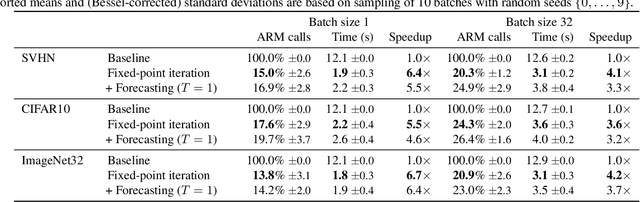
Autoregressive models (ARMs) currently hold state-of-the-art performance in likelihood-based modeling of image and audio data. Generally, neural network based ARMs are designed to allow fast inference, but sampling from these models is impractically slow. In this paper, we introduce the predictive sampling algorithm: a procedure that exploits the fast inference property of ARMs in order to speed up sampling, while keeping the model intact. We propose two variations of predictive sampling, namely sampling with ARM fixed-point iteration and learned forecasting modules. Their effectiveness is demonstrated in two settings: i) explicit likelihood modeling on binary MNIST, SVHN and CIFAR10, and ii) discrete latent modeling in an autoencoder trained on SVHN, CIFAR10 and Imagenet32. Empirically, we show considerable improvements over baselines in number of ARM inference calls and sampling speed.
Monocular Direct Sparse Localization in a Prior 3D Surfel Map
Feb 23, 2020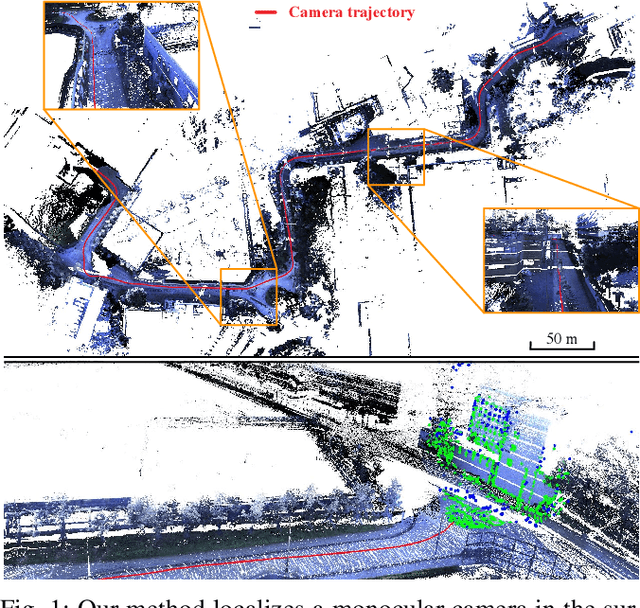
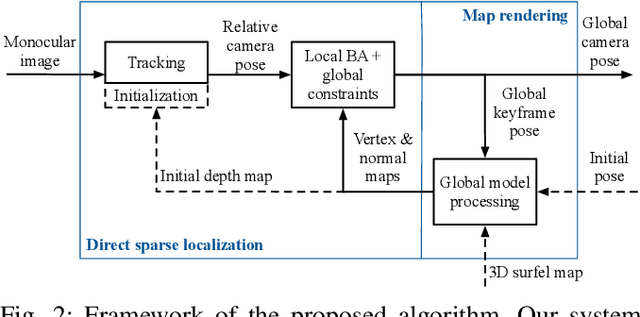
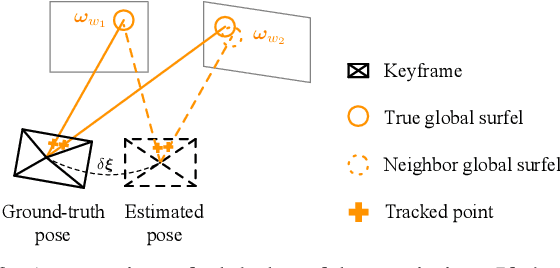

In this paper, we introduce an approach to tracking the pose of a monocular camera in a prior surfel map. By rendering vertex and normal maps from the prior surfel map, the global planar information for the sparse tracked points in the image frame is obtained. The tracked points with and without the global planar information involve both global and local constraints of frames to the system. Our approach formulates all constraints in the form of direct photometric errors within a local window of the frames. The final optimization utilizes these constraints to provide the accurate estimation of global 6-DoF camera poses with the absolute scale. The extensive simulation and real-world experiments demonstrate that our monocular method can provide accurate camera localization results under various conditions.
Structured Multimodal Attentions for TextVQA
Jun 01, 2020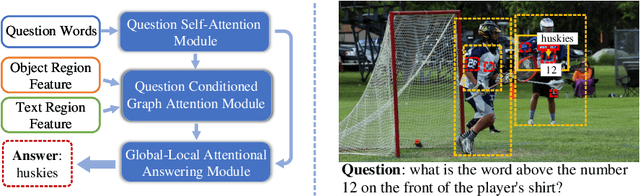
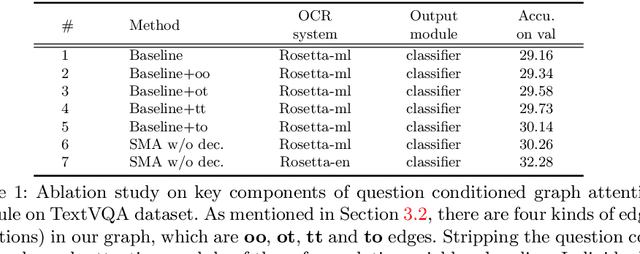
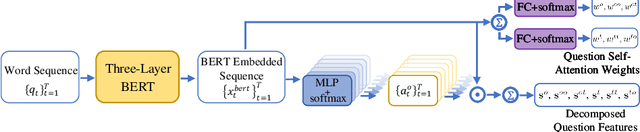

Text based Visual Question Answering (TextVQA) is a recently raised challenge that requires a machine to read text in images and answer natural language questions by jointly reasoning over the question, Optical Character Recognition (OCR) tokens and visual content. Most of the state-of-the-art (SoTA) VQA methods fail to answer these questions because of i) poor text reading ability; ii) lacking of text-visual reasoning capacity; and iii) adopting a discriminative answering mechanism instead of a generative one which is hard to cover both OCR tokens and general text tokens in the final answer. In this paper, we propose a structured multimodal attention (SMA) neural network to solve the above issues. Our SMA first uses a structural graph representation to encode the object-object, object-text and text-text relationships appearing in the image, and then design a multimodal graph attention network to reason over it. Finally, the outputs from the above module are processed by a global-local attentional answering module to produce an answer that covers tokens from both OCR and general text iteratively. Our proposed model outperforms the SoTA models on TextVQA dataset and all three tasks of ST-VQA dataset. To provide an upper bound for our method and a fair testing base for further works, we also provide human-annotated ground-truth OCR annotations for the TextVQA dataset, which were not given in the original release.
Self-organization of multi-layer spiking neural networks
Jun 12, 2020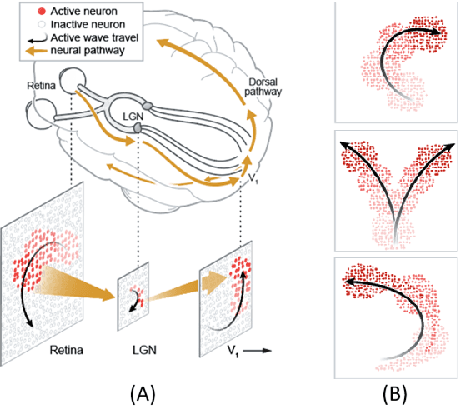
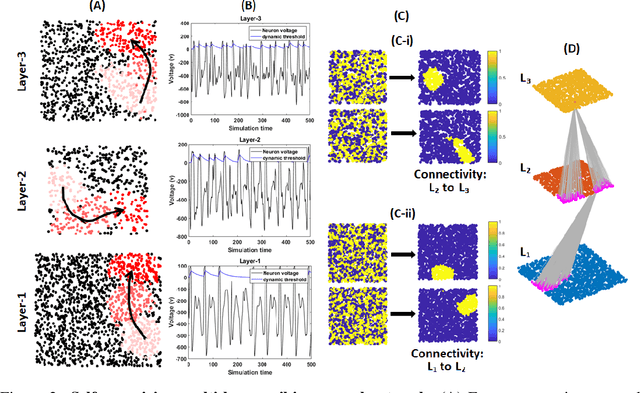
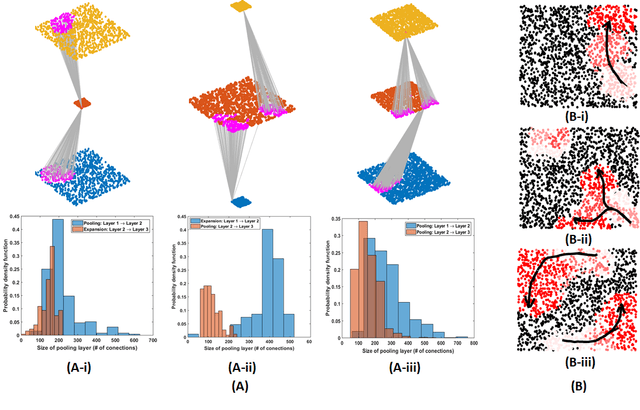
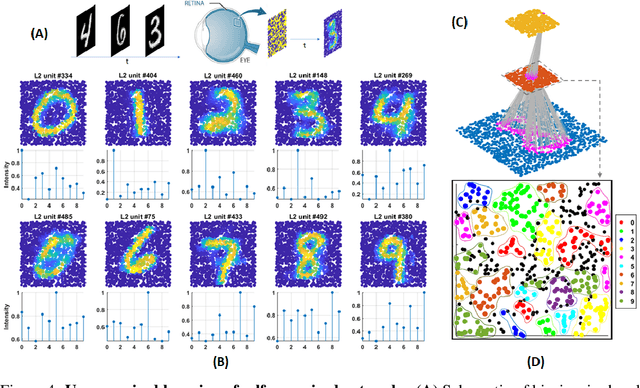
Living neural networks in our brains autonomously self-organize into large, complex architectures during early development to result in an organized and functional organic computational device. A key mechanism that enables the formation of complex architecture in the developing brain is the emergence of traveling spatio-temporal waves of neuronal activity across the growing brain. Inspired by this strategy, we attempt to efficiently self-organize large neural networks with an arbitrary number of layers into a wide variety of architectures. To achieve this, we propose a modular tool-kit in the form of a dynamical system that can be seamlessly stacked to assemble multi-layer neural networks. The dynamical system encapsulates the dynamics of spiking units, their inter/intra layer interactions as well as the plasticity rules that control the flow of information between layers. The key features of our tool-kit are (1) autonomous spatio-temporal waves across multiple layers triggered by activity in the preceding layer and (2) Spike-timing dependent plasticity (STDP) learning rules that update the inter-layer connectivity based on wave activity in the connecting layers. Our framework leads to the self-organization of a wide variety of architectures, ranging from multi-layer perceptrons to autoencoders. We also demonstrate that emergent waves can self-organize spiking network architecture to perform unsupervised learning, and networks can be coupled with a linear classifier to perform classification on classic image datasets like MNIST. Broadly, our work shows that a dynamical systems framework for learning can be used to self-organize large computational devices.