 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Risk of Training Diagnostic Algorithms on Data with Demographic Bias
May 20, 2020

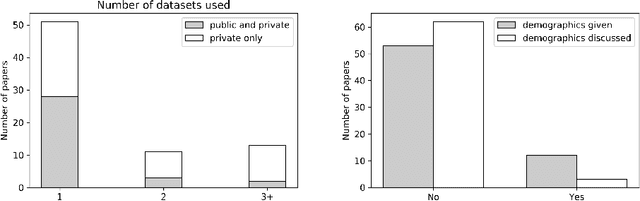
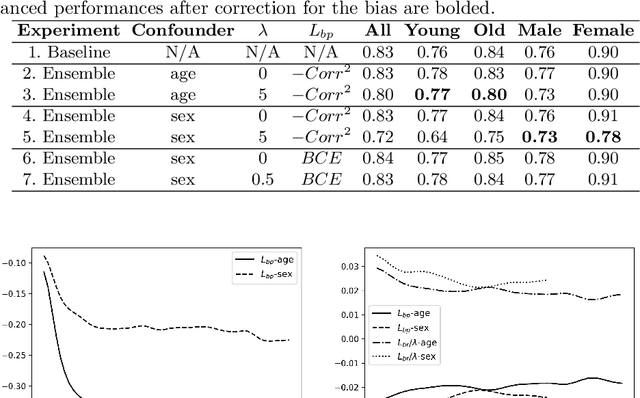
One of the critical challenges in machine learning applications is to have fair predictions. There are numerous recent examples in various domains that convincingly show that algorithms trained with biased datasets can easily lead to erroneous or discriminatory conclusions. This is even more crucial in clinical applications where the predictive algorithms are designed mainly based on a limited or given set of medical images and demographic variables such as age, sex and race are not taken into account. In this work, we conduct a survey of the MICCAI 2018 proceedings to investigate the common practice in medical image analysis applications. Surprisingly, we found that papers focusing on diagnosis rarely describe the demographics of the datasets used, and the diagnosis is purely based on images. In order to highlight the importance of considering the demographics in diagnosis tasks, we used a publicly available dataset of skin lesions. We then demonstrate that a classifier with an overall area under the curve (AUC) of 0.83 has variable performance between 0.76 and 0.91 on subgroups based on age and sex, even though the training set was relatively balanced. Moreover, we show that it is possible to learn unbiased features by explicitly using demographic variables in an adversarial training setup, which leads to balanced scores per subgroups. Finally, we discuss the implications of these results and provide recommendations for further research.
Using U-Nets to Create High-Fidelity Virtual Observations of the Solar Corona
Nov 10, 2019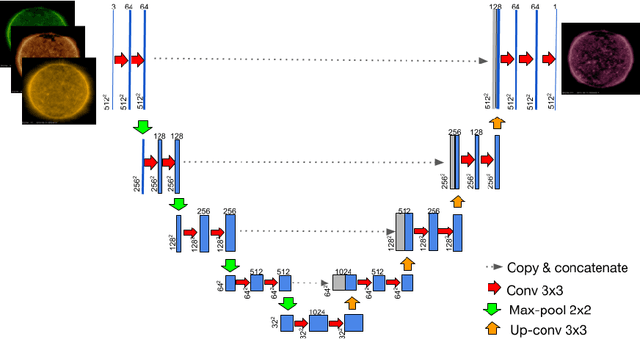

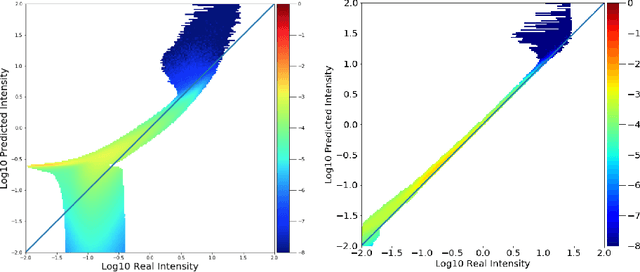
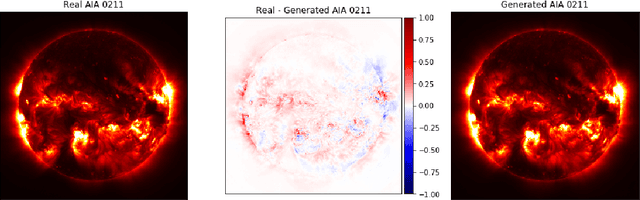
Understanding and monitoring the complex and dynamic processes of the Sun is important for a number of human activities on Earth and in space. For this reason, NASA's Solar Dynamics Observatory (SDO) has been continuously monitoring the multi-layered Sun's atmosphere in high-resolution since its launch in 2010, generating terabytes of observational data every day. The synergy between machine learning and this enormous amount of data has the potential, still largely unexploited, to advance our understanding of the Sun and extend the capabilities of heliophysics missions. In the present work, we show that deep learning applied to SDO data can be successfully used to create a high-fidelity virtual telescope that generates synthetic observations of the solar corona by image translation. Towards this end we developed a deep neural network, structured as an encoder-decoder with skip connections (U-Net), that reconstructs the Sun's image of one instrument channel given temporally aligned images in three other channels. The approach we present has the potential to reduce the telemetry needs of SDO, enhance the capabilities of missions that have less observing channels, and transform the concept development of future missions.
Application of a Convolutional Neural Network for image classification to the analysis of collisions in High Energy Physics
Aug 23, 2017
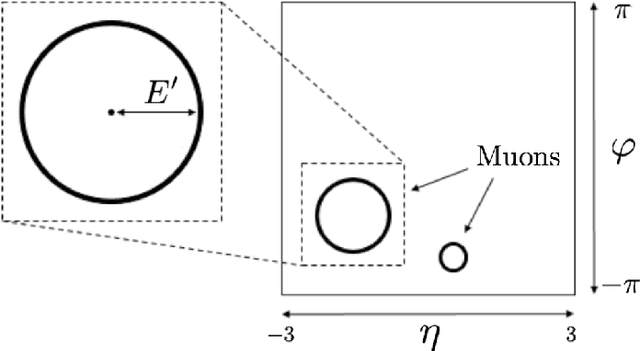
The application of deep learning techniques using convolutional neural networks to the classification of particle collisions in High Energy Physics is explored. An intuitive approach to transform physical variables, like momenta of particles and jets, into a single image that captures the relevant information, is proposed. The idea is tested using a well known deep learning framework on a simulation dataset, including leptonic ttbar events and the corresponding background at 7 TeV from the CMS experiment at LHC, available as Open Data. This initial test shows competitive results when compared to more classical approaches, like those using feedforward neural networks.
Render4Completion: Synthesizing Multi-view Depth Maps for 3D Shape Completion
May 24, 2019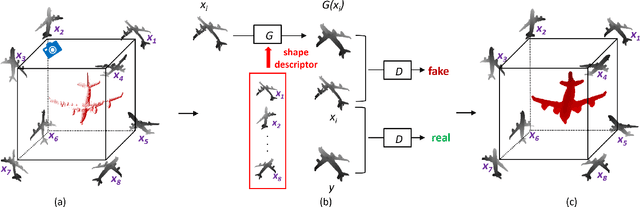

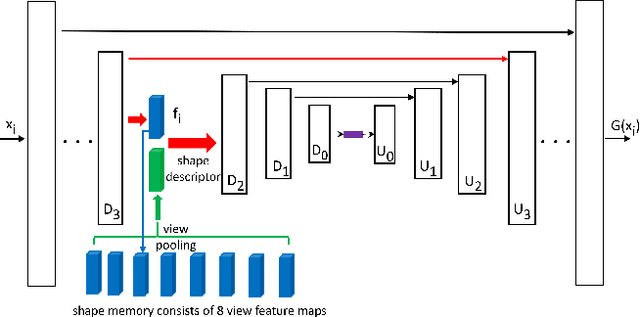

We propose a novel approach for 3D shape completion by synthesizing multi-view depth maps. While previous work for shape completion relies on volumetric representations, meshes, or point clouds, we propose to use multi-view depth maps from a set of fixed viewing angles as our shape representation. This allows us to be free of the limitations of memory for volumetric representations and point clouds by casting shape completion into an image-to-image translation problem. Specifically, we render depth maps of the incomplete shape from a fixed set of viewpoints, and perform depth map completion in each view. Different from image-to-image translation network that completes each view separately, our novel network, multi-view completion net (MVCN), leverages information from all views of a 3D shape to help the completion of each single view. This enables MVCN to leverage more information from different depth views to achieve high accuracy in single depth view completion and keep the consistency among the completed depth images in different views. Benefited by the multi-view representation and the novel network structure, MVCN significantly improves the accuracy of 3D shape completion in large-scale benchmarks compared to the state of the art.
LayoutVAE: Stochastic Scene Layout Generation From a Label Set
Aug 13, 2019
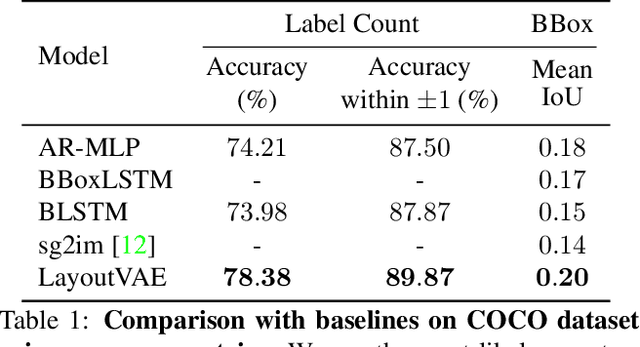
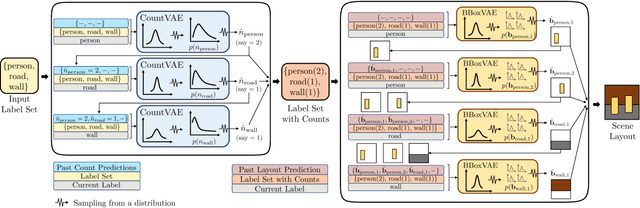
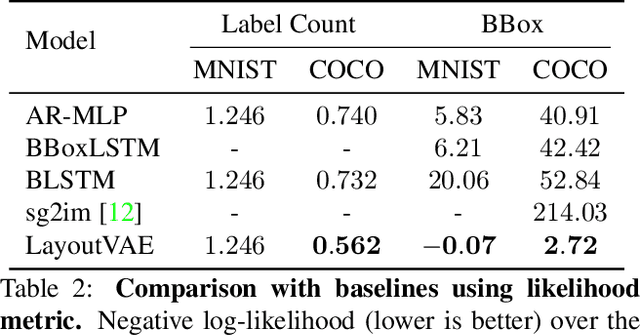
Recently there is an increasing interest in scene generation within the research community. However, models used for generating scene layouts from textual description largely ignore plausible visual variations within the structure dictated by the text. We propose LayoutVAE, a variational autoencoder based framework for generating stochastic scene layouts. LayoutVAE is a versatile modeling framework that allows for generating full image layouts given a label set, or per label layouts for an existing image given a new label. In addition, it is also capable of detecting unusual layouts, potentially providing a way to evaluate layout generation problem. Extensive experiments on MNIST-Layouts and challenging COCO 2017 Panoptic dataset verifies the effectiveness of our proposed framework.
Needles in Haystacks: On Classifying Tiny Objects in Large Images
Aug 16, 2019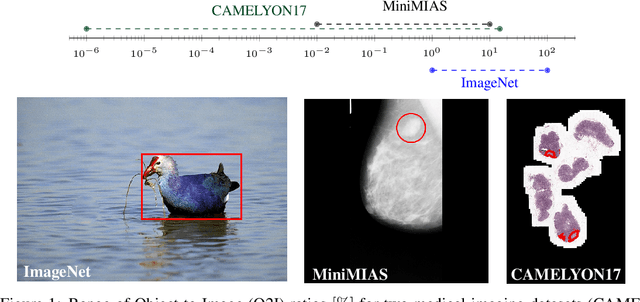
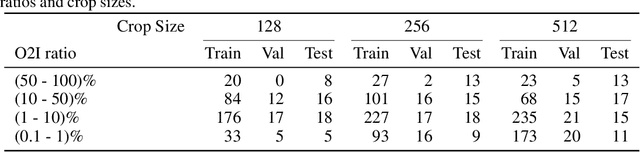
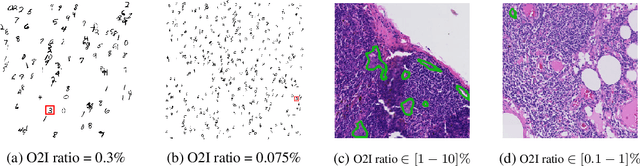
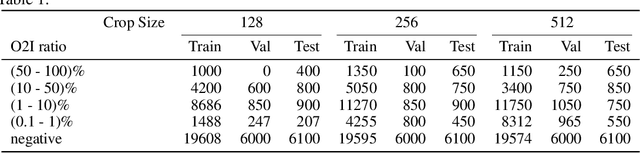
In some computer vision domains, such as medical or hyperspectral imaging, we care about the classification of tiny objects in large images. However, most Convolutional Neural Networks (CNNs) for image classification were developed and analyzed using biased datasets that contain large objects, most often, in central image positions. To assess whether classical CNN architectures work well for tiny object classification we build a comprehensive testbed containing two datasets: one derived from MNIST digits and other from histopathology images. This testbed allows us to perform controlled experiments to stress-test CNN architectures using a broad spectrum of signal-to-noise ratios. Our observations suggest that: (1) There exists a limit to signal-to-noise below which CNNs fail to generalize and that this limit is affected by dataset size - more data leading to better performances; however, the amount of training data required for the model to generalize scales rapidly with the inverse of the object-to-image ratio (2) in general, higher capacity models exhibit better generalization; (3) when knowing the approximate object sizes, adapting receptive field is beneficial; and (4) for very small signal-to-noise ratio the choice of global pooling operation affects optimization, whereas for relatively large signal-to-noise values, all tested global pooling operations exhibit similar performance.
Deep Metric Learning Beyond Binary Supervision
Apr 21, 2019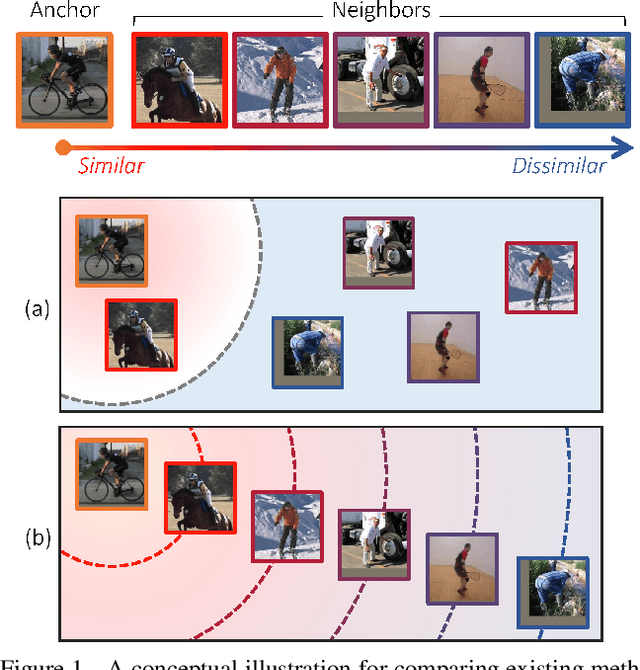
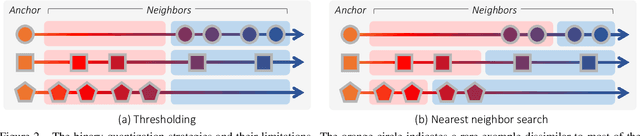
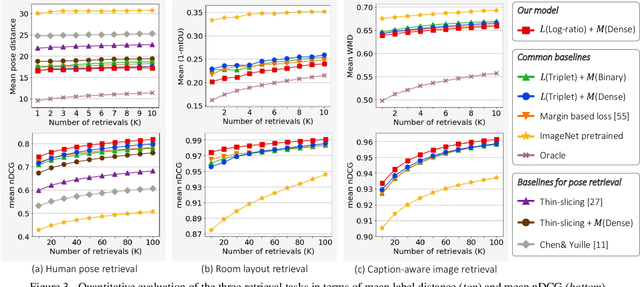
Metric Learning for visual similarity has mostly adopted binary supervision indicating whether a pair of images are of the same class or not. Such a binary indicator covers only a limited subset of image relations, and is not sufficient to represent semantic similarity between images described by continuous and/or structured labels such as object poses, image captions, and scene graphs. Motivated by this, we present a novel method for deep metric learning using continuous labels. First, we propose a new triplet loss that allows distance ratios in the label space to be preserved in the learned metric space. The proposed loss thus enables our model to learn the degree of similarity rather than just the order. Furthermore, we design a triplet mining strategy adapted to metric learning with continuous labels. We address three different image retrieval tasks with continuous labels in terms of human poses, room layouts and image captions, and demonstrate the superior performance of our approach compared to previous methods.
Illumination-based Transformations Improve Skin Lesion Segmentation in Dermoscopic Images
Mar 23, 2020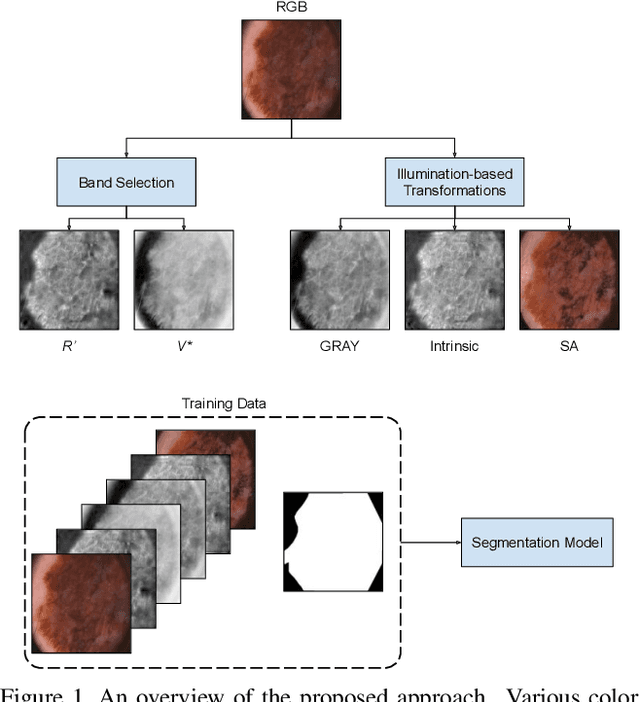
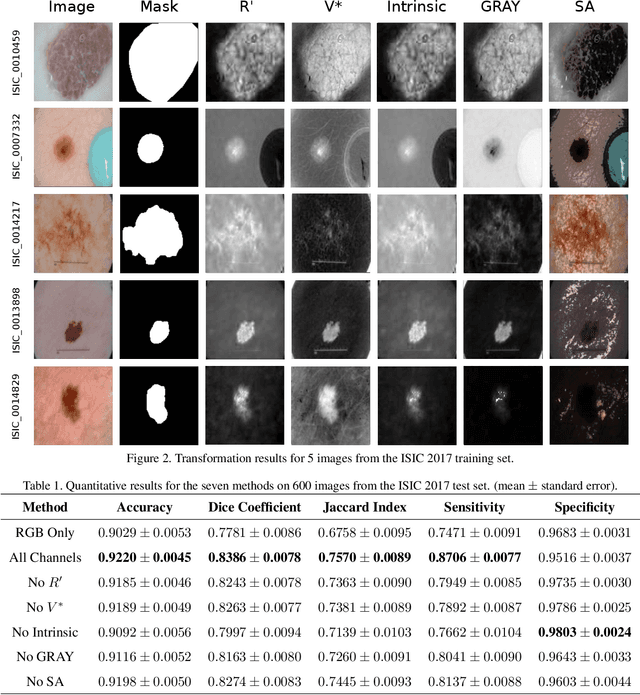

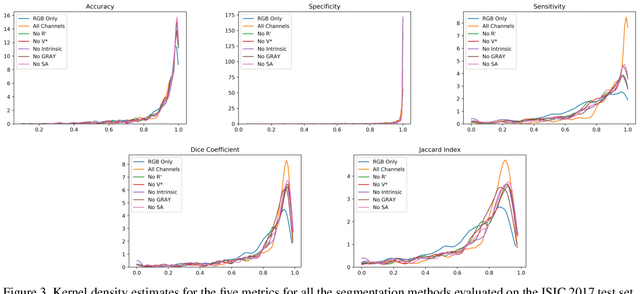
The semantic segmentation of skin lesions is an important and common initial task in the computer aided diagnosis of dermoscopic images. Although deep learning-based approaches have considerably improved the segmentation accuracy, there is still room for improvement by addressing the major challenges, such as variations in lesion shape, size, color and varying levels of contrast. In this work, we propose the first deep semantic segmentation framework for dermoscopic images which incorporates, along with the original RGB images, information extracted using the physics of skin illumination and imaging. In particular, we incorporate information from specific color bands, illumination invariant grayscale images, and shading-attenuated images. We evaluate our method on three datasets: the ISBI ISIC 2017 Skin Lesion Segmentation Challenge dataset, the DermoFit Image Library, and the PH2 dataset and observe improvements of 12.02%, 4.30%, and 8.86% respectively in the mean Jaccard index over a baseline model trained only with RGB images.
Semi-supervised Disentanglement with Independent Vector Variational Autoencoders
Mar 14, 2020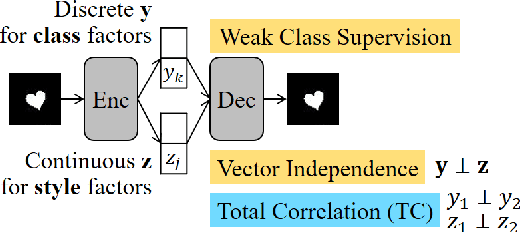
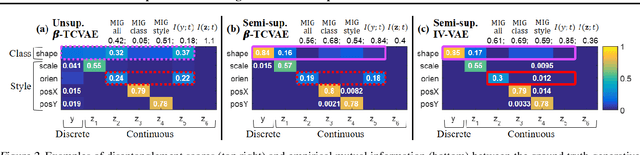

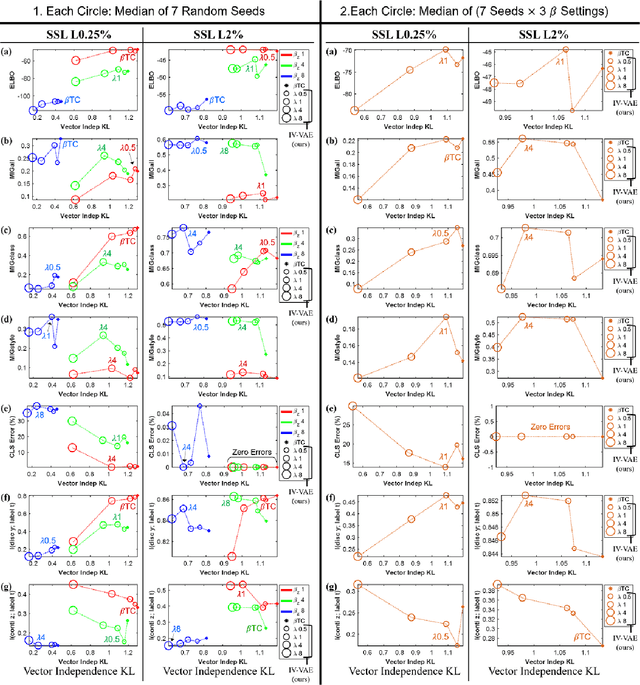
We aim to separate the generative factors of data into two latent vectors in a variational autoencoder. One vector captures class factors relevant to target classification tasks, while the other vector captures style factors relevant to the remaining information. To learn the discrete class features, we introduce supervision using a small amount of labeled data, which can simply yet effectively reduce the effort required for hyperparameter tuning performed in existing unsupervised methods. Furthermore, we introduce a learning objective to encourage statistical independence between the vectors. We show that (i) this vector independence term exists within the result obtained on decomposing the evidence lower bound with multiple latent vectors, and (ii) encouraging such independence along with reducing the total correlation within the vectors enhances disentanglement performance. Experiments conducted on several image datasets demonstrate that the disentanglement achieved via our method can improve classification performance and generation controllability.
Adversarial Machine Learning in Network Intrusion Detection Systems
Apr 23, 2020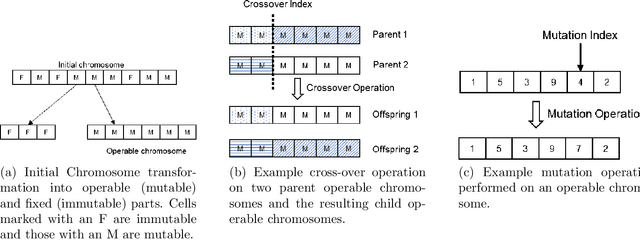
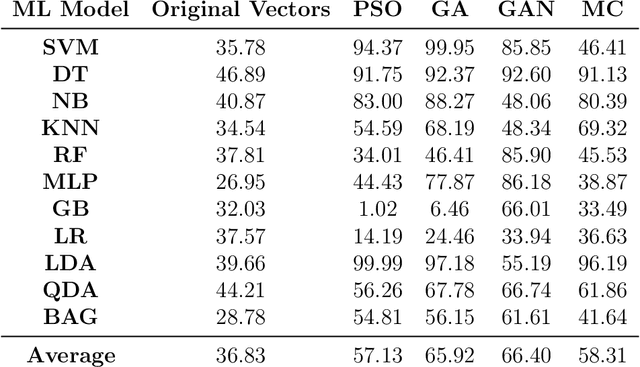
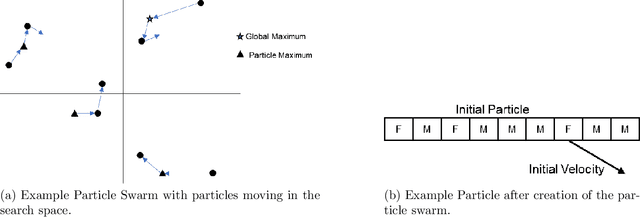
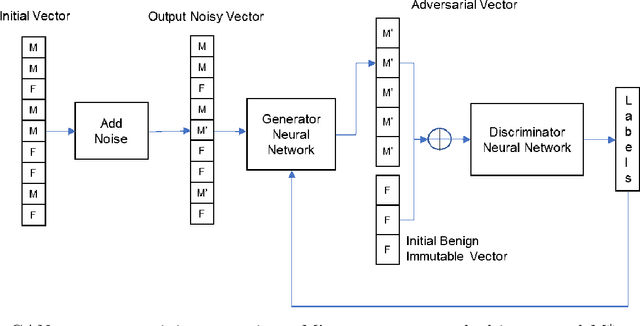
Adversarial examples are inputs to a machine learning system intentionally crafted by an attacker to fool the model into producing an incorrect output. These examples have achieved a great deal of success in several domains such as image recognition, speech recognition and spam detection. In this paper, we study the nature of the adversarial problem in Network Intrusion Detection Systems (NIDS). We focus on the attack perspective, which includes techniques to generate adversarial examples capable of evading a variety of machine learning models. More specifically, we explore the use of evolutionary computation (particle swarm optimization and genetic algorithm) and deep learning (generative adversarial networks) as tools for adversarial example generation. To assess the performance of these algorithms in evading a NIDS, we apply them to two publicly available data sets, namely the NSL-KDD and UNSW-NB15, and we contrast them to a baseline perturbation method: Monte Carlo simulation. The results show that our adversarial example generation techniques cause high misclassification rates in eleven different machine learning models, along with a voting classifier. Our work highlights the vulnerability of machine learning based NIDS in the face of adversarial perturbation.