 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Screen Content Image Segmentation Using Least Absolute Deviation Fitting
Feb 19, 2015
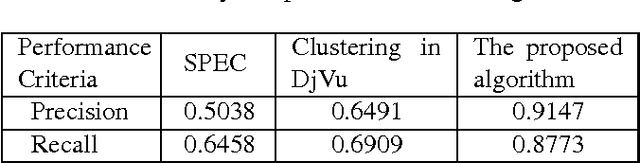

We propose an algorithm for separating the foreground (mainly text and line graphics) from the smoothly varying background in screen content images. The proposed method is designed based on the assumption that the background part of the image is smoothly varying and can be represented by a linear combination of a few smoothly varying basis functions, while the foreground text and graphics create sharp discontinuity and cannot be modeled by this smooth representation. The algorithm separates the background and foreground using a least absolute deviation method to fit the smooth model to the image pixels. This algorithm has been tested on several images from HEVC standard test sequences for screen content coding, and is shown to have superior performance over other popular methods, such as k-means clustering based segmentation in DjVu and shape primitive extraction and coding (SPEC) algorithm. Such background/foreground segmentation are important pre-processing steps for text extraction and separate coding of background and foreground for compression of screen content images.
Mono-SF: Multi-View Geometry Meets Single-View Depth for Monocular Scene Flow Estimation of Dynamic Traffic Scenes
Aug 17, 2019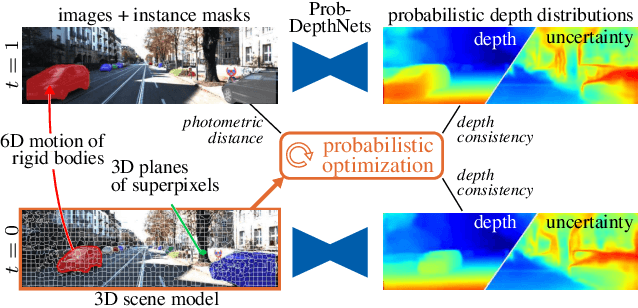
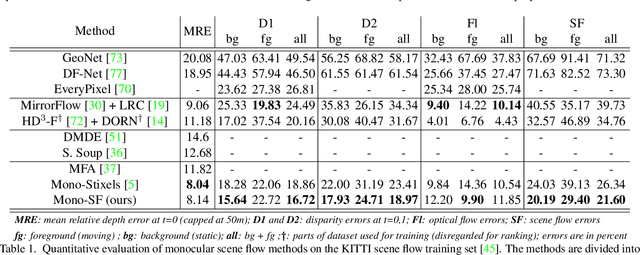
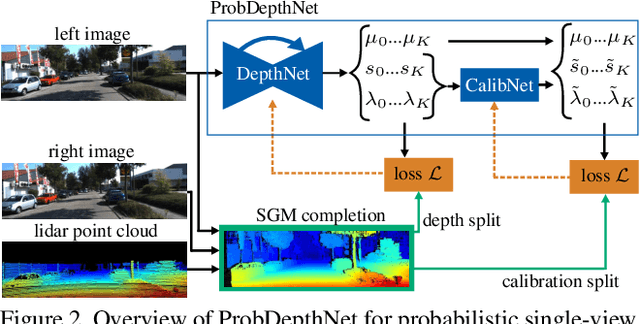
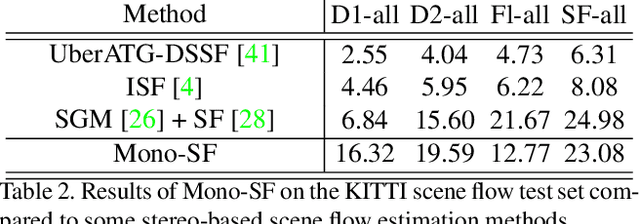
Existing 3D scene flow estimation methods provide the 3D geometry and 3D motion of a scene and gain a lot of interest, for example in the context of autonomous driving. These methods are traditionally based on a temporal series of stereo images. In this paper, we propose a novel monocular 3D scene flow estimation method, called Mono-SF. Mono-SF jointly estimates the 3D structure and motion of the scene by combining multi-view geometry and single-view depth information. Mono-SF considers that the scene flow should be consistent in terms of warping the reference image in the consecutive image based on the principles of multi-view geometry. For integrating single-view depth in a statistical manner, a convolutional neural network, called ProbDepthNet, is proposed. ProbDepthNet estimates pixel-wise depth distributions from a single image rather than single depth values. Additionally, as part of ProbDepthNet, a novel recalibration technique for regression problems is proposed to ensure well-calibrated distributions. Our experiments show that Mono-SF outperforms state-of-the-art monocular baselines and ablation studies support the Mono-SF approach and ProbDepthNet design.
AGAN: Towards Automated Design of Generative Adversarial Networks
Jun 25, 2019
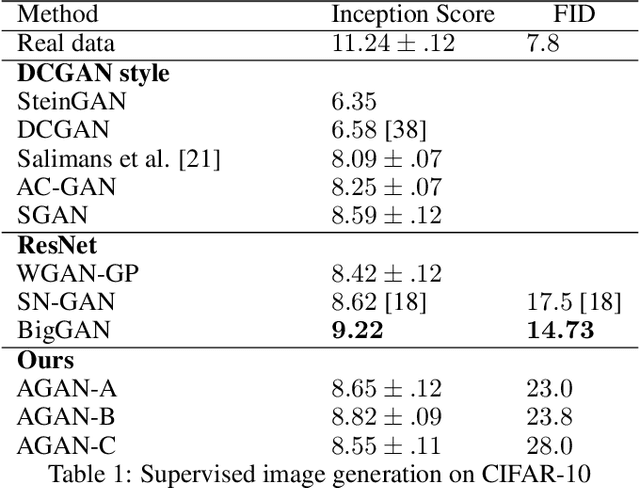
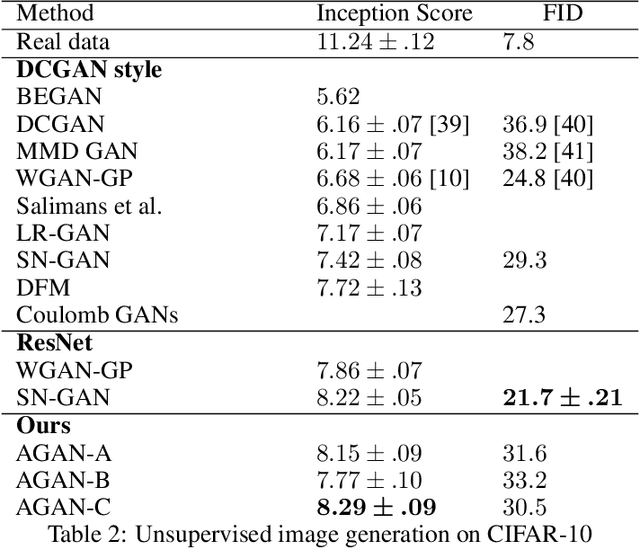
Recent progress in Generative Adversarial Networks (GANs) has shown promising signs of improving GAN training via architectural change. Despite some early success, at present the design of GAN architectures requires human expertise, laborious trial-and-error testings, and often draws inspiration from its image classification counterpart. In the current paper, we present the first neural architecture search algorithm, automated neural architecture search for deep generative models, or AGAN for abbreviation, that is specifically suited for GAN training. For unsupervised image generation tasks on CIFAR-10, our algorithm finds architecture that outperforms state-of-the-art models under same regularization techniques. For supervised tasks, the automatically searched architectures also achieve highly competitive performance, outperforming best human-invented architectures at resolution $32\times32$. Moreover, we empirically demonstrate that the modules learned by AGAN are transferable to other image generation tasks such as STL-10.
Artificial Intelligence for Diagnosis of Skin Cancer: Challenges and Opportunities
Nov 26, 2019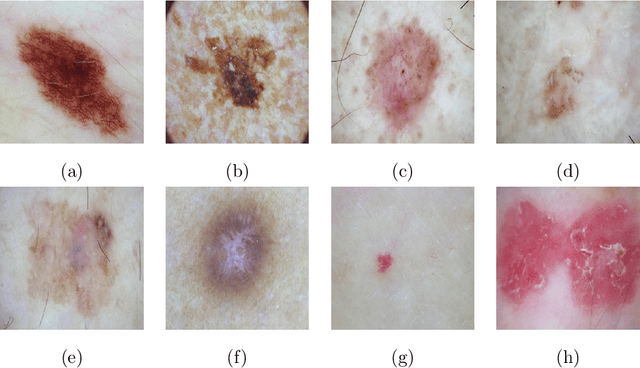
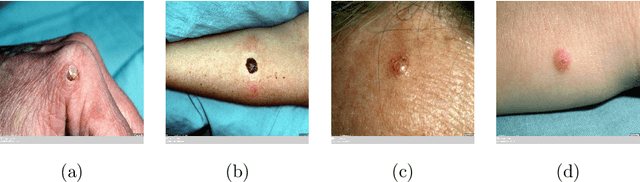
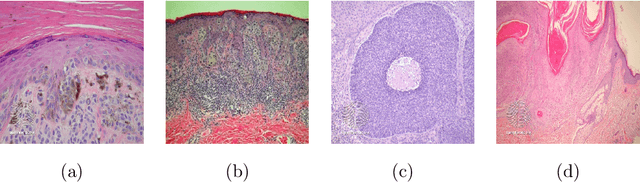
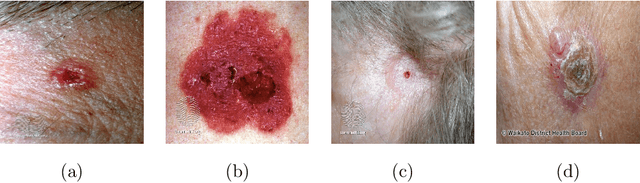
Recently, there has been great interest in developing Artificial Intelligence (AI) enabled computer-aided diagnostics solutions for the diagnosis of skin cancer. With the increasing incidence of skin cancers, low awareness among a growing population, and a lack of adequate clinical expertise and services, there is an immediate need for AI systems to assist clinicians in this domain. A large number of skin lesion datasets are available publicly, and researchers have developed AI solutions, particularly deep learning algorithms, to distinguish malignant skin lesions from benign lesions in different image modalities such as dermoscopic, clinical, and histopathology images. Despite the various claims of AI systems achieving higher accuracy than dermatologists in the classification of different skin lesions, these AI systems are still in the very early stages of clinical application in terms of being ready to aid clinicians in the diagnosis of skin cancers. In this review, we discuss advancements in the digital image-based AI solutions for the diagnosis of skin cancer, along with some challenges and future opportunities to improve these AI systems to support dermatologists and enhance their ability to diagnose skin cancer.
Bridging the Gap Between $f$-GANs and Wasserstein GANs
Oct 22, 2019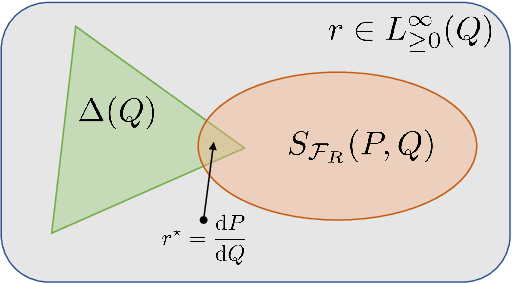

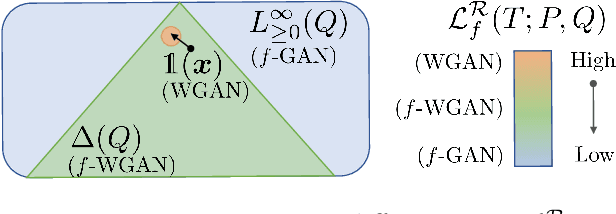
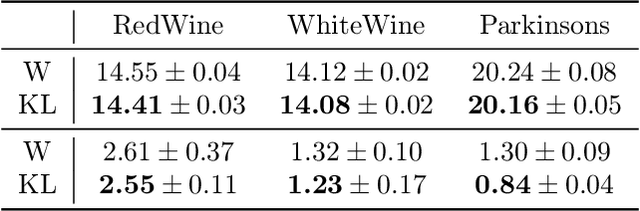
Generative adversarial networks (GANs) have enjoyed much success in learning high-dimensional distributions. Learning objectives approximately minimize an $f$-divergence ($f$-GANs) or an integral probability metric (Wasserstein GANs) between the model and the data distribution using a discriminator. Wasserstein GANs enjoy superior empirical performance, but in $f$-GANs the discriminator can be interpreted as a density ratio estimator which is necessary in some GAN applications. In this paper, we bridge the gap between $f$-GANs and Wasserstein GANs (WGANs). First, we list two constraints over variational $f$-divergence estimation objectives that preserves the optimal solution. Next, we minimize over a Lagrangian relaxation of the constrained objective, and show that it generalizes critic objectives of both $f$-GAN and WGAN. Based on this generalization, we propose a novel practical objective, named KL-Wasserstein GAN (KL-WGAN). We demonstrate empirical success of KL-WGAN on synthetic datasets and real-world image generation benchmarks, and achieve state-of-the-art FID scores on CIFAR10 image generation.
All-In-One Underwater Image Enhancement using Domain-Adversarial Learning
May 30, 2019
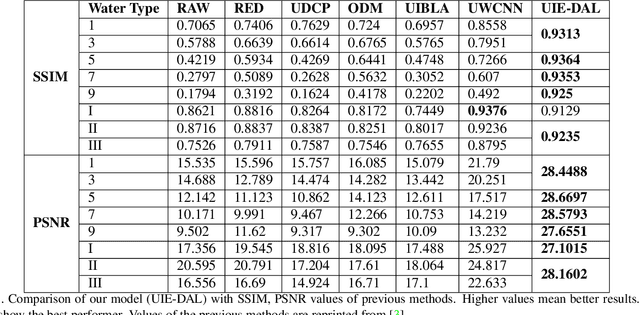
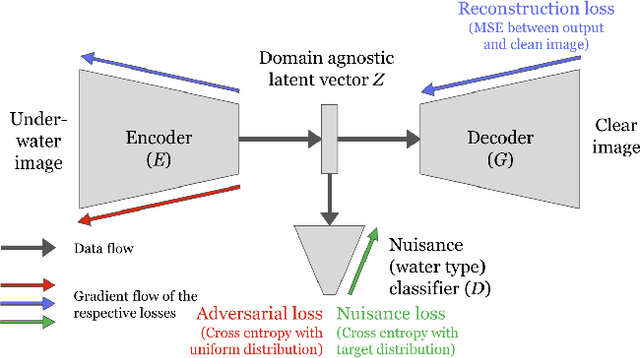
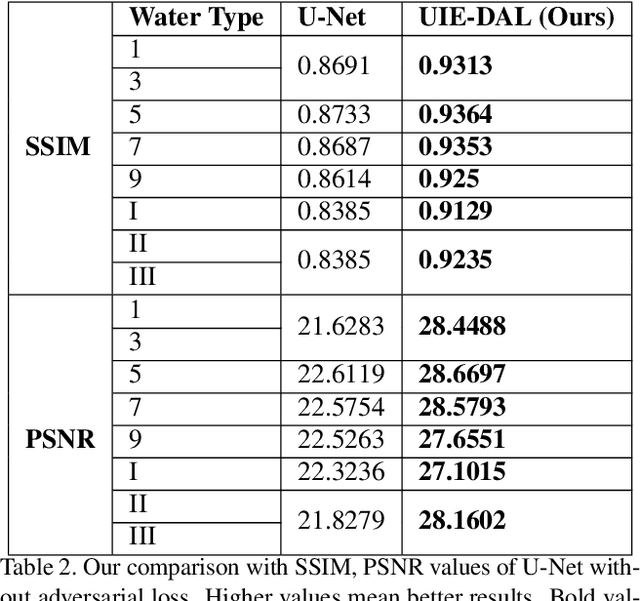
Raw underwater images are degraded due to wavelength dependent light attenuation and scattering, limiting their applicability in vision systems. Another factor that makes enhancing underwater images particularly challenging is the diversity of the water types in which they are captured. For example, images captured in deep oceanic waters have a different distribution from those captured in shallow coastal waters. Such diversity makes it hard to train a single model to enhance underwater images. In this work, we propose a novel model which nicely handles the diversity of water during the enhancement, by adversarially learning the content features of the images by disentangling the unwanted nuisances corresponding to water types (viewed as different domains). We use the learned domain agnostic features to generate enhanced underwater images. We train our model on a dataset consisting images of 10 Jerlov water types. Experimental results show that the proposed model not only outperforms the previous methods in SSIM and PSNR scores for almost all Jerlov water types but also generalizes well on real-world datasets. The performance of a high-level vision task (object detection) also shows improvement using enhanced images with our model.
A Novel Technique of Noninvasive Hemoglobin Level Measurement Using HSV Value of Fingertip Image
Oct 07, 2019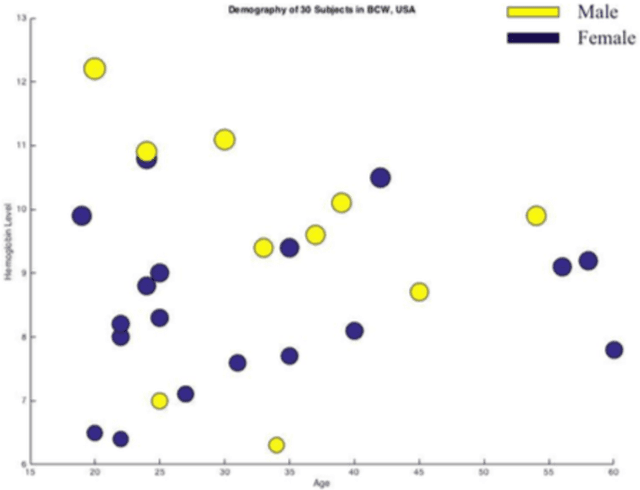
Over the last decade, smartphones have changed radically to support us with mHealth technology, cloud computing, and machine learning algorithm. Having its multifaceted facilities, we present a novel smartphone-based noninvasive hemoglobin (Hb) level prediction model by analyzing hue, saturation and value (HSV) of a fingertip video. Here, we collect 60 videos of 60 subjects from two different locations: Blood Center of Wisconsin, USA and AmaderGram, Bangladesh. We extract red, green, and blue (RGB) pixel intensities of selected images of those videos captured by the smartphone camera with flash on. Then we convert RGB values of selected video frames of a fingertip video into HSV color space and we generate histogram values of these HSV pixel intensities. We average these histogram values of a fingertip video and consider as an observation against the gold standard Hb concentration. We generate two input feature matrices based on observation of two different data sets. Partial Least Squares (PLS) algorithm is applied on the input feature matrix. We observe R2=0.95 in both data sets through our research. We analyze our data using Python OpenCV, Matlab, and R statistics tool.
Skin Segmentation from NIR Images using Unsupervised Domain Adaptation through Generative Latent Search
Jun 15, 2020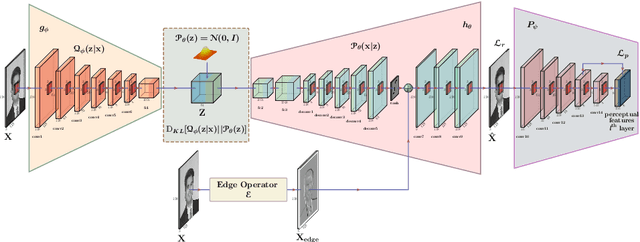
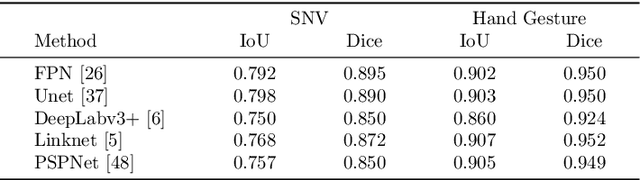

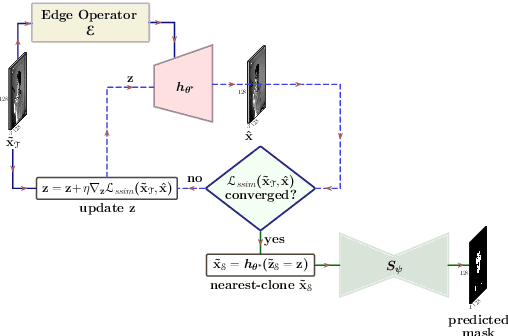
Segmentation of the pixels corresponding to human skin is an essential first step in multiple applications ranging from surveillance to heart-rate estimation from remote-photoplethysmography. However, the existing literature considers the problem only in the visible-range of the EM-spectrum which limits their utility in low or no light settings where the criticality of the application is higher. To alleviate this problem, we consider the problem of skin segmentation from the Near-infrared images. However, Deep learning based state-of-the-art segmentation techniques demands large amounts of labelled data that is unavailable for the current problem. Therefore we cast the skin segmentation problem as that of target-independent unsupervised domain adaptation (UDA) where we use the data from the Red-channel of the visible-range to develop skin segmentation algorithm on NIR images. We propose a method for target-independent segmentation where the 'nearest-clone' of a target image in the source domain is searched and used as a proxy in the segmentation network trained only on the source domain. We prove the existence of 'nearest-clone' and propose a method to find it through an optimization algorithm over the latent space of a Deep generative model based on variational inference. We demonstrate the efficacy of the proposed method for NIR skin segmentation over the state-of-the-art UDA segmenation methods on the two newly created skin segmentation datasets in NIR domain despite not having access to the target NIR data.
Event Based, Near Eye Gaze Tracking Beyond 10,000Hz
Apr 07, 2020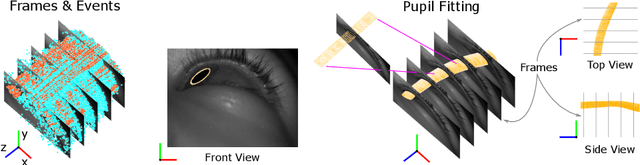
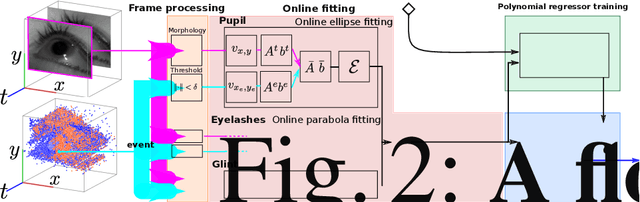
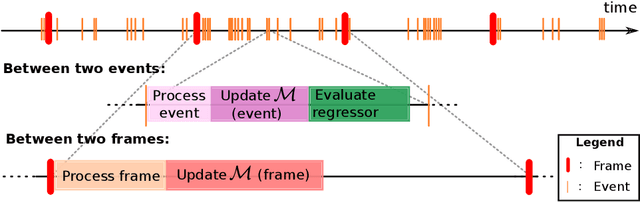

Fast and accurate eye tracking is crucial for many applications. Current camera-based eye tracking systems, however, are fundamentally limited by their bandwidth, forcing a tradeoff between image resolution and framerate, i.e. between latency and update rate. Here, we propose a hybrid frame-event-based near-eye gaze tracking system offering update rates beyond 10,000 Hz with an accuracy that matches that of high-end desktop-mounted commercial eye trackers when evaluated in the same conditions. Our system builds on emerging event cameras that simultaneously acquire regularly sampled frames and adaptively sampled events. We develop an online 2D pupil fitting method that updates a parametric model every one or few events. Moreover, we propose a polynomial regressor for estimating the gaze vector from the parametric pupil model in real time. Using the first hybrid frame-event gaze dataset, which will be made public, we demonstrate that our system achieves accuracies of 0.45 degrees -- 1.75 degrees for fields of view ranging from 45 degrees to 98 degrees.
Cascaded Recurrent Neural Networks for Hyperspectral Image Classification
Feb 28, 2019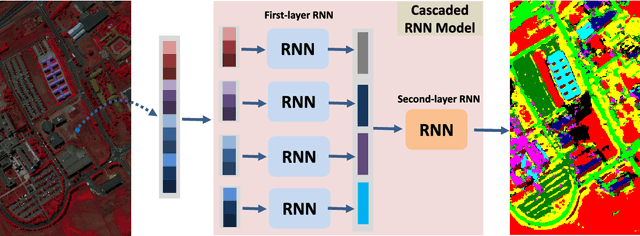
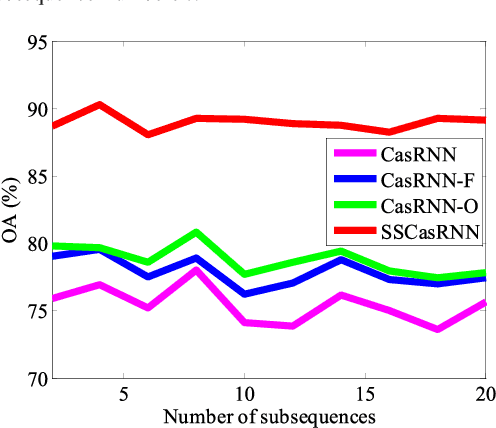
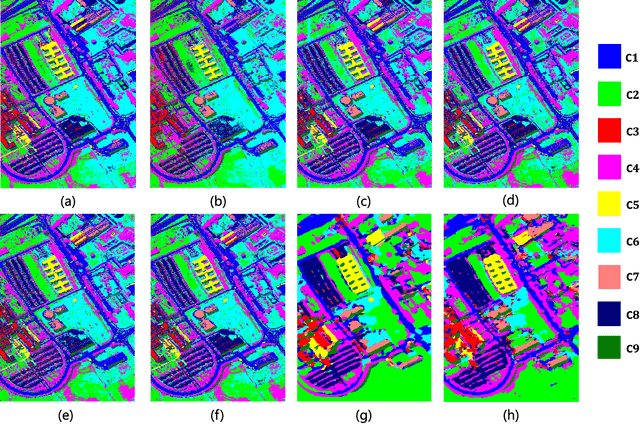
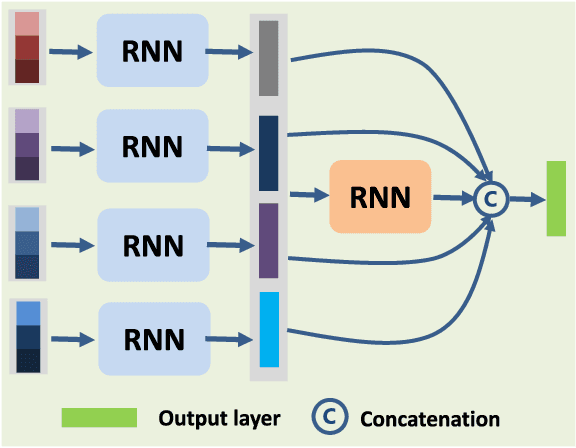
By considering the spectral signature as a sequence, recurrent neural networks (RNNs) have been successfully used to learn discriminative features from hyperspectral images (HSIs) recently. However, most of these models only input the whole spectral bands into RNNs directly, which may not fully explore the specific properties of HSIs. In this paper, we propose a cascaded RNN model using gated recurrent units (GRUs) to explore the redundant and complementary information of HSIs. It mainly consists of two RNN layers. The first RNN layer is used to eliminate redundant information between adjacent spectral bands, while the second RNN layer aims to learn the complementary information from non-adjacent spectral bands. To improve the discriminative ability of the learned features, we design two strategies for the proposed model. Besides, considering the rich spatial information contained in HSIs, we further extend the proposed model to its spectral-spatial counterpart by incorporating some convolutional layers. To test the effectiveness of our proposed models, we conduct experiments on two widely used HSIs. The experimental results show that our proposed models can achieve better results than the compared models.