 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PoseConvGRU: A Monocular Approach for Visual Ego-motion Estimation by Learning
Jun 19, 2019
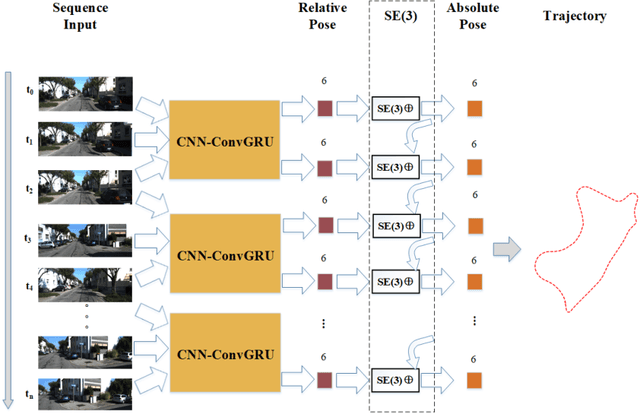
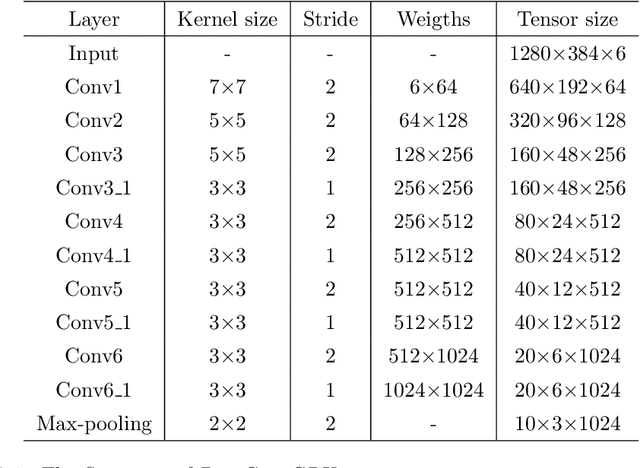
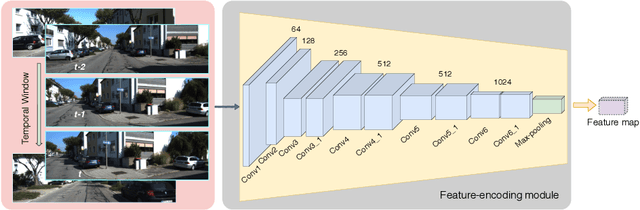
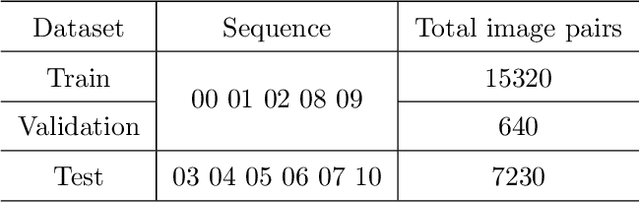
While many visual ego-motion algorithm variants have been proposed in the past decade, learning based ego-motion estimation methods have seen an increasing attention because of its desirable properties of robustness to image noise and camera calibration independence. In this work, we propose a data-driven approach of fully trainable visual ego-motion estimation for a monocular camera. We use an end-to-end learning approach in allowing the model to map directly from input image pairs to an estimate of ego-motion (parameterized as 6-DoF transformation matrices). We introduce a novel two-module Long-term Recurrent Convolutional Neural Networks called PoseConvGRU, with an explicit sequence pose estimation loss to achieve this. The feature-encoding module encodes the short-term motion feature in an image pair, while the memory-propagating module captures the long-term motion feature in the consecutive image pairs. The visual memory is implemented with convolutional gated recurrent units, which allows propagating information over time. At each time step, two consecutive RGB images are stacked together to form a 6 channels tensor for module-1 to learn how to extract motion information and estimate poses. The sequence of output maps is then passed through a stacked ConvGRU module to generate the relative transformation pose of each image pair. We also augment the training data by randomly skipping frames to simulate the velocity variation which results in a better performance in turning and high-velocity situations. We evaluate the performance of our proposed approach on the KITTI Visual Odometry benchmark. The experiments show a competitive performance of the proposed method to the geometric method and encourage further exploration of learning based methods for the purpose of estimating camera ego-motion even though geometrical methods demonstrate promising results.
A smartphone application to measure the quality of pest control spraying machines via image analysis
Dec 16, 2017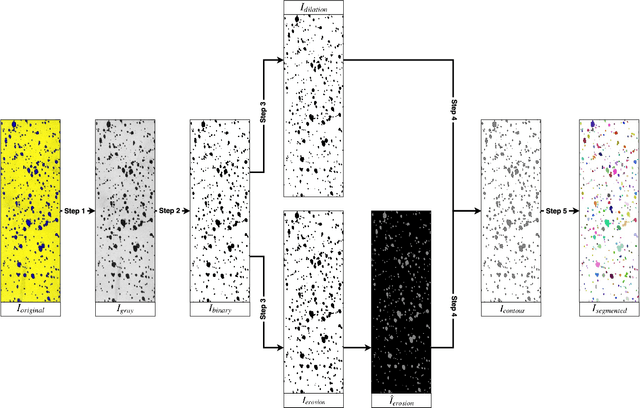

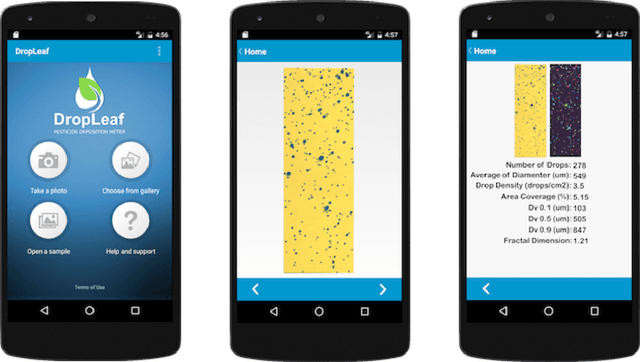
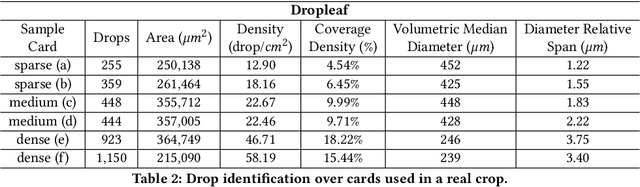
The need for higher agricultural productivity has demanded the intensive use of pesticides. However, their correct use depends on assessment methods that can accurately predict how well the pesticides' spraying covered the intended crop region. Some methods have been proposed in the literature, but their high cost and low portability harm their widespread use. This paper proposes and experimentally evaluates a new methodology based on the use of a smartphone-based mobile application, named DropLeaf. Experiments performed using DropLeaf showed that, in addition to its versatility, it can predict with high accuracy the pesticide spraying. DropLeaf is a five-fold image-processing methodology based on: (i) color space conversion, (ii) threshold noise removal, (iii) convolutional operations of dilation and erosion, (iv) detection of contour markers in the water-sensitive card, and, (v) identification of droplets via the marker-controlled watershed transformation. The authors performed successful experiments over two case studies, the first using a set of synthetic cards and the second using a real-world crop. The proposed tool can be broadly used by farmers equipped with conventional mobile phones, improving the use of pesticides with health, environmental and financial benefits.
Monte Carlo non local means: Random sampling for large-scale image filtering
May 14, 2014



We propose a randomized version of the non-local means (NLM) algorithm for large-scale image filtering. The new algorithm, called Monte Carlo non-local means (MCNLM), speeds up the classical NLM by computing a small subset of image patch distances, which are randomly selected according to a designed sampling pattern. We make two contributions. First, we analyze the performance of the MCNLM algorithm and show that, for large images or large external image databases, the random outcomes of MCNLM are tightly concentrated around the deterministic full NLM result. In particular, our error probability bounds show that, at any given sampling ratio, the probability for MCNLM to have a large deviation from the original NLM solution decays exponentially as the size of the image or database grows. Second, we derive explicit formulas for optimal sampling patterns that minimize the error probability bound by exploiting partial knowledge of the pairwise similarity weights. Numerical experiments show that MCNLM is competitive with other state-of-the-art fast NLM algorithms for single-image denoising. When applied to denoising images using an external database containing ten billion patches, MCNLM returns a randomized solution that is within 0.2 dB of the full NLM solution while reducing the runtime by three orders of magnitude.
Render4Completion: Synthesizing Multi-view Depth Maps for 3D Shape Completion
May 24, 2019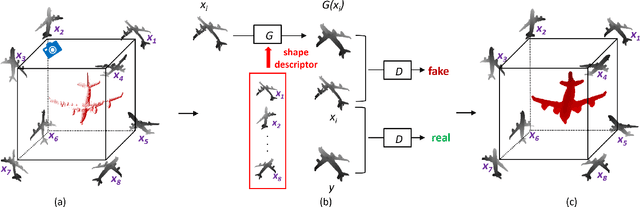

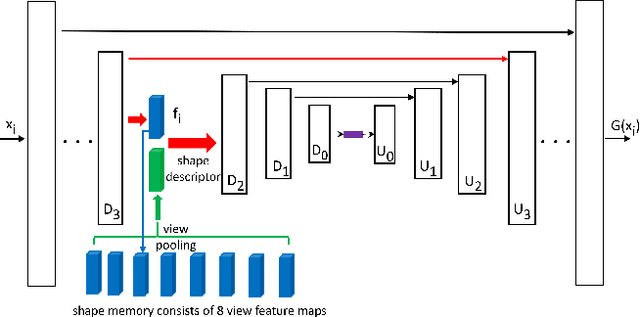

We propose a novel approach for 3D shape completion by synthesizing multi-view depth maps. While previous work for shape completion relies on volumetric representations, meshes, or point clouds, we propose to use multi-view depth maps from a set of fixed viewing angles as our shape representation. This allows us to be free of the limitations of memory for volumetric representations and point clouds by casting shape completion into an image-to-image translation problem. Specifically, we render depth maps of the incomplete shape from a fixed set of viewpoints, and perform depth map completion in each view. Different from image-to-image translation network that completes each view separately, our novel network, multi-view completion net (MVCN), leverages information from all views of a 3D shape to help the completion of each single view. This enables MVCN to leverage more information from different depth views to achieve high accuracy in single depth view completion and keep the consistency among the completed depth images in different views. Benefited by the multi-view representation and the novel network structure, MVCN significantly improves the accuracy of 3D shape completion in large-scale benchmarks compared to the state of the art.
Automated Deep Photo Style Transfer
Jan 12, 2019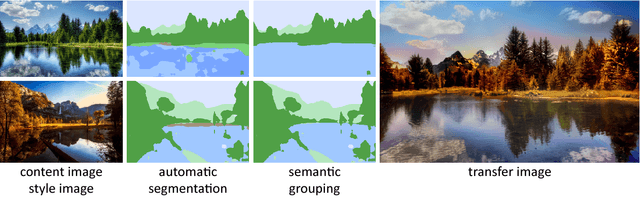

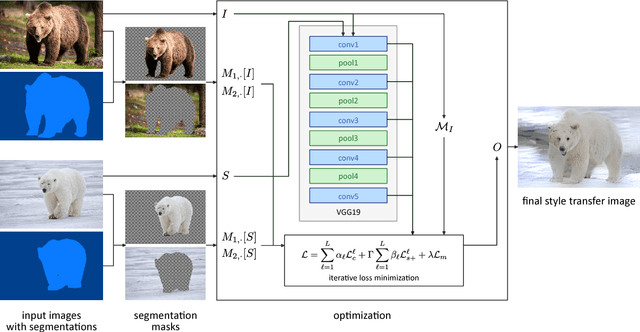

Photorealism is a complex concept that cannot easily be formulated mathematically. Deep Photo Style Transfer is an attempt to transfer the style of a reference image to a content image while preserving its photorealism. This is achieved by introducing a constraint that prevents distortions in the content image and by applying the style transfer independently for semantically different parts of the images. In addition, an automated segmentation process is presented that consists of a neural network based segmentation method followed by a semantic grouping step. To further improve the results a measure for image aesthetics is used and elaborated. If the content and the style image are sufficiently similar, the result images look very realistic. With the automation of the image segmentation the pipeline becomes completely independent from any user interaction, which allows for new applications.
The Visual Social Distancing Problem
May 11, 2020
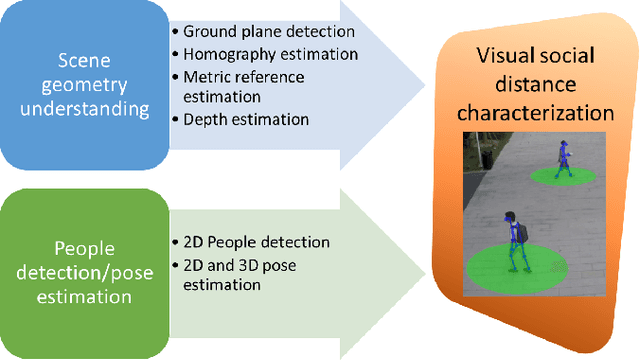
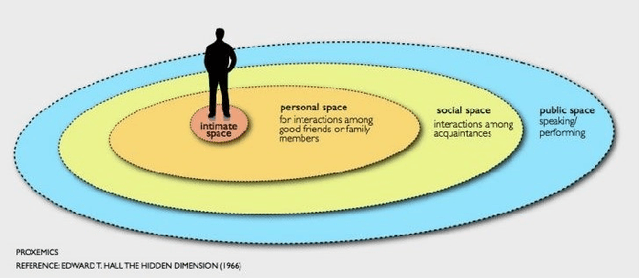
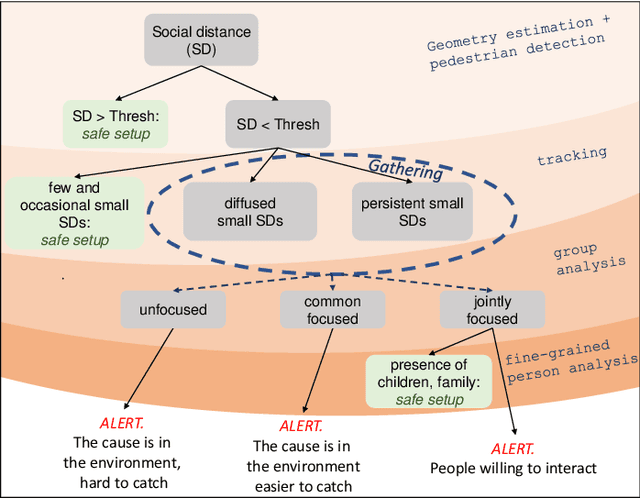
One of the main and most effective measures to contain the recent viral outbreak is the maintenance of the so-called Social Distancing (SD). To comply with this constraint, workplaces, public institutions, transports and schools will likely adopt restrictions over the minimum inter-personal distance between people. Given this actual scenario, it is crucial to massively measure the compliance to such physical constraint in our life, in order to figure out the reasons of the possible breaks of such distance limitations, and understand if this implies a possible threat given the scene context. All of this, complying with privacy policies and making the measurement acceptable. To this end, we introduce the Visual Social Distancing (VSD) problem, defined as the automatic estimation of the inter-personal distance from an image, and the characterization of the related people aggregations. VSD is pivotal for a non-invasive analysis to whether people comply with the SD restriction, and to provide statistics about the level of safety of specific areas whenever this constraint is violated. We then discuss how VSD relates with previous literature in Social Signal Processing and indicate which existing Computer Vision methods can be used to manage such problem. We conclude with future challenges related to the effectiveness of VSD systems, ethical implications and future application scenarios.
Sequential Interpretability: Methods, Applications, and Future Direction for Understanding Deep Learning Models in the Context of Sequential Data
Apr 27, 2020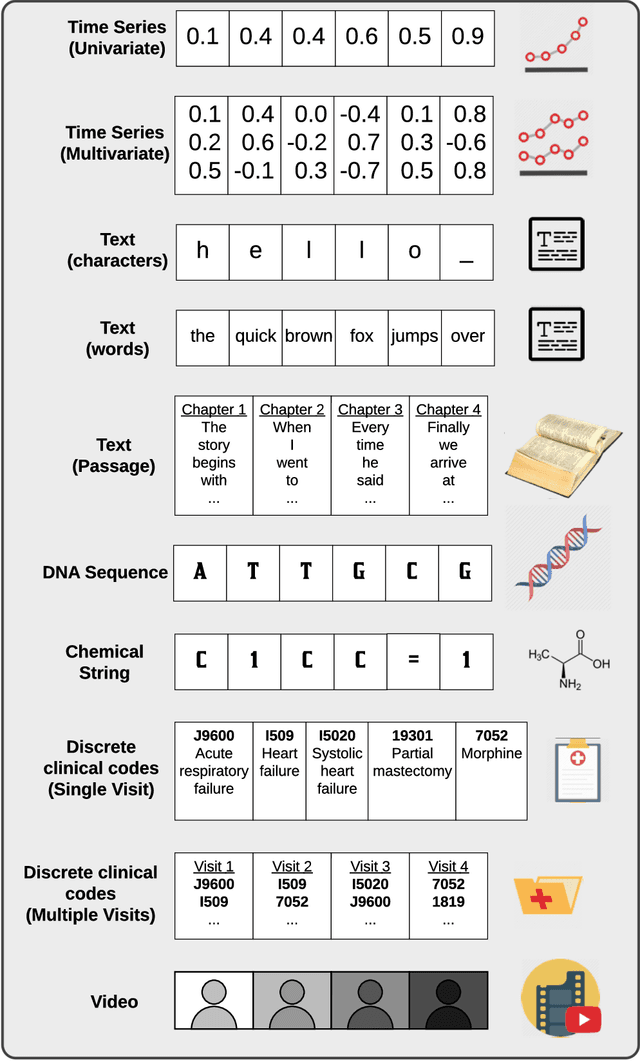
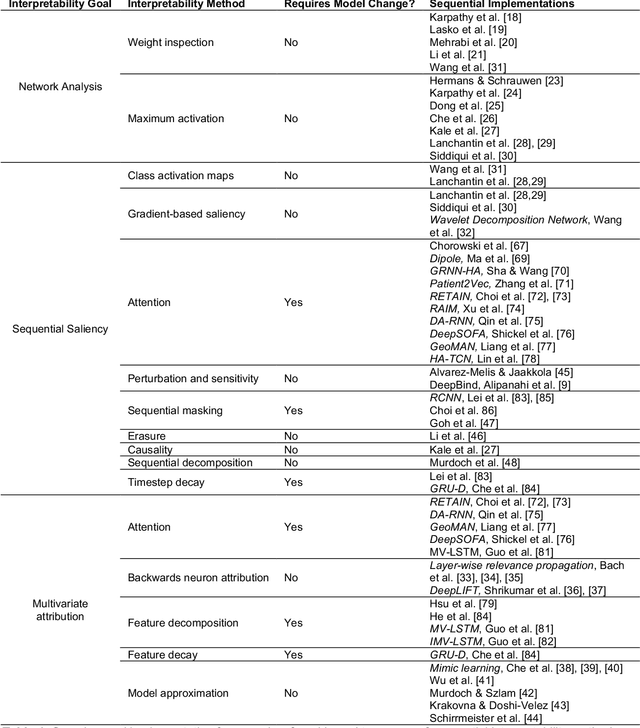
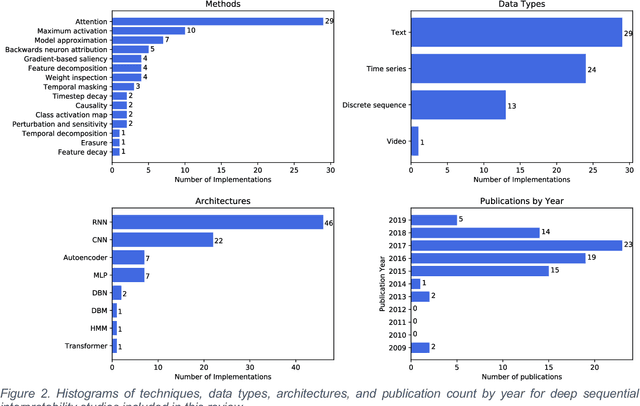
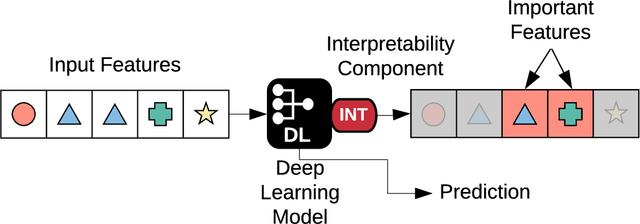
Deep learning continues to revolutionize an ever-growing number of critical application areas including healthcare, transportation, finance, and basic sciences. Despite their increased predictive power, model transparency and human explainability remain a significant challenge due to the "black box" nature of modern deep learning models. In many cases the desired balance between interpretability and performance is predominately task specific. Human-centric domains such as healthcare necessitate a renewed focus on understanding how and why these frameworks are arriving at critical and potentially life-or-death decisions. Given the quantity of research and empirical successes of deep learning for computer vision, most of the existing interpretability research has focused on image processing techniques. Comparatively, less attention has been paid to interpreting deep learning frameworks using sequential data. Given recent deep learning advancements in highly sequential domains such as natural language processing and physiological signal processing, the need for deep sequential explanations is at an all-time high. In this paper, we review current techniques for interpreting deep learning techniques involving sequential data, identify similarities to non-sequential methods, and discuss current limitations and future avenues of sequential interpretability research.
Embedding Compression with Isotropic Iterative Quantization
Jan 11, 2020
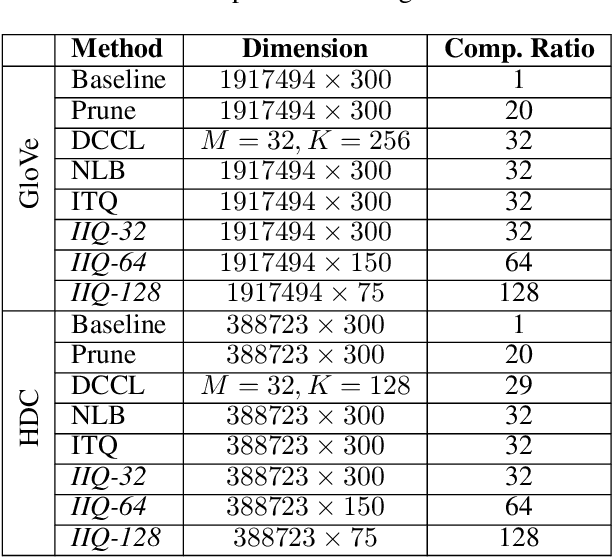
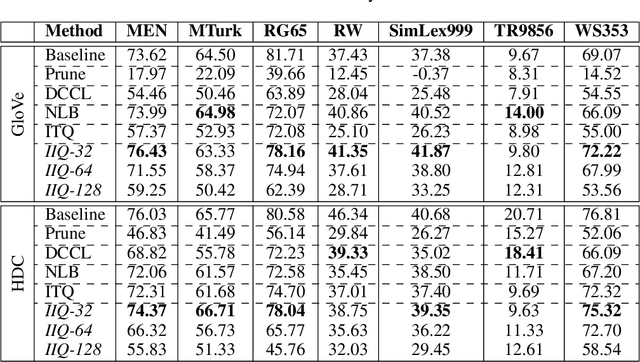
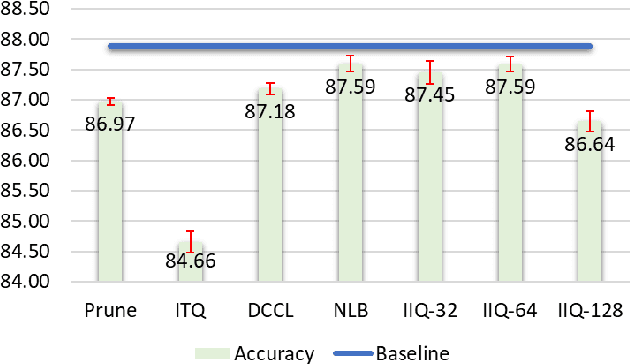
Continuous representation of words is a standard component in deep learning-based NLP models. However, representing a large vocabulary requires significant memory, which can cause problems, particularly on resource-constrained platforms. Therefore, in this paper we propose an isotropic iterative quantization (IIQ) approach for compressing embedding vectors into binary ones, leveraging the iterative quantization technique well established for image retrieval, while satisfying the desired isotropic property of PMI based models. Experiments with pre-trained embeddings (i.e., GloVe and HDC) demonstrate a more than thirty-fold compression ratio with comparable and sometimes even improved performance over the original real-valued embedding vectors.
A Light Dual-Task Neural Network for Haze Removal
Apr 12, 2019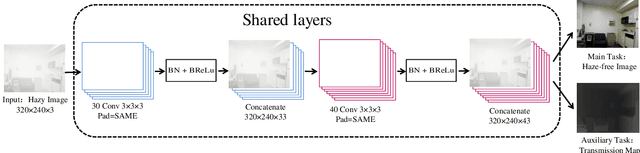
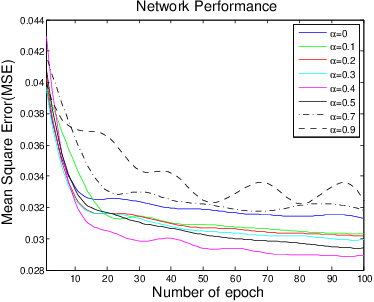


Single-image dehazing is a challenging problem due to its ill-posed nature. Existing methods rely on a suboptimal two-step approach, where an intermediate product like a depth map is estimated, based on which the haze-free image is subsequently generated using an artificial prior formula. In this paper, we propose a light dual-task Neural Network called LDTNet that restores the haze-free image in one shot. We use transmission map estimation as an auxiliary task to assist the main task, haze removal, in feature extraction and to enhance the generalization of the network. In LDTNet, the haze-free image and the transmission map are produced simultaneously. As a result, the artificial prior is reduced to the smallest extent. Extensive experiments demonstrate that our algorithm achieves superior performance against the state-of-the-art methods on both synthetic and real-world images.
* 6 pages, 4 figures
Image Decomposition and Classification through a Generative Model
Feb 09, 2019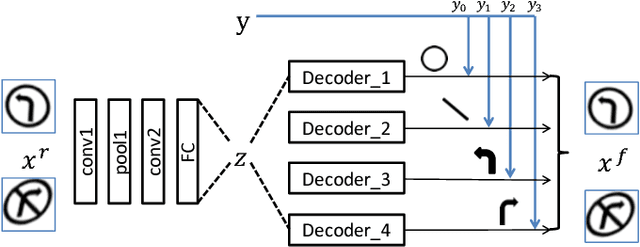
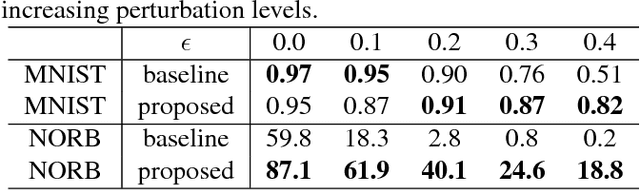
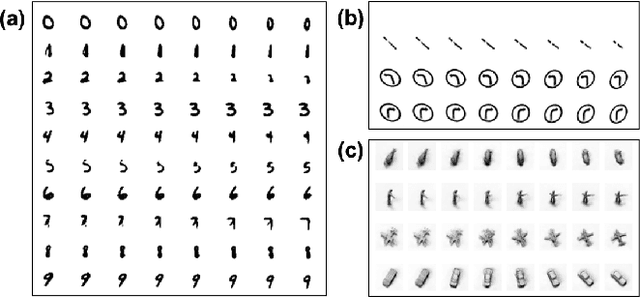
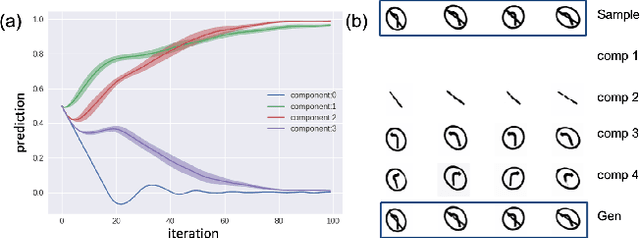
We demonstrate in this paper that a generative model can be designed to perform classification tasks under challenging settings, including adversarial attacks and input distribution shifts. Specifically, we propose a conditional variational autoencoder that learns both the decomposition of inputs and the distributions of the resulting components. During test, we jointly optimize the latent variables of the generator and the relaxed component labels to find the best match between the given input and the output of the generator. The model demonstrates promising performance at recognizing overlapping components from the multiMNIST dataset, and novel component combinations from a traffic sign dataset. Experiments also show that the proposed model achieves high robustness on MNIST and NORB datasets, in particular for high-strength gradient attacks and non-gradient attacks.