 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NeuroPrompts: An Adaptive Framework to Optimize Prompts for Text-to-Image Generation
Nov 20, 2023
Despite impressive recent advances in text-to-image diffusion models, obtaining high-quality images often requires prompt engineering by humans who have developed expertise in using them. In this work, we present NeuroPrompts, an adaptive framework that automatically enhances a user's prompt to improve the quality of generations produced by text-to-image models. Our framework utilizes constrained text decoding with a pre-trained language model that has been adapted to generate prompts similar to those produced by human prompt engineers. This approach enables higher-quality text-to-image generations and provides user control over stylistic features via constraint set specification. We demonstrate the utility of our framework by creating an interactive application for prompt enhancement and image generation using Stable Diffusion. Additionally, we conduct experiments utilizing a large dataset of human-engineered prompts for text-to-image generation and show that our approach automatically produces enhanced prompts that result in superior image quality. We make our code, a screencast video demo and a live demo instance of NeuroPrompts publicly available.
Uncertainty Estimation in Contrast-Enhanced MR Image Translation with Multi-Axis Fusion
Nov 20, 2023In recent years, deep learning has been applied to a wide range of medical imaging and image processing tasks. In this work, we focus on the estimation of epistemic uncertainty for 3D medical image-to-image translation. We propose a novel model uncertainty quantification method, Multi-Axis Fusion (MAF), which relies on the integration of complementary information derived from multiple views on volumetric image data. The proposed approach is applied to the task of synthesizing contrast enhanced T1-weighted images based on native T1, T2 and T2-FLAIR scans. The quantitative findings indicate a strong correlation ($\rho_{\text healthy} = 0.89$) between the mean absolute image synthetization error and the mean uncertainty score for our MAF method. Hence, we consider MAF as a promising approach to solve the highly relevant task of detecting synthetization failures at inference time.
Attack Tree Analysis for Adversarial Evasion Attacks
Dec 28, 2023Recently, the evolution of deep learning has promoted the application of machine learning (ML) to various systems. However, there are ML systems, such as autonomous vehicles, that cause critical damage when they misclassify. Conversely, there are ML-specific attacks called adversarial attacks based on the characteristics of ML systems. For example, one type of adversarial attack is an evasion attack, which uses minute perturbations called "adversarial examples" to intentionally misclassify classifiers. Therefore, it is necessary to analyze the risk of ML-specific attacks in introducing ML base systems. In this study, we propose a quantitative evaluation method for analyzing the risk of evasion attacks using attack trees. The proposed method consists of the extension of the conventional attack tree to analyze evasion attacks and the systematic construction method of the extension. In the extension of the conventional attack tree, we introduce ML and conventional attack nodes to represent various characteristics of evasion attacks. In the systematic construction process, we propose a procedure to construct the attack tree. The procedure consists of three steps: (1) organizing information about attack methods in the literature to a matrix, (2) identifying evasion attack scenarios from methods in the matrix, and (3) constructing the attack tree from the identified scenarios using a pattern. Finally, we conducted experiments on three ML image recognition systems to demonstrate the versatility and effectiveness of our proposed method.
* 10 pages
Diagonal Hierarchical Consistency Learning for Semi-supervised Medical Image Segmentation
Nov 24, 2023Medical image segmentation, which is essential for many clinical applications, has achieved almost human-level performance via data-driven deep learning technologies. Nevertheless, its performance is predicated upon the costly process of manually annotating a vast amount of medical images. To this end, we propose a novel framework for robust semi-supervised medical image segmentation using diagonal hierarchical consistency learning (DiHC-Net). First, it is composed of multiple sub-models with identical multi-scale architecture but with distinct sub-layers, such as up-sampling and normalisation layers. Second, with mutual consistency, a novel consistency regularisation is enforced between one model's intermediate and final prediction and soft pseudo labels from other models in a diagonal hierarchical fashion. A series of experiments verifies the efficacy of our simple framework, outperforming all previous approaches on public Left Atrium (LA) dataset.
HMP: Hand Motion Priors for Pose and Shape Estimation from Video
Dec 27, 2023Understanding how humans interact with the world necessitates accurate 3D hand pose estimation, a task complicated by the hand's high degree of articulation, frequent occlusions, self-occlusions, and rapid motions. While most existing methods rely on single-image inputs, videos have useful cues to address aforementioned issues. However, existing video-based 3D hand datasets are insufficient for training feedforward models to generalize to in-the-wild scenarios. On the other hand, we have access to large human motion capture datasets which also include hand motions, e.g. AMASS. Therefore, we develop a generative motion prior specific for hands, trained on the AMASS dataset which features diverse and high-quality hand motions. This motion prior is then employed for video-based 3D hand motion estimation following a latent optimization approach. Our integration of a robust motion prior significantly enhances performance, especially in occluded scenarios. It produces stable, temporally consistent results that surpass conventional single-frame methods. We demonstrate our method's efficacy via qualitative and quantitative evaluations on the HO3D and DexYCB datasets, with special emphasis on an occlusion-focused subset of HO3D. Code is available at https://hmp.is.tue.mpg.de
Bengali License Plate Recognition: Unveiling Clarity with CNN and GFP-GAN
Dec 17, 2023Automated License Plate Recognition(ALPR) is a system that automatically reads and extracts data from vehicle license plates using image processing and computer vision techniques. The Goal of LPR is to identify and read the license plate number accurately and quickly, even under challenging, conditions such as poor lighting, angled or obscured plates, and different plate fonts and layouts. The proposed method consists of processing the Bengali low-resolution blurred license plates and identifying the plate's characters. The processes include image restoration using GFPGAN, Maximizing contrast, Morphological image processing like dilation, feature extraction and Using Convolutional Neural Networks (CNN), character segmentation and recognition are accomplished. A dataset of 1292 images of Bengali digits and characters was prepared for this project.
TIBET: Identifying and Evaluating Biases in Text-to-Image Generative Models
Dec 03, 2023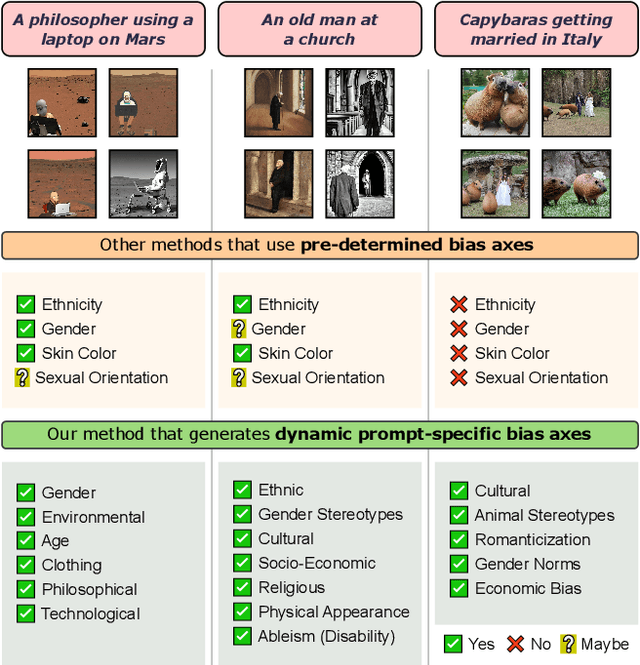
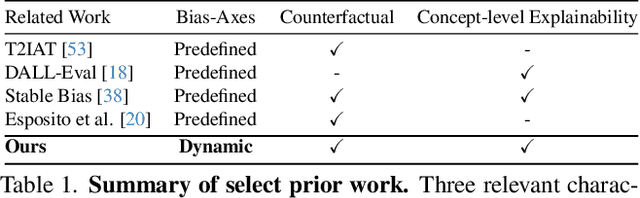
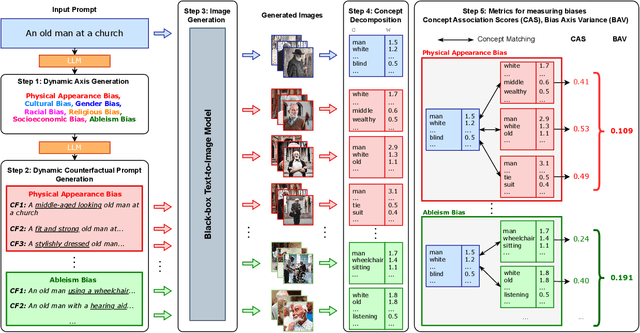
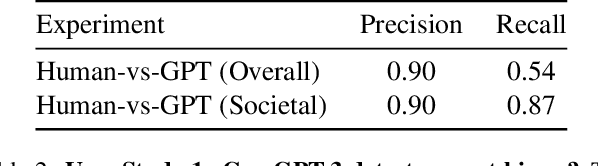
Text-to-Image (TTI) generative models have shown great progress in the past few years in terms of their ability to generate complex and high-quality imagery. At the same time, these models have been shown to suffer from harmful biases, including exaggerated societal biases (e.g., gender, ethnicity), as well as incidental correlations that limit such model's ability to generate more diverse imagery. In this paper, we propose a general approach to study and quantify a broad spectrum of biases, for any TTI model and for any prompt, using counterfactual reasoning. Unlike other works that evaluate generated images on a predefined set of bias axes, our approach automatically identifies potential biases that might be relevant to the given prompt, and measures those biases. In addition, our paper extends quantitative scores with post-hoc explanations in terms of semantic concepts in the images generated. We show that our method is uniquely capable of explaining complex multi-dimensional biases through semantic concepts, as well as the intersectionality between different biases for any given prompt. We perform extensive user studies to illustrate that the results of our method and analysis are consistent with human judgements.
FerKD: Surgical Label Adaptation for Efficient Distillation
Dec 29, 2023We present FerKD, a novel efficient knowledge distillation framework that incorporates partial soft-hard label adaptation coupled with a region-calibration mechanism. Our approach stems from the observation and intuition that standard data augmentations, such as RandomResizedCrop, tend to transform inputs into diverse conditions: easy positives, hard positives, or hard negatives. In traditional distillation frameworks, these transformed samples are utilized equally through their predictive probabilities derived from pretrained teacher models. However, merely relying on prediction values from a pretrained teacher, a common practice in prior studies, neglects the reliability of these soft label predictions. To address this, we propose a new scheme that calibrates the less-confident regions to be the context using softened hard groundtruth labels. Our approach involves the processes of hard regions mining + calibration. We demonstrate empirically that this method can dramatically improve the convergence speed and final accuracy. Additionally, we find that a consistent mixing strategy can stabilize the distributions of soft supervision, taking advantage of the soft labels. As a result, we introduce a stabilized SelfMix augmentation that weakens the variation of the mixed images and corresponding soft labels through mixing similar regions within the same image. FerKD is an intuitive and well-designed learning system that eliminates several heuristics and hyperparameters in former FKD solution. More importantly, it achieves remarkable improvement on ImageNet-1K and downstream tasks. For instance, FerKD achieves 81.2% on ImageNet-1K with ResNet-50, outperforming FKD and FunMatch by remarkable margins. Leveraging better pre-trained weights and larger architectures, our finetuned ViT-G14 even achieves 89.9%. Our code is available at https://github.com/szq0214/FKD/tree/main/FerKD.
XAI for time-series classification leveraging image highlight methods
Nov 28, 2023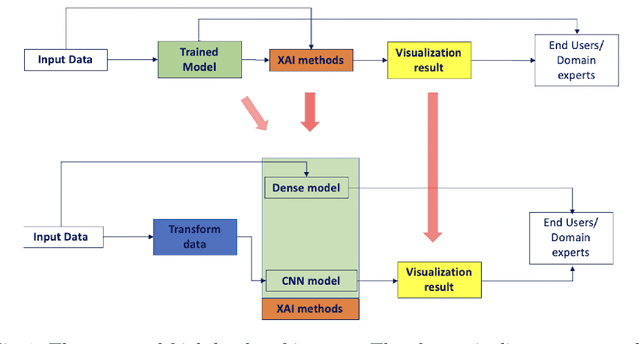
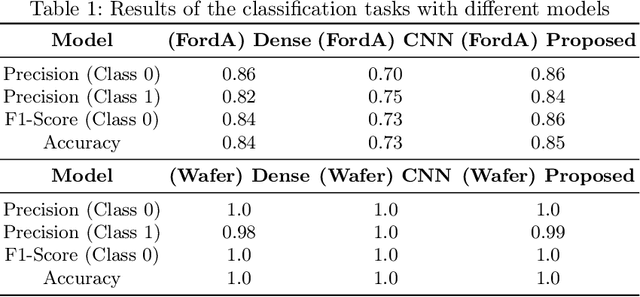
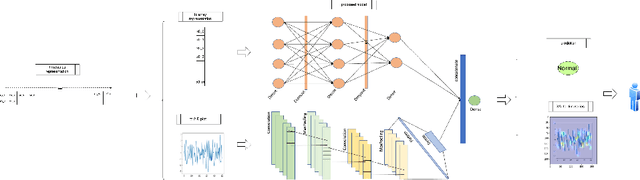
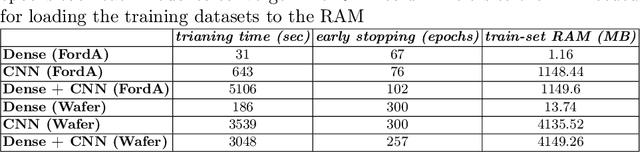
Although much work has been done on explainability in the computer vision and natural language processing (NLP) fields, there is still much work to be done to explain methods applied to time series as time series by nature can not be understood at first sight. In this paper, we present a Deep Neural Network (DNN) in a teacher-student architecture (distillation model) that offers interpretability in time-series classification tasks. The explainability of our approach is based on transforming the time series to 2D plots and applying image highlight methods (such as LIME and GradCam), making the predictions interpretable. At the same time, the proposed approach offers increased accuracy competing with the baseline model with the trade-off of increasing the training time.
CLiSA: A Hierarchical Hybrid Transformer Model using Orthogonal Cross Attention for Satellite Image Cloud Segmentation
Nov 29, 2023Clouds in optical satellite images are a major concern since their presence hinders the ability to carry accurate analysis as well as processing. Presence of clouds also affects the image tasking schedule and results in wastage of valuable storage space on ground as well as space-based systems. Due to these reasons, deriving accurate cloud masks from optical remote-sensing images is an important task. Traditional methods such as threshold-based, spatial filtering for cloud detection in satellite images suffer from lack of accuracy. In recent years, deep learning algorithms have emerged as a promising approach to solve image segmentation problems as it allows pixel-level classification and semantic-level segmentation. In this paper, we introduce a deep-learning model based on hybrid transformer architecture for effective cloud mask generation named CLiSA - Cloud segmentation via Lipschitz Stable Attention network. In this context, we propose an concept of orthogonal self-attention combined with hierarchical cross attention model, and we validate its Lipschitz stability theoretically and empirically. We design the whole setup under adversarial setting in presence of Lov\'asz-Softmax loss. We demonstrate both qualitative and quantitative outcomes for multiple satellite image datasets including Landsat-8, Sentinel-2, and Cartosat-2s. Performing comparative study we show that our model performs preferably against other state-of-the-art methods and also provides better generalization in precise cloud extraction from satellite multi-spectral (MX) images. We also showcase different ablation studies to endorse our choices corresponding to different architectural elements and objective functions.