 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Plug-and-play ISTA converges with kernel denoisers
Apr 14, 2020

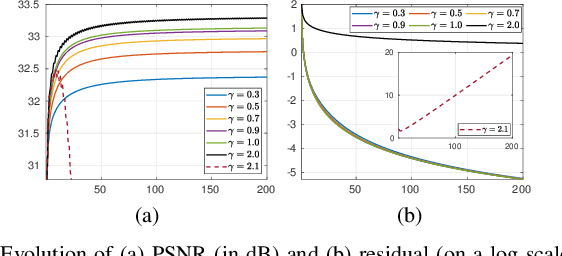
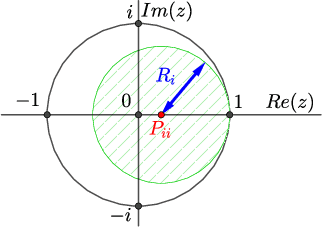
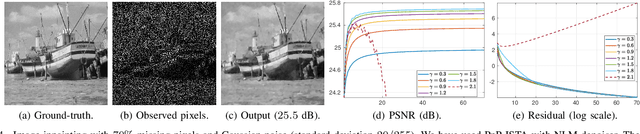
Plug-and-play (PnP) method is a recent paradigm for image regularization, where the proximal operator (associated with some given regularizer) in an iterative algorithm is replaced with a powerful denoiser. Algorithmically, this involves repeated inversion (of the forward model) and denoising until convergence. Remarkably, PnP regularization produces promising results for several restoration applications. However, a fundamental question in this regard is the theoretical convergence of the PnP iterations, since the algorithm is not strictly derived from an optimization framework. This question has been investigated in recent works, but there are still many unresolved problems. For example, it is not known if convergence can be guaranteed if we use generic kernel denoisers (e.g. nonlocal means) within the ISTA framework (PnP-ISTA). We prove that, under reasonable assumptions, fixed-point convergence of PnP-ISTA is indeed guaranteed for linear inverse problems such as deblurring, inpainting and superresolution (the assumptions are verifiable for inpainting). We compare our theoretical findings with existing results, validate them numerically, and explain their practical relevance.
On a new formulation of nonlocal image filters involving the relative rearrangement
Jun 27, 2014Nonlocal filters are simple and powerful techniques for image denoising. In this paper we study the reformulation of a broad class of nonlocal filters in terms of two functional rearrangements: the decreasing and the relative rearrangements. Independently of the dimension of the image, we reformulate these filters as integral operators defined in a one-dimensional space corresponding to the level sets measures. We prove the equivalency between the original and the rearranged versions of the filters and propose a discretization in terms of constant-wise interpolators, which we prove to be convergent to the solution of the continuous setting. For some particular cases, this new formulation allows us to perform a detailed analysis of the filtering properties. Among others, we prove that the filtered image is a contrast change of the original image, and that the filtering procedure behaves asymptotically as a shock filter combined with a border diffusive term, responsible for the staircaising effect and the loss of contrast.
Research on the Multiple Feature Fusion Image Retrieval Algorithm based on Texture Feature and Rough Set Theory
Dec 08, 2016
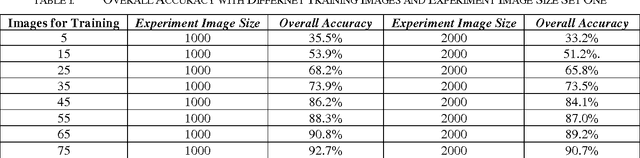
Recently, we have witnessed the explosive growth of images with complex information and content. In order to effectively and precisely retrieve desired images from a large-scale image database with low time-consuming, we propose the multiple feature fusion image retrieval algorithm based on the texture feature and rough set theory in this paper. In contrast to the conventional approaches that only use the single feature or standard, we fuse the different features with operation of normalization. The rough set theory will assist us to enhance the robustness of retrieval system when facing with incomplete data warehouse. To enhance the texture extraction paradigm, we use the wavelet Gabor function that holds better robustness. In addition, from the perspectives of the internal and external normalization, we re-organize extracted feature with the better combination. The numerical experiment has verified general feasibility of our methodology. We enhance the overall accuracy compared with the other state-of-the-art algorithms.
A sub-Riemannian model of the visual cortex with frequency and phase
Oct 11, 2019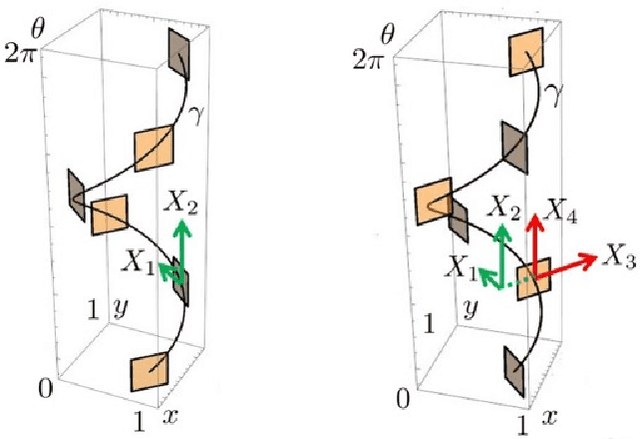
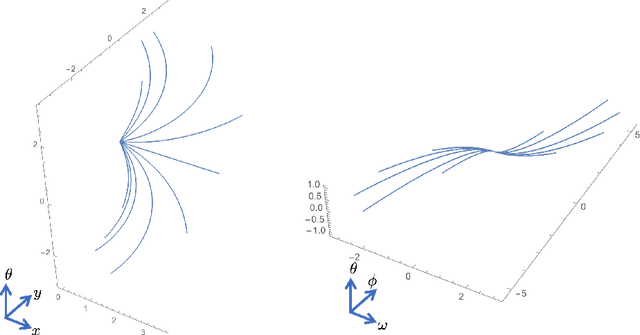

In this paper we present a novel model of the primary visual cortex (V1) based on orientation, frequency and phase selective behavior of the V1 simple cells. We start from the first level mechanisms of visual perception: receptive profiles. The model interprets V1 as a fiber bundle over the 2-dimensional retinal plane by introducing orientation, frequency and phase as intrinsic variables. Each receptive profile on the fiber is mathematically interpreted as a rotated, frequency modulated and phase shifted Gabor function. We start from the Gabor function and show that it induces in a natural way the model geometry and the associated horizontal connectivity modeling the neural connectivity patterns in V1. We provide an image enhancement algorithm employing the model framework. The algorithm is capable of exploiting not only orientation but also frequency and phase information existing intrinsically in a 2-dimensional input image. We provide the experimental results corresponding to the enhancement algorithm.
Extracting Cellular Location of Human Proteins Using Deep Learning
Jun 06, 2020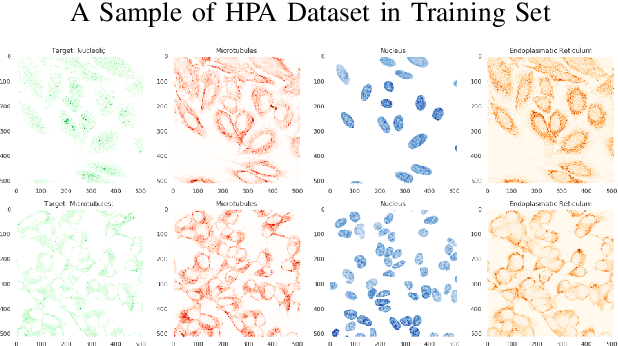
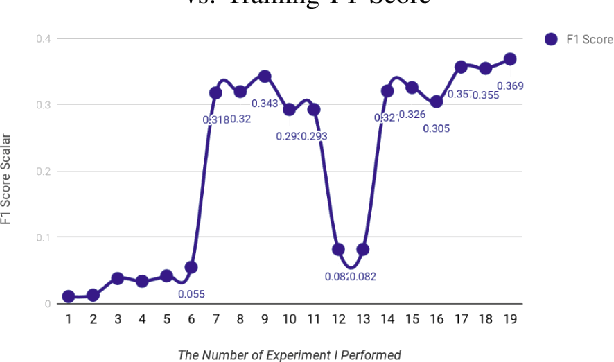
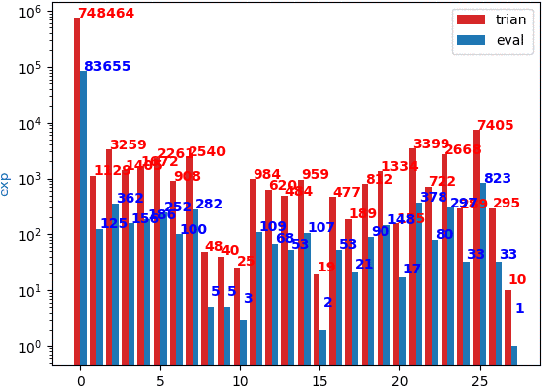
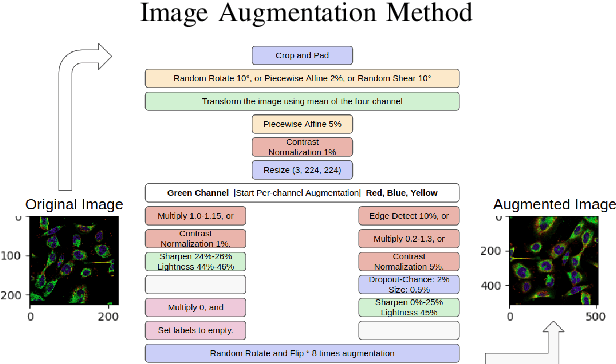
Understanding and extracting the patterns of microscopy images has been a major challenge in the biomedical field. Although trained scientists can locate the proteins of interest within a human cell, this procedure is not efficient and accurate enough to process a large amount of data and it often leads to bias. To resolve this problem, we attempted to create an automatic image classifier using Machine Learning to locate human proteins with higher speed and accuracy than human beings. We implemented a Convolution Neural Network with Residue and Squeeze-Excitation layers classifier to locate given proteins of any type in a subcellular structure. After training the model using a series of techniques, it can locate thousands of proteins in 27 different human cell types into 28 subcellular locations, way significant than historical approaches. The model can classify 4,500 images per minute with an accuracy of 63.07%, surpassing human performance in accuracy (by 35%) and speed. Because our system can be implemented on different cell types, it opens a new vision of understanding in the biomedical field. From the locational information of the human proteins, doctors can easily detect cell's abnormal behaviors including viral infection, pathogen invasion, and malignant tumor development. Given the amount of data generalized by experiments are greater than that human can analyze, the model cut down the human resources and time needed to analyze data. Moreover, this locational information can be used in different scenarios like subcellular engineering, medical care, and etiology inspection.
Adversarial Pulmonary Pathology Translation for Pairwise Chest X-ray Data Augmentation
Oct 11, 2019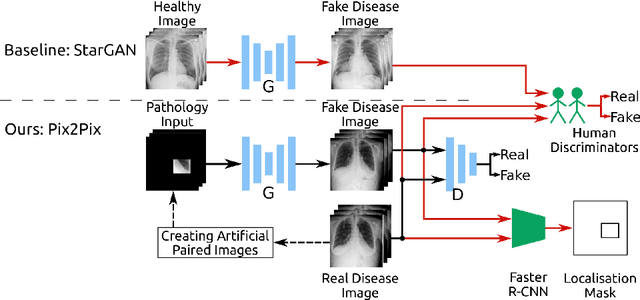
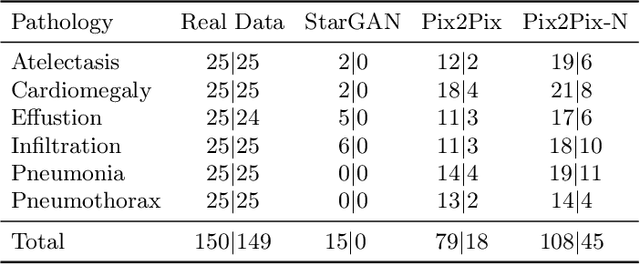
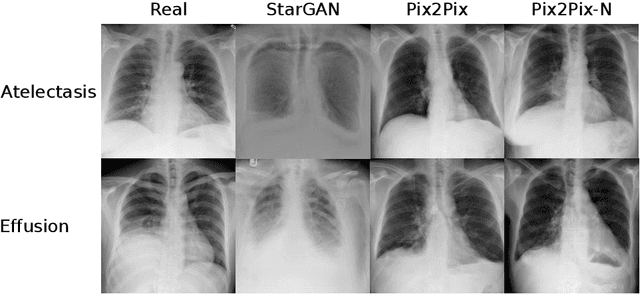
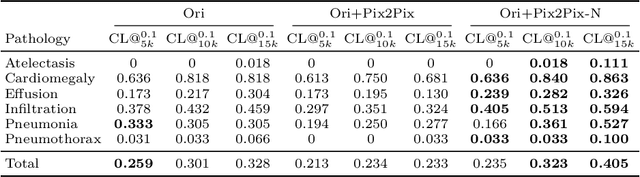
Recent works show that Generative Adversarial Networks (GANs) can be successfully applied to chest X-ray data augmentation for lung disease recognition. However, the implausible and distorted pathology features generated from the less than perfect generator may lead to wrong clinical decisions. Why not keep the original pathology region? We proposed a novel approach that allows our generative model to generate high quality plausible images that contain undistorted pathology areas. The main idea is to design a training scheme based on an image-to-image translation network to introduce variations of new lung features around the pathology ground-truth area. Moreover, our model is able to leverage both annotated disease images and unannotated healthy lung images for the purpose of generation. We demonstrate the effectiveness of our model on two tasks: (i) we invite certified radiologists to assess the quality of the generated synthetic images against real and other state-of-the-art generative models, and (ii) data augmentation to improve the performance of disease localisation.
PI-RCNN: An Efficient Multi-sensor 3D Object Detector with Point-based Attentive Cont-conv Fusion Module
Dec 02, 2019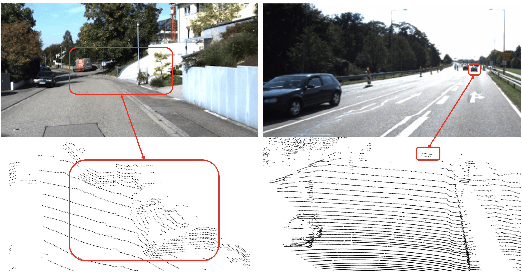
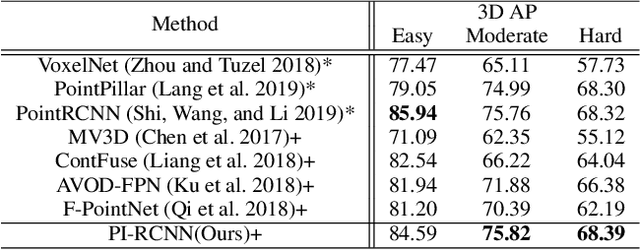
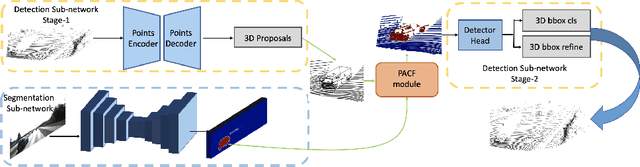
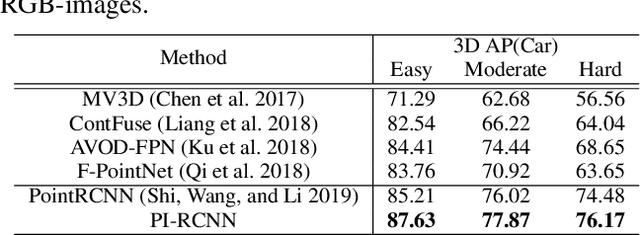
LIDAR point clouds and RGB-images are both extremely essential for 3D object detection. So many state-of-the-art 3D detection algorithms dedicate in fusing these two types of data effectively. However, their fusion methods based on Birds Eye View (BEV) or voxel format are not accurate. In this paper, we propose a novel fusion approach named Point-based Attentive Cont-conv Fusion(PACF) module, which fuses multi-sensor features directly on 3D points. Except for continuous convolution, we additionally add a Point-Pooling and an Attentive Aggregation to make the fused features more expressive. Moreover, based on the PACF module, we propose a 3D multi-sensor multi-task network called Pointcloud-Image RCNN(PI-RCNN as brief), which handles the image segmentation and 3D object detection tasks. PI-RCNN employs a segmentation sub-network to extract full-resolution semantic feature maps from images and then fuses the multi-sensor features via powerful PACF module. Beneficial from the effectiveness of the PACF module and the expressive semantic features from the segmentation module, PI-RCNN can improve much in 3D object detection. We demonstrate the effectiveness of the PACF module and PI-RCNN on the KITTI 3D Detection benchmark, and our method can achieve state-of-the-art on the metric of 3D AP.
E2GC: Energy-efficient Group Convolution in Deep Neural Networks
Jun 26, 2020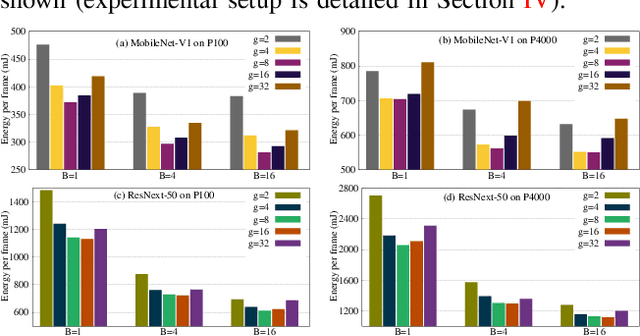
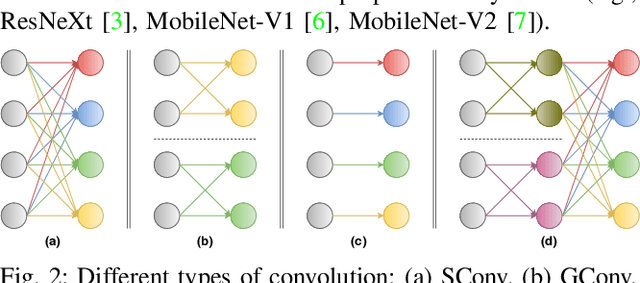
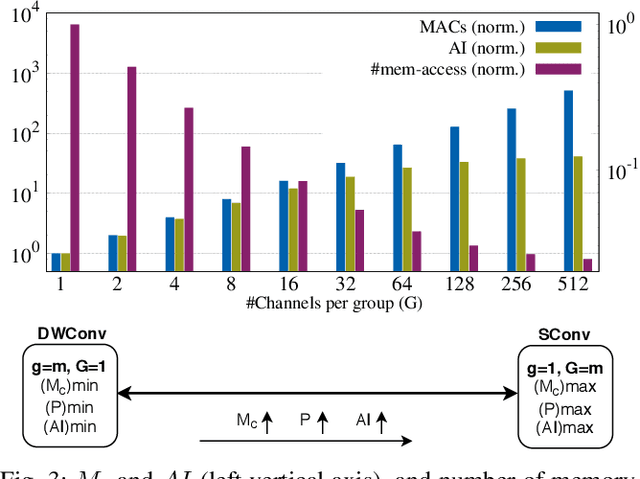
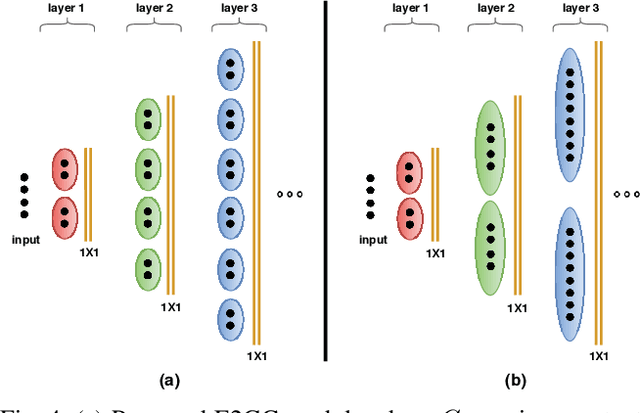
The number of groups ($g$) in group convolution (GConv) is selected to boost the predictive performance of deep neural networks (DNNs) in a compute and parameter efficient manner. However, we show that naive selection of $g$ in GConv creates an imbalance between the computational complexity and degree of data reuse, which leads to suboptimal energy efficiency in DNNs. We devise an optimum group size model, which enables a balance between computational cost and data movement cost, thus, optimize the energy-efficiency of DNNs. Based on the insights from this model, we propose an "energy-efficient group convolution" (E2GC) module where, unlike the previous implementations of GConv, the group size ($G$) remains constant. Further, to demonstrate the efficacy of the E2GC module, we incorporate this module in the design of MobileNet-V1 and ResNeXt-50 and perform experiments on two GPUs, P100 and P4000. We show that, at comparable computational complexity, DNNs with constant group size (E2GC) are more energy-efficient than DNNs with a fixed number of groups (F$g$GC). For example, on P100 GPU, the energy-efficiency of MobileNet-V1 and ResNeXt-50 is increased by 10.8% and 4.73% (respectively) when E2GC modules substitute the F$g$GC modules in both the DNNs. Furthermore, through our extensive experimentation with ImageNet-1K and Food-101 image classification datasets, we show that the E2GC module enables a trade-off between generalization ability and representational power of DNN. Thus, the predictive performance of DNNs can be optimized by selecting an appropriate $G$. The code and trained models are available at https://github.com/iithcandle/E2GC-release.
* Accepted as a conference paper in 2020 33rd International Conference on VLSI Design and 2020 19th International Conference on Embedded Systems (VLSID)
DUAL-GLOW: Conditional Flow-Based Generative Model for Modality Transfer
Aug 21, 2019

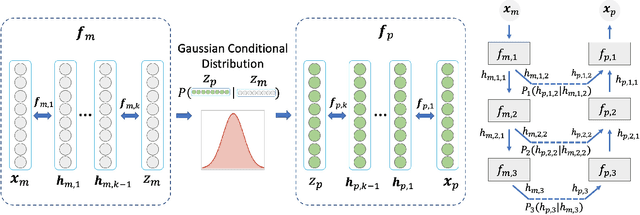
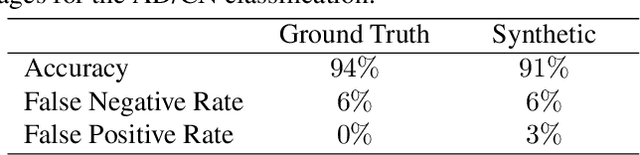
Positron emission tomography (PET) imaging is an imaging modality for diagnosing a number of neurological diseases. In contrast to Magnetic Resonance Imaging (MRI), PET is costly and involves injecting a radioactive substance into the patient. Motivated by developments in modality transfer in vision, we study the generation of certain types of PET images from MRI data. We derive new flow-based generative models which we show perform well in this small sample size regime (much smaller than dataset sizes available in standard vision tasks). Our formulation, DUAL-GLOW, is based on two invertible networks and a relation network that maps the latent spaces to each other. We discuss how given the prior distribution, learning the conditional distribution of PET given the MRI image reduces to obtaining the conditional distribution between the two latent codes w.r.t. the two image types. We also extend our framework to leverage 'side' information (or attributes) when available. By controlling the PET generation through 'conditioning' on age, our model is also able to capture brain FDG-PET (hypometabolism) changes, as a function of age. We present experiments on the Alzheimers Disease Neuroimaging Initiative (ADNI) dataset with 826 subjects, and obtain good performance in PET image synthesis, qualitatively and quantitatively better than recent works.
Quantum Edge Detection for Image Segmentation in Optical Environments
Sep 09, 2014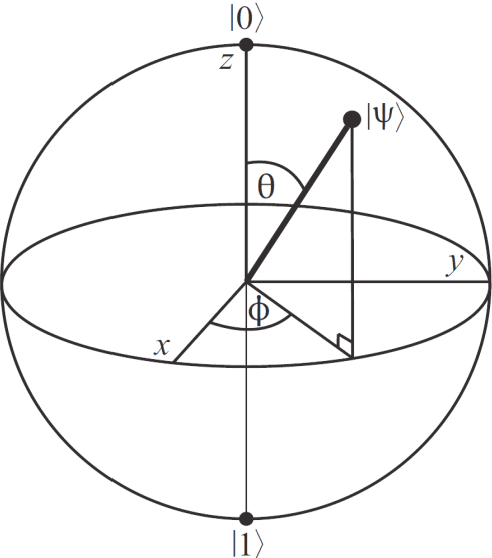
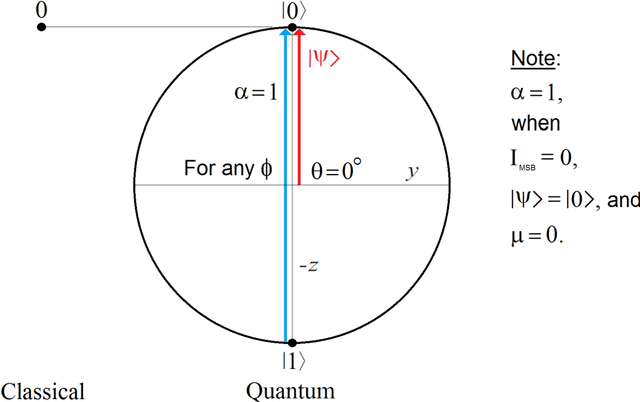
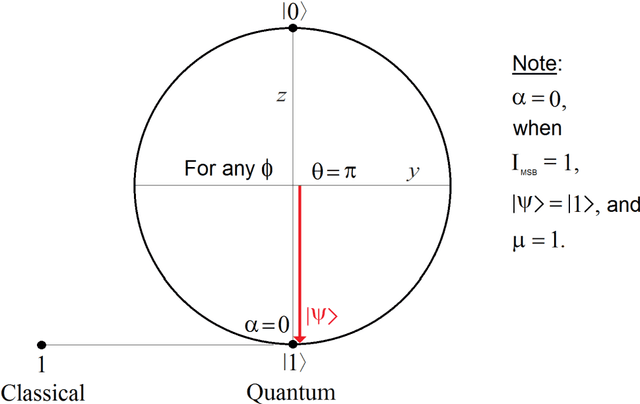
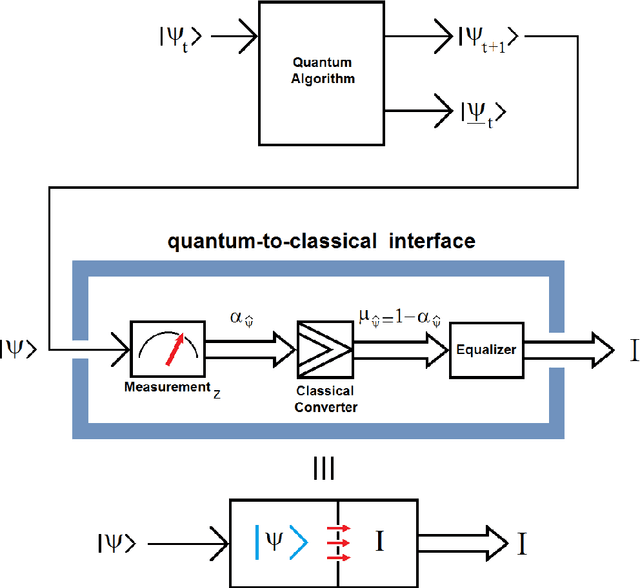
A quantum edge detector for image segmentation in optical environments is presented in this work. A Boolean version of the same detector is presented too. The quantum version of the new edge detector works with computational basis states, exclusively. This way, we can easily avoid the problem of quantum measurement retrieving the result of applying the new detector on the image. Besides, a new criterion and logic based on projections onto vertical axis of Bloch's Sphere exclusively are presented too. This approach will allow us: 1) a simpler development of logic quantum operations, where they will closer to those used in the classical logic operations, 2) building simple and robust classical-to-quantum and quantum-to-classical interfaces. Said so far is extended to quantum algorithms outside image processing too. In a special section on metric and simulations, a new metric based on the comparison between the classical and quantum versions algorithms for edge detection of images is presented. Notable differences between the results of classical and quantum versions of such algorithms (outside and inside of quantum computer, respectively) show the existence of implementation problems involved in the experiment, and that they have not been properly modeled for optical environments. However, although they are different, the quantum results are equally valid. The latter is clearly seen in the computer simulations