 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning in Multi-organ Segmentation
Jan 28, 2020
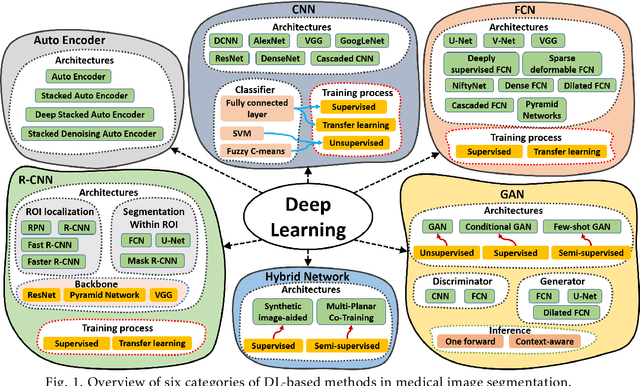
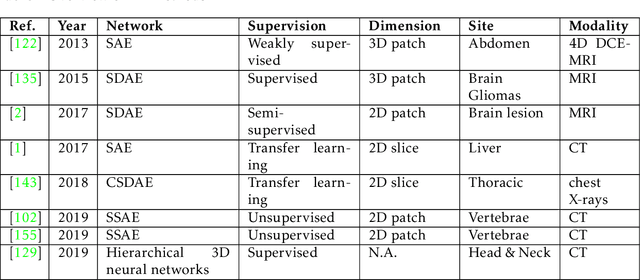
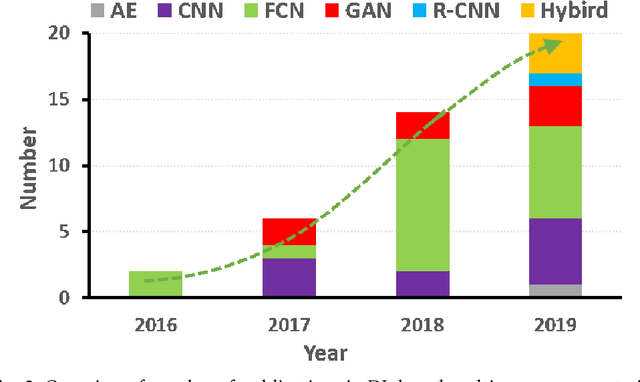
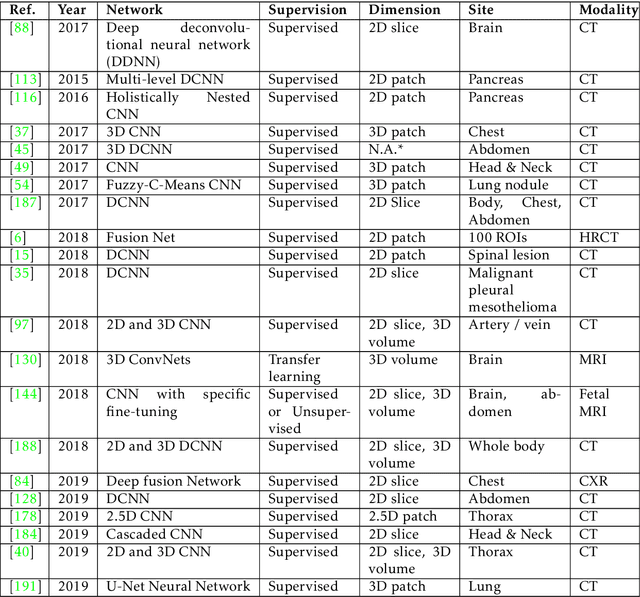
This paper presents a review of deep learning (DL) in multi-organ segmentation. We summarized the latest DL-based methods for medical image segmentation and applications. These methods were classified into six categories according to their network design. For each category, we listed the surveyed works, highlighted important contributions and identified specific challenges. Following the detailed review of each category, we briefly discussed its achievements, shortcomings and future potentials. We provided a comprehensive comparison among DL-based methods for thoracic and head & neck multiorgan segmentation using benchmark datasets, including the 2017 AAPM Thoracic Auto-segmentation Challenge datasets and 2015 MICCAI Head Neck Auto-Segmentation Challenge datasets.
Dense Fusion Classmate Network for Land Cover Classification
Nov 19, 2019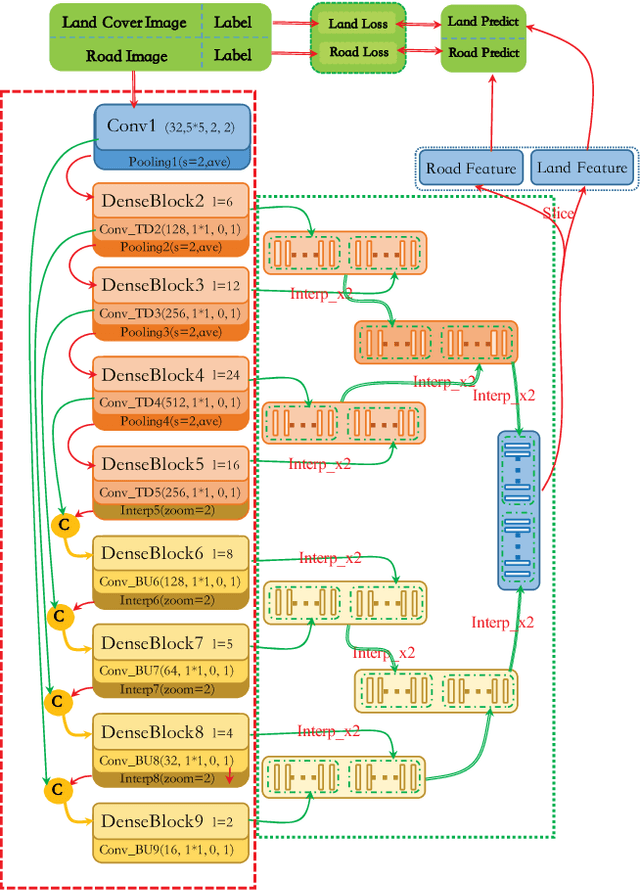
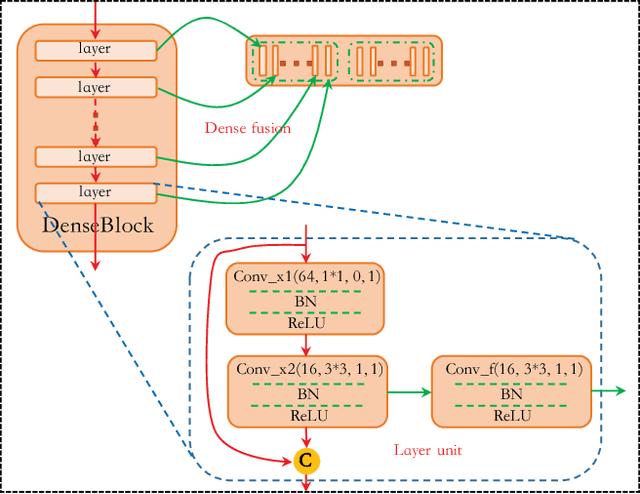

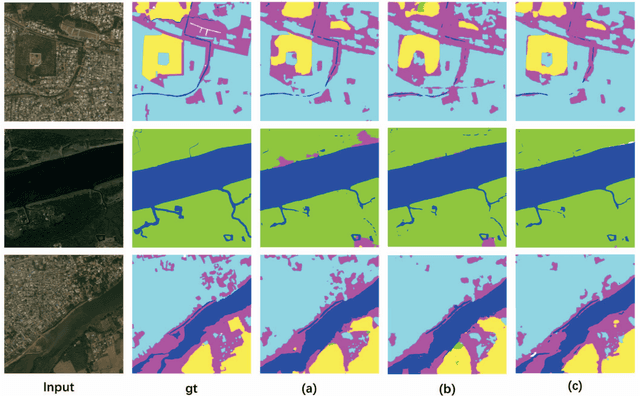
Recently, FCNs based methods have made great progress in semantic segmentation. Different with ordinary scenes, satellite image owns specific characteristics, which elements always extend to large scope and no regular or clear boundaries. Therefore, effective mid-level structure information extremely missing, precise pixel-level classification becomes tough issues. In this paper, a Dense Fusion Classmate Network (DFCNet) is proposed to adopt in land cover classification.
Probabilistic Motion Modeling from Medical Image Sequences: Application to Cardiac Cine-MRI
Jul 31, 2019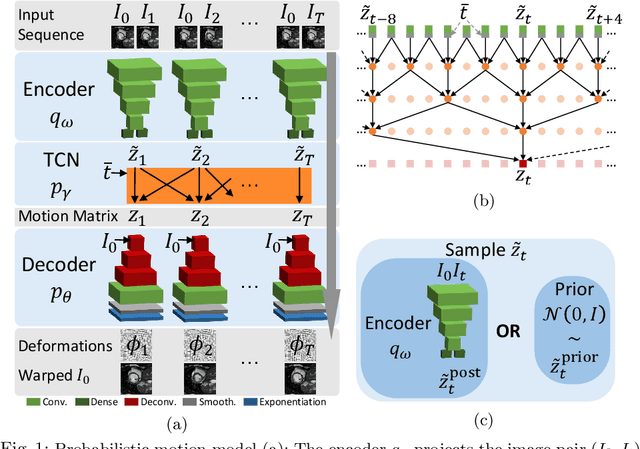
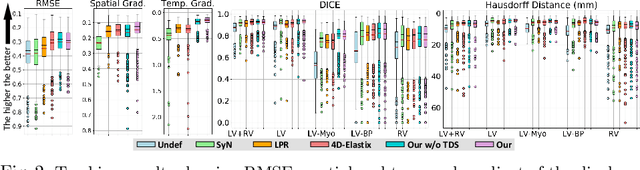
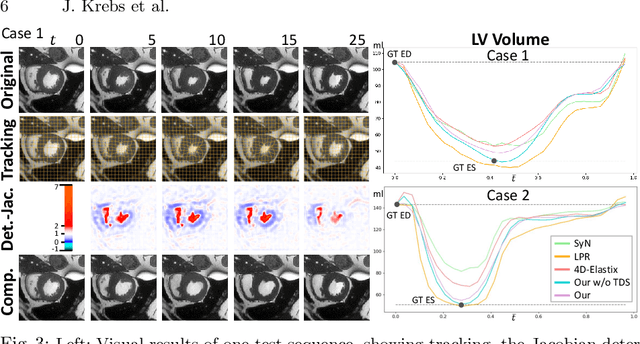
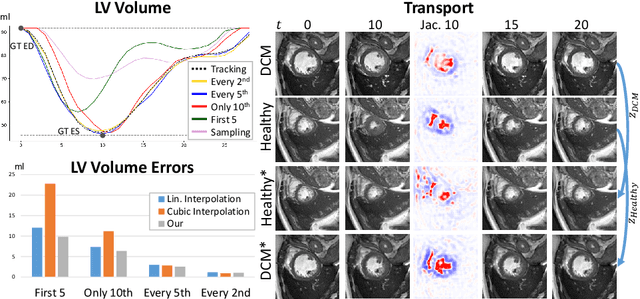
We propose to learn a probabilistic motion model from a sequence of images. Besides spatio-temporal registration, our method offers to predict motion from a limited number of frames, useful for temporal super-resolution. The model is based on a probabilistic latent space and a novel temporal dropout training scheme. This enables simulation and interpolation of realistic motion patterns given only one or any subset of frames of a sequence. The encoded motion also allows to be transported from one subject to another without the need of inter-subject registration. An unsupervised generative deformation model is applied within a temporal convolutional network which leads to a diffeomorphic motion model, encoded as a low-dimensional motion matrix. Applied to cardiac cine-MRI sequences, we show improved registration accuracy and spatio-temporally smoother deformations compared to three state-of-the-art registration algorithms. Besides, we demonstrate the model's applicability to motion transport by simulating a pathology in a healthy case. Furthermore, we show an improved motion reconstruction from incomplete sequences compared to linear and cubic interpolation.
Adversarial Continual Learning
Mar 21, 2020

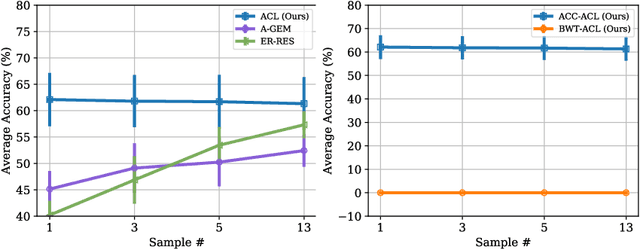
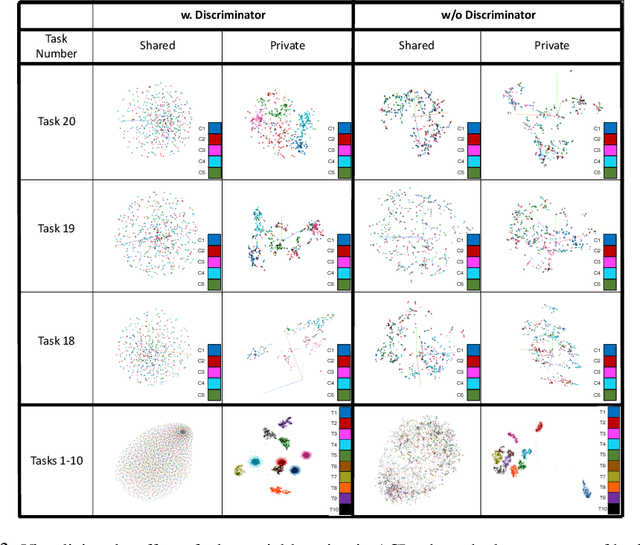
Continual learning aims to learn new tasks without forgetting previously learned ones. We hypothesize that representations learned to solve each task in a sequence have a shared structure while containing some task-specific properties. We show that shared features are significantly less prone to forgetting and propose a novel hybrid continual learning framework that learns a disjoint representation for task-invariant and task-specific features required to solve a sequence of tasks. Our model combines architecture growth to prevent forgetting of task-specific skills and an experience replay approach to preserve shared skills. We demonstrate our hybrid approach is effective in avoiding forgetting and show it is superior to both architecture-based and memory-based approaches on class incrementally learning of a single dataset as well as a sequence of multiple datasets in image classification. Our code is available at \url{https://github.com/facebookresearch/Adversarial-Continual-Learning}.
Code-Aligned Autoencoders for Unsupervised Change Detection in Multimodal Remote Sensing Images
Apr 15, 2020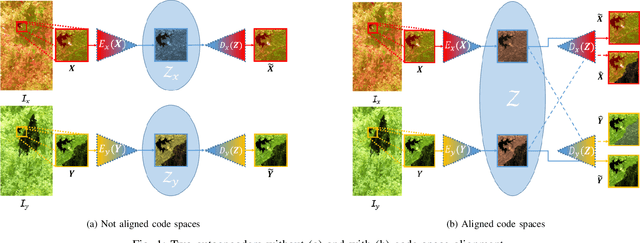

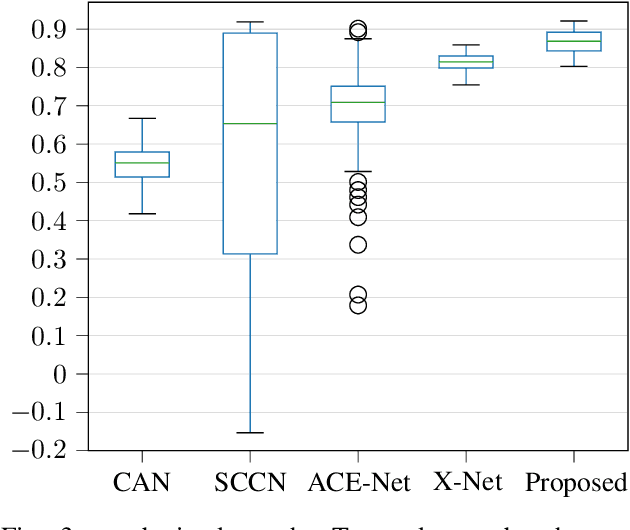
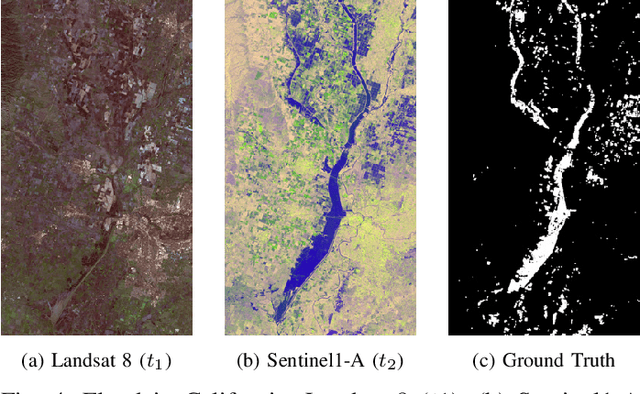
Image translation with convolutional autoencoders has recently been used as an approach to multimodal change detection in bitemporal satellite images. A main challenge is the alignment of the code spaces by reducing the contribution of change pixels to the learning of the translation function. Many existing approaches train the networks by exploiting supervised information of the change areas, which, however, is not always available. We propose to extract relational pixel information captured by domain-specific affinity matrices at the input and use this to enforce alignment of the code spaces and reduce the impact of change pixels on the learning objective. A change prior is derived in an unsupervised fashion from pixel pair affinities that are comparable across domains. To achieve code space alignment we enforce that pixel with similar affinity relations in the input domains should be correlated also in code space. We demonstrate the utility of this procedure in combination with cycle consistency. The proposed approach are compared with state-of-the-art deep learning algorithms. Experiments conducted on four real datasets show the effectiveness of our methodology.
Visual Descriptor Learning from Monocular Video
Apr 15, 2020


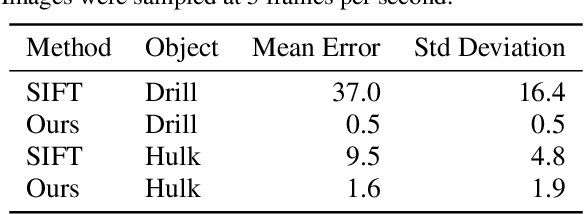
Correspondence estimation is one of the most widely researched and yet only partially solved area of computer vision with many applications in tracking, mapping, recognition of objects and environment. In this paper, we propose a novel way to estimate dense correspondence on an RGB image where visual descriptors are learned from video examples by training a fully convolutional network. Most deep learning methods solve this by training the network with a large set of expensive labeled data or perform labeling through strong 3D generative models using RGB-D videos. Our method learns from RGB videos using contrastive loss, where relative labeling is estimated from optical flow. We demonstrate the functionality in a quantitative analysis on rendered videos, where ground truth information is available. Not only does the method perform well on test data with the same background, it also generalizes to situations with a new background. The descriptors learned are unique and the representations determined by the network are global. We further show the applicability of the method to real-world videos.
End to End Recognition System for Recognizing Offline Unconstrained Vietnamese Handwriting
May 14, 2019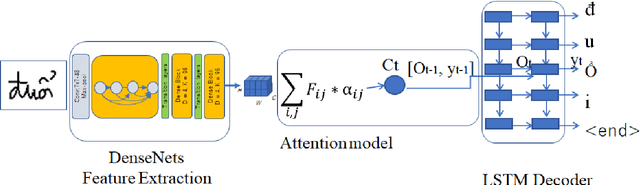
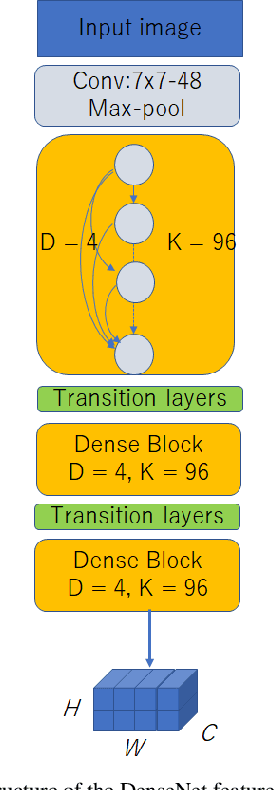
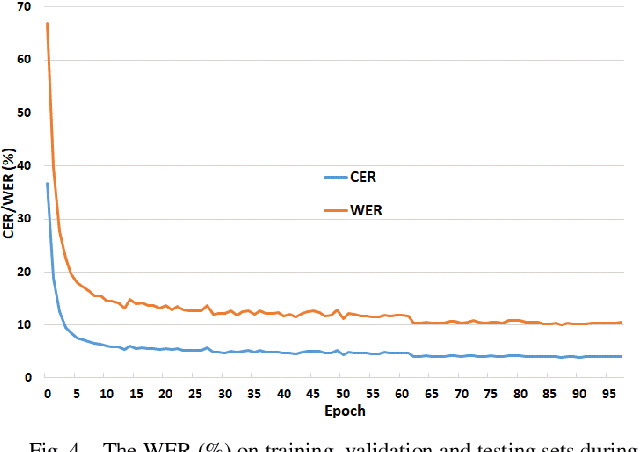

Inspired by recent successes in neural machine translation and image caption generation, we present an attention based encoder decoder model (AED) to recognize Vietnamese Handwritten Text. The model composes of two parts: a DenseNet for extracting invariant features, and a Long Short-Term Memory network (LSTM) with an attention model incorporated for generating output text (LSTM decoder), which are connected from the CNN part to the attention model. The input of the CNN part is a handwritten text image and the target of the LSTM decoder is the corresponding text of the input image. Our model is trained end-to-end to predict the text from a given input image since all the parts are differential components. In the experiment section, we evaluate our proposed AED model on the VNOnDB-Word and VNOnDB-Line datasets to verify its efficiency. The experiential results show that our model achieves 12.30% of word error rate without using any language model. This result is competitive with the handwriting recognition system provided by Google in the Vietnamese Online Handwritten Text Recognition competition.
On a new formulation of nonlocal image filters involving the relative rearrangement
Jun 27, 2014Nonlocal filters are simple and powerful techniques for image denoising. In this paper we study the reformulation of a broad class of nonlocal filters in terms of two functional rearrangements: the decreasing and the relative rearrangements. Independently of the dimension of the image, we reformulate these filters as integral operators defined in a one-dimensional space corresponding to the level sets measures. We prove the equivalency between the original and the rearranged versions of the filters and propose a discretization in terms of constant-wise interpolators, which we prove to be convergent to the solution of the continuous setting. For some particular cases, this new formulation allows us to perform a detailed analysis of the filtering properties. Among others, we prove that the filtered image is a contrast change of the original image, and that the filtering procedure behaves asymptotically as a shock filter combined with a border diffusive term, responsible for the staircaising effect and the loss of contrast.
Exploiting Multi-Layer Grid Maps for Surround-View Semantic Segmentation of Sparse LiDAR Data
May 13, 2020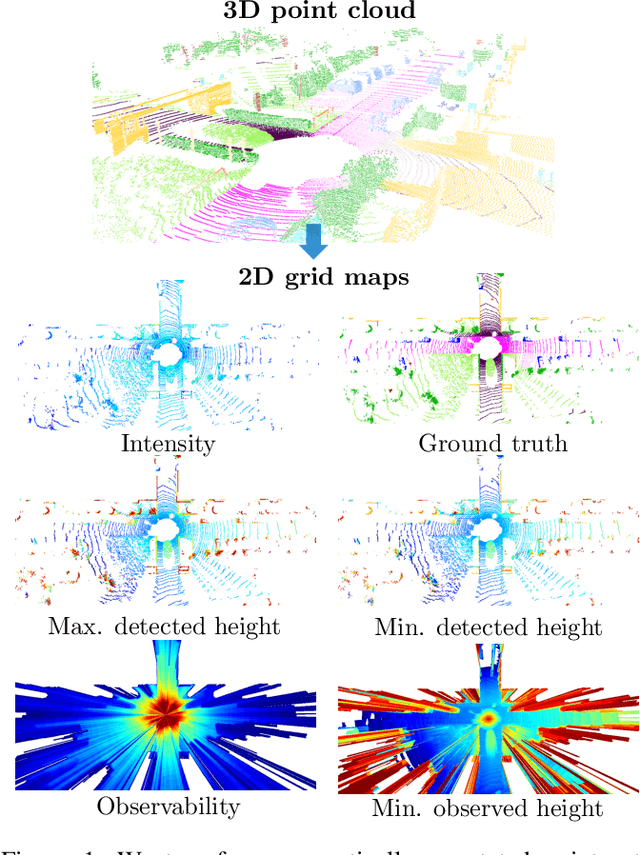

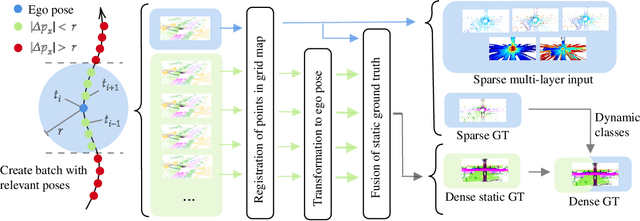
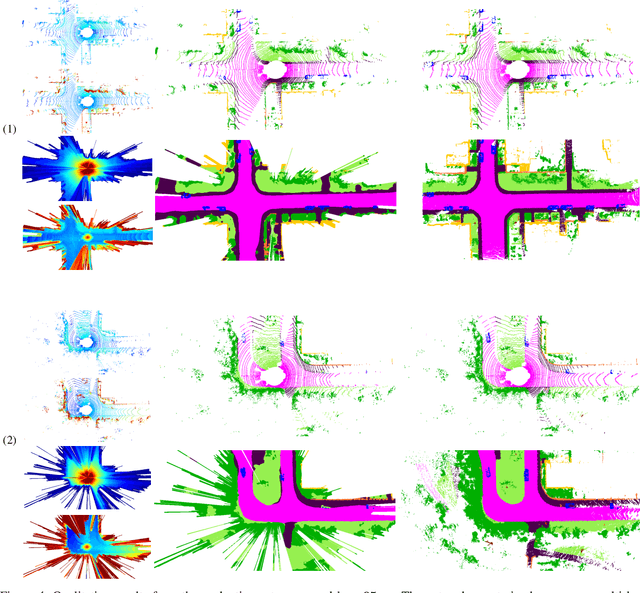
In this paper, we consider the transformation of laser range measurements into a top-view grid map representation to approach the task of LiDAR-only semantic segmentation. Since the recent publication of the SemanticKITTI data set, researchers are now able to study semantic segmentation of urban LiDAR sequences based on a reasonable amount of data. While other approaches propose to directly learn on the 3D point clouds, we are exploiting a grid map framework to extract relevant information and represent them by using multi-layer grid maps. This representation allows us to use well-studied deep learning architectures from the image domain to predict a dense semantic grid map using only the sparse input data of a single LiDAR scan. We compare single-layer and multi-layer approaches and demonstrate the benefit of a multi-layer grid map input. Since the grid map representation allows us to predict a dense, 360{\deg} semantic environment representation, we further develop a method to combine the semantic information from multiple scans and create dense ground truth grids. This method allows us to evaluate and compare the performance of our models not only based on grid cells with a detection, but on the full visible measurement range.
IntersectGAN: Learning Domain Intersection for Generating Images with Multiple Attributes
Sep 21, 2019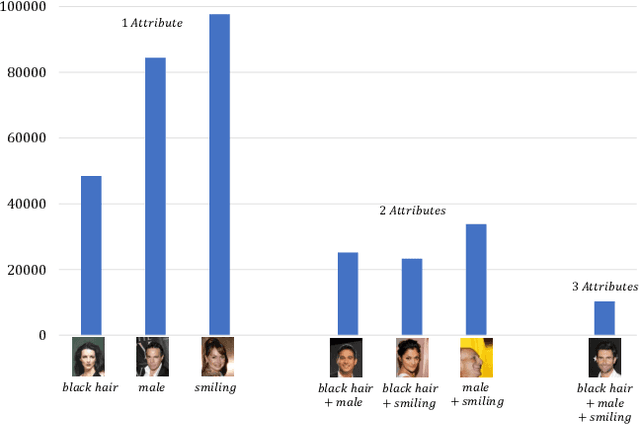
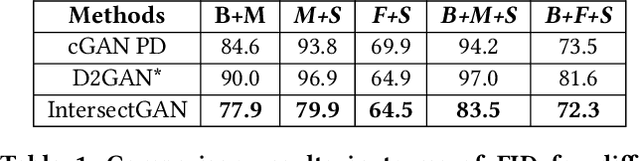

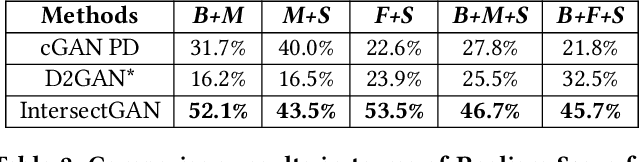
Generative adversarial networks (GANs) have demonstrated great success in generating various visual content. However, images generated by existing GANs are often of attributes (e.g., smiling expression) learned from one image domain. As a result, generating images of multiple attributes requires many real samples possessing multiple attributes which are very resource expensive to be collected. In this paper, we propose a novel GAN, namely IntersectGAN, to learn multiple attributes from different image domains through an intersecting architecture. For example, given two image domains X1 and X2 with certain attributes, the intersection of X1 and X2 is a new domain where images possess the attributes from both X1 and X2 domains. The proposed IntersectGAN consists of two discriminators D1 and D2 to distinguish between generated and real samples of different domains, and three generators where the intersection generator is trained against both discriminators. And an overall adversarial loss function is defined over three generators. As a result, our proposed IntersectGAN can be trained on multiple domains of which each presents one specific attribute, and eventually eliminates the need of real sample images simultaneously possessing multiple attributes. By using the CelebFaces Attributes dataset, our proposed IntersectGAN is able to produce high-quality face images possessing multiple attributes (e.g., a face with black hair and a smiling expression). Both qualitative and quantitative evaluations are conducted to compare our proposed IntersectGAN with other baseline methods. Besides, several different applications of IntersectGAN have been explored with promising results.