 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Demosaicing and Superresolution for Color Filter Array via Residual Image Reconstruction and Sparse Representation
Jul 04, 2013
A framework of demosaicing and superresolution for color filter array (CFA) via residual image reconstruction and sparse representation is presented.Given the intermediate image produced by certain demosaicing and interpolation technique, a residual image between the final reconstruction image and the intermediate image is reconstructed using sparse representation.The final reconstruction image has richer edges and details than that of the intermediate image. Specifically, a generic dictionary is learned from a large set of composite training data composed of intermediate data and residual data. The learned dictionary implies a mapping between the two data. A specific dictionary adaptive to the input CFA is learned thereafter. Using the adaptive dictionary, the sparse coefficients of intermediate data are computed and transformed to predict residual image. The residual image is added back into the intermediate image to obtain the final reconstruction image. Experimental results demonstrate the state-of-the-art performance in terms of PSNR and subjective visual perception.
A Privacy-Preserving Distributed Architecture for Deep-Learning-as-a-Service
Mar 30, 2020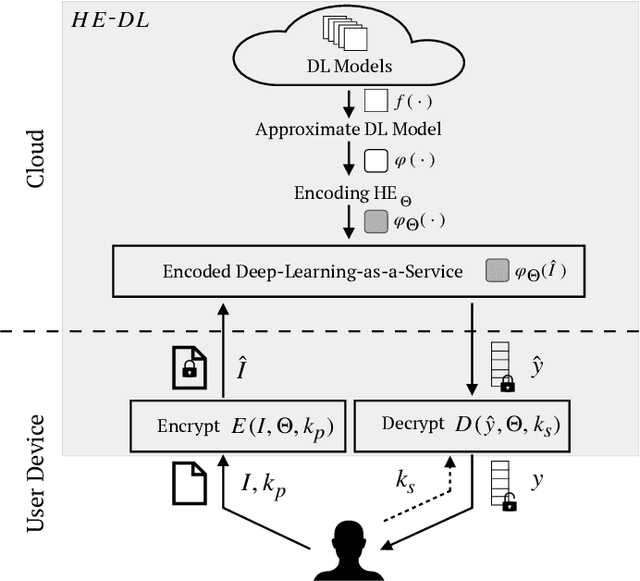

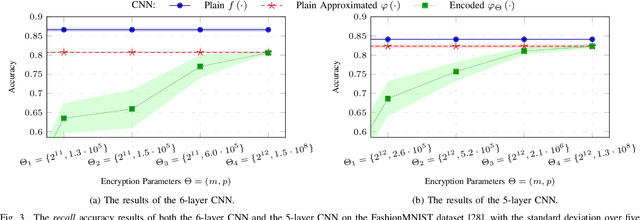
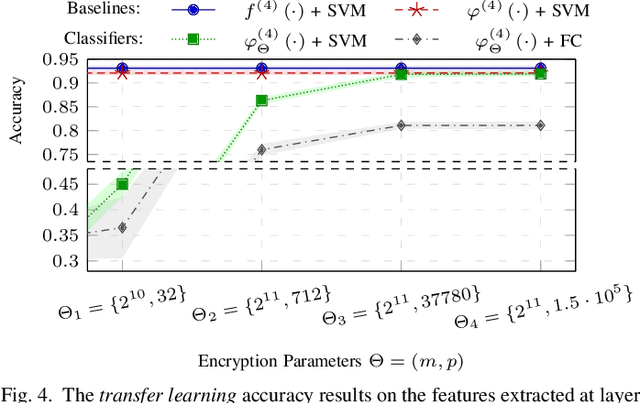
Deep-learning-as-a-service is a novel and promising computing paradigm aiming at providing machine/deep learning solutions and mechanisms through Cloud-based computing infrastructures. Thanks to its ability to remotely execute and train deep learning models (that typically require high computational loads and memory occupation), such an approach guarantees high performance, scalability, and availability. Unfortunately, such an approach requires to send information to be processed (e.g., signals, images, positions, sounds, videos) to the Cloud, hence having potentially catastrophic-impacts on the privacy of users. This paper introduces a novel distributed architecture for deep-learning-as-a-service that is able to preserve the user sensitive data while providing Cloud-based machine and deep learning services. The proposed architecture, which relies on Homomorphic Encryption that is able to perform operations on encrypted data, has been tailored for Convolutional Neural Networks (CNNs) in the domain of image analysis and implemented through a client-server REST-based approach. Experimental results show the effectiveness of the proposed architecture.
Feature-Area Optimization: A Novel SAR Image Registration Method
Feb 18, 2016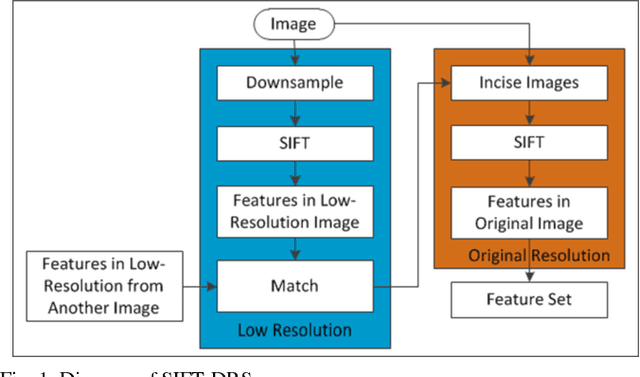
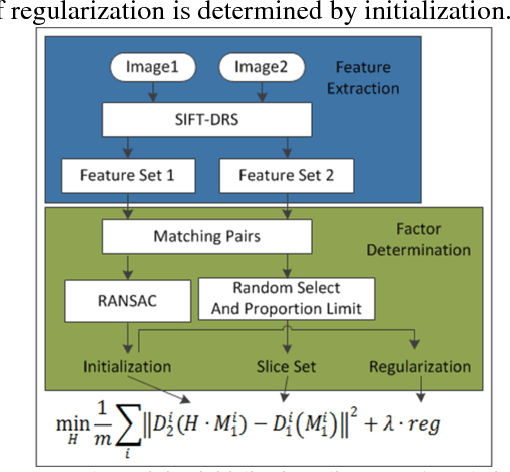
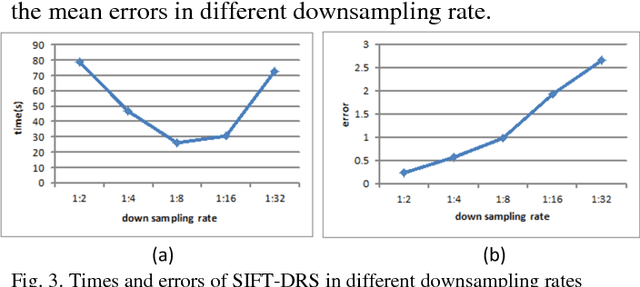
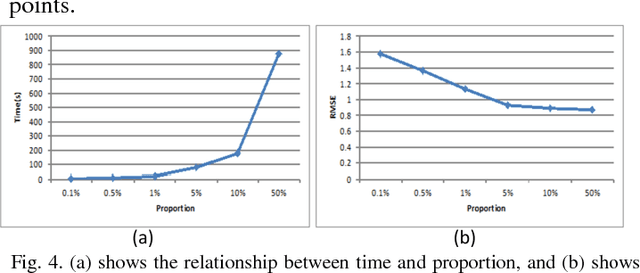
This letter proposes a synthetic aperture radar (SAR) image registration method named Feature-Area Optimization (FAO). First, the traditional area-based optimization model is reconstructed and decomposed into three key but uncertain factors: initialization, slice set and regularization. Next, structural features are extracted by scale invariant feature transform (SIFT) in dual-resolution space (SIFT-DRS), a novel SIFT-Like method dedicated to FAO. Then, the three key factors are determined based on these features. Finally, solving the factor-determined optimization model can get the registration result. A series of experiments demonstrate that the proposed method can register multi-temporal SAR images accurately and efficiently.
* 5 pages, 5 figures
Training with Quantization Noise for Extreme Fixed-Point Compression
Apr 15, 2020
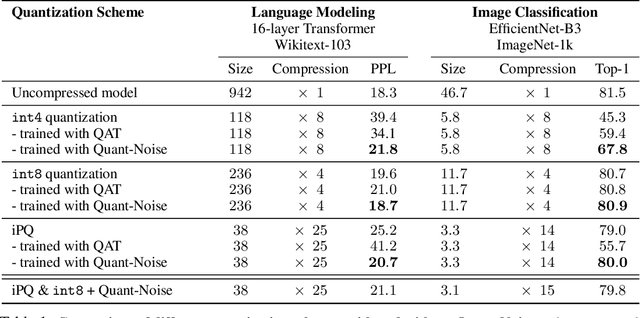
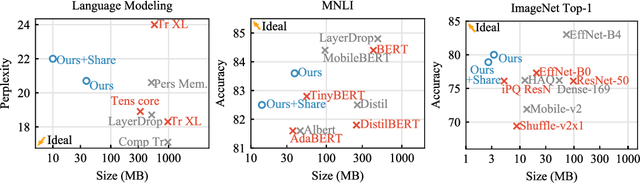
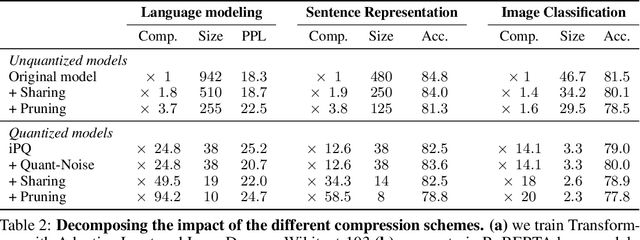
We tackle the problem of producing compact models, maximizing their accuracy for a given model size. A standard solution is to train networks with Quantization Aware Training, where the weights are quantized during training and the gradients approximated with the Straight-Through Estimator. In this paper, we extend this approach to work with extreme compression methods where the approximations introduced by STE are severe. Our proposal is to only quantize a different random subset of weights during each forward, allowing for unbiased gradients to flow through the other weights. Controlling the amount of noise and its form allows for extreme compression rates while maintaining the performance of the original model. As a result we establish new state-of-the-art compromises between accuracy and model size both in natural language processing and image classification. For example, applying our method to state-of-the-art Transformer and ConvNet architectures, we can achieve 82.5% accuracy on MNLI by compressing RoBERTa to 14MB and 80.0% top-1 accuracy on ImageNet by compressing an EfficientNet-B3 to 3.3MB.
Applications of Deep Learning for Ill-Posed Inverse Problems Within Optical Tomography
Mar 21, 2020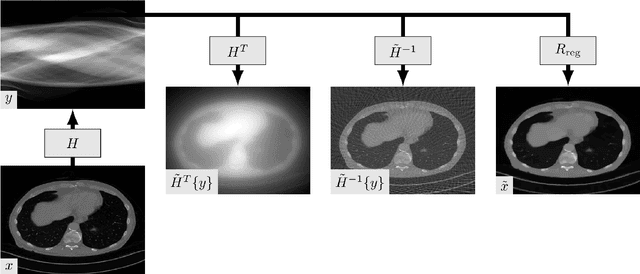
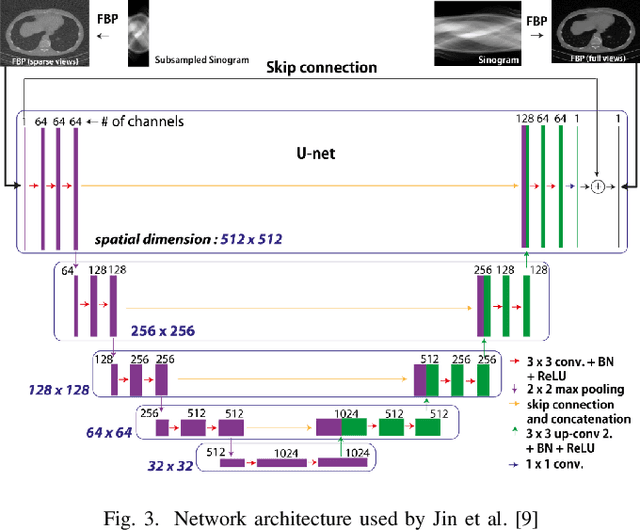
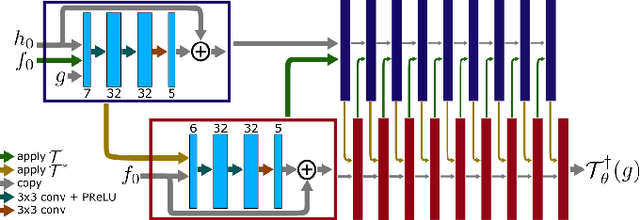
Increasingly in medical imaging has emerged an issue surrounding the reconstruction of noisy images from raw measurement data. Where the forward problem is the generation of raw measurement data from a ground truth image, the inverse problem is the reconstruction of those images from the measurement data. In most cases with medical imaging, classical inverse Radon transforms, such as an inverse Fourier transform for MRI, work well for recovering clean images from the measured data. Unfortunately in the case of X-Ray CT, where undersampled data is very common, more than this is needed to resolve faithful and usable images. In this paper, we explore the history of classical methods for solving the inverse problem for X-Ray CT, followed by an analysis of the state of the art methods that utilize supervised deep learning. Finally, we will provide some possible avenues for research in the future.
TapLab: A Fast Framework for Semantic Video Segmentation Tapping into Compressed-Domain Knowledge
Mar 30, 2020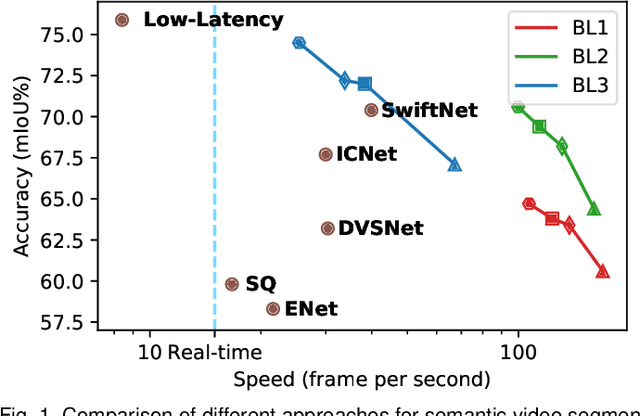
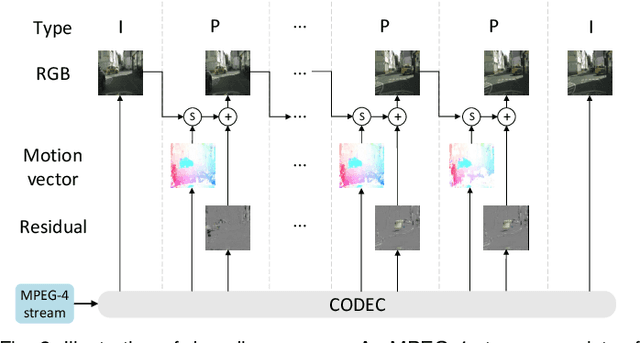

Real-time semantic video segmentation is a challenging task due to the strict requirements of inference speed. Recent approaches mainly devote great efforts to reducing the model size for high efficiency. In this paper, we rethink this problem from a different viewpoint: using knowledge contained in compressed videos. We propose a simple and effective framework, dubbed TapLab, to tap into resources from the compressed domain. Specifically, we design a fast feature warping module using motion vectors for acceleration. To reduce the noise introduced by motion vectors, we design a residual-guided correction module and a residual-guided frame selection module using residuals. Compared with the state-of-the-art fast semantic image segmentation models, our proposed TapLab significantly reduces redundant computations, running around 3 times faster with comparable accuracy for 1024x2048 video. The experimental results show that TapLab achieves 70.6% mIoU on the Cityscapes dataset at 99.8 FPS with a single GPU card. A high-speed version even reaches the speed of 160+ FPS.
A Hybrid Method for Training Convolutional Neural Networks
Apr 15, 2020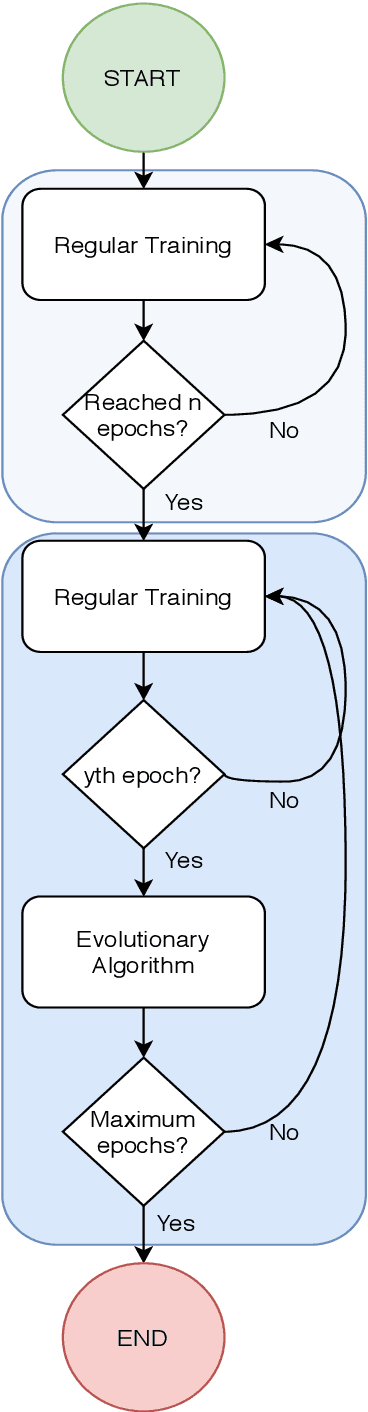
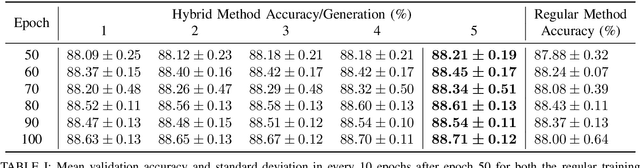

Artificial Intelligence algorithms have been steadily increasing in popularity and usage. Deep Learning, allows neural networks to be trained using huge datasets and also removes the need for human extracted features, as it automates the feature learning process. In the hearth of training deep neural networks, such as Convolutional Neural Networks, we find backpropagation, that by computing the gradient of the loss function with respect to the weights of the network for a given input, it allows the weights of the network to be adjusted to better perform in the given task. In this paper, we propose a hybrid method that uses both backpropagation and evolutionary strategies to train Convolutional Neural Networks, where the evolutionary strategies are used to help to avoid local minimas and fine-tune the weights, so that the network achieves higher accuracy results. We show that the proposed hybrid method is capable of improving upon regular training in the task of image classification in CIFAR-10, where a VGG16 model was used and the final test results increased 0.61%, in average, when compared to using only backpropagation.
Inverse Graphics: Unsupervised Learning of 3D Shapes from Single Images
Oct 31, 2019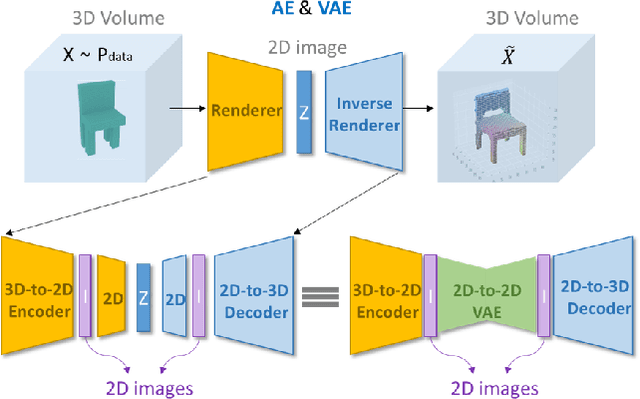

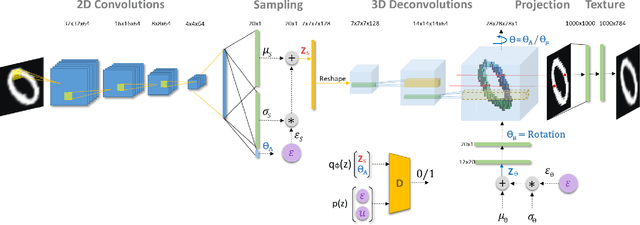
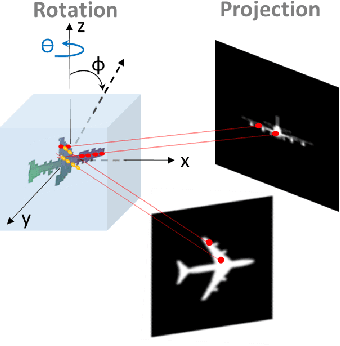
Using generative models for Inverse Graphics is an active area of research. However, most works focus on developing models for supervised and semi-supervised methods. In this paper, we study the problem of unsupervised learning of 3D geometry from single images. Our approach is to use a generative model that produces 2-D images as projections of a latent 3D voxel grid, which we train either as a variational auto-encoder or using adversarial methods. Our contributions are as follows: First, we show how to recover 3D shape and pose from general datasets such as MNIST, and MNIST Fashion in good quality. Second, we compare the shapes learned using adversarial and variational methods. Adversarial approach gives denser 3D shapes. Third, we explore the idea of modelling the pose of an object as uniform distribution to recover 3D shape from a single image. Our experiment with the CelebA dataset \cite{liu2015faceattributes} proves that we can recover complete 3D shape from a single image when the object is symmetric along one, or more axis whilst results obtained using ModelNet40 \cite{wu20153d} show the potential side-effects, in which the model learns 3D shapes such that it can render the same image from any viewpoint. Forth, we present a general end-to-end approach to learning 3D shapes from single images in a completely unsupervised fashion by modelling the factors of variation such as azimuth as independent latent variables. Our method makes no assumptions about the dataset, and can work with synthetic as well as real images (i.e. unsupervised in true sense). We present our results, by training the model using the $\mu$-VAE objective \cite{ucar2019bridging} and a dataset combining all images from MNIST, MNIST Fashion, CelebA and six categories of ModelNet40. The model is able to learn 3D shapes and the pose in qood quality and leverages information learned across all datasets.
This is not what I imagined: Error Detection for Semantic Segmentation through Visual Dissimilarity
Sep 02, 2019
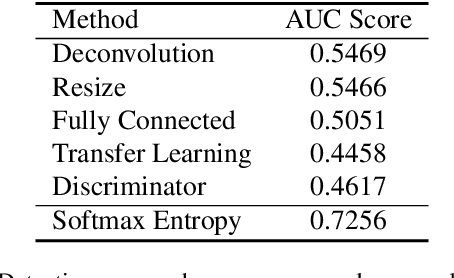
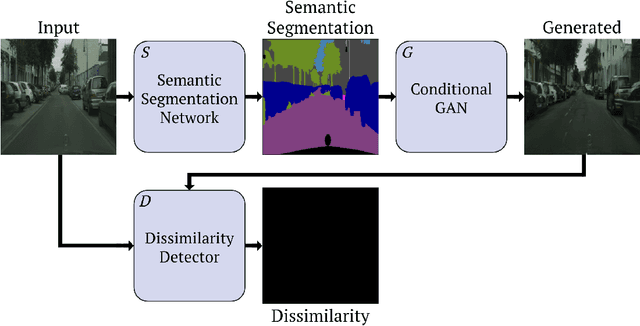
There has been a remarkable progress in the accuracy of semantic segmentation due to the capabilities of deep learning. Unfortunately, these methods are not able to generalize much further than the distribution of their training data and fail to handle out-of-distribution classes appropriately. This limits the applicability to autonomous or safety critical systems. We propose a novel method leveraging generative models to detect wrongly segmented or out-of-distribution instances. Conditioned on the predicted semantic segmentation, an RGB image is generated. We then learn a dissimilarity metric that compares the generated image with the original input and detects inconsistencies introduced by the semantic segmentation. We present test cases for outlier and misclassification detection and evaluate our method qualitatively and quantitatively on multiple datasets.
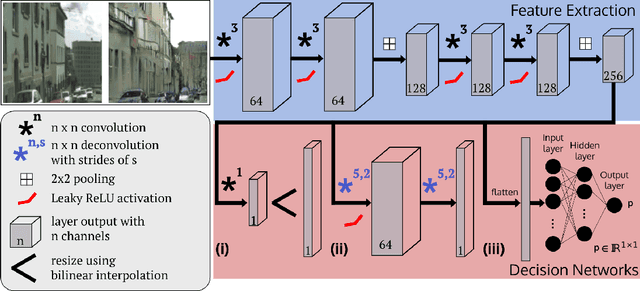
ERNet Family: Hardware-Oriented CNN Models for Computational Imaging Using Block-Based Inference
Oct 13, 2019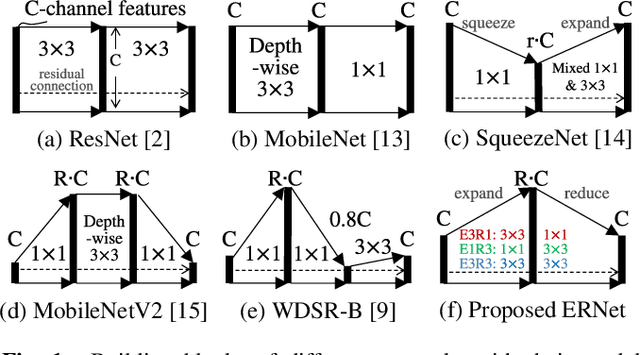
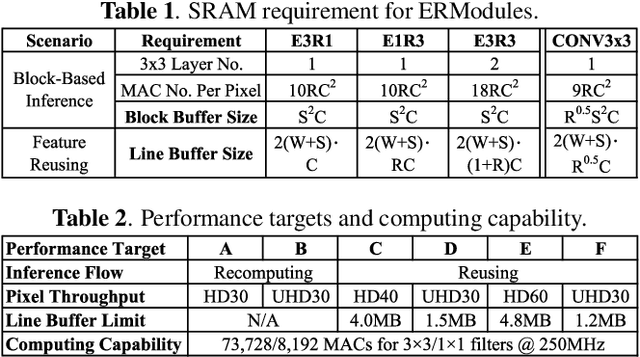
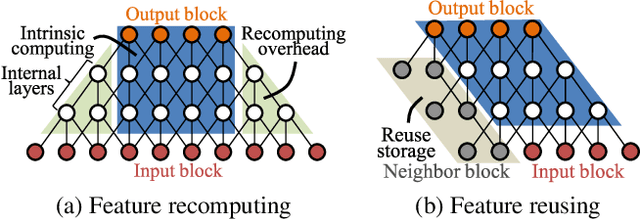
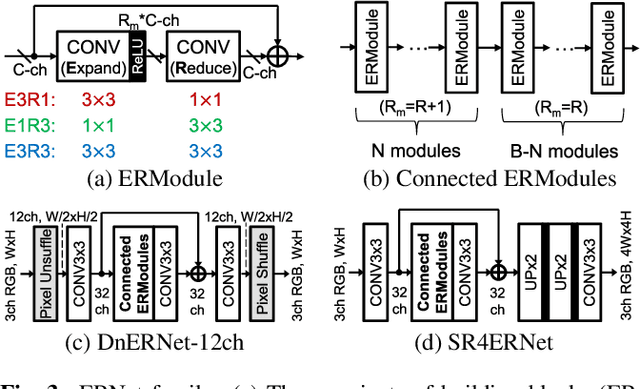
Convolutional neural networks (CNNs) demand huge DRAM bandwidth for computational imaging tasks, and block-based processing has recently been applied to greatly reduce the bandwidth. However, the induced additional computation for feature recomputing or the large SRAM for feature reusing will degrade the performance or even forbid the usage of state-of-the-art models. In this paper, we address these issues by considering the overheads and hardware constraints in advance when constructing CNNs. We investigate a novel model family---ERNet---which includes temporary layer expansion as another means for increasing model capacity. We analyze three ERNet variants in terms of hardware requirement and introduce a hardware-aware model optimization procedure. Evaluations on Full HD and 4K UHD applications will be given to show the effectiveness in terms of image quality, pixel throughput, and SRAM usage. The results also show that, for block-based inference, ERNet can outperform the state-of-the-art FFDNet and EDSR-baseline models for image denoising and super-resolution respectively.