 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards Deep Learning Methods for Quality Assessment of Computer-Generated Imagery
May 02, 2020
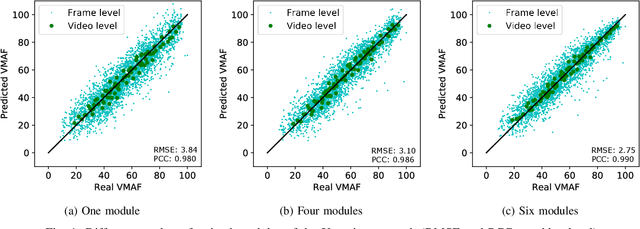
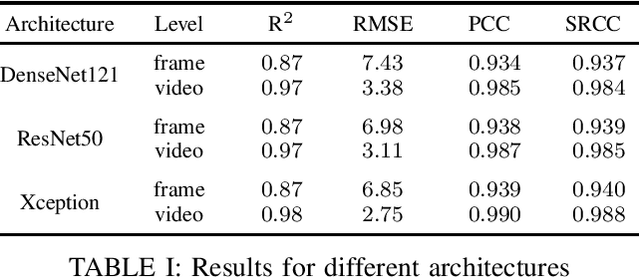
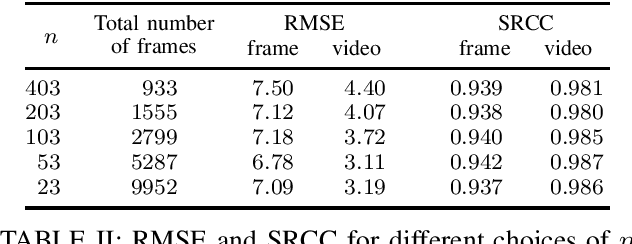
Video gaming streaming services are growing rapidly due to new services such as passive video streaming, e.g. Twitch.tv, and cloud gaming, e.g. Nvidia Geforce Now. In contrast to traditional video content, gaming content has special characteristics such as extremely high motion for some games, special motion patterns, synthetic content and repetitive content, which makes the state-of-the-art video and image quality metrics perform weaker for this special computer generated content. In this paper, we outline our plan to build a deep learningbased quality metric for video gaming quality assessment. In addition, we present initial results by training the network based on VMAF values as a ground truth to give some insights on how to build a metric in future. The paper describes the method that is used to choose an appropriate Convolutional Neural Network architecture. Furthermore, we estimate the size of the required subjective quality dataset which achieves a sufficiently high performance. The results show that by taking around 5k images for training of the last six modules of Xception, we can obtain a relatively high performance metric to assess the quality of distorted video games.
This is not what I imagined: Error Detection for Semantic Segmentation through Visual Dissimilarity
Sep 02, 2019
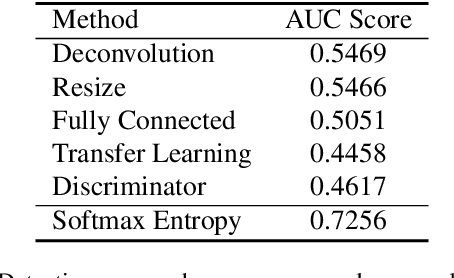
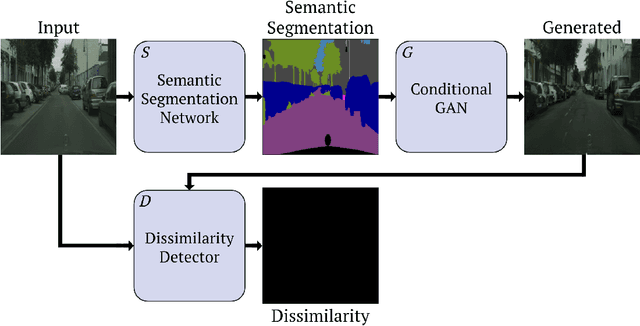
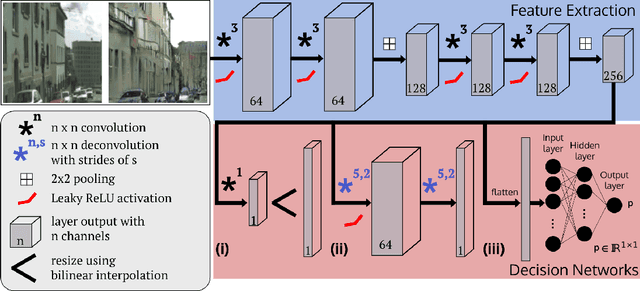
There has been a remarkable progress in the accuracy of semantic segmentation due to the capabilities of deep learning. Unfortunately, these methods are not able to generalize much further than the distribution of their training data and fail to handle out-of-distribution classes appropriately. This limits the applicability to autonomous or safety critical systems. We propose a novel method leveraging generative models to detect wrongly segmented or out-of-distribution instances. Conditioned on the predicted semantic segmentation, an RGB image is generated. We then learn a dissimilarity metric that compares the generated image with the original input and detects inconsistencies introduced by the semantic segmentation. We present test cases for outlier and misclassification detection and evaluate our method qualitatively and quantitatively on multiple datasets.
Training with Quantization Noise for Extreme Model Compression
Apr 17, 2020
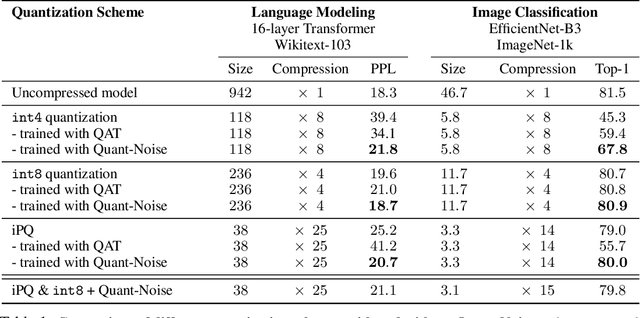
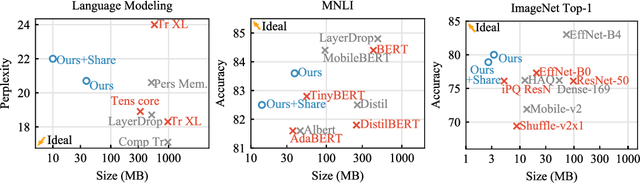
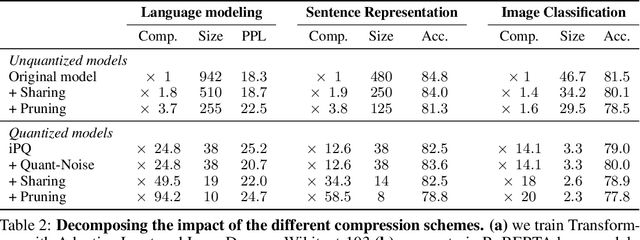
We tackle the problem of producing compact models, maximizing their accuracy for a given model size. A standard solution is to train networks with Quantization Aware Training, where the weights are quantized during training and the gradients approximated with the Straight-Through Estimator. In this paper, we extend this approach to work beyond int8 fixed-point quantization with extreme compression methods where the approximations introduced by STE are severe, such as Product Quantization. Our proposal is to only quantize a different random subset of weights during each forward, allowing for unbiased gradients to flow through the other weights. Controlling the amount of noise and its form allows for extreme compression rates while maintaining the performance of the original model. As a result we establish new state-of-the-art compromises between accuracy and model size both in natural language processing and image classification. For example, applying our method to state-of-the-art Transformer and ConvNet architectures, we can achieve 82.5% accuracy on MNLI by compressing RoBERTa to 14MB and 80.0 top-1 accuracy on ImageNet by compressing an EfficientNet-B3 to 3.3MB.
StyleRig: Rigging StyleGAN for 3D Control over Portrait Images
Mar 31, 2020
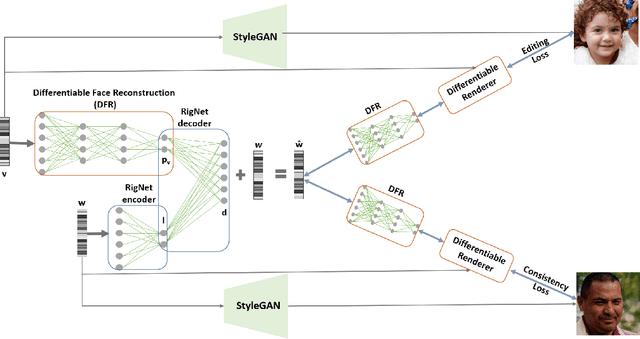
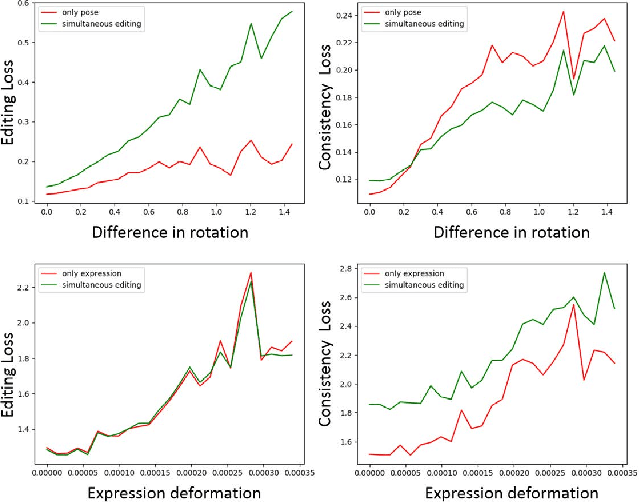

StyleGAN generates photorealistic portrait images of faces with eyes, teeth, hair and context (neck, shoulders, background), but lacks a rig-like control over semantic face parameters that are interpretable in 3D, such as face pose, expressions, and scene illumination. Three-dimensional morphable face models (3DMMs) on the other hand offer control over the semantic parameters, but lack photorealism when rendered and only model the face interior, not other parts of a portrait image (hair, mouth interior, background). We present the first method to provide a face rig-like control over a pretrained and fixed StyleGAN via a 3DMM. A new rigging network, RigNet is trained between the 3DMM's semantic parameters and StyleGAN's input. The network is trained in a self-supervised manner, without the need for manual annotations. At test time, our method generates portrait images with the photorealism of StyleGAN and provides explicit control over the 3D semantic parameters of the face.
Automatic Image Segmentation by Dynamic Region Merging
Dec 06, 2010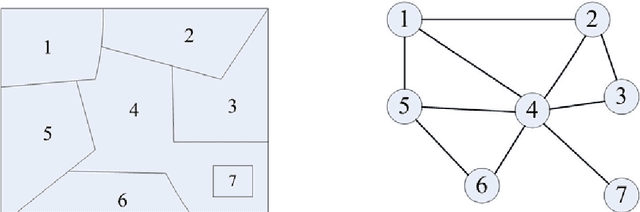


This paper addresses the automatic image segmentation problem in a region merging style. With an initially over-segmented image, in which the many regions (or super-pixels) with homogeneous color are detected, image segmentation is performed by iteratively merging the regions according to a statistical test. There are two essential issues in a region merging algorithm: order of merging and the stopping criterion. In the proposed algorithm, these two issues are solved by a novel predicate, which is defined by the sequential probability ratio test (SPRT) and the maximum likelihood criterion. Starting from an over-segmented image, neighboring regions are progressively merged if there is an evidence for merging according to this predicate. We show that the merging order follows the principle of dynamic programming. This formulates image segmentation as an inference problem, where the final segmentation is established based on the observed image. We also prove that the produced segmentation satisfies certain global properties. In addition, a faster algorithm is developed to accelerate the region merging process, which maintains a nearest neighbor graph in each iteration. Experiments on real natural images are conducted to demonstrate the performance of the proposed dynamic region merging algorithm.
Robust binary classification with the 01 loss
Feb 09, 2020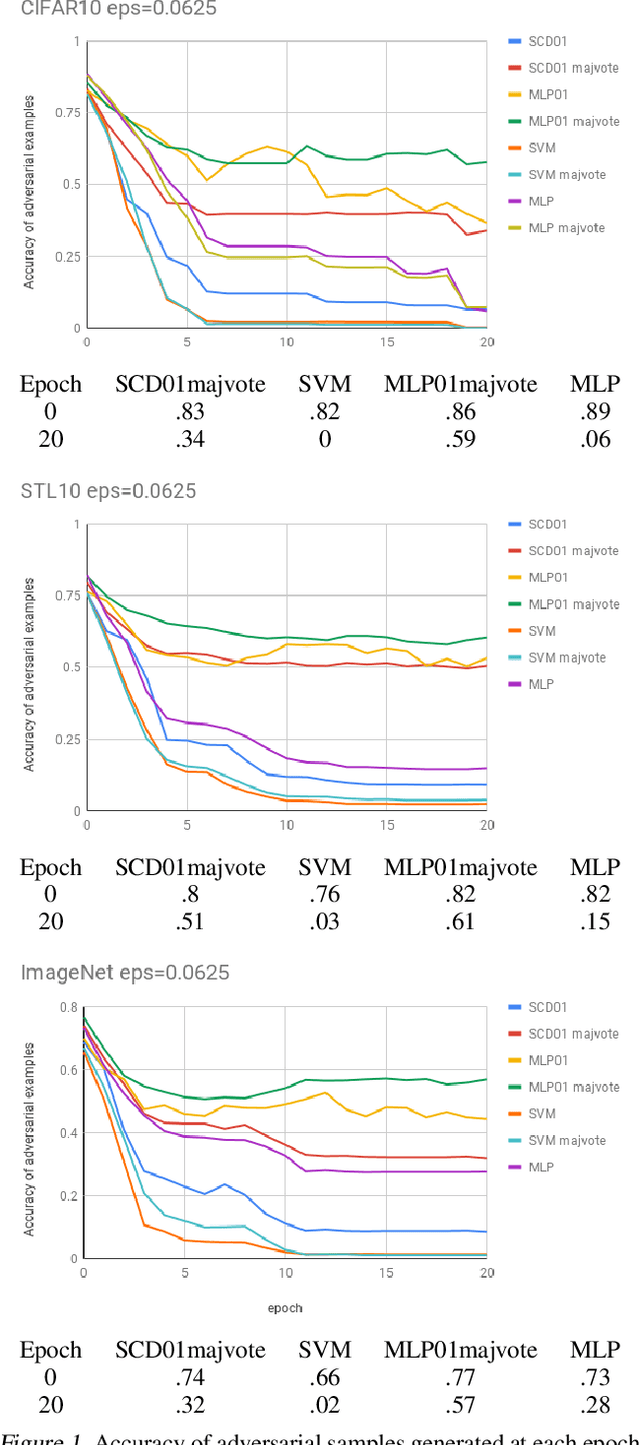
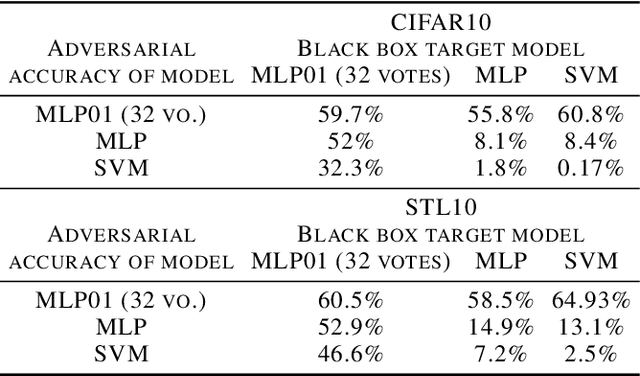

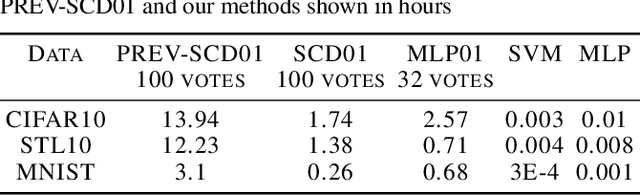
The 01 loss is robust to outliers and tolerant to noisy data compared to convex loss functions. We conjecture that the 01 loss may also be more robust to adversarial attacks. To study this empirically we have developed a stochastic coordinate descent algorithm for a linear 01 loss classifier and a single hidden layer 01 loss neural network. Due to the absence of the gradient we iteratively update coordinates on random subsets of the data for fixed epochs. We show our algorithms to be fast and comparable in accuracy to the linear support vector machine and logistic loss single hidden layer network for binary classification on several image benchmarks, thus establishing that our method is on-par in test accuracy with convex losses. We then subject them to accurately trained substitute model black box attacks on the same image benchmarks and find them to be more robust than convex counterparts. On CIFAR10 binary classification task between classes 0 and 1 with adversarial perturbation of 0.0625 we see that the MLP01 network loses 27\% in accuracy whereas the MLP-logistic counterpart loses 83\%. Similarly on STL10 and ImageNet binary classification between classes 0 and 1 the MLP01 network loses 21\% and 20\% while MLP-logistic loses 67\% and 45\% respectively. On MNIST that is a well-separable dataset we find MLP01 comparable to MLP-logistic and show under simulation how and why our 01 loss solver is less robust there. We then propose adversarial training for our linear 01 loss solver that significantly improves its robustness on MNIST and all other datasets and retains clean test accuracy. Finally we show practical applications of our method to deter traffic sign and facial recognition adversarial attacks. We discuss attacks with 01 loss, substitute model accuracy, and several future avenues like multiclass, 01 loss convolutions, and further adversarial training.
What Information Does a ResNet Compress?
Mar 13, 2020
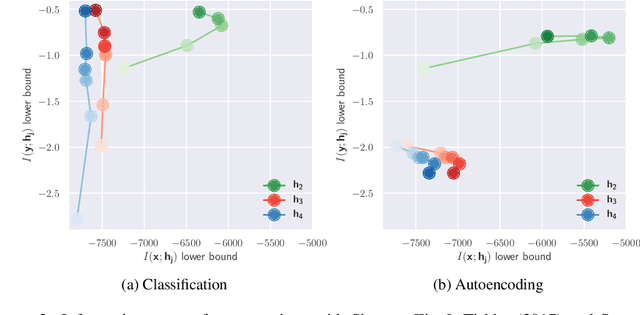
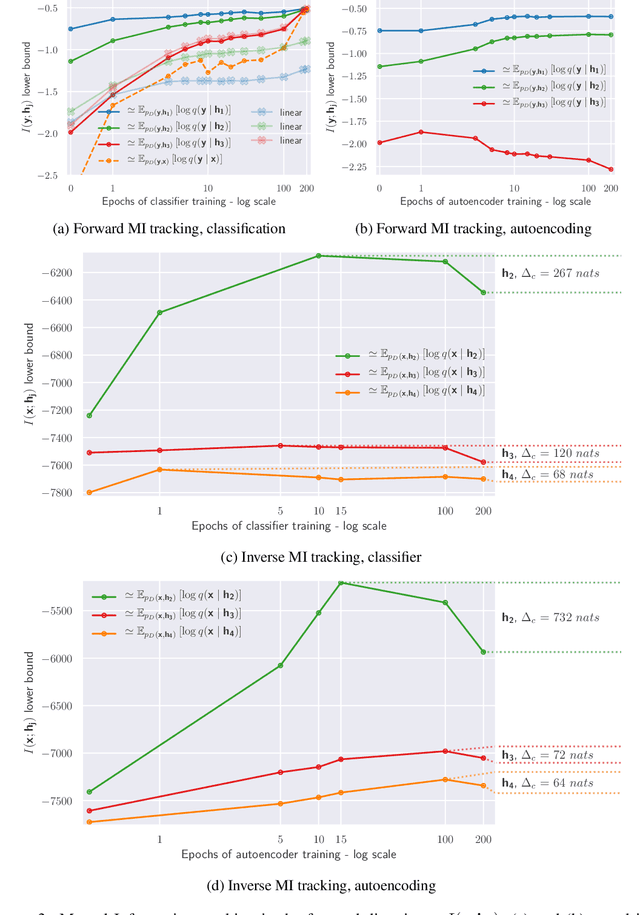
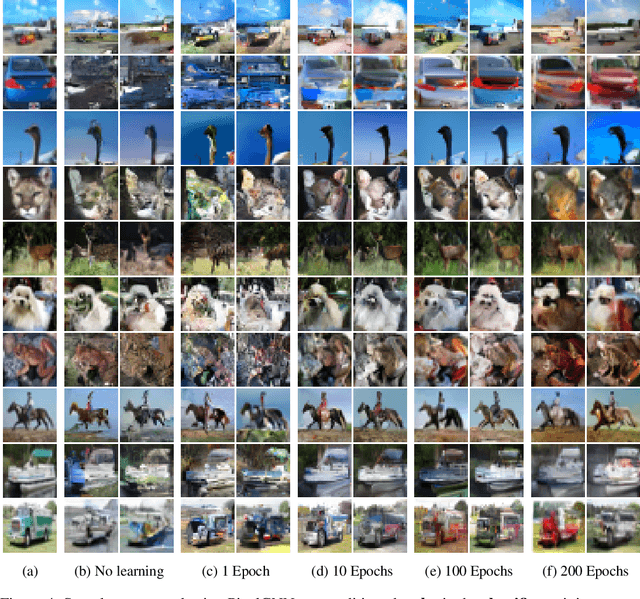
The information bottleneck principle (Shwartz-Ziv & Tishby, 2017) suggests that SGD-based training of deep neural networks results in optimally compressed hidden layers, from an information theoretic perspective. However, this claim was established on toy data. The goal of the work we present here is to test whether the information bottleneck principle is applicable to a realistic setting using a larger and deeper convolutional architecture, a ResNet model. We trained PixelCNN++ models as inverse representation decoders to measure the mutual information between hidden layers of a ResNet and input image data, when trained for (1) classification and (2) autoencoding. We find that two stages of learning happen for both training regimes, and that compression does occur, even for an autoencoder. Sampling images by conditioning on hidden layers' activations offers an intuitive visualisation to understand what a ResNets learns to forget.
Dynamic Domain Classification for Fractal Image Compression
May 20, 2012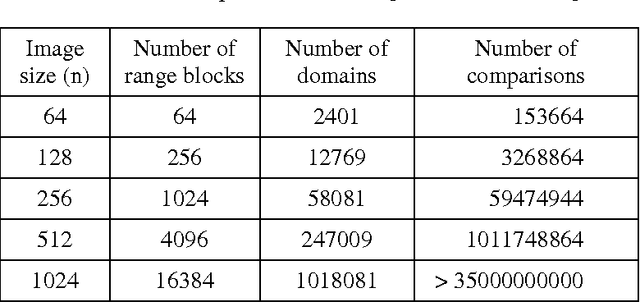

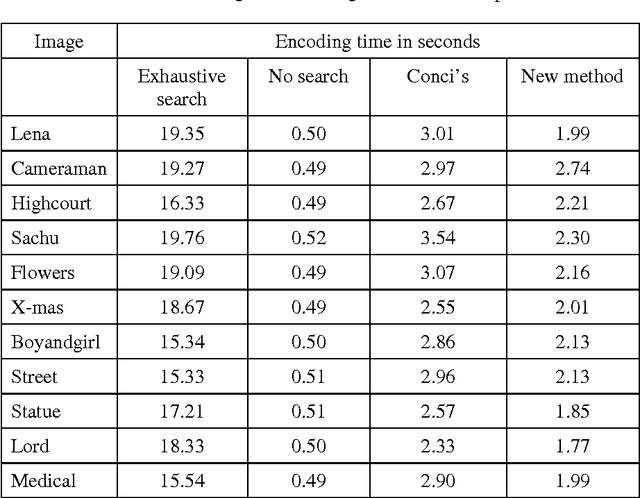
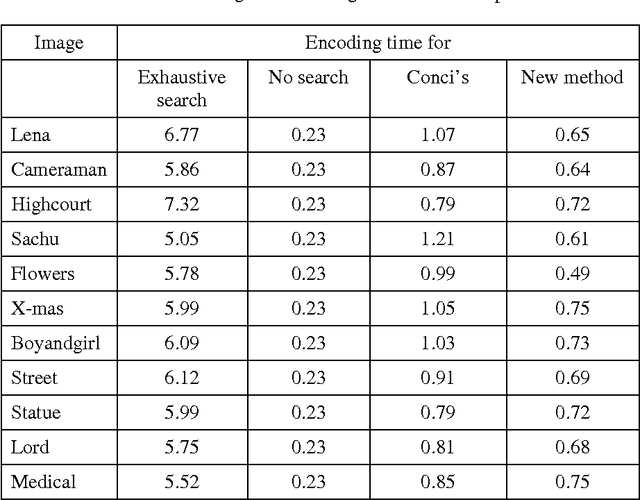
Fractal image compression is attractive except for its high encoding time requirements. The image is encoded as a set of contractive affine transformations. The image is partitioned into non-overlapping range blocks, and a best matching domain block larger than the range block is identified. There are many attempts on improving the encoding time by reducing the size of search pool for range-domain matching. But these methods are attempting to prepare a static domain pool that remains unchanged throughout the encoding process. This paper proposes dynamic preparation of separate domain pool for each range block. This will result in significant reduction in the encoding time. The domain pool for a particular range block can be selected based upon a parametric value. Here we use classification based on local fractal dimension.
Quantum Edge Detection for Image Segmentation in Optical Environments
Sep 09, 2014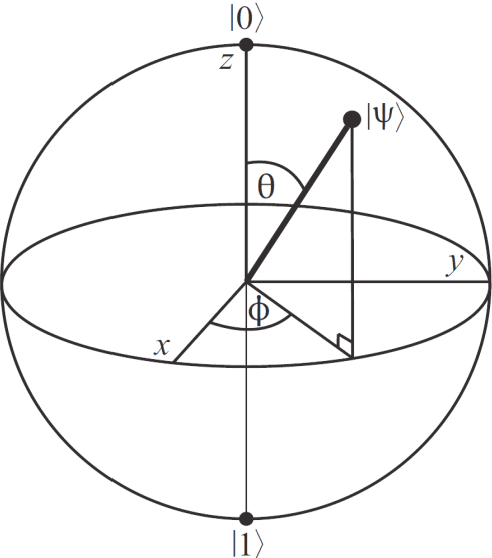
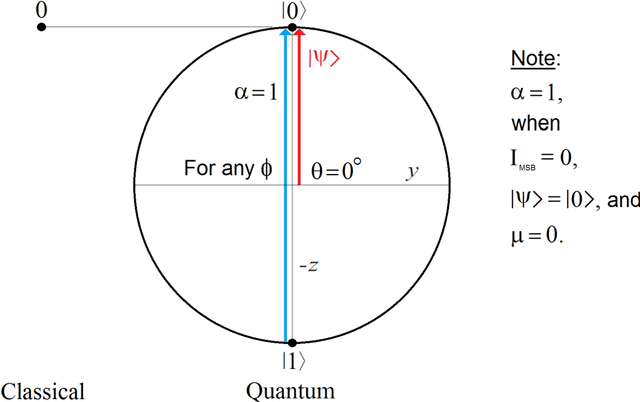
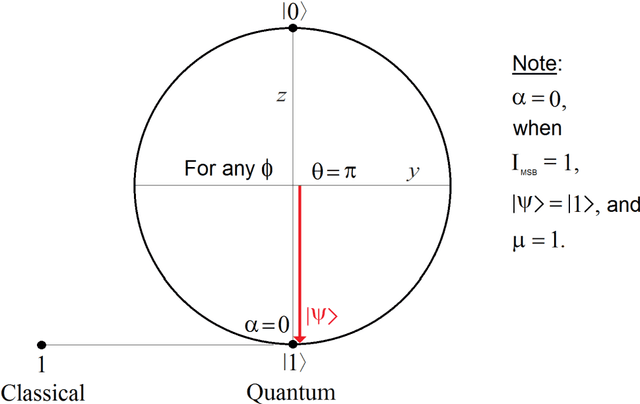
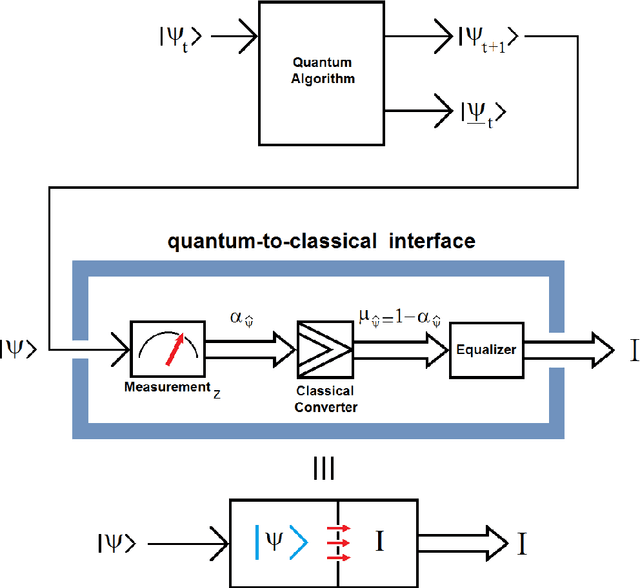
A quantum edge detector for image segmentation in optical environments is presented in this work. A Boolean version of the same detector is presented too. The quantum version of the new edge detector works with computational basis states, exclusively. This way, we can easily avoid the problem of quantum measurement retrieving the result of applying the new detector on the image. Besides, a new criterion and logic based on projections onto vertical axis of Bloch's Sphere exclusively are presented too. This approach will allow us: 1) a simpler development of logic quantum operations, where they will closer to those used in the classical logic operations, 2) building simple and robust classical-to-quantum and quantum-to-classical interfaces. Said so far is extended to quantum algorithms outside image processing too. In a special section on metric and simulations, a new metric based on the comparison between the classical and quantum versions algorithms for edge detection of images is presented. Notable differences between the results of classical and quantum versions of such algorithms (outside and inside of quantum computer, respectively) show the existence of implementation problems involved in the experiment, and that they have not been properly modeled for optical environments. However, although they are different, the quantum results are equally valid. The latter is clearly seen in the computer simulations
Binary Neural Networks: A Survey
Mar 31, 2020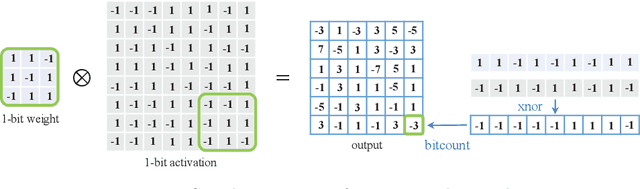
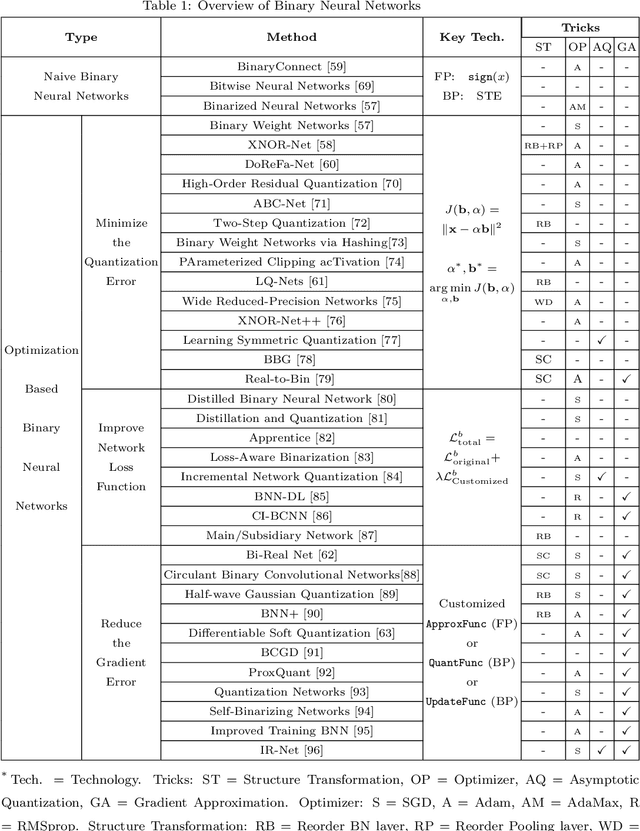
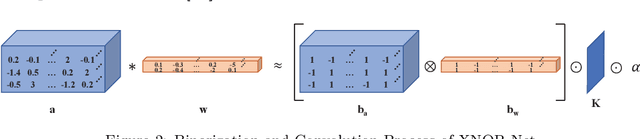
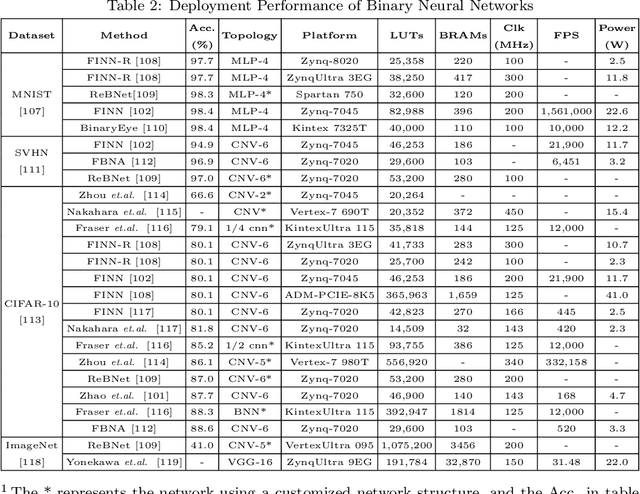
The binary neural network, largely saving the storage and computation, serves as a promising technique for deploying deep models on resource-limited devices. However, the binarization inevitably causes severe information loss, and even worse, its discontinuity brings difficulty to the optimization of the deep network. To address these issues, a variety of algorithms have been proposed, and achieved satisfying progress in recent years. In this paper, we present a comprehensive survey of these algorithms, mainly categorized into the native solutions directly conducting binarization, and the optimized ones using techniques like minimizing the quantization error, improving the network loss function, and reducing the gradient error. We also investigate other practical aspects of binary neural networks such as the hardware-friendly design and the training tricks. Then, we give the evaluation and discussions on different tasks, including image classification, object detection and semantic segmentation. Finally, the challenges that may be faced in future research are prospected.