 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
On a new formulation of nonlocal image filters involving the relative rearrangement
Jun 27, 2014
Nonlocal filters are simple and powerful techniques for image denoising. In this paper we study the reformulation of a broad class of nonlocal filters in terms of two functional rearrangements: the decreasing and the relative rearrangements. Independently of the dimension of the image, we reformulate these filters as integral operators defined in a one-dimensional space corresponding to the level sets measures. We prove the equivalency between the original and the rearranged versions of the filters and propose a discretization in terms of constant-wise interpolators, which we prove to be convergent to the solution of the continuous setting. For some particular cases, this new formulation allows us to perform a detailed analysis of the filtering properties. Among others, we prove that the filtered image is a contrast change of the original image, and that the filtering procedure behaves asymptotically as a shock filter combined with a border diffusive term, responsible for the staircaising effect and the loss of contrast.
Globally-Aware Multiple Instance Classifier for Breast Cancer Screening
Jun 07, 2019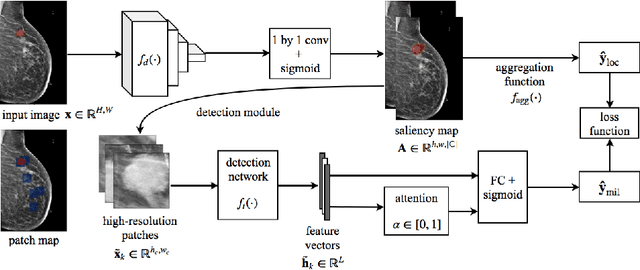
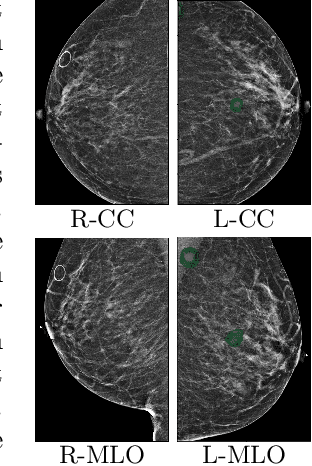
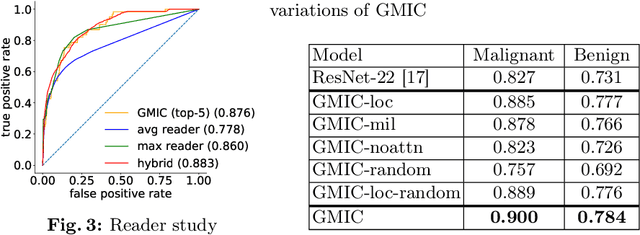
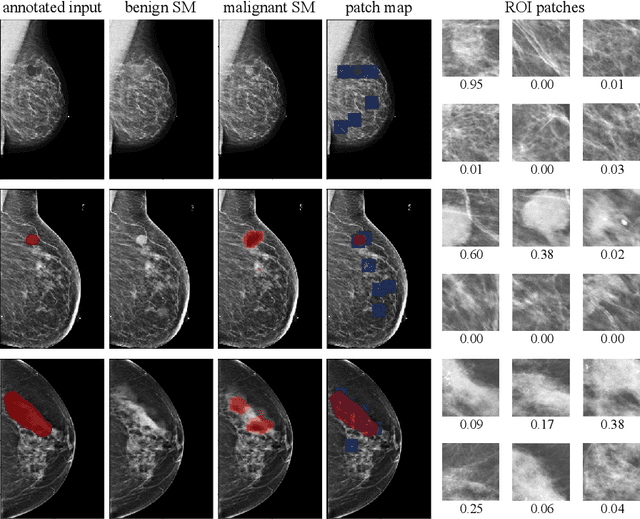
Deep learning models designed for visual classification tasks on natural images have become prevalent in medical image analysis. However, medical images differ from typical natural images in many ways, such as significantly higher resolutions and smaller regions of interest. Moreover, both the global structure and local details play important roles in medical image analysis tasks. To address these unique properties of medical images, we propose a neural network that is able to classify breast cancer lesions utilizing information from both a global saliency map and multiple local patches. The proposed model outperforms the ResNet-based baseline and achieves radiologist-level performance in the interpretation of screening mammography. Although our model is trained only with image-level labels, it is able to generate pixel-level saliency maps that provide localization of possible malignant findings.
End-to-End Learned Random Walker for Seeded Image Segmentation
May 22, 2019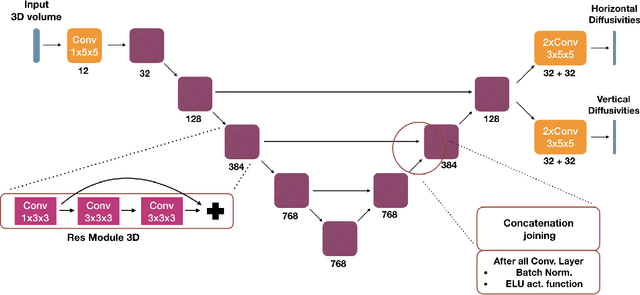

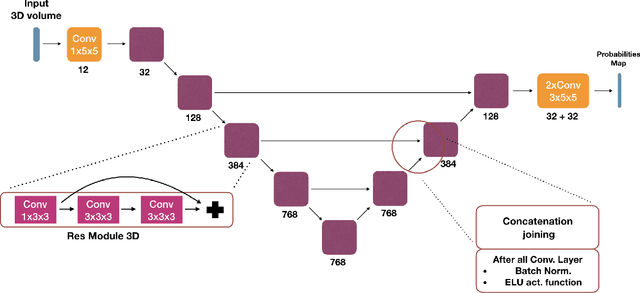
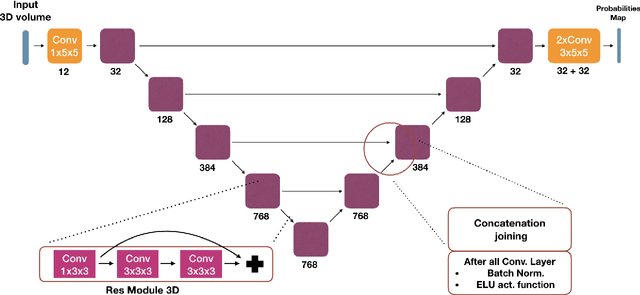
We present an end-to-end learned algorithm for seeded segmentation. Our method is based on the Random Walker algorithm, where we predict the edge weights of the underlying graph using a convolutional neural network. This can be interpreted as learning context-dependent diffusivities for a linear diffusion process. Besides calculating the exact gradient for optimizing these diffusivities, we also propose simplifications that sparsely sample the gradient and still yield competitive results. The proposed method achieves the currently best results on a seeded version of the CREMI neuron segmentation challenge.
Perceptually-based single-image depth super-resolution
Dec 24, 2018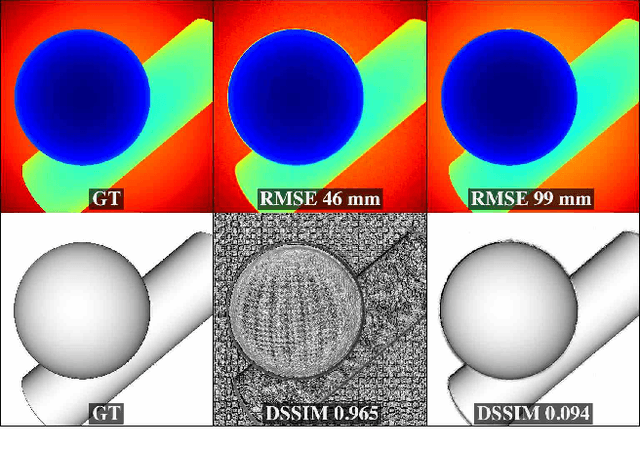
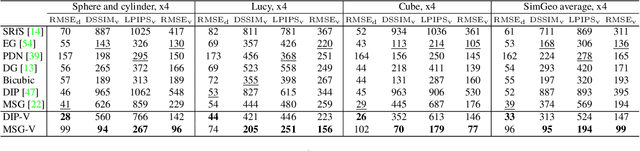

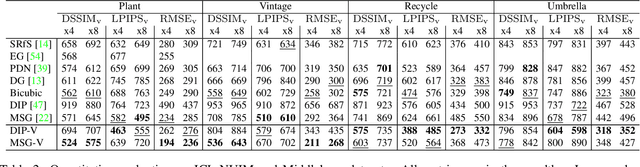
RGBD images, combining high-resolution color and lower-resolution depth from various types of depth sensors, are increasingly common. One can significantly improve the resolution of depth images by taking advantage of color information; deep learning methods make combining color and depth information particularly easy. However, fusing these two sources of data may lead to a variety of artifacts. If depth maps are used to reconstruct 3D shapes, e.g., for virtual reality applications, the visual quality of upsampled images is particularly important. To achieve high-quality results, visual metric need to be taken into account. The main idea of our approach is to measure the quality of depth map upsampling using renderings of resulting 3D surfaces. We demonstrate that a simple visual appearance-based loss, when used with either a trained CNN or simply a deep prior, yields significantly improved 3D shapes, as measured by a number of existing perceptual metrics. We compare this approach with a number of existing optimization and learning-based techniques.
Efficient Blind Deblurring under High Noise Levels
May 16, 2019


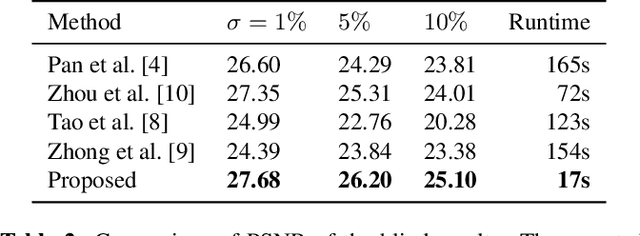
The goal of blind image deblurring is to recover a sharp image from a motion blurred one without knowing the camera motion. Current state-of-the-art methods have a remarkably good performance on images with no noise or very low noise levels. However, the noiseless assumption is not realistic considering that low light conditions are the main reason for the presence of motion blur due to requiring longer exposure times. In fact, motion blur and high to moderate noise often appear together. Most works approach this problem by first estimating the blur kernel $k$ and then deconvolving the noisy blurred image. In this work, we first show that current state-of-the-art kernel estimation methods based on the $\ell_0$ gradient prior can be adapted to handle high noise levels while keeping their efficiency. Then, we show that a fast non-blind deconvolution method can be significantly improved by first denoising the blurry image. The proposed approach yields results that are equivalent to those obtained with much more computationally demanding methods.
Automatic Image Segmentation by Dynamic Region Merging
Dec 06, 2010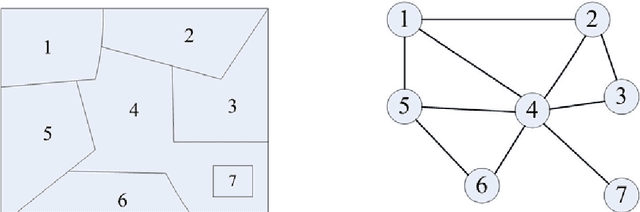

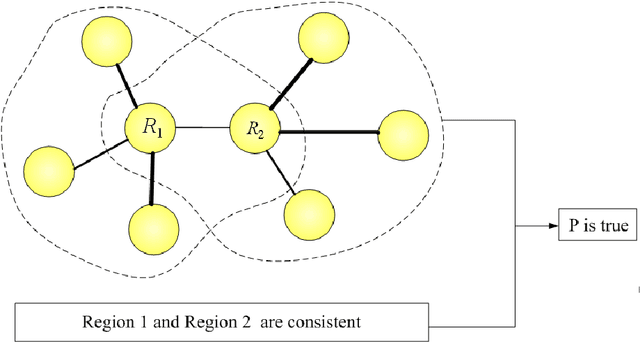

This paper addresses the automatic image segmentation problem in a region merging style. With an initially over-segmented image, in which the many regions (or super-pixels) with homogeneous color are detected, image segmentation is performed by iteratively merging the regions according to a statistical test. There are two essential issues in a region merging algorithm: order of merging and the stopping criterion. In the proposed algorithm, these two issues are solved by a novel predicate, which is defined by the sequential probability ratio test (SPRT) and the maximum likelihood criterion. Starting from an over-segmented image, neighboring regions are progressively merged if there is an evidence for merging according to this predicate. We show that the merging order follows the principle of dynamic programming. This formulates image segmentation as an inference problem, where the final segmentation is established based on the observed image. We also prove that the produced segmentation satisfies certain global properties. In addition, a faster algorithm is developed to accelerate the region merging process, which maintains a nearest neighbor graph in each iteration. Experiments on real natural images are conducted to demonstrate the performance of the proposed dynamic region merging algorithm.
A Hierarchical Deep Convolutional Neural Network and Gated Recurrent Unit Framework for Structural Damage Detection
May 29, 2020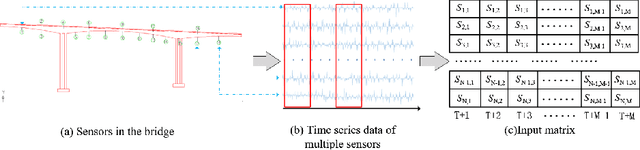

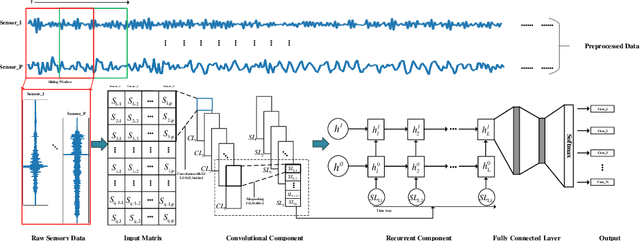

Structural damage detection has become an interdisciplinary area of interest for various engineering fields, while the available damage detection methods are being in the process of adapting machine learning concepts. Most machine learning based methods heavily depend on extracted ``hand-crafted" features that are manually selected in advance by domain experts and then, fixed. Recently, deep learning has demonstrated remarkable performance on traditional challenging tasks, such as image classification, object detection, etc., due to the powerful feature learning capabilities. This breakthrough has inspired researchers to explore deep learning techniques for structural damage detection problems. However, existing methods have considered either spatial relation (e.g., using convolutional neural network (CNN)) or temporal relation (e.g., using long short term memory network (LSTM)) only. In this work, we propose a novel Hierarchical CNN and Gated recurrent unit (GRU) framework to model both spatial and temporal relations, termed as HCG, for structural damage detection. Specifically, CNN is utilized to model the spatial relations and the short-term temporal dependencies among sensors, while the output features of CNN are fed into the GRU to learn the long-term temporal dependencies jointly. Extensive experiments on IASC-ASCE structural health monitoring benchmark and scale model of three-span continuous rigid frame bridge structure datasets have shown that our proposed HCG outperforms other existing methods for structural damage detection significantly.
Dynamic Domain Classification for Fractal Image Compression
May 20, 2012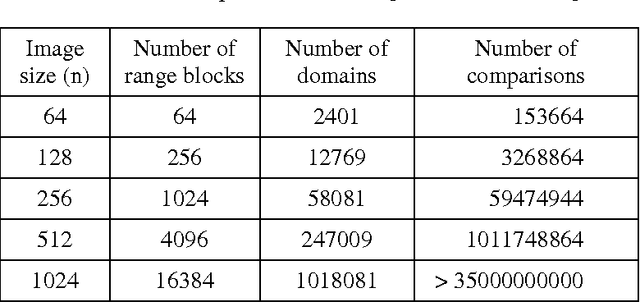

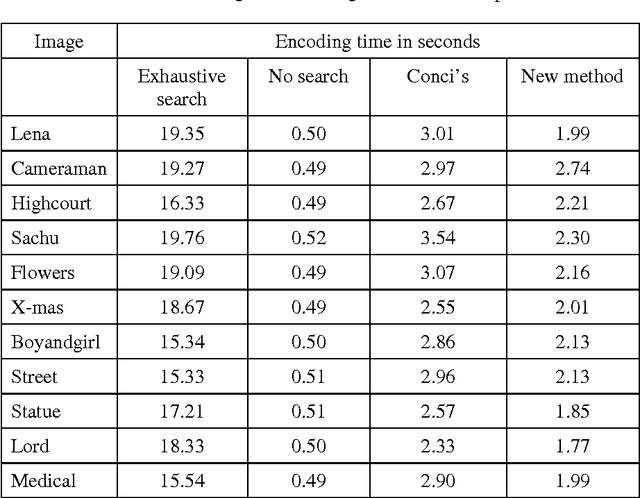
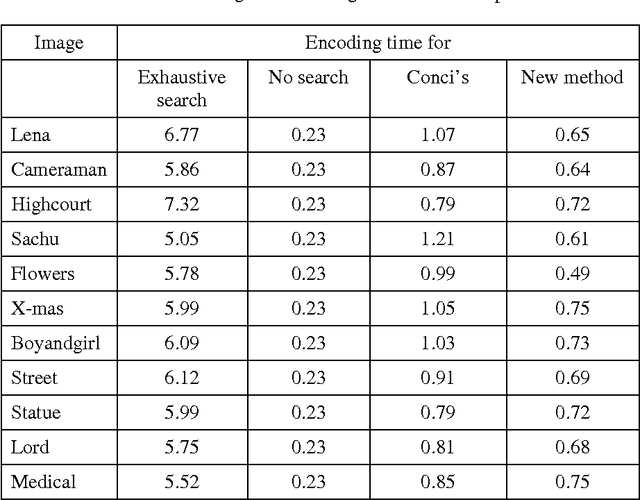
Fractal image compression is attractive except for its high encoding time requirements. The image is encoded as a set of contractive affine transformations. The image is partitioned into non-overlapping range blocks, and a best matching domain block larger than the range block is identified. There are many attempts on improving the encoding time by reducing the size of search pool for range-domain matching. But these methods are attempting to prepare a static domain pool that remains unchanged throughout the encoding process. This paper proposes dynamic preparation of separate domain pool for each range block. This will result in significant reduction in the encoding time. The domain pool for a particular range block can be selected based upon a parametric value. Here we use classification based on local fractal dimension.
Distilled Hierarchical Neural Ensembles with Adaptive Inference Cost
Apr 01, 2020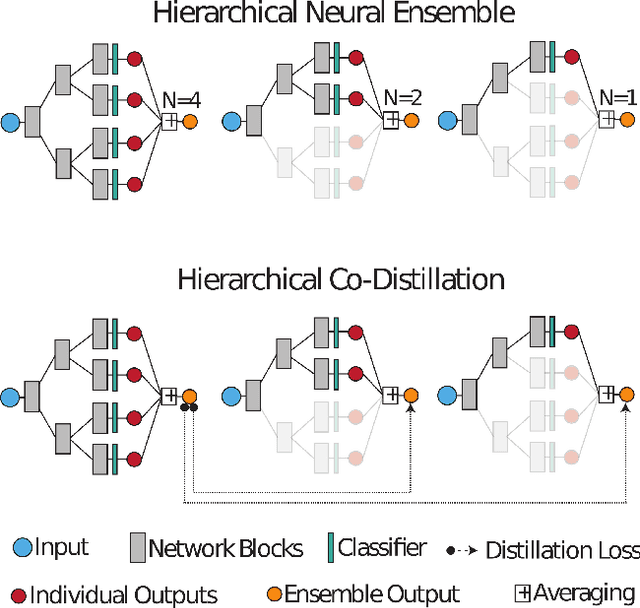
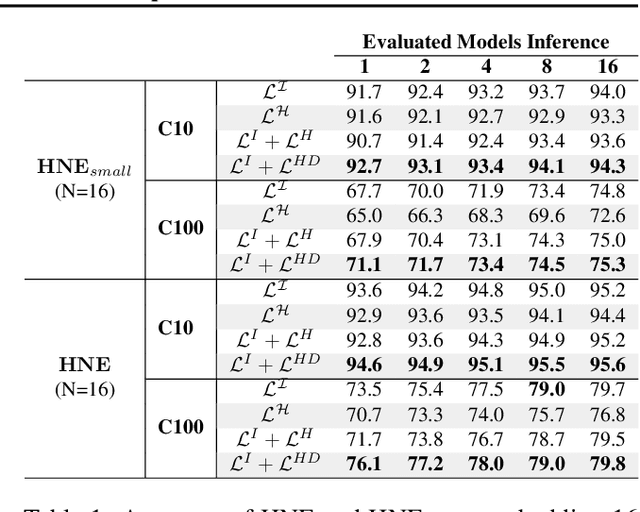
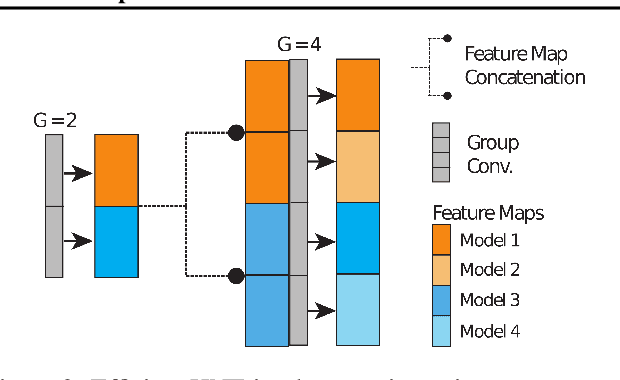
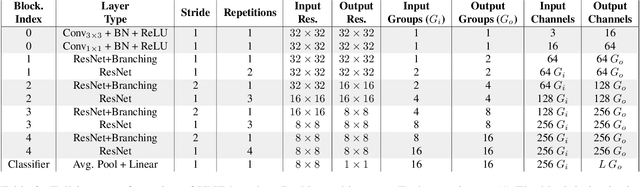
Deep neural networks form the basis of state-of-the-art models across a variety of application domains. Moreover, networks that are able to dynamically adapt the computational cost of inference are important in scenarios where the amount of compute or input data varies over time. In this paper, we propose Hierarchical Neural Ensembles (HNE), a novel framework to embed an ensemble of multiple networks by sharing intermediate layers using a hierarchical structure. In HNE we control the inference cost by evaluating only a subset of models, which are organized in a nested manner. Our second contribution is a novel co-distillation method to boost the performance of ensemble predictions with low inference cost. This approach leverages the nested structure of our ensembles, to optimally allocate accuracy and diversity across the ensemble members. Comprehensive experiments over the CIFAR and ImageNet datasets confirm the effectiveness of HNE in building deep networks with adaptive inference cost for image classification.
Protecting GANs against privacy attacks by preventing overfitting
Jan 03, 2020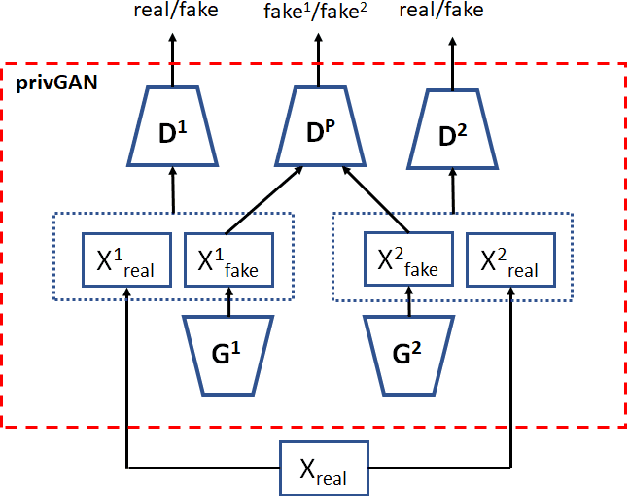


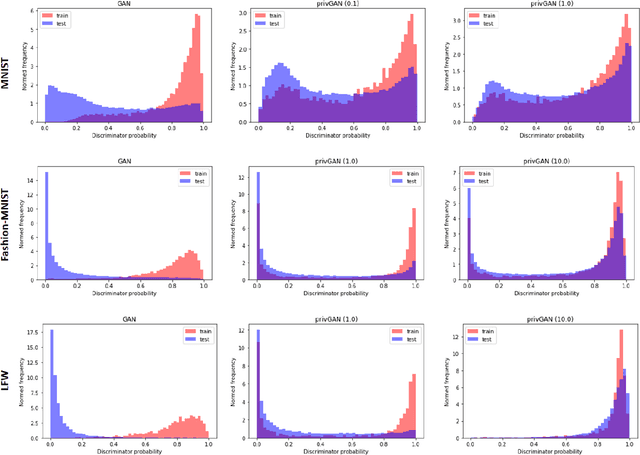
Generative Adversarial Networks (GANs) have made releasing of synthetic images a viable approach to share data without releasing the original dataset. It has been shown that such synthetic data can be used for a variety of downstream tasks such as training classifiers that would otherwise require the original dataset to be shared. However, recent work has shown that the GAN models and their synthetically generated data can be used to infer the training set membership by an adversary who has access to the entire dataset and some auxiliary information. Here we develop a new GAN architecture (privGAN) which provides protection against this mode of attack while leading to negligible loss in downstream performances. Our architecture explicitly prevents overfitting to the training set thereby providing implicit protection against white-box attacks. The main contributions of this paper are: i) we propose a novel GAN architecture that can generate synthetic data in a privacy preserving manner and demonstrate the effectiveness of our model against white--box attacks on several benchmark datasets, ii) we provide a theoretical understanding of the optimal solution of the GAN loss function, iii) we demonstrate on two common benchmark datasets that synthetic images generated by privGAN lead to negligible loss in downstream performance when compared against non--private GANs. While we have focosued on benchmarking privGAN exclusively of image datasets, the architecture of privGAN is not exclusive to image datasets and can be easily extended to other types of datasets.