 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Covering the News with (AI) Style
Jan 05, 2020

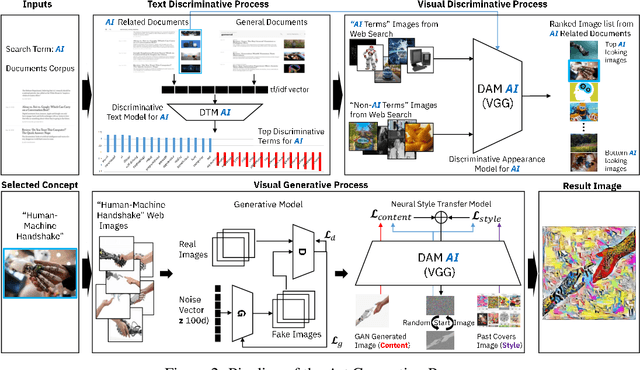

We introduce a multi-modal discriminative and generative frame-work capable of assisting humans in producing visual content re-lated to a given theme, starting from a collection of documents(textual, visual, or both). This framework can be used by edit or to generate images for articles, as well as books or music album covers. Motivated by a request from the The New York Times (NYT) seeking help to use AI to create art for their special section on Artificial Intelligence, we demonstrated the application of our system in producing such image.
Demosaicing and Superresolution for Color Filter Array via Residual Image Reconstruction and Sparse Representation
Jul 04, 2013A framework of demosaicing and superresolution for color filter array (CFA) via residual image reconstruction and sparse representation is presented.Given the intermediate image produced by certain demosaicing and interpolation technique, a residual image between the final reconstruction image and the intermediate image is reconstructed using sparse representation.The final reconstruction image has richer edges and details than that of the intermediate image. Specifically, a generic dictionary is learned from a large set of composite training data composed of intermediate data and residual data. The learned dictionary implies a mapping between the two data. A specific dictionary adaptive to the input CFA is learned thereafter. Using the adaptive dictionary, the sparse coefficients of intermediate data are computed and transformed to predict residual image. The residual image is added back into the intermediate image to obtain the final reconstruction image. Experimental results demonstrate the state-of-the-art performance in terms of PSNR and subjective visual perception.
Distilled Hierarchical Neural Ensembles with Adaptive Inference Cost
Apr 01, 2020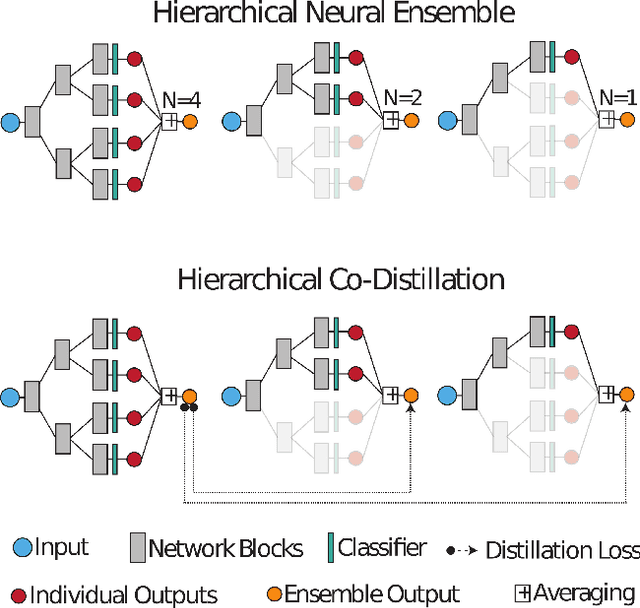
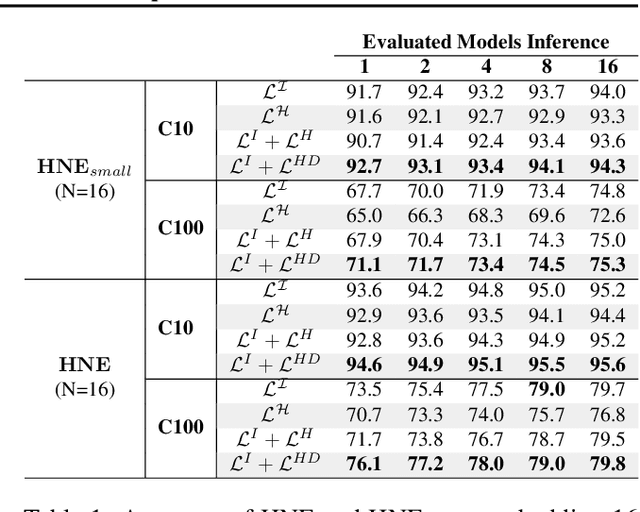
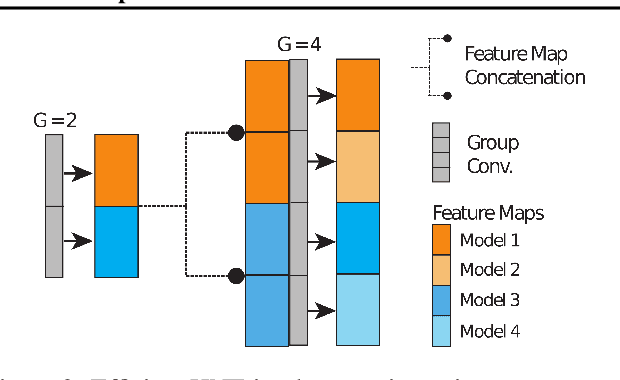
Deep neural networks form the basis of state-of-the-art models across a variety of application domains. Moreover, networks that are able to dynamically adapt the computational cost of inference are important in scenarios where the amount of compute or input data varies over time. In this paper, we propose Hierarchical Neural Ensembles (HNE), a novel framework to embed an ensemble of multiple networks by sharing intermediate layers using a hierarchical structure. In HNE we control the inference cost by evaluating only a subset of models, which are organized in a nested manner. Our second contribution is a novel co-distillation method to boost the performance of ensemble predictions with low inference cost. This approach leverages the nested structure of our ensembles, to optimally allocate accuracy and diversity across the ensemble members. Comprehensive experiments over the CIFAR and ImageNet datasets confirm the effectiveness of HNE in building deep networks with adaptive inference cost for image classification.
Self Organization Map based Texture Feature Extraction for Efficient Medical Image Categorization
Jul 14, 2014Texture is one of the most important properties of visual surface that helps in discriminating one object from another or an object from background. The self-organizing map (SOM) is an excellent tool in exploratory phase of data mining. It projects its input space on prototypes of a low-dimensional regular grid that can be effectively utilized to visualize and explore properties of the data. This paper proposes an enhancement extraction method for accurate extracting features for efficient image representation it based on SOM neural network. In this approach, we apply three different partitioning approaches as a region of interested (ROI) selection methods for extracting different accurate textural features from medical image as a primary step of our extraction method. Fisherfaces feature selection is used, for selecting discriminated features form extracted textural features. Experimental result showed the high accuracy of medical image categorization with our proposed extraction method. Experiments held on Mammographic Image Analysis Society (MIAS) dataset.
Towards Deep Learning Methods for Quality Assessment of Computer-Generated Imagery
May 02, 2020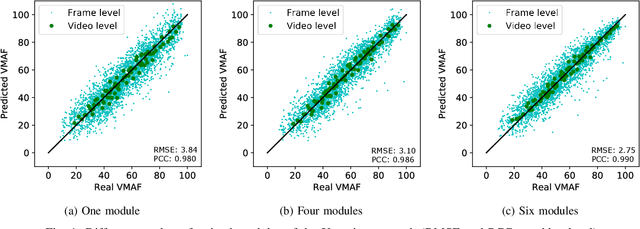
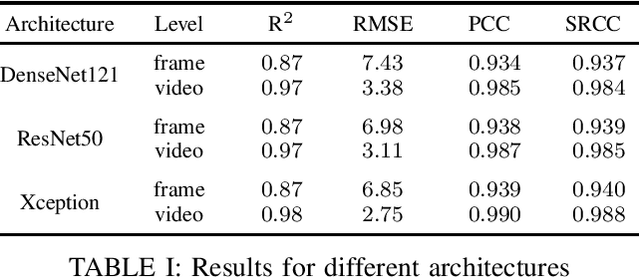
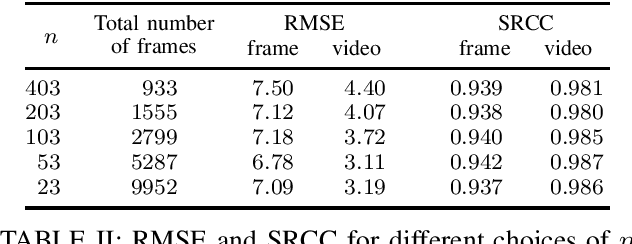
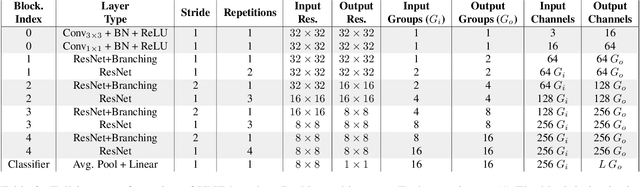
Video gaming streaming services are growing rapidly due to new services such as passive video streaming, e.g. Twitch.tv, and cloud gaming, e.g. Nvidia Geforce Now. In contrast to traditional video content, gaming content has special characteristics such as extremely high motion for some games, special motion patterns, synthetic content and repetitive content, which makes the state-of-the-art video and image quality metrics perform weaker for this special computer generated content. In this paper, we outline our plan to build a deep learningbased quality metric for video gaming quality assessment. In addition, we present initial results by training the network based on VMAF values as a ground truth to give some insights on how to build a metric in future. The paper describes the method that is used to choose an appropriate Convolutional Neural Network architecture. Furthermore, we estimate the size of the required subjective quality dataset which achieves a sufficiently high performance. The results show that by taking around 5k images for training of the last six modules of Xception, we can obtain a relatively high performance metric to assess the quality of distorted video games.
EnlightenGAN: Deep Light Enhancement without Paired Supervision
Jun 17, 2019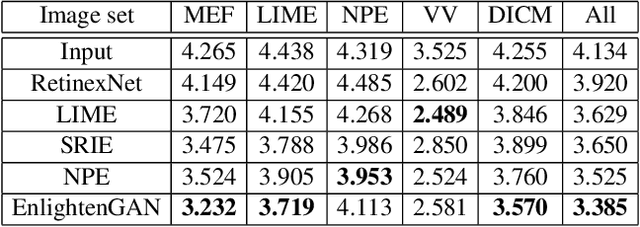
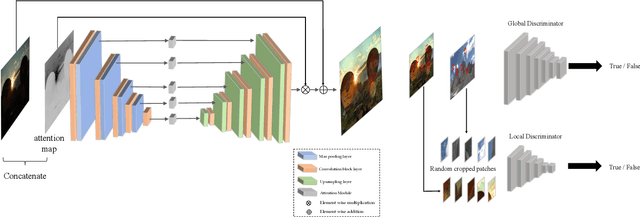


Deep learning-based methods have achieved remarkable success in image restoration and enhancement, but are they still competitive when there is a lack of paired training data? As one such example, this paper explores the low-light image enhancement problem, where in practice it is extremely challenging to simultaneously take a low-light and a normal-light photo of the same visual scene. We propose a highly effective unsupervised generative adversarial network, dubbed EnlightenGAN, that can be trained without low/normal-light image pairs, yet proves to generalize very well on various real-world test images. Instead of supervising the learning using ground truth data, we propose to regularize the unpaired training using the information extracted from the input itself, and benchmark a series of innovations for the low-light image enhancement problem, including a global-local discriminator structure, a self-regularized perceptual loss fusion, and attention mechanism. Through extensive experiments, our proposed approach outperforms recent methods under a variety of metrics in terms of visual quality and subjective user study. Thanks to the great flexibility brought by unpaired training, EnlightenGAN is demonstrated to be easily adaptable to enhancing real-world images from various domains. The code is available at \url{https://github.com/yueruchen/EnlightenGAN}
Training with Quantization Noise for Extreme Model Compression
Apr 17, 2020
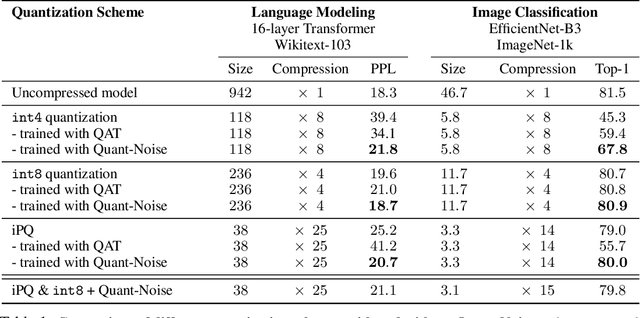
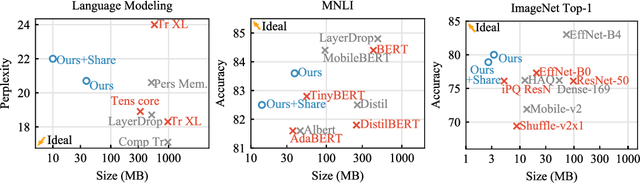
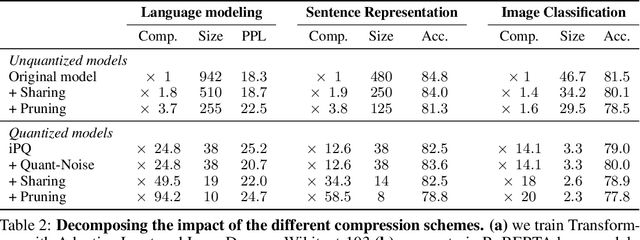
We tackle the problem of producing compact models, maximizing their accuracy for a given model size. A standard solution is to train networks with Quantization Aware Training, where the weights are quantized during training and the gradients approximated with the Straight-Through Estimator. In this paper, we extend this approach to work beyond int8 fixed-point quantization with extreme compression methods where the approximations introduced by STE are severe, such as Product Quantization. Our proposal is to only quantize a different random subset of weights during each forward, allowing for unbiased gradients to flow through the other weights. Controlling the amount of noise and its form allows for extreme compression rates while maintaining the performance of the original model. As a result we establish new state-of-the-art compromises between accuracy and model size both in natural language processing and image classification. For example, applying our method to state-of-the-art Transformer and ConvNet architectures, we can achieve 82.5% accuracy on MNLI by compressing RoBERTa to 14MB and 80.0 top-1 accuracy on ImageNet by compressing an EfficientNet-B3 to 3.3MB.
Active Multi-Kernel Domain Adaptation for Hyperspectral Image Classification
Apr 10, 2019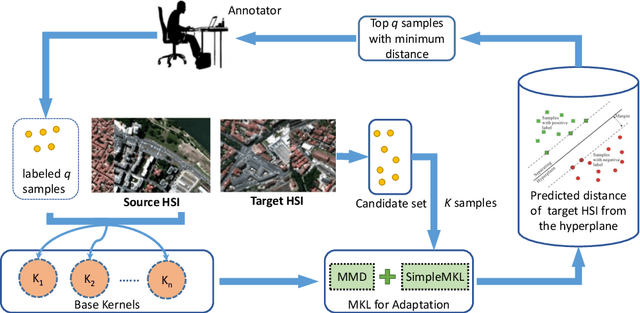

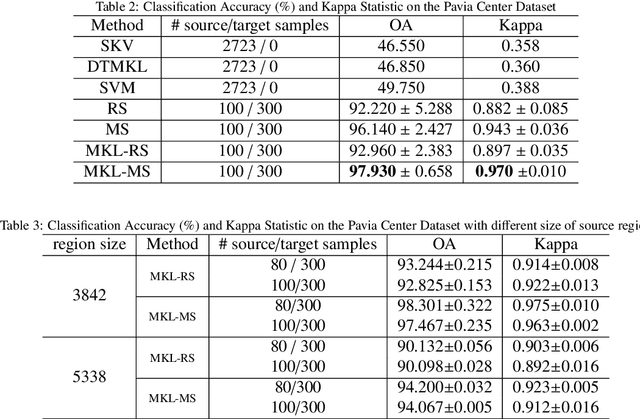
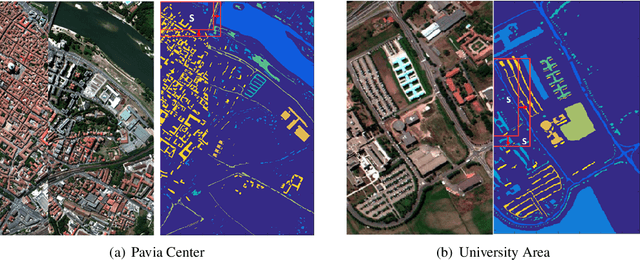
Recent years have witnessed the quick progress of the hyperspectral images (HSI) classification. Most of existing studies either heavily rely on the expensive label information using the supervised learning or can hardly exploit the discriminative information borrowed from related domains. To address this issues, in this paper we show a novel framework addressing HSI classification based on the domain adaptation (DA) with active learning (AL). The main idea of our method is to retrain the multi-kernel classifier by utilizing the available labeled samples from source domain, and adding minimum number of the most informative samples with active queries in the target domain. The proposed method adaptively combines multiple kernels, forming a DA classifier that minimizes the bias between the source and target domains. Further equipped with the nested actively updating process, it sequentially expands the training set and gradually converges to a satisfying level of classification performance. We study this active adaptation framework with the Margin Sampling (MS) strategy in the HSI classification task. Our experimental results on two popular HSI datasets demonstrate its effectiveness.
StyleRig: Rigging StyleGAN for 3D Control over Portrait Images
Mar 31, 2020
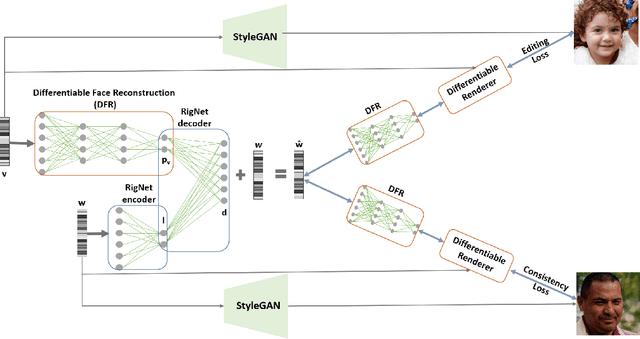
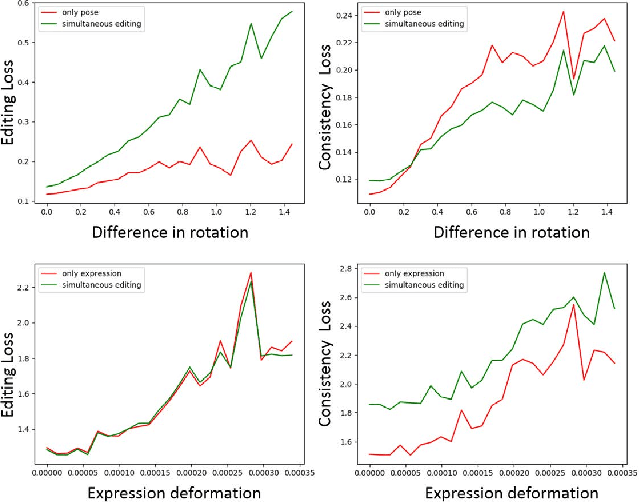

StyleGAN generates photorealistic portrait images of faces with eyes, teeth, hair and context (neck, shoulders, background), but lacks a rig-like control over semantic face parameters that are interpretable in 3D, such as face pose, expressions, and scene illumination. Three-dimensional morphable face models (3DMMs) on the other hand offer control over the semantic parameters, but lack photorealism when rendered and only model the face interior, not other parts of a portrait image (hair, mouth interior, background). We present the first method to provide a face rig-like control over a pretrained and fixed StyleGAN via a 3DMM. A new rigging network, RigNet is trained between the 3DMM's semantic parameters and StyleGAN's input. The network is trained in a self-supervised manner, without the need for manual annotations. At test time, our method generates portrait images with the photorealism of StyleGAN and provides explicit control over the 3D semantic parameters of the face.
Protecting GANs against privacy attacks by preventing overfitting
Jan 03, 2020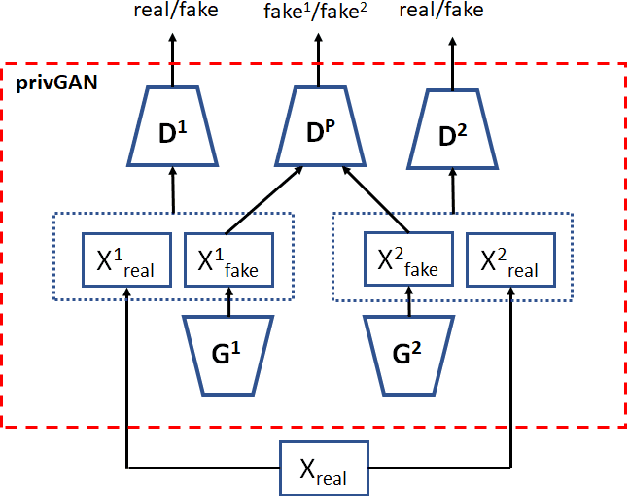


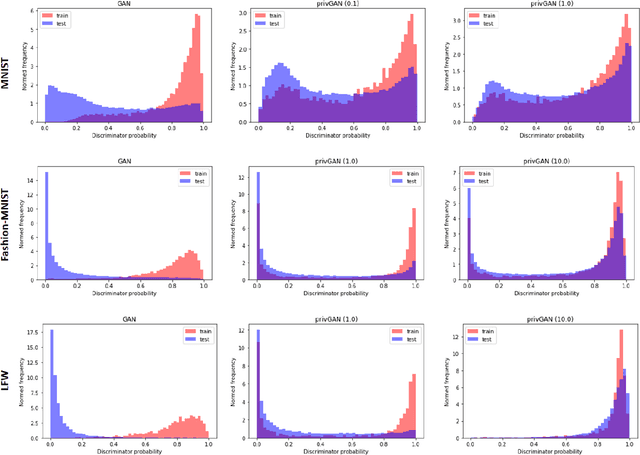
Generative Adversarial Networks (GANs) have made releasing of synthetic images a viable approach to share data without releasing the original dataset. It has been shown that such synthetic data can be used for a variety of downstream tasks such as training classifiers that would otherwise require the original dataset to be shared. However, recent work has shown that the GAN models and their synthetically generated data can be used to infer the training set membership by an adversary who has access to the entire dataset and some auxiliary information. Here we develop a new GAN architecture (privGAN) which provides protection against this mode of attack while leading to negligible loss in downstream performances. Our architecture explicitly prevents overfitting to the training set thereby providing implicit protection against white-box attacks. The main contributions of this paper are: i) we propose a novel GAN architecture that can generate synthetic data in a privacy preserving manner and demonstrate the effectiveness of our model against white--box attacks on several benchmark datasets, ii) we provide a theoretical understanding of the optimal solution of the GAN loss function, iii) we demonstrate on two common benchmark datasets that synthetic images generated by privGAN lead to negligible loss in downstream performance when compared against non--private GANs. While we have focosued on benchmarking privGAN exclusively of image datasets, the architecture of privGAN is not exclusive to image datasets and can be easily extended to other types of datasets.