 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An encoder-decoder-based method for COVID-19 lung infection segmentation
Jul 04, 2020
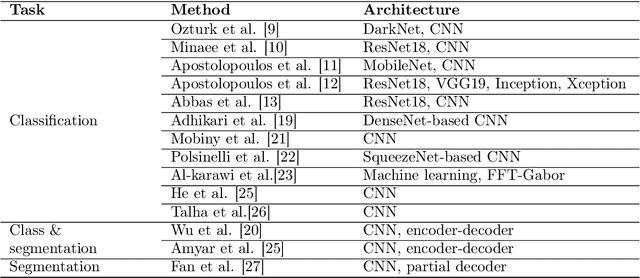
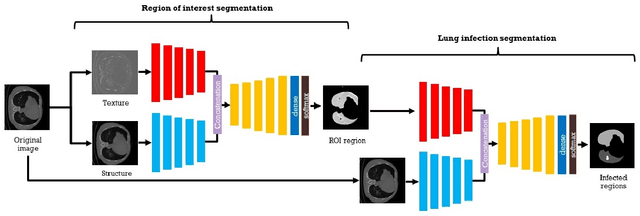
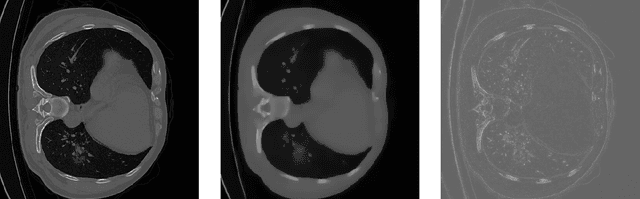
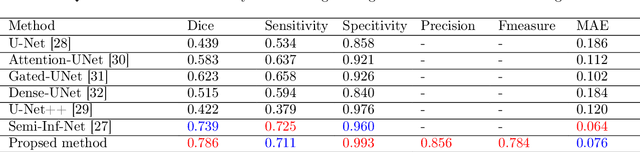
The novelty of the COVID-19 disease and the speed of spread has created a colossal chaos, impulse among researchers worldwide to exploit all the resources and capabilities to understand and analyze characteristics of the coronavirus in term of the ways it spreads and virus incubation time. For that, the existing medical features like CT and X-ray images are used. For example, CT-scan images can be used for the detection of lung infection. But the challenges of these features such as the quality of the image and infection characteristics limitate the effectiveness of these features. Using artificial intelligence (AI) tools and computer vision algorithms, the accuracy of detection can be more accurate and can help to overcome these issues. This paper proposes a multi-task deep-learning-based method for lung infection segmentation using CT-scan images. Our proposed method starts by segmenting the lung regions that can be infected. Then, segmenting the infections in these regions. Also, to perform a multi-class segmentation the proposed model is trained using the two-stream inputs. The multi-task learning used in this paper allows us to overcome shortage of labeled data. Also, the multi-input stream allows the model to do the learning on many features that can improve the results. To evaluate the proposed method, many features have been used. Also, from the experiments, the proposed method can segment lung infections with a high degree performance even with shortage of data and labeled images. In addition, comparing with the state-of-the-art method our method achieves good performance results.
OrigamiNet: Weakly-Supervised, Segmentation-Free, One-Step, Full Page Text Recognition by learning to unfold
Jun 12, 2020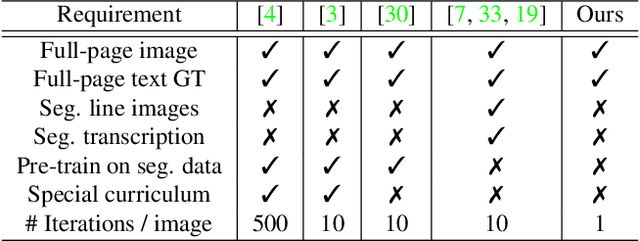
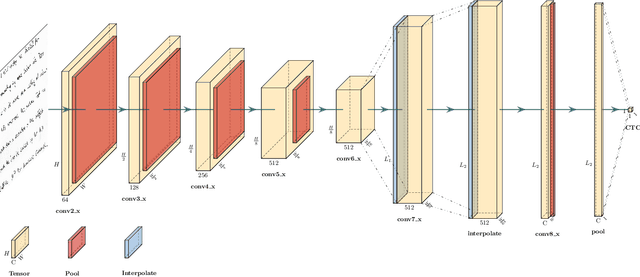
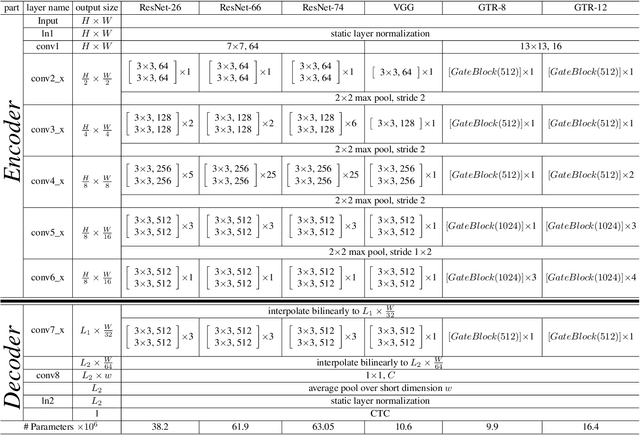

Text recognition is a major computer vision task with a big set of associated challenges. One of those traditional challenges is the coupled nature of text recognition and segmentation. This problem has been progressively solved over the past decades, going from segmentation based recognition to segmentation free approaches, which proved more accurate and much cheaper to annotate data for. We take a step from segmentation-free single line recognition towards segmentation-free multi-line / full page recognition. We propose a novel and simple neural network module, termed \textbf{OrigamiNet}, that can augment any CTC-trained, fully convolutional single line text recognizer, to convert it into a multi-line version by providing the model with enough spatial capacity to be able to properly collapse a 2D input signal into 1D without losing information. Such modified networks can be trained using exactly their same simple original procedure, and using only \textbf{unsegmented} image and text pairs. We carry out a set of interpretability experiments that show that our trained models learn an accurate implicit line segmentation. We achieve state-of-the-art character error rate on both IAM \& ICDAR 2017 HTR benchmarks for handwriting recognition, surpassing all other methods in the literature. On IAM we even surpass single line methods that use accurate localization information during training. Our code is available online at \url{https://github.com/IntuitionMachines/OrigamiNet}.
Multi-Stage Variational Auto-Encoders for Coarse-to-Fine Image Generation
May 19, 2017
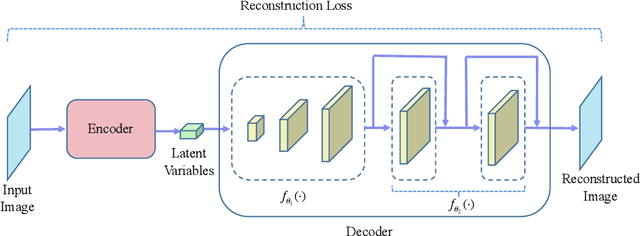
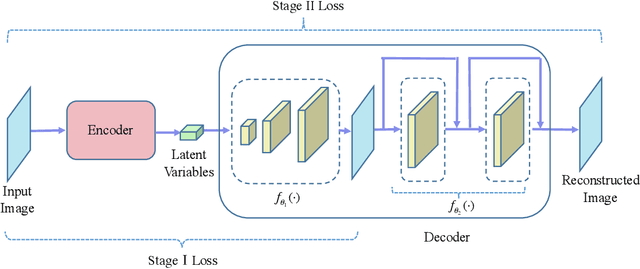

Variational auto-encoder (VAE) is a powerful unsupervised learning framework for image generation. One drawback of VAE is that it generates blurry images due to its Gaussianity assumption and thus L2 loss. To allow the generation of high quality images by VAE, we increase the capacity of decoder network by employing residual blocks and skip connections, which also enable efficient optimization. To overcome the limitation of L2 loss, we propose to generate images in a multi-stage manner from coarse to fine. In the simplest case, the proposed multi-stage VAE divides the decoder into two components in which the second component generates refined images based on the course images generated by the first component. Since the second component is independent of the VAE model, it can employ other loss functions beyond the L2 loss and different model architectures. The proposed framework can be easily generalized to contain more than two components. Experiment results on the MNIST and CelebA datasets demonstrate that the proposed multi-stage VAE can generate sharper images as compared to those from the original VAE.
Set-Structured Latent Representations
Mar 09, 2020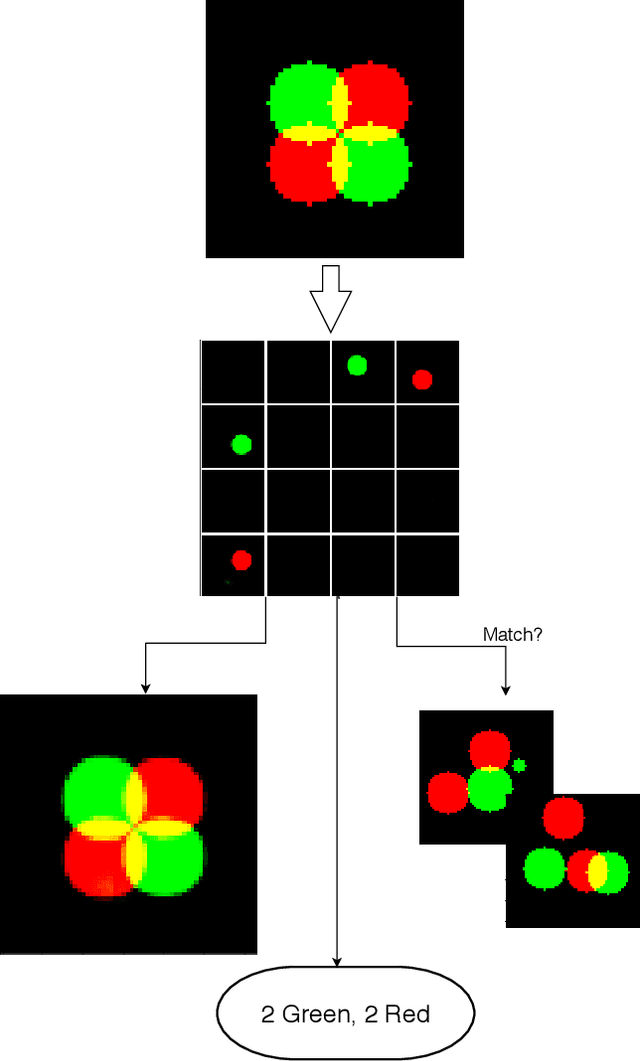
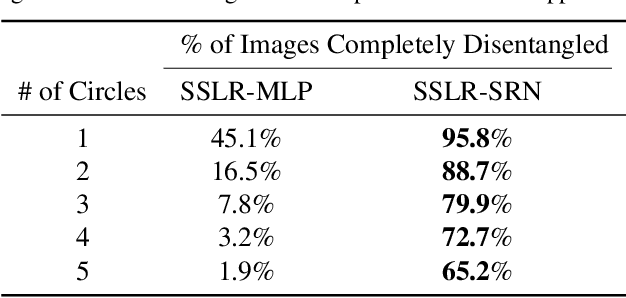

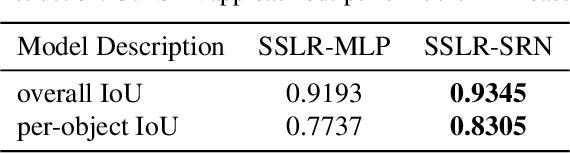
Unstructured data often has latent component structure, such as the objects in an image of a scene. In these situations, the relevant latent structure is an unordered collection or \emph{set}. However, learning such representations directly from data is difficult due to the discrete and unordered structure. Here, we develop a framework for differentiable learning of set-structured latent representations. We show how to use this framework to naturally decompose data such as images into sets of interpretable and meaningful components and demonstrate how existing techniques cannot properly disentangle relevant structure. We also show how to extend our methodology to downstream tasks such as set matching, which uses set-specific operations. Our code is available at https://github.com/CUVL/SSLR.
Multi-Resolution 3D CNN for MRI Brain Tumor Segmentation and Survival Prediction
Nov 19, 2019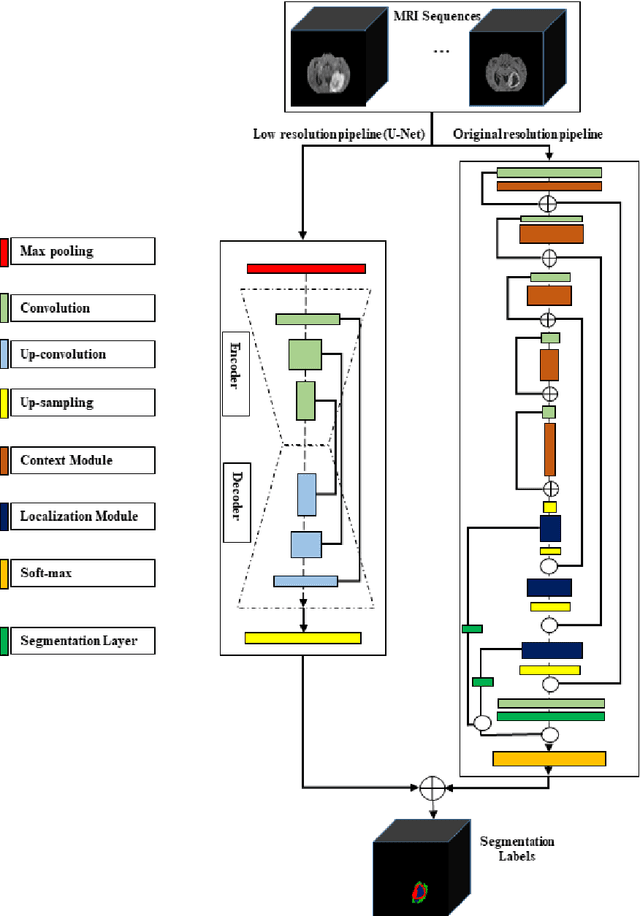
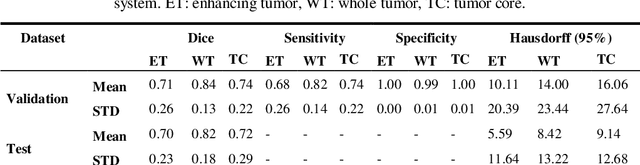
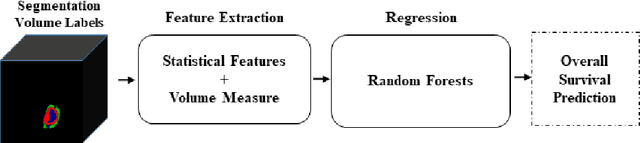

In this study, an automated three dimensional (3D) deep segmentation approach for detecting gliomas in 3D pre-operative MRI scans is proposed. Then, a classi-fication algorithm based on random forests, for survival prediction is presented. The objective is to segment the glioma area and produce segmentation labels for its different sub-regions, i.e. necrotic and the non-enhancing tumor core, the peri-tumoral edema, and enhancing tumor. The proposed deep architecture for the segmentation task encompasses two parallel streamlines with two different reso-lutions. One deep convolutional neural network is to learn local features of the input data while the other one is set to have a global observation on whole image. Deemed to be complementary, the outputs of each stream are then merged to pro-vide an ensemble complete learning of the input image. The proposed network takes the whole image as input instead of patch-based approaches in order to con-sider the semantic features throughout the whole volume. The algorithm is trained on BraTS 2019 which included 335 training cases, and validated on 127 unseen cases from the validation dataset using a blind testing approach. The proposed method was also evaluated on the BraTS 2019 challenge test dataset of 166 cases. The results show that the proposed methods provide promising segmentations as well as survival prediction. The mean Dice overlap measures of automatic brain tumor segmentation for validation set were 0.84, 0.74 and 0.71 for the whole tu-mor, core and enhancing tumor, respectively. The corresponding results for the challenge test dataset were 0.82, 0.72, and 0.70, respectively. The overall accura-cy of the proposed model for the survival prediction task is %52 for the valida-tion and %49 for the test dataset.
Spatio-spectral networks for color-texture analysis
Sep 13, 2019
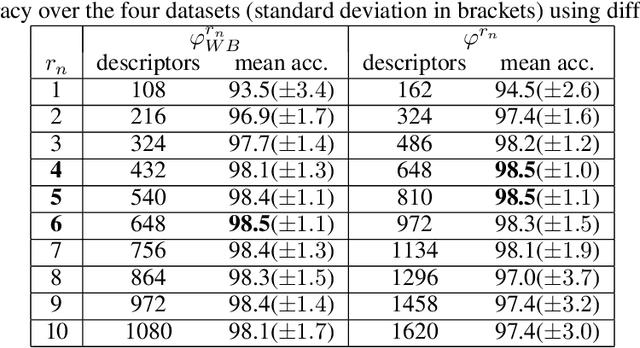
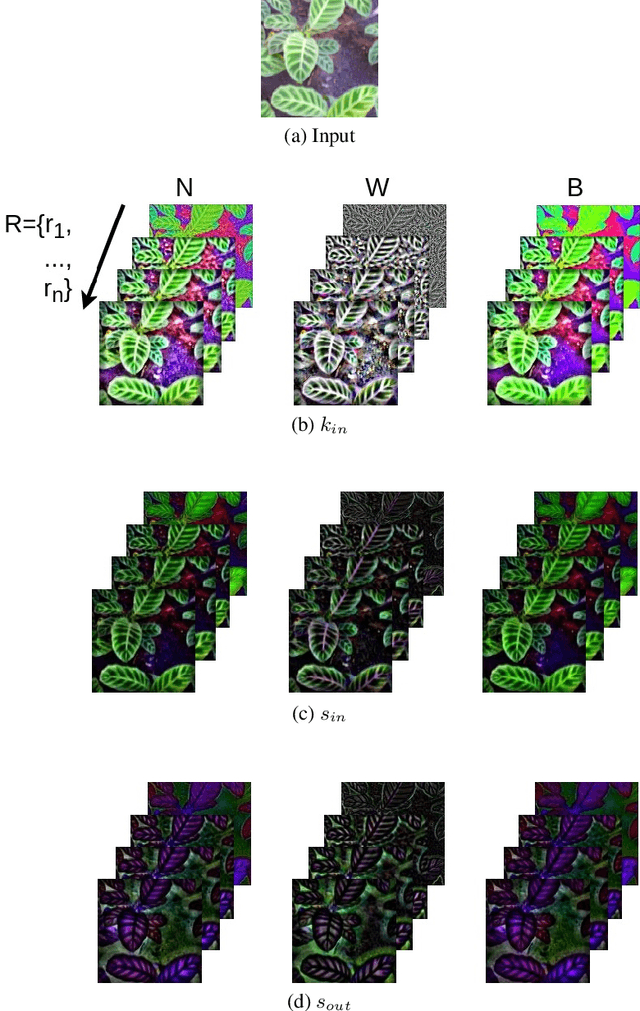
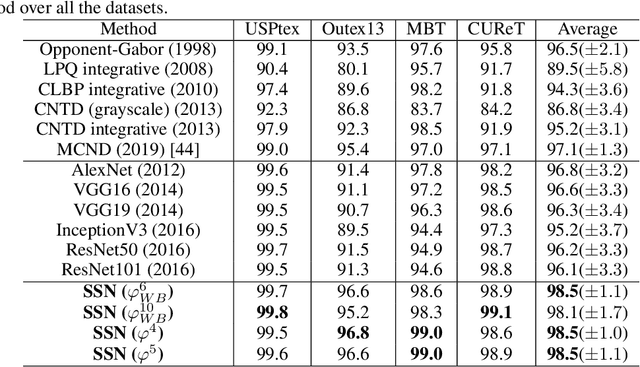
Texture is one of the most-studied visual attribute for image characterization since the 1960s. However, most hand-crafted descriptors are monochromatic, focusing on the gray scale images and discarding the color information. In this context, this work focus on a new method for color texture analysis considering all color channels in a more intrinsic approach. Our proposal consists of modeling color images as directed complex networks that we named Spatio-Spectral Network (SSN). Its topology includes within-channel edges that cover spatial patterns throughout individual image color channels, while between-channel edges tackle spectral properties of channel pairs in an opponent fashion. Image descriptors are obtained through a concise topological characterization of the modeled network in a multiscale approach with radially symmetric neighborhoods. Experiments with four datasets cover several aspects of color-texture analysis, and results demonstrate that SSN overcomes all the compared literature methods, including known deep convolutional networks, and also has the most stable performance between datasets, achieving $98.5(\pm1.1)$ of average accuracy against $97.1(\pm1.3)$ of MCND and $96.8(\pm3.2)$ of AlexNet. Additionally, an experiment verifies the performance of the methods under different color spaces, where results show that SSN also has higher performance and robustness.
RIU-Net: Embarrassingly simple semantic segmentation of 3D LiDAR point cloud
May 21, 2019

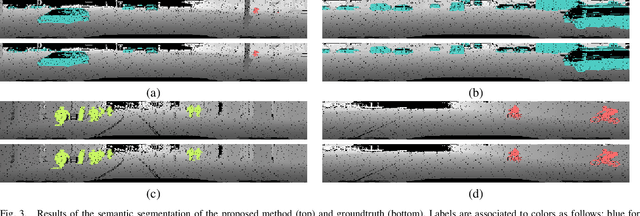
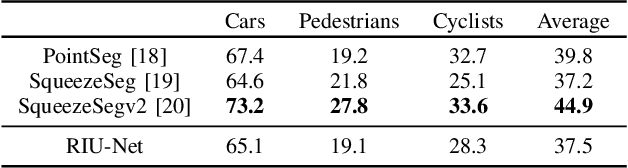
This paper proposes RIU-Net (for Range-Image U-Net), the adaptation of a popular semantic segmentation network for the semantic segmentation of a 3D LiDAR point cloud. The point cloud is turned into a 2D range-image by exploiting the topology of the sensor. This image is then used as input to a U-net. This architecture has already proved its efficiency for the task of semantic segmentation of medical images. We propose to demonstrate how it can also be used for the accurate semantic segmentation of a 3D LiDAR point cloud. Our model is trained on range-images built from KITTI 3D object detection dataset. Experiments show that RIU-Net, despite being very simple, outperforms the state-of-the-art of range-image based methods. Finally, we demonstrate that this architecture is able to operate at 90fps on a single GPU, which enables deployment on low computational power systems such as robots.
Slope Difference Distribution and Its Computer Vision Applications
Oct 13, 2019Slope difference distribution (SDD) is computed from the one-dimensional curve and makes it possible to find derivatives that do not exist in the original curve. It is not only robust to calculate the threshold point to separate the curve logically, but also robust to calculate the center of each part of the separated curve. SDD has been used in image segmentation and it outperforms all classical and state of the art image segmentation methods. SDD is also very useful in calculating the features for pattern recognition and object detection. For the gesture recognition, SDD achieved 100% accuracy for two public datasets: the NUS dataset and the near-infrared dataset. For the object recognition, SDD achieved 100% accuracy for the Kimia 99 dataset. In this memorandum, I will demonstrate the effectiveness of SDD with some typical examples.
Understanding and Improving Information Transfer in Multi-Task Learning
May 02, 2020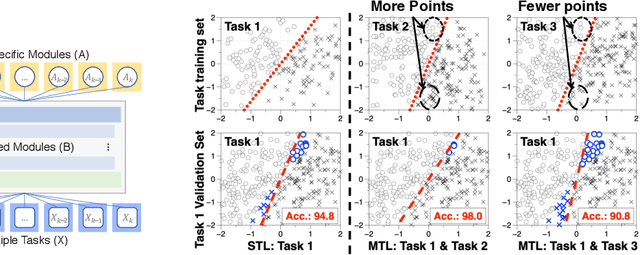

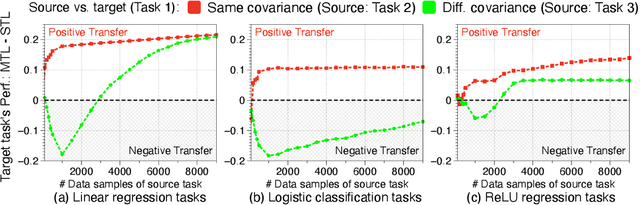
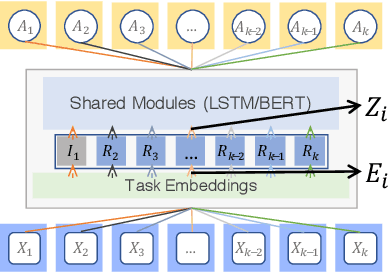
We investigate multi-task learning approaches that use a shared feature representation for all tasks. To better understand the transfer of task information, we study an architecture with a shared module for all tasks and a separate output module for each task. We study the theory of this setting on linear and ReLU-activated models. Our key observation is that whether or not tasks' data are well-aligned can significantly affect the performance of multi-task learning. We show that misalignment between task data can cause negative transfer (or hurt performance) and provide sufficient conditions for positive transfer. Inspired by the theoretical insights, we show that aligning tasks' embedding layers leads to performance gains for multi-task training and transfer learning on the GLUE benchmark and sentiment analysis tasks; for example, we obtain a 2.35% GLUE score average improvement on 5 GLUE tasks over BERT-LARGE using our alignment method. We also design an SVD-based task reweighting scheme and show that it improves the robustness of multi-task training on a multi-label image dataset.
Long Range 3D with Quadocular Thermal (LWIR) Camera
Nov 20, 2019
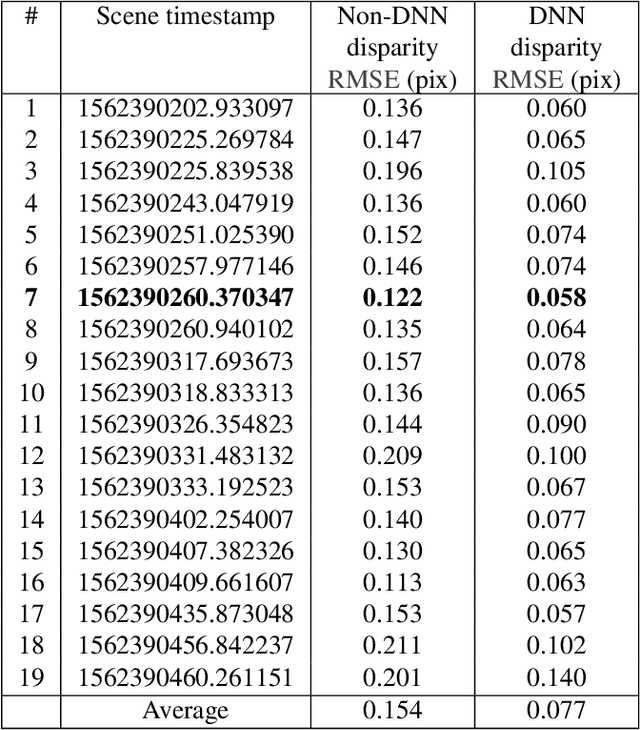


Long Wave Infrared (LWIR) cameras provide images regardles of the ambient illumination, they tolerate fog and are not blinded by the incoming car headlights. These features make LWIR cameras attractive for autonomous navigation, security and military applications. Thermal images can be used similarly to the visible range ones, including 3D scene reconstruction with two or more such cameras mounted on a rigid frame. There are two additional challenges for this spectral range: lower image resolution and lower contrast of the textures. In this work, we demonstrate quadocular LWIR camera setup, calibration, image capturing and processing that result in long range 3D perception with 0.077 pix disparity error over 90% of the depth map. With low resolution (160 x 120) LWIR sensors we achieved 10% range accuracy at 28 m with 56 degrees horizontal field of view (HFoV) and 150 mm baseline. Scaled to the now-standard 640 x 512 resolution and 200 mm baseline suitable for head-mounted application the result would be 10% accuracy at 130 m.