 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learned reconstructions for practical mask-based lensless imaging
Aug 30, 2019
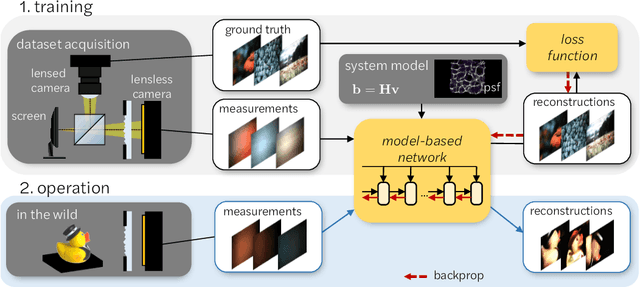
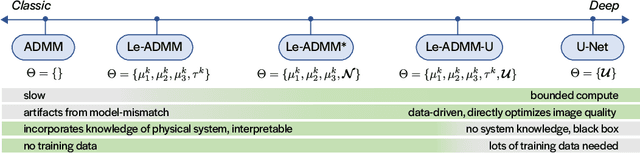
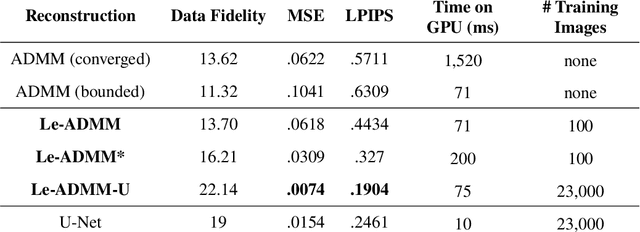
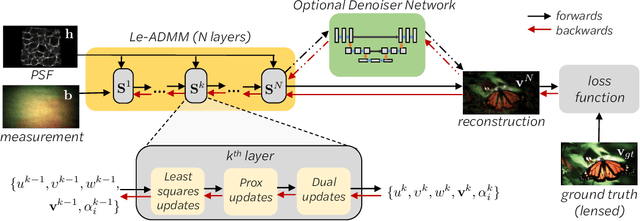
Mask-based lensless imagers are smaller and lighter than traditional lensed cameras. In these imagers, the sensor does not directly record an image of the scene; rather, a computational algorithm reconstructs it. Typically, mask-based lensless imagers use a model-based reconstruction approach that suffers from long compute times and a heavy reliance on both system calibration and heuristically chosen denoisers. In this work, we address these limitations using a bounded-compute, trainable neural network to reconstruct the image. We leverage our knowledge of the physical system by unrolling a traditional model-based optimization algorithm, whose parameters we optimize using experimentally gathered ground-truth data. Optionally, images produced by the unrolled network are then fed into a jointly-trained denoiser. As compared to traditional methods, our architecture achieves better perceptual image quality and runs 20x faster, enabling interactive previewing of the scene. We explore a spectrum between model-based and deep learning methods, showing the benefits of using an intermediate approach. Finally, we test our network on images taken in the wild with a prototype mask-based camera, demonstrating that our network generalizes to natural images.
Beyond Photometric Consistency: Gradient-based Dissimilarity for Improving Visual Odometry and Stereo Matching
Apr 08, 2020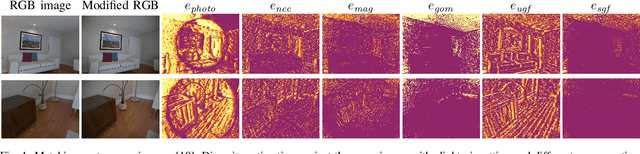
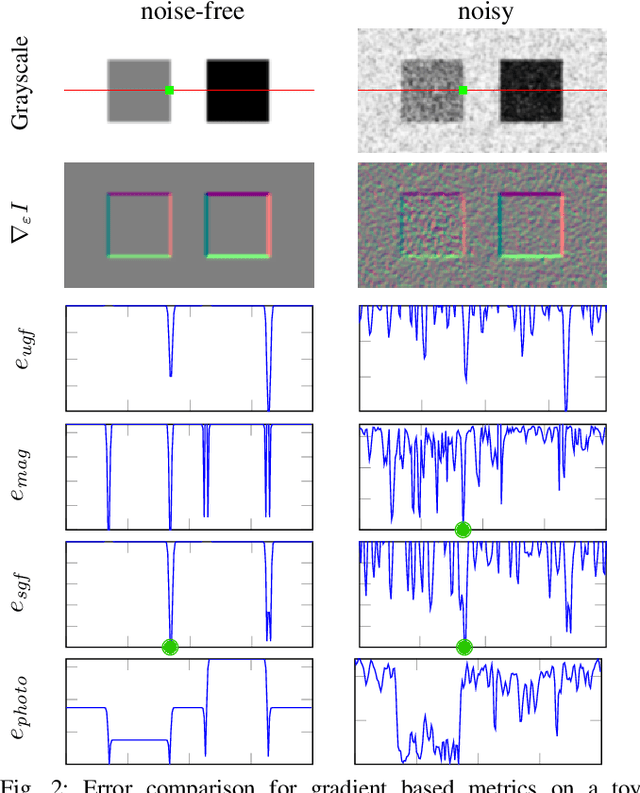
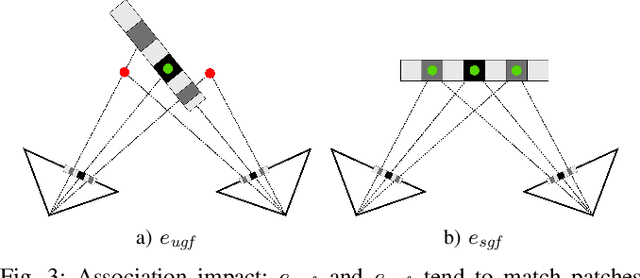
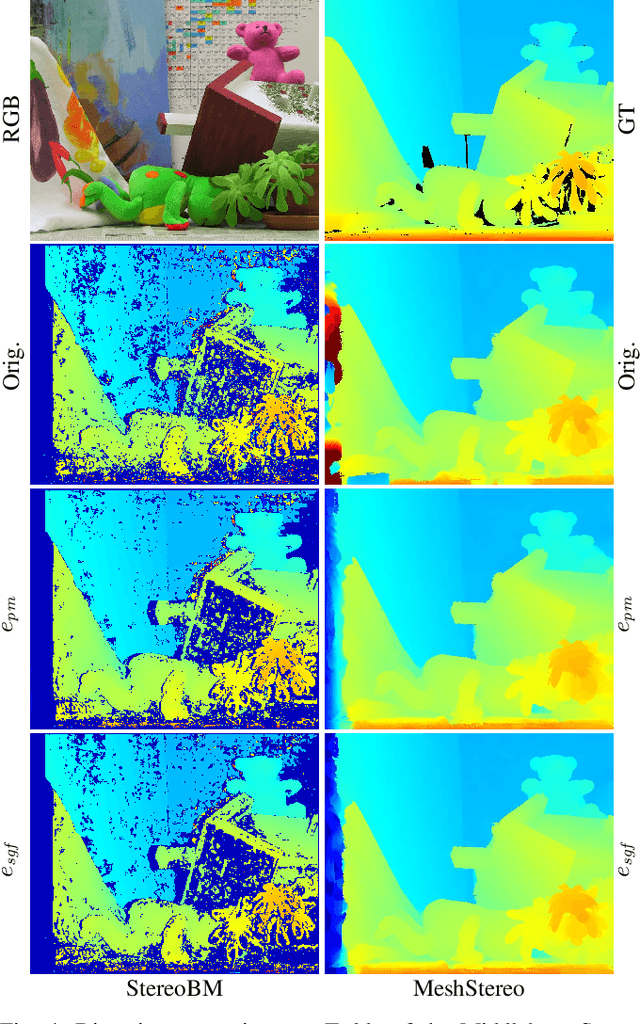
Pose estimation and map building are central ingredients of autonomous robots and typically rely on the registration of sensor data. In this paper, we investigate a new metric for registering images that builds upon on the idea of the photometric error. Our approach combines a gradient orientation-based metric with a magnitude-dependent scaling term. We integrate both into stereo estimation as well as visual odometry systems and show clear benefits for typical disparity and direct image registration tasks when using our proposed metric. Our experimental evaluation indicats that our metric leads to more robust and more accurate estimates of the scene depth as well as camera trajectory. Thus, the metric improves camera pose estimation and in turn the mapping capabilities of mobile robots. We believe that a series of existing visual odometry and visual SLAM systems can benefit from the findings reported in this paper.
Visualization of Convolutional Neural Networks for Monocular Depth Estimation
Apr 06, 2019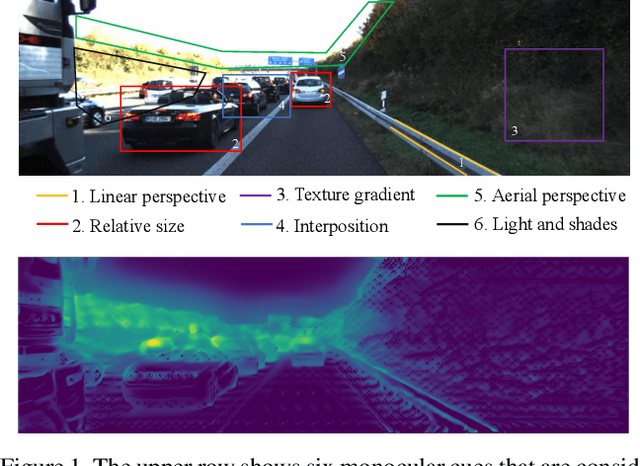
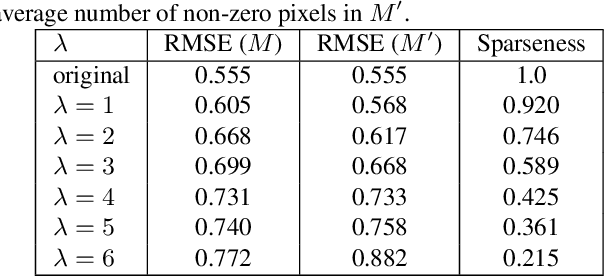


Recently, convolutional neural networks (CNNs) have shown great success on the task of monocular depth estimation. A fundamental yet unanswered question is: how CNNs can infer depth from a single image. Toward answering this question, we consider visualization of inference of a CNN by identifying relevant pixels of an input image to depth estimation. We formulate it as an optimization problem of identifying the smallest number of image pixels from which the CNN can estimate a depth map with the minimum difference from the estimate from the entire image. To cope with a difficulty with optimization through a deep CNN, we propose to use another network to predict those relevant image pixels in a forward computation. In our experiments, we first show the effectiveness of this approach, and then apply it to different depth estimation networks on indoor and outdoor scene datasets. The results provide several findings that help exploration of the above question.
Cascaded Context Enhancement for Automated Skin Lesion Segmentation
Apr 17, 2020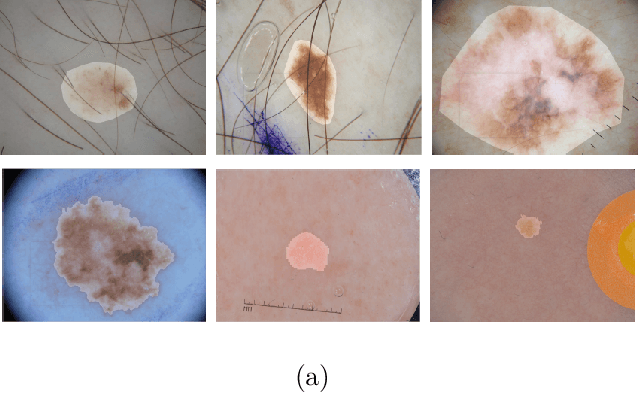
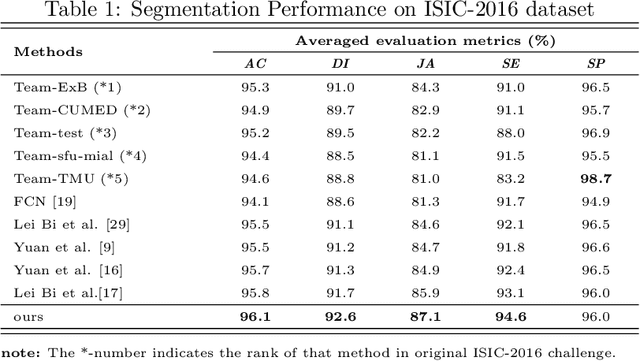
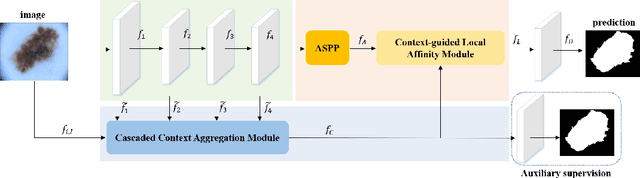
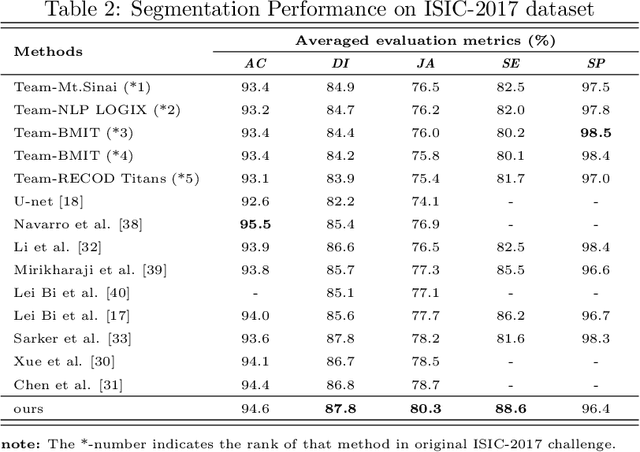
Skin lesion segmentation is an important step for automated melanoma diagnosis. Due to the non-negligible diversity of lesions from different patients, extracting powerful context for fine-grained semantic segmentation is still challenging today. In this paper, we formulate a cascaded context enhancement neural network for skin lesion segmentation. The proposed method adopts encoder-decoder architecture, a new cascaded context aggregation (CCA) module with gate-based information integration approach is proposed for sequentially and selectively aggregating original image and encoder network features from low-level to high-level. The generated context is further utilized to guide discriminative features extraction by the designed context-guided local affinity module. Furthermore, an auxiliary loss is added to the CCA module for refining the prediction. In our work, we evaluate our approach on three public datasets. We achieve the Jaccard Index (JA) of 87.1%, 80.3% and 86.6% on ISIC-2016, ISIC-2017 and PH2 datasets, which are higher than other state-of-the-art methods respectively.
A novel and reliable deep learning web-based tool to detect COVID-19 infection form chest CT-scan
Jun 24, 2020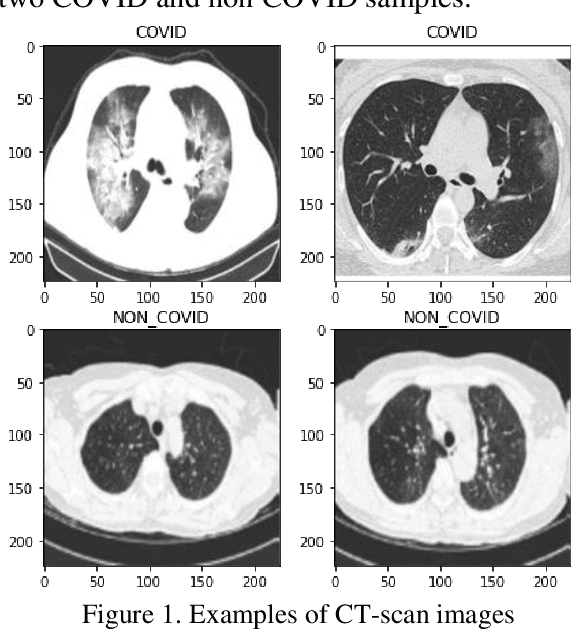
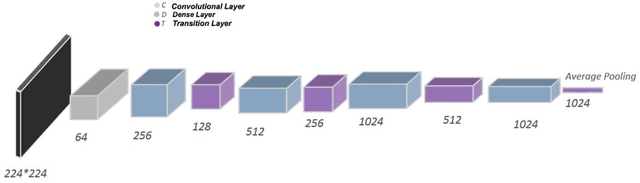
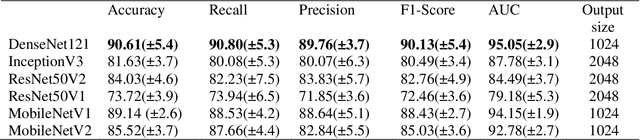
The corona virus is already spread around the world in many countries, and it has taken many lives. Furthermore, the world health organization (WHO) has announced that COVID-19 has reached the global epidemic stage. Early and reliable diagnosis using chest CT-scan can assist medical specialists in vital circumstances. In this study, we introduce a computer aided diagnosis (CAD) web service to detect COVID-19 based on chest CT- scan images and deep learning approach. A public database containing 746 participants were used in this experiment. A novel combination of the Densely connected convolutional network (DenseNet) in order to extract spatial features and a Nu-SVM was applied on the feature maps were implemented to distinguish between COVID-19 and healthy controls. A number of well-known deep neural network architectures consisting of ResNet, Inception and MobileNet were also applied and compared to main model in order to prove efficiency of the hybrid system. The developed flask web service in this research uses the trained model to provide a RESTful COVID-19 detector, which takes only 39 milliseconds to process one image. The source code is also available 2. The proposed methodology achieved 90.80% recall, 89.76% precision and 90.61% accuracy. The method also yields an AUC of 95.05%. Based on the findings, it can be inferred that it is feasible to use the proposed technique as an automated tool for diagnosis of COVID-19.
An End-to-end Deep Learning Approach for Landmark Detection and Matching in Medical Images
Jan 21, 2020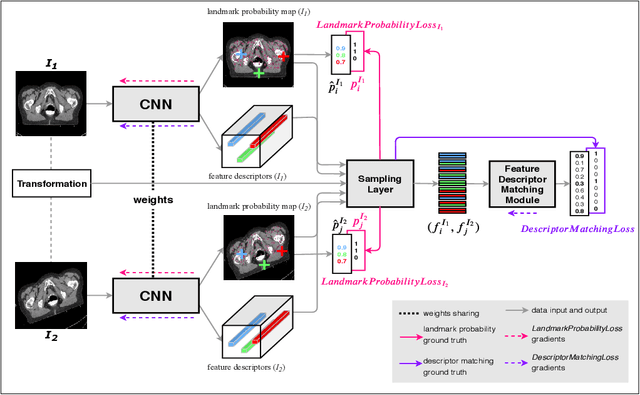
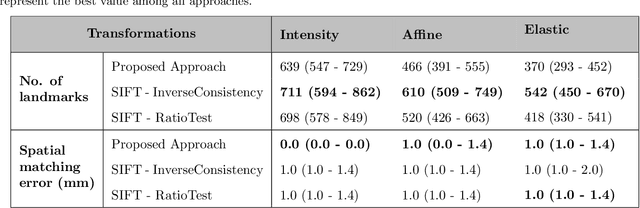
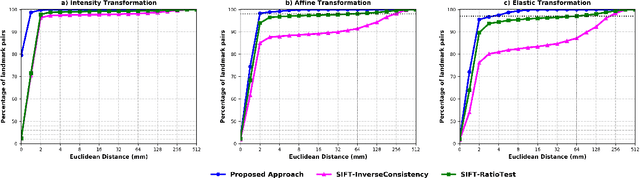
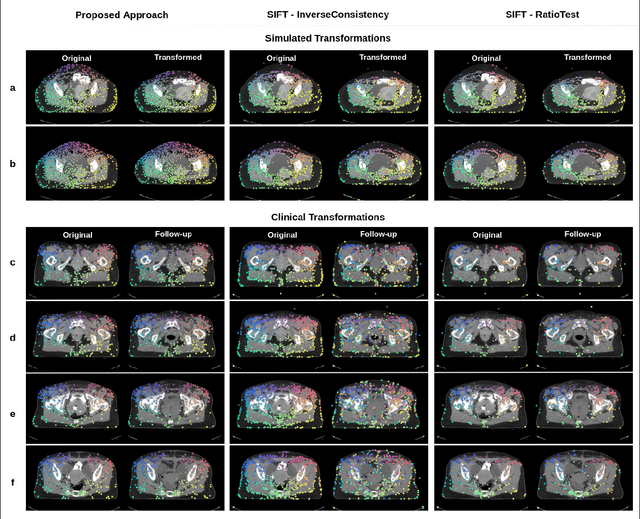
Anatomical landmark correspondences in medical images can provide additional guidance information for the alignment of two images, which, in turn, is crucial for many medical applications. However, manual landmark annotation is labor-intensive. Therefore, we propose an end-to-end deep learning approach to automatically detect landmark correspondences in pairs of two-dimensional (2D) images. Our approach consists of a Siamese neural network, which is trained to identify salient locations in images as landmarks and predict matching probabilities for landmark pairs from two different images. We trained our approach on 2D transverse slices from 168 lower abdominal Computed Tomography (CT) scans. We tested the approach on 22,206 pairs of 2D slices with varying levels of intensity, affine, and elastic transformations. The proposed approach finds an average of 639, 466, and 370 landmark matches per image pair for intensity, affine, and elastic transformations, respectively, with spatial matching errors of at most 1 mm. Further, more than 99% of the landmark pairs are within a spatial matching error of 2 mm, 4 mm, and 8 mm for image pairs with intensity, affine, and elastic transformations, respectively. To investigate the utility of our developed approach in a clinical setting, we also tested our approach on pairs of transverse slices selected from follow-up CT scans of three patients. Visual inspection of the results revealed landmark matches in both bony anatomical regions as well as in soft tissues lacking prominent intensity gradients.
SIP-SegNet: A Deep Convolutional Encoder-Decoder Network for Joint Semantic Segmentation and Extraction of Sclera, Iris and Pupil based on Periocular Region Suppression
Feb 15, 2020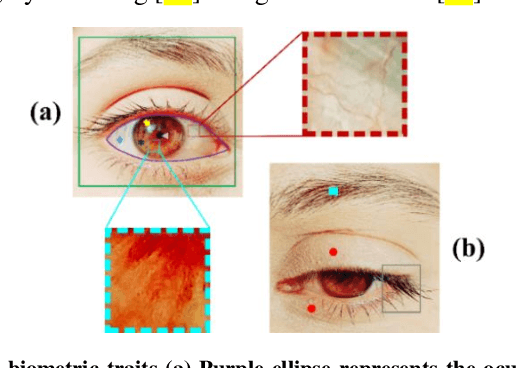
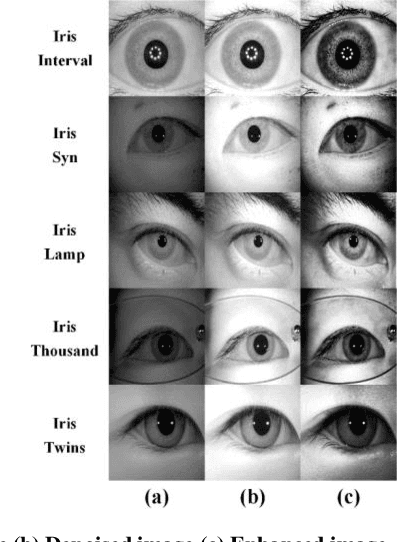
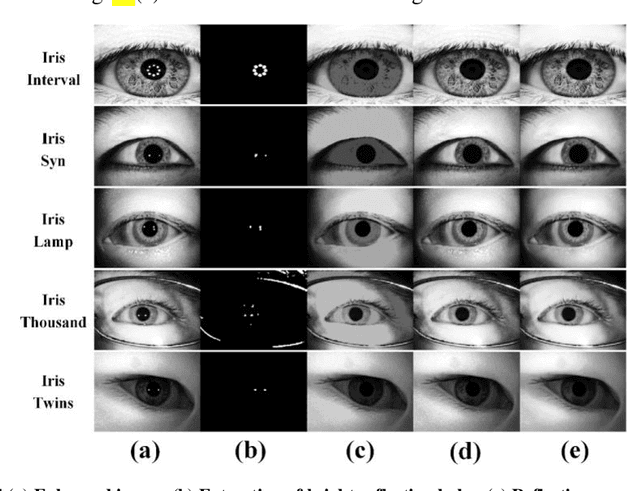
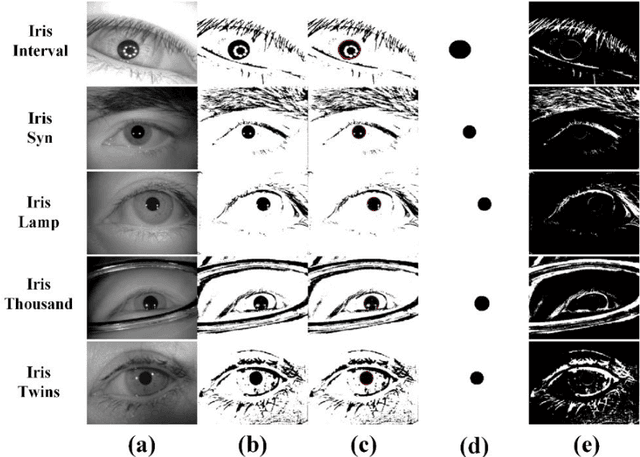
The current developments in the field of machine vision have opened new vistas towards deploying multimodal biometric recognition systems in various real-world applications. These systems have the ability to deal with the limitations of unimodal biometric systems which are vulnerable to spoofing, noise, non-universality and intra-class variations. In addition, the ocular traits among various biometric traits are preferably used in these recognition systems. Such systems possess high distinctiveness, permanence, and performance while, technologies based on other biometric traits (fingerprints, voice etc.) can be easily compromised. This work presents a novel deep learning framework called SIP-SegNet, which performs the joint semantic segmentation of ocular traits (sclera, iris and pupil) in unconstrained scenarios with greater accuracy. The acquired images under these scenarios exhibit purkinje reflexes, specular reflections, eye gaze, off-angle shots, low resolution, and various occlusions particularly by eyelids and eyelashes. To address these issues, SIP-SegNet begins with denoising the pristine image using denoising convolutional neural network (DnCNN), followed by reflection removal and image enhancement based on contrast limited adaptive histogram equalization (CLAHE). Our proposed framework then extracts the periocular information using adaptive thresholding and employs the fuzzy filtering technique to suppress this information. Finally, the semantic segmentation of sclera, iris and pupil is achieved using the densely connected fully convolutional encoder-decoder network. We used five CASIA datasets to evaluate the performance of SIP-SegNet based on various evaluation metrics. The simulation results validate the optimal segmentation of the proposed SIP-SegNet, with the mean f1 scores of 93.35, 95.11 and 96.69 for the sclera, iris and pupil classes respectively.
Generative Smoke Removal
Feb 01, 2019
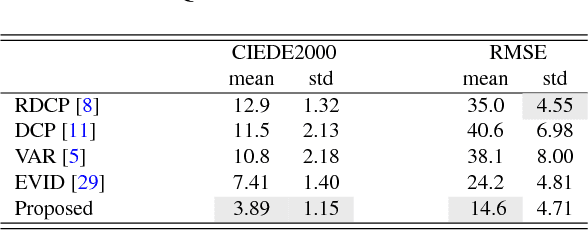
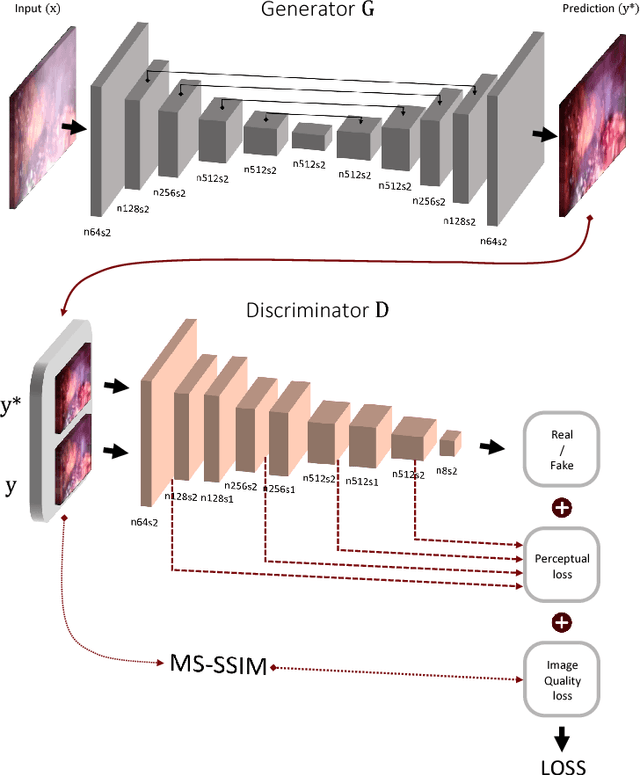
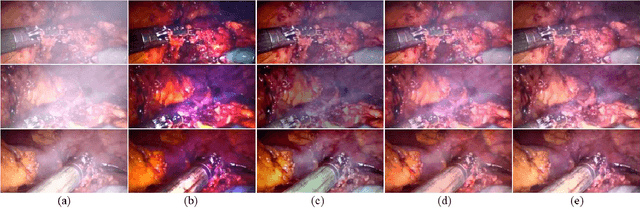
In minimally invasive surgery, the use of tissue dissection tools causes smoke, which inevitably degrades the image quality. This could reduce the visibility of the operation field for surgeons and introduces errors for the computer vision algorithms used in surgical navigation systems. In this paper, we propose a novel approach for computational smoke removal using supervised image-to-image translation. We demonstrate that straightforward application of existing generative algorithms allows removing smoke but decreases image quality and introduces synthetic noise (grid-structure). Thus, we propose to solve this issue by modification of GAN's architecture and adding perceptual image quality metric to the loss function. Obtained results demonstrate that proposed method efficiently removes smoke as well as preserves perceptually sufficient image quality.
eCNN: A Block-Based and Highly-Parallel CNN Accelerator for Edge Inference
Oct 13, 2019

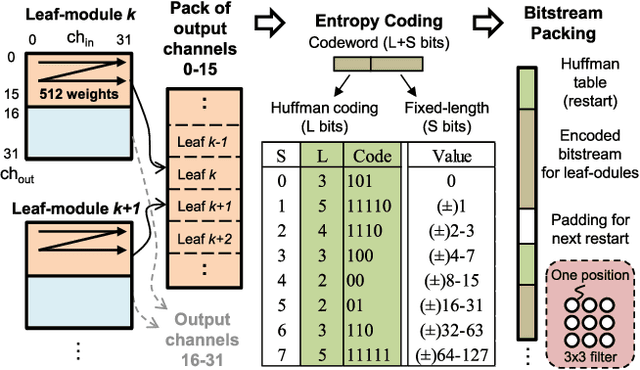
Convolutional neural networks (CNNs) have recently demonstrated superior quality for computational imaging applications. Therefore, they have great potential to revolutionize the image pipelines on cameras and displays. However, it is difficult for conventional CNN accelerators to support ultra-high-resolution videos at the edge due to their considerable DRAM bandwidth and power consumption. Therefore, finding a further memory- and computation-efficient microarchitecture is crucial to speed up this coming revolution. In this paper, we approach this goal by considering the inference flow, network model, instruction set, and processor design jointly to optimize hardware performance and image quality. We apply a block-based inference flow which can eliminate all the DRAM bandwidth for feature maps and accordingly propose a hardware-oriented network model, ERNet, to optimize image quality based on hardware constraints. Then we devise a coarse-grained instruction set architecture, FBISA, to support power-hungry convolution by massive parallelism. Finally,we implement an embedded processor---eCNN---which accommodates to ERNet and FBISA with a flexible processing architecture. Layout results show that it can support high-quality ERNets for super-resolution and denoising at up to 4K Ultra-HD 30 fps while using only DDR-400 and consuming 6.94W on average. By comparison, the state-of-the-art Diffy uses dual-channel DDR3-2133 and consumes 54.3W to support lower-quality VDSR at Full HD 30 fps. Lastly, we will also present application examples of high-performance style transfer and object recognition to demonstrate the flexibility of eCNN.
An encoder-decoder-based method for COVID-19 lung infection segmentation
Jul 04, 2020
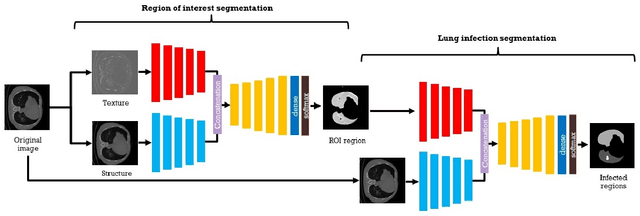
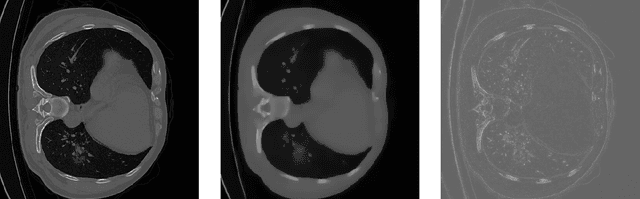
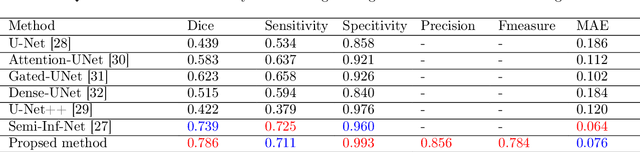
The novelty of the COVID-19 disease and the speed of spread has created a colossal chaos, impulse among researchers worldwide to exploit all the resources and capabilities to understand and analyze characteristics of the coronavirus in term of the ways it spreads and virus incubation time. For that, the existing medical features like CT and X-ray images are used. For example, CT-scan images can be used for the detection of lung infection. But the challenges of these features such as the quality of the image and infection characteristics limitate the effectiveness of these features. Using artificial intelligence (AI) tools and computer vision algorithms, the accuracy of detection can be more accurate and can help to overcome these issues. This paper proposes a multi-task deep-learning-based method for lung infection segmentation using CT-scan images. Our proposed method starts by segmenting the lung regions that can be infected. Then, segmenting the infections in these regions. Also, to perform a multi-class segmentation the proposed model is trained using the two-stream inputs. The multi-task learning used in this paper allows us to overcome shortage of labeled data. Also, the multi-input stream allows the model to do the learning on many features that can improve the results. To evaluate the proposed method, many features have been used. Also, from the experiments, the proposed method can segment lung infections with a high degree performance even with shortage of data and labeled images. In addition, comparing with the state-of-the-art method our method achieves good performance results.