 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Person Re-identification via Multi-label Classification
Apr 20, 2020
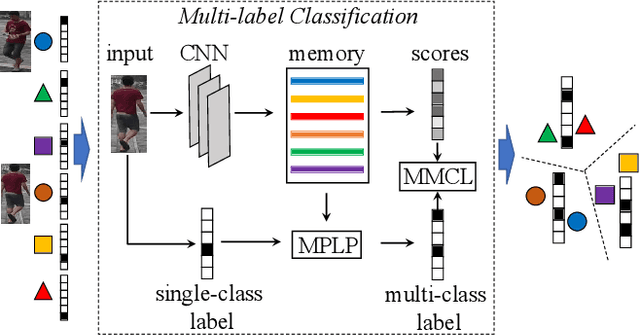
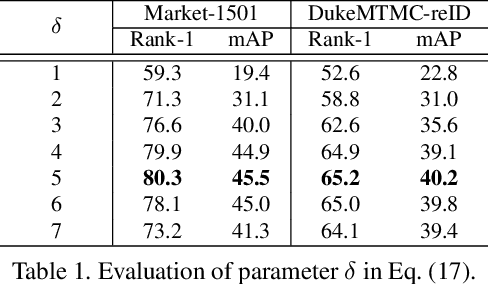
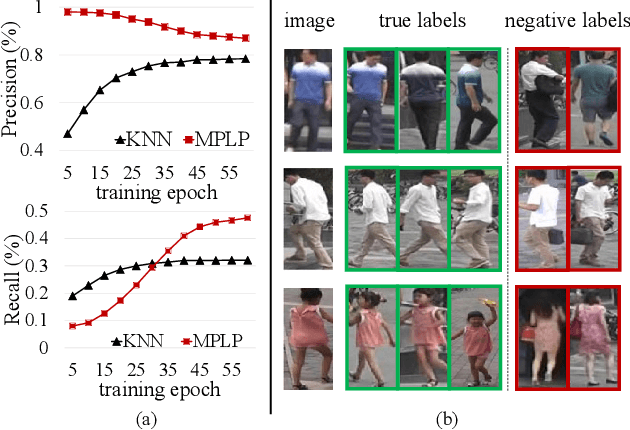
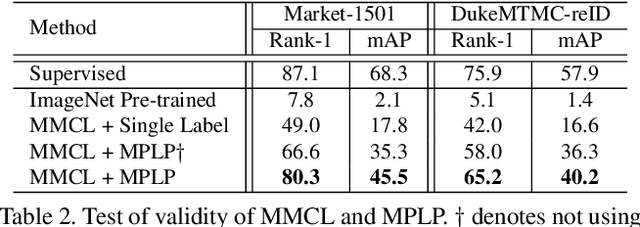
The challenge of unsupervised person re-identification (ReID) lies in learning discriminative features without true labels. This paper formulates unsupervised person ReID as a multi-label classification task to progressively seek true labels. Our method starts by assigning each person image with a single-class label, then evolves to multi-label classification by leveraging the updated ReID model for label prediction. The label prediction comprises similarity computation and cycle consistency to ensure the quality of predicted labels. To boost the ReID model training efficiency in multi-label classification, we further propose the memory-based multi-label classification loss (MMCL). MMCL works with memory-based non-parametric classifier and integrates multi-label classification and single-label classification in a unified framework. Our label prediction and MMCL work iteratively and substantially boost the ReID performance. Experiments on several large-scale person ReID datasets demonstrate the superiority of our method in unsupervised person ReID. Our method also allows to use labeled person images in other domains. Under this transfer learning setting, our method also achieves state-of-the-art performance.
Fast Scenario Reduction for Power Systems by Deep Learning
Aug 30, 2019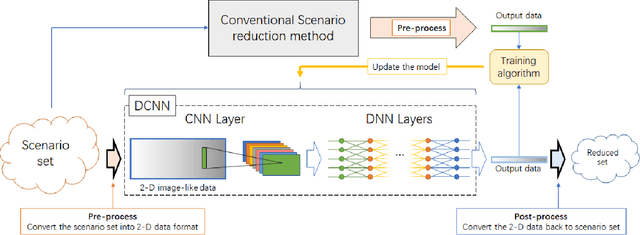
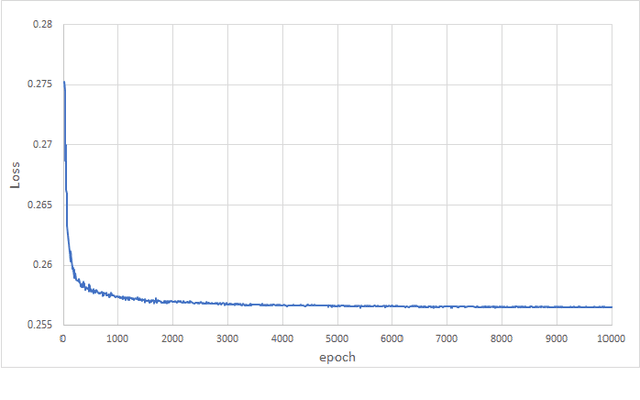

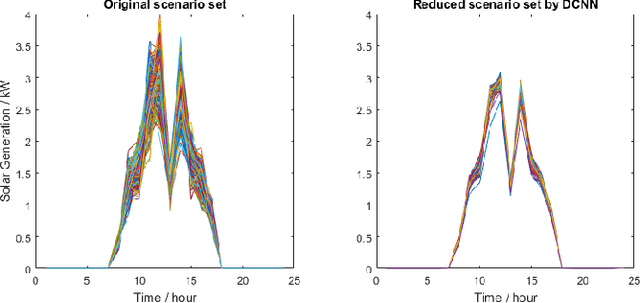
Scenario reduction is an important topic in stochastic programming problems. Due to the random behavior of load and renewable energy, stochastic programming becomes a useful technique to optimize power systems. Thus, scenario reduction gets more attentions in recent years. Many scenario reduction methods have been proposed to reduce the scenario set in a fast speed. However, the speed of scenario reduction is still very slow, in which it takes at least several seconds to several minutes to finish the reduction. This limitation of speed prevents stochastic programming to be implemented in real-time optimal control problems. In this paper, a fast scenario reduction method based on deep learning is proposed to solve this problem. Inspired by the deep learning based image process, recognition and generation methods, the scenario data are transformed into a 2D image-like data and then to be fed into a deep convolutional neural network (DCNN). The output of the DCNN will be an "image" of the reduced scenario set. Since images can be processed in a very high speed by neural networks, the scenario reduction by neural network can also be very fast. The results of the simulation show that the scenario reduction with the proposed DCNN method can be completed in very high speed.
Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model
Apr 20, 2020


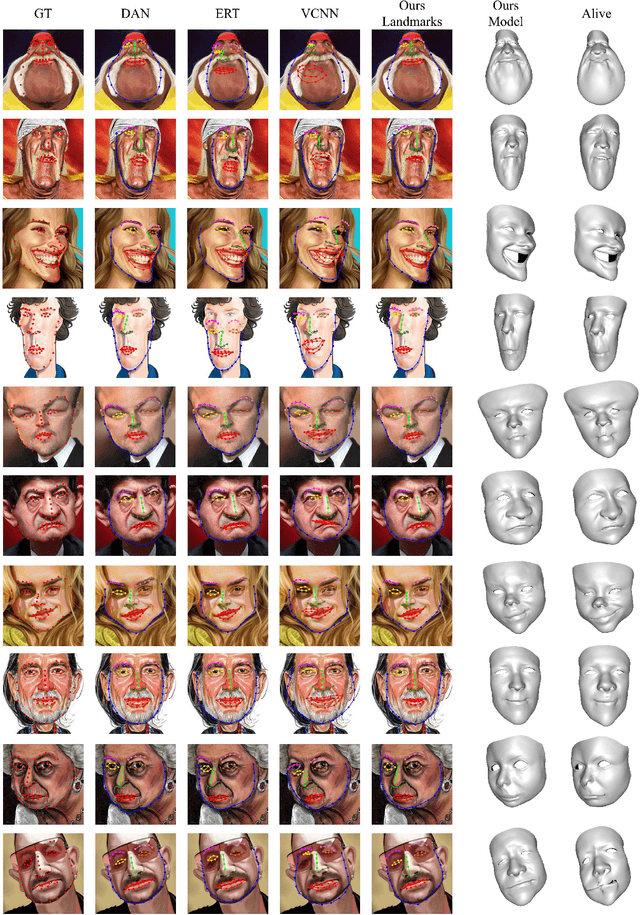
Caricature is an artistic abstraction of the human face by distorting or exaggerating certain facial features, while still retains a likeness with the given face. Due to the large diversity of geometric and texture variations, automatic landmark detection and 3D face reconstruction for caricature is a challenging problem and has rarely been studied before. In this paper, we propose the first automatic method for this task by a novel 3D approach. To this end, we first build a dataset with various styles of 2D caricatures and their corresponding 3D shapes, and then build a parametric model on vertex based deformation space for 3D caricature face. Based on the constructed dataset and the nonlinear parametric model, we propose a neural network based method to regress the 3D face shape and orientation from the input 2D caricature image. Ablation studies and comparison with baseline methods demonstrate the effectiveness of our algorithm design, and extensive experimental results demonstrate that our method works well for various caricatures. Our constructed dataset, source code and trained model are available at https://github.com/Juyong/CaricatureFace.
From Open Set to Closed Set: Supervised Spatial Divide-and-Conquer for Object Counting
Jan 07, 2020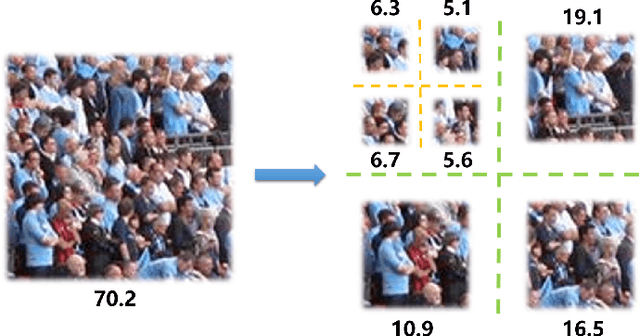

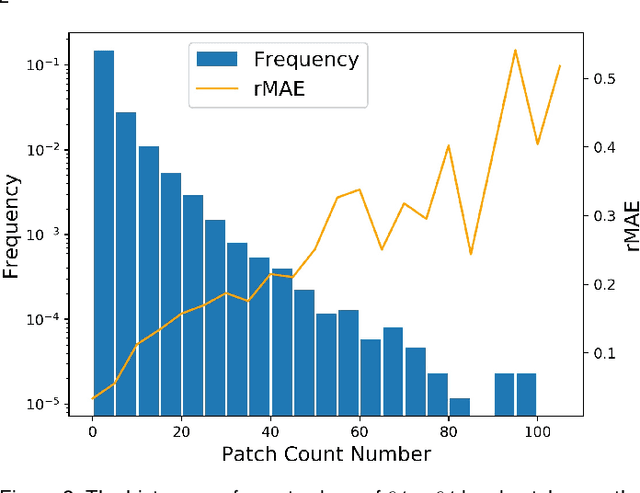
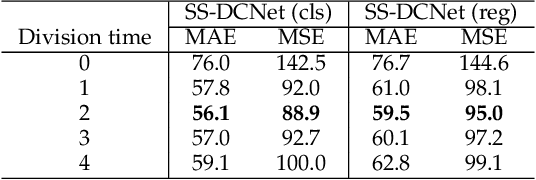
Visual counting, a task that aims to estimate the number of objects from an image/video, is an open-set problem by nature, i.e., the number of population can vary in [0, inf) in theory. However, collected data and labeled instances are limited in reality, which means that only a small closed set is observed. Existing methods typically model this task in a regression manner, while they are prone to suffer from an unseen scene with counts out of the scope of the closed set. In fact, counting has an interesting and exclusive property---spatially decomposable. A dense region can always be divided until sub-region counts are within the previously observed closed set. We therefore introduce the idea of spatial divide-and-conquer (S-DC) that transforms open-set counting into a closed-set problem. This idea is implemented by a novel Supervised Spatial Divide-and-Conquer Network (SS-DCNet). Thus, SS-DCNet can only learn from a closed set but generalize well to open-set scenarios via S-DC. SS-DCNet is also efficient. To avoid repeatedly computing sub-region convolutional features, S-DC is executed on the feature map instead of on the input image. We provide theoretical analyses as well as a controlled experiment on toy data, demonstrating why closed-set modeling makes sense. Extensive experiments show that SS-DCNet achieves the state-of-the-art performance. Code and models are available at: https://tinyurl.com/SS-DCNet.
Deep Adaptive Semantic Logic (DASL): Compiling Declarative Knowledge into Deep Neural Networks
Mar 16, 2020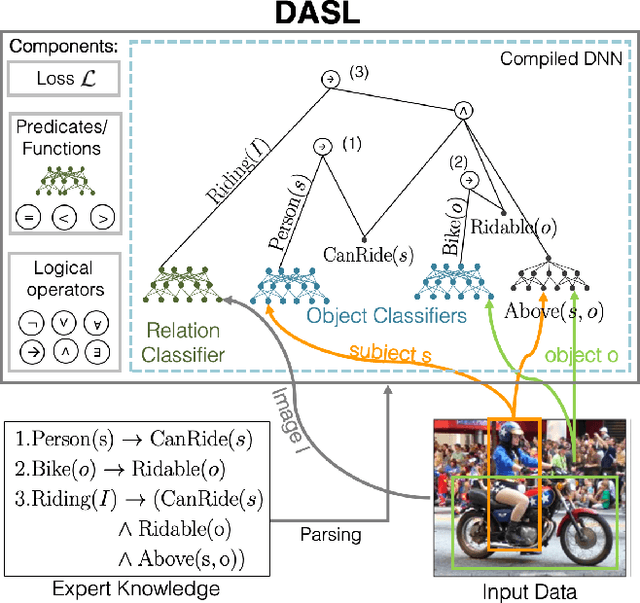
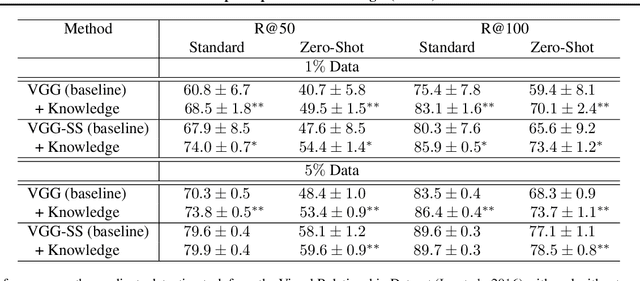
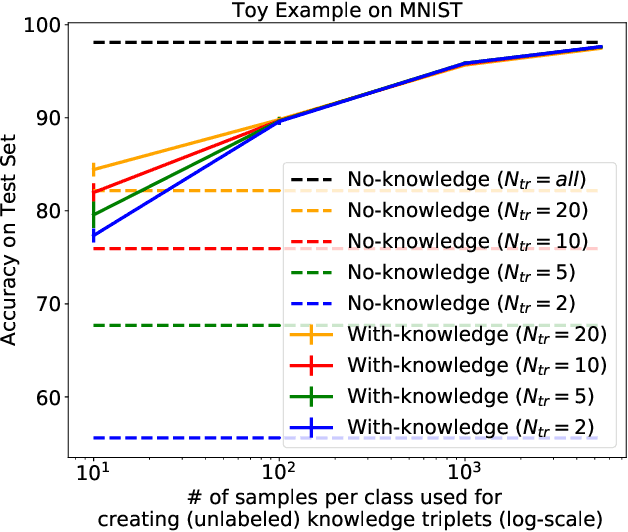
We introduce Deep Adaptive Semantic Logic (DASL), a novel framework for automating the generation of deep neural networks that incorporates user-provided formal knowledge to improve learning from data. We provide formal semantics that demonstrate that our knowledge representation captures all of first order logic and that finite sampling from infinite domains converges to correct truth values. DASL's representation improves on prior neural-symbolic work by avoiding vanishing gradients, allowing deeper logical structure, and enabling richer interactions between the knowledge and learning components. We illustrate DASL through a toy problem in which we add structure to an image classification problem and demonstrate that knowledge of that structure reduces data requirements by a factor of $1000$. We then evaluate DASL on a visual relationship detection task and demonstrate that the addition of commonsense knowledge improves performance by $10.7\%$ in a data scarce setting.
MSA-MIL: A deep residual multiple instance learning model based on multi-scale annotation for classification and visualization of glomerular spikes
Jul 02, 2020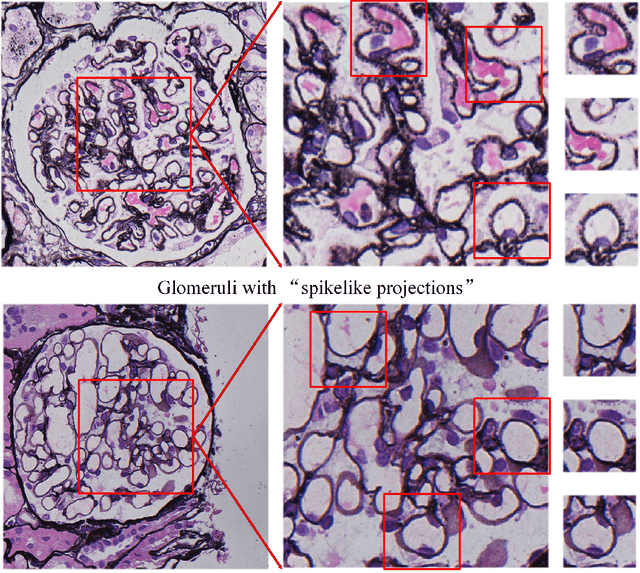
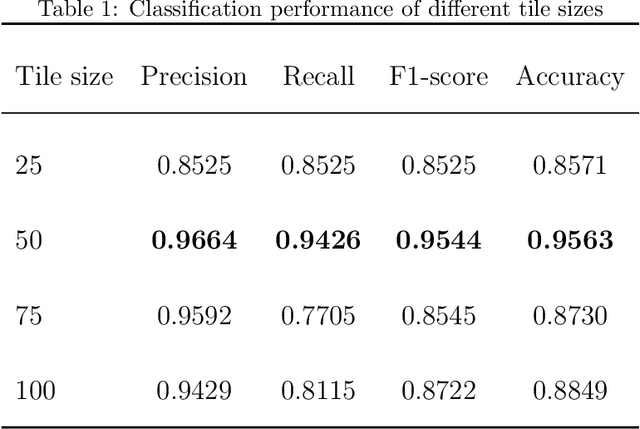
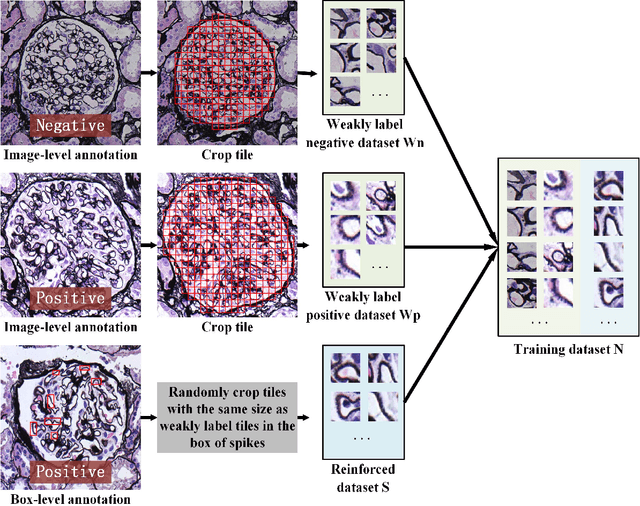
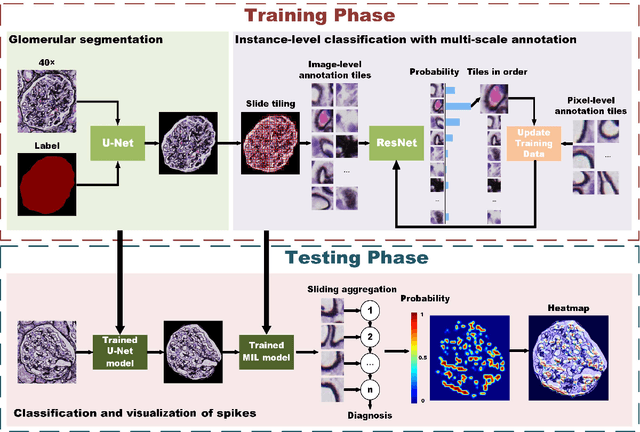
Membranous nephropathy (MN) is a frequent type of adult nephrotic syndrome, which has a high clinical incidence and can cause various complications. In the biopsy microscope slide of membranous nephropathy, spikelike projections on the glomerular basement membrane is a prominent feature of the MN. However, due to the whole biopsy slide contains large number of glomeruli, and each glomerulus includes many spike lesions, the pathological feature of the spikes is not obvious. It thus is time-consuming for doctors to diagnose glomerulus one by one and is difficult for pathologists with less experience to diagnose. In this paper, we establish a visualized classification model based on the multi-scale annotation multi-instance learning (MSA-MIL) to achieve glomerular classification and spikes visualization. The MSA-MIL model mainly involves three parts. Firstly, U-Net is used to extract the region of the glomeruli to ensure that the features learned by the succeeding algorithm are focused inside the glomeruli itself. Secondly, we use MIL to train an instance-level classifier combined with MSA method to enhance the learning ability of the network by adding a location-level labeled reinforced dataset, thereby obtaining an example-level feature representation with rich semantics. Lastly, the predicted scores of each tile in the image are summarized to obtain glomerular classification and visualization of the classification results of the spikes via the usage of sliding window method. The experimental results confirm that the proposed MSA-MIL model can effectively and accurately classify normal glomeruli and spiked glomerulus and visualize the position of spikes in the glomerulus. Therefore, the proposed model can provide a good foundation for assisting the clinical doctors to diagnose the glomerular membranous nephropathy.
What Should I Ask? Using Conversationally Informative Rewards for Goal-Oriented Visual Dialog
Jul 28, 2019
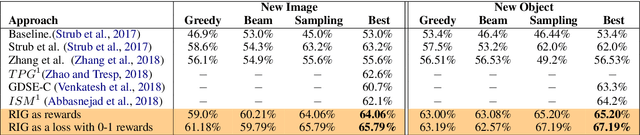
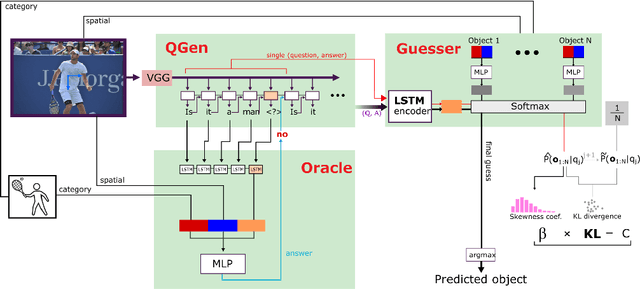
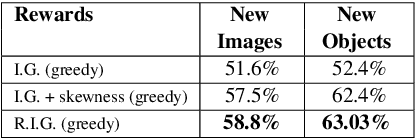
The ability to engage in goal-oriented conversations has allowed humans to gain knowledge, reduce uncertainty, and perform tasks more efficiently. Artificial agents, however, are still far behind humans in having goal-driven conversations. In this work, we focus on the task of goal-oriented visual dialogue, aiming to automatically generate a series of questions about an image with a single objective. This task is challenging since these questions must not only be consistent with a strategy to achieve a goal, but also consider the contextual information in the image. We propose an end-to-end goal-oriented visual dialogue system, that combines reinforcement learning with regularized information gain. Unlike previous approaches that have been proposed for the task, our work is motivated by the Rational Speech Act framework, which models the process of human inquiry to reach a goal. We test the two versions of our model on the GuessWhat?! dataset, obtaining significant results that outperform the current state-of-the-art models in the task of generating questions to find an undisclosed object in an image.
CBCT-to-CT synthesis with a single neural network for head-and-neck, lung and breast cancer adaptive radiotherapy
Dec 23, 2019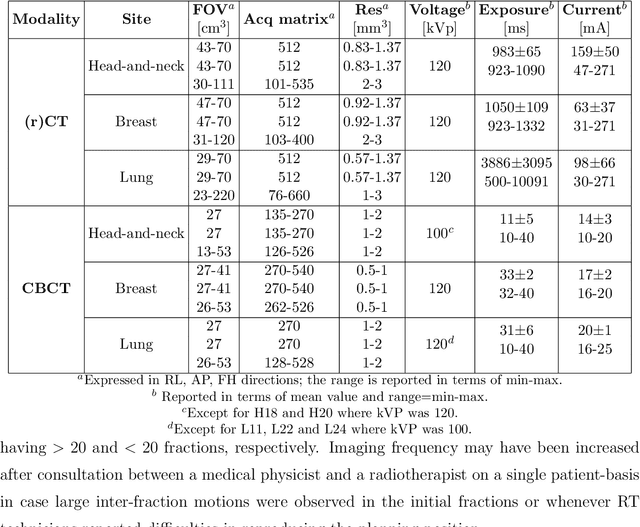
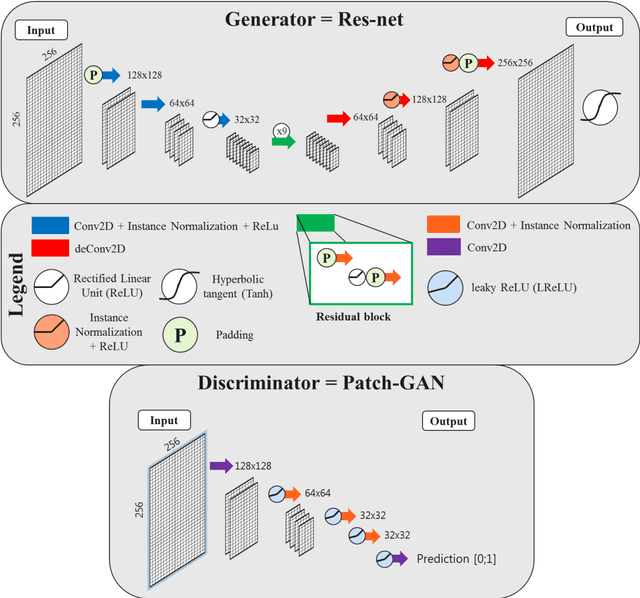
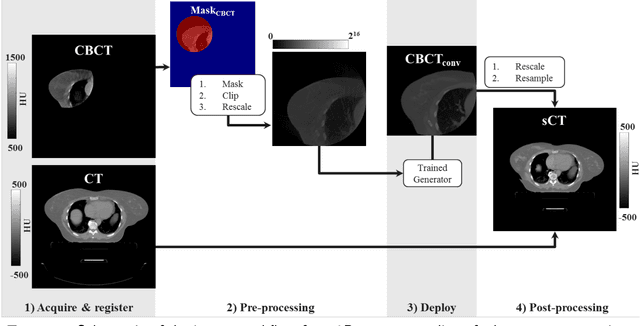
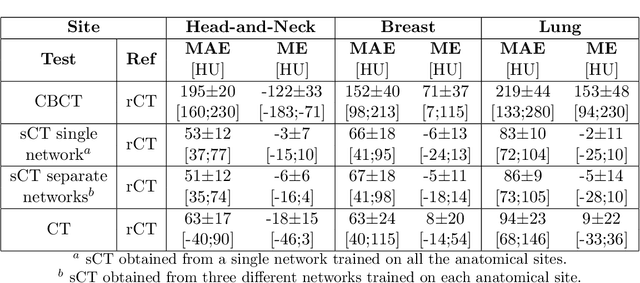
Purpose: CBCT-based adaptive radiotherapy requires daily images for accurate dose calculations. This study investigates the feasibility of applying a single convolutional network to facilitate CBCT-to-CT synthesis for head-and-neck, lung, and breast cancer patients. Methods: Ninety-nine patients diagnosed with head-and-neck, lung or breast cancer undergoing radiotherapy with CBCT-based position verification were included in this study. CBCTs were registered to planning CTs according to clinical procedures. Three cycle-consistent generative adversarial networks (cycle-GANs) were trained in an unpaired manner on 15 patients per anatomical site generating synthetic-CTs (sCTs). Another network was trained with all the anatomical sites together. Performances of all four networks were compared and evaluated for image similarity against rescan CT (rCT). Clinical plans were recalculated on CT and sCT and analysed through voxel-based dose differences and {\gamma}-analysis. Results: A sCT was generated in 10 seconds. Image similarity was comparable between models trained on different anatomical sites and a single model for all sites. Mean dose differences < 0.5% were obtained in high-dose regions. Mean gamma (2%,2mm) pass-rates > 95% were achieved for all sites. Conclusions: Cycle-GAN reduced CBCT artefacts and increased HU similarity to CT, enabling sCT-based dose calculations. The speed of the network can facilitate on-line adaptive radiotherapy using a single network for head-and-neck, lung and breast cancer patients.
Unsupervised Separation of Dynamics from Pixels
Jul 20, 2019
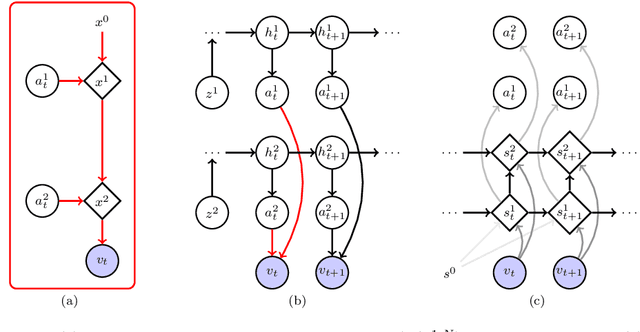
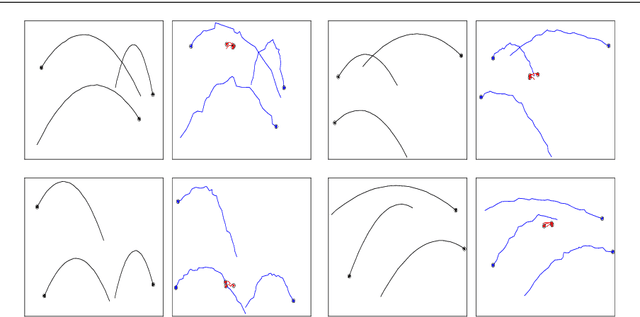
We present an approach to learn the dynamics of multiple objects from image sequences in an unsupervised way. We introduce a probabilistic model that first generate noisy positions for each object through a separate linear state-space model, and then renders the positions of all objects in the same image through a highly non-linear process. Such a linear representation of the dynamics enables us to propose an inference method that uses exact and efficient inference tools and that can be deployed to query the model in different ways without retraining.
Screen Content Image Segmentation Using Least Absolute Deviation Fitting
Feb 19, 2015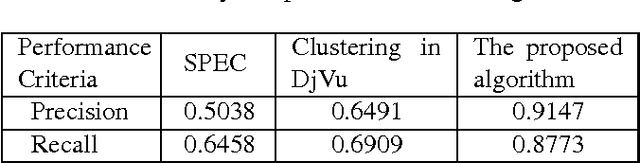

We propose an algorithm for separating the foreground (mainly text and line graphics) from the smoothly varying background in screen content images. The proposed method is designed based on the assumption that the background part of the image is smoothly varying and can be represented by a linear combination of a few smoothly varying basis functions, while the foreground text and graphics create sharp discontinuity and cannot be modeled by this smooth representation. The algorithm separates the background and foreground using a least absolute deviation method to fit the smooth model to the image pixels. This algorithm has been tested on several images from HEVC standard test sequences for screen content coding, and is shown to have superior performance over other popular methods, such as k-means clustering based segmentation in DjVu and shape primitive extraction and coding (SPEC) algorithm. Such background/foreground segmentation are important pre-processing steps for text extraction and separate coding of background and foreground for compression of screen content images.