 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Embedding Compression with Isotropic Iterative Quantization
Jan 23, 2020
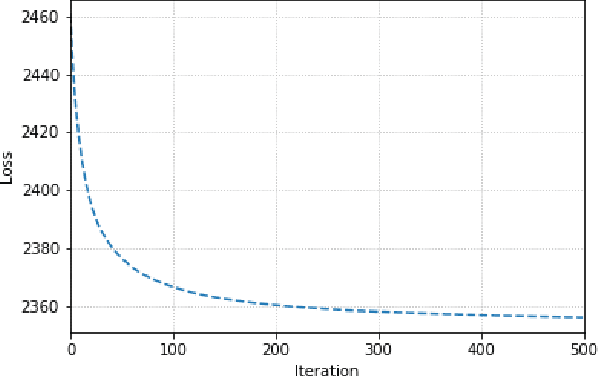
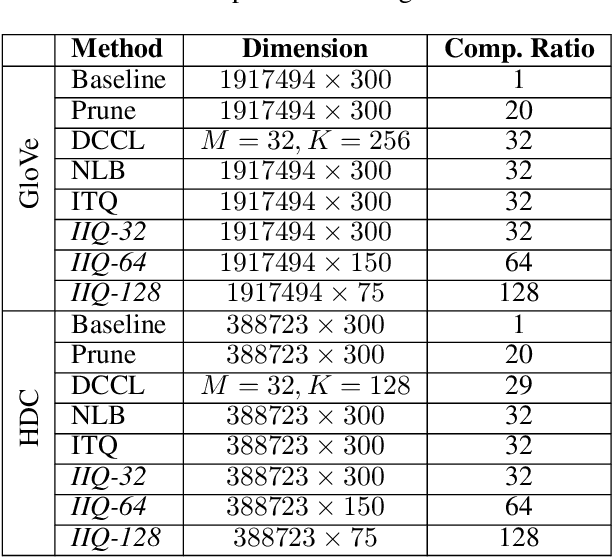
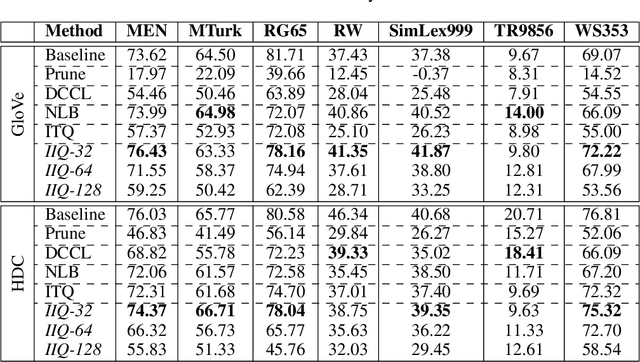
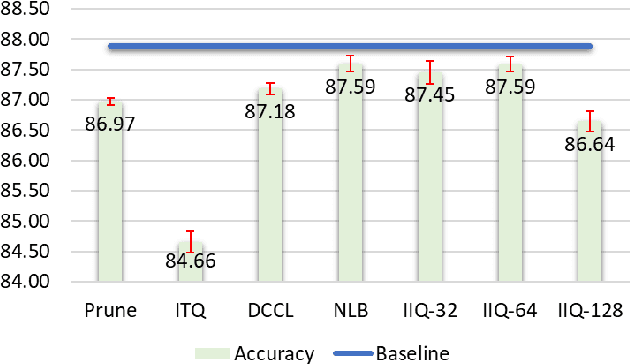
Continuous representation of words is a standard component in deep learning-based NLP models. However, representing a large vocabulary requires significant memory, which can cause problems, particularly on resource-constrained platforms. Therefore, in this paper we propose an isotropic iterative quantization (IIQ) approach for compressing embedding vectors into binary ones, leveraging the iterative quantization technique well established for image retrieval, while satisfying the desired isotropic property of PMI based models. Experiments with pre-trained embeddings (i.e., GloVe and HDC) demonstrate a more than thirty-fold compression ratio with comparable and sometimes even improved performance over the original real-valued embedding vectors.
DR$\vert$GRADUATE: uncertainty-aware deep learning-based diabetic retinopathy grading in eye fundus images
Oct 25, 2019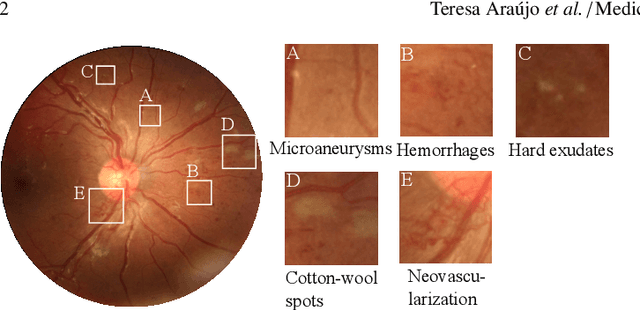
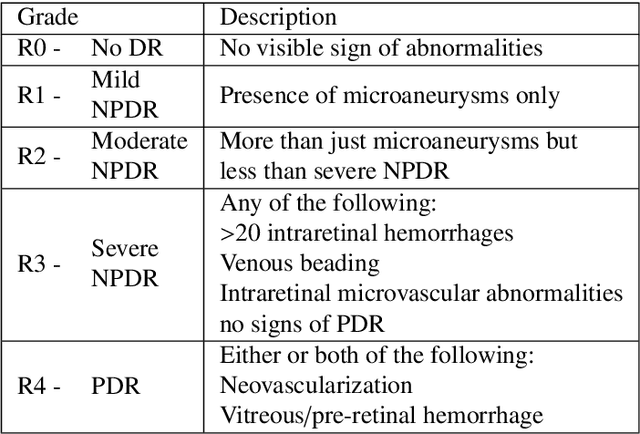
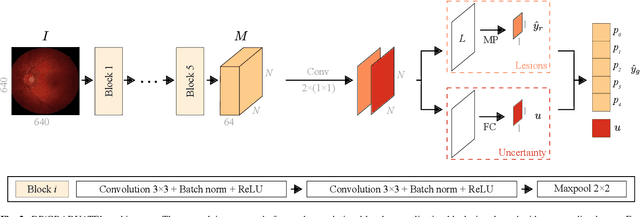

Diabetic retinopathy (DR) grading is crucial in determining the patients' adequate treatment and follow up, but the screening process can be tiresome and prone to errors. Deep learning approaches have shown promising performance as computer-aided diagnosis(CAD) systems, but their black-box behaviour hinders the clinical application. We propose DR$\vert$GRADUATE, a novel deep learning-based DR grading CAD system that supports its decision by providing a medically interpretable explanation and an estimation of how uncertain that prediction is, allowing the ophthalmologist to measure how much that decision should be trusted. We designed DR$\vert$GRADUATE taking into account the ordinal nature of the DR grading problem. A novel Gaussian-sampling approach built upon a Multiple Instance Learning framework allow DR$\vert$GRADUATE to infer an image grade associated with an explanation map and a prediction uncertainty while being trained only with image-wise labels. DR$\vert$GRADUATE was trained on the Kaggle training set and evaluated across multiple datasets. In DR grading, a quadratic-weighted Cohen's kappa (QWK) between 0.71 and 0.84 was achieved in five different datasets. We show that high QWK values occur for images with low prediction uncertainty, thus indicating that this uncertainty is a valid measure of the predictions' quality. Further, bad quality images are generally associated with higher uncertainties, showing that images not suitable for diagnosis indeed lead to less trustworthy predictions. Additionally, tests on unfamiliar medical image data types suggest that DR$\vert$GRADUATE allows outlier detection. The attention maps generally highlight regions of interest for diagnosis. These results show the great potential of DR$\vert$GRADUATE as a second-opinion system in DR severity grading.
Generative adversarial network for segmentation of motion affected neonatal brain MRI
Jun 11, 2019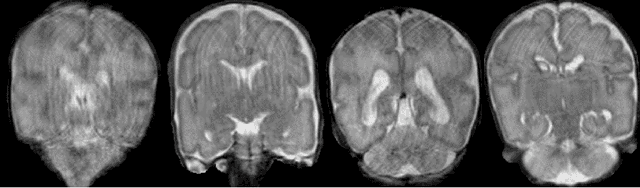
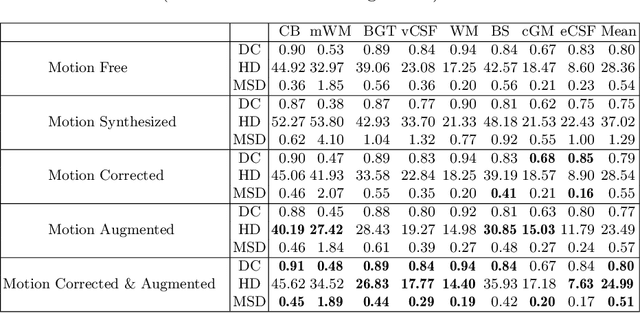
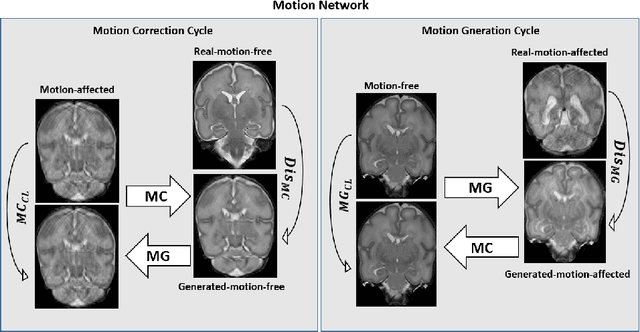
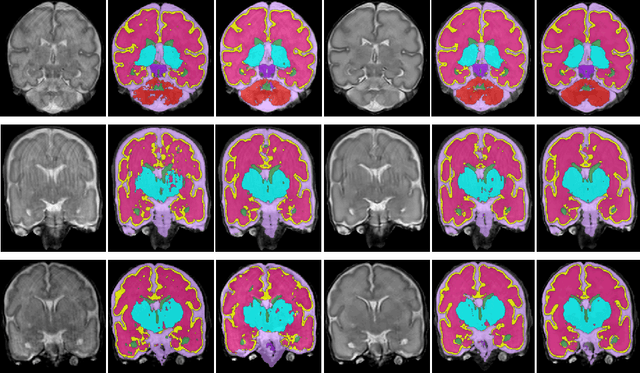
Automatic neonatal brain tissue segmentation in preterm born infants is a prerequisite for evaluation of brain development. However, automatic segmentation is often hampered by motion artifacts caused by infant head movements during image acquisition. Methods have been developed to remove or minimize these artifacts during image reconstruction using frequency domain data. However, frequency domain data might not always be available. Hence, in this study we propose a method for removing motion artifacts from the already reconstructed MR scans. The method employs a generative adversarial network trained with a cycle consistency loss to transform slices affected by motion into slices without motion artifacts, and vice versa. In the experiments 40 T2-weighted coronal MR scans of preterm born infants imaged at 30 weeks postmenstrual age were used. All images contained slices affected by motion artifacts hampering automatic tissue segmentation. To evaluate whether correction allows more accurate image segmentation, the images were segmented into 8 tissue classes: cerebellum, myelinated white matter, basal ganglia and thalami, ventricular cerebrospinal fluid, white matter, brain stem, cortical gray matter, and extracerebral cerebrospinal fluid. Images corrected for motion and corresponding segmentations were qualitatively evaluated using 5-point Likert scale. Before the correction of motion artifacts, median image quality and quality of corresponding automatic segmentations were assigned grade 2 (poor) and 3 (moderate), respectively. After correction of motion artifacts, both improved to grades 3 and 4, respectively. The results indicate that correction of motion artifacts in the image space using the proposed approach allows accurate segmentation of brain tissue classes in slices affected by motion artifacts.
Gaussian-Dirichlet Random Fields for Inference over High Dimensional Categorical Observations
Mar 26, 2020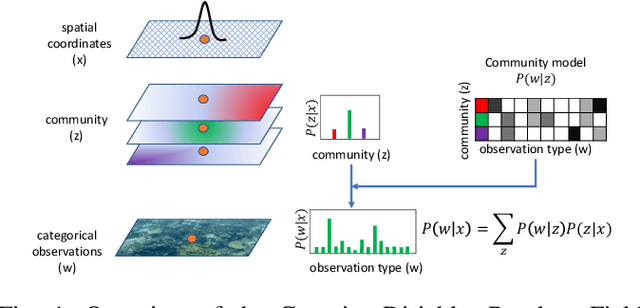
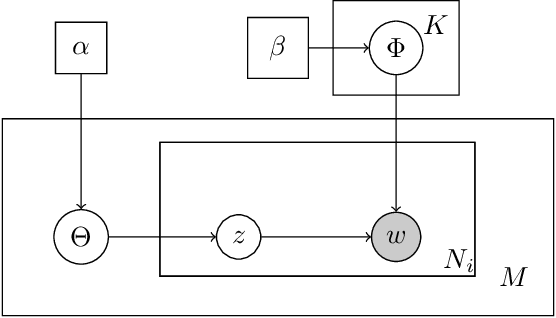
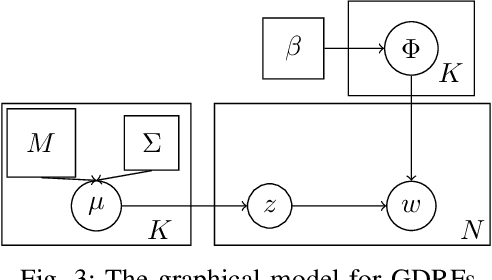
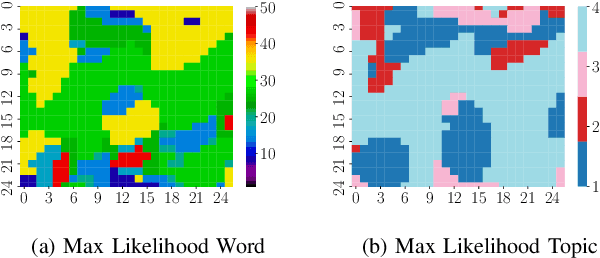
We propose a generative model for the spatio-temporal distribution of high dimensional categorical observations. These are commonly produced by robots equipped with an imaging sensor such as a camera, paired with an image classifier, potentially producing observations over thousands of categories. The proposed approach combines the use of Dirichlet distributions to model sparse co-occurrence relations between the observed categories using a latent variable, and Gaussian processes to model the latent variable's spatio-temporal distribution. Experiments in this paper show that the resulting model is able to efficiently and accurately approximate the temporal distribution of high dimensional categorical measurements such as taxonomic observations of microscopic organisms in the ocean, even in unobserved (held out) locations, far from other samples. This work's primary motivation is to enable deployment of informative path planning techniques over high dimensional categorical fields, which until now have been limited to scalar or low dimensional vector observations.
Learning Physical Graph Representations from Visual Scenes
Jun 22, 2020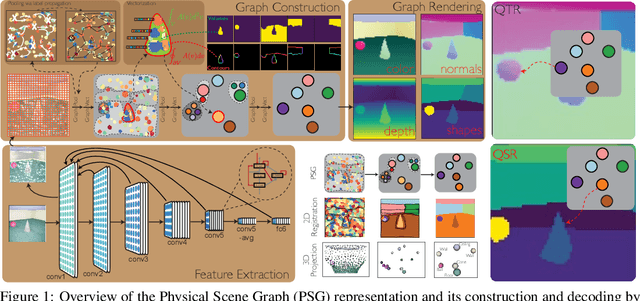
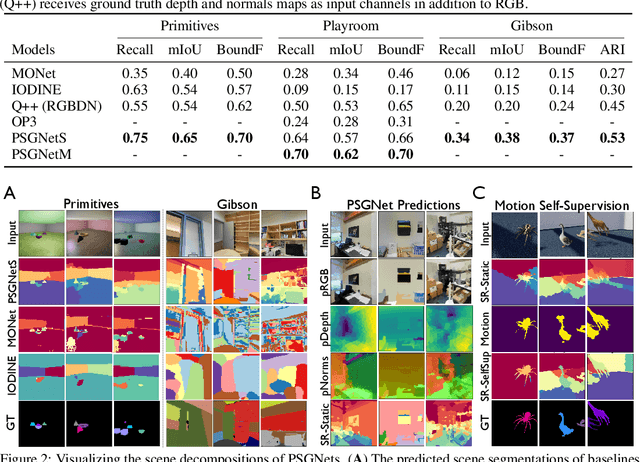
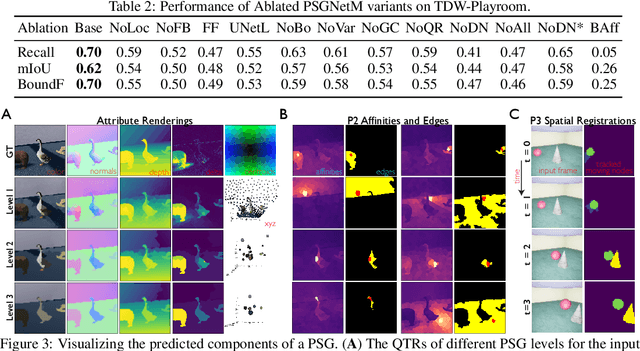

Convolutional Neural Networks (CNNs) have proved exceptional at learning representations for visual object categorization. However, CNNs do not explicitly encode objects, parts, and their physical properties, which has limited CNNs' success on tasks that require structured understanding of visual scenes. To overcome these limitations, we introduce the idea of Physical Scene Graphs (PSGs), which represent scenes as hierarchical graphs, with nodes in the hierarchy corresponding intuitively to object parts at different scales, and edges to physical connections between parts. Bound to each node is a vector of latent attributes that intuitively represent object properties such as surface shape and texture. We also describe PSGNet, a network architecture that learns to extract PSGs by reconstructing scenes through a PSG-structured bottleneck. PSGNet augments standard CNNs by including: recurrent feedback connections to combine low and high-level image information; graph pooling and vectorization operations that convert spatially-uniform feature maps into object-centric graph structures; and perceptual grouping principles to encourage the identification of meaningful scene elements. We show that PSGNet outperforms alternative self-supervised scene representation algorithms at scene segmentation tasks, especially on complex real-world images, and generalizes well to unseen object types and scene arrangements. PSGNet is also able learn from physical motion, enhancing scene estimates even for static images. We present a series of ablation studies illustrating the importance of each component of the PSGNet architecture, analyses showing that learned latent attributes capture intuitive scene properties, and illustrate the use of PSGs for compositional scene inference.
Face Hallucination by Attentive Sequence Optimization with Reinforcement Learning
May 04, 2019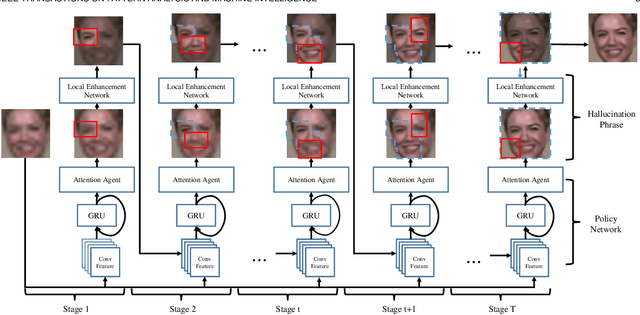
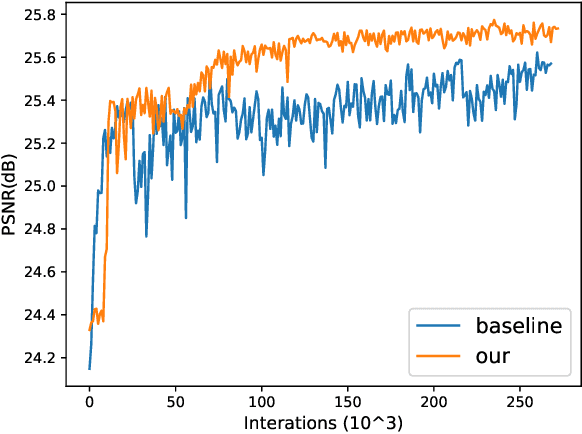
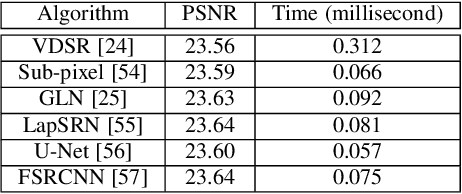
Face hallucination is a domain-specific super-resolution problem that aims to generate a high-resolution (HR) face image from a low-resolution~(LR) input. In contrast to the existing patch-wise super-resolution models that divide a face image into regular patches and independently apply LR to HR mapping to each patch, we implement deep reinforcement learning and develop a novel attention-aware face hallucination (Attention-FH) framework, which recurrently learns to attend a sequence of patches and performs facial part enhancement by fully exploiting the global interdependency of the image. Specifically, our proposed framework incorporates two components: a recurrent policy network for dynamically specifying a new attended region at each time step based on the status of the super-resolved image and the past attended region sequence, and a local enhancement network for selected patch hallucination and global state updating. The Attention-FH model jointly learns the recurrent policy network and local enhancement network through maximizing a long-term reward that reflects the hallucination result with respect to the whole HR image. Extensive experiments demonstrate that our Attention-FH significantly outperforms the state-of-the-art methods on in-the-wild face images with large pose and illumination variations.
AL2: Progressive Activation Loss for Learning General Representations in Classification Neural Networks
Mar 07, 2020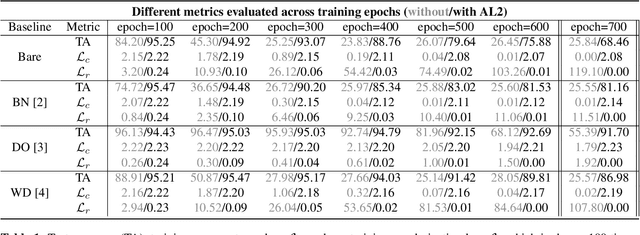
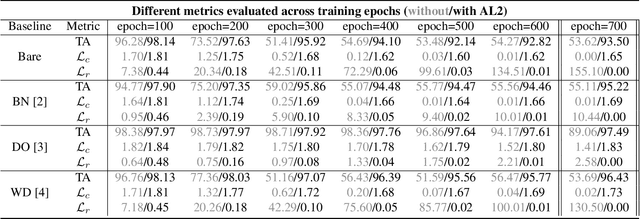
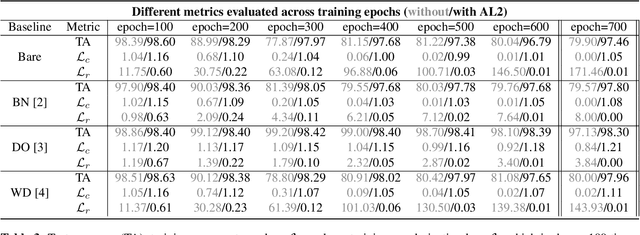
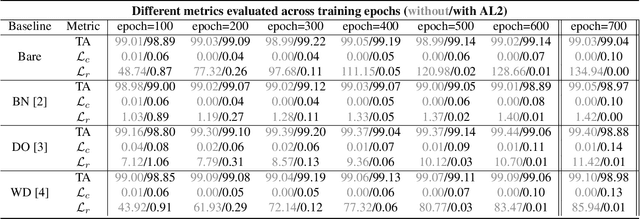
The large capacity of neural networks enables them to learn complex functions. To avoid overfitting, networks however require a lot of training data that can be expensive and time-consuming to collect. A common practical approach to attenuate overfitting is the use of network regularization techniques. We propose a novel regularization method that progressively penalizes the magnitude of activations during training. The combined activation signals produced by all neurons in a given layer form the representation of the input image in that feature space. We propose to regularize this representation in the last feature layer before classification layers. Our method's effect on generalization is analyzed with label randomization tests and cumulative ablations. Experimental results show the advantages of our approach in comparison with commonly-used regularizers on standard benchmark datasets.
Multi-modal Sensor Fusion-Based Deep Neural Network for End-to-end Autonomous Driving with Scene Understanding
May 19, 2020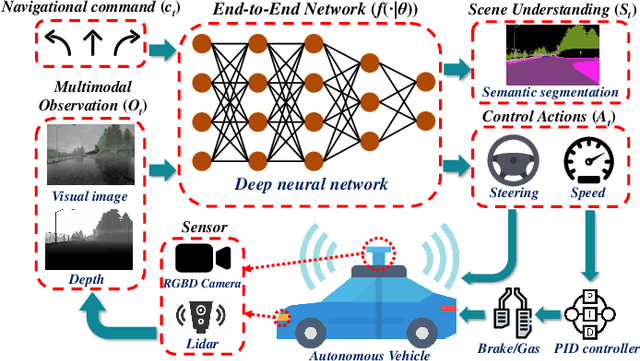
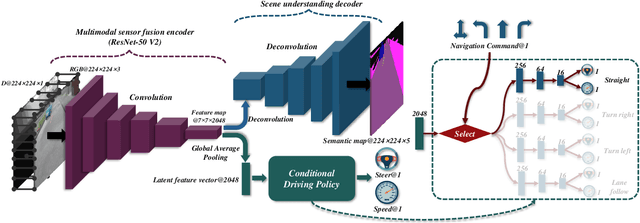
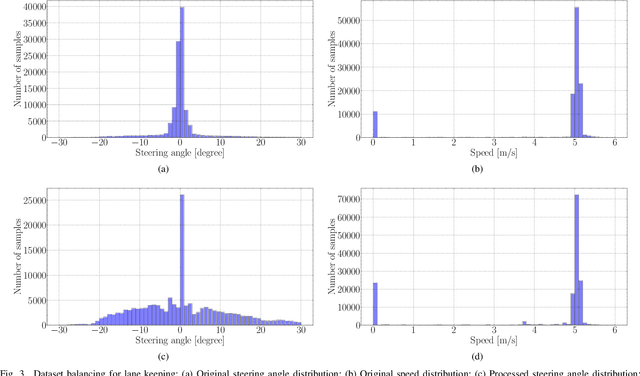

This study aims to improve the control performance and generalization capability of end-to-end autonomous driving with scene understanding leveraging deep learning and multimodal sensor fusion technology. The designed end-to-end deep neural network takes the visual image and associated depth information as inputs in an early fusion level and outputs the pixel-wise semantic segmentation as scene understanding and vehicle control commands concurrently. The end-to-end deep learning-based autonomous driving model is tested in high-fidelity simulated urban driving conditions and compared with the benchmark of CoRL2017 and NoCrash. The testing results show that the proposed approach is of better performance and generalization ability, achieving a 100\% success rate in static navigation tasks in both training and unobserved situations, as well as better success rates in other tasks than other existing models. A further ablation study shows that the model with the removal of multimodal sensor fusion or scene understanding pales in the new environment because of the false perception. The results verify that the performance of our model is improved by the synergy of multimodal sensor fusion with scene understanding subtask, demonstrating the feasibility and effectiveness of the developed deep neural network with multimodal sensor fusion.
Image Denoising Using Interquartile Range Filter with Local Averaging
Feb 05, 2013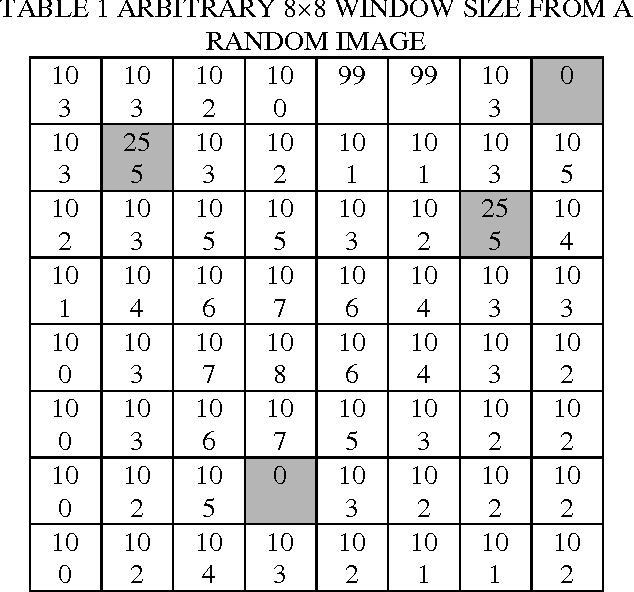
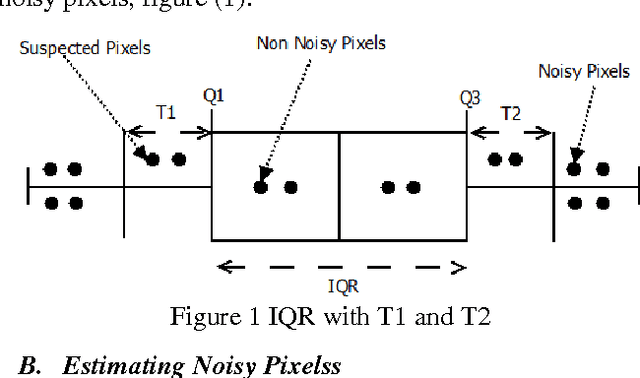

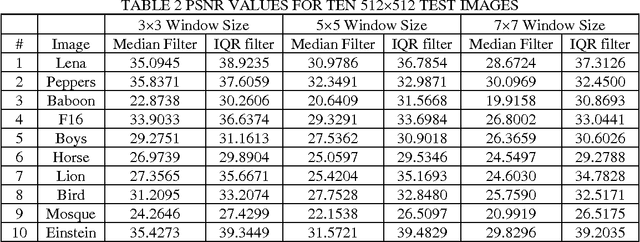
Image denoising is one of the fundamental problems in image processing. In this paper, a novel approach to suppress noise from the image is conducted by applying the interquartile range (IQR) which is one of the statistical methods used to detect outlier effect from a dataset. A window of size kXk was implemented to support IQR filter. Each pixel outside the IQR range of the kXk window is treated as noisy pixel. The estimation of the noisy pixels was obtained by local averaging. The essential advantage of applying IQR filter is to preserve edge sharpness better of the original image. A variety of test images have been used to support the proposed filter and PSNR was calculated and compared with median filter. The experimental results on standard test images demonstrate this filter is simpler and better performing than median filter.
* 5 pages, 8 figures, 2 tables
Comparing the Performance of L*A*B* and HSV Color Spaces with Respect to Color Image Segmentation
Jun 04, 2015Color image segmentation is a very emerging topic for image processing research. Since it has the ability to present the result in a way that is much more close to the human yes perceive, so todays more research is going on this area. Choosing a proper color space is a very important issue for color image segmentation process. Generally LAB and HSV are the two frequently chosen color spaces. In this paper a comparative analysis is performed between these two color spaces with respect to color image segmentation. For measuring their performance, we consider the parameters: mse and psnr . It is found that HSV color space is performing better than LAB.