 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Train, Learn, Expand, Repeat
Mar 18, 2020
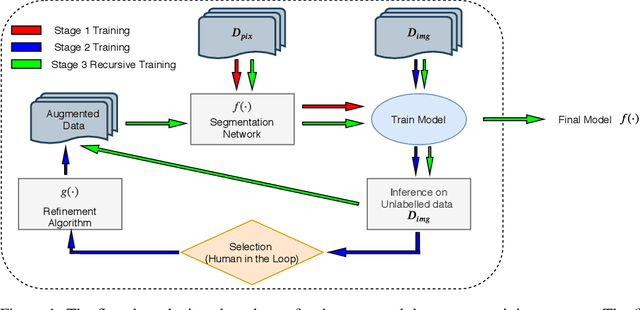
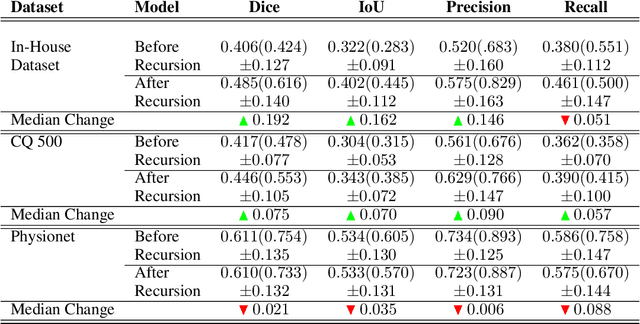
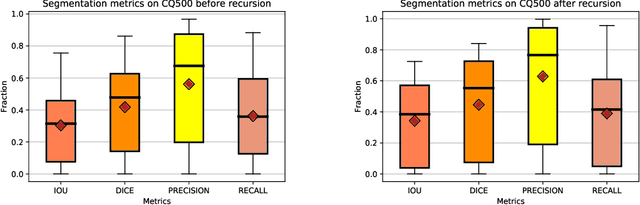
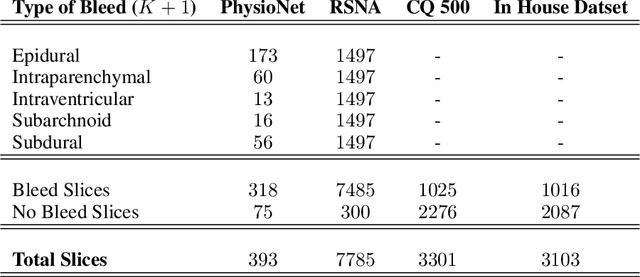
High-quality labeled data is essential to successfully train supervised machine learning models. Although a large amount of unlabeled data is present in the medical domain, labeling poses a major challenge: medical professionals who can expertly label the data are a scarce and expensive resource. Making matters worse, voxel-wise delineation of data (e.g. for segmentation tasks) is tedious and suffers from high inter-rater variance, thus dramatically limiting available training data. We propose a recursive training strategy to perform the task of semantic segmentation given only very few training samples with pixel-level annotations. We expand on this small training set having cheaper image-level annotations using a recursive training strategy. We apply this technique on the segmentation of intracranial hemorrhage (ICH) in CT (computed tomography) scans of the brain, where typically few annotated data is available.
Vibration Analysis in Bearings for Failure Prevention using CNN
May 06, 2020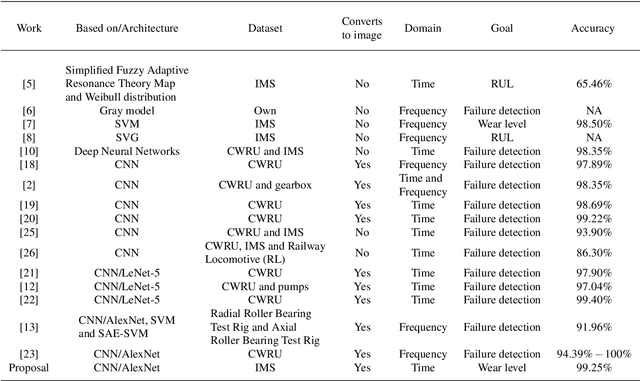
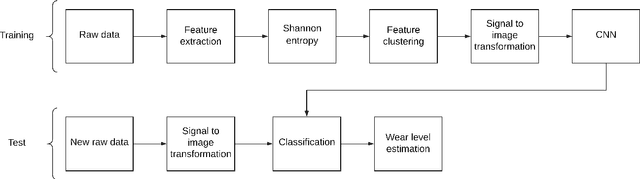

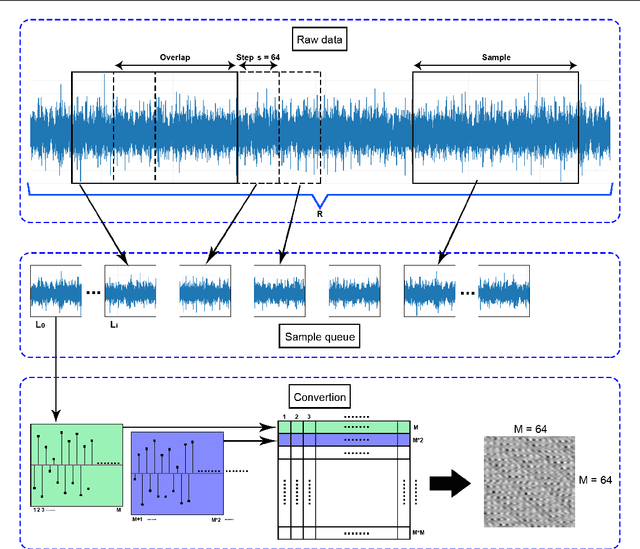
Timely failure detection for bearings is of great importance to prevent economic loses in the industry. In this article we propose a method based on Convolutional Neural Networks (CNN) to estimate the level of wear in bearings. First of all, an automatic labeling of the raw vibration data is performed to obtain different levels of bearing wear, by means of the Root Mean Square features along with the Shannon's entropy to extract features from the raw data, which is then grouped in seven different classes using the K-means algorithm to obtain the labels. Then, the raw vibration data is converted into small square images, each sample of the data representing one pixel of the image. Following this, we propose a CNN model based on the AlexNet architecture to classify the wear level and diagnose the rotatory system. To train the network and validate our proposal, we use a dataset from the center of Intelligent Maintenance Systems (IMS), and extensively compare it with other methods reported in the literature. The effectiveness of the proposed strategy proved to be excellent, outperforming other approaches in the state-of-the-art.
An empirical study on the effects of different types of noise in image classification tasks
Sep 09, 2016
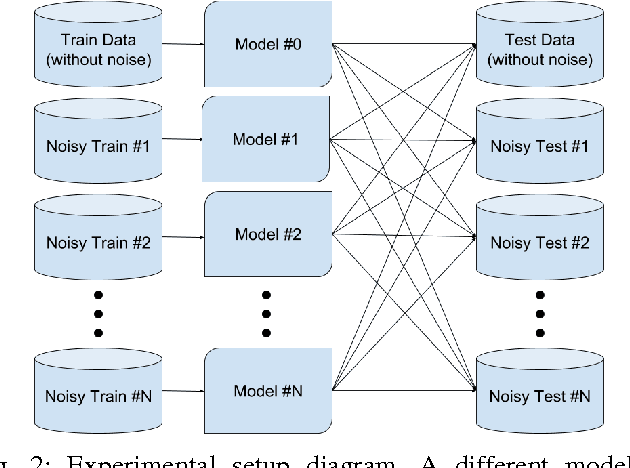

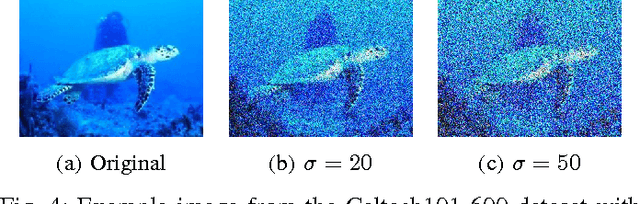
Image classification is one of the main research problems in computer vision and machine learning. Since in most real-world image classification applications there is no control over how the images are captured, it is necessary to consider the possibility that these images might be affected by noise (e.g. sensor noise in a low-quality surveillance camera). In this paper we analyse the impact of three different types of noise on descriptors extracted by two widely used feature extraction methods (LBP and HOG) and how denoising the images can help to mitigate this problem. We carry out experiments on two different datasets and consider several types of noise, noise levels, and denoising methods. Our results show that noise can hinder classification performance considerably and make classes harder to separate. Although denoising methods were not able to reach the same performance of the noise-free scenario, they improved classification results for noisy data.
A Novel Visual Fault Detection and Classification System for Semiconductor Manufacturing Using Stacked Hybrid Convolutional Neural Networks
Nov 25, 2019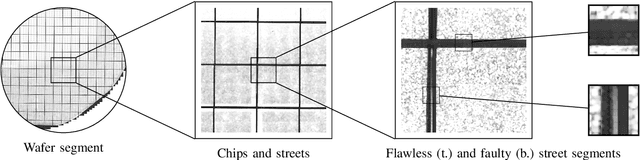
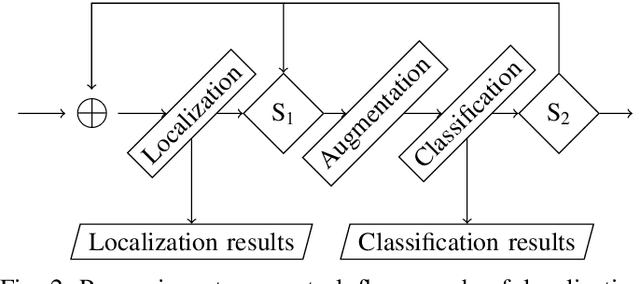
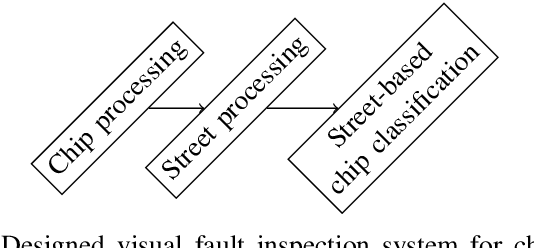
Automated visual inspection in the semiconductor industry aims to detect and classify manufacturing defects utilizing modern image processing techniques. While an earliest possible detection of defect patterns allows quality control and automation of manufacturing chains, manufacturers benefit from an increased yield and reduced manufacturing costs. Since classical image processing systems are limited in their ability to detect novel defect patterns, and machine learning approaches often involve a tremendous amount of computational effort, this contribution introduces a novel deep neural network-based hybrid approach. Unlike classical deep neural networks, a multi-stage system allows the detection and classification of the finest structures in pixel size within high-resolution imagery. Consisting of stacked hybrid convolutional neural networks (SH-CNN) and inspired by current approaches of visual attention, the realized system draws the focus over the level of detail from its structures to more task-relevant areas of interest. The results of our test environment show that the SH-CNN outperforms current approaches of learning-based automated visual inspection, whereas a distinction depending on the level of detail enables the elimination of defect patterns in earlier stages of the manufacturing process.
A Mean-Field Theory for Learning the Schönberg Measure of Radial Basis Functions
Jul 03, 2020
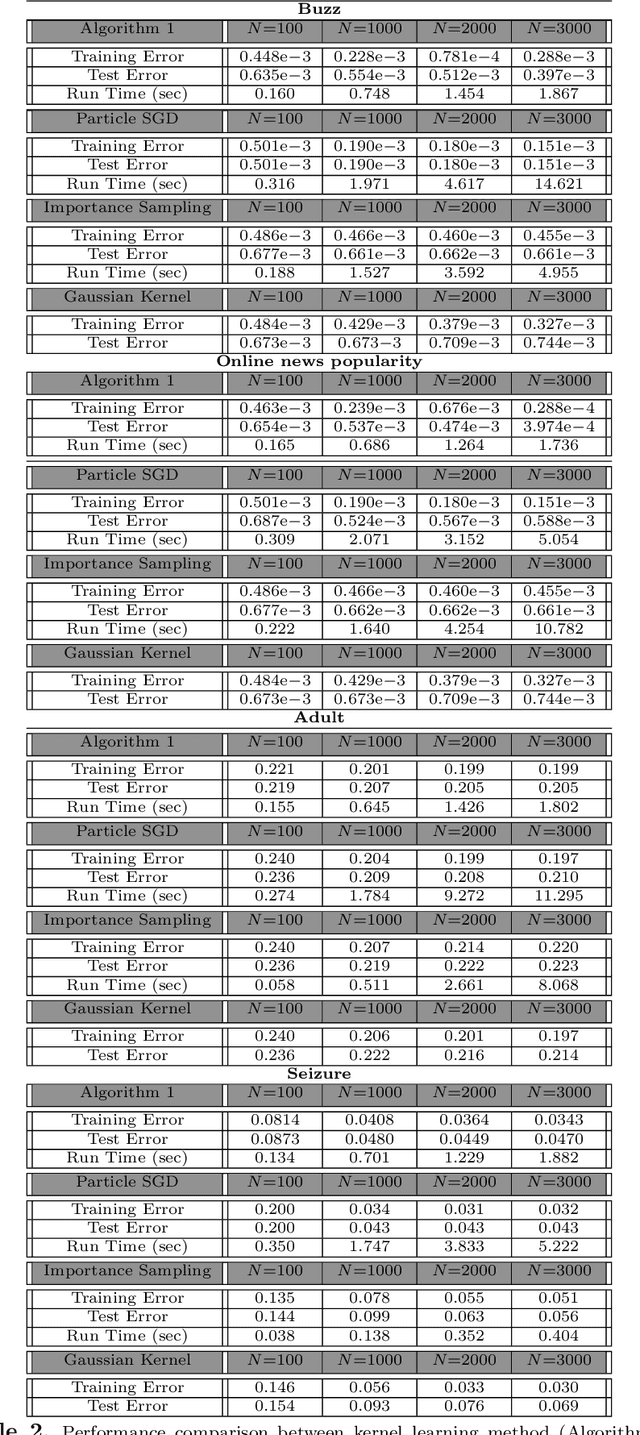
We develop and analyze a projected particle Langevin optimization method to learn the distribution in the Sch\"{o}nberg integral representation of the radial basis functions from training samples. More specifically, we characterize a distributionally robust optimization method with respect to the Wasserstein distance to optimize the distribution in the Sch\"{o}nberg integral representation. To provide theoretical performance guarantees, we analyze the scaling limits of a projected particle online (stochastic) optimization method in the mean-field regime. In particular, we prove that in the scaling limits, the empirical measure of the Langevin particles converges to the law of a reflected It\^{o} diffusion-drift process. Moreover, the drift is also a function of the law of the underlying process. Using It\^{o} lemma for semi-martingales and Grisanov's change of measure for the Wiener processes, we then derive a Mckean-Vlasov type partial differential equation (PDE) with Robin boundary conditions that describes the evolution of the empirical measure of the projected Langevin particles in the mean-field regime. In addition, we establish the existence and uniqueness of the steady-state solutions of the derived PDE in the weak sense. We apply our learning approach to train radial kernels in the kernel locally sensitive hash (LSH) functions, where the training data-set is generated via a $k$-mean clustering method on a small subset of data-base. We subsequently apply our kernel LSH with a trained kernel for image retrieval task on MNIST data-set, and demonstrate the efficacy of our kernel learning approach. We also apply our kernel learning approach in conjunction with the kernel support vector machines (SVMs) for classification of benchmark data-sets.
Mono-SF: Multi-View Geometry Meets Single-View Depth for Monocular Scene Flow Estimation of Dynamic Traffic Scenes
Aug 17, 2019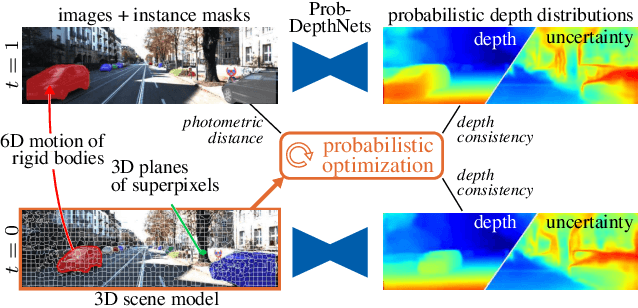
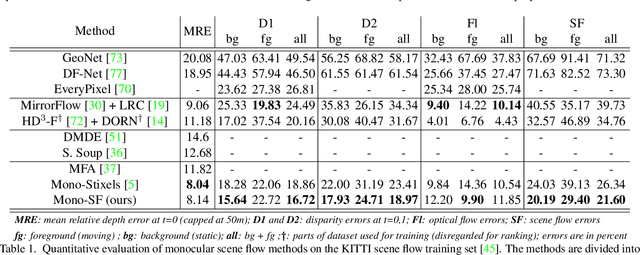
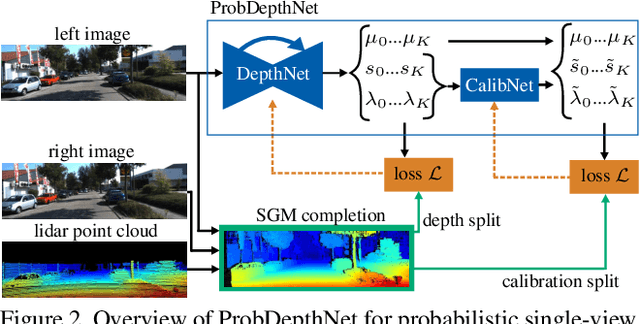
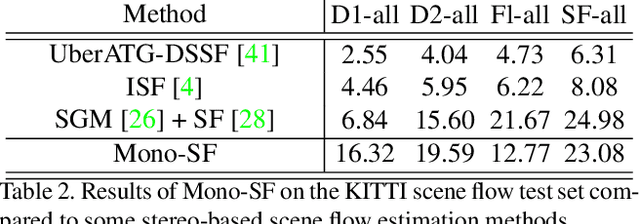
Existing 3D scene flow estimation methods provide the 3D geometry and 3D motion of a scene and gain a lot of interest, for example in the context of autonomous driving. These methods are traditionally based on a temporal series of stereo images. In this paper, we propose a novel monocular 3D scene flow estimation method, called Mono-SF. Mono-SF jointly estimates the 3D structure and motion of the scene by combining multi-view geometry and single-view depth information. Mono-SF considers that the scene flow should be consistent in terms of warping the reference image in the consecutive image based on the principles of multi-view geometry. For integrating single-view depth in a statistical manner, a convolutional neural network, called ProbDepthNet, is proposed. ProbDepthNet estimates pixel-wise depth distributions from a single image rather than single depth values. Additionally, as part of ProbDepthNet, a novel recalibration technique for regression problems is proposed to ensure well-calibrated distributions. Our experiments show that Mono-SF outperforms state-of-the-art monocular baselines and ablation studies support the Mono-SF approach and ProbDepthNet design.
Was there COVID-19 back in 2012? Challenge for AI in Diagnosis with Similar Indications
Jun 23, 2020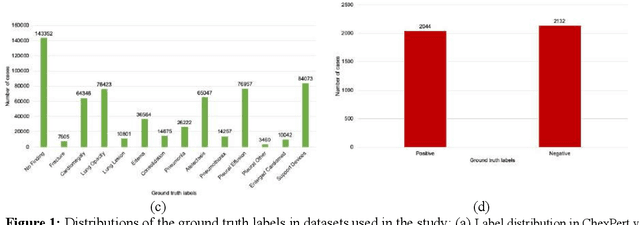
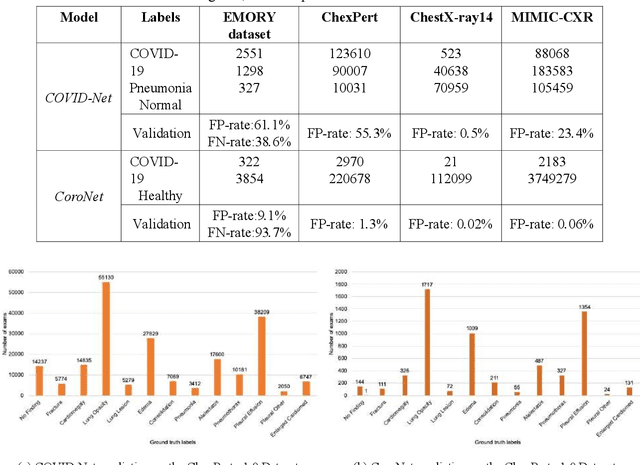
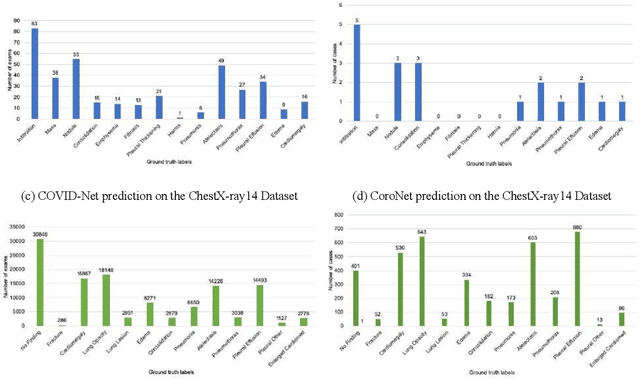
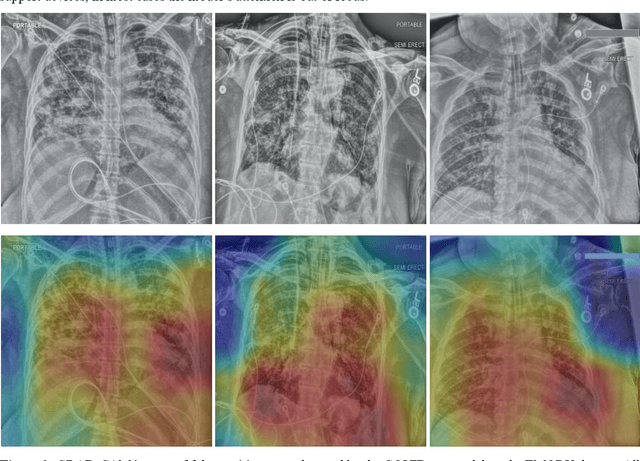
Purpose: Since the recent COVID-19 outbreak, there has been an avalanche of research papers applying deep learning based image processing to chest radiographs for detection of the disease. To test the performance of the two top models for CXR COVID-19 diagnosis on external datasets to assess model generalizability. Methods: In this paper, we present our argument regarding the efficiency and applicability of existing deep learning models for COVID-19 diagnosis. We provide results from two popular models - COVID-Net and CoroNet evaluated on three publicly available datasets and an additional institutional dataset collected from EMORY Hospital between January and May 2020, containing patients tested for COVID-19 infection using RT-PCR. Results: There is a large false positive rate (FPR) for COVID-Net on both ChexPert (55.3%) and MIMIC-CXR (23.4%) dataset. On the EMORY Dataset, COVID-Net has 61.4% sensitivity, 0.54 F1-score and 0.49 precision value. The FPR of the CoroNet model is significantly lower across all the datasets as compared to COVID-Net - EMORY(9.1%), ChexPert (1.3%), ChestX-ray14 (0.02%), MIMIC-CXR (0.06%). Conclusion: The models reported good to excellent performance on their internal datasets, however we observed from our testing that their performance dramatically worsened on external data. This is likely from several causes including overfitting models due to lack of appropriate control patients and ground truth labels. The fourth institutional dataset was labeled using RT-PCR, which could be positive without radiographic findings and vice versa. Therefore, a fusion model of both clinical and radiographic data may have better performance and generalization.
Multi-View Optimization of Local Feature Geometry
Mar 18, 2020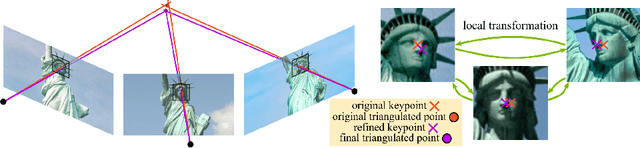
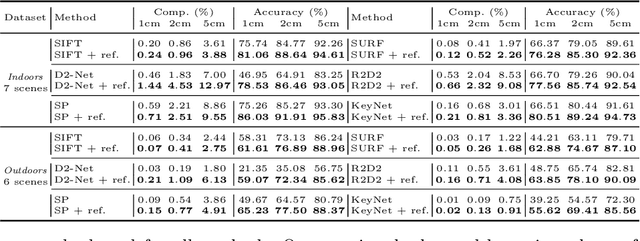
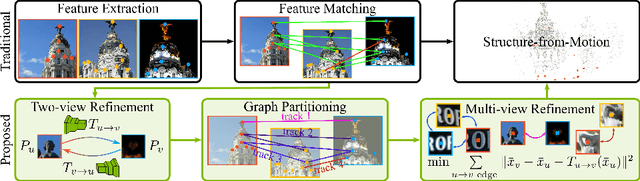
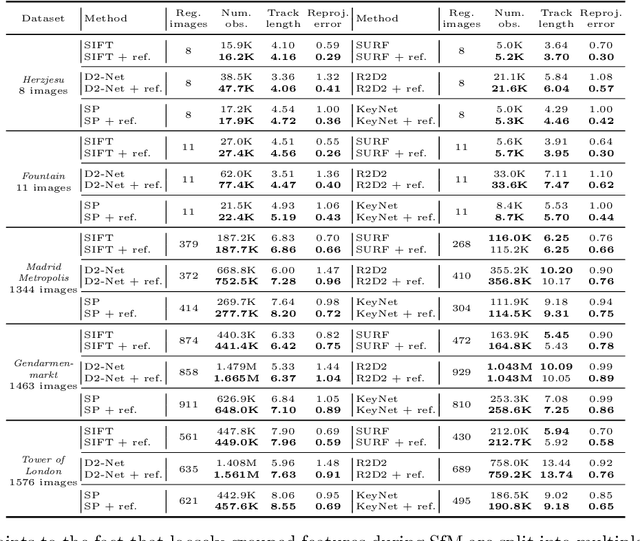
In this work, we address the problem of refining the geometry of local image features from multiple views without known scene or camera geometry. Current approaches to local feature detection are inherently limited in their keypoint localization accuracy because they only operate on a single view. This limitation has a negative impact on downstream tasks such as Structure-from-Motion, where inaccurate keypoints lead to large errors in triangulation and camera localization. Our proposed method naturally complements the traditional feature extraction and matching paradigm. We first estimate local geometric transformations between tentative matches and then optimize the keypoint locations over multiple views jointly according to a non-linear least squares formulation. Throughout a variety of experiments, we show that our method consistently improves the triangulation and camera localization performance for both hand-crafted and learned local features.
Learning Priors for Adversarial Autoencoders
Sep 10, 2019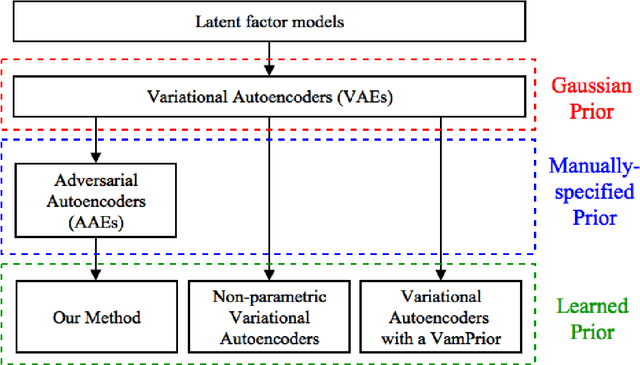
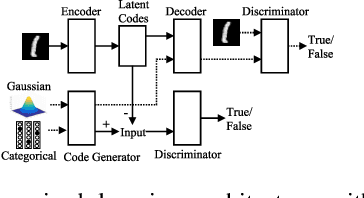

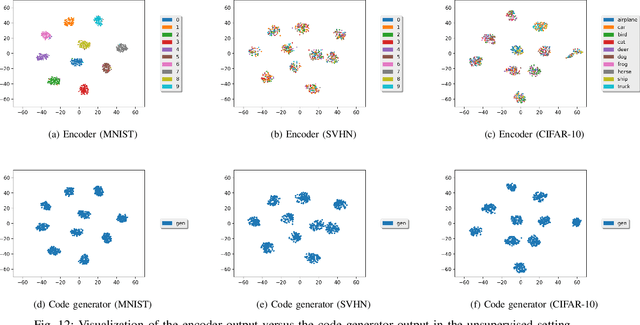
Most deep latent factor models choose simple priors for simplicity, tractability or not knowing what prior to use. Recent studies show that the choice of the prior may have a profound effect on the expressiveness of the model,especially when its generative network has limited capacity. In this paper, we propose to learn a proper prior from data for adversarial autoencoders(AAEs). We introduce the notion of code generators to transform manually selected simple priors into ones that can better characterize the data distribution. Experimental results show that the proposed model can generate better image quality and learn better disentangled representations than AAEs in both supervised and unsupervised settings. Lastly, we present its ability to do cross-domain translation in a text-to-image synthesis task.
DenoiSeg: Joint Denoising and Segmentation
May 06, 2020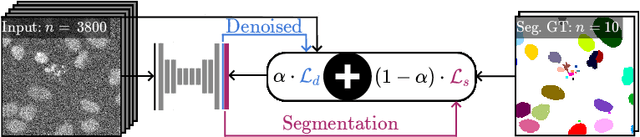

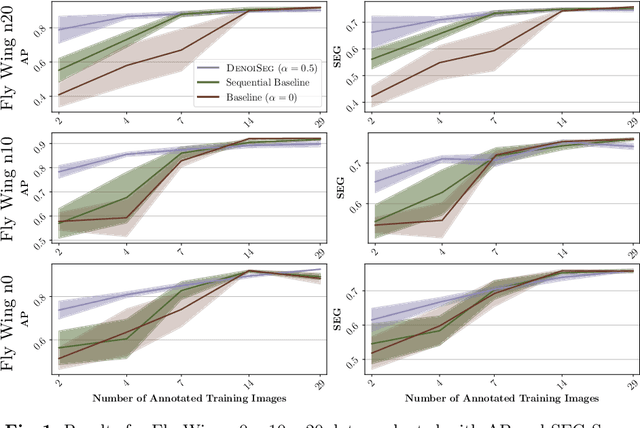
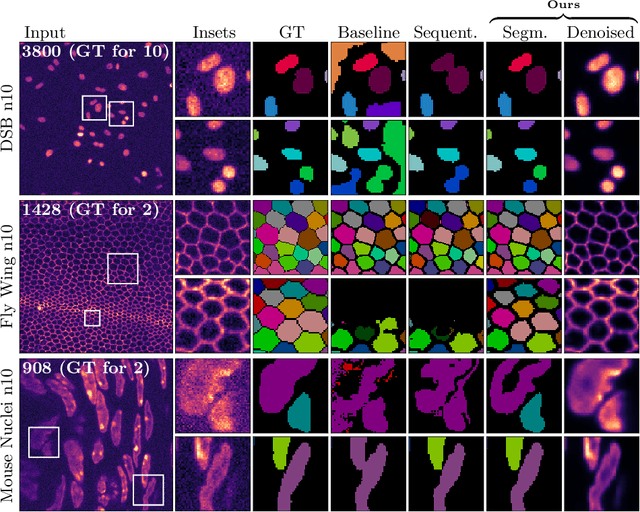
Microscopy image analysis often requires the segmentation of objects, but training data for this task is typically scarce and hard to obtain. Here we propose DenoiSeg, a new method that can be trained end-to-end on only a few annotated ground truth segmentations. We achieve this by extending Noise2Void, a self-supervised denoising scheme that can be trained on noisy images alone, to also predict dense 3-class segmentations. The reason for the success of our method is that segmentation can profit from denoising, especially when performed jointly within the same network. The network becomes a denoising expert by seeing all available raw data, while co-learning to segment, even if only a few segmentation labels are available. This hypothesis is additionally fueled by our observation that the best segmentation results on high quality (very low noise) raw data are obtained when moderate amounts of synthetic noise are added. This renders the denoising-task non-trivial and unleashes the desired co-learning effect. We believe that DenoiSeg offers a viable way to circumvent the tremendous hunger for high quality training data and effectively enables few-shot learning of dense segmentations.