 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Texture Superpixel Clustering from Patch-based Nearest Neighbor Matching
Mar 09, 2020
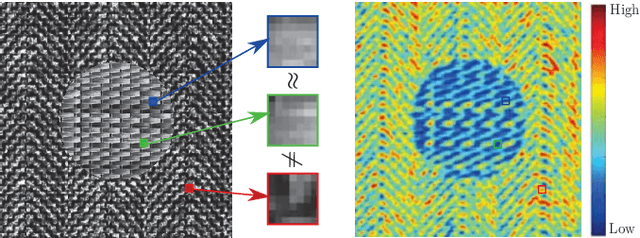
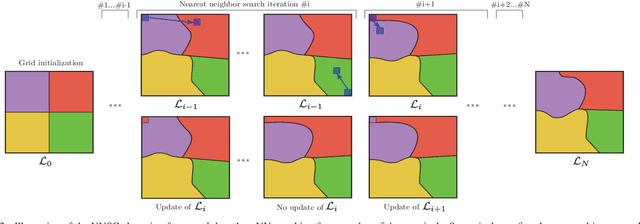
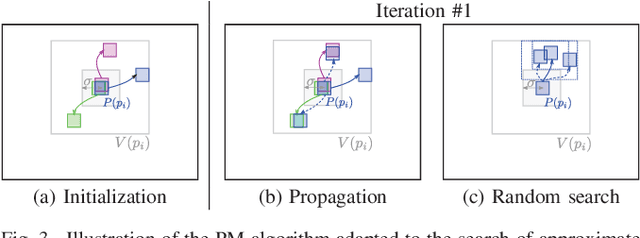
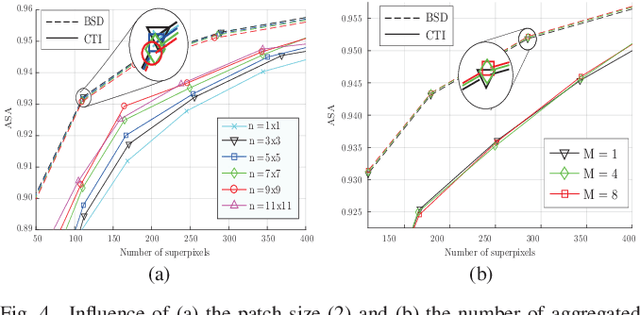
Superpixels are widely used in computer vision applications. Nevertheless, decomposition methods may still fail to efficiently cluster image pixels according to their local texture. In this paper, we propose a new Nearest Neighbor-based Superpixel Clustering (NNSC) method to generate texture-aware superpixels in a limited computational time compared to previous approaches. We introduce a new clustering framework using patch-based nearest neighbor matching, while most existing methods are based on a pixel-wise K-means clustering. Therefore, we directly group pixels in the patch space enabling to capture texture information. We demonstrate the efficiency of our method with favorable comparison in terms of segmentation performances on both standard color and texture datasets. We also show the computational efficiency of NNSC compared to recent texture-aware superpixel methods.
Generative Feature Replay with Orthogonal Weight Modification for Continual Learning
May 07, 2020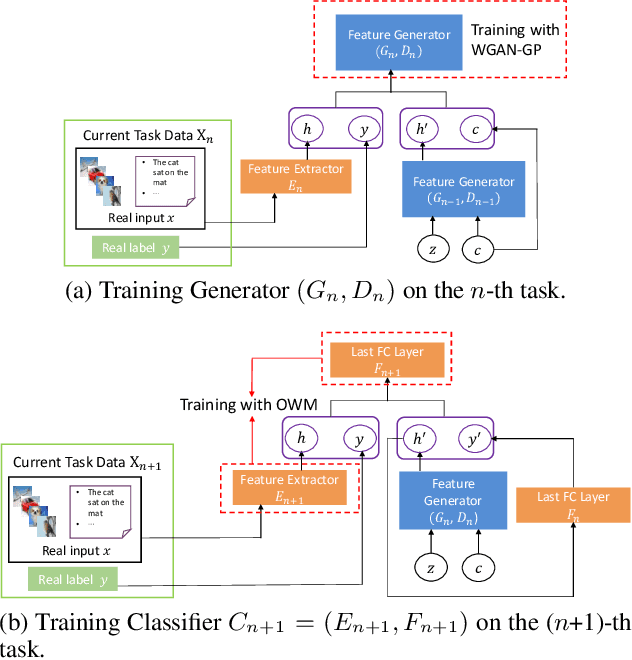


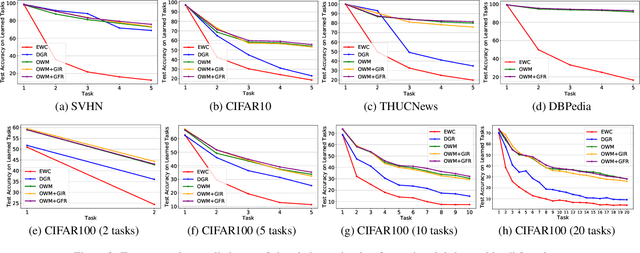
The ability of intelligent agents to learn and remember multiple tasks sequentially is crucial to achieving artificial general intelligence. Many continual learning (CL) methods have been proposed to overcome catastrophic forgetting. Catastrophic forgetting notoriously impedes the sequential learning of neural networks as the data of previous tasks are unavailable. In this paper we focus on class incremental learning, a challenging CL scenario, in which classes of each task are disjoint and task identity is unknown during test. For this scenario, generative replay is an effective strategy which generates and replays pseudo data for previous tasks to alleviate catastrophic forgetting. However, it is not trivial to learn a generative model continually for relatively complex data. Based on recently proposed orthogonal weight modification (OWM) algorithm which can keep previously learned input-output mappings invariant approximately when learning new tasks, we propose to directly generate and replay feature. Empirical results on image and text datasets show our method can improve OWM consistently by a significant margin while conventional generative replay always results in a negative effect. Our method also beats a state-of-the-art generative replay method and is competitive with a strong baseline based on real data storage.
Multi-Scale Representation Learning for Spatial Feature Distributions using Grid Cells
Feb 16, 2020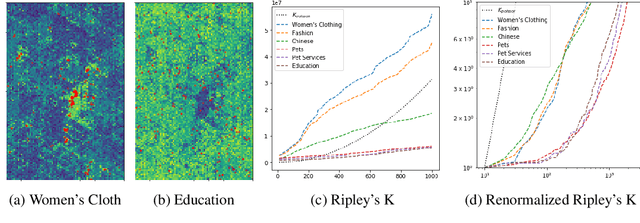
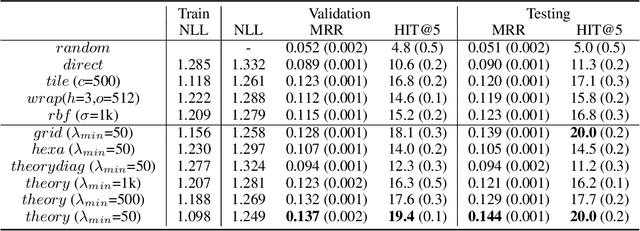

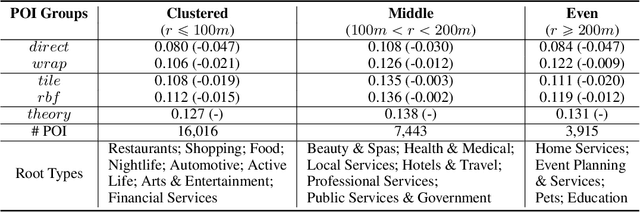
Unsupervised text encoding models have recently fueled substantial progress in NLP. The key idea is to use neural networks to convert words in texts to vector space representations based on word positions in a sentence and their contexts, which are suitable for end-to-end training of downstream tasks. We see a strikingly similar situation in spatial analysis, which focuses on incorporating both absolute positions and spatial contexts of geographic objects such as POIs into models. A general-purpose representation model for space is valuable for a multitude of tasks. However, no such general model exists to date beyond simply applying discretization or feed-forward nets to coordinates, and little effort has been put into jointly modeling distributions with vastly different characteristics, which commonly emerges from GIS data. Meanwhile, Nobel Prize-winning Neuroscience research shows that grid cells in mammals provide a multi-scale periodic representation that functions as a metric for location encoding and is critical for recognizing places and for path-integration. Therefore, we propose a representation learning model called Space2Vec to encode the absolute positions and spatial relationships of places. We conduct experiments on two real-world geographic data for two different tasks: 1) predicting types of POIs given their positions and context, 2) image classification leveraging their geo-locations. Results show that because of its multi-scale representations, Space2Vec outperforms well-established ML approaches such as RBF kernels, multi-layer feed-forward nets, and tile embedding approaches for location modeling and image classification tasks. Detailed analysis shows that all baselines can at most well handle distribution at one scale but show poor performances in other scales. In contrast, Space2Vec's multi-scale representation can handle distributions at different scales.
* 15 pages; Accepted to ICLR 2020 as a spotlight paper
Vid2Curve: Simultaneously Camera Motion Estimation and Thin Structure Reconstruction from an RGB Video
May 07, 2020
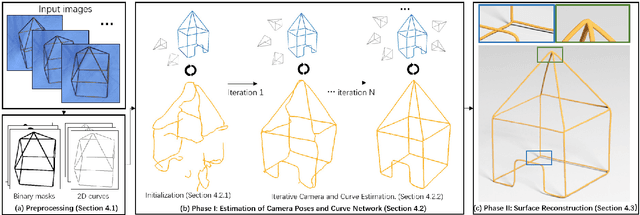
Thin structures, such as wire-frame sculptures, fences, cables, power lines, and tree branches, are common in the real world. It is extremely challenging to acquire their 3D digital models using traditional image-based or depth-based reconstruction methods because thin structures often lack distinct point features and have severe self-occlusion. We propose the first approach that simultaneously estimates camera motion and reconstructs the geometry of complex 3D thin structures in high quality from a color video captured by a handheld camera. Specifically, we present a new curve-based approach to estimate accurate camera poses by establishing correspondences between featureless thin objects in the foreground in consecutive video frames, without requiring visual texture in the background scene to lock on. Enabled by this effective curve-based camera pose estimation strategy, we develop an iterative optimization method with tailored measures on geometry, topology as well as self-occlusion handling for reconstructing 3D thin structures. Extensive validations on a variety of thin structures show that our method achieves accurate camera pose estimation and faithful reconstruction of 3D thin structures with complex shape and topology at a level that has not been attained by other existing reconstruction methods.
Adaptive Periodic Averaging: A Practical Approach to Reducing Communication in Distributed Learning
Jul 13, 2020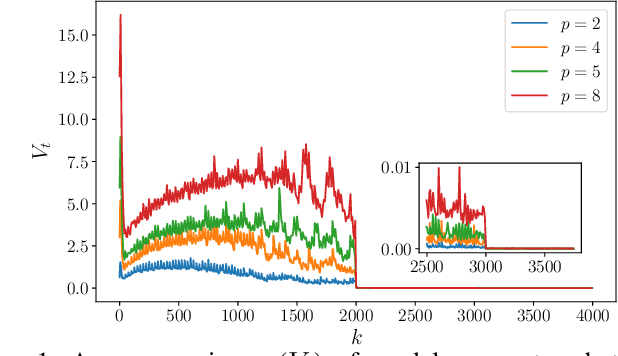
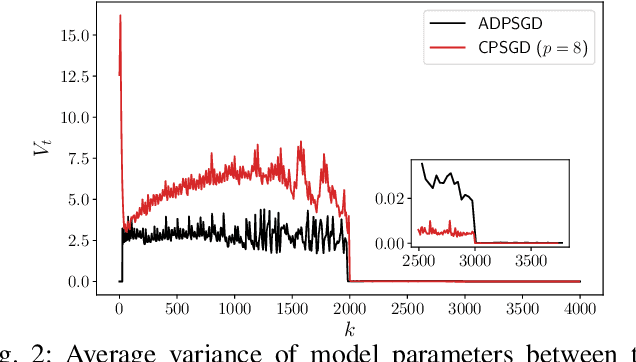
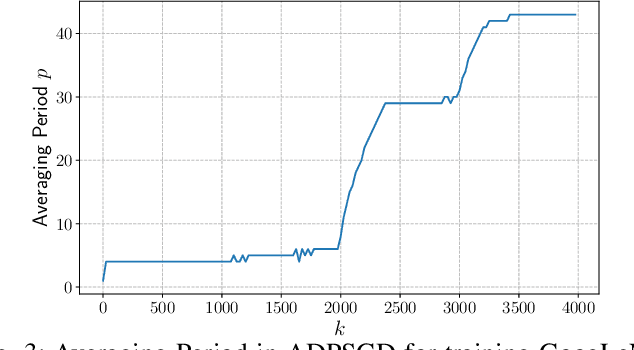
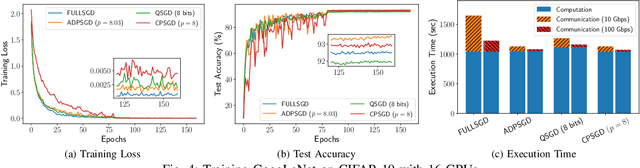
Stochastic Gradient Descent (SGD) is the key learning algorithm for many machine learning tasks. Because of its computational costs, there is a growing interest in accelerating SGD on HPC resources like GPU clusters. However, the performance of parallel SGD is still bottlenecked by the high communication costs even with a fast connection among the machines. A simple approach to alleviating this problem, used in many existing efforts, is to perform communication every few iterations, using a constant averaging period. In this paper, we show that the optimal averaging period in terms of convergence and communication cost is not a constant, but instead varies over the course of the execution. Specifically, we observe that reducing the variance of model parameters among the computing nodes is critical to the convergence of periodic parameter averaging SGD. Given a fixed communication budget, we show that it is more beneficial to synchronize more frequently in early iterations to reduce the initial large variance and synchronize less frequently in the later phase of the training process. We propose a practical algorithm, named ADaptive Periodic parameter averaging SGD (ADPSGD), to achieve a smaller overall variance of model parameters, and thus better convergence compared with the Constant Periodic parameter averaging SGD (CPSGD). We evaluate our method with several image classification benchmarks and show that our ADPSGD indeed achieves smaller training losses and higher test accuracies with smaller communication compared with CPSGD. Compared with gradient-quantization SGD, we show that our algorithm achieves faster convergence with only half of the communication. Compared with full-communication SGD, our ADPSGD achieves 1:14x to 1:27x speedups with a 100Gbps connection among computing nodes, and the speedups increase to 1:46x ~ 1:95x with a 10Gbps connection.
Double Transfer Learning for Breast Cancer Histopathologic Image Classification
Apr 16, 2019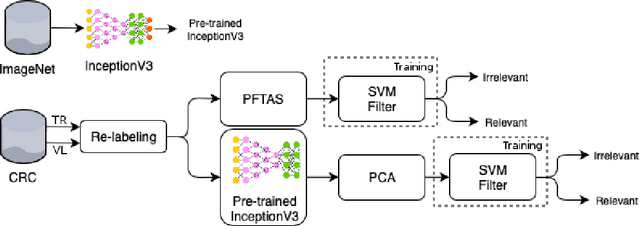
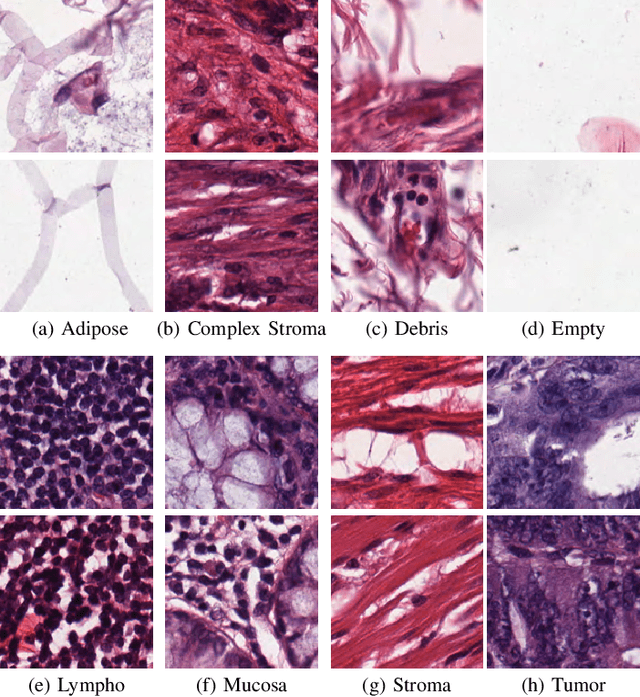
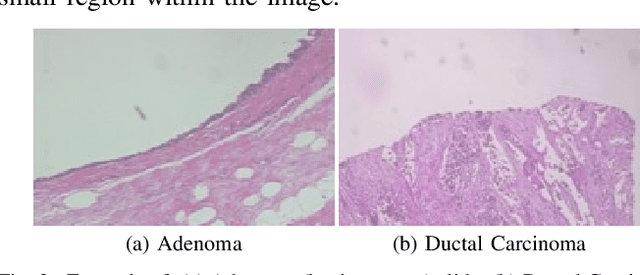
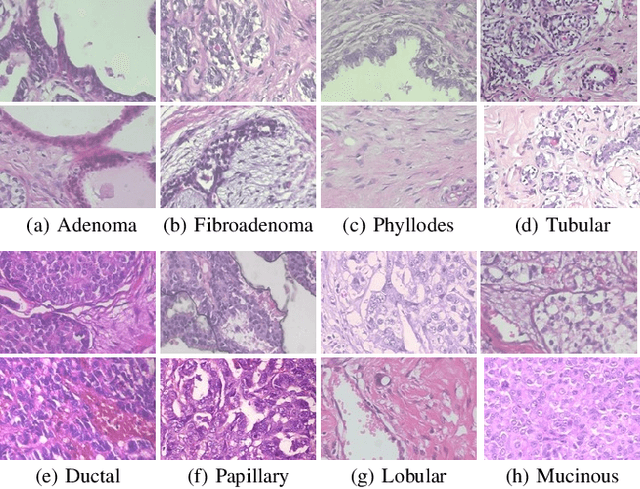
This work proposes a classification approach for breast cancer histopathologic images (HI) that uses transfer learning to extract features from HI using an Inception-v3 CNN pre-trained with ImageNet dataset. We also use transfer learning on training a support vector machine (SVM) classifier on a tissue labeled colorectal cancer dataset aiming to filter the patches from a breast cancer HI and remove the irrelevant ones. We show that removing irrelevant patches before training a second SVM classifier, improves the accuracy for classifying malign and benign tumors on breast cancer images. We are able to improve the classification accuracy in 3.7% using the feature extraction transfer learning and an additional 0.7% using the irrelevant patch elimination. The proposed approach outperforms the state-of-the-art in three out of the four magnification factors of the breast cancer dataset.
Blind Deconvolution Method using Omnidirectional Gabor Filter-based Edge Information
May 03, 2019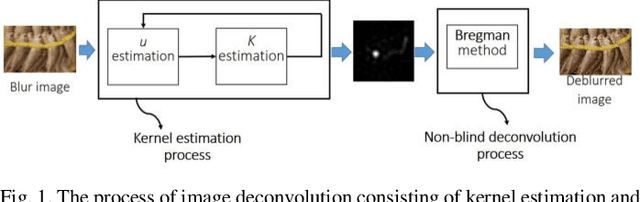



In the previous blind deconvolution methods, de-blurred images can be obtained by using the edge or pixel information. However, the existing edge-based methods did not take advantage of edge information in ommi-directions, but only used horizontal and vertical edges when recovering the de-blurred images. This limitation lowers the quality of the recovered images. This paper proposes a method which utilizes edges in different directions to recover the true sharp image. We also provide a statistical table score to show how many directions are enough to recover a high quality true sharp image. In order to grade the quality of the deblurring image, we introduce a measurement, namely Haar defocus score that takes advantage of the Haar-Wavelet transform. The experimental results prove that the proposed method obtains a high quality deblurred image with respect to both the Haar defocus score and the Peak Signal to Noise Ratio.
Functional Principal Component Analysis and Randomized Sparse Clustering Algorithm for Medical Image Analysis
Aug 01, 2014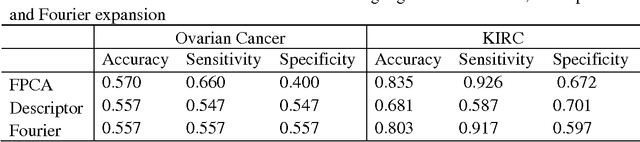

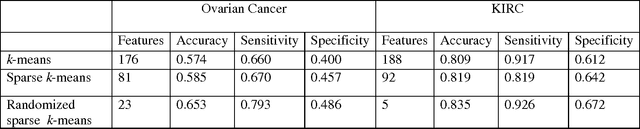

Due to advances in sensors, growing large and complex medical image data have the ability to visualize the pathological change in the cellular or even the molecular level or anatomical changes in tissues and organs. As a consequence, the medical images have the potential to enhance diagnosis of disease, prediction of clinical outcomes, characterization of disease progression, management of health care and development of treatments, but also pose great methodological and computational challenges for representation and selection of features in image cluster analysis. To address these challenges, we first extend one dimensional functional principal component analysis to the two dimensional functional principle component analyses (2DFPCA) to fully capture space variation of image signals. Image signals contain a large number of redundant and irrelevant features which provide no additional or no useful information for cluster analysis. Widely used methods for removing redundant and irrelevant features are sparse clustering algorithms using a lasso-type penalty to select the features. However, the accuracy of clustering using a lasso-type penalty depends on how to select penalty parameters and a threshold for selecting features. In practice, they are difficult to determine. Recently, randomized algorithms have received a great deal of attention in big data analysis. This paper presents a randomized algorithm for accurate feature selection in image cluster analysis. The proposed method is applied to ovarian and kidney cancer histology image data from the TCGA database. The results demonstrate that the randomized feature selection method coupled with functional principal component analysis substantially outperforms the current sparse clustering algorithms in image cluster analysis.
Color and Shape Content Based Image Classification using RBF Network and PSO Technique: A Survey
Nov 27, 2013The improvement of the accuracy of image query retrieval used image classification technique. Image classification is well known technique of supervised learning. The improved method of image classification increases the working efficiency of image query retrieval. For the improvements of classification technique we used RBF neural network function for better prediction of feature used in image retrieval.Colour content is represented by pixel values in image classification using radial base function(RBF) technique. This approach provides better result compare to SVM technique in image representation.Image is represented by matrix though RBF using pixel values of colour intensity of image. Firstly we using RGB colour model. In this colour model we use red, green and blue colour intensity values in matrix.SVM with partical swarm optimization for image classification is implemented in content of images which provide better Results based on the proposed approach are found encouraging in terms of color image classification accuracy.
Compute-Bound and Low-Bandwidth Distributed 3D Graph-SLAM
May 20, 2020
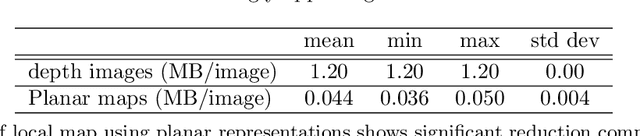

This article describes a new approach for distributed 3D SLAM map building. The key contribution of this article is the creation of a distributed graph-SLAM map-building architecture responsive to bandwidth and computational needs of the robotic platform. Responsiveness is afforded by the integration of a 3D point cloud to plane cloud compression algorithm that approximates dense 3D point cloud using local planar patches. Compute bound platforms may restrict the computational duration of the compression algorithm and low-bandwidth platforms can restrict the size of the compression result. The backbone of the approach is an ultra-fast adaptive 3D compression algorithm that transforms swaths of 3D planar surface data into planar patches attributed with image textures. Our approach uses DVO SLAM, a leading algorithm for 3D mapping, and extends it by computationally isolating map integration tasks from local Guidance, Navigation, and Control tasks and includes an addition of a network protocol to share the compressed plane clouds. The joint effect of these contributions allows agents with 3D sensing capabilities to calculate and communicate compressed map information commensurate with their onboard computational resources and communication channel capacities. This opens SLAM mapping to new categories of robotic platforms that may have computational and memory limits that prohibit other SLAM solutions.