 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Inertial Measurements for Motion Compensation in Weight-bearing Cone-beam CT of the Knee
Jul 09, 2020
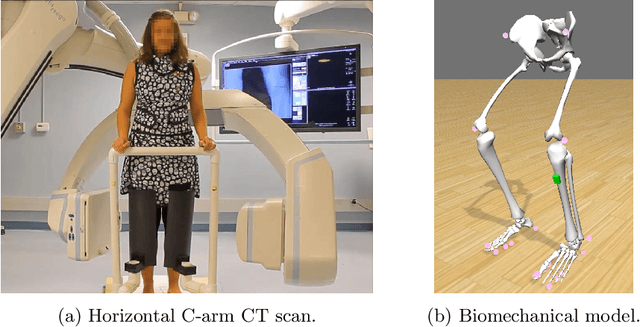
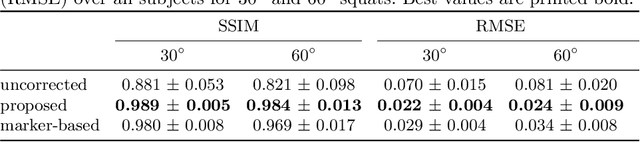
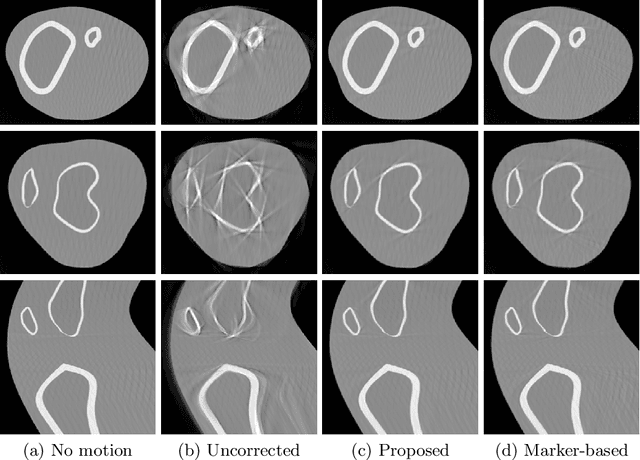

Involuntary motion during weight-bearing cone-beam computed tomography (CT) scans of the knee causes artifacts in the reconstructed volumes making them unusable for clinical diagnosis. Currently, image-based or marker-based methods are applied to correct for this motion, but often require long execution or preparation times. We propose to attach an inertial measurement unit (IMU) containing an accelerometer and a gyroscope to the leg of the subject in order to measure the motion during the scan and correct for it. To validate this approach, we present a simulation study using real motion measured with an optical 3D tracking system. With this motion, an XCAT numerical knee phantom is non-rigidly deformed during a simulated CT scan creating motion corrupted projections. A biomechanical model is animated with the same tracked motion in order to generate measurements of an IMU placed below the knee. In our proposed multi-stage algorithm, these signals are transformed to the global coordinate system of the CT scan and applied for motion compensation during reconstruction. Our proposed approach can effectively reduce motion artifacts in the reconstructed volumes. Compared to the motion corrupted case, the average structural similarity index and root mean squared error with respect to the no-motion case improved by 13-21% and 68-70%, respectively. These results are qualitatively and quantitatively on par with a state-of-the-art marker-based method we compared our approach to. The presented study shows the feasibility of this novel approach, and yields promising results towards a purely IMU-based motion compensation in C-arm CT.
Mixup Regularization for Region Proposal based Object Detectors
Mar 04, 2020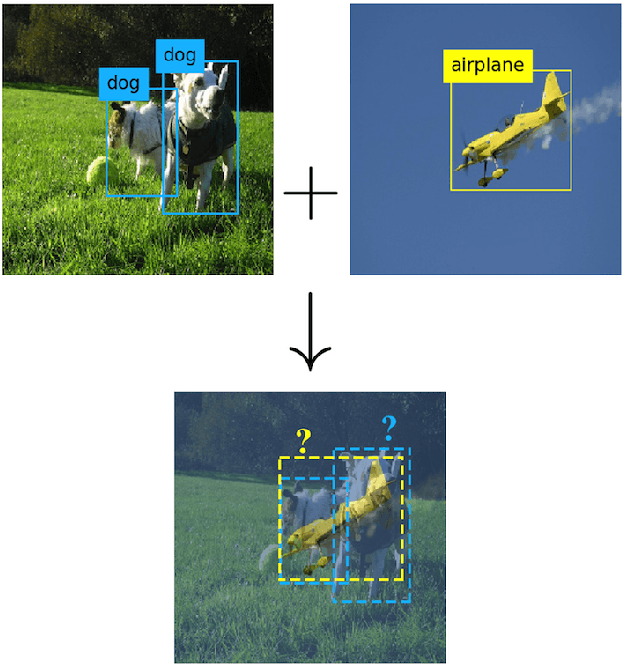
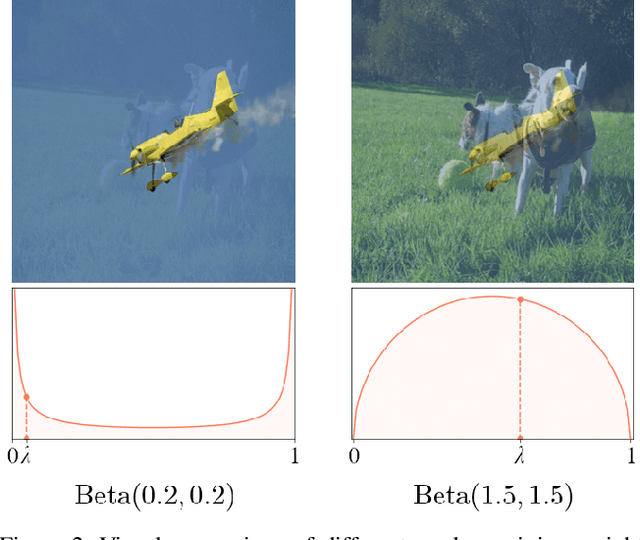

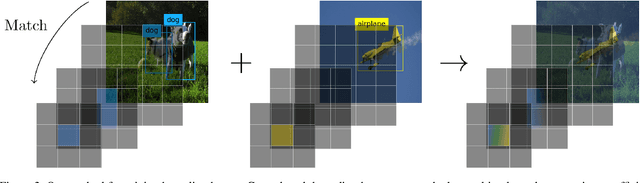
Mixup - a neural network regularization technique based on linear interpolation of labeled sample pairs - has stood out by its capacity to improve model's robustness and generalizability through a surprisingly simple formalism. However, its extension to the field of object detection remains unclear as the interpolation of bounding boxes cannot be naively defined. In this paper, we propose to leverage the inherent region mapping structure of anchors to introduce a mixup-driven training regularization for region proposal based object detectors. The proposed method is benchmarked on standard datasets with challenging detection settings. Our experiments show an enhanced robustness to image alterations along with an ability to decontextualize detections, resulting in an improved generalization power.
Biogeography based Satellite Image Classification
Dec 05, 2009

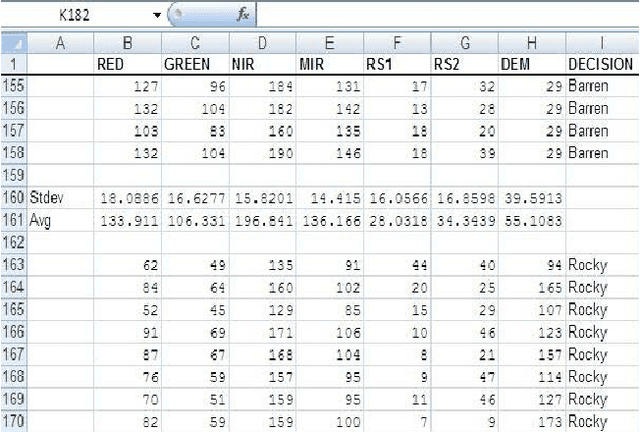

Biogeography is the study of the geographical distribution of biological organisms. The mindset of the engineer is that we can learn from nature. Biogeography Based Optimization is a burgeoning nature inspired technique to find the optimal solution of the problem. Satellite image classification is an important task because it is the only way we can know about the land cover map of inaccessible areas. Though satellite images have been classified in past by using various techniques, the researchers are always finding alternative strategies for satellite image classification so that they may be prepared to select the most appropriate technique for the feature extraction task in hand. This paper is focused on classification of the satellite image of a particular land cover using the theory of Biogeography based Optimization. The original BBO algorithm does not have the inbuilt property of clustering which is required during image classification. Hence modifications have been proposed to the original algorithm and the modified algorithm is used to classify the satellite image of a given region. The results indicate that highly accurate land cover features can be extracted effectively when the proposed algorithm is used.
* 6 pages IEEE format, International Journal of Computer Science and Information Security, IJCSIS November 2009, ISSN 1947 5500, http://sites.google.com/site/ijcsis/
Deep Parametric Indoor Lighting Estimation
Oct 19, 2019

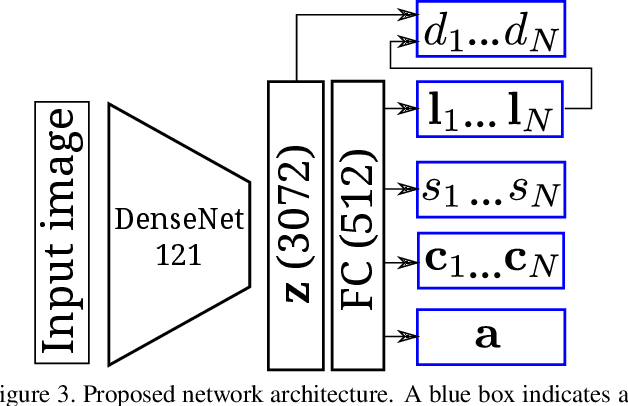

We present a method to estimate lighting from a single image of an indoor scene. Previous work has used an environment map representation that does not account for the localized nature of indoor lighting. Instead, we represent lighting as a set of discrete 3D lights with geometric and photometric parameters. We train a deep neural network to regress these parameters from a single image, on a dataset of environment maps annotated with depth. We propose a differentiable layer to convert these parameters to an environment map to compute our loss; this bypasses the challenge of establishing correspondences between estimated and ground truth lights. We demonstrate, via quantitative and qualitative evaluations, that our representation and training scheme lead to more accurate results compared to previous work, while allowing for more realistic 3D object compositing with spatially-varying lighting.
The iWildCam 2020 Competition Dataset
Apr 21, 2020

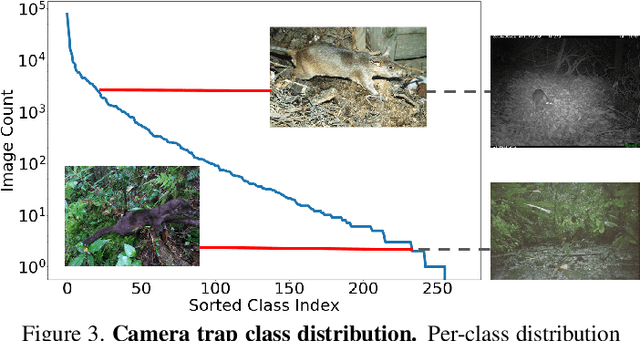

Camera traps enable the automatic collection of large quantities of image data. Biologists all over the world use camera traps to monitor animal populations. We have recently been making strides towards automatic species classification in camera trap images. However, as we try to expand the geographic scope of these models we are faced with an interesting question: how do we train models that perform well on new (unseen during training) camera trap locations? Can we leverage data from other modalities, such as citizen science data and remote sensing data? In order to tackle this problem, we have prepared a challenge where the training data and test data are from different cameras spread across the globe. For each camera, we provide a series of remote sensing imagery that is tied to the location of the camera. We also provide citizen science imagery from the set of species seen in our data. The challenge is to correctly classify species in the test camera traps.
Extracting 2D weak labels from volume labels using multiple instance learning in CT hemorrhage detection
Nov 13, 2019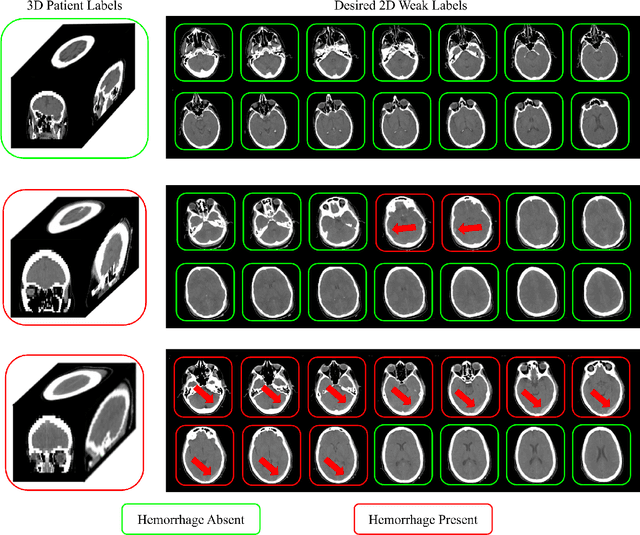

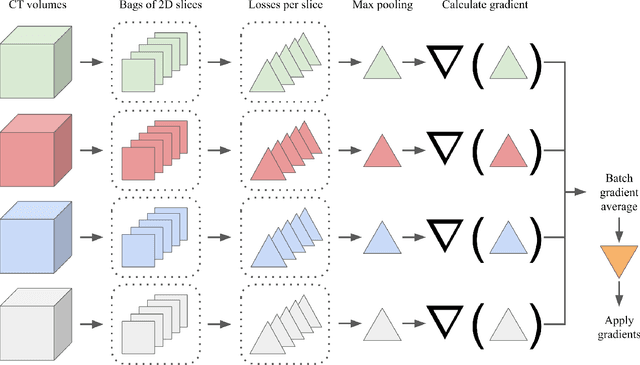
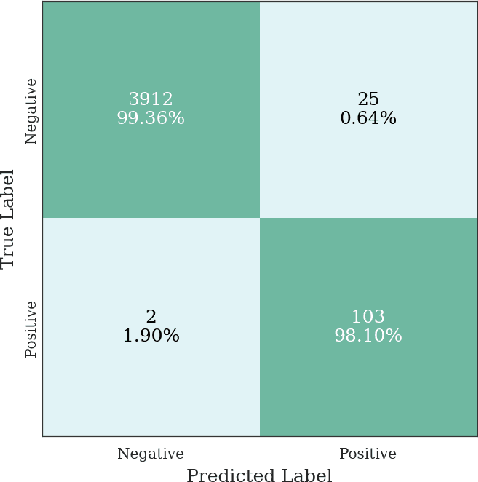
Multiple instance learning (MIL) is a supervised learning methodology that aims to allow models to learn instance class labels from bag class labels, where a bag is defined to contain multiple instances. MIL is gaining traction for learning from weak labels but has not been widely applied to 3D medical imaging. MIL is well-suited to clinical CT acquisitions since (1) the highly anisotropic voxels hinder application of traditional 3D networks and (2) patch-based networks have limited ability to learn whole volume labels. In this work, we apply MIL with a deep convolutional neural network to identify whether clinical CT head image volumes possess one or more large hemorrhages (> 20cm$^3$), resulting in a learned 2D model without the need for 2D slice annotations. Individual image volumes are considered separate bags, and the slices in each volume are instances. Such a framework sets the stage for incorporating information obtained in clinical reports to help train a 2D segmentation approach. Within this context, we evaluate the data requirements to enable generalization of MIL by varying the amount of training data. Our results show that a training size of at least 400 patient image volumes was needed to achieve accurate per-slice hemorrhage detection. Over a five-fold cross-validation, the leading model, which made use of the maximum number of training volumes, had an average true positive rate of 98.10%, an average true negative rate of 99.36%, and an average precision of 0.9698. The models have been made available along with source code to enabled continued exploration and adaption of MIL in CT neuroimaging.
SLAM-based Integrity Monitoring Using GPS and Fish-eye Camera
Oct 04, 2019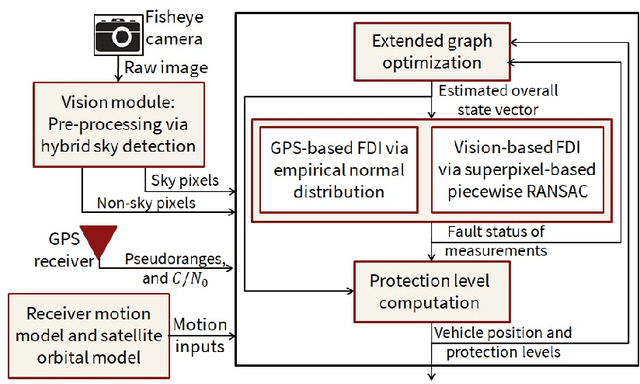
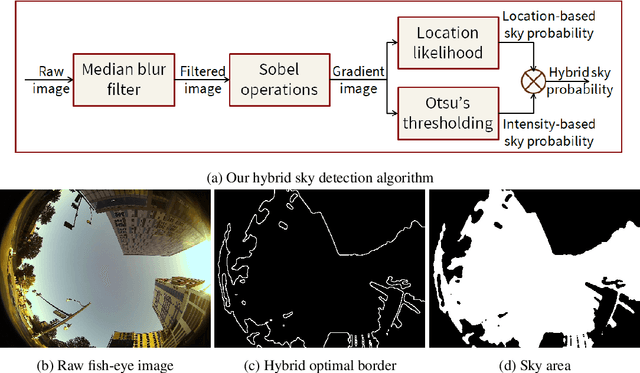
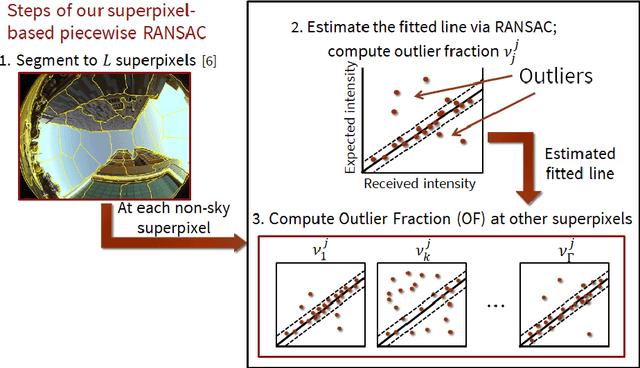
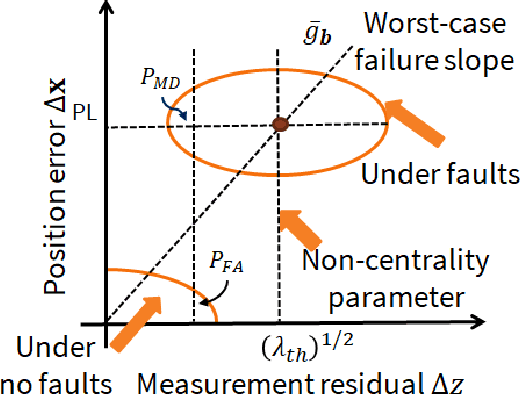
Urban navigation using GPS and fish-eye camera suffers from multipath effects in GPS measurements and data association errors in pixel intensities across image frames. We propose a Simultaneous Localization and Mapping (SLAM)-based Integrity Monitoring (IM) algorithm to compute the position protection levels while accounting for multiple faults in both GPS and vision. We perform graph optimization using the sequential data of GPS pseudoranges, pixel intensities, vehicle dynamics, and satellite ephemeris to simultaneously localize the vehicle as well as the landmarks, namely GPS satellites and key image pixels in the world frame. We estimate the fault mode vector by analyzing the temporal correlation across the GPS measurement residuals and spatial correlation across the vision intensity residuals. In particular, to detect and isolate the vision faults, we developed a superpixel-based piecewise Random Sample Consensus (RANSAC) technique to perform spatial voting across image pixels. For an estimated fault mode, we compute the protection levels by applying worst-case failure slope analysis to the linearized Graph-SLAM framework. We perform ground vehicle experiments in the semi-urban area of Champaign, IL and have demonstrated the successful detection and isolation of multiple faults. We also validate tighter protection levels and lower localization errors achieved via the proposed algorithm as compared to SLAM-based IM that utilizes only GPS measurements.
Y-Net for Chest X-Ray Preprocessing: Simultaneous Classification of Geometry and Segmentation of Annotations
May 08, 2020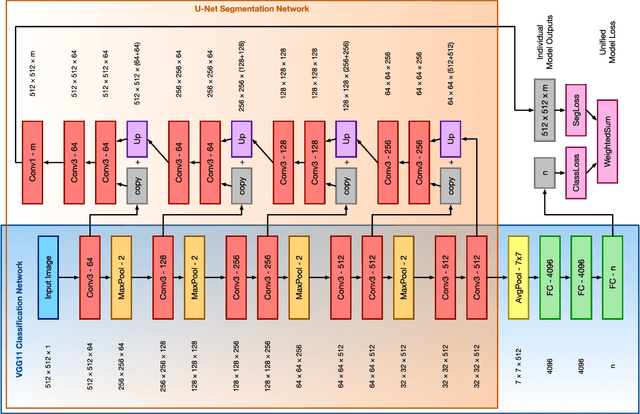
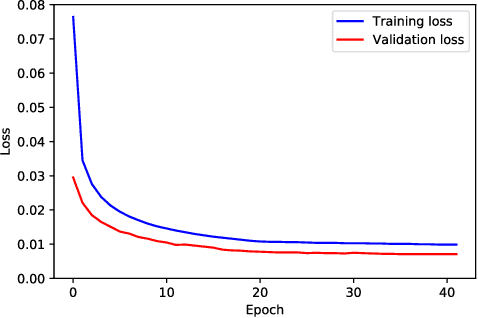
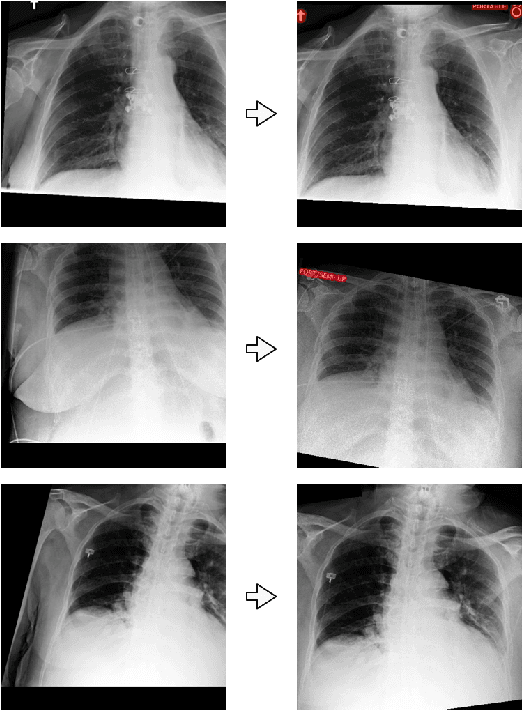
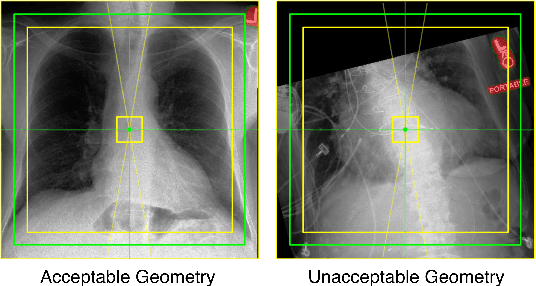
Over the last decade, convolutional neural networks (CNNs) have emerged as the leading algorithms in image classification and segmentation. Recent publication of large medical imaging databases have accelerated their use in the biomedical arena. While training data for photograph classification benefits from aggressive geometric augmentation, medical diagnosis -- especially in chest radiographs -- depends more strongly on feature location. Diagnosis classification results may be artificially enhanced by reliance on radiographic annotations. This work introduces a general pre-processing step for chest x-ray input into machine learning algorithms. A modified Y-Net architecture based on the VGG11 encoder is used to simultaneously learn geometric orientation (similarity transform parameters) of the chest and segmentation of radiographic annotations. Chest x-rays were obtained from published databases. The algorithm was trained with 1000 manually labeled images with augmentation. Results were evaluated by expert clinicians, with acceptable geometry in 95.8% and annotation mask in 96.2% (n=500), compared to 27.0% and 34.9% respectively in control images (n=241). We hypothesize that this pre-processing step will improve robustness in future diagnostic algorithms.
Unsupervised Domain Adaptation in the Dissimilarity Space for Person Re-identification
Jul 27, 2020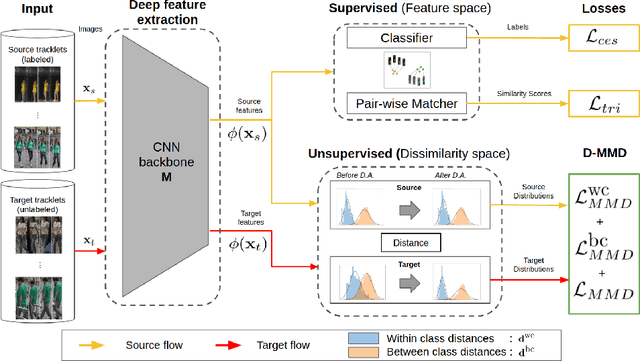
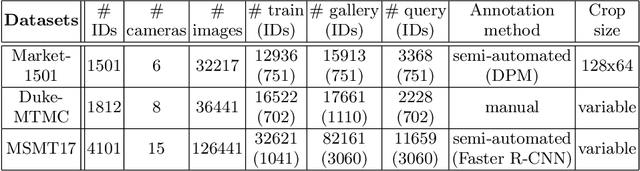
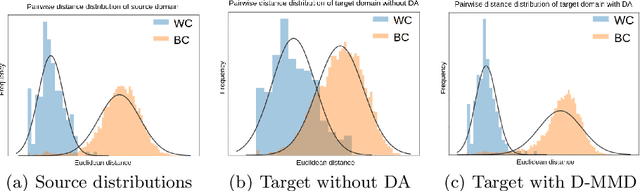
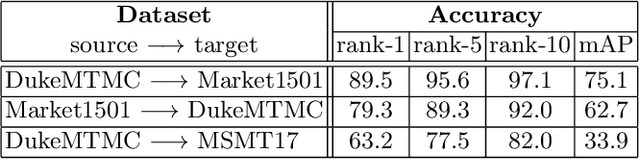
Person re-identification (ReID) remains a challenging task in many real-word video analytics and surveillance applications, even though state-of-the-art accuracy has improved considerably with the advent of deep learning (DL) models trained on large image datasets. Given the shift in distributions that typically occurs between video data captured from the source and target domains, and absence of labeled data from the target domain, it is difficult to adapt a DL model for accurate recognition of target data. We argue that for pair-wise matchers that rely on metric learning, e.g., Siamese networks for person ReID, the unsupervised domain adaptation (UDA) objective should consist in aligning pair-wise dissimilarity between domains, rather than aligning feature representations. Moreover, dissimilarity representations are more suitable for designing open-set ReID systems, where identities differ in the source and target domains. In this paper, we propose a novel Dissimilarity-based Maximum Mean Discrepancy (D-MMD) loss for aligning pair-wise distances that can be optimized via gradient descent. From a person ReID perspective, the evaluation of D-MMD loss is straightforward since the tracklet information allows to label a distance vector as being either within-class or between-class. This allows approximating the underlying distribution of target pair-wise distances for D-MMD loss optimization, and accordingly align source and target distance distributions. Empirical results with three challenging benchmark datasets show that the proposed D-MMD loss decreases as source and domain distributions become more similar. Extensive experimental evaluation also indicates that UDA methods that rely on the D-MMD loss can significantly outperform baseline and state-of-the-art UDA methods for person ReID without the common requirement for data augmentation and/or complex networks.
Risk of Training Diagnostic Algorithms on Data with Demographic Bias
Jun 17, 2020
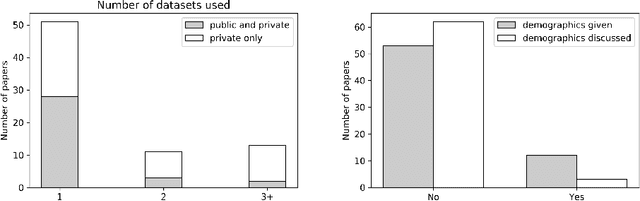
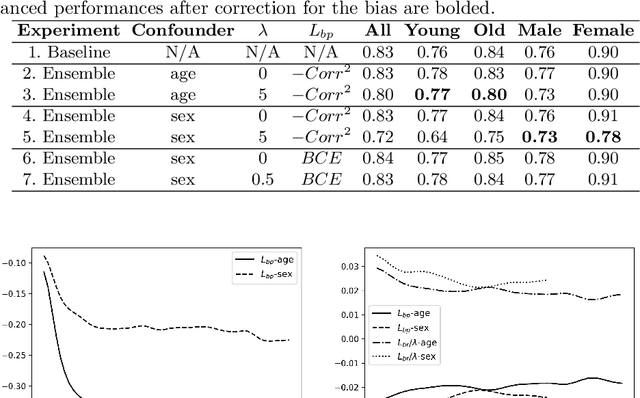
One of the critical challenges in machine learning applications is to have fair predictions. There are numerous recent examples in various domains that convincingly show that algorithms trained with biased datasets can easily lead to erroneous or discriminatory conclusions. This is even more crucial in clinical applications where the predictive algorithms are designed mainly based on a limited or given set of medical images and demographic variables such as age, sex and race are not taken into account. In this work, we conduct a survey of the MICCAI 2018 proceedings to investigate the common practice in medical image analysis applications. Surprisingly, we found that papers focusing on diagnosis rarely describe the demographics of the datasets used, and the diagnosis is purely based on images. In order to highlight the importance of considering the demographics in diagnosis tasks, we used a publicly available dataset of skin lesions. We then demonstrate that a classifier with an overall area under the curve (AUC) of 0.83 has variable performance between 0.76 and 0.91 on subgroups based on age and sex, even though the training set was relatively balanced. Moreover, we show that it is possible to learn unbiased features by explicitly using demographic variables in an adversarial training setup, which leads to balanced scores per subgroups. Finally, we discuss the implications of these results and provide recommendations for further research.