 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Semi-parametric Object Synthesis
Jul 24, 2019


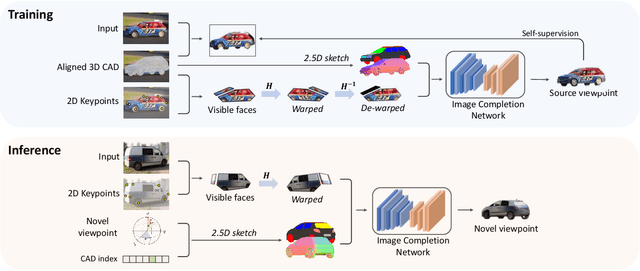
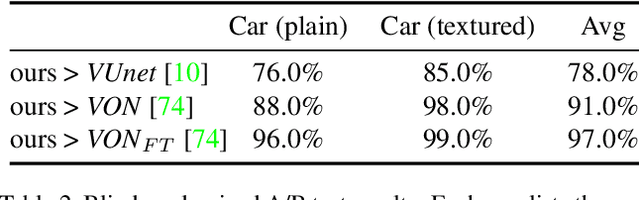
We present a new semi-parametric approach to synthesize novel views of an object from a single monocular image. First, we exploit man-made object symmetry and piece-wise planarity to integrate rich a-priori visual information into the novel viewpoint synthesis process. An Image Completion Network (ICN) then leverages 2.5D sketches rendered from a 3D CAD as guidance to generate a realistic image. In contrast to concurrent works, we do not rely solely on synthetic data but leverage instead existing datasets for 3D object detection to operate in a real-world scenario. Differently from competitors, our semi-parametric framework allows the handling of a wide range of 3D transformations. Thorough experimental analysis against state-of-the-art baselines shows the efficacy of our method both from a quantitative and a perceptive point of view. Code and supplementary material are available at: https://github.com/ndrplz/semiparametric
Stochastic gradient descent with random learning rate
Mar 15, 2020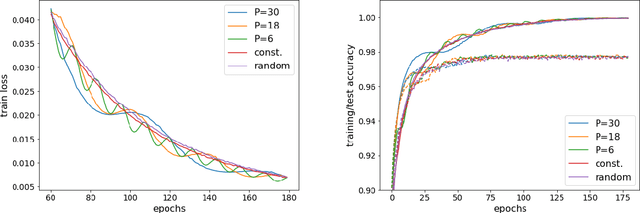
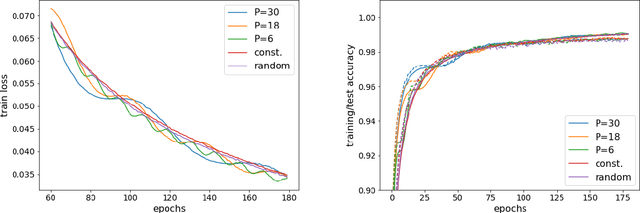
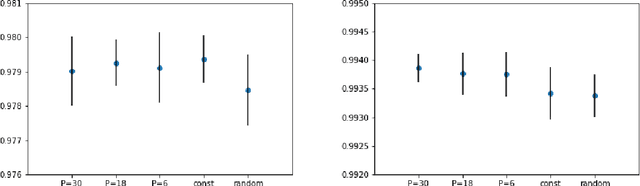
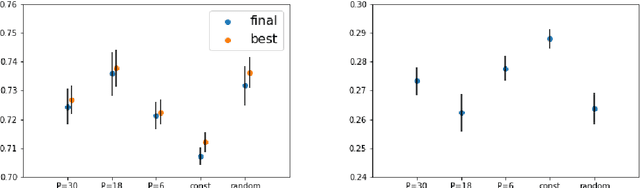
We propose to optimize neural networks with a uniformly-distributed random learning rate. The associated stochastic gradient descent algorithm can be approximated by continuous stochastic equations and analyzed with the Fokker-Planck formalism. In the small learning rate approximation, the training process is characterized by an effective temperature which depends on the average learning rate, the mini-batch size and the momentum of the optimization algorithm. By comparing the random learning rate protocol with cyclic and constant protocols, we suggest that the random choice is generically the best strategy in the small learning rate regime, yielding better regularization without extra computational cost. We provide supporting evidence through experiments on both shallow, fully-connected and deep, convolutional neural networks for image classification on the MNIST and CIFAR10 datasets.
Purifying Naturalistic Images through a Real-time Style Transfer Semantics Network
Mar 14, 2019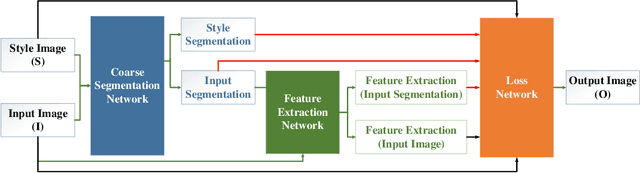

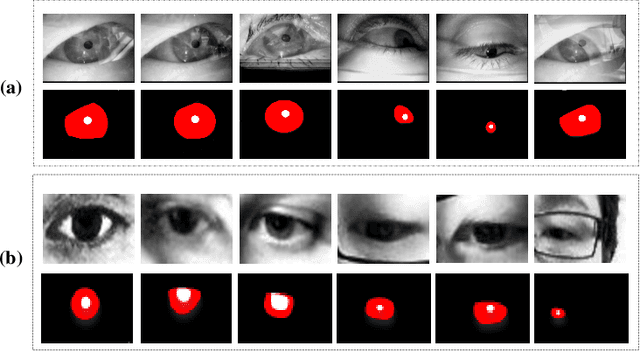
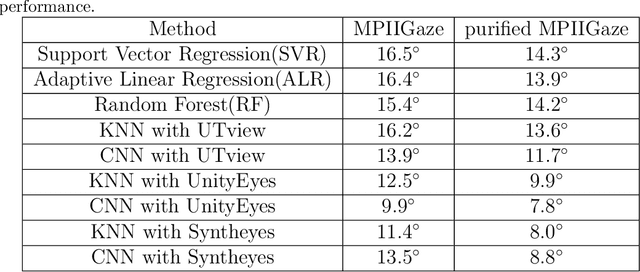
Recently, the progress of learning-by-synthesis has proposed a training model for synthetic images, which can effectively reduce the cost of human and material resources. However, due to the different distribution of synthetic images compared to real images, the desired performance cannot still be achieved. Real images consist of multiple forms of light orientation, while synthetic images consist of a uniform light orientation. These features are considered to be characteristic of outdoor and indoor scenes, respectively. To solve this problem, the previous method learned a model to improve the realism of the synthetic image. Different from the previous methods, this paper takes the first step to purify real images. Through the style transfer task, the distribution of outdoor real images is converted into indoor synthetic images, thereby reducing the influence of light. Therefore, this paper proposes a real-time style transfer network that preserves image content information (eg, gaze direction, pupil center position) of an input image (real image) while inferring style information (eg, image color structure, semantic features) of style image (synthetic image). In addition, the network accelerates the convergence speed of the model and adapts to multi-scale images. Experiments were performed using mixed studies (qualitative and quantitative) methods to demonstrate the possibility of purifying real images in complex directions. Qualitatively, it compares the proposed method with the available methods in a series of indoor and outdoor scenarios of the LPW dataset. In quantitative terms, it evaluates the purified image by training a gaze estimation model on the cross data set. The results show a significant improvement over the baseline method compared to the raw real image.
Real-time Simultaneous 3D Head Modeling and Facial Motion Capture with an RGB-D camera
Apr 22, 2020
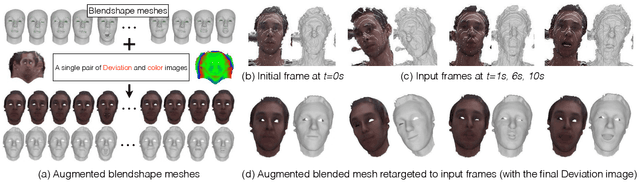

We propose a method to build in real-time animated 3D head models using a consumer-grade RGB-D camera. Our proposed method is the first one to provide simultaneously comprehensive facial motion tracking and a detailed 3D model of the user's head. Anyone's head can be instantly reconstructed and his facial motion captured without requiring any training or pre-scanning. The user starts facing the camera with a neutral expression in the first frame, but is free to move, talk and change his face expression as he wills otherwise. The facial motion is captured using a blendshape animation model while geometric details are captured using a Deviation image mapped over the template mesh. We contribute with an efficient algorithm to grow and refine the deforming 3D model of the head on-the-fly and in real-time. We demonstrate robust and high-fidelity simultaneous facial motion capture and 3D head modeling results on a wide range of subjects with various head poses and facial expressions.
Towards Fairness in Visual Recognition: Effective Strategies for Bias Mitigation
Nov 26, 2019
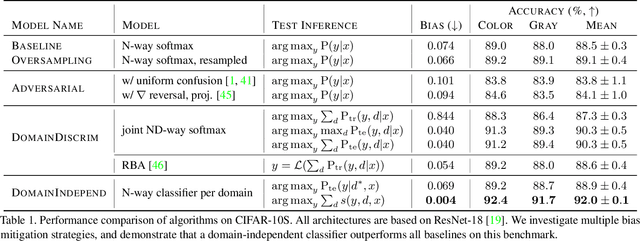

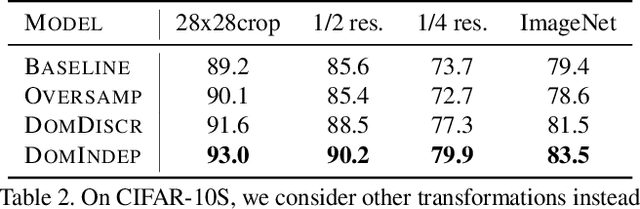
Computer vision models learn to perform a task by capturing relevant statistics from training data. It has been shown that models learn spurious age, gender, and race correlations when trained for seemingly unrelated tasks like activity recognition or image captioning. Various mitigation techniques have been presented to prevent models from utilizing or learning such biases. However, there has been little systematic comparison between these techniques. We design a simple but surprisingly effective visual recognition benchmark for studying bias mitigation. Using this benchmark, we provide a thorough analysis of a wide range of techniques. We highlight the shortcomings of popular adversarial training approaches for bias mitigation, propose a simple but similarly effective alternative to the inference-time Reducing Bias Amplification method of Zhao et al., and design a domain-independent training technique that outperforms all other methods. Finally, we validate our findings on the attribute classification task in the CelebA dataset, where attribute presence is known to be correlated with the gender of people in the image, and demonstrate that the proposed technique is effective at mitigating real-world gender bias.
Correlation Maximized Structural Similarity Loss for Semantic Segmentation
Oct 19, 2019

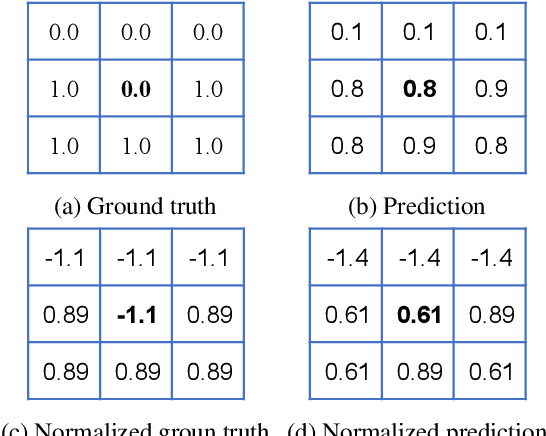
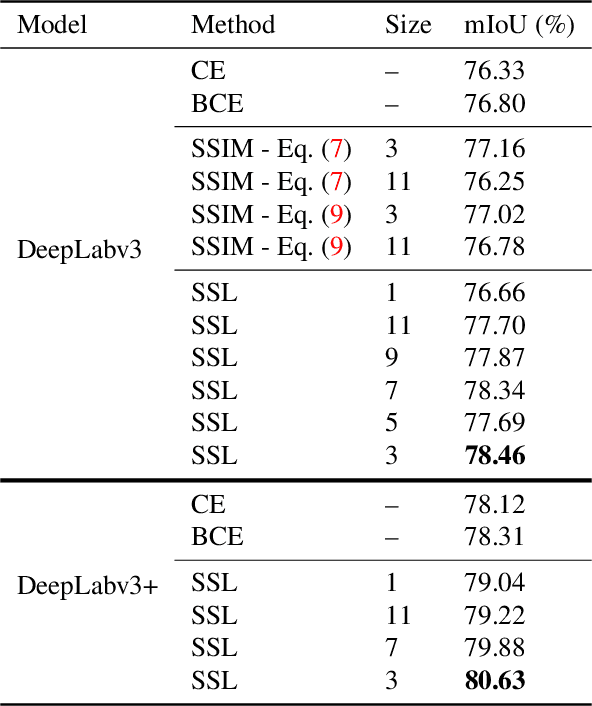
Most semantic segmentation models treat semantic segmentation as a pixel-wise classification task and use a pixel-wise classification error as their optimization criterions. However, the pixel-wise error ignores the strong dependencies among the pixels in an image, which limits the performance of the model. Several ways to incorporate the structure information of the objects have been investigated, \eg, conditional random fields (CRF), image structure priors based methods, and generative adversarial network (GAN). Nevertheless, these methods usually require extra model branches or additional memories, and some of them show limited improvements. In contrast, we propose a simple yet effective structural similarity loss (SSL) to encode the structure information of the objects, which only requires a few additional computational resources in the training phase. Inspired by the widely-used structural similarity (SSIM) index in image quality assessment, we use the linear correlation between two images to quantify their structural similarity. And the goal of the proposed SSL is to pay more attention to the positions, whose associated predictions lead to a low degree of linear correlation between two corresponding regions in the ground truth map and the predicted map. Thus the model can achieve a strong structural similarity between the two maps through minimizing the SSL over the whole map. The experimental results demonstrate that our method can achieve substantial and consistent improvements in performance on the PASCAL VOC 2012 and Cityscapes datasets. The code will be released soon.
Biogeography based Satellite Image Classification
Dec 05, 2009

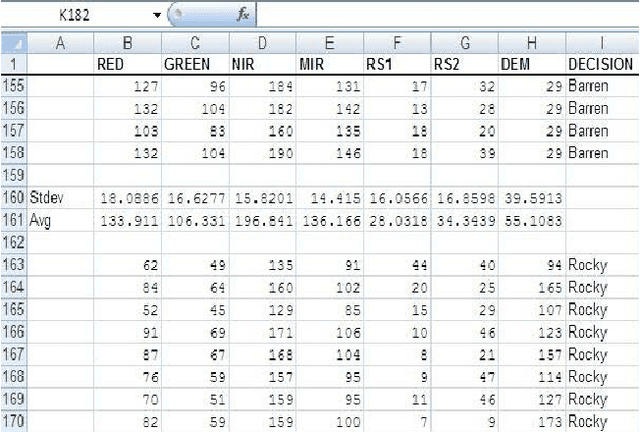

Biogeography is the study of the geographical distribution of biological organisms. The mindset of the engineer is that we can learn from nature. Biogeography Based Optimization is a burgeoning nature inspired technique to find the optimal solution of the problem. Satellite image classification is an important task because it is the only way we can know about the land cover map of inaccessible areas. Though satellite images have been classified in past by using various techniques, the researchers are always finding alternative strategies for satellite image classification so that they may be prepared to select the most appropriate technique for the feature extraction task in hand. This paper is focused on classification of the satellite image of a particular land cover using the theory of Biogeography based Optimization. The original BBO algorithm does not have the inbuilt property of clustering which is required during image classification. Hence modifications have been proposed to the original algorithm and the modified algorithm is used to classify the satellite image of a given region. The results indicate that highly accurate land cover features can be extracted effectively when the proposed algorithm is used.
* 6 pages IEEE format, International Journal of Computer Science and Information Security, IJCSIS November 2009, ISSN 1947 5500, http://sites.google.com/site/ijcsis/
Poly-GAN: Multi-Conditioned GAN for Fashion Synthesis
Sep 05, 2019
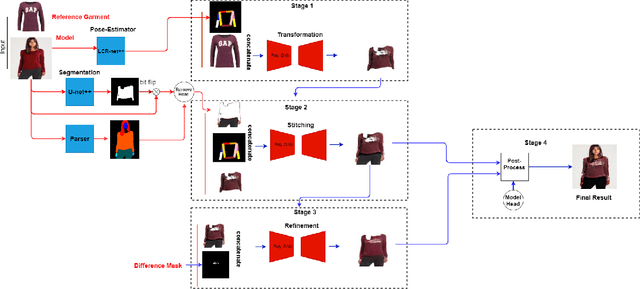
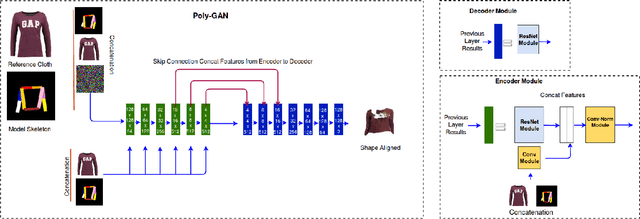

We present Poly-GAN, a novel conditional GAN architecture that is motivated by Fashion Synthesis, an application where garments are automatically placed on images of human models at an arbitrary pose. Poly-GAN allows conditioning on multiple inputs and is suitable for many tasks, including image alignment, image stitching, and inpainting. Existing methods have a similar pipeline where three different networks are used to first align garments with the human pose, then perform stitching of the aligned garment and finally refine the results. Poly-GAN is the first instance where a common architecture is used to perform all three tasks. Our novel architecture enforces the conditions at all layers of the encoder and utilizes skip connections from the coarse layers of the encoder to the respective layers of the decoder. Poly-GAN is able to perform a spatial transformation of the garment based on the RGB skeleton of the model at an arbitrary pose. Additionally, Poly-GAN can perform image stitching, regardless of the garment orientation, and inpainting on the garment mask when it contains irregular holes. Our system achieves state-of-the-art quantitative results on Structural Similarity Index metric and Inception Score metric using the DeepFashion dataset.
Structure preserving deep learning
Jun 05, 2020
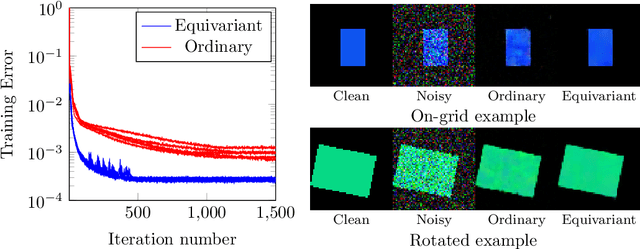
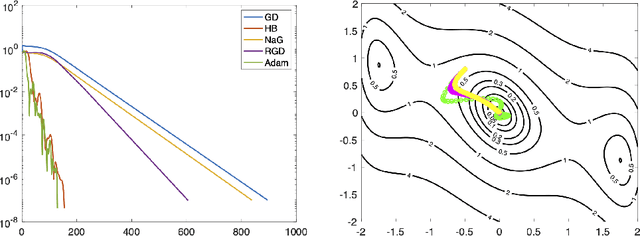
Over the past few years, deep learning has risen to the foreground as a topic of massive interest, mainly as a result of successes obtained in solving large-scale image processing tasks. There are multiple challenging mathematical problems involved in applying deep learning: most deep learning methods require the solution of hard optimisation problems, and a good understanding of the tradeoff between computational effort, amount of data and model complexity is required to successfully design a deep learning approach for a given problem. A large amount of progress made in deep learning has been based on heuristic explorations, but there is a growing effort to mathematically understand the structure in existing deep learning methods and to systematically design new deep learning methods to preserve certain types of structure in deep learning. In this article, we review a number of these directions: some deep neural networks can be understood as discretisations of dynamical systems, neural networks can be designed to have desirable properties such as invertibility or group equivariance, and new algorithmic frameworks based on conformal Hamiltonian systems and Riemannian manifolds to solve the optimisation problems have been proposed. We conclude our review of each of these topics by discussing some open problems that we consider to be interesting directions for future research.
Explaining Autonomous Driving by Learning End-to-End Visual Attention
Jun 05, 2020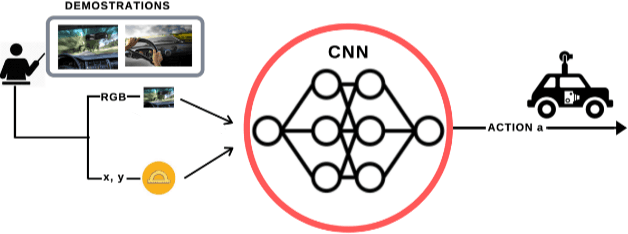
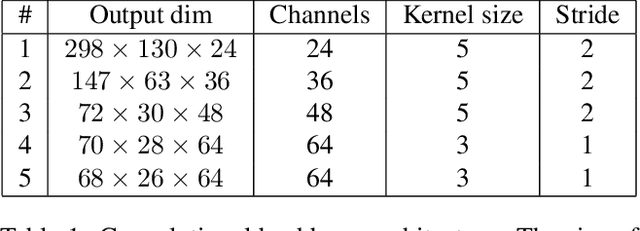
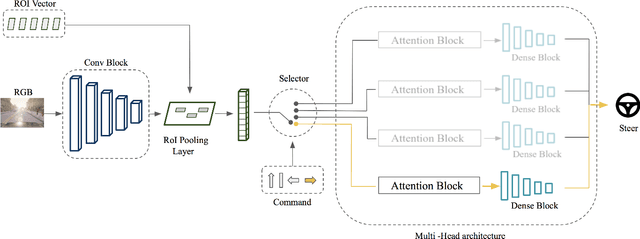

Current deep learning based autonomous driving approaches yield impressive results also leading to in-production deployment in certain controlled scenarios. One of the most popular and fascinating approaches relies on learning vehicle controls directly from data perceived by sensors. This end-to-end learning paradigm can be applied both in classical supervised settings and using reinforcement learning. Nonetheless the main drawback of this approach as also in other learning problems is the lack of explainability. Indeed, a deep network will act as a black-box outputting predictions depending on previously seen driving patterns without giving any feedback on why such decisions were taken. While to obtain optimal performance it is not critical to obtain explainable outputs from a learned agent, especially in such a safety critical field, it is of paramount importance to understand how the network behaves. This is particularly relevant to interpret failures of such systems. In this work we propose to train an imitation learning based agent equipped with an attention model. The attention model allows us to understand what part of the image has been deemed most important. Interestingly, the use of attention also leads to superior performance in a standard benchmark using the CARLA driving simulator.