 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Convolutional neural net face recognition works in non-human-like ways
Apr 08, 2020

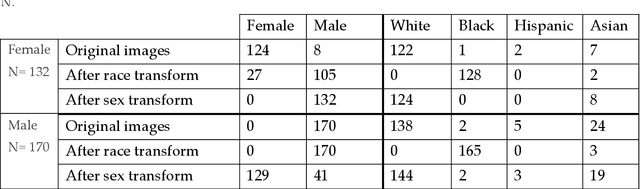

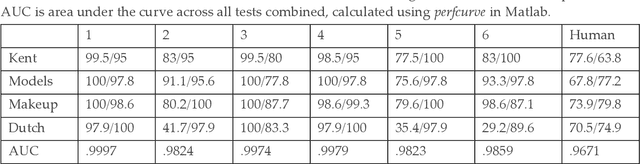
Convolutional neural networks (CNNs) give state of the art performance in many pattern recognition problems but can be fooled by carefully crafted patterns of noise. We report that CNN face recognition systems also make surprising "errors". We tested six commercial face recognition CNNs and found that they outperform typical human participants on standard face matching tasks. However, they also declare matches that humans would not, where one image from the pair has been transformed to look a different sex or race. This is not due to poor performance; the best CNNs perform almost perfectly on the human face matching tasks, but also declare the most matches for faces of a different apparent race or sex. Although differing on the salience of sex and race, humans and computer systems are not working in completely different ways. They tend to find the same pairs of images difficult, suggesting some agreement about the underlying similarity space.
Skin Segmentation from NIR Images using Unsupervised Domain Adaptation through Generative Latent Search
Jun 15, 2020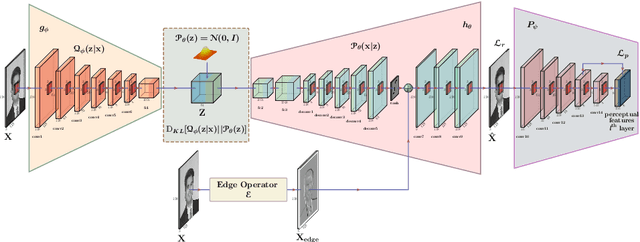
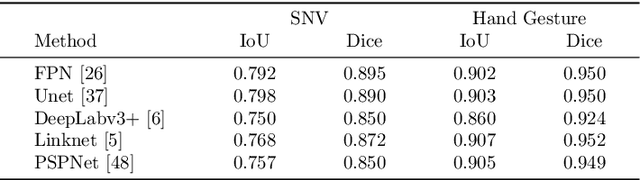

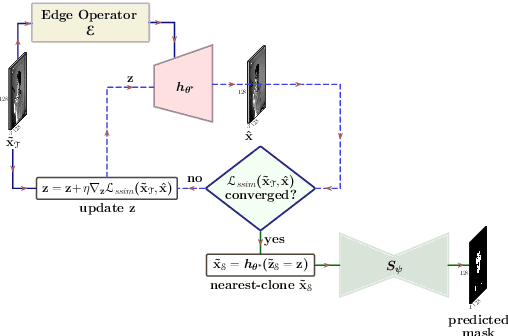
Segmentation of the pixels corresponding to human skin is an essential first step in multiple applications ranging from surveillance to heart-rate estimation from remote-photoplethysmography. However, the existing literature considers the problem only in the visible-range of the EM-spectrum which limits their utility in low or no light settings where the criticality of the application is higher. To alleviate this problem, we consider the problem of skin segmentation from the Near-infrared images. However, Deep learning based state-of-the-art segmentation techniques demands large amounts of labelled data that is unavailable for the current problem. Therefore we cast the skin segmentation problem as that of target-independent unsupervised domain adaptation (UDA) where we use the data from the Red-channel of the visible-range to develop skin segmentation algorithm on NIR images. We propose a method for target-independent segmentation where the 'nearest-clone' of a target image in the source domain is searched and used as a proxy in the segmentation network trained only on the source domain. We prove the existence of 'nearest-clone' and propose a method to find it through an optimization algorithm over the latent space of a Deep generative model based on variational inference. We demonstrate the efficacy of the proposed method for NIR skin segmentation over the state-of-the-art UDA segmenation methods on the two newly created skin segmentation datasets in NIR domain despite not having access to the target NIR data.
Bridging the gap between AI and Healthcare sides: towards developing clinically relevant AI-powered diagnosis systems
Jan 12, 2020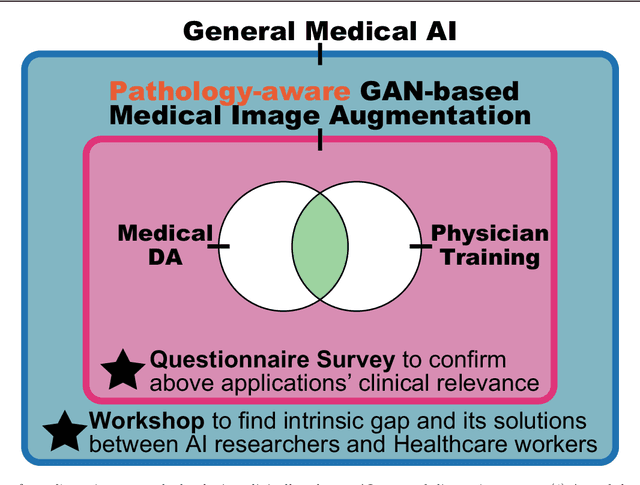

This work aims to identify/bridge the gap between Artificial Intelligence (AI) and Healthcare sides in Japan towards developing medical AI fitting into a clinical environment in five years. Moreover, we attempt to confirm the clinical relevance for diagnosis of our research-proven pathology-aware Generative Adversarial Network (GAN)-based medical image augmentation: a data wrangling and information conversion technique to address data paucity. We hold a clinically valuable AI-envisioning workshop among 2 Medical Imaging experts, 2 physicians, and 3 Healthcare/Informatics generalists. A qualitative/quantitative questionnaire survey for 3 project-related physicians and 6 project non-related radiologists evaluates the GAN projects in terms of Data Augmentation (DA) and physician training. The workshop reveals the intrinsic gap between AI/Healthcare sides and its preliminary solutions on Why (i.e., clinical significance/interpretation) and How (i.e., data acquisition, commercial deployment, and safety/feeling safe). The survey confirms our pathology-aware GANs' clinical relevance as a clinical decision support system and non-expert physician training tool. Radiologists generally have high expectations for AI-based diagnosis as a reliable second opinion and abnormal candidate detection, instead of replacing them. Our findings would play a key role in connecting inter-disciplinary research and clinical applications, not limited to the Japanese medical context and pathology-aware GANs. We find that better DA and expert physician training would require atypical image generation via further GAN-based extrapolation.
The iMaterialist Fashion Attribute Dataset
Jun 14, 2019
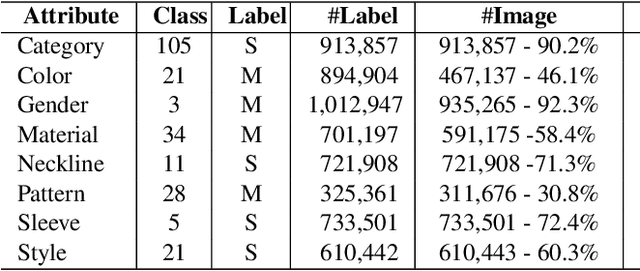
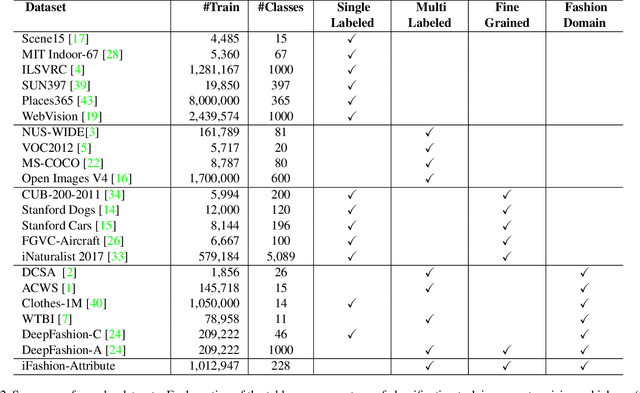
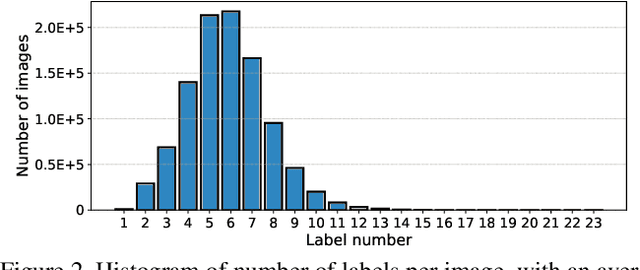
Large-scale image databases such as ImageNet have significantly advanced image classification and other visual recognition tasks. However much of these datasets are constructed only for single-label and coarse object-level classification. For real-world applications, multiple labels and fine-grained categories are often needed, yet very few such datasets exist publicly, especially those of large-scale and high quality. In this work, we contribute to the community a new dataset called iMaterialist Fashion Attribute (iFashion-Attribute) to address this problem in the fashion domain. The dataset is constructed from over one million fashion images with a label space that includes 8 groups of 228 fine-grained attributes in total. Each image is annotated by experts with multiple, high-quality fashion attributes. The result is the first known million-scale multi-label and fine-grained image dataset. We conduct extensive experiments and provide baseline results with modern deep Convolutional Neural Networks (CNNs). Additionally, we demonstrate models pre-trained on iFashion-Attribute achieve superior transfer learning performance on fashion related tasks compared with pre-training from ImageNet or other fashion datasets. Data is available at: https://github.com/visipedia/imat_fashion_comp
Semantic Hierarchy Emerges in Deep Generative Representations for Scene Synthesis
Nov 29, 2019

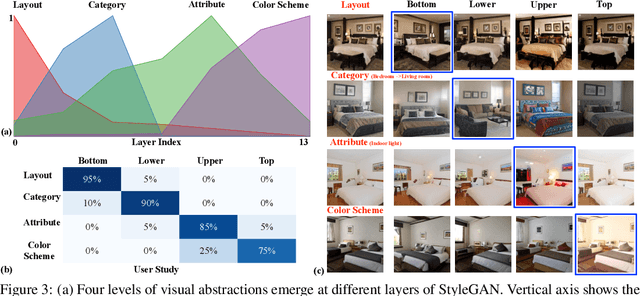
Despite the success of Generative Adversarial Networks (GANs) in image synthesis, there lacks enough understanding on what networks have learned inside the deep generative representations and how photo-realistic images are able to be composed of random noises. In this work, we show that highly-structured semantic hierarchy emerges as variation factors for synthesizing scenes from the generative representations in state-of-the-art GAN models, like StyleGAN and BigGAN. By probing the layer-wise representations with a broad set of semantics at different abstraction levels, we are able to quantify the causality between the activations and semantics occurring in the output image. Such a quantification identifies the human-understandable variation factors learned by GANs to compose scenes. The qualitative and quantitative results suggest that the generative representations learned by the GANs with layer-wise latent codes are specialized to synthesize different hierarchical semantics: the early layers tend to determine the spatial layout and configuration, the middle layers control the objects, and the later layers finally render the scene attributes as well as color scheme. Identifying such a set of manipulatable latent variation factors facilitates semantic scene manipulation.
SpotTheFake: An Initial Report on a New CNN-Enhanced Platform for Counterfeit Goods Detection
Feb 19, 2020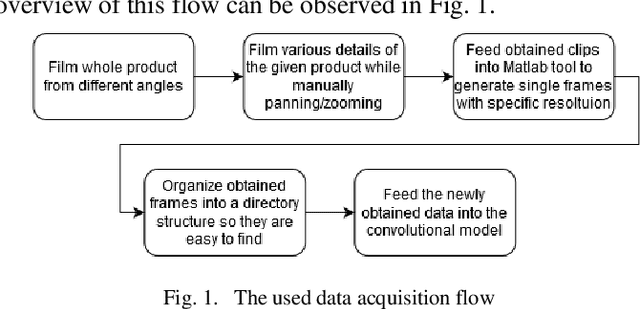


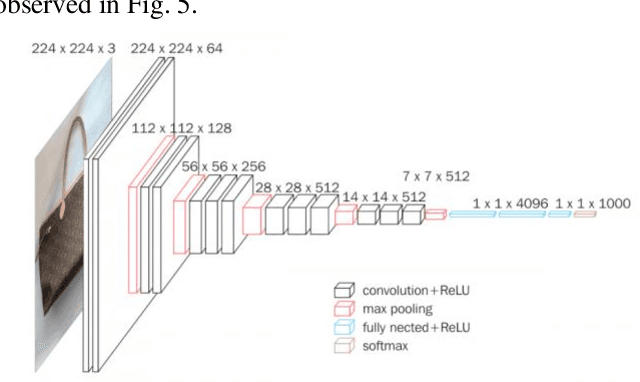
The counterfeit goods trade represents nowadays more than 3.3% of the whole world trade and thus it's a problem that needs now more than ever a lot of attention and a reliable solution that would reduce the negative impact it has over the modern society. This paper presents the design and early stage development of a novel counterfeit goods detection platform that makes use of the outstsanding learning capabilities of the classical VGG16 convolutional model trained through the process of "transfer learning" and a multi-stage fake detection procedure that proved to be not only reliable but also very robust in the experiments we have conducted so far using an image dataset of various goods which we gathered ourselves.
A Novel Technique of Noninvasive Hemoglobin Level Measurement Using HSV Value of Fingertip Image
Oct 07, 2019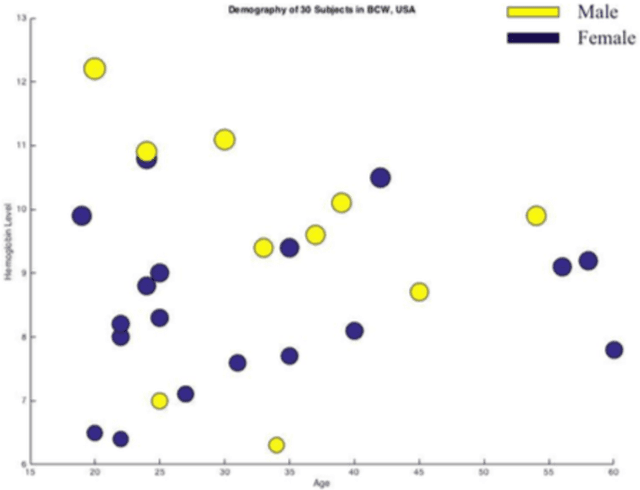
Over the last decade, smartphones have changed radically to support us with mHealth technology, cloud computing, and machine learning algorithm. Having its multifaceted facilities, we present a novel smartphone-based noninvasive hemoglobin (Hb) level prediction model by analyzing hue, saturation and value (HSV) of a fingertip video. Here, we collect 60 videos of 60 subjects from two different locations: Blood Center of Wisconsin, USA and AmaderGram, Bangladesh. We extract red, green, and blue (RGB) pixel intensities of selected images of those videos captured by the smartphone camera with flash on. Then we convert RGB values of selected video frames of a fingertip video into HSV color space and we generate histogram values of these HSV pixel intensities. We average these histogram values of a fingertip video and consider as an observation against the gold standard Hb concentration. We generate two input feature matrices based on observation of two different data sets. Partial Least Squares (PLS) algorithm is applied on the input feature matrix. We observe R2=0.95 in both data sets through our research. We analyze our data using Python OpenCV, Matlab, and R statistics tool.
An Approach for Reducing Outliers of Non Local Means Image Denoising Filter
Dec 09, 2014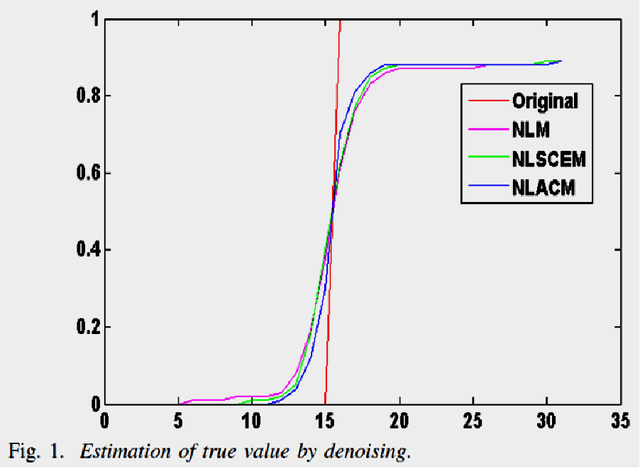
We propose an adaptive approach for non local means (NLM) image filtering termed as non local adaptive clipped means (NLACM), which reduces the effect of outliers and improves the denoising quality as compared to traditional NLM. Common method to neglect outliers from a data population is computation of mean in a range defined by mean and standard deviation. In NLACM we perform the median within the defined range based on statistical estimation of the neighbourhood region of a pixel to be denoised. As parameters of the range are independent of any additional input and is based on local intensity values, hence the approach is adaptive. Experimental results for NLACM show better estimation of true intensity from noisy neighbourhood observation as compared to NLM at high noise levels. We have verified the technique for speckle noise reduction and we have tested it on ultrasound (US) image of lumbar spine. These ultrasound images act as guidance for injection therapy for treatment of lumbar radiculopathy. We believe that the proposed approach for image denoising is first of its kind and its efficiency can be well justified as it shows better performance in image restoration.
Sketch-based Image Retrieval from Millions of Images under Rotation, Translation and Scale Variations
Oct 31, 2015
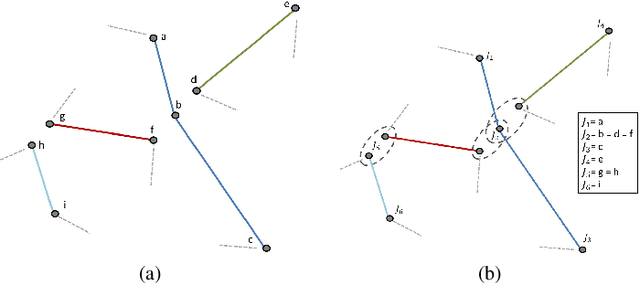
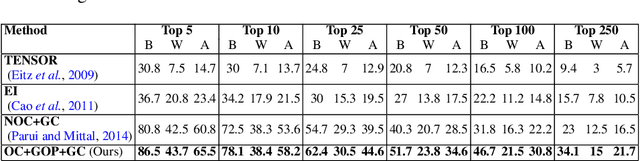
Proliferation of touch-based devices has made sketch-based image retrieval practical. While many methods exist for sketch-based object detection/image retrieval on small datasets, relatively less work has been done on large (web)-scale image retrieval. In this paper, we present an efficient approach for image retrieval from millions of images based on user-drawn sketches. Unlike existing methods for this problem which are sensitive to even translation or scale variations, our method handles rotation, translation, scale (i.e. a similarity transformation) and small deformations. The object boundaries are represented as chains of connected segments and the database images are pre-processed to obtain such chains that have a high chance of containing the object. This is accomplished using two approaches in this work: a) extracting long chains in contour segment networks and b) extracting boundaries of segmented object proposals. These chains are then represented by similarity-invariant variable length descriptors. Descriptor similarities are computed by a fast Dynamic Programming-based partial matching algorithm. This matching mechanism is used to generate a hierarchical k-medoids based indexing structure for the extracted chains of all database images in an offline process which is used to efficiently retrieve a small set of possible matched images for query chains. Finally, a geometric verification step is employed to test geometric consistency of multiple chain matches to improve results. Qualitative and quantitative results clearly demonstrate superiority of the approach over existing methods.
Patch Reordering: a Novel Way to Achieve Rotation and Translation Invariance in Convolutional Neural Networks
Nov 28, 2019
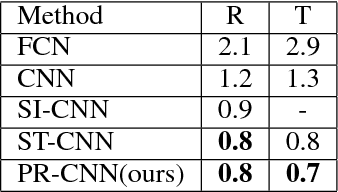
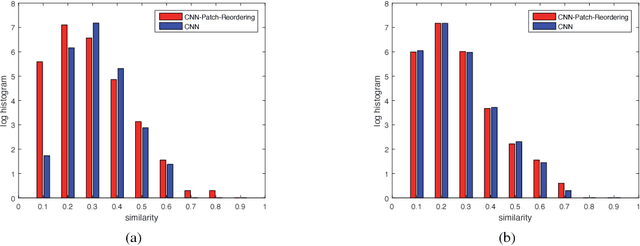
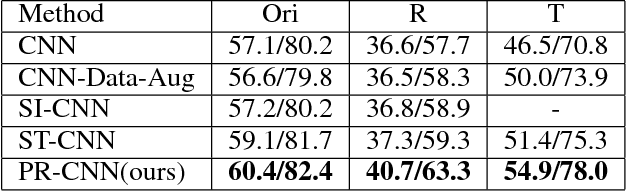
Convolutional Neural Networks (CNNs) have demonstrated state-of-the-art performance on many visual recognition tasks. However, the combination of convolution and pooling operations only shows invariance to small local location changes in meaningful objects in input. Sometimes, such networks are trained using data augmentation to encode this invariance into the parameters, which restricts the capacity of the model to learn the content of these objects. A more efficient use of the parameter budget is to encode rotation or translation invariance into the model architecture, which relieves the model from the need to learn them. To enable the model to focus on learning the content of objects other than their locations, we propose to conduct patch ranking of the feature maps before feeding them into the next layer. When patch ranking is combined with convolution and pooling operations, we obtain consistent representations despite the location of meaningful objects in input. We show that the patch ranking module improves the performance of the CNN on many benchmark tasks, including MNIST digit recognition, large-scale image recognition, and image retrieval. The code is available at https://github.com//jasonustc/caffe-multigpu/tree/TICNN .