 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Weakly-Supervised 3D Pose Estimation from a Single Image using Multi-View Consistency
Sep 13, 2019
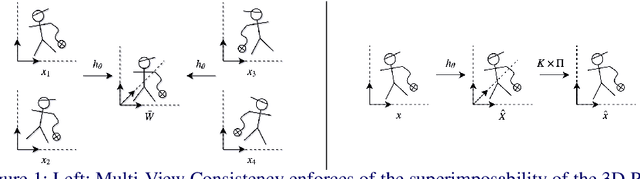
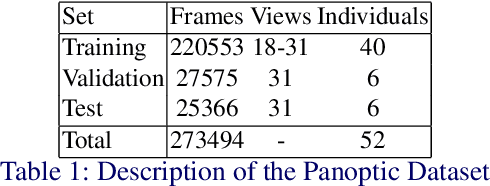


We present a novel data-driven regularizer for weakly-supervised learning of 3D human pose estimation that eliminates the drift problem that affects existing approaches. We do this by moving the stereo reconstruction problem into the loss of the network itself. This avoids the need to reconstruct 3D data prior to training and unlike previous semi-supervised approaches, avoids the need for a warm-up period of supervised training. The conceptual and implementational simplicity of our approach is fundamental to its appeal. Not only is it straightforward to augment many weakly-supervised approaches with our additional re-projection based loss, but it is obvious how it shapes reconstructions and prevents drift. As such we believe it will be a valuable tool for any researcher working in weakly-supervised 3D reconstruction. Evaluating on Panoptic, the largest multi-camera and markerless dataset available, we obtain an accuracy that is essentially indistinguishable from a strongly-supervised approach making full use of 3D groundtruth in training.
Hybridization of Otsu Method and Median Filter for Color Image Segmentation
May 05, 2013

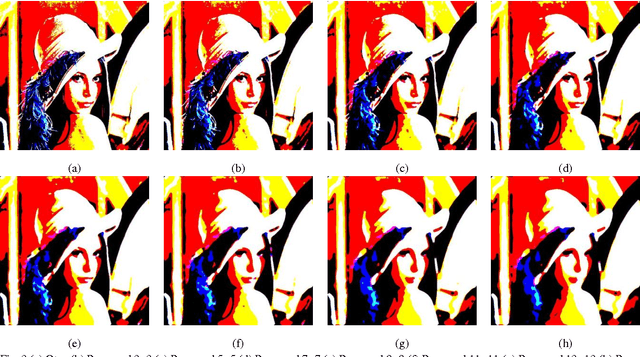

In this article a novel algorithm for color image segmentation has been developed. The proposed algorithm based on combining two existing methods in such a novel way to obtain a significant method to partition the color image into significant regions. On the first phase, the traditional Otsu method for gray channel image segmentation were applied for each of the R,G, and B channels separately to determine the suitable automatic threshold for each channel. After that, the new modified channels are integrated again to formulate a new color image. The resulted image suffers from some kind of distortion. To get rid of this distortion, the second phase is arise which is the median filter to smooth the image and increase the segmented regions. This process looks very significant by the ocular eye. Experimental results were presented on a variety of test images to support the proposed algorithm.
* 6 pages, 7 figures
Real-time 3D Nanoscale Coherent Imaging via Physics-aware Deep Learning
Jun 16, 2020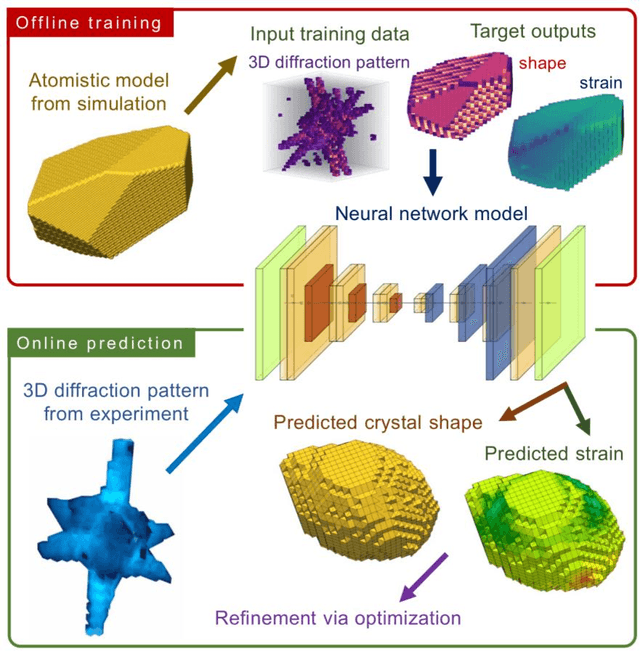
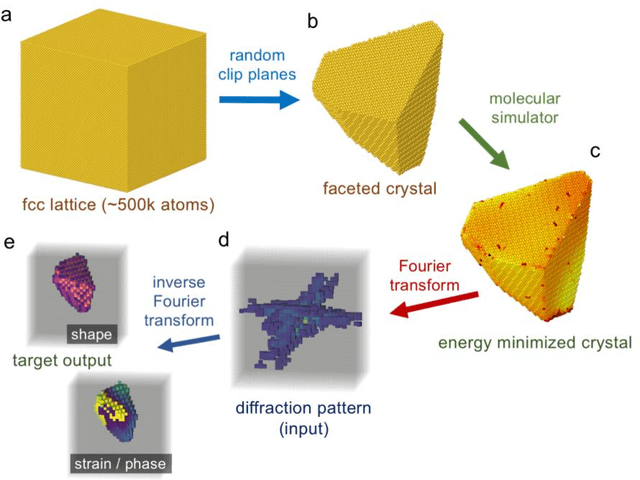
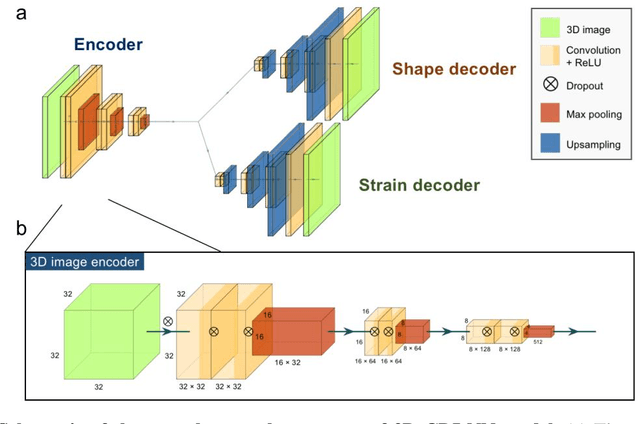
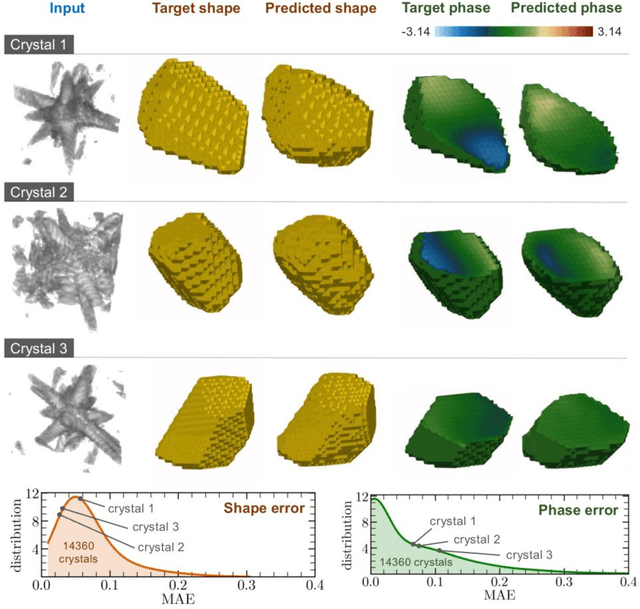
Phase retrieval, the problem of recovering lost phase information from measured intensity alone, is an inverse problem that is widely faced in various imaging modalities ranging from astronomy to nanoscale imaging. The current process of phase recovery is iterative in nature. As a result, the image formation is time-consuming and computationally expensive, precluding real-time imaging. Here, we use 3D nanoscale X-ray imaging as a representative example to develop a deep learning model to address this phase retrieval problem. We introduce 3D-CDI-NN, a deep convolutional neural network and differential programming framework trained to predict 3D structure and strain solely from input 3D X-ray coherent scattering data. Our networks are designed to be "physics-aware" in multiple aspects; in that the physics of x-ray scattering process is explicitly enforced in the training of the network, and the training data are drawn from atomistic simulations that are representative of the physics of the material. We further refine the neural network prediction through a physics-based optimization procedure to enable maximum accuracy at lowest computational cost. 3D-CDI-NN can invert a 3D coherent diffraction pattern to real-space structure and strain hundreds of times faster than traditional iterative phase retrieval methods, with negligible loss in accuracy. Our integrated machine learning and differential programming solution to the phase retrieval problem is broadly applicable across inverse problems in other application areas.
Information Condensing Active Learning
Feb 20, 2020
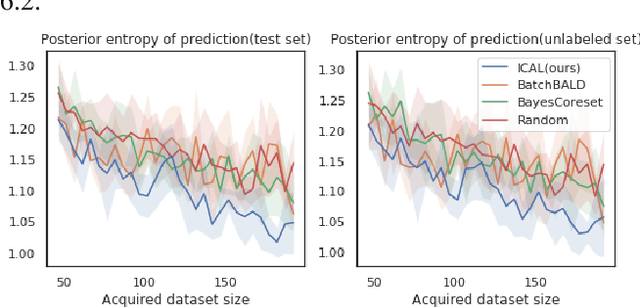
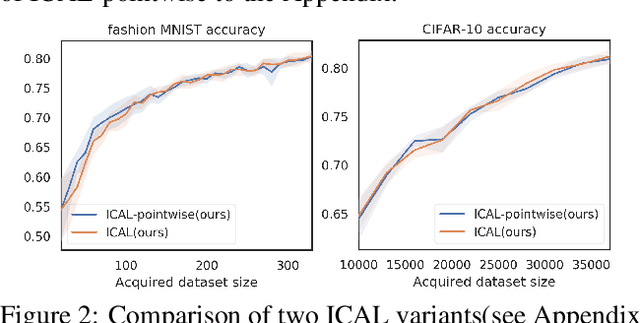
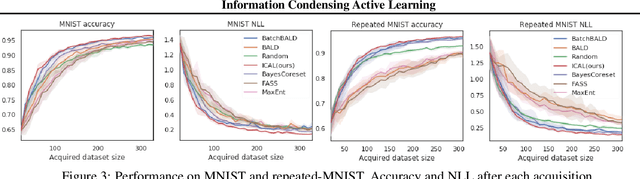
We introduce Information Condensing Active Learning (ICAL), a batch mode model agnostic Active Learning (AL) method targeted at Deep Bayesian Active Learning that focuses on acquiring labels for points which have as much information as possible about the still unacquired points. ICAL uses the Hilbert Schmidt Independence Criterion (HSIC) to measure the strength of the dependency between a candidate batch of points and the unlabeled set. We develop key optimizations that allow us to scale our method to large unlabeled sets. We show significant improvements in terms of model accuracy and negative log likelihood (NLL) on several image datasets compared to state of the art batch mode AL methods for deep learning.
Learning to Scale Multilingual Representations for Vision-Language Tasks
Apr 09, 2020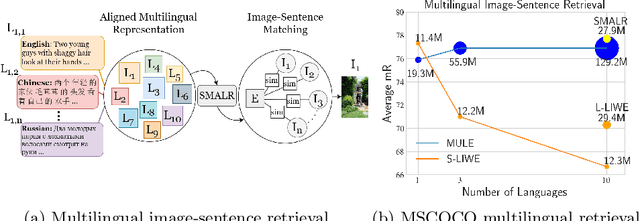
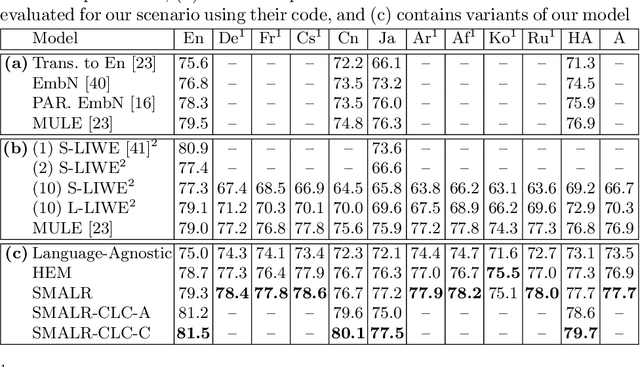
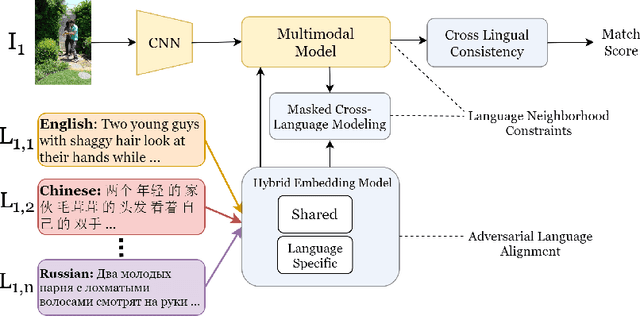
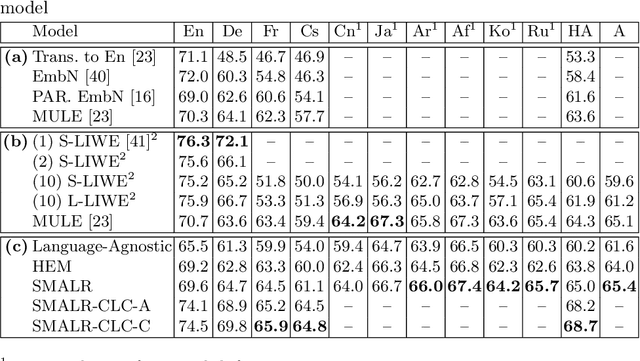
Current multilingual vision-language models either require a large number of additional parameters for each supported language, or suffer performance degradation as languages are added. In this paper, we propose a Scalable Multilingual Aligned Language Representation (SMALR) that represents many languages with few model parameters without sacrificing downstream task performance. SMALR learns a fixed size language-agnostic representation for most words in a multilingual vocabulary, keeping language-specific features for few. We use a novel masked cross-language modeling loss to align features with context from other languages. Additionally, we propose a cross-lingual consistency module that ensures predictions made for a query and its machine translation are comparable. The effectiveness of SMALR is demonstrated with ten diverse languages, over twice the number supported in vision-language tasks to date. We evaluate on multilingual image-sentence retrieval and outperform prior work by 3-4% with less than 1/5th the training parameters compared to other word embedding methods.
Image Generation from Small Datasets via Batch Statistics Adaptation
Apr 22, 2019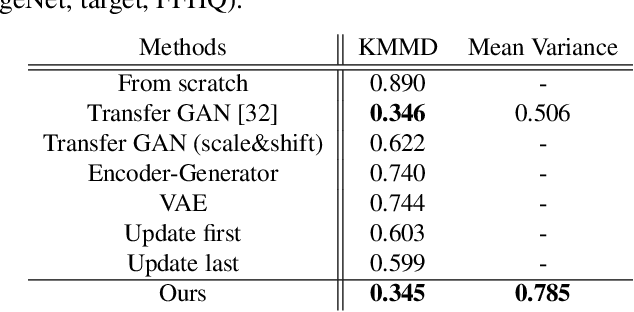

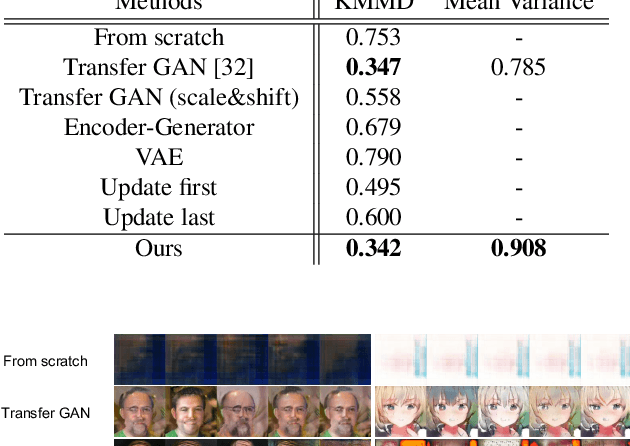
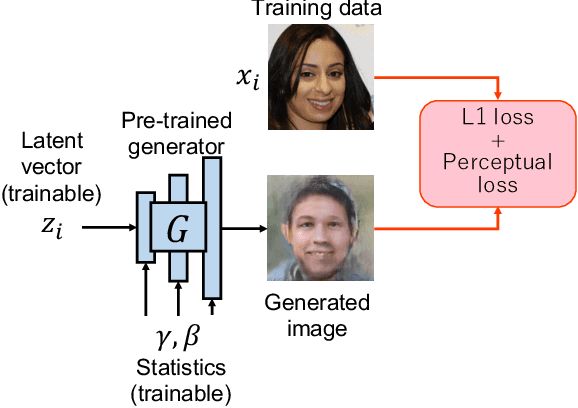
Thanks to the recent development of deep generative models, it is becoming possible to generate high-quality images with both fidelity and diversity. However, the training of such generative models requires a large dataset. To reduce the amount of data required, we propose a new method for transferring prior knowledge of the pre-trained generator, which is trained with a large dataset, to a small dataset in a different domain. Using such prior knowledge, the model can generate images leveraging some common sense that cannot be acquired from a small dataset. In this work, we propose a novel method focusing on the parameters for batch statistics, scale and shift, of the hidden layers in the generator. By training only these parameters in a supervised manner, we achieved stable training of the generator, and our method can generate higher quality images compared to previous methods without collapsing even when the dataset is small (~100). Our results show that the diversity of the filters acquired in the pre-trained generator is important for the performance on the target domain. By our method, it becomes possible to add a new class or domain to a pre-trained generator without disturbing the performance on the original domain.
Semantic Hierarchy Emerges in Deep Generative Representations for Scene Synthesis
Nov 29, 2019

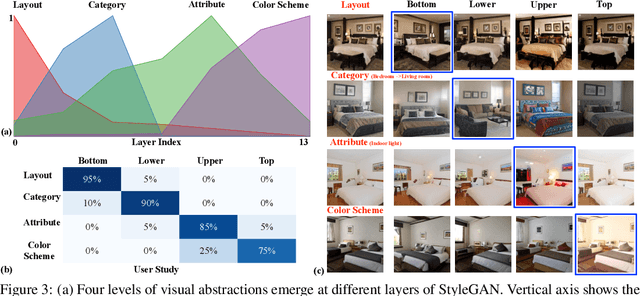
Despite the success of Generative Adversarial Networks (GANs) in image synthesis, there lacks enough understanding on what networks have learned inside the deep generative representations and how photo-realistic images are able to be composed of random noises. In this work, we show that highly-structured semantic hierarchy emerges as variation factors for synthesizing scenes from the generative representations in state-of-the-art GAN models, like StyleGAN and BigGAN. By probing the layer-wise representations with a broad set of semantics at different abstraction levels, we are able to quantify the causality between the activations and semantics occurring in the output image. Such a quantification identifies the human-understandable variation factors learned by GANs to compose scenes. The qualitative and quantitative results suggest that the generative representations learned by the GANs with layer-wise latent codes are specialized to synthesize different hierarchical semantics: the early layers tend to determine the spatial layout and configuration, the middle layers control the objects, and the later layers finally render the scene attributes as well as color scheme. Identifying such a set of manipulatable latent variation factors facilitates semantic scene manipulation.
Deep Multimodal Neural Architecture Search
Apr 25, 2020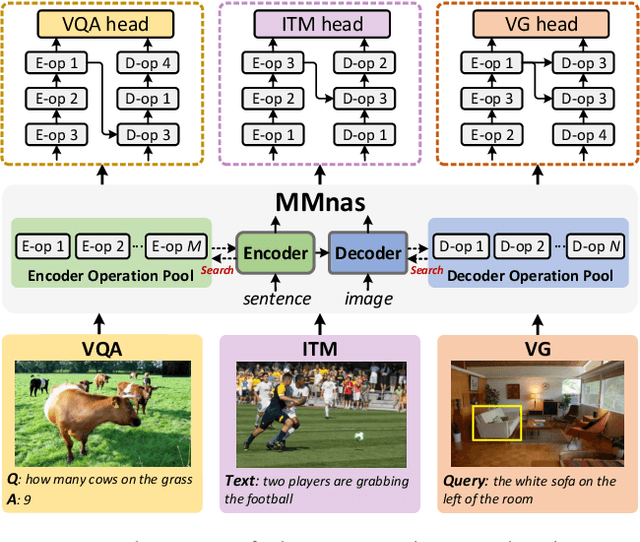
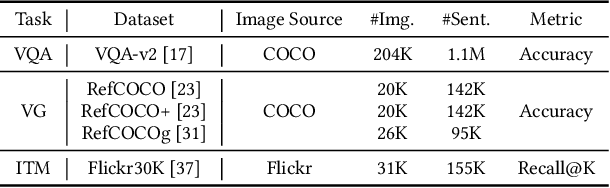
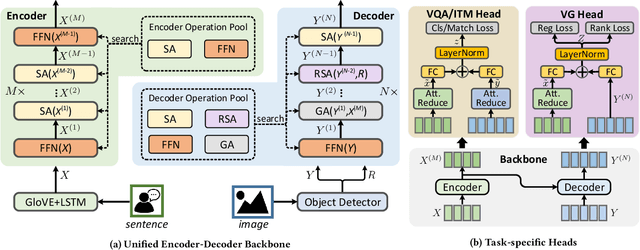
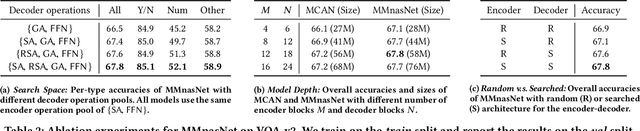
Designing effective neural networks is fundamentally important in deep multimodal learning. Most existing works focus on a single task and design neural architectures manually, which are highly task-specific and hard to generalize to different tasks. In this paper, we devise a generalized deep multimodal neural architecture search (MMnas) framework for various multimodal learning tasks. Given multimodal input, we first define a set of primitive operations, and then construct a deep encoder-decoder based unified backbone, where each encoder or decoder block corresponds to an operation searched from a predefined operation pool. On top of the unified backbone, we attach task-specific heads to tackle different multimodal learning tasks. By using a gradient-based NAS algorithm, the optimal architectures for different tasks are learned efficiently. Extensive ablation studies, comprehensive analysis, and superior experimental results show that MMnasNet significantly outperforms existing state-of-the-art approaches across three multimodal learning tasks (over five datasets), including visual question answering, image-text matching, and visual grounding. Code will be made available.
An Approach for Reducing Outliers of Non Local Means Image Denoising Filter
Dec 09, 2014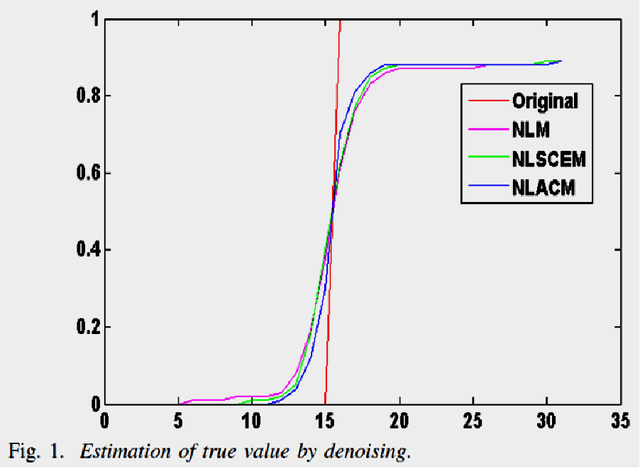
We propose an adaptive approach for non local means (NLM) image filtering termed as non local adaptive clipped means (NLACM), which reduces the effect of outliers and improves the denoising quality as compared to traditional NLM. Common method to neglect outliers from a data population is computation of mean in a range defined by mean and standard deviation. In NLACM we perform the median within the defined range based on statistical estimation of the neighbourhood region of a pixel to be denoised. As parameters of the range are independent of any additional input and is based on local intensity values, hence the approach is adaptive. Experimental results for NLACM show better estimation of true intensity from noisy neighbourhood observation as compared to NLM at high noise levels. We have verified the technique for speckle noise reduction and we have tested it on ultrasound (US) image of lumbar spine. These ultrasound images act as guidance for injection therapy for treatment of lumbar radiculopathy. We believe that the proposed approach for image denoising is first of its kind and its efficiency can be well justified as it shows better performance in image restoration.
Augment Yourself: Mixed Reality Self-Augmentation Using Optical See-through Head-mounted Displays and Physical Mirrors
Jul 06, 2020
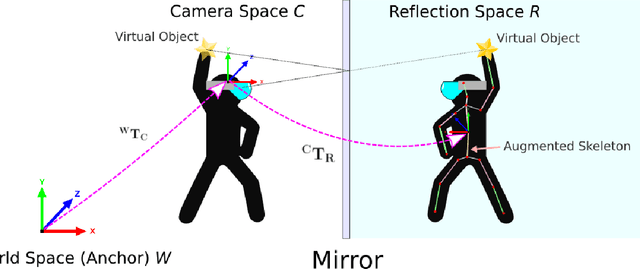
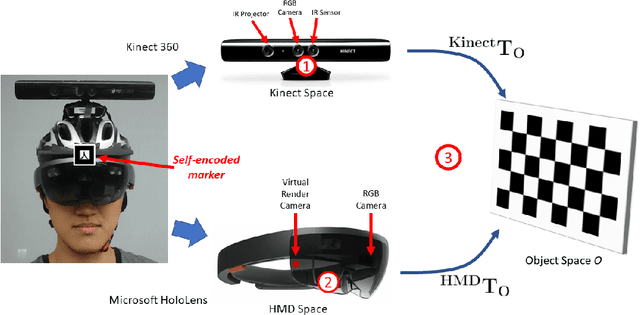
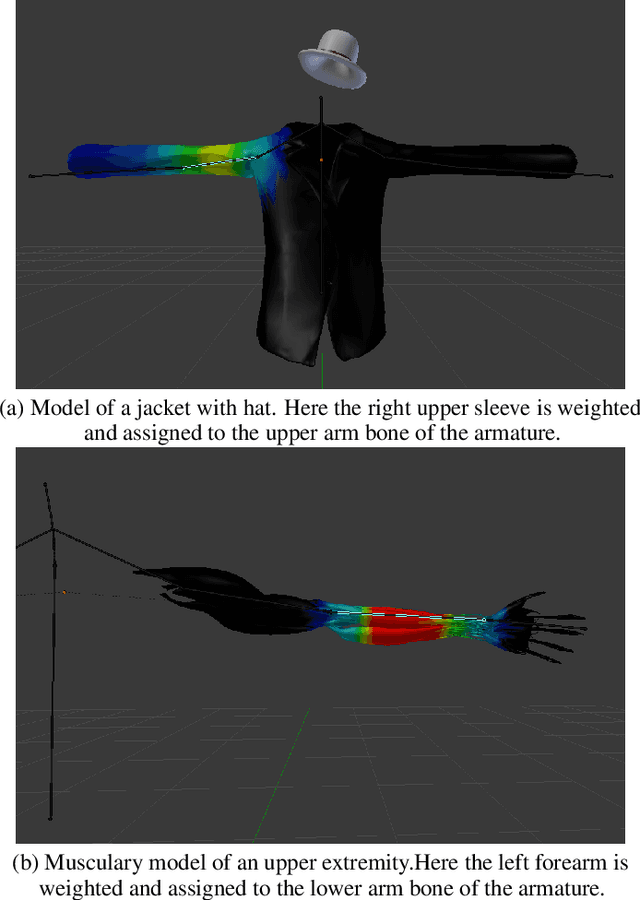
Optical see-though head-mounted displays (OST HMDs) are one of the key technologies for merging virtual objects and physical scenes to provide an immersive mixed reality (MR) environment to its user. A fundamental limitation of HMDs is, that the user itself cannot be augmented conveniently as, in casual posture, only the distal upper extremities are within the field of view of the HMD. Consequently, most MR applications that are centered around the user, such as virtual dressing rooms or learning of body movements, cannot be realized with HMDs. In this paper, we propose a novel concept and prototype system that combines OST HMDs and physical mirrors to enable self-augmentation and provide an immersive MR environment centered around the user. Our system, to the best of our knowledge the first of its kind, estimates the user's pose in the virtual image generated by the mirror using an RGBD camera attached to the HMD and anchors virtual objects to the reflection rather than the user directly. We evaluate our system quantitatively with respect to calibration accuracy and infrared signal degradation effects due to the mirror, and show its potential in applications where large mirrors are already an integral part of the facility. Particularly, we demonstrate its use for virtual fitting rooms, gaming applications, anatomy learning, and personal fitness. In contrast to competing devices such as LCD-equipped smart mirrors, the proposed system consists of only an HMD with RGBD camera and, thus, does not require a prepared environment making it very flexible and generic. In future work, we will aim to investigate how the system can be optimally used for physical rehabilitation and personal training as a promising application.