 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rectangular Pyramid Partitioning using Integrated Depth Sensors (RAPPIDS): A Fast Planner for Multicopter Navigation
Mar 02, 2020
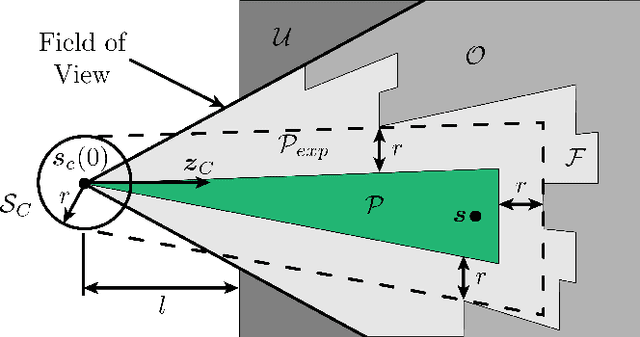


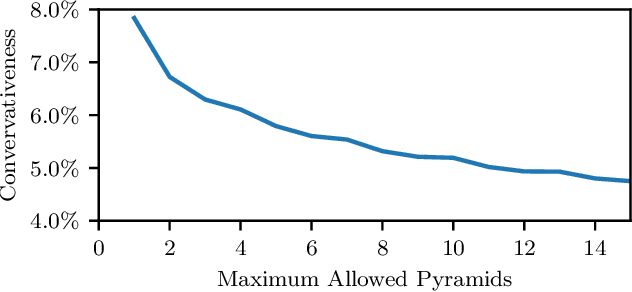
We present a novel multicopter trajectory planning algorithm (RAPPIDS) that is capable of quickly finding local collision-free trajectories given a single depth image from an onboard camera. The algorithm leverages a new pyramid-based spatial partitioning method that enables rapid collision detection between candidate trajectories and the environment. Due to its efficiency, the algorithm can be run at high rates on computationally constrained hardware, evaluating thousands of candidate trajectories in milliseconds. The performance of the algorithm is compared to existing collision checking methods in simulation, showing our method to be capable of evaluating orders of magnitude more trajectories per second. Experimental results are presented showing a quadcopter quickly navigating a previously unseen cluttered environment by running the algorithm on an ODROID-XU4 at 30 Hz.
Real-time 3D Nanoscale Coherent Imaging via Physics-aware Deep Learning
Jun 16, 2020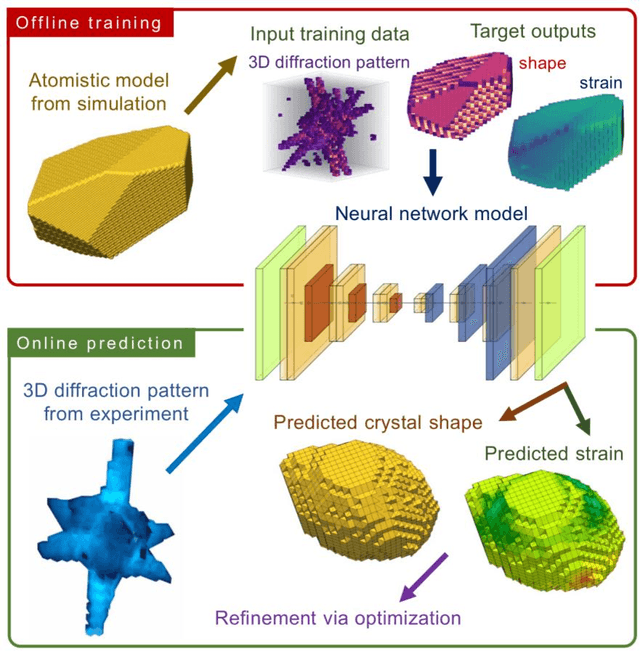
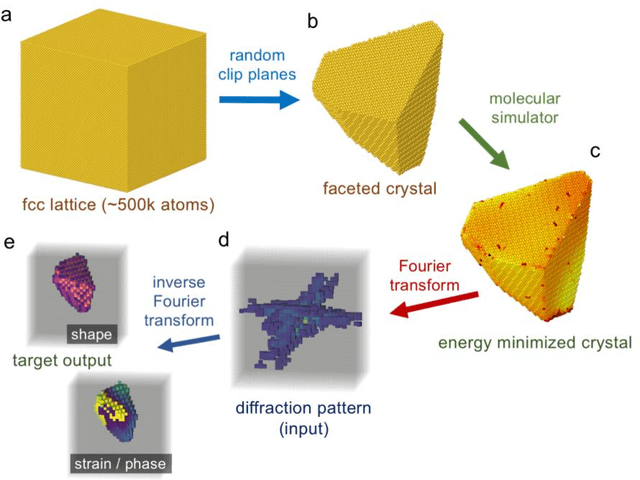
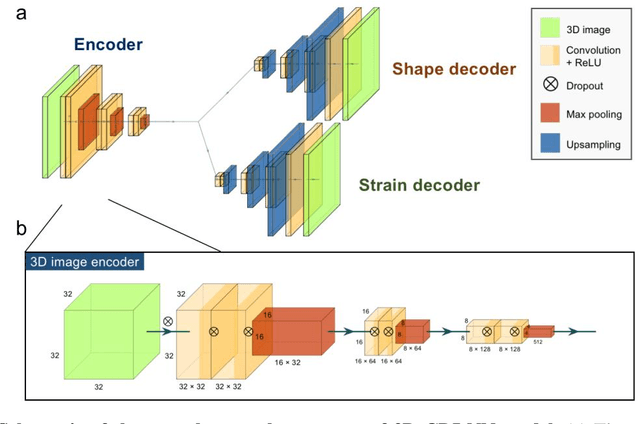
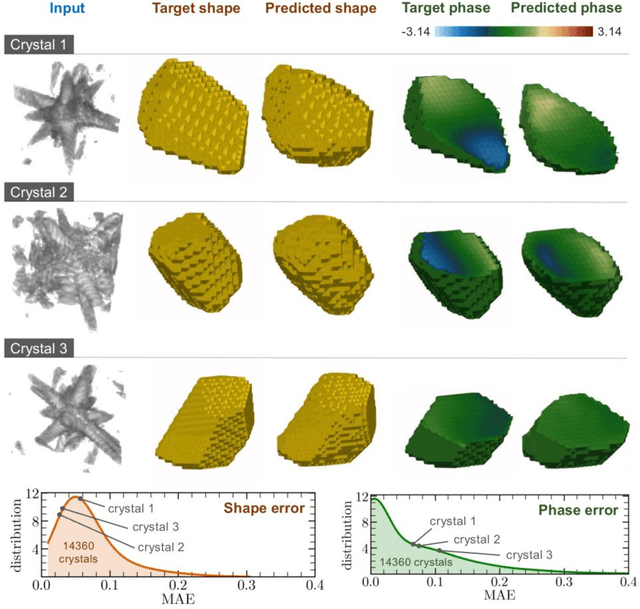
Phase retrieval, the problem of recovering lost phase information from measured intensity alone, is an inverse problem that is widely faced in various imaging modalities ranging from astronomy to nanoscale imaging. The current process of phase recovery is iterative in nature. As a result, the image formation is time-consuming and computationally expensive, precluding real-time imaging. Here, we use 3D nanoscale X-ray imaging as a representative example to develop a deep learning model to address this phase retrieval problem. We introduce 3D-CDI-NN, a deep convolutional neural network and differential programming framework trained to predict 3D structure and strain solely from input 3D X-ray coherent scattering data. Our networks are designed to be "physics-aware" in multiple aspects; in that the physics of x-ray scattering process is explicitly enforced in the training of the network, and the training data are drawn from atomistic simulations that are representative of the physics of the material. We further refine the neural network prediction through a physics-based optimization procedure to enable maximum accuracy at lowest computational cost. 3D-CDI-NN can invert a 3D coherent diffraction pattern to real-space structure and strain hundreds of times faster than traditional iterative phase retrieval methods, with negligible loss in accuracy. Our integrated machine learning and differential programming solution to the phase retrieval problem is broadly applicable across inverse problems in other application areas.
Learning a No-Reference Quality Assessment Model of Enhanced Images With Big Data
Apr 18, 2019
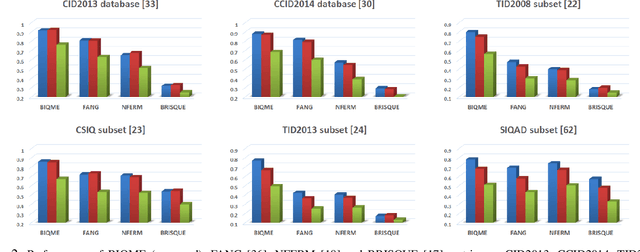
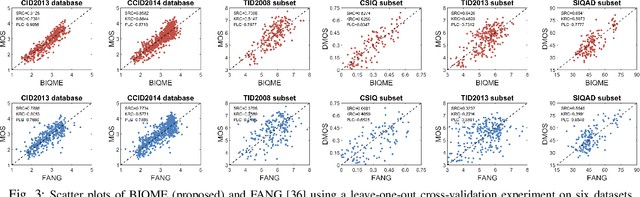
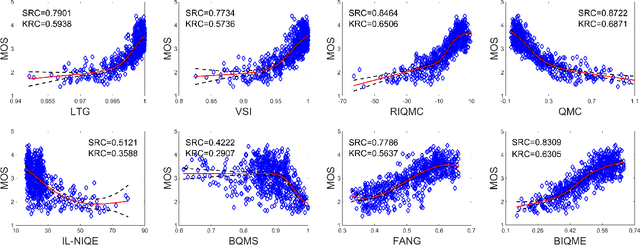
In this paper we investigate into the problem of image quality assessment (IQA) and enhancement via machine learning. This issue has long attracted a wide range of attention in computational intelligence and image processing communities, since, for many practical applications, e.g. object detection and recognition, raw images are usually needed to be appropriately enhanced to raise the visual quality (e.g. visibility and contrast). In fact, proper enhancement can noticeably improve the quality of input images, even better than originally captured images which are generally thought to be of the best quality. In this work, we present two most important contributions. The first contribution is to develop a new no-reference (NR) IQA model. Given an image, our quality measure first extracts 17 features through analysis of contrast, sharpness, brightness and more, and then yields a measre of visual quality using a regression module, which is learned with big-data training samples that are much bigger than the size of relevant image datasets. Results of experiments on nine datasets validate the superiority and efficiency of our blind metric compared with typical state-of-the-art full-, reduced- and no-reference IQA methods. The second contribution is that a robust image enhancement framework is established based on quality optimization. For an input image, by the guidance of the proposed NR-IQA measure, we conduct histogram modification to successively rectify image brightness and contrast to a proper level. Thorough tests demonstrate that our framework can well enhance natural images, low-contrast images, low-light images and dehazed images. The source code will be released at https://sites.google.com/site/guke198701/publications.
Scene Recognition with Prototype-agnostic Scene Layout
Sep 07, 2019
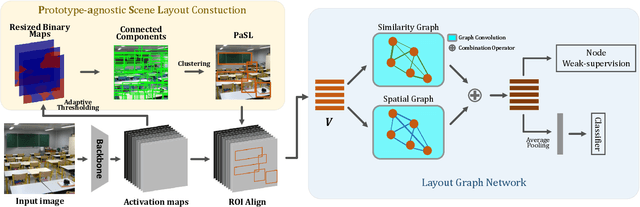

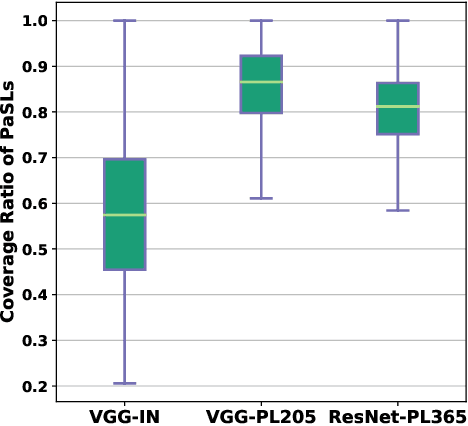
Abstract--- Exploiting the spatial structure in scene images is a key research direction for scene recognition. Due to the large intra-class structural diversity, building and modeling flexible structural layout to adapt various image characteristics is a challenge. Existing structural modeling methods in scene recognition either focus on predefined grids or rely on learned prototypes, which all have limited representative ability. In this paper, we propose Prototype-agnostic Scene Layout (PaSL) construction method to build the spatial structure for each image without conforming to any prototype. Our PaSL can flexibly capture the diverse spatial characteristic of scene images and have considerable generalization capability. Given a PaSL, we build Layout Graph Network (LGN) where regions in PaSL are defined as nodes and two kinds of independent relations between regions are encoded as edges. The LGN aims to incorporate two topological structures (formed in spatial and semantic similarity dimensions) into image representations through graph convolution. Extensive experiments show that our approach achieves state-of-the-art results on widely recognized MIT67 and SUN397 datasets without multi-model or multi-scale fusion. Moreover, we also conduct the experiments on one of the largest scale datasets, Places365. The results demonstrate the proposed method can be well generalized and obtains competitive performance.
Sequential Neural Rendering with Transformer
Apr 09, 2020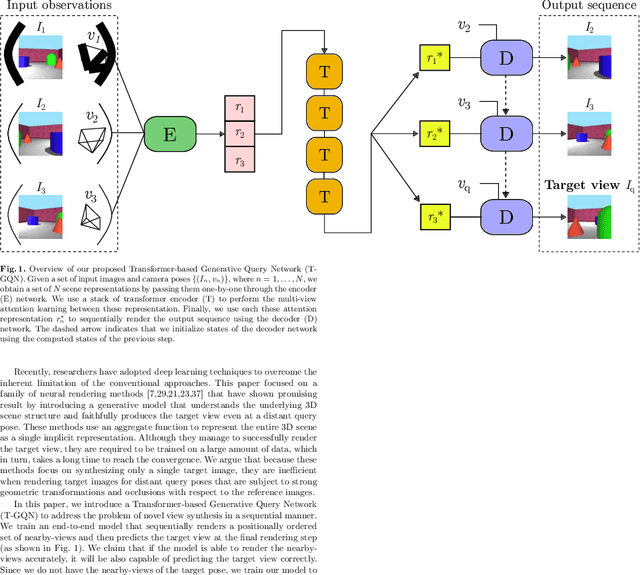
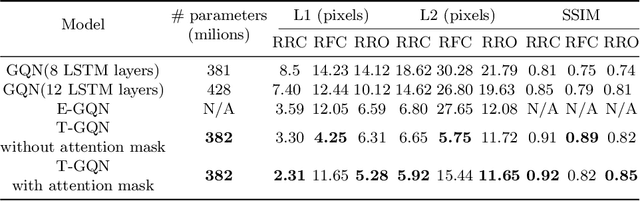
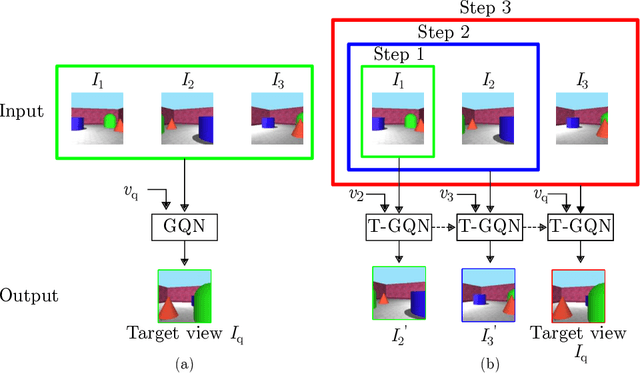
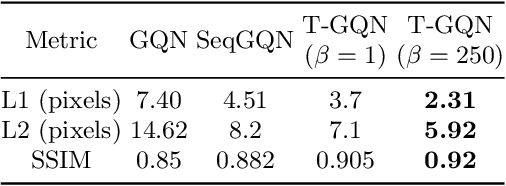
This paper address the problem of novel view synthesis by means of neural rendering, where we are interested in predicting the novel view at an arbitrary camera pose based on a given set of input images from other viewpoints. Using the known query pose and input poses, we create an ordered set of observations that leads to the target view. Thus, the problem of single novel view synthesis is reformulated as a sequential view prediction task. In this paper, the proposed Transformer-based Generative Query Network (T-GQN) extends the neural-rendering methods by adding two new concepts. First, we use multi-view attention learning between context images to obtain multiple implicit scene representations. Second, we introduce a sequential rendering decoder to predict an image sequence, including the target view, based on the learned representations. We evaluate our model on various challenging synthetic datasets and demonstrate that our model can give consistent predictions and achieve faster training convergence than the former architectures.
Two-stage Geometric Information Guided Image Reconstruction
Sep 26, 2014
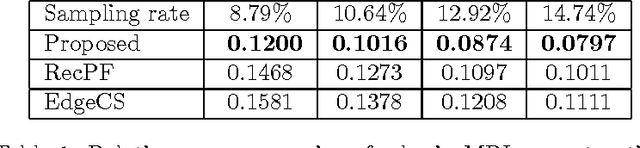
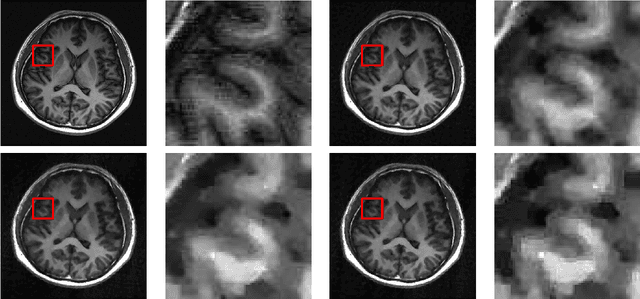
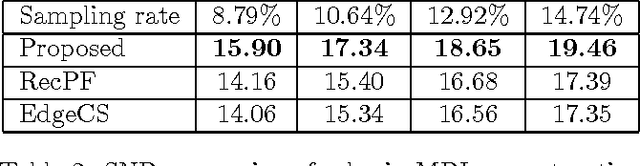
In compressive sensing, it is challenging to reconstruct image of high quality from very few noisy linear projections. Existing methods mostly work well on piecewise constant images but not so well on piecewise smooth images such as natural images, medical images that contain a lot of details. We propose a two-stage method called GeoCS to recover images with rich geometric information from very limited amount of noisy measurements. The method adopts the shearlet transform that is mathematically proven to be optimal in sparsely representing images containing anisotropic features such as edges, corners, spikes etc. It also uses the weighted total variation (TV) sparsity with spatially variant weights to preserve sharp edges but to reduce the staircase effects of TV. Geometric information extracted from the results of stage I serves as an initial prior for stage II which alternates image reconstruction and geometric information update in a mutually beneficial way. GeoCS has been tested on incomplete spectral Fourier samples. It is applicable to other types of measurements as well. Experimental results on various complicated images show that GeoCS is efficient and generates high-quality images.
Gimme Signals: Discriminative signal encoding for multimodal activity recognition
Apr 09, 2020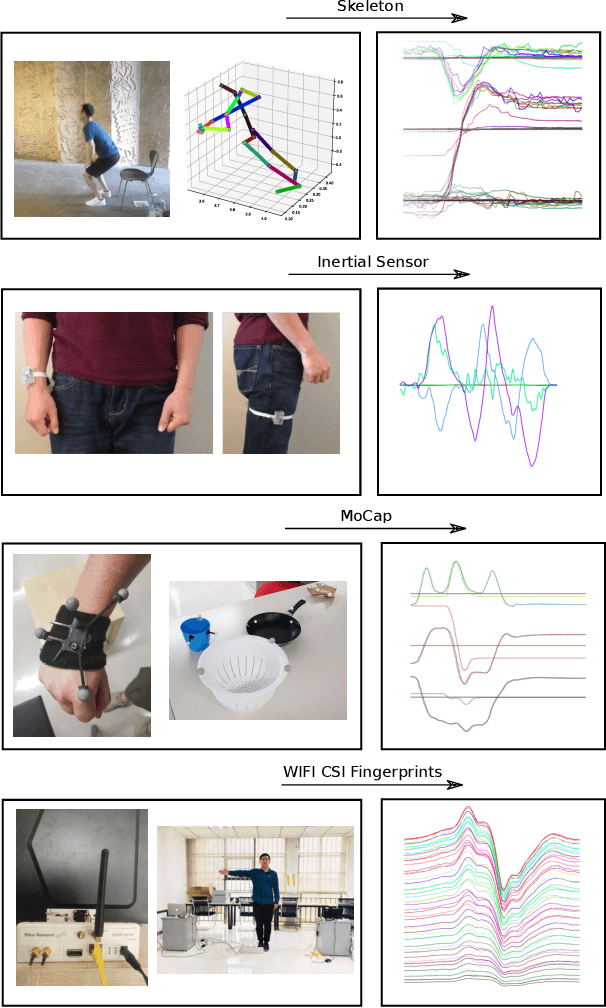
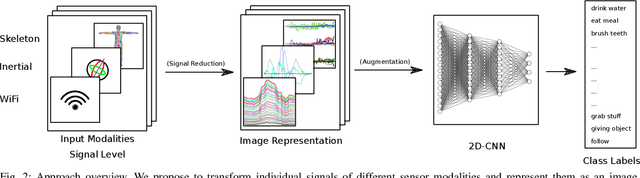
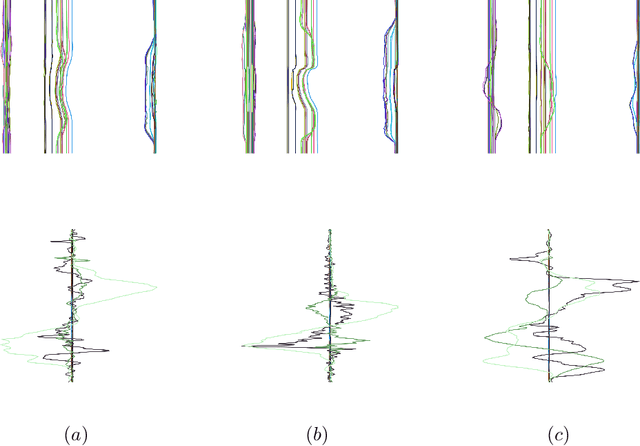

We present a simple, yet effective and flexible method for action recognition supporting multiple sensor modalities. Multivariate signal sequences are encoded in an image and are then classified using a recently proposed EfficientNet CNN architecture. Our focus was to find an approach that generalizes well across different sensor modalities without specific adaptions while still achieving good results. We apply our method to 4 action recognition datasets containing skeleton sequences, inertial and motion capturing measurements as well as \wifi fingerprints that range up to 120 action classes. Our method defines the current best CNN-based approach on the NTU RGB+D 120 dataset, lifts the state of the art on the ARIL Wi-Fi dataset by +6.78%, improves the UTD-MHAD inertial baseline by +14.4%, the UTD-MHAD skeleton baseline by 1.13% and achieves 96.11% on the Simitate motion capturing data (80/20 split). We further demonstrate experiments on both, modality fusion on a signal level and signal reduction to prevent the representation from overloading.
ICDAR 2019 Competition on Scene Text Visual Question Answering
Jun 30, 2019
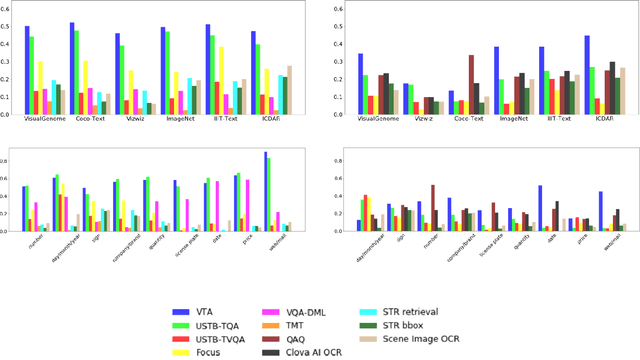
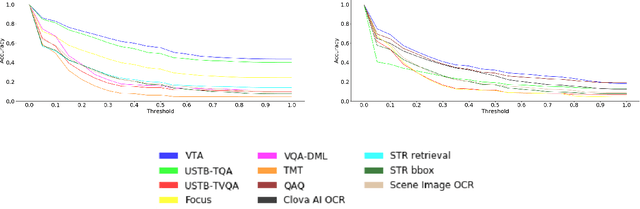
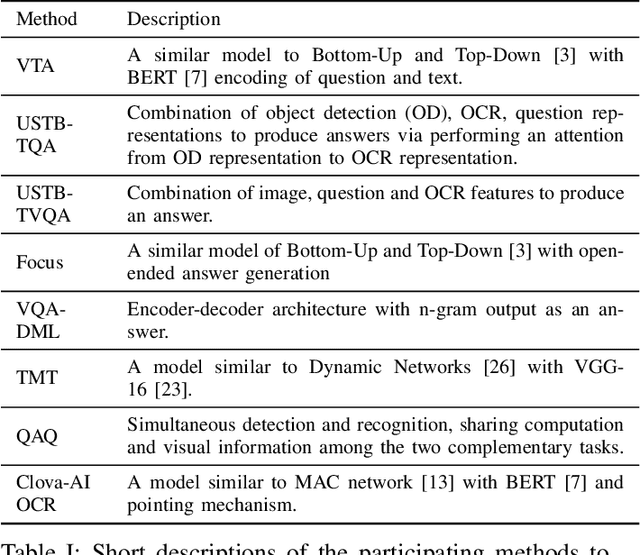
This paper presents final results of ICDAR 2019 Scene Text Visual Question Answering competition (ST-VQA). ST-VQA introduces an important aspect that is not addressed by any Visual Question Answering system up to date, namely the incorporation of scene text to answer questions asked about an image. The competition introduces a new dataset comprising 23,038 images annotated with 31,791 question/answer pairs where the answer is always grounded on text instances present in the image. The images are taken from 7 different public computer vision datasets, covering a wide range of scenarios. The competition was structured in three tasks of increasing difficulty, that require reading the text in a scene and understanding it in the context of the scene, to correctly answer a given question. A novel evaluation metric is presented, which elegantly assesses both key capabilities expected from an optimal model: text recognition and image understanding. A detailed analysis of results from different participants is showcased, which provides insight into the current capabilities of VQA systems that can read. We firmly believe the dataset proposed in this challenge will be an important milestone to consider towards a path of more robust and general models that can exploit scene text to achieve holistic image understanding.
Augment Yourself: Mixed Reality Self-Augmentation Using Optical See-through Head-mounted Displays and Physical Mirrors
Jul 06, 2020
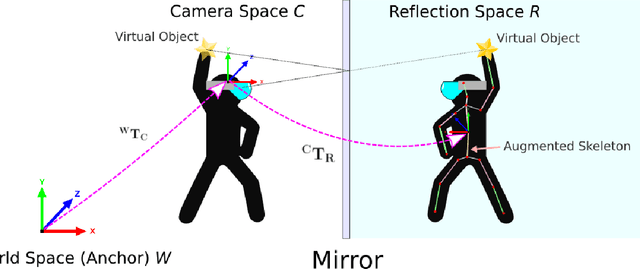
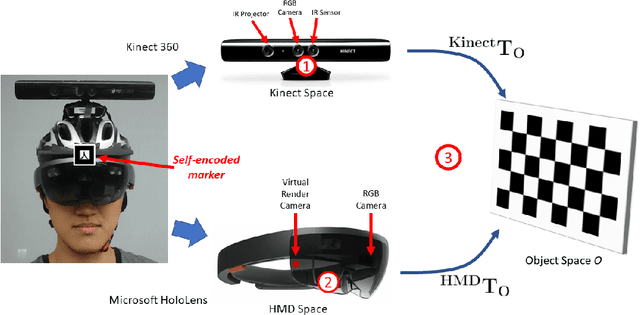
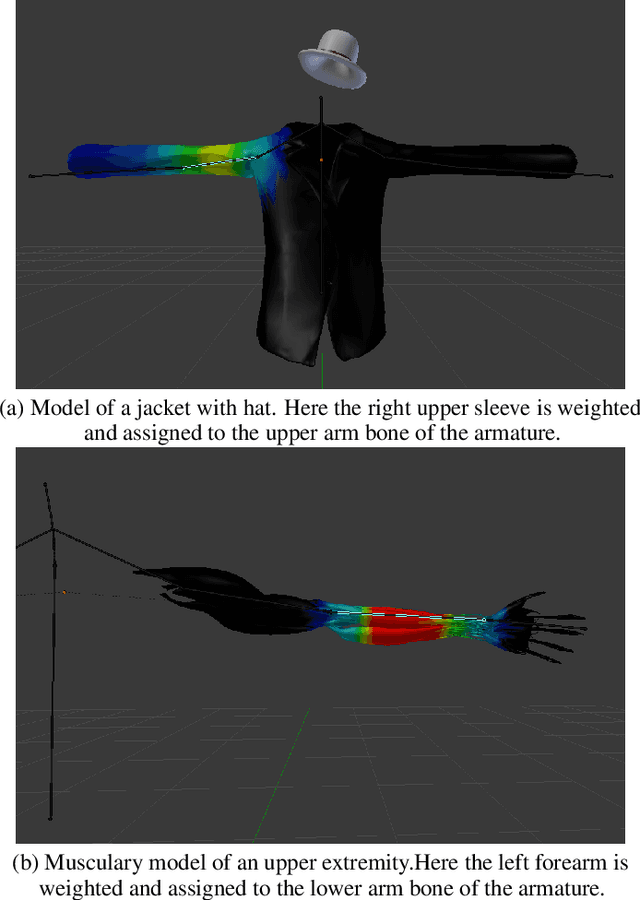
Optical see-though head-mounted displays (OST HMDs) are one of the key technologies for merging virtual objects and physical scenes to provide an immersive mixed reality (MR) environment to its user. A fundamental limitation of HMDs is, that the user itself cannot be augmented conveniently as, in casual posture, only the distal upper extremities are within the field of view of the HMD. Consequently, most MR applications that are centered around the user, such as virtual dressing rooms or learning of body movements, cannot be realized with HMDs. In this paper, we propose a novel concept and prototype system that combines OST HMDs and physical mirrors to enable self-augmentation and provide an immersive MR environment centered around the user. Our system, to the best of our knowledge the first of its kind, estimates the user's pose in the virtual image generated by the mirror using an RGBD camera attached to the HMD and anchors virtual objects to the reflection rather than the user directly. We evaluate our system quantitatively with respect to calibration accuracy and infrared signal degradation effects due to the mirror, and show its potential in applications where large mirrors are already an integral part of the facility. Particularly, we demonstrate its use for virtual fitting rooms, gaming applications, anatomy learning, and personal fitness. In contrast to competing devices such as LCD-equipped smart mirrors, the proposed system consists of only an HMD with RGBD camera and, thus, does not require a prepared environment making it very flexible and generic. In future work, we will aim to investigate how the system can be optimally used for physical rehabilitation and personal training as a promising application.
Image Segmentation by Size-Dependent Single Linkage Clustering of a Watershed Basin Graph
May 01, 2015

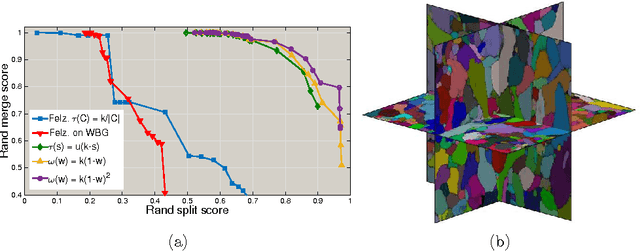
We present a method for hierarchical image segmentation that defines a disaffinity graph on the image, over-segments it into watershed basins, defines a new graph on the basins, and then merges basins with a modified, size-dependent version of single linkage clustering. The quasilinear runtime of the method makes it suitable for segmenting large images. We illustrate the method on the challenging problem of segmenting 3D electron microscopic brain images.