 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Are Accelerometers for Activity Recognition a Dead-end?
Jan 30, 2020
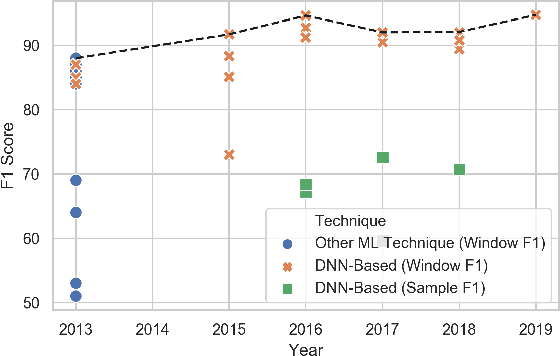

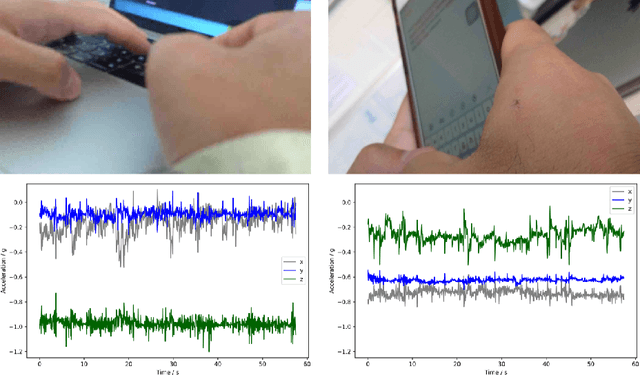
Accelerometer-based (and by extension other inertial sensors) research for Human Activity Recognition (HAR) is a dead-end. This sensor does not offer enough information for us to progress in the core domain of HAR - to recognize everyday activities from sensor data. Despite continued and prolonged efforts in improving feature engineering and machine learning models, the activities that we can recognize reliably have only expanded slightly and many of the same flaws of early models are still present today. Instead of relying on acceleration data, we should instead consider modalities with much richer information - a logical choice are images. With the rapid advance in image sensing hardware and modelling techniques, we believe that a widespread adoption of image sensors will open many opportunities for accurate and robust inference across a wide spectrum of human activities. In this paper, we make the case for imagers in place of accelerometers as the default sensor for human activity recognition. Our review of past works has led to the observation that progress in HAR had stalled, caused by our reliance on accelerometers. We further argue for the suitability of images for activity recognition by illustrating their richness of information and the marked progress in computer vision. Through a feasibility analysis, we find that deploying imagers and CNNs on device poses no substantial burden on modern mobile hardware. Overall, our work highlights the need to move away from accelerometers and calls for further exploration of using imagers for activity recognition.
FaceHack: Triggering backdoored facial recognition systems using facial characteristics
Jun 20, 2020
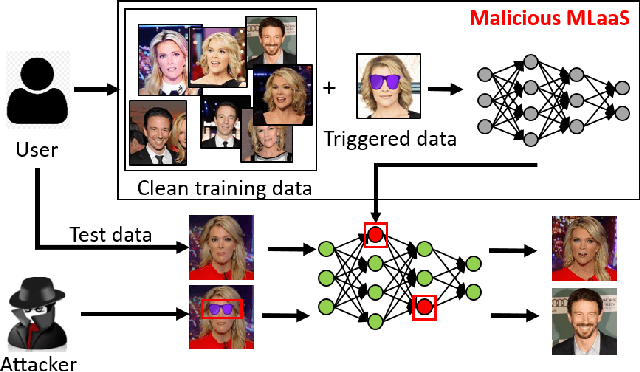

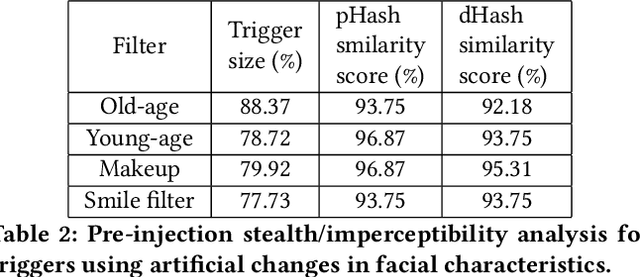
Recent advances in Machine Learning (ML) have opened up new avenues for its extensive use in real-world applications. Facial recognition, specifically, is used from simple friend suggestions in social-media platforms to critical security applications for biometric validation in automated immigration at airports. Considering these scenarios, security vulnerabilities to such ML algorithms pose serious threats with severe outcomes. Recent work demonstrated that Deep Neural Networks (DNNs), typically used in facial recognition systems, are susceptible to backdoor attacks; in other words,the DNNs turn malicious in the presence of a unique trigger. Adhering to common characteristics for being unnoticeable, an ideal trigger is small, localized, and typically not a part of the main im-age. Therefore, detection mechanisms have focused on detecting these distinct trigger-based outliers statistically or through their reconstruction. In this work, we demonstrate that specific changes to facial characteristics may also be used to trigger malicious behavior in an ML model. The changes in the facial attributes maybe embedded artificially using social-media filters or introduced naturally using movements in facial muscles. By construction, our triggers are large, adaptive to the input, and spread over the entire image. We evaluate the success of the attack and validate that it does not interfere with the performance criteria of the model. We also substantiate the undetectability of our triggers by exhaustively testing them with state-of-the-art defenses.
Exploiting Image-trained CNN Architectures for Unconstrained Video Classification
May 08, 2015
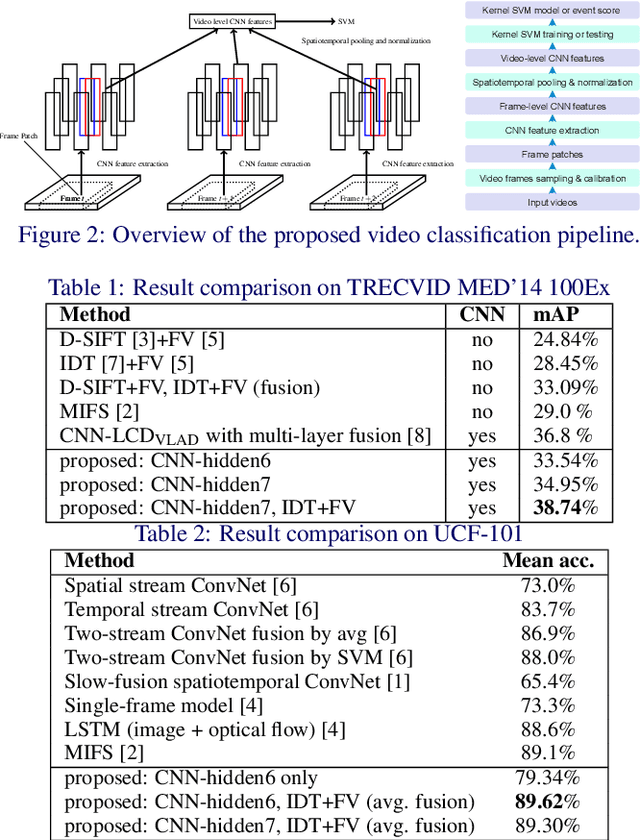
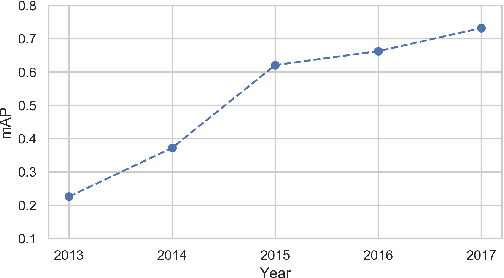
We conduct an in-depth exploration of different strategies for doing event detection in videos using convolutional neural networks (CNNs) trained for image classification. We study different ways of performing spatial and temporal pooling, feature normalization, choice of CNN layers as well as choice of classifiers. Making judicious choices along these dimensions led to a very significant increase in performance over more naive approaches that have been used till now. We evaluate our approach on the challenging TRECVID MED'14 dataset with two popular CNN architectures pretrained on ImageNet. On this MED'14 dataset, our methods, based entirely on image-trained CNN features, can outperform several state-of-the-art non-CNN models. Our proposed late fusion of CNN- and motion-based features can further increase the mean average precision (mAP) on MED'14 from 34.95% to 38.74%. The fusion approach achieves the state-of-the-art classification performance on the challenging UCF-101 dataset.
Learn to Predict Sets Using Feed-Forward Neural Networks
Jan 30, 2020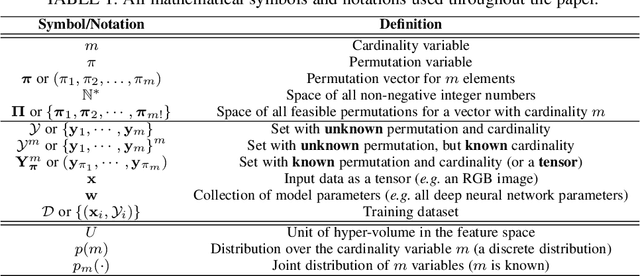
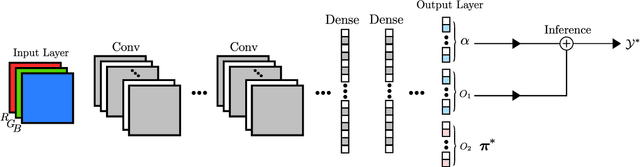
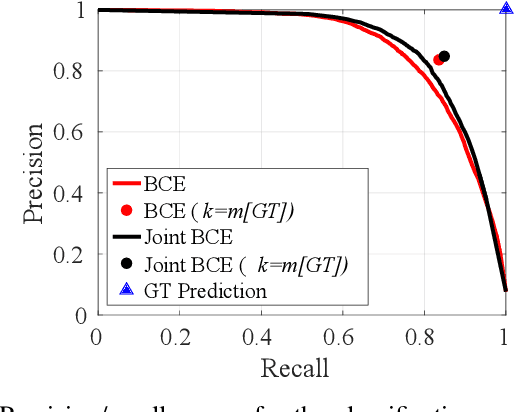

This paper addresses the task of set prediction using deep feed-forward neural networks. A set is a collection of elements which is invariant under permutation and the size of a set is not fixed in advance. Many real-world problems, such as image tagging and object detection, have outputs that are naturally expressed as sets of entities. This creates a challenge for traditional deep neural networks which naturally deal with structured outputs such as vectors, matrices or tensors. We present a novel approach for learning to predict sets with unknown permutation and cardinality using deep neural networks. In our formulation we define a likelihood for a set distribution represented by a) two discrete distributions defining the set cardinally and permutation variables, and b) a joint distribution over set elements with a fixed cardinality. Depending on the problem under consideration, we define different training models for set prediction using deep neural networks. We demonstrate the validity of our set formulations on relevant vision problems such as: 1)multi-label image classification where we achieve state-of-the-art performance on the PASCAL VOC and MS COCO datasets, 2) object detection, for which our formulation outperforms state-of-the-art detectors such as Faster R-CNN and YOLO v3, and 3) a complex CAPTCHA test, where we observe that, surprisingly, our set-based network acquired the ability of mimicking arithmetics without any rules being coded.
Granular Multimodal Attention Networks for Visual Dialog
Oct 13, 2019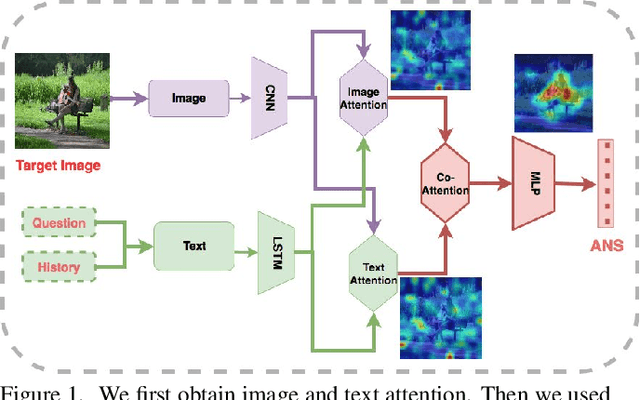
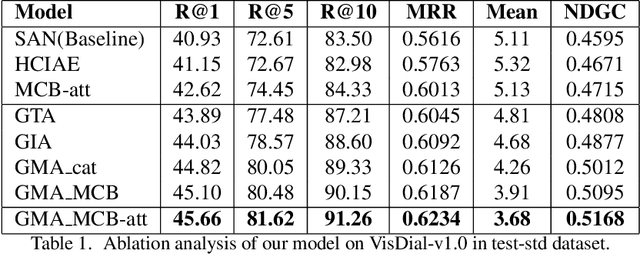
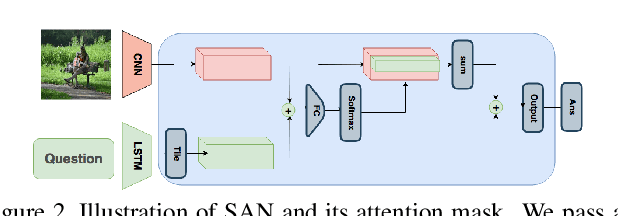
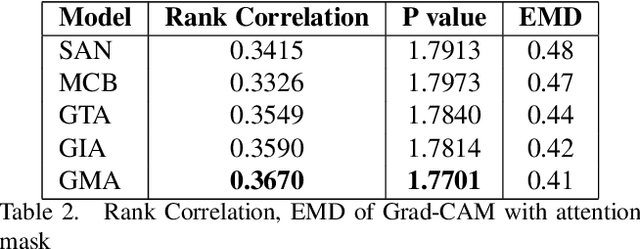
Vision and language tasks have benefited from attention. There have been a number of different attention models proposed. However, the scale at which attention needs to be applied has not been well examined. Particularly, in this work, we propose a new method Granular Multi-modal Attention, where we aim to particularly address the question of the right granularity at which one needs to attend while solving the Visual Dialog task. The proposed method shows improvement in both image and text attention networks. We then propose a granular Multi-modal Attention network that jointly attends on the image and text granules and shows the best performance. With this work, we observe that obtaining granular attention and doing exhaustive Multi-modal Attention appears to be the best way to attend while solving visual dialog.
Harvesting Information from Captions for Weakly Supervised Semantic Segmentation
May 16, 2019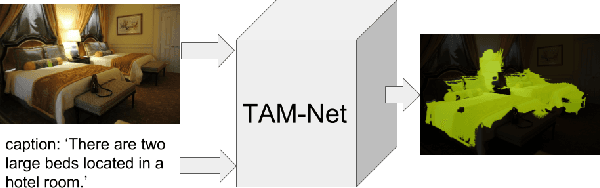
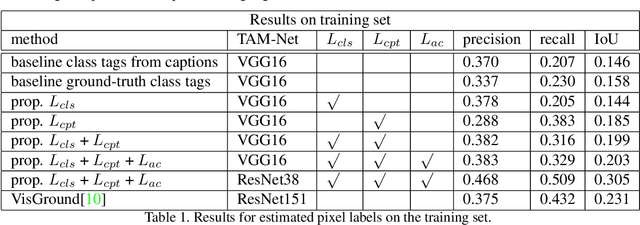
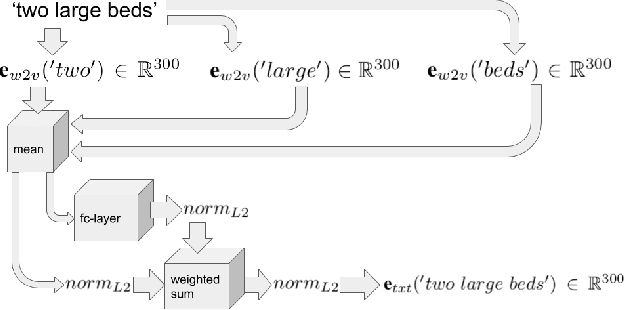

Since acquiring pixel-wise annotations for training convolutional neural networks for semantic image segmentation is time-consuming, weakly supervised approaches that only require class tags have been proposed. In this work, we propose another form of supervision, namely image captions as they can be found on the Internet. These captions have two advantages. They do not require additional curation as it is the case for the clean class tags used by current weakly supervised approaches and they provide textual context for the classes present in an image. To leverage such textual context, we deploy a multi-modal network that learns a joint embedding of the visual representation of the image and the textual representation of the caption. The network estimates text activation maps (TAMs) for class names as well as compound concepts, i.e. combinations of nouns and their attributes. The TAMs of compound concepts describing classes of interest substantially improve the quality of the estimated class activation maps which are then used to train a network for semantic segmentation. We evaluate our method on the COCO dataset where it achieves state of the art results for weakly supervised image segmentation.
Polarized Reflection Removal with Perfect Alignment in the Wild
Mar 28, 2020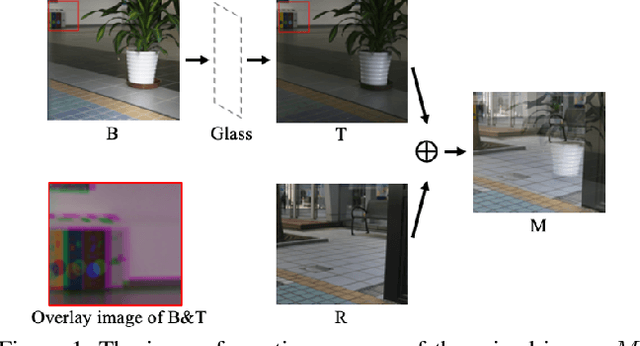

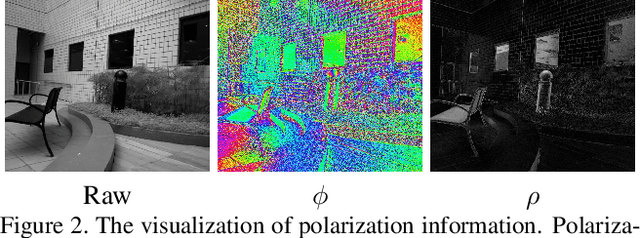
We present a novel formulation to removing reflection from polarized images in the wild. We first identify the misalignment issues of existing reflection removal datasets where the collected reflection-free images are not perfectly aligned with input mixed images due to glass refraction. Then we build a new dataset with more than 100 types of glass in which obtained transmission images are perfectly aligned with input mixed images. Second, capitalizing on the special relationship between reflection and polarized light, we propose a polarized reflection removal model with a two-stage architecture. In addition, we design a novel perceptual NCC loss that can improve the performance of reflection removal and general image decomposition tasks. We conduct extensive experiments, and results suggest that our model outperforms state-of-the-art methods on reflection removal.
Onion-Peel Networks for Deep Video Completion
Aug 23, 2019
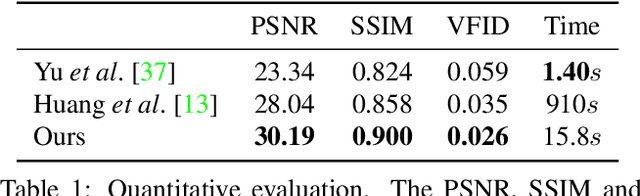
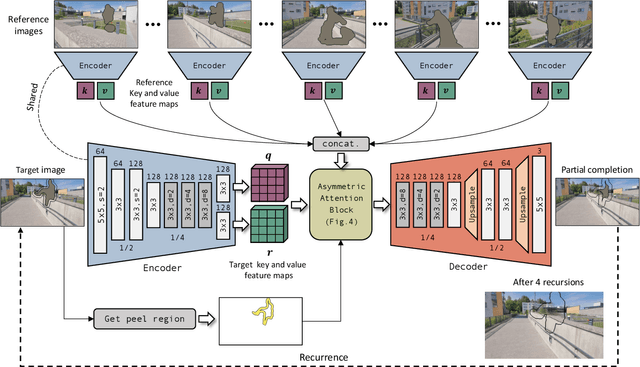
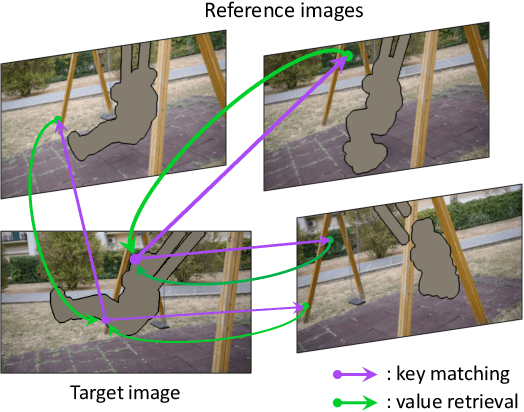
We propose the onion-peel networks for video completion. Given a set of reference images and a target image with holes, our network fills the hole by referring the contents in the reference images. Our onion-peel network progressively fills the hole from the hole boundary enabling it to exploit richer contextual information for the missing regions every step. Given a sufficient number of recurrences, even a large hole can be inpainted successfully. To attend to the missing information visible in the reference images, we propose an asymmetric attention block that computes similarities between the hole boundary pixels in the target and the non-hole pixels in the references in a non-local manner. With our attention block, our network can have an unlimited spatial-temporal window size and fill the holes with globally coherent contents. In addition, our framework is applicable to the image completion guided by the reference images without any modification, which is difficult to do with the previous methods. We validate that our method produces visually pleasing image and video inpainting results in realistic test cases.
Accuracy comparison across face recognition algorithms: Where are we on measuring race bias?
Dec 16, 2019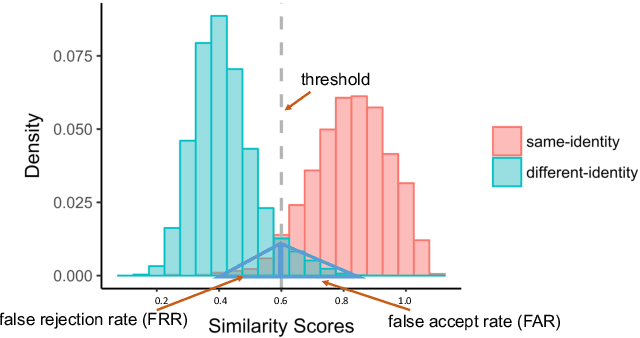
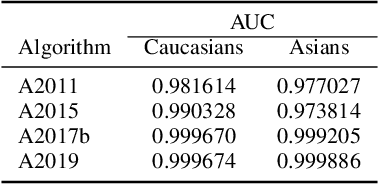

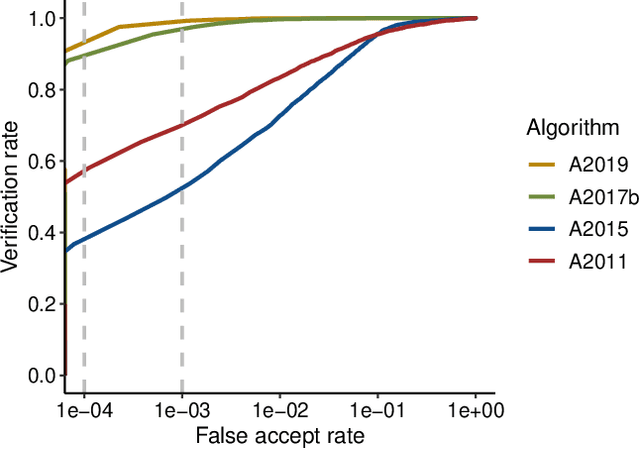
Previous generations of face recognition algorithms differ in accuracy for faces of different races (race bias). Whether deep convolutional neural networks (DCNNs) are race biased is less studied. To measure race bias in algorithms, it is important to consider the underlying factors. Here, we present the possible underlying factors and methodological considerations for assessing race bias in algorithms. We investigate data-driven and scenario modeling factors. Data-driven factors include image quality, image population statistics, and algorithm architecture. Scenario modeling considers the role of the "user" of the algorithm (e.g., threshold decisions and demographic constraints). To illustrate how these issues apply, we present data from four face recognition algorithms (one pre- DCNN, three DCNN) for Asian and Caucasian faces. First, for all four algorithms, the degree of bias varied depending on the identification decision threshold. Second, for all algorithms, to achieve equal false accept rates (FARs), Asian faces required higher identification thresholds than Caucasian faces. Third, dataset difficulty affected both overall recognition accuracy and race bias. Fourth, demographic constraints on the formulation of the distributions used in the test, impacted estimates of algorithm accuracy. We conclude with a recommended checklist for measuring race bias in face recognition algorithms.
Visual Attention: Deep Rare Features
May 25, 2020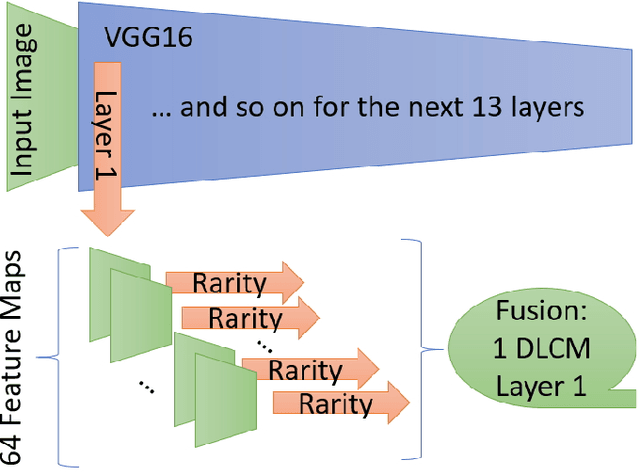



Human visual system is modeled in engineering field providing feature-engineered methods which detect contrasted/surprising/unusual data into images. This data is "interesting" for humans and leads to numerous applications. Deep learning (DNNs) drastically improved the algorithms efficiency on the main benchmark datasets. However, DNN-based models are counter-intuitive: surprising or unusual data is by definition difficult to learn because of its low occurrence probability. In reality, DNNs models mainly learn top-down features such as faces, text, people, or animals which usually attract human attention, but they have low efficiency in extracting surprising or unusual data in the images. In this paper, we propose a model called DeepRare2019 (DR) which uses the power of DNNs feature extraction and the genericity of feature-engineered algorithms. DR 1) does not need any training, 2) it takes less than a second per image on CPU only and 3) our tests on three very different eye-tracking datasets show that DR is generic and is always in the top-3 models on all datasets and metrics while no other model exhibits such a regularity and genericity. DeepRare2019 code can be found at https://github.com/numediart/VisualAttention-RareFamily