 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards VQA Models That Can Read
May 13, 2019

Studies have shown that a dominant class of questions asked by visually impaired users on images of their surroundings involves reading text in the image. But today's VQA models can not read! Our paper takes a first step towards addressing this problem. First, we introduce a new "TextVQA" dataset to facilitate progress on this important problem. Existing datasets either have a small proportion of questions about text (e.g., the VQA dataset) or are too small (e.g., the VizWiz dataset). TextVQA contains 45,336 questions on 28,408 images that require reasoning about text to answer. Second, we introduce a novel model architecture that reads text in the image, reasons about it in the context of the image and the question, and predicts an answer which might be a deduction based on the text and the image or composed of the strings found in the image. Consequently, we call our approach Look, Read, Reason & Answer (LoRRA). We show that LoRRA outperforms existing state-of-the-art VQA models on our TextVQA dataset. We find that the gap between human performance and machine performance is significantly larger on TextVQA than on VQA 2.0, suggesting that TextVQA is well-suited to benchmark progress along directions complementary to VQA 2.0.
High-Accuracy Malware Classification with a Malware-Optimized Deep Learning Model
Apr 10, 2020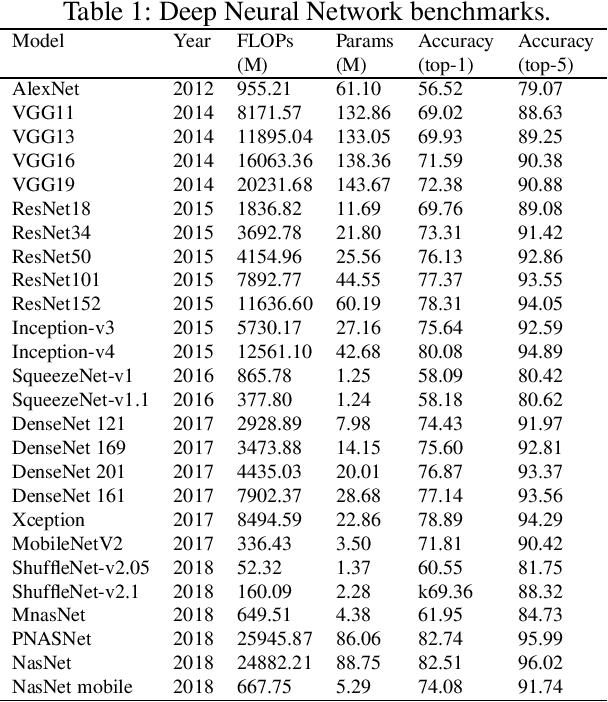
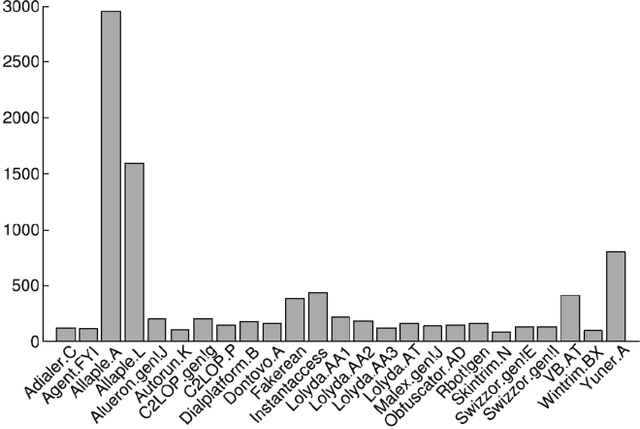
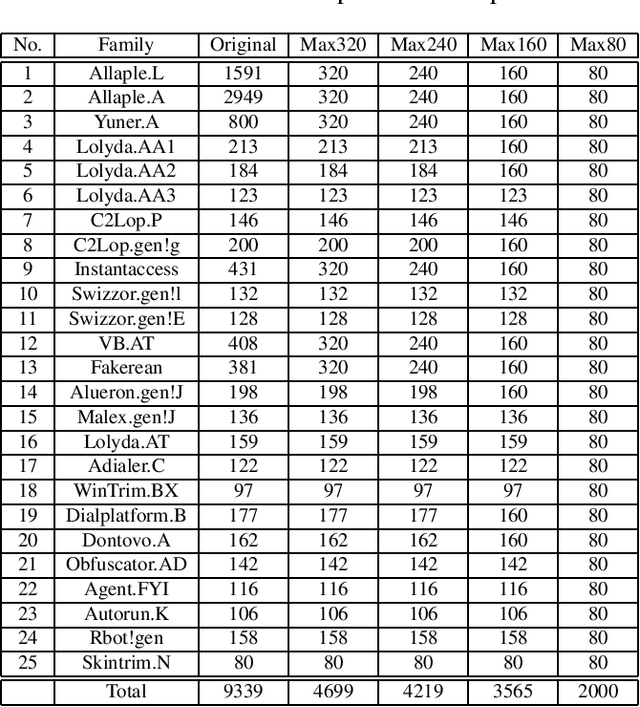
Malware threats are a serious problem for computer security, and the ability to detect and classify malware is critical for maintaining the security level of a computer. Recently, a number of researchers are investigating techniques for classifying malware families using malware visualization, which convert the binary structure of malware into grayscale images. Although there have been many reports that applied CNN to malware visualization image classification, it has not been revealed how to pick out a model that fits a given malware dataset and achieves higher classification accuracy. We propose a strategy to select a Deep learning model that fits the malware visualization images. Our strategy uses the fine-tuning method for the pre-trained CNN model and a dataset that solves the imbalance problem. We chose the VGG19 model based on the proposed strategy to classify the Malimg dataset. Experimental results show that the classification accuracy is 99.72 %, which is higher than other previously proposed malware classification methods.
Semi-Bagging Based Deep Neural Architecture to Extract Text from High Entropy Images
Jul 02, 2019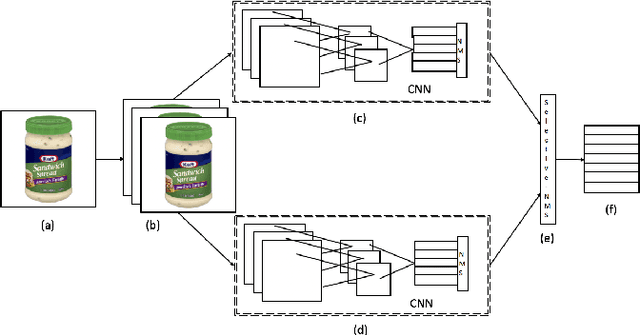
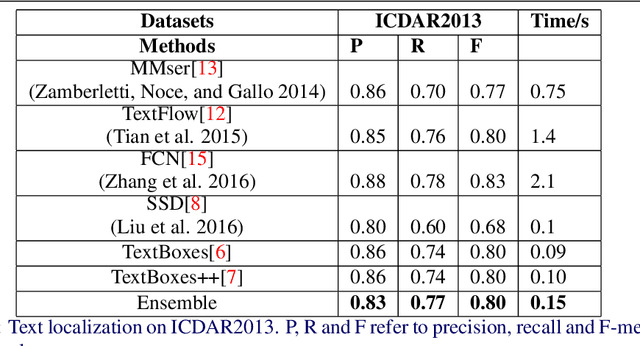

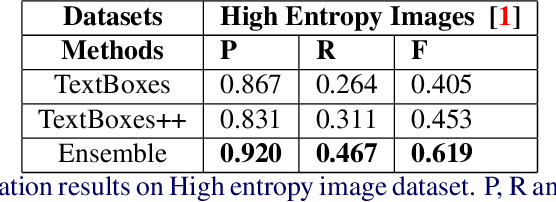
Extracting texts of various size and shape from images containing multiple objects is an important problem in many contexts, especially, in connection to e-commerce, augmented reality assistance system in natural scene, etc. The existing works (based on only CNN) often perform sub-optimally when the image contains regions of high entropy having multiple objects. This paper presents an end-to-end text detection strategy combining a segmentation algorithm and an ensemble of multiple text detectors of different types to detect text in every individual image segments independently. The proposed strategy involves a super-pixel based image segmenter which splits an image into multiple regions. A convolutional deep neural architecture is developed which works on each of the segments and detects texts of multiple shapes, sizes, and structures. It outperforms the competing methods in terms of coverage in detecting texts in images especially the ones where the text of various types and sizes are compacted in a small region along with various other objects. Furthermore, the proposed text detection method along with a text recognizer outperforms the existing state-of-the-art approaches in extracting text from high entropy images. We validate the results on a dataset consisting of product images on an e-commerce website.
Compositional Convolutional Neural Networks: A Robust and Interpretable Model for Object Recognition under Occlusion
Jun 28, 2020Computer vision systems in real-world applications need to be robust to partial occlusion while also being explainable. In this work, we show that black-box deep convolutional neural networks (DCNNs) have only limited robustness to partial occlusion. We overcome these limitations by unifying DCNNs with part-based models into Compositional Convolutional Neural Networks (CompositionalNets) - an interpretable deep architecture with innate robustness to partial occlusion. Specifically, we propose to replace the fully connected classification head of DCNNs with a differentiable compositional model that can be trained end-to-end. The structure of the compositional model enables CompositionalNets to decompose images into objects and context, as well as to further decompose object representations in terms of individual parts and the objects' pose. The generative nature of our compositional model enables it to localize occluders and to recognize objects based on their non-occluded parts. We conduct extensive experiments in terms of image classification and object detection on images of artificially occluded objects from the PASCAL3D+ and ImageNet dataset, and real images of partially occluded vehicles from the MS-COCO dataset. Our experiments show that CompositionalNets made from several popular DCNN backbones (VGG-16, ResNet50, ResNext) improve by a large margin over their non-compositional counterparts at classifying and detecting partially occluded objects. Furthermore, they can localize occluders accurately despite being trained with class-level supervision only. Finally, we demonstrate that CompositionalNets provide human interpretable predictions as their individual components can be understood as detecting parts and estimating an objects' viewpoint.
Hindi Visual Genome: A Dataset for Multimodal English-to-Hindi Machine Translation
Jul 21, 2019
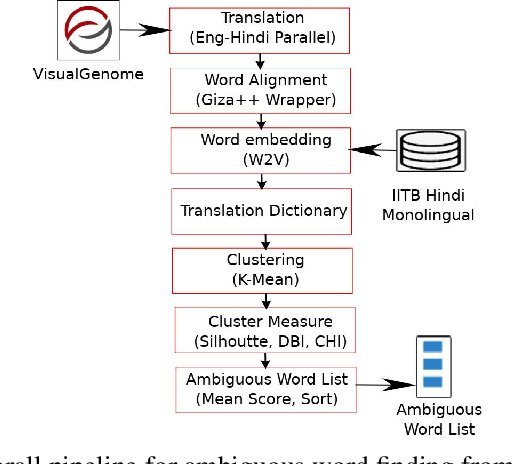
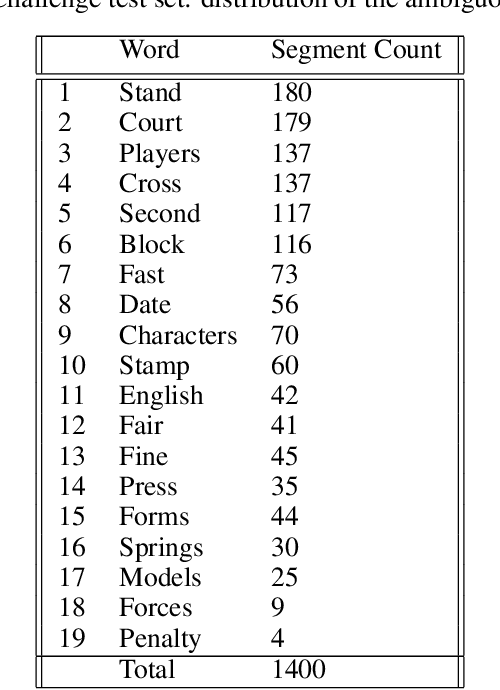

Visual Genome is a dataset connecting structured image information with English language. We present ``Hindi Visual Genome'', a multimodal dataset consisting of text and images suitable for English-Hindi multimodal machine translation task and multimodal research. We have selected short English segments (captions) from Visual Genome along with associated images and automatically translated them to Hindi with manual post-editing which took the associated images into account. We prepared a set of 31525 segments, accompanied by a challenge test set of 1400 segments. This challenge test set was created by searching for (particularly) ambiguous English words based on the embedding similarity and manually selecting those where the image helps to resolve the ambiguity. Our dataset is the first for multimodal English-Hindi machine translation, freely available for non-commercial research purposes. Our Hindi version of Visual Genome also allows to create Hindi image labelers or other practical tools. Hindi Visual Genome also serves in Workshop on Asian Translation (WAT) 2019 Multi-Modal Translation Task.
Lung nodule segmentation via level set machine learning
Oct 08, 2019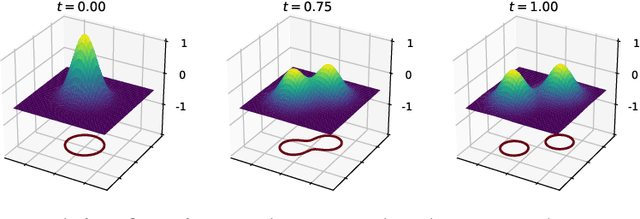
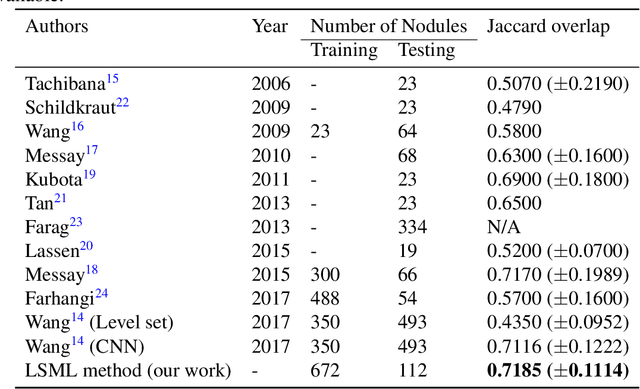
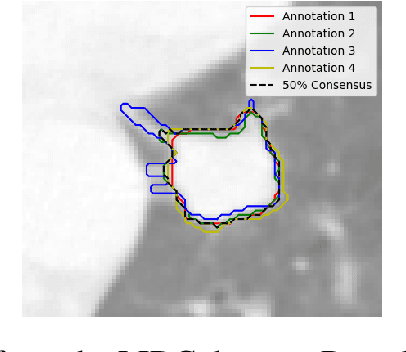

Lung cancer has the highest mortality rate of all cancers in both men and women. The algorithmic detection, characterization, and diagnosis of abnormalities found in chest CT scan images can potentially aid radiologists by providing additional medical information to consider in their assessment. Lung nodule segmentation, i.e., the algorithmic delineation of the lung nodule surface, is a fundamental component of an automated nodule analysis pipeline. We introduce an extension of the vanilla level set image segmentation method where the velocity function is learned from data via machine learning regression methods, rather than manually designed. This mitigates the tedious design process of the velocity term from the standard method. We apply the method to image volumes of lung nodules from CT scans in the publicly available LIDC dataset, obtaining an average intersection over union score of 0.7185($\pm$0.1114).
Fetal Head and Abdomen Measurement Using Convolutional Neural Network, Hough Transform, and Difference of Gaussian Revolved along Elliptical Path (Dogell) Algorithm
Nov 14, 2019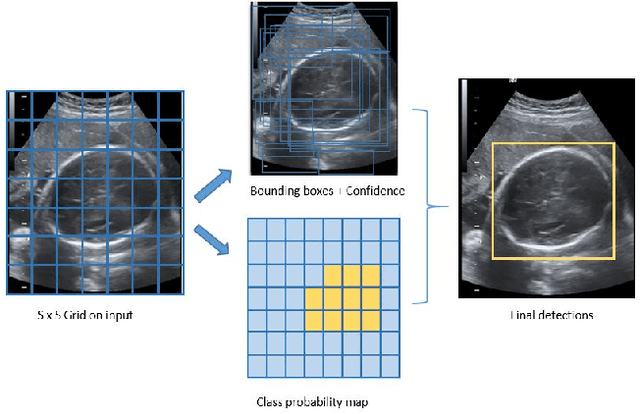
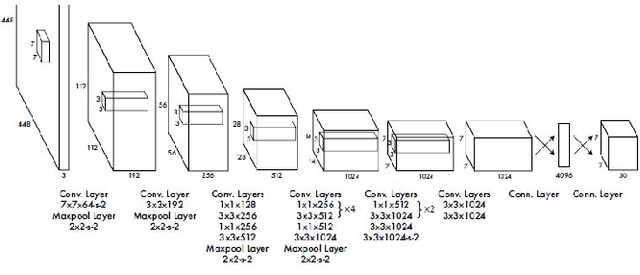

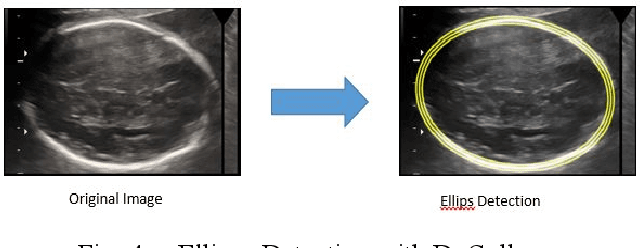
The number of fetal-neonatal death in Indonesia is still high compared to developed countries. This is caused by the absence of maternal monitoring during pregnancy. This paper presents an automated measurement for fetal head circumference (HC) and abdominal circumference (AC) from the ultrasonography (USG) image. This automated measurement is beneficial to detect early fetal abnormalities during the pregnancy period. We used the convolutional neural network (CNN) method, to preprocess the USG data. After that, we approximate the head and abdominal circumference using the Hough transform algorithm and the difference of Gaussian Revolved along Elliptical Path (Dogell) Algorithm. We used the data set from national hospitals in Indonesia and for the accuracy measurement, we compared our results to the annotated images measured by professional obstetricians. The result shows that by using CNN, we reduced errors caused by a noisy image. We found that the Dogell algorithm performs better than the Hough transform algorithm in both time and accuracy. This is the first HC and AC approximation that used the CNN method to preprocess the data.
StickyPillars: Robust feature matching on point clouds using Graph Neural Networks
Feb 10, 2020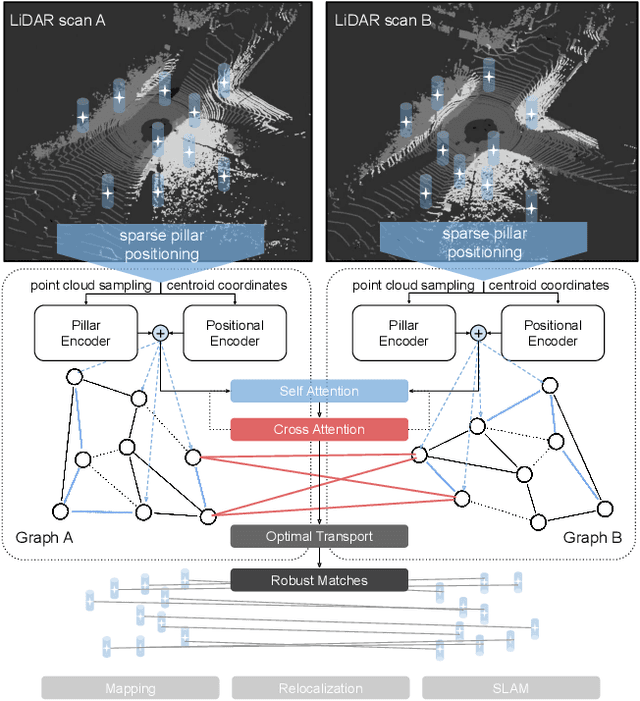
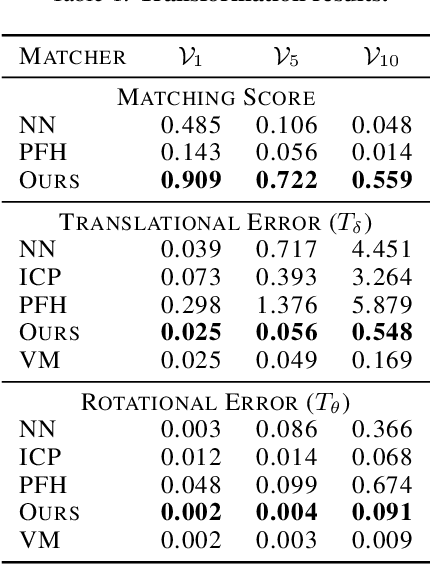
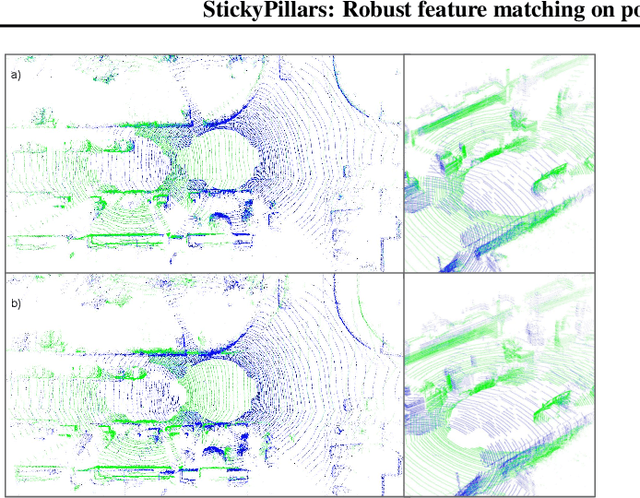
StickyPillars introduces a sparse feature matching method on point clouds. It is the first approach applying Graph Neural Networks on point clouds to stick points of interest. The feature estimation and assignment relies on the optimal transport problem, where the cost is based on the neural network itself. We utilize a Graph Neural Network for context aggregation with the aid of multihead self and cross attention. In contrast to image based feature matching methods, the architecture learns feature extraction in an end-to-end manner. Hence, the approach does not rely on handcrafted features. Our method outperforms state-of-the art matching algorithms, while providing real-time capability.
Detecting cutaneous basal cell carcinomas in ultra-high resolution and weakly labelled histopathological images
Nov 14, 2019

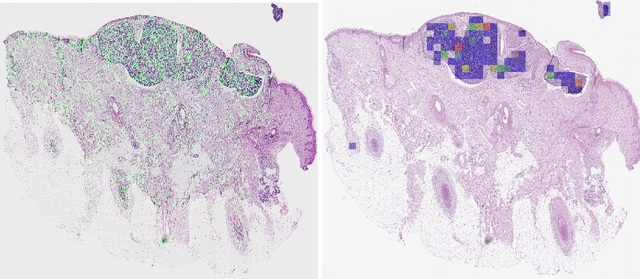
Diagnosing basal cell carcinomas (BCC), one of the most common cutaneous malignancies in humans, is a task regularly performed by pathologists and dermato-pathologists. Improving histological diagnosis by providing diagnosis suggestions, i.e. computer-assisted diagnoses is actively researched to improve safety, quality and efficiency. Increasingly, machine learning methods are applied due to their superior performance. However, typical images obtained by scanning histological sections often have a resolution that is prohibitive for processing with current state-of-the-art neural networks. Furthermore, the data pose a problem of weak labels, since only a tiny fraction of the image is indicative of the disease class, whereas a large fraction of the image is highly similar to the non-disease class. The aim of this study is to evaluate whether it is possible to detect basal cell carcinomas in histological sections using attention-based deep learning models and to overcome the ultra-high resolution and the weak labels of whole slide images. We demonstrate that attention-based models can indeed yield almost perfect classification performance with an AUC of 0.95.
Adversarial Deepfakes: Evaluating Vulnerability of Deepfake Detectors to Adversarial Examples
Mar 14, 2020
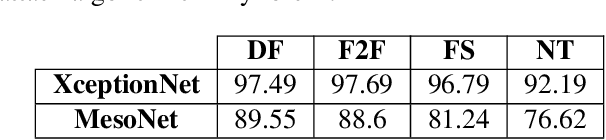
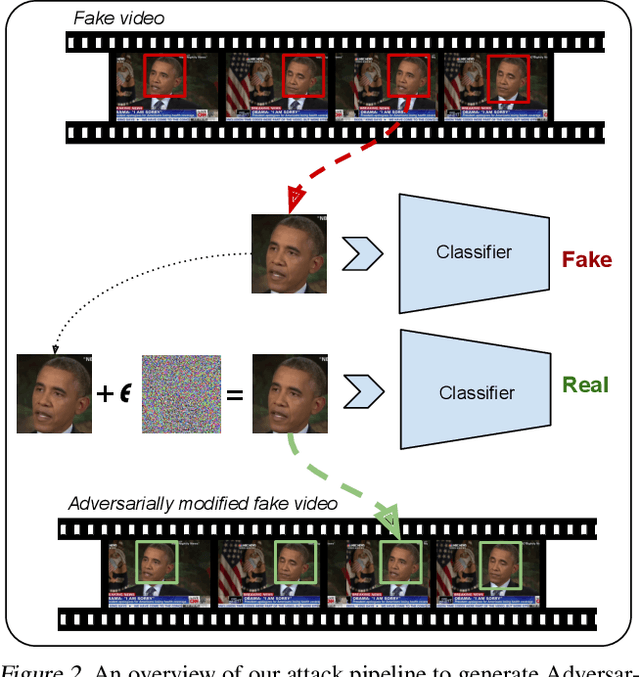
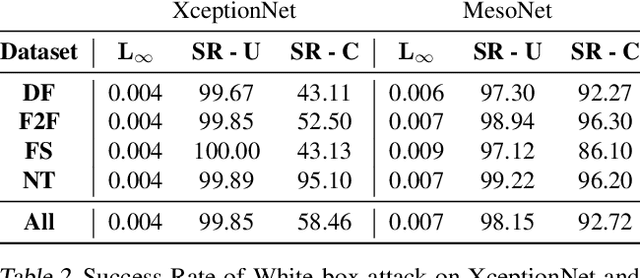
Recent advances in video manipulation techniques have made the generation of fake videos more accessible than ever before. Manipulated videos can fuel disinformation and reduce trust in media. Therefore detection of fake videos has garnered immense interest in academia and industry. Recently developed Deepfake detection methods rely on deep neural networks (DNNs) to distinguish AI-generated fake videos from real videos. In this work, we demonstrate that it is possible to bypass such detectors by adversarially modifying fake videos synthesized using existing Deepfake generation methods. We further demonstrate that our adversarial perturbations are robust to image and video compression codecs, making them a real-world threat. We present pipelines in both white-box and black-box attack scenarios that can fool DNN based Deepfake detectors into classifying fake videos as real.