 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Detecting cutaneous basal cell carcinomas in ultra-high resolution and weakly labelled histopathological images
Dec 02, 2019


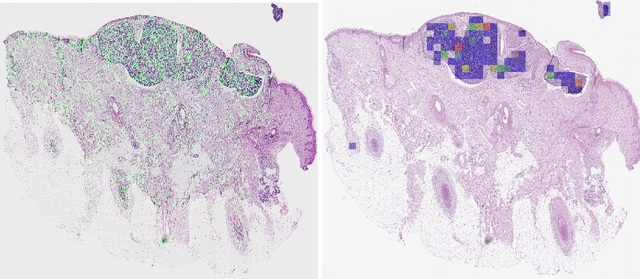
Diagnosing basal cell carcinomas (BCC), one of the most common cutaneous malignancies in humans, is a task regularly performed by pathologists and dermato-pathologists. Improving histological diagnosis by providing diagnosis suggestions, i.e. computer-assisted diagnoses is actively researched to improve safety, quality and efficiency. Increasingly, machine learning methods are applied due to their superior performance. However, typical images obtained by scanning histological sections often have a resolution that is prohibitive for processing with current state-of-the-art neural networks. Furthermore, the data pose a problem of weak labels, since only a tiny fraction of the image is indicative of the disease class, whereas a large fraction of the image is highly similar to the non-disease class. The aim of this study is to evaluate whether it is possible to detect basal cell carcinomas in histological sections using attention-based deep learning models and to overcome the ultra-high resolution and the weak labels of whole slide images. We demonstrate that attention-based models can indeed yield almost perfect classification performance with an AUC of 0.99.
CorNet: Generic 3D Corners for 6D Pose Estimation of New Objects without Retraining
Aug 29, 2019
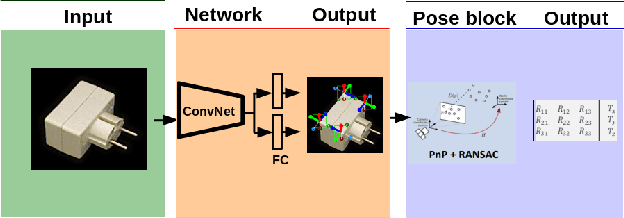
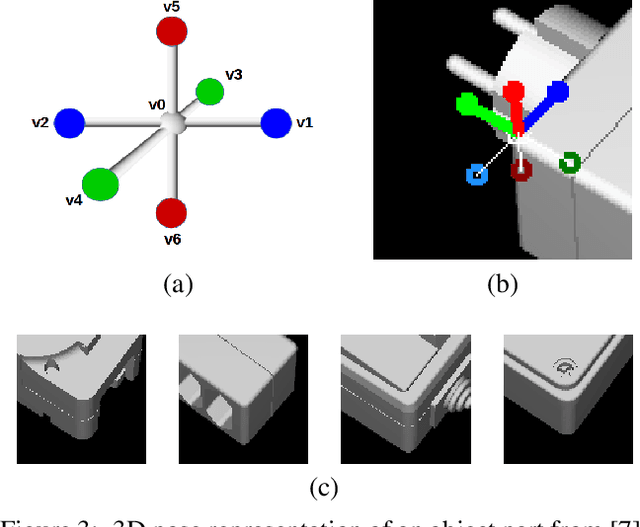
We present a novel approach to the detection and 3D pose estimation of objects in color images. Its main contribution is that it does not require any training phases nor data for new objects, while state-of-the-art methods typically require hours of training time and hundreds of training registered images. Instead, our method relies only on the objects' geometries. Our method focuses on objects with prominent corners, which covers a large number of industrial objects. We first learn to detect object corners of various shapes in images and also to predict their 3D poses, by using training images of a small set of objects. To detect a new object in a given image, we first identify its corners from its CAD model; we also detect the corners visible in the image and predict their 3D poses. We then introduce a RANSAC-like algorithm that robustly and efficiently detects and estimates the object's 3D pose by matching its corners on the CAD model with their detected counterparts in the image. Because we also estimate the 3D poses of the corners in the image, detecting only 1 or 2 corners is sufficient to estimate the pose of the object, which makes the approach robust to occlusions. We finally rely on a final check that exploits the full 3D geometry of the objects, in case multiple objects have the same corner spatial arrangement. The advantages of our approach make it particularly attractive for industrial contexts, and we demonstrate our approach on the challenging T-LESS dataset.
Generative Adversarial Networks: A Survey and Taxonomy
Jun 14, 2019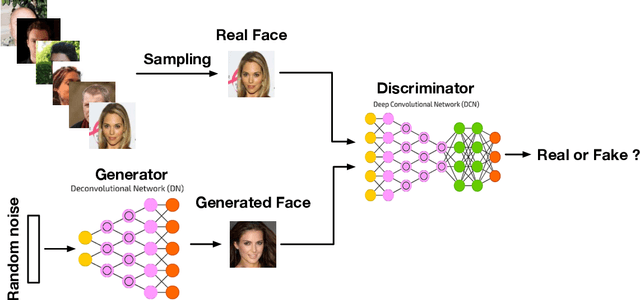
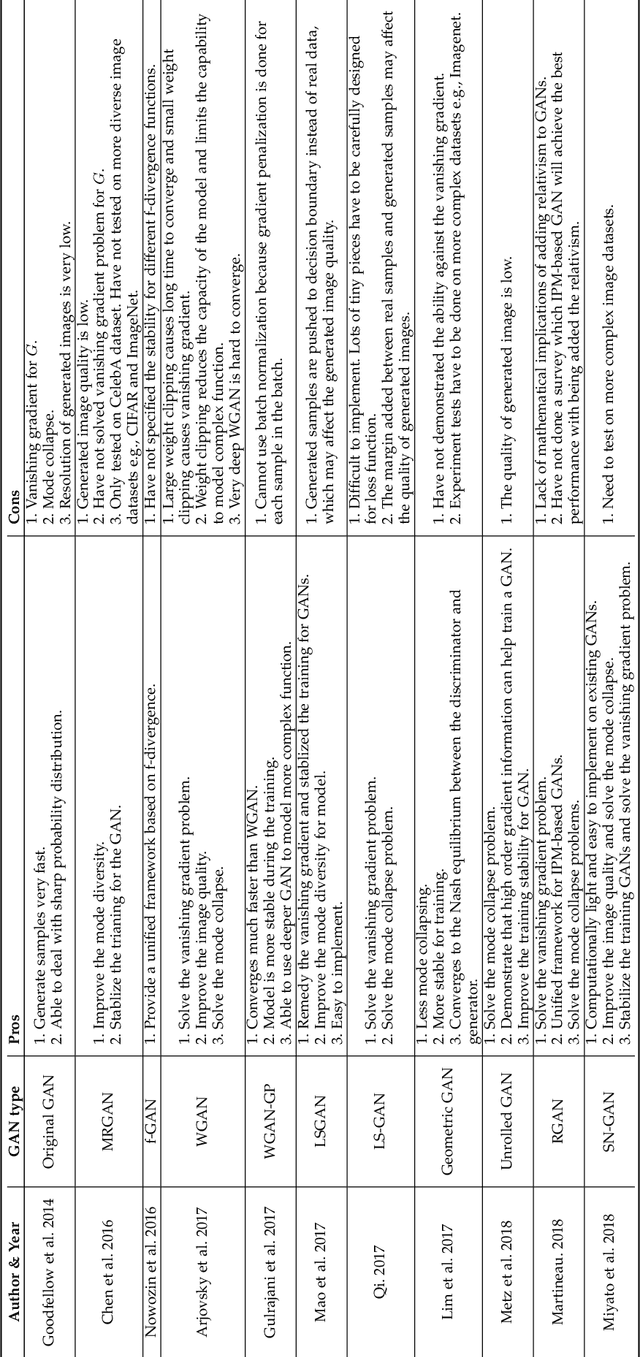
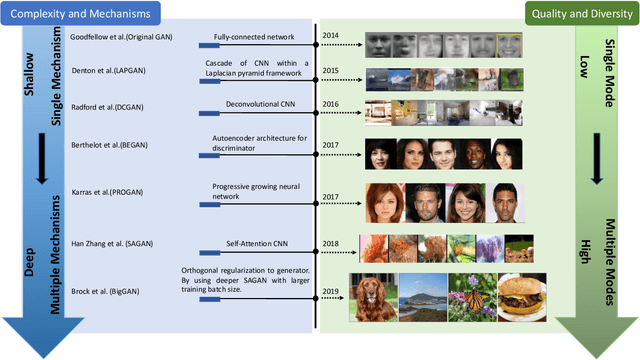
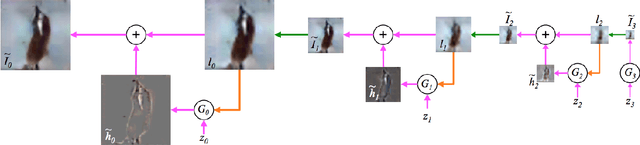
Generative adversarial networks (GANs) have been extensively studied in the past few years. Arguably the revolutionary techniques are in the area of computer vision such as plausible image generation, image to image translation, facial attribute manipulation and similar domains. Despite the significant success achieved in the computer vision field, applying GANs to real-world problems still poses significant challenges, three of which we focus on here: (1) High quality image generation; (2) Diverse image generation; and (3) Stable training. Through an in-depth review of GAN-related research in the literature, we provide an account of the architecture-variants and loss-variants, which have been proposed to handle these three challenges from two perspectives. We propose loss-variants and architecture-variants for classifying the most popular GANs, and discuss the potential improvements with focusing on these two aspects. While several reviews for GANs have been presented to date, none have focused on the review of GAN-variants based on their handling the challenges mentioned above. In this paper, we review and critically discuss 7 architecture-variant GANs and 9 loss-variant GANs for remedying those three challenges. The objective of this review is to provide an insight on the footprint that current GANs research focuses on the performance improvement. Code related to GAN-variants studied in this work is summarized on https://github.com/sheqi/GAN_Review.
Large scale near-duplicate image retrieval using Triples of Adjacent Ranked Features (TARF) with embedded geometric information
Mar 19, 2016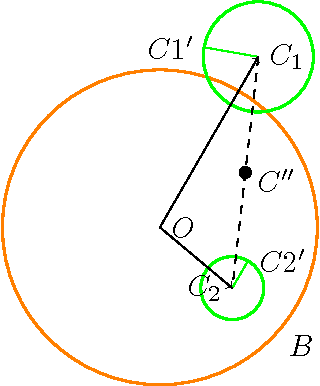
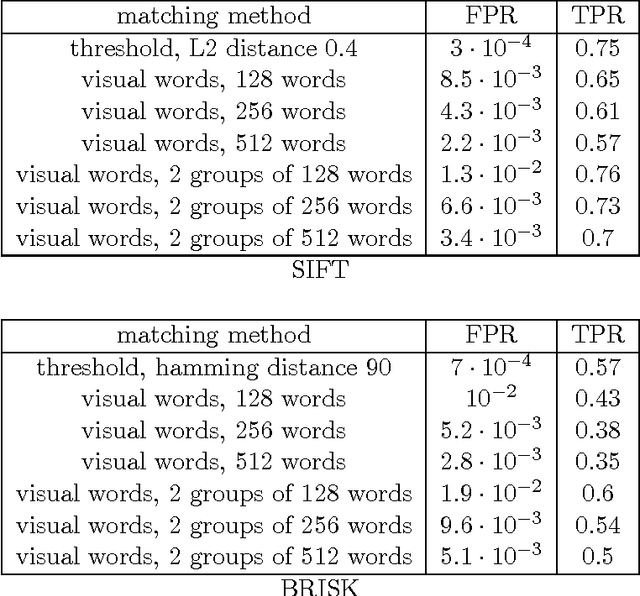

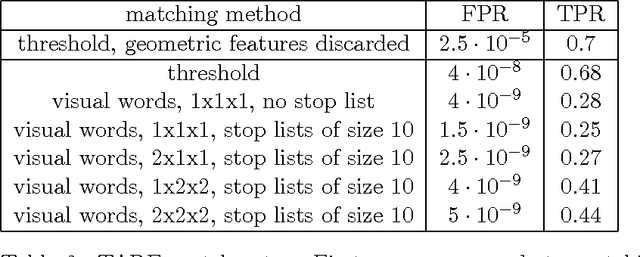
Most approaches to large-scale image retrieval are based on the construction of the inverted index of local image descriptors or visual words. A search in such an index usually results in a large number of candidates. This list of candidates is then re-ranked with the help of a geometric verification, using a RANSAC algorithm, for example. In this paper we propose a feature representation, which is built as a combination of three local descriptors. It allows one to significantly decrease the number of false matches and to shorten the list of candidates after the initial search in the inverted index. This combination of local descriptors is both reproducible and highly discriminative, and thus can be efficiently used for large-scale near-duplicate image retrieval.
NeurIPS 2019 Disentanglement Challenge: Improved Disentanglement through Learned Aggregation of Convolutional Feature Maps
Feb 27, 2020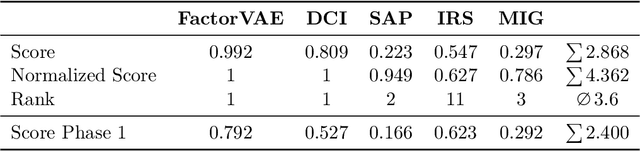
This report to our stage 2 submission to the NeurIPS 2019 disentanglement challenge presents a simple image preprocessing method for learning disentangled latent factors. We propose to train a variational autoencoder on regionally aggregated feature maps obtained from networks pretrained on the ImageNet database, utilizing the implicit inductive bias contained in those features for disentanglement. This bias can be further enhanced by explicitly fine-tuning the feature maps on auxiliary tasks useful for the challenge, such as angle, position estimation, or color classification. Our approach achieved the 2nd place in stage 2 of the challenge. Code is available at https://github.com/mseitzer/neurips2019-disentanglement-challenge.
Human Extraction and Scene Transition utilizing Mask R-CNN
Jul 20, 2019
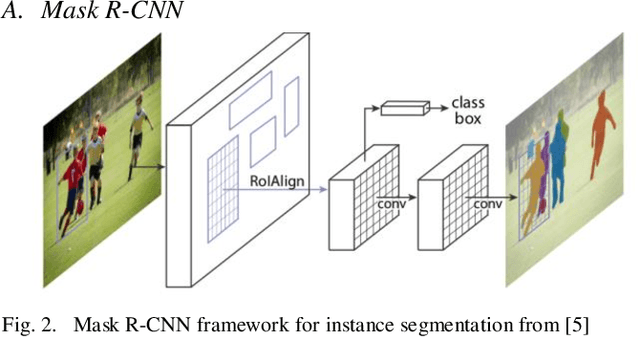

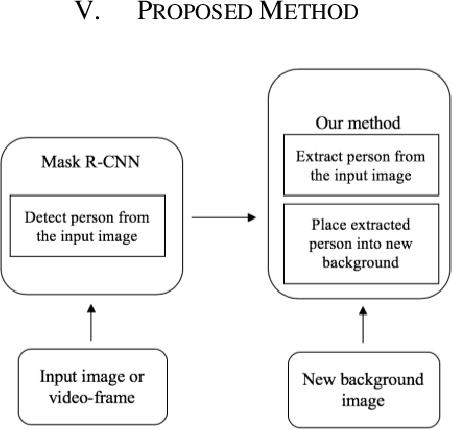
Object detection is a trendy branch of computer vision, especially on human recognition and pedestrian detection. Recognizing the complete body of a person has always been a difficult problem. Over the years, researchers proposed various methods, and recently, a breakthrough came into the light as Mask R-CNN. Based on Faster R-CNN, Mask R-CNN was able to generate a segmentation mask for each instance. We propose an application to extract multiple persons and put them into a new background image utilizing Mask R-CNN. Mask R-CNN detects all type of object mask from images. Then our algorithm considers only the target person and extracts a person only without obstacles, such as dogs in front of the person, and the user also can select multiple persons as their expectations. Our algorithm is effective for both an image and a video irrespective of the length of it. Also, extract those persons and place them into the new background. Our algorithm does not add any overhead to Mask R-CNN, running at 5 fps. We show examples of yoga-person in an image and a dancer in a dance-video frame. We hope our simple and effective approach would serve as a baseline for replacing the image background and help ease future research.
Regularizing linear inverse problems with convolutional neural networks
Jul 06, 2019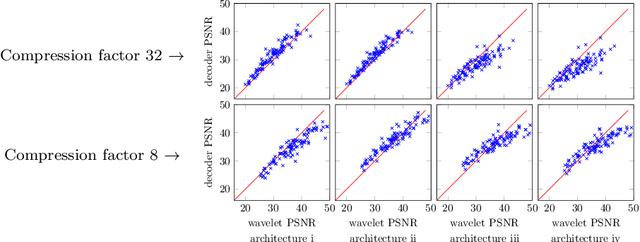
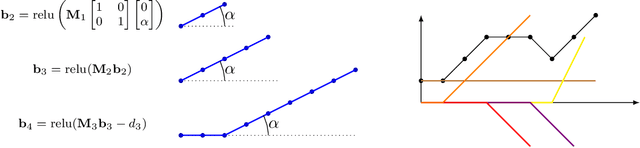

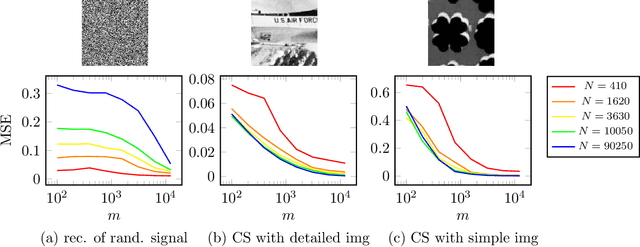
Deep convolutional neural networks trained on large datsets have emerged as an intriguing alternative for compressing images and solving inverse problems such as denoising and compressive sensing. However, it has only recently been realized that even without training, convolutional networks can function as concise image models, and thus regularize inverse problems. In this paper, we provide further evidence for this finding by studying variations of convolutional neural networks that map few weight parameters to an image. The networks we consider only consist of convolutional operations, with either fixed or parameterized filters followed by ReLU non-linearities. We demonstrate that with both fixed and parameterized convolutional filters those networks enable representing images with few coefficients. What is more, the underparameterization enables regularization of inverse problems, in particular recovering an image from few observations. We show that, similar to standard compressive sensing guarantees, on the order of the number of model parameters many measurements suffice for recovering an image from compressive measurements. Finally, we demonstrate that signal recovery with a un-trained convolutional network outperforms standard l1 and total variation minimization for magnetic resonance imaging (MRI).
Increased-confidence adversarial examples for improved transferability of Counter-Forensic attacks
May 12, 2020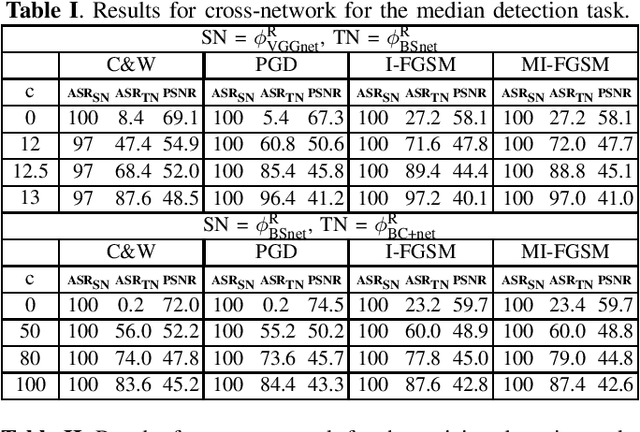
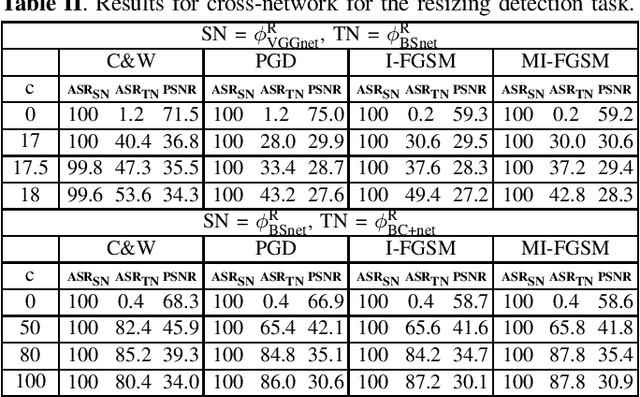
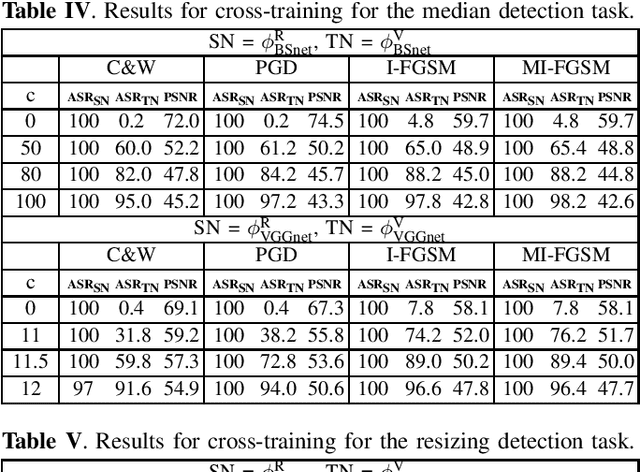
Transferability of adversarial examples is a key issue to study the security of multimedia forensics (MMF) techniques relying on Deep Learning (DL). The transferability of the attacks, in fact, would open the way to the deployment of successful counter forensics attacks also in cases where the attacker does not have a full knowledge of the to-be-attacked system. Some preliminary works have shown that adversarial examples against CNN-based image forensics detectors are in general non-transferrable, at least when the basic versions of the attacks implemented in the most popular attack packages are adopted. In this paper, we introduce a general strategy to increase the strength of the attacks and evaluate the transferability of the adversarial examples when such a strength varies. We experimentally show that, in this way, attack transferability can be improved to a large extent, at the expense of a larger distortion. Our research confirms the security threats posed by the existence of adversarial examples even in multimedia forensics scenarios, thus calling for new defense strategies to improve the security of DL-based MMF techniques.
GIFT: Learning Transformation-Invariant Dense Visual Descriptors via Group CNNs
Nov 14, 2019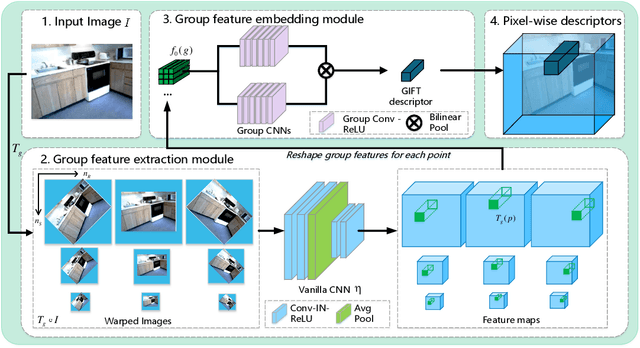
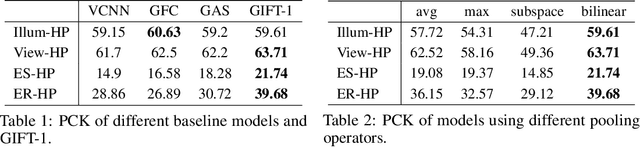
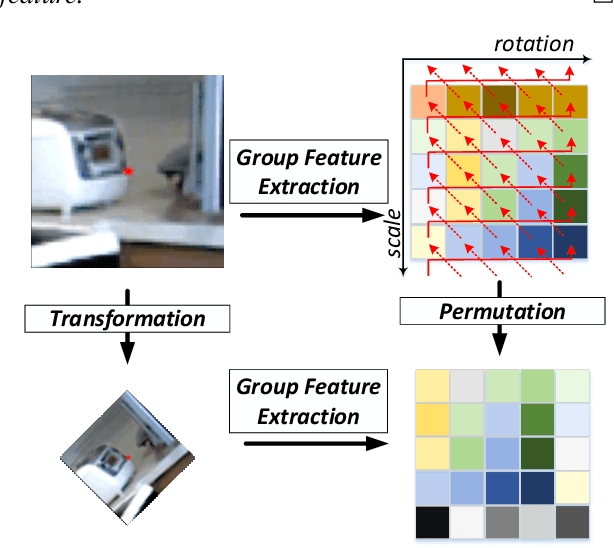

Finding local correspondences between images with different viewpoints requires local descriptors that are robust against geometric transformations. An approach for transformation invariance is to integrate out the transformations by pooling the features extracted from transformed versions of an image. However, the feature pooling may sacrifice the distinctiveness of the resulting descriptors. In this paper, we introduce a novel visual descriptor named Group Invariant Feature Transform (GIFT), which is both discriminative and robust to geometric transformations. The key idea is that the features extracted from the transformed versions of an image can be viewed as a function defined on the group of the transformations. Instead of feature pooling, we use group convolutions to exploit underlying structures of the extracted features on the group, resulting in descriptors that are both discriminative and provably invariant to the group of transformations. Extensive experiments show that GIFT outperforms state-of-the-art methods on several benchmark datasets and practically improves the performance of relative pose estimation.
Let's Transfer Transformations of Shared Semantic Representations
Mar 02, 2019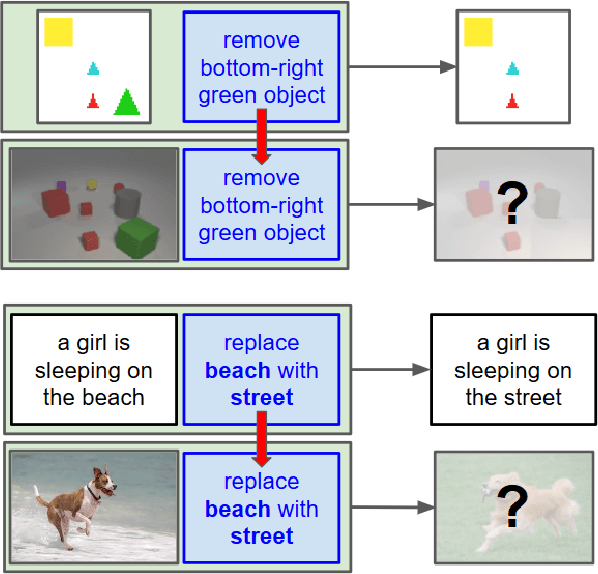

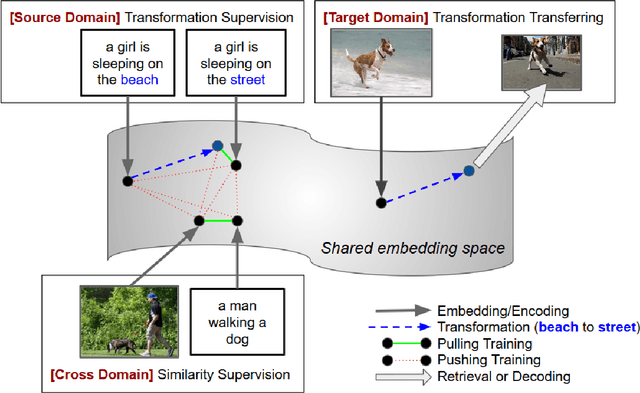

With a good image understanding capability, can we manipulate the images high level semantic representation? Such transformation operation can be used to generate or retrieve similar images but with a desired modification (for example changing beach background to street background); similar ability has been demonstrated in zero shot learning, attribute composition and attribute manipulation image search. In this work we show how one can learn transformations with no training examples by learning them on another domain and then transfer to the target domain. This is feasible if: first, transformation training data is more accessible in the other domain and second, both domains share similar semantics such that one can learn transformations in a shared embedding space. We demonstrate this on an image retrieval task where search query is an image, plus an additional transformation specification (for example: search for images similar to this one but background is a street instead of a beach). In one experiment, we transfer transformation from synthesized 2D blobs image to 3D rendered image, and in the other, we transfer from text domain to natural image domain.