 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAGE: Sequential Attribute Generator for Analyzing Glioblastomas using Limited Dataset
May 14, 2020
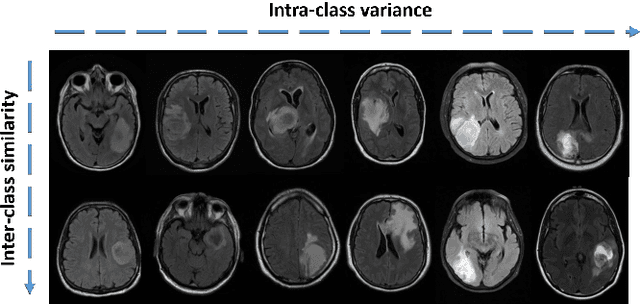
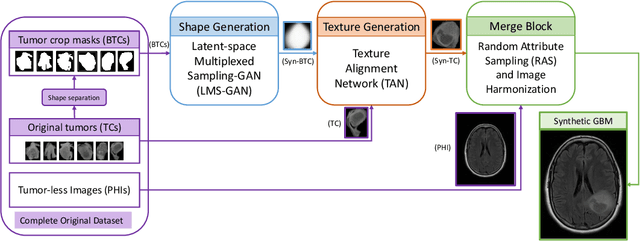
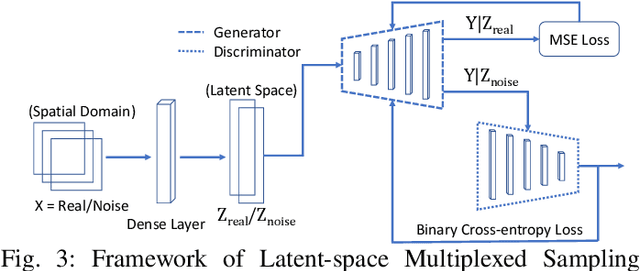
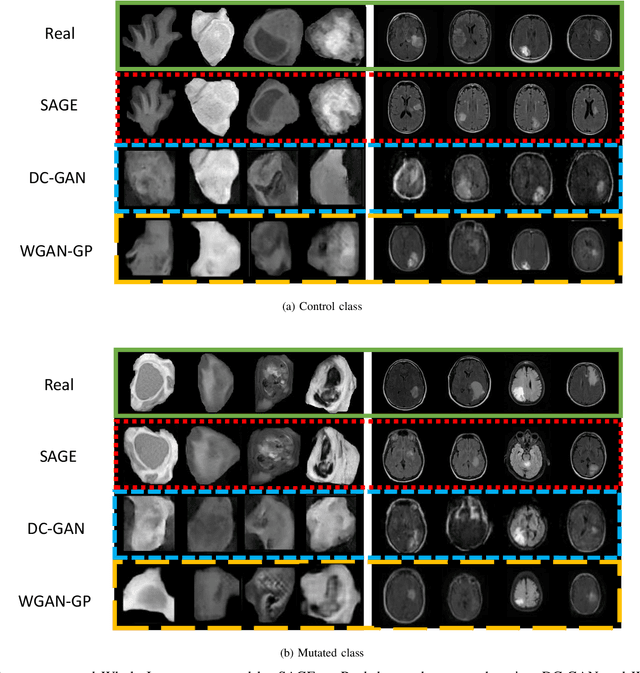
While deep learning approaches have shown remarkable performance in many imaging tasks, most of these methods rely on availability of large quantities of data. Medical image data, however, is scarce and fragmented. Generative Adversarial Networks (GANs) have recently been very effective in handling such datasets by generating more data. If the datasets are very small, however, GANs cannot learn the data distribution properly, resulting in less diverse or low-quality results. One such limited dataset is that for the concurrent gain of 19 and 20 chromosomes (19/20 co-gain), a mutation with positive prognostic value in Glioblastomas (GBM). In this paper, we detect imaging biomarkers for the mutation to streamline the extensive and invasive prognosis pipeline. Since this mutation is relatively rare, i.e. small dataset, we propose a novel generative framework - the Sequential Attribute GEnerator (SAGE), that generates detailed tumor imaging features while learning from a limited dataset. Experiments show that not only does SAGE generate high quality tumors when compared to standard Deep Convolutional GAN (DC-GAN) and Wasserstein GAN with Gradient Penalty (WGAN-GP), it also captures the imaging biomarkers accurately.
Triple Generative Adversarial Networks
Dec 20, 2019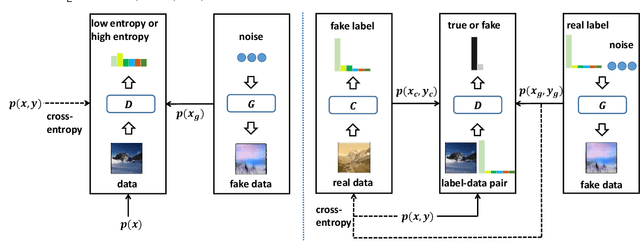
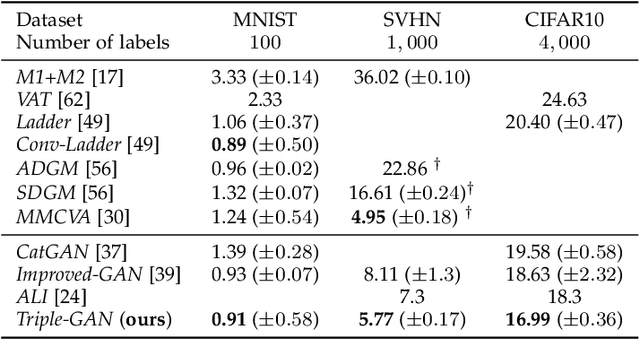

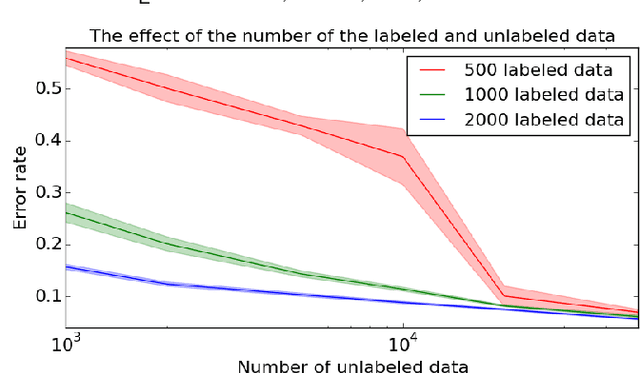
Generative adversarial networks (GANs) have shown promise in image generation and classification given limited supervision. Existing methods extend the unsupervised GAN framework to incorporate supervision heuristically. Specifically, a single discriminator plays two incompatible roles of identifying fake samples and predicting labels and it only estimates the data without considering the labels. The formulation intrinsically causes two problems: (1) the generator and the discriminator (i.e., the classifier) may not converge to the data distribution at the same time; and (2) the generator cannot control the semantics of the generated samples. In this paper, we present the triple generative adversarial network (Triple-GAN), which consists of three players---a generator, a classifier, and a discriminator. The generator and the classifier characterize the conditional distributions between images and labels, and the discriminator solely focuses on identifying fake image-label pairs. We design compatible objective functions to ensure that the distributions characterized by the generator and the classifier converge to the data distribution. We evaluate Triple-GAN in two challenging settings, namely, semi-supervised learning and the extreme low data regime. In both settings, Triple-GAN can achieve state-of-the-art classification results among deep generative models and generate meaningful samples in a specific class simultaneously.
What takes the brain so long: Object recognition at the level of minimal images develops for up to seconds of presentation time
Jun 09, 2020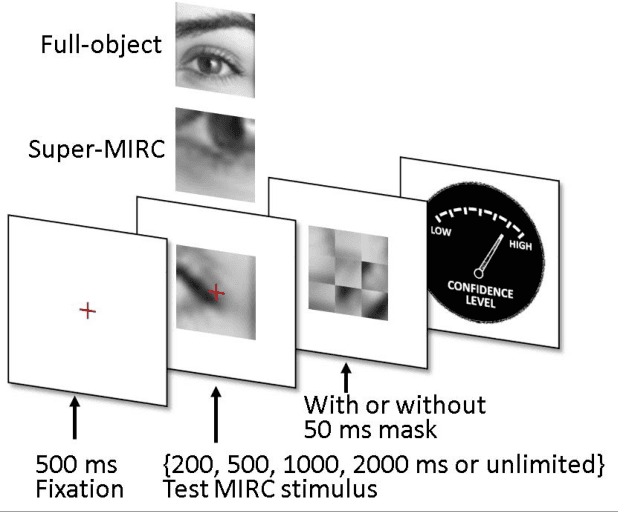
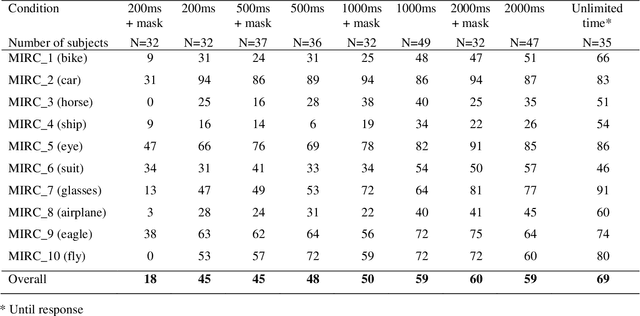
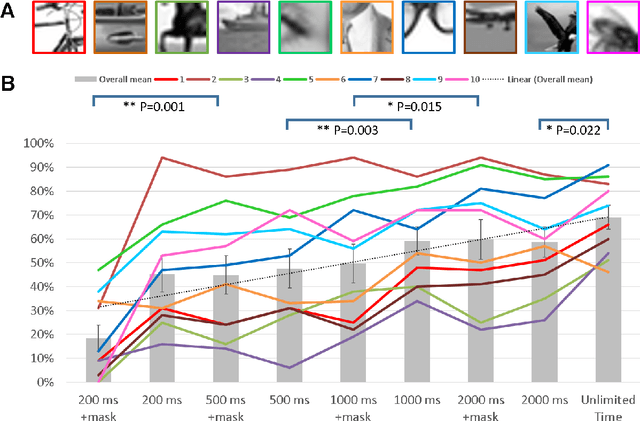
Rich empirical evidence has shown that visual object recognition in the brain is fast and effortless, with relevant brain signals reported to start as early as 80 ms. Here we study the time trajectory of the recognition process at the level of minimal recognizable images (termed MIRC). These are images that can be recognized reliably, but in which a minute change of the image (reduction by either size or resolution) has a drastic effect on recognition. Subjects were assigned to one of nine exposure conditions: 200, 500, 1000, 2000 ms with or without masking, as well as unlimited time. The subjects were not limited in time to respond after presentation. The results show that in the masked conditions, recognition rates develop gradually over an extended period, e.g. average of 18% for 200 ms exposure and 45% for 500 ms, increasing significantly with longer exposure even above 2 secs. When presented for unlimited time (until response), MIRC recognition rates were equivalent to the rates of full-object images presented for 50 ms followed by masking. What takes the brain so long to recognize such images? We discuss why processes involving eye-movements, perceptual decision-making and pattern completion are unlikely explanations. Alternatively, we hypothesize that MIRC recognition requires an extended top-down process complementing the feed-forward phase.
A New Ratio Image Based CNN Algorithm For SAR Despeckling
Jun 10, 2019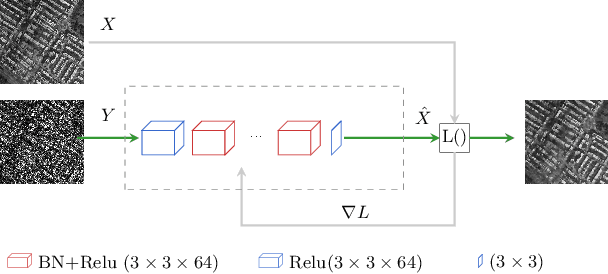
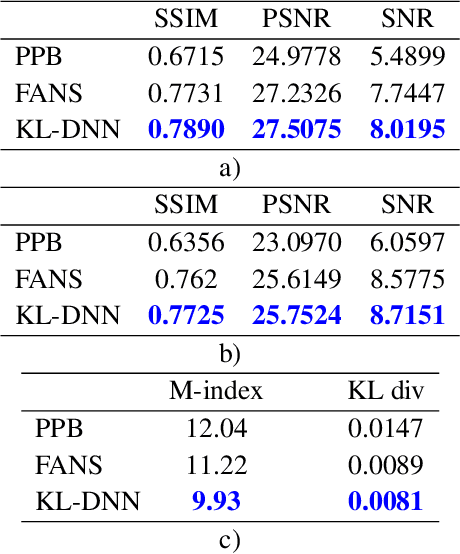


In SAR domain many application like classification, detection and segmentation are impaired by speckle. Hence, despeckling of SAR images is the key for scene understanding. Usually despeckling filters face the trade-off of speckle suppression and information preservation. In the last years deep learning solutions for speckle reduction have been proposed. One the biggest issue for these methods is how to train a network given the lack of a reference. In this work we proposed a convolutional neural network based solution trained on simulated data. We propose the use of a cost function taking into account both spatial and statistical properties. The aim is two fold: overcome the trade-off between speckle suppression and details suppression; find a suitable cost function for despeckling in unsupervised learning. The algorithm is validated on both real and simulated data, showing interesting performances.
Learning with Hierarchical Complement Objective
Nov 17, 2019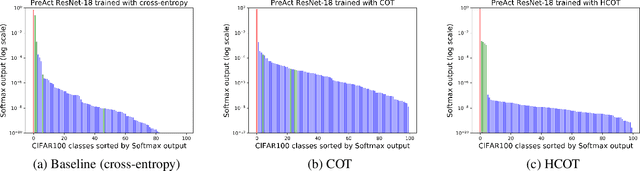
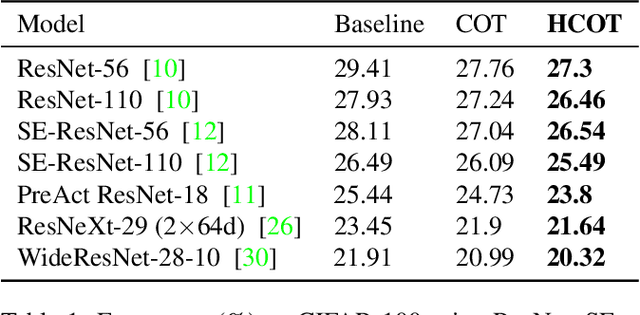
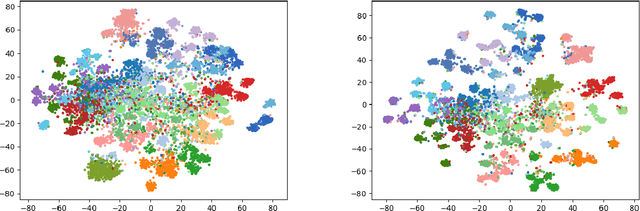
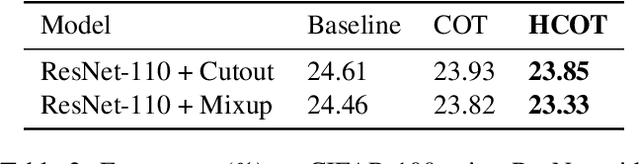
Label hierarchies widely exist in many vision-related problems, ranging from explicit label hierarchies existed in image classification to latent label hierarchies existed in semantic segmentation. Nevertheless, state-of-the-art methods often deploy cross-entropy loss that implicitly assumes class labels to be exclusive and thus independence from each other. Motivated by the fact that classes from the same parental category usually share certain similarity, we design a new training diagram called Hierarchical Complement Objective Training (HCOT) that leverages the information from label hierarchy. HCOT maximizes the probability of the ground truth class, and at the same time, neutralizes the probabilities of rest of the classes in a hierarchical fashion, making the model take advantage of the label hierarchy explicitly. The proposed HCOT is evaluated on both image classification and semantic segmentation tasks. Experimental results confirm that HCOT outperforms state-of-the-art models in CIFAR-100, ImageNet-2012, and PASCAL-Context. The study further demonstrates that HCOT can be applied on tasks with latent label hierarchies, which is a common characteristic in many machine learning tasks.
Meta-learning algorithms for Few-Shot Computer Vision
Sep 30, 2019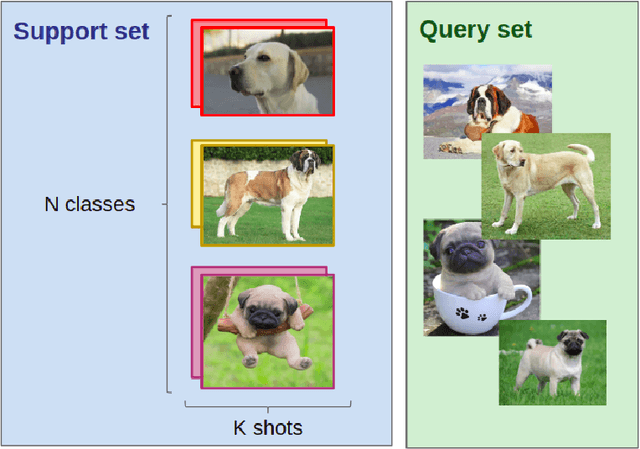
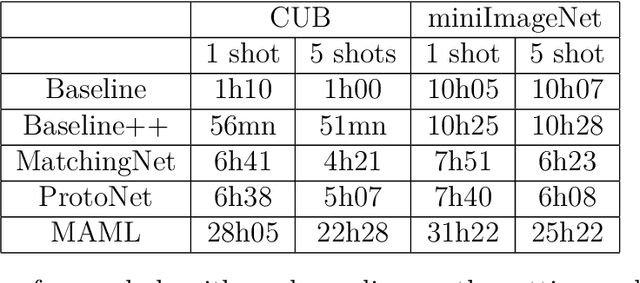
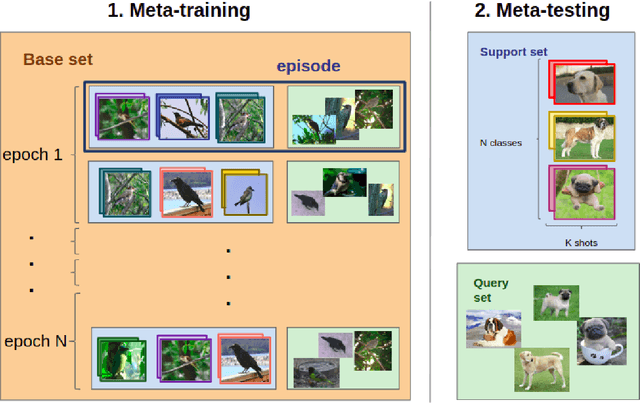
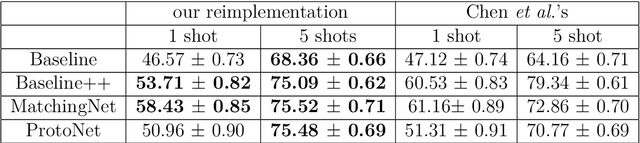
Few-Shot Learning is the challenge of training a model with only a small amount of data. Many solutions to this problem use meta-learning algorithms, i.e. algorithms that learn to learn. By sampling few-shot tasks from a larger dataset, we can teach these algorithms to solve new, unseen tasks. This document reports my work on meta-learning algorithms for Few-Shot Computer Vision. This work was done during my internship at Sicara, a French company building image recognition solutions for businesses. It contains: 1. an extensive review of the state-of-the-art in few-shot computer vision; 2. a benchmark of meta-learning algorithms for few-shot image classification; 3. the introduction to a novel meta-learning algorithm for few-shot object detection, which is still in development.
Momentum-Net: Fast and convergent iterative neural network for inverse problems
Sep 11, 2019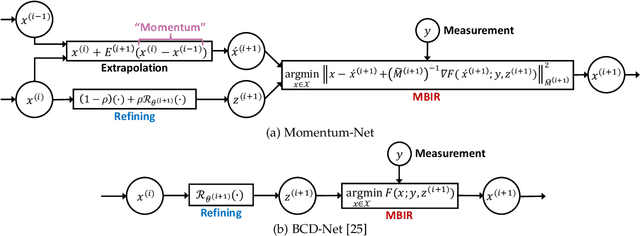
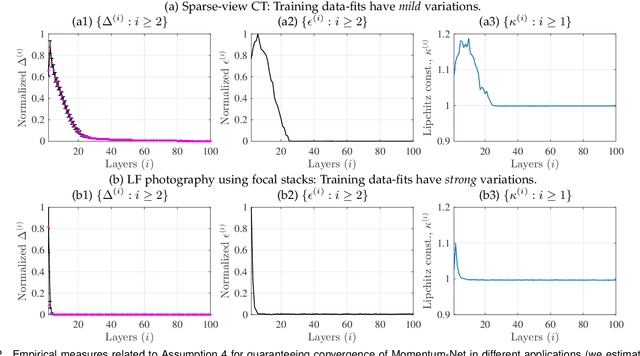
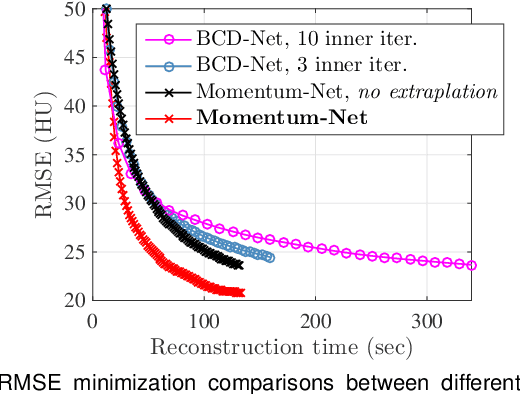
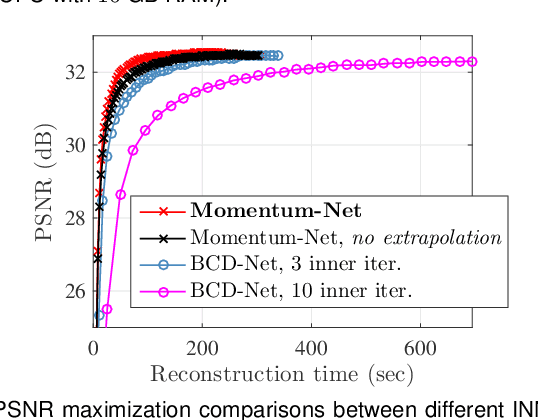
Iterative neural networks (INN) are rapidly gaining attention for solving inverse problems in imaging, image processing, and computer vision. INNs combine regression NNs and an iterative model-based image reconstruction (MBIR) algorithm, leading to both good generalization capability and outperforming reconstruction quality over existing MBIR optimization models. This paper proposes the first fast and convergent INN architecture, Momentum-Net, by generalizing a block-wise MBIR algorithm that uses momentums and majorizers with regression NNs. For fast MBIR, Momentum-Net uses momentum terms in extrapolation modules, and noniterative MBIR modules at each layer by using majorizers, where each layer of Momentum-Net consists of three core modules: image refining, extrapolation, and MBIR. Momentum-Net guarantees convergence to a fixed-point for general differentiable (non)convex MBIR functions (or data-fit terms) and convex feasible sets, under two asymptomatic conditions. To consider data-fit variations across training and testing samples, we also propose a regularization parameter selection scheme based on the spectral radius of majorization matrices. Numerical experiments for light-field photography using a focal stack and sparse-view computational tomography demonstrate that given identical regression NN architectures, Momentum-Net significantly improves MBIR speed and accuracy over several existing INNs; it significantly improves reconstruction quality compared to a state-of-the-art MBIR method in each application.
Deep-learning-based Breast CT for Radiation Dose Reduction
Sep 25, 2019
Cone-beam breast computed tomography (CT) provides true 3D breast images with isotropic resolution and high-contrast information, detecting calcifications as small as a few hundred microns and revealing subtle tissue differences. However, breast is highly sensitive to x-ray radiation. It is critically important for healthcare to reduce radiation dose. Few-view cone-beam CT only uses a fraction of x-ray projection data acquired by standard cone-beam breast CT, enabling significant reduction of the radiation dose. However, insufficient sampling data would cause severe streak artifacts in CT images reconstructed using conventional methods. In this study, we propose a deep-learning-based method to establish a residual neural network model for the image reconstruction, which is applied for few-view breast CT to produce high quality breast CT images. We respectively evaluate the deep-learning-based image reconstruction using one third and one quarter of x-ray projection views of the standard cone-beam breast CT. Based on clinical breast imaging dataset, we perform a supervised learning to train the neural network from few-view CT images to corresponding full-view CT images. Experimental results show that the deep learning-based image reconstruction method allows few-view breast CT to achieve a radiation dose <6 mGy per cone-beam CT scan, which is a threshold set by FDA for mammographic screening.
Multi-Stage Variational Auto-Encoders for Coarse-to-Fine Image Generation
May 19, 2017
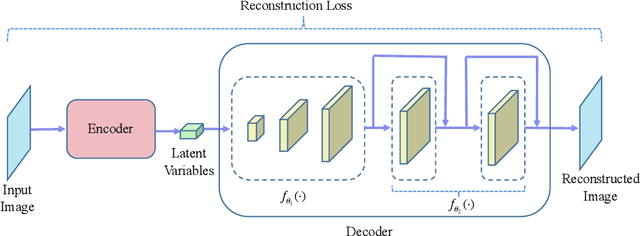
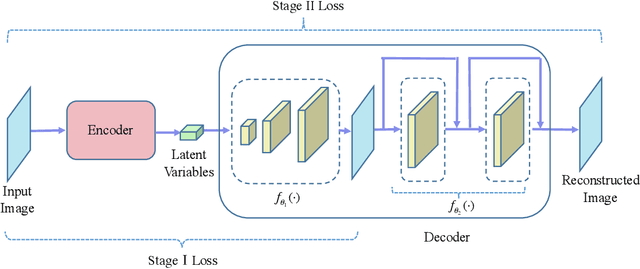

Variational auto-encoder (VAE) is a powerful unsupervised learning framework for image generation. One drawback of VAE is that it generates blurry images due to its Gaussianity assumption and thus L2 loss. To allow the generation of high quality images by VAE, we increase the capacity of decoder network by employing residual blocks and skip connections, which also enable efficient optimization. To overcome the limitation of L2 loss, we propose to generate images in a multi-stage manner from coarse to fine. In the simplest case, the proposed multi-stage VAE divides the decoder into two components in which the second component generates refined images based on the course images generated by the first component. Since the second component is independent of the VAE model, it can employ other loss functions beyond the L2 loss and different model architectures. The proposed framework can be easily generalized to contain more than two components. Experiment results on the MNIST and CelebA datasets demonstrate that the proposed multi-stage VAE can generate sharper images as compared to those from the original VAE.
Generating Adversarial Examples with an Optimized Quality
Jun 30, 2020
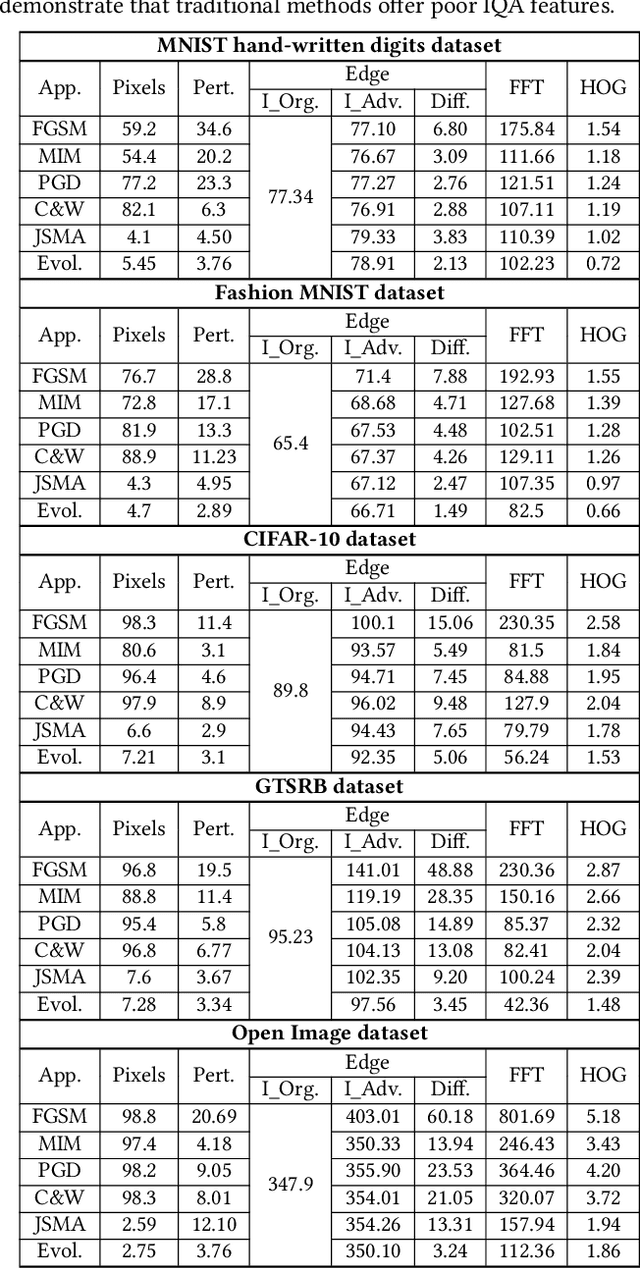
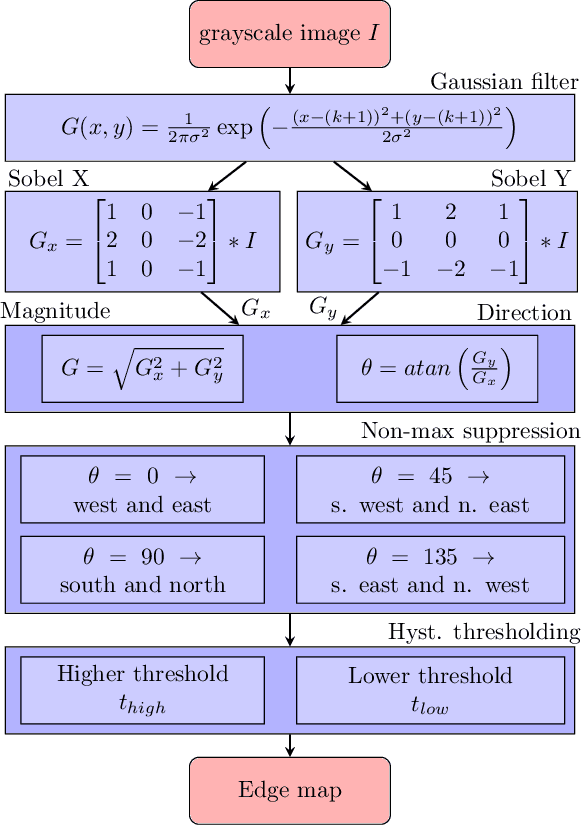
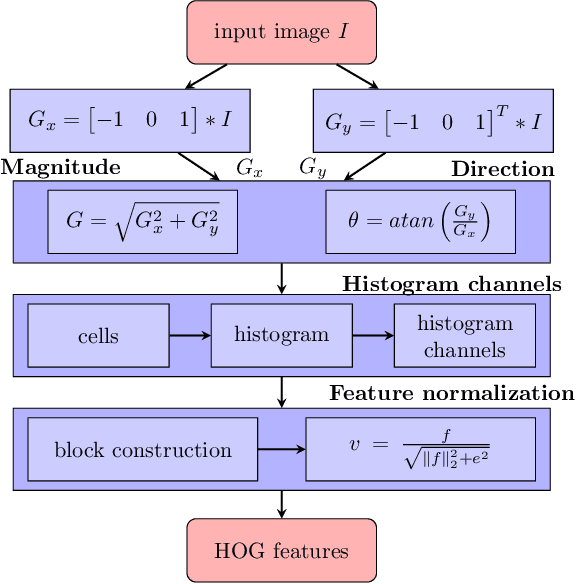
Deep learning models are widely used in a range of application areas, such as computer vision, computer security, etc. However, deep learning models are vulnerable to Adversarial Examples (AEs),carefully crafted samples to deceive those models. Recent studies have introduced new adversarial attack methods, but, to the best of our knowledge, none provided guaranteed quality for the crafted examples as part of their creation, beyond simple quality measures such as Misclassification Rate (MR). In this paper, we incorporateImage Quality Assessment (IQA) metrics into the design and generation process of AEs. We propose an evolutionary-based single- and multi-objective optimization approaches that generate AEs with high misclassification rate and explicitly improve the quality, thus indistinguishability, of the samples, while perturbing only a limited number of pixels. In particular, several IQA metrics, including edge analysis, Fourier analysis, and feature descriptors, are leveraged into the process of generating AEs. Unique characteristics of the evolutionary-based algorithm enable us to simultaneously optimize the misclassification rate and the IQA metrics of the AEs. In order to evaluate the performance of the proposed method, we conduct intensive experiments on different well-known benchmark datasets(MNIST, CIFAR, GTSRB, and Open Image Dataset V5), while considering various objective optimization configurations. The results obtained from our experiments, when compared with the exist-ing attack methods, validate our initial hypothesis that the use ofIQA metrics within generation process of AEs can substantially improve their quality, while maintaining high misclassification rate.Finally, transferability and human perception studies are provided, demonstrating acceptable performance.