 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Explanation by Progressive Exaggeration
Nov 01, 2019
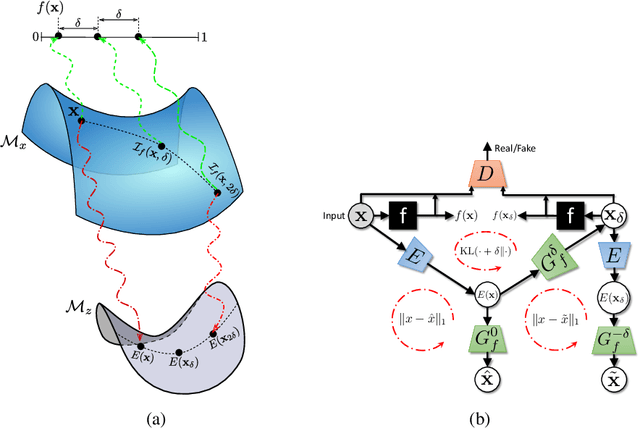

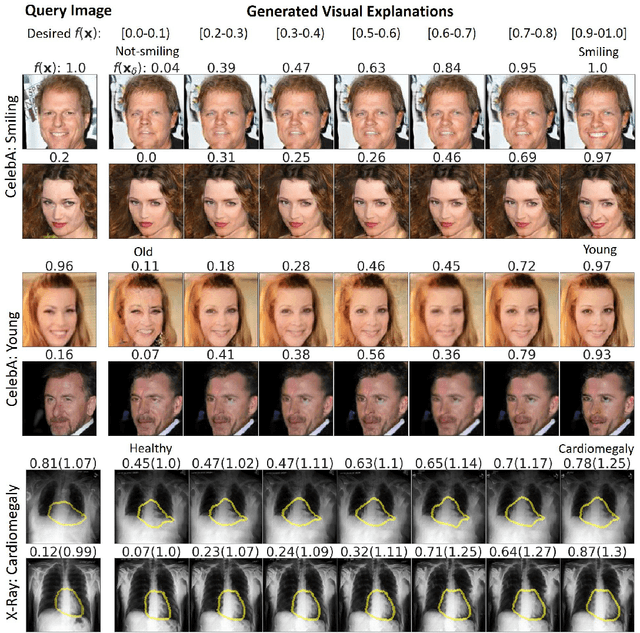

As machine learning methods see greater adoption and implementation in high stakes applications such as medical image diagnosis, the need for model interpretability and explanation has become more critical. Classical approaches that assess feature importance (\eg saliency maps) do not explain how and why a particular region of an image is relevant to the prediction. We propose a method that explains the outcome of a classification black-box by gradually exaggerating the semantic effect of a given class. Given a query input to a classifier, our method produces a progressive set of plausible variations of that query, which gradually changes the posterior probability from its original class to its negation. These counter-factually generated samples preserve features unrelated to the classification decision, such that a user can employ our method as a "tuning knob" to traverse a data manifold while crossing the decision boundary. Our method is model agnostic and only requires the output value and gradient of the predictor with respect to its input.
A Cyclically-Trained Adversarial Network for Invariant Representation Learning
Jun 21, 2019
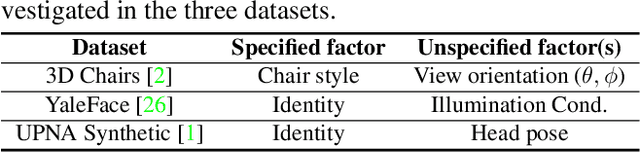
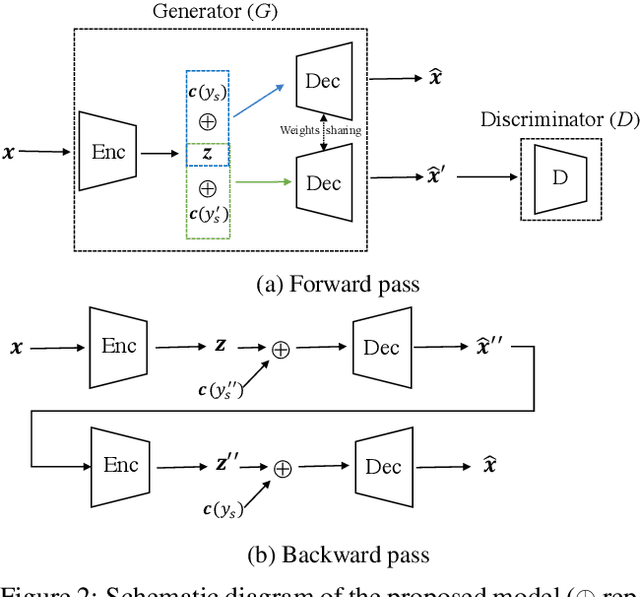
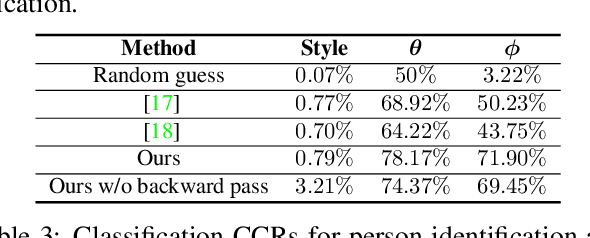
We propose a cyclically-trained adversarial network to learn mappings from image space to a latent representation space and back such that the latent representation is invariant to a specified factor of variation (e.g., identity). The learned mappings also assure that the synthesized image is not only realistic, but has the same values for unspecified factors (e.g., pose and illumination) as the original image and a desired value of the specified factor. We encourage invariance to a specified factor, by applying adversarial training using a variational autoencoder in the image space as opposed to the latent space. We strengthen this invariance by introducing a cyclic training process (forward and backward pass). We also propose a new method to evaluate conditional generative networks. It compares how well different factors of variation can be predicted from the synthesized, as opposed to real, images. We demonstrate the effectiveness of our approach on factors such as identity, pose, illumination or style on three datasets and compare it with state-of-the-art methods. Our network produces good quality synthetic images and, interestingly, can be used to perform face morphing in latent space.
Multi-Stage Variational Auto-Encoders for Coarse-to-Fine Image Generation
May 19, 2017
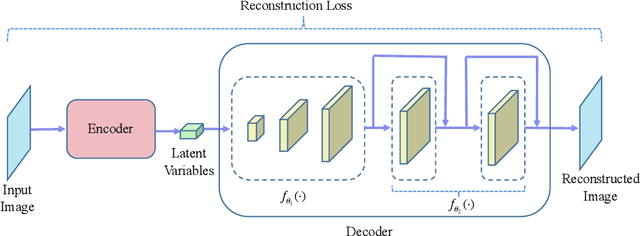
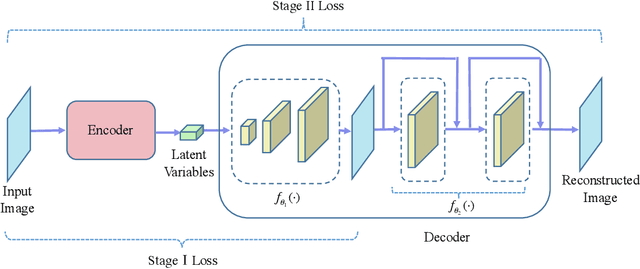

Variational auto-encoder (VAE) is a powerful unsupervised learning framework for image generation. One drawback of VAE is that it generates blurry images due to its Gaussianity assumption and thus L2 loss. To allow the generation of high quality images by VAE, we increase the capacity of decoder network by employing residual blocks and skip connections, which also enable efficient optimization. To overcome the limitation of L2 loss, we propose to generate images in a multi-stage manner from coarse to fine. In the simplest case, the proposed multi-stage VAE divides the decoder into two components in which the second component generates refined images based on the course images generated by the first component. Since the second component is independent of the VAE model, it can employ other loss functions beyond the L2 loss and different model architectures. The proposed framework can be easily generalized to contain more than two components. Experiment results on the MNIST and CelebA datasets demonstrate that the proposed multi-stage VAE can generate sharper images as compared to those from the original VAE.
ESRGAN+ : Further Improving Enhanced Super-Resolution Generative Adversarial Network
Jan 21, 2020

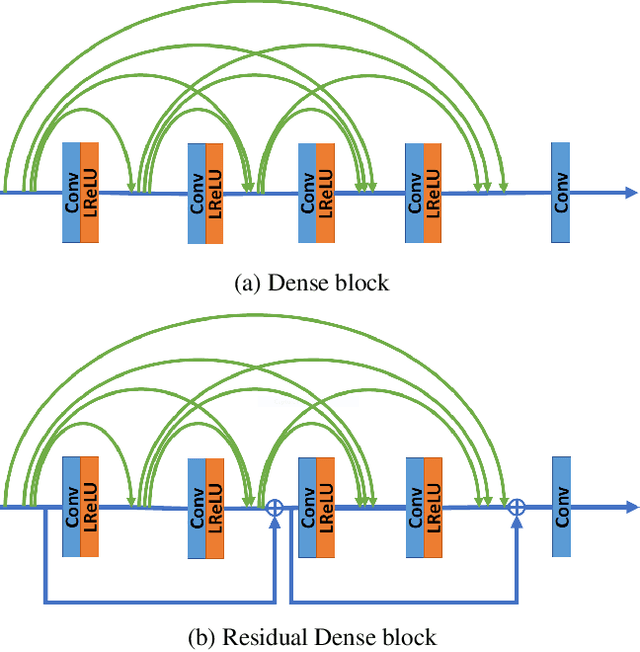
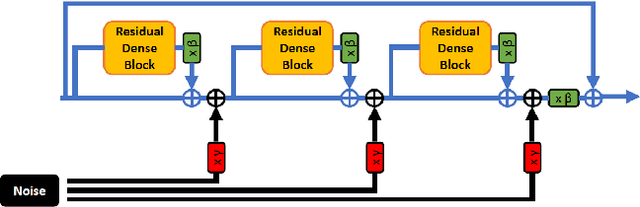
Enhanced Super-Resolution Generative Adversarial Network (ESRGAN) is a perceptual-driven approach for single image super resolution that is able to produce photorealistic images. Despite the visual quality of these generated images, there is still room for improvement. In this fashion, the model is extended to further improve the perceptual quality of the images. We have designed a novel block to replace the one used by the original ESRGAN. Moreover, we introduce noise inputs to the generator network in order to exploit stochastic variation. The resulting images present more realistic textures.
Crossmodal Voice Conversion
Apr 09, 2019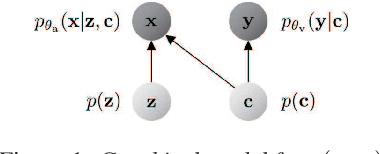
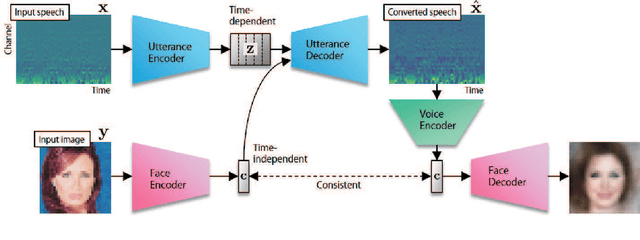
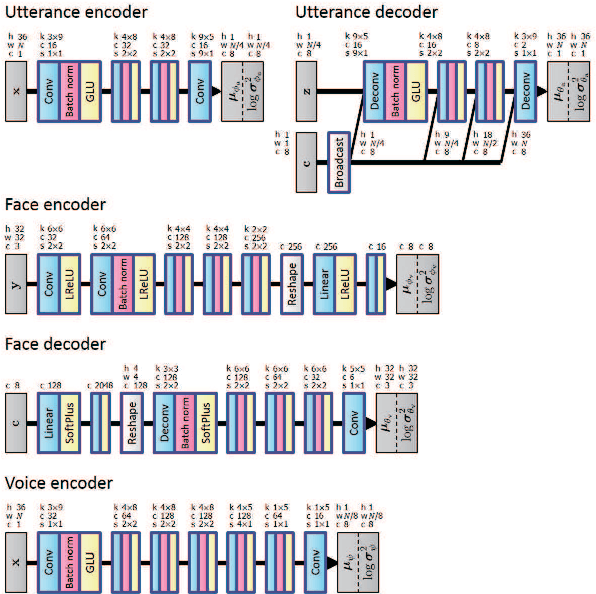
Humans are able to imagine a person's voice from the person's appearance and imagine the person's appearance from his/her voice. In this paper, we make the first attempt to develop a method that can convert speech into a voice that matches an input face image and generate a face image that matches the voice of the input speech by leveraging the correlation between faces and voices. We propose a model, consisting of a speech converter, a face encoder/decoder and a voice encoder. We use the latent code of an input face image encoded by the face encoder as the auxiliary input into the speech converter and train the speech converter so that the original latent code can be recovered from the generated speech by the voice encoder. We also train the face decoder along with the face encoder to ensure that the latent code will contain sufficient information to reconstruct the input face image. We confirmed experimentally that a speech converter trained in this way was able to convert input speech into a voice that matched an input face image and that the voice encoder and face decoder can be used to generate a face image that matches the voice of the input speech.
Inverse Renormalization Group Transformation in Bayesian Image Segmentations
Jan 05, 2015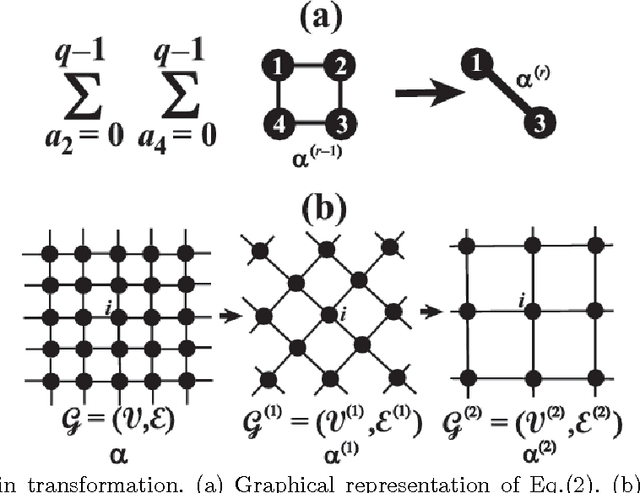

A new Bayesian image segmentation algorithm is proposed by combining a loopy belief propagation with an inverse real space renormalization group transformation to reduce the computational time. In results of our experiment, we observe that the proposed method can reduce the computational time to less than one-tenth of that taken by conventional Bayesian approaches.
* 6 pages, 2 figures
Classification of Chest Diseases using Wavelet Transforms and Transfer Learning
Feb 03, 2020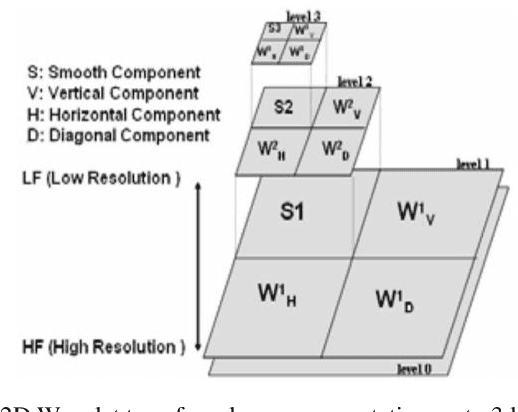

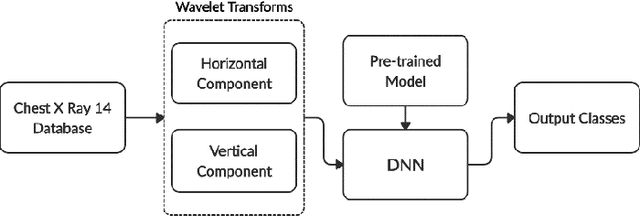
Chest X-ray scan is a most often used modality by radiologists to diagnose many chest related diseases in their initial stages. The proposed system aids the radiologists in making decision about the diseases found in the scans more efficiently. Our system combines the techniques of image processing for feature enhancement and deep learning for classification among diseases. We have used the ChestX-ray14 database in order to train our deep learning model on the 14 different labeled diseases found in it. The proposed research shows the significant improvement in the results by using wavelet transforms as pre-processing technique.
Detecting cutaneous basal cell carcinomas in ultra-high resolution and weakly labelled histopathological images
Nov 19, 2019

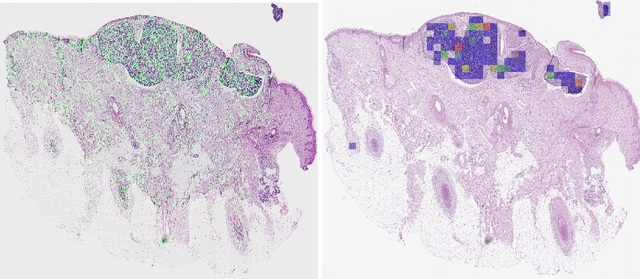
Diagnosing basal cell carcinomas (BCC), one of the most common cutaneous malignancies in humans, is a task regularly performed by pathologists and dermato-pathologists. Improving histological diagnosis by providing diagnosis suggestions, i.e. computer-assisted diagnoses is actively researched to improve safety, quality and efficiency. Increasingly, machine learning methods are applied due to their superior performance. However, typical images obtained by scanning histological sections often have a resolution that is prohibitive for processing with current state-of-the-art neural networks. Furthermore, the data pose a problem of weak labels, since only a tiny fraction of the image is indicative of the disease class, whereas a large fraction of the image is highly similar to the non-disease class. The aim of this study is to evaluate whether it is possible to detect basal cell carcinomas in histological sections using attention-based deep learning models and to overcome the ultra-high resolution and the weak labels of whole slide images. We demonstrate that attention-based models can indeed yield almost perfect classification performance with an AUC of 0.95.
Deep learning reconstruction of digital breast tomosynthesis images for accurate breast density and patient-specific radiation dose estimation
Jun 11, 2020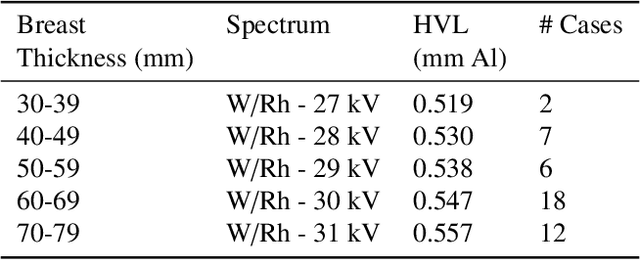


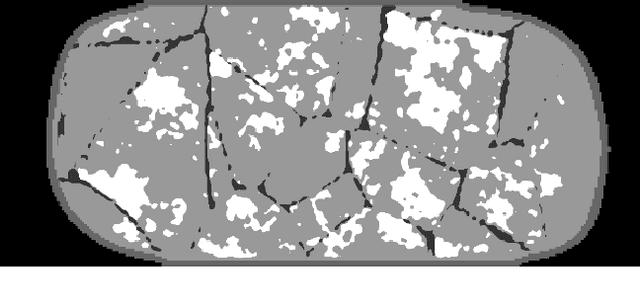
The two-dimensional nature of mammography makes estimation of the overall breast density challenging, and estimation of the true patient-specific radiation dose impossible. Digital breast tomosynthesis (DBT), a pseudo-3D technique, is now commonly used in breast cancer screening and diagnostics. Still, the severely limited 3rd dimension information in DBT has not been used, until now, to estimate the true breast density or the patient-specific dose. In this study, we propose a reconstruction algorithm for DBT based on deep learning specifically optimized for these tasks. The algorithm, which we name DBToR, is based on unrolling a proximal primal-dual optimization method, where the proximal operators are replaced with convolutional neural networks and prior knowledge is included in the model. This extends previous work on a deep learning based reconstruction model by providing both the primal and the dual blocks with breast thickness information, which is available in DBT. Training and testing of the model were performed using virtual patient phantoms from two different sources. Reconstruction performance, as well as accuracy in estimation of breast density and radiation dose, was estimated, showing high accuracy (density density < +/-3%; dose < +/-20%), without bias, significantly improving on the current state-of-the-art. This work also lays the groundwork for developing a deep learning-based reconstruction algorithm for the task of image interpretation by radiologists.
Discrete Laplace Operator Estimation for Dynamic 3D Reconstruction
Aug 29, 2019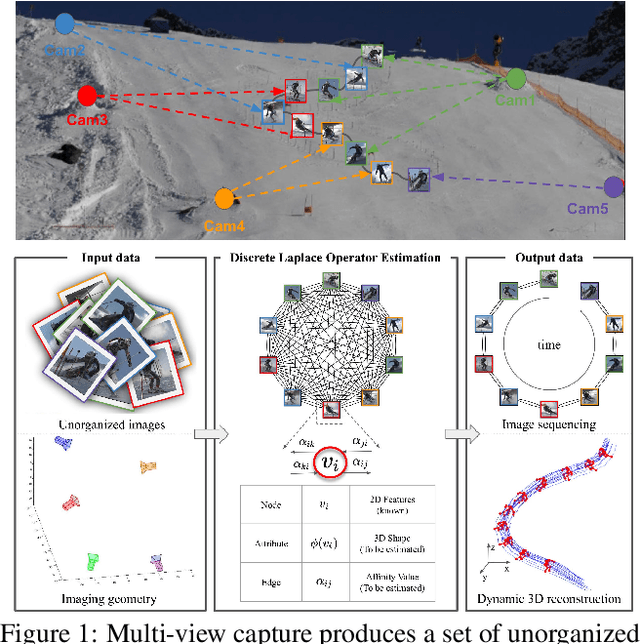
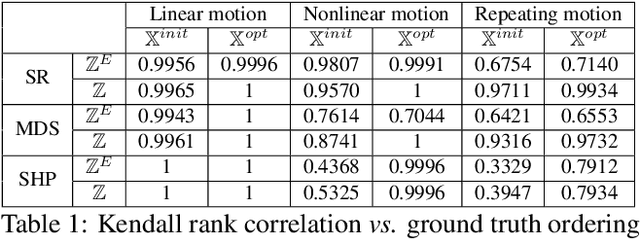
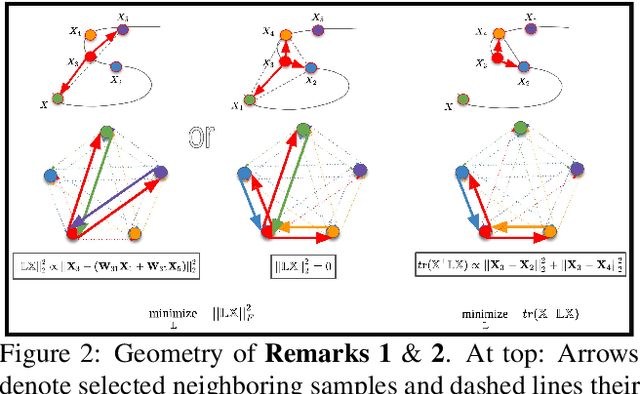
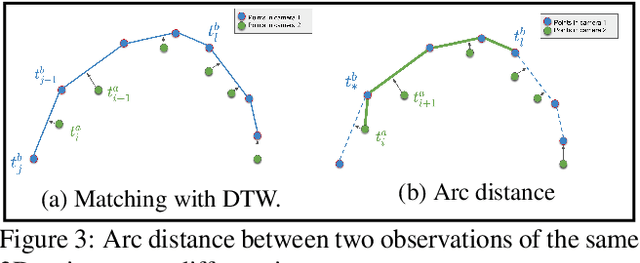
We present a general paradigm for dynamic 3D reconstruction from multiple independent and uncontrolled image sources having arbitrary temporal sampling density and distribution. Our graph-theoretic formulation models the Spatio-temporal relationships among our observations in terms of the joint estimation of their 3D geometry and its discrete Laplace operator. Towards this end, we define a tri-convex optimization framework that leverages the geometric properties and dependencies found among a Euclideanshape-space and the discrete Laplace operator describing its local and global topology. We present a reconstructability analysis, experiments on motion capture data and multi-view image datasets, as well as explore applications to geometry-based event segmentation and data association.