 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Modal Machine Learning for Flood Detection in News, Social Media and Satellite Sequences
Oct 07, 2019
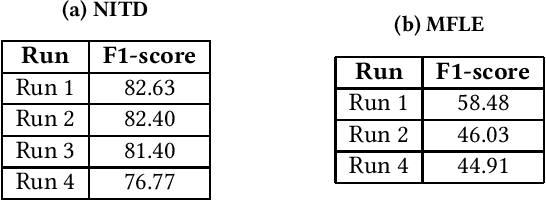
In this paper we present our methods for the MediaEval 2019 Mul-timedia Satellite Task, which is aiming to extract complementaryinformation associated with adverse events from Social Media andsatellites. For the first challenge, we propose a framework jointly uti-lizing colour, object and scene-level information to predict whetherthe topic of an article containing an image is a flood event or not.Visual features are combined using early and late fusion techniquesachieving an average F1-score of82.63,82.40,81.40and76.77. Forthe multi-modal flood level estimation, we rely on both visualand textual information achieving an average F1-score of58.48and46.03, respectively. Finally, for the flooding detection in time-based satellite image sequences we used a combination of classicalcomputer-vision and machine learning approaches achieving anaverage F1-score of58.82%
SegNBDT: Visual Decision Rules for Segmentation
Jun 11, 2020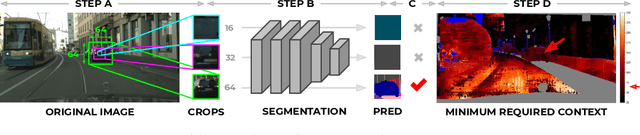


The black-box nature of neural networks limits model decision interpretability, in particular for high-dimensional inputs in computer vision and for dense pixel prediction tasks like segmentation. To address this, prior work combines neural networks with decision trees. However, such models (1) perform poorly when compared to state-of-the-art segmentation models or (2) fail to produce decision rules with spatially-grounded semantic meaning. In this work, we build a hybrid neural-network and decision-tree model for segmentation that (1) attains neural network segmentation accuracy and (2) provides semi-automatically constructed visual decision rules such as "Is there a window?". We obtain semantic visual meaning by extending saliency methods to segmentation and attain accuracy by leveraging insights from neural-backed decision trees, a deep learning analog of decision trees for image classification. Our model SegNBDT attains accuracy within ~2-4% of the state-of-the-art HRNetV2 segmentation model while also retaining explainability; we achieve state-of-the-art performance for explainable models on three benchmark datasets -- Pascal-Context (49.12%), Cityscapes (79.01%), and Look Into Person (51.64%). Furthermore, user studies suggest visual decision rules are more interpretable, particularly for incorrect predictions. Code and pretrained models can be found at https://github.com/daniel-ho/SegNBDT.
ViTAA: Visual-Textual Attributes Alignment in Person Search by Natural Language
May 15, 2020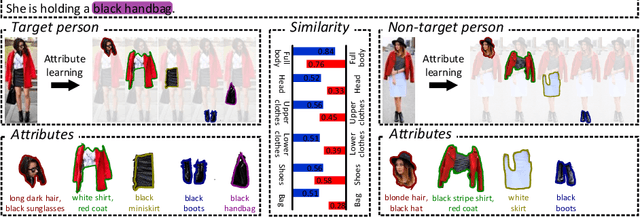
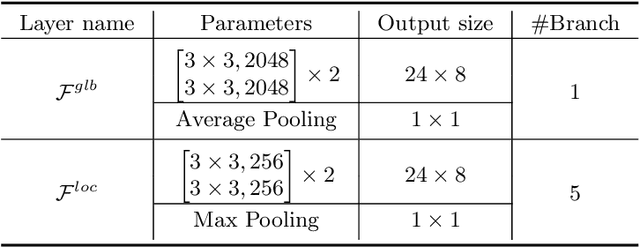

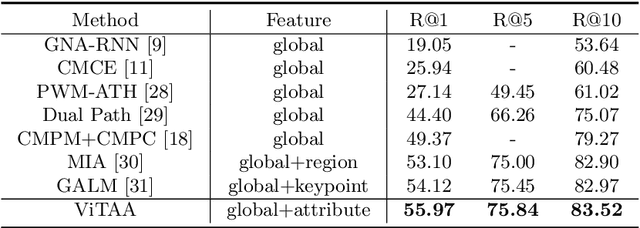
Person search by natural language aims at retrieving a specific person in a large-scale image pool that matches the given textual descriptions. While most of the current methods treat the task as a holistic visual and textual feature matching one, we approach it from an attribute-aligning perspective that allows grounding specific attribute phrases to the corresponding visual regions. We achieve success as well as the performance boosting by a robust feature learning that the referred identity can be accurately bundled by multiple attribute visual cues. To be concrete, our Visual-Textual Attribute Alignment model (dubbed as ViTAA) learns to disentangle the feature space of a person into subspaces corresponding to attributes using a light auxiliary attribute segmentation computing branch. It then aligns these visual features with the textual attributes parsed from the sentences by using a novel contrastive learning loss. Upon that, we validate our ViTAA framework through extensive experiments on tasks of person search by natural language and by attribute-phrase queries, on which our system achieves state-of-the-art performances. Code will be publicly available upon publication.
LSM: Learning Subspace Minimization for Low-level Vision
Apr 20, 2020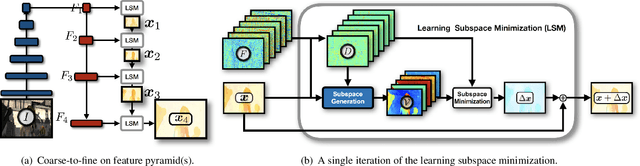
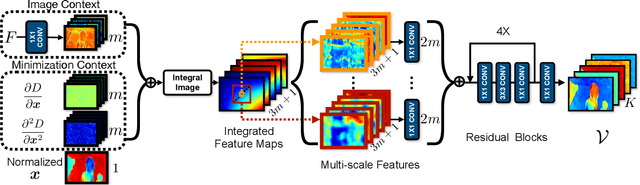
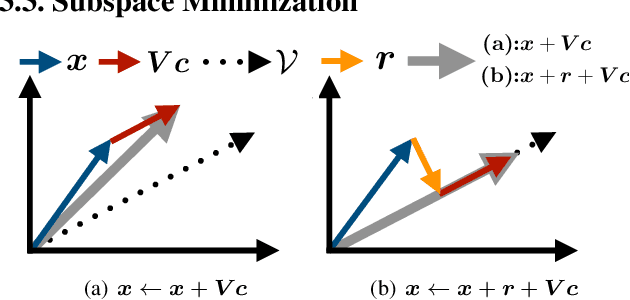
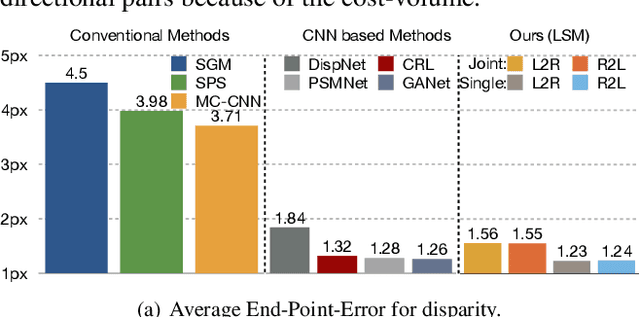
We study the energy minimization problem in low-level vision tasks from a novel perspective. We replace the heuristic regularization term with a learnable subspace constraint, and preserve the data term to exploit domain knowledge derived from the first principle of a task. This learning subspace minimization (LSM) framework unifies the network structures and the parameters for many low-level vision tasks, which allows us to train a single network for multiple tasks simultaneously with completely shared parameters, and even generalizes the trained network to an unseen task as long as its data term can be formulated. We demonstrate our LSM framework on four low-level tasks including interactive image segmentation, video segmentation, stereo matching, and optical flow, and validate the network on various datasets. The experiments show that the proposed LSM generates state-of-the-art results with smaller model size, faster training convergence, and real-time inference.
Memory-efficient Learning for Large-scale Computational Imaging
Mar 11, 2020
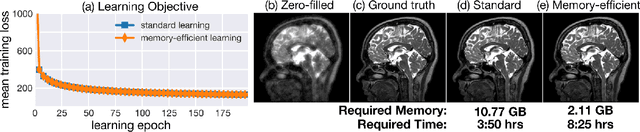
Critical aspects of computational imaging systems, such as experimental design and image priors, can be optimized through deep networks formed by the unrolled iterations of classical model-based reconstructions (termed physics-based networks). However, for real-world large-scale inverse problems, computing gradients via backpropagation is infeasible due to memory limitations of graphics processing units. In this work, we propose a memory-efficient learning procedure that exploits the reversibility of the network's layers to enable data-driven design for large-scale computational imaging systems. We demonstrate our method on a small-scale compressed sensing example, as well as two large-scale real-world systems: multi-channel magnetic resonance imaging and super-resolution optical microscopy.
A Swarm of Simple Robots Constructing Planar Shapes
Apr 28, 2020



We present a new version of our previously proposed algorithm enabling a swarm of robots to construct a desired shape from objects in the plane. We also describe a hardware realization for this system which makes use of simple and readily sourced components. We refer to the task as planar construction which is the gathering of ambient objects into some desired shape. As an example application, a swarm of robots could use this algorithm to not only gather waste material into a pile, but shape that pile into a line for easy collection. The shape is specified by an image known as the scalar field. The scalar field serves an analogous role to the template pheromones that guide the construction of complex natural structures such as termite mounds. In addition to describing the algorithm and hardware platform, we develop some performance insights using a custom simulation environment and present experimental results on physical robots.
CIDMP: Completely Interpretable Detection of Malaria Parasite in Red Blood Cells using Lower-dimensional Feature Space
Jul 05, 2020
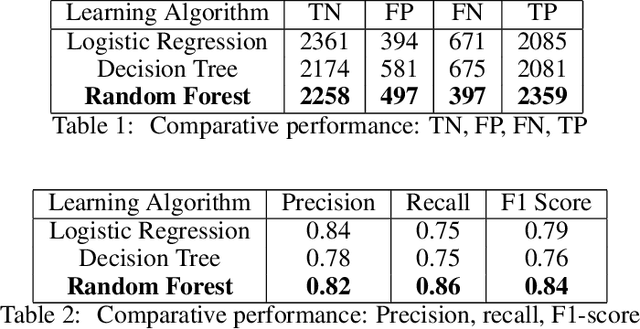
Predicting if red blood cells (RBC) are infected with the malaria parasite is an important problem in Pathology. Recently, supervised machine learning approaches have been used for this problem, and they have had reasonable success. In particular, state-of-the-art methods such as Convolutional Neural Networks automatically extract increasingly complex feature hierarchies from the image pixels. While such generalized automatic feature extraction methods have significantly reduced the burden of feature engineering in many domains, for niche tasks such as the one we consider in this paper, they result in two major problems. First, they use a very large number of features (that may or may not be relevant) and therefore training such models is computationally expensive. Further, more importantly, the large feature-space makes it very hard to interpret which features are truly important for predictions. Thus, a criticism of such methods is that learning algorithms pose opaque black boxes to its users, in this case, medical experts. The recommendation of such algorithms can be understood easily, but the reason for their recommendation is not clear. This is the problem of non-interpretability of the model, and the best-performing algorithms are usually the least interpretable. To address these issues, in this paper, we propose an approach to extract a very small number of aggregated features that are easy to interpret and compute, and empirically show that we obtain high prediction accuracy even with a significantly reduced feature-space.
Focus-and-Expand: Training Guidance Through Gradual Manipulation of Input Features
Jul 15, 2020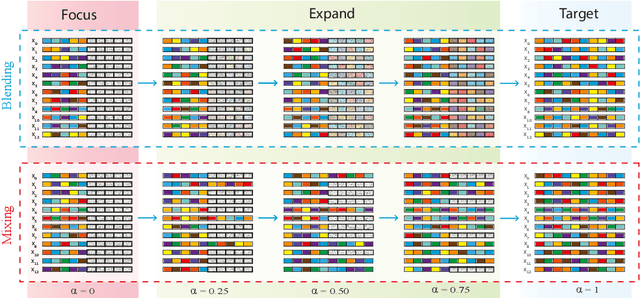
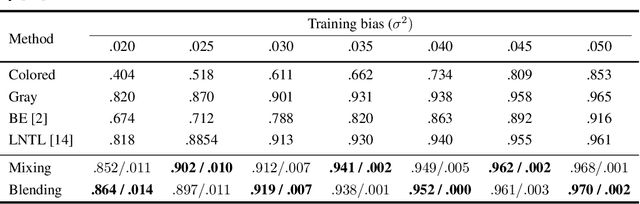

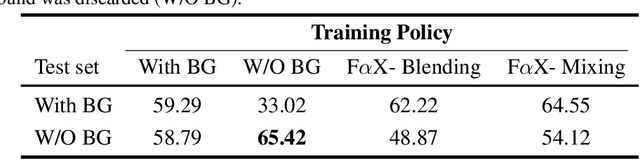
We present a simple and intuitive Focus-and-eXpand (\fax) method to guide the training process of a neural network towards a specific solution. Optimizing a neural network is a highly non-convex problem. Typically, the space of solutions is large, with numerous possible local minima, where reaching a specific minimum depends on many factors. In many cases, however, a solution which considers specific aspects, or features, of the input is desired. For example, in the presence of bias, a solution that disregards the biased feature is a more robust and accurate one. Drawing inspiration from Parameter Continuation methods, we propose steering the training process to consider specific features in the input more than others, through gradual shifts in the input domain. \fax extracts a subset of features from each input data-point, and exposes the learner to these features first, Focusing the solution on them. Then, by using a blending/mixing parameter $\alpha$ it gradually eXpands the learning process to include all features of the input. This process encourages the consideration of the desired features more than others. Though not restricted to this field, we quantitatively evaluate the effectiveness of our approach on various Computer Vision tasks, and achieve state-of-the-art bias removal, improvements to an established augmentation method, and two examples of improvements to image classification tasks. Through these few examples we demonstrate the impact this approach potentially carries for a wide variety of problems, which stand to gain from understanding the solution landscape.
When Do Neural Networks Outperform Kernel Methods?
Jun 24, 2020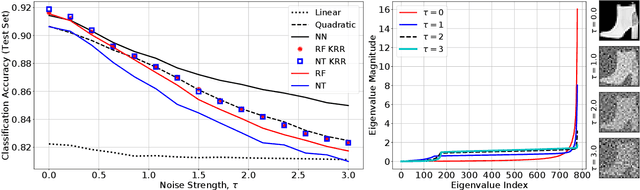

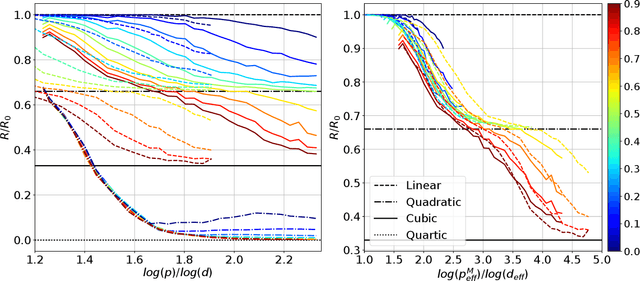
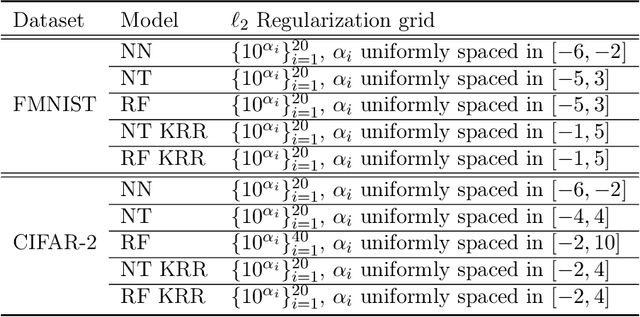
For a certain scaling of the initialization of stochastic gradient descent (SGD), wide neural networks (NN) have been shown to be well approximated by reproducing kernel Hilbert space (RKHS) methods. Recent empirical work showed that, for some classification tasks, RKHS methods can replace NNs without a large loss in performance. On the other hand, two-layers NNs are known to encode richer smoothness classes than RKHS and we know of special examples for which SGD-trained NN provably outperform RKHS. This is true even in the wide network limit, for a different scaling of the initialization. How can we reconcile the above claims? For which tasks do NNs outperform RKHS? If feature vectors are nearly isotropic, RKHS methods suffer from the curse of dimensionality, while NNs can overcome it by learning the best low-dimensional representation. Here we show that this curse of dimensionality becomes milder if the feature vectors display the same low-dimensional structure as the target function, and we precisely characterize this tradeoff. Building on these results, we present a model that can capture in a unified framework both behaviors observed in earlier work. We hypothesize that such a latent low-dimensional structure is present in image classification. We test numerically this hypothesis by showing that specific perturbations of the training distribution degrade the performances of RKHS methods much more significantly than NNs.
Generative Adversarial Networks: A Survey and Taxonomy
Jun 04, 2019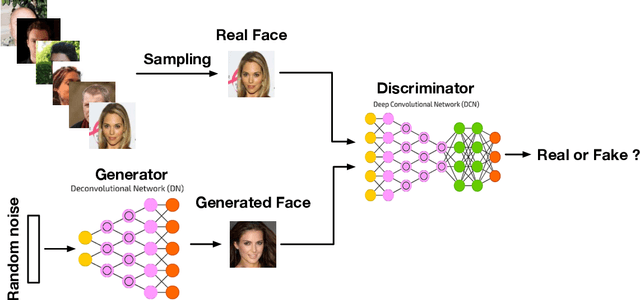
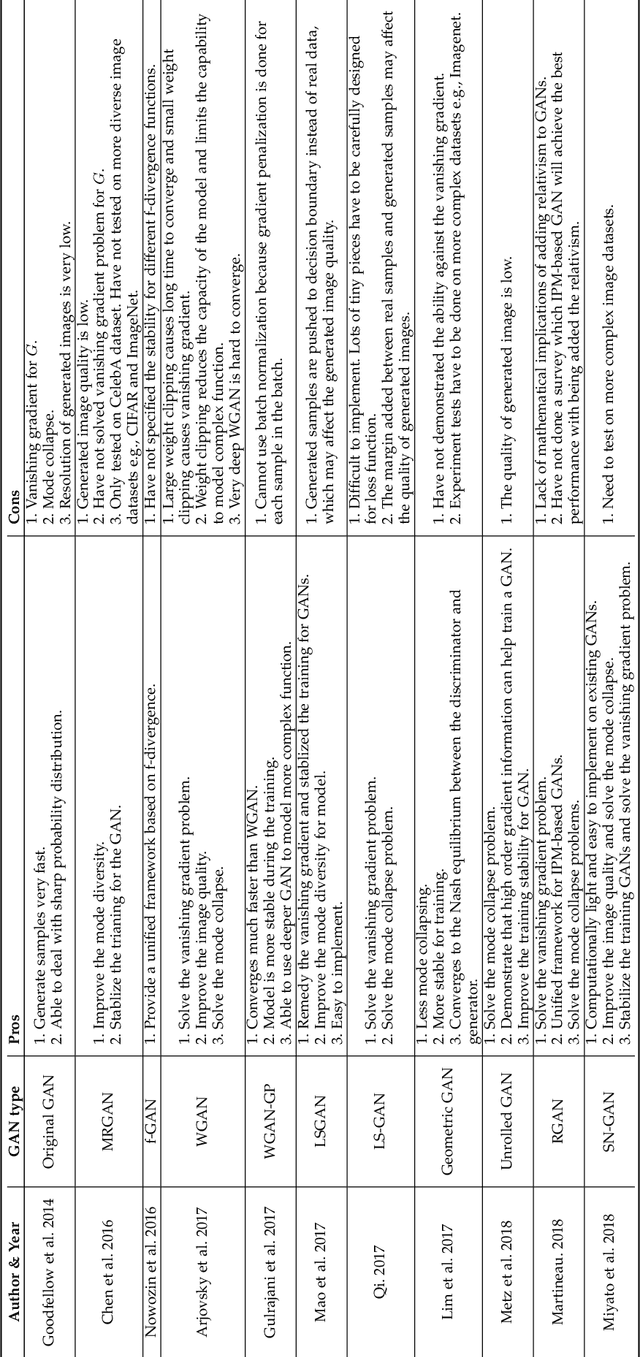
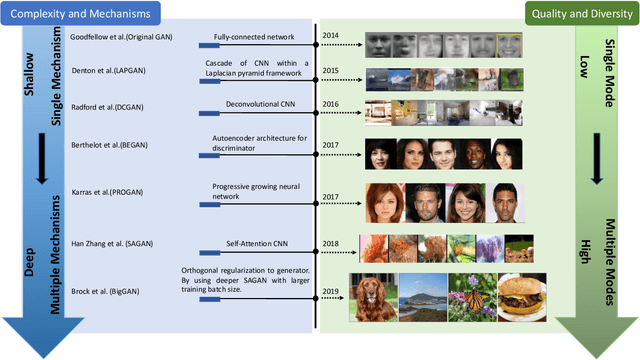
Generative adversarial networks (GANs) have been extensively studied in the past few years. Arguably the revolutionary techniques are in the area of computer vision such as plausible image generation, image to image translation, facial attribute manipulation and similar domains. Despite the significant success achieved in computer vision field, applying GANs over real-world problems still have three main challenges: (1) High quality image generation; (2) Diverse image generation; and (3) Stable training. Considering numerous GAN-related research in the literature, we provide a study on the architecture-variants and loss-variants, which are proposed to handle these three challenges from two perspectives. We propose loss and architecture-variants for classifying most popular GANs, and discuss the potential improvements with focusing on these two aspects. While several reviews for GANs have been presented, there is no work focusing on the review of GAN-variants based on handling challenges mentioned above. In this paper, we review and critically discuss 7 architecture-variant GANs and 9 loss-variant GANs for remedying those three challenges. The objective of this review is to provide an insight on the footprint that current GANs research focuses on the performance improvement. Code related to GAN-variants studied in this work is summarized on https://github.com/sheqi/GAN_Review.