 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An End-to-end Deep Learning Approach for Landmark Detection and Matching in Medical Images
Jan 21, 2020
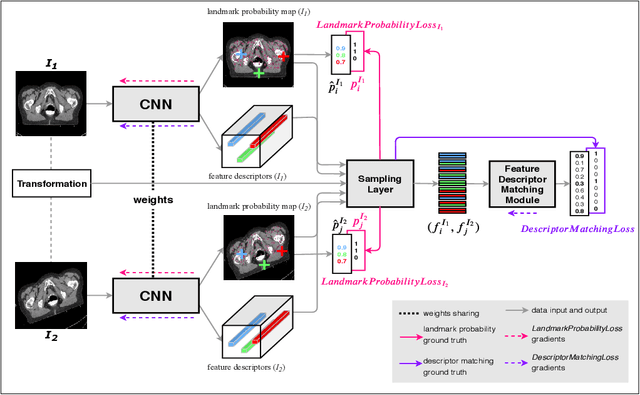
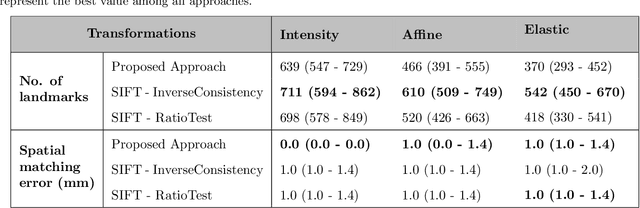
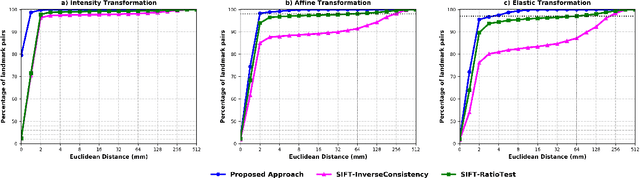
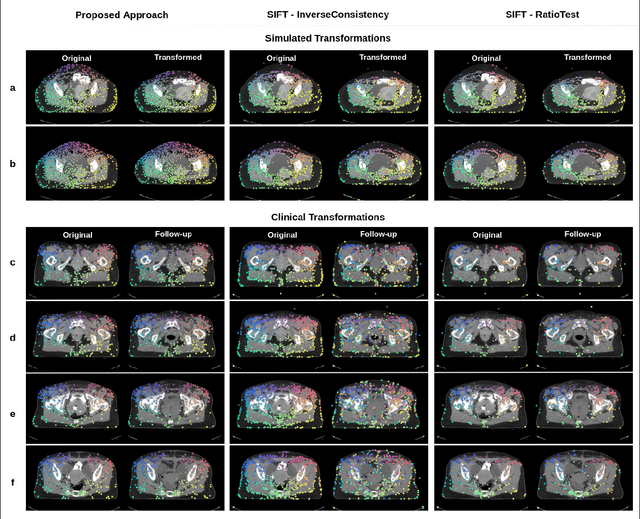
Anatomical landmark correspondences in medical images can provide additional guidance information for the alignment of two images, which, in turn, is crucial for many medical applications. However, manual landmark annotation is labor-intensive. Therefore, we propose an end-to-end deep learning approach to automatically detect landmark correspondences in pairs of two-dimensional (2D) images. Our approach consists of a Siamese neural network, which is trained to identify salient locations in images as landmarks and predict matching probabilities for landmark pairs from two different images. We trained our approach on 2D transverse slices from 168 lower abdominal Computed Tomography (CT) scans. We tested the approach on 22,206 pairs of 2D slices with varying levels of intensity, affine, and elastic transformations. The proposed approach finds an average of 639, 466, and 370 landmark matches per image pair for intensity, affine, and elastic transformations, respectively, with spatial matching errors of at most 1 mm. Further, more than 99% of the landmark pairs are within a spatial matching error of 2 mm, 4 mm, and 8 mm for image pairs with intensity, affine, and elastic transformations, respectively. To investigate the utility of our developed approach in a clinical setting, we also tested our approach on pairs of transverse slices selected from follow-up CT scans of three patients. Visual inspection of the results revealed landmark matches in both bony anatomical regions as well as in soft tissues lacking prominent intensity gradients.
Visualization of Convolutional Neural Networks for Monocular Depth Estimation
Apr 06, 2019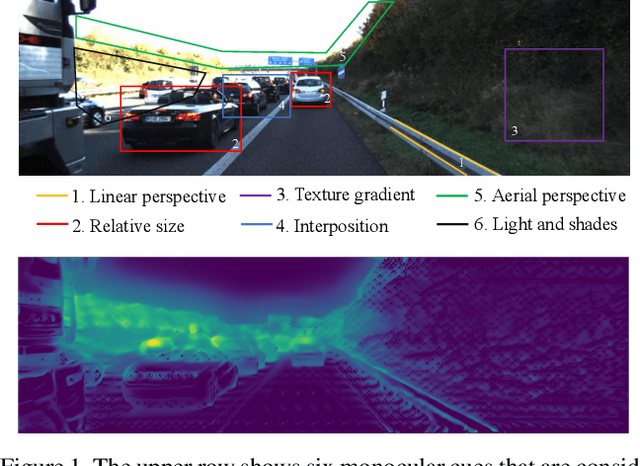
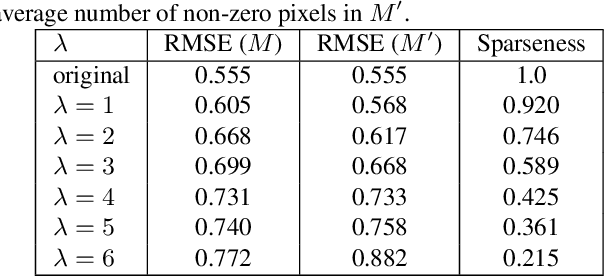


Recently, convolutional neural networks (CNNs) have shown great success on the task of monocular depth estimation. A fundamental yet unanswered question is: how CNNs can infer depth from a single image. Toward answering this question, we consider visualization of inference of a CNN by identifying relevant pixels of an input image to depth estimation. We formulate it as an optimization problem of identifying the smallest number of image pixels from which the CNN can estimate a depth map with the minimum difference from the estimate from the entire image. To cope with a difficulty with optimization through a deep CNN, we propose to use another network to predict those relevant image pixels in a forward computation. In our experiments, we first show the effectiveness of this approach, and then apply it to different depth estimation networks on indoor and outdoor scene datasets. The results provide several findings that help exploration of the above question.
SIP-SegNet: A Deep Convolutional Encoder-Decoder Network for Joint Semantic Segmentation and Extraction of Sclera, Iris and Pupil based on Periocular Region Suppression
Feb 15, 2020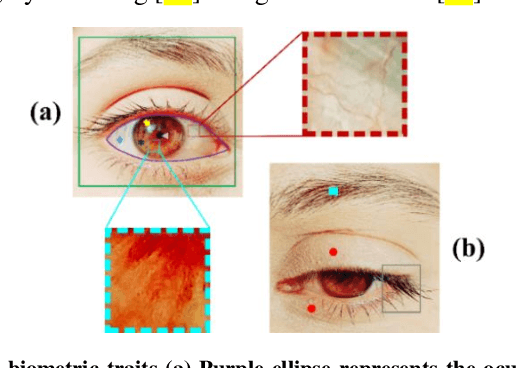
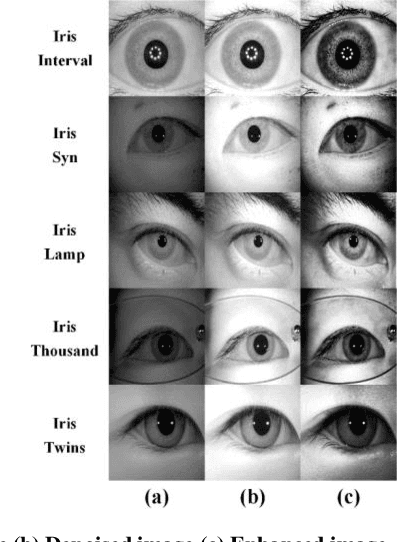
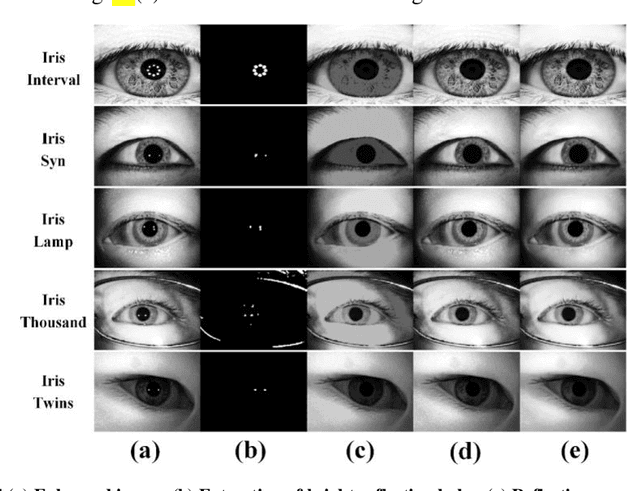
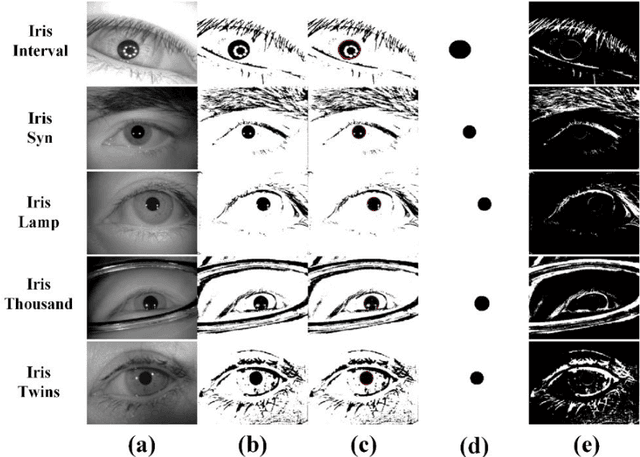
The current developments in the field of machine vision have opened new vistas towards deploying multimodal biometric recognition systems in various real-world applications. These systems have the ability to deal with the limitations of unimodal biometric systems which are vulnerable to spoofing, noise, non-universality and intra-class variations. In addition, the ocular traits among various biometric traits are preferably used in these recognition systems. Such systems possess high distinctiveness, permanence, and performance while, technologies based on other biometric traits (fingerprints, voice etc.) can be easily compromised. This work presents a novel deep learning framework called SIP-SegNet, which performs the joint semantic segmentation of ocular traits (sclera, iris and pupil) in unconstrained scenarios with greater accuracy. The acquired images under these scenarios exhibit purkinje reflexes, specular reflections, eye gaze, off-angle shots, low resolution, and various occlusions particularly by eyelids and eyelashes. To address these issues, SIP-SegNet begins with denoising the pristine image using denoising convolutional neural network (DnCNN), followed by reflection removal and image enhancement based on contrast limited adaptive histogram equalization (CLAHE). Our proposed framework then extracts the periocular information using adaptive thresholding and employs the fuzzy filtering technique to suppress this information. Finally, the semantic segmentation of sclera, iris and pupil is achieved using the densely connected fully convolutional encoder-decoder network. We used five CASIA datasets to evaluate the performance of SIP-SegNet based on various evaluation metrics. The simulation results validate the optimal segmentation of the proposed SIP-SegNet, with the mean f1 scores of 93.35, 95.11 and 96.69 for the sclera, iris and pupil classes respectively.
eCNN: A Block-Based and Highly-Parallel CNN Accelerator for Edge Inference
Oct 13, 2019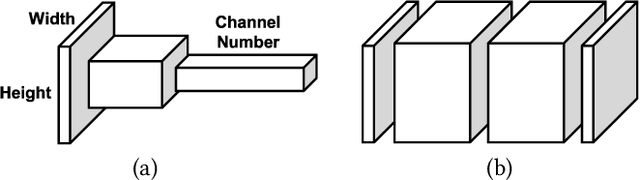

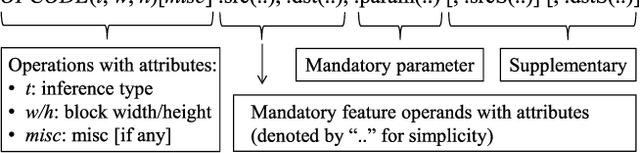
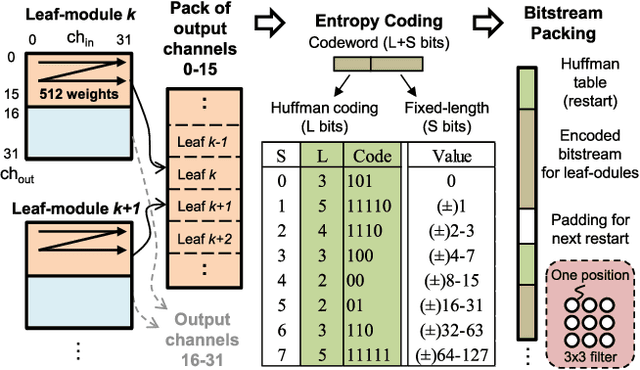
Convolutional neural networks (CNNs) have recently demonstrated superior quality for computational imaging applications. Therefore, they have great potential to revolutionize the image pipelines on cameras and displays. However, it is difficult for conventional CNN accelerators to support ultra-high-resolution videos at the edge due to their considerable DRAM bandwidth and power consumption. Therefore, finding a further memory- and computation-efficient microarchitecture is crucial to speed up this coming revolution. In this paper, we approach this goal by considering the inference flow, network model, instruction set, and processor design jointly to optimize hardware performance and image quality. We apply a block-based inference flow which can eliminate all the DRAM bandwidth for feature maps and accordingly propose a hardware-oriented network model, ERNet, to optimize image quality based on hardware constraints. Then we devise a coarse-grained instruction set architecture, FBISA, to support power-hungry convolution by massive parallelism. Finally,we implement an embedded processor---eCNN---which accommodates to ERNet and FBISA with a flexible processing architecture. Layout results show that it can support high-quality ERNets for super-resolution and denoising at up to 4K Ultra-HD 30 fps while using only DDR-400 and consuming 6.94W on average. By comparison, the state-of-the-art Diffy uses dual-channel DDR3-2133 and consumes 54.3W to support lower-quality VDSR at Full HD 30 fps. Lastly, we will also present application examples of high-performance style transfer and object recognition to demonstrate the flexibility of eCNN.
An encoder-decoder-based method for COVID-19 lung infection segmentation
Jul 04, 2020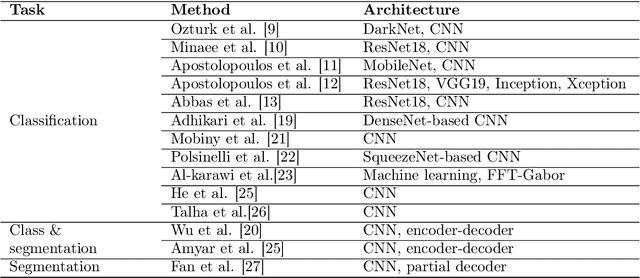
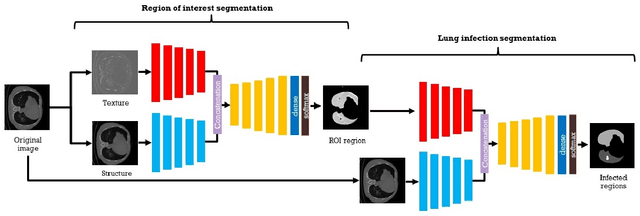
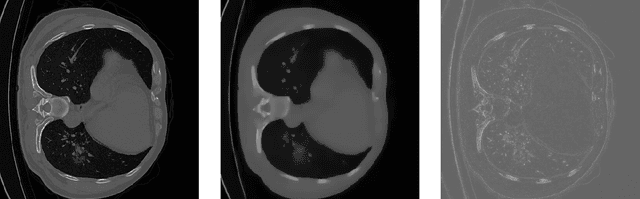
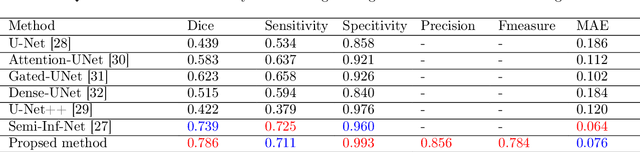
The novelty of the COVID-19 disease and the speed of spread has created a colossal chaos, impulse among researchers worldwide to exploit all the resources and capabilities to understand and analyze characteristics of the coronavirus in term of the ways it spreads and virus incubation time. For that, the existing medical features like CT and X-ray images are used. For example, CT-scan images can be used for the detection of lung infection. But the challenges of these features such as the quality of the image and infection characteristics limitate the effectiveness of these features. Using artificial intelligence (AI) tools and computer vision algorithms, the accuracy of detection can be more accurate and can help to overcome these issues. This paper proposes a multi-task deep-learning-based method for lung infection segmentation using CT-scan images. Our proposed method starts by segmenting the lung regions that can be infected. Then, segmenting the infections in these regions. Also, to perform a multi-class segmentation the proposed model is trained using the two-stream inputs. The multi-task learning used in this paper allows us to overcome shortage of labeled data. Also, the multi-input stream allows the model to do the learning on many features that can improve the results. To evaluate the proposed method, many features have been used. Also, from the experiments, the proposed method can segment lung infections with a high degree performance even with shortage of data and labeled images. In addition, comparing with the state-of-the-art method our method achieves good performance results.
Generative Smoke Removal
Feb 01, 2019
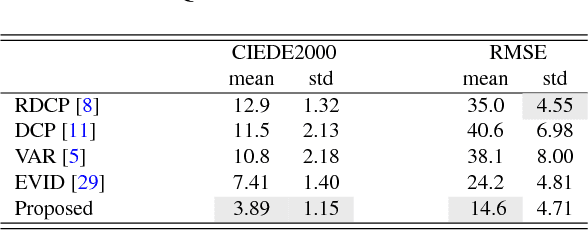
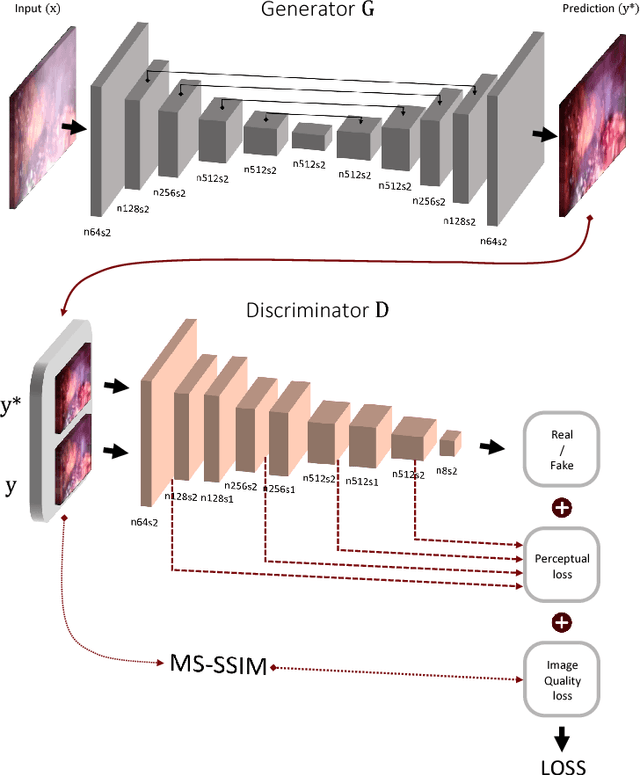
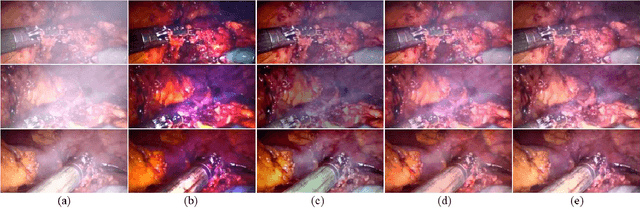
In minimally invasive surgery, the use of tissue dissection tools causes smoke, which inevitably degrades the image quality. This could reduce the visibility of the operation field for surgeons and introduces errors for the computer vision algorithms used in surgical navigation systems. In this paper, we propose a novel approach for computational smoke removal using supervised image-to-image translation. We demonstrate that straightforward application of existing generative algorithms allows removing smoke but decreases image quality and introduces synthetic noise (grid-structure). Thus, we propose to solve this issue by modification of GAN's architecture and adding perceptual image quality metric to the loss function. Obtained results demonstrate that proposed method efficiently removes smoke as well as preserves perceptually sufficient image quality.
OrigamiNet: Weakly-Supervised, Segmentation-Free, One-Step, Full Page Text Recognition by learning to unfold
Jun 12, 2020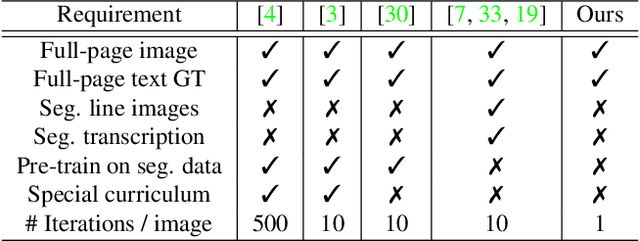
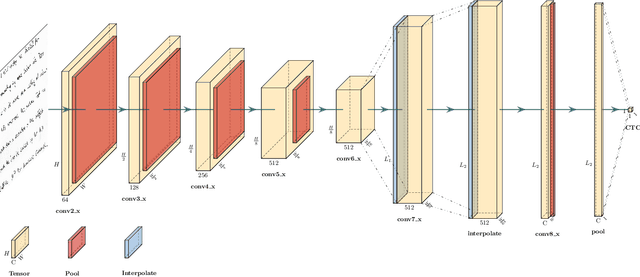
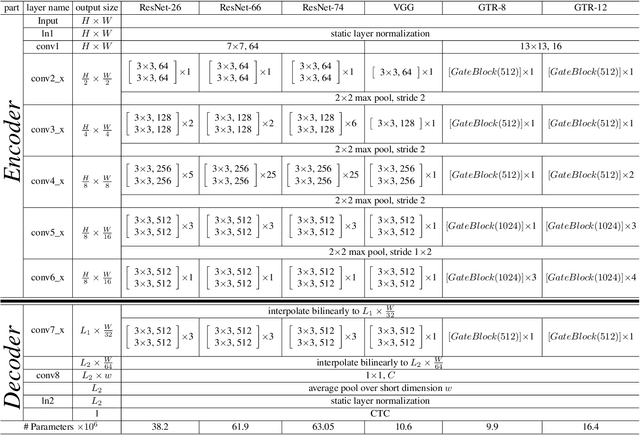

Text recognition is a major computer vision task with a big set of associated challenges. One of those traditional challenges is the coupled nature of text recognition and segmentation. This problem has been progressively solved over the past decades, going from segmentation based recognition to segmentation free approaches, which proved more accurate and much cheaper to annotate data for. We take a step from segmentation-free single line recognition towards segmentation-free multi-line / full page recognition. We propose a novel and simple neural network module, termed \textbf{OrigamiNet}, that can augment any CTC-trained, fully convolutional single line text recognizer, to convert it into a multi-line version by providing the model with enough spatial capacity to be able to properly collapse a 2D input signal into 1D without losing information. Such modified networks can be trained using exactly their same simple original procedure, and using only \textbf{unsegmented} image and text pairs. We carry out a set of interpretability experiments that show that our trained models learn an accurate implicit line segmentation. We achieve state-of-the-art character error rate on both IAM \& ICDAR 2017 HTR benchmarks for handwriting recognition, surpassing all other methods in the literature. On IAM we even surpass single line methods that use accurate localization information during training. Our code is available online at \url{https://github.com/IntuitionMachines/OrigamiNet}.
Set-Structured Latent Representations
Mar 09, 2020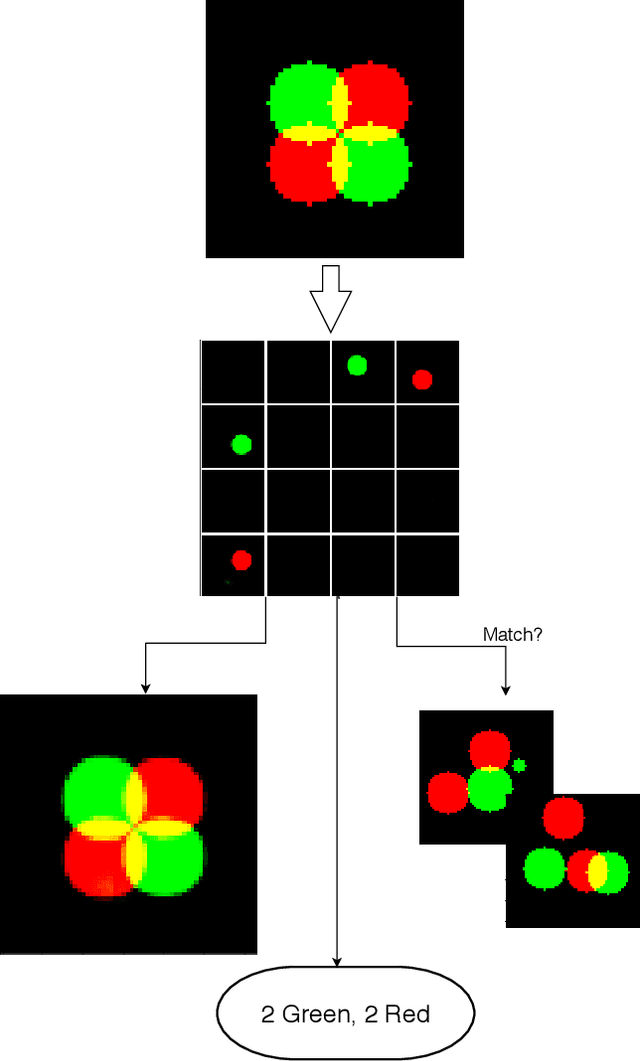
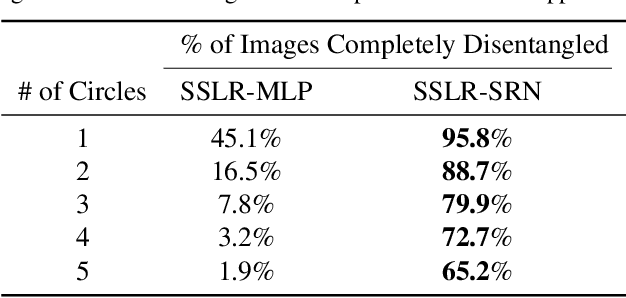

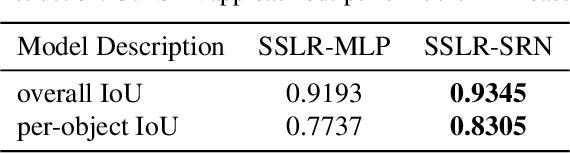
Unstructured data often has latent component structure, such as the objects in an image of a scene. In these situations, the relevant latent structure is an unordered collection or \emph{set}. However, learning such representations directly from data is difficult due to the discrete and unordered structure. Here, we develop a framework for differentiable learning of set-structured latent representations. We show how to use this framework to naturally decompose data such as images into sets of interpretable and meaningful components and demonstrate how existing techniques cannot properly disentangle relevant structure. We also show how to extend our methodology to downstream tasks such as set matching, which uses set-specific operations. Our code is available at https://github.com/CUVL/SSLR.
Multi-Resolution 3D CNN for MRI Brain Tumor Segmentation and Survival Prediction
Nov 19, 2019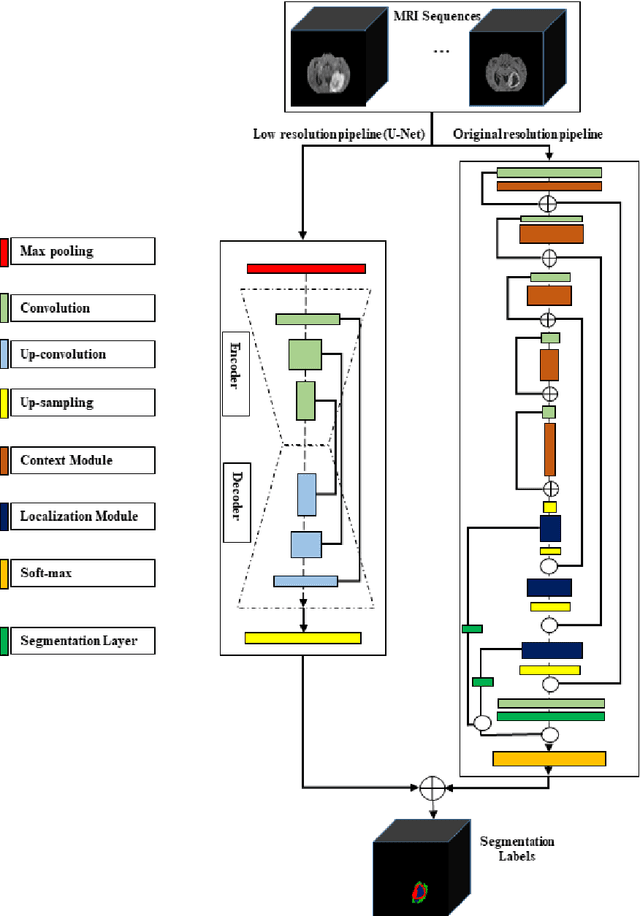
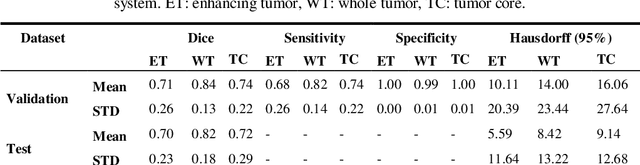
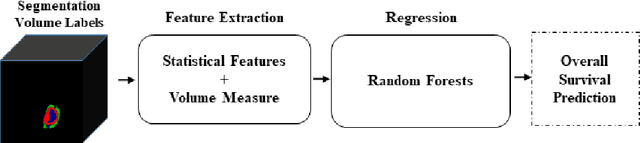

In this study, an automated three dimensional (3D) deep segmentation approach for detecting gliomas in 3D pre-operative MRI scans is proposed. Then, a classi-fication algorithm based on random forests, for survival prediction is presented. The objective is to segment the glioma area and produce segmentation labels for its different sub-regions, i.e. necrotic and the non-enhancing tumor core, the peri-tumoral edema, and enhancing tumor. The proposed deep architecture for the segmentation task encompasses two parallel streamlines with two different reso-lutions. One deep convolutional neural network is to learn local features of the input data while the other one is set to have a global observation on whole image. Deemed to be complementary, the outputs of each stream are then merged to pro-vide an ensemble complete learning of the input image. The proposed network takes the whole image as input instead of patch-based approaches in order to con-sider the semantic features throughout the whole volume. The algorithm is trained on BraTS 2019 which included 335 training cases, and validated on 127 unseen cases from the validation dataset using a blind testing approach. The proposed method was also evaluated on the BraTS 2019 challenge test dataset of 166 cases. The results show that the proposed methods provide promising segmentations as well as survival prediction. The mean Dice overlap measures of automatic brain tumor segmentation for validation set were 0.84, 0.74 and 0.71 for the whole tu-mor, core and enhancing tumor, respectively. The corresponding results for the challenge test dataset were 0.82, 0.72, and 0.70, respectively. The overall accura-cy of the proposed model for the survival prediction task is %52 for the valida-tion and %49 for the test dataset.
Understanding and Improving Information Transfer in Multi-Task Learning
May 02, 2020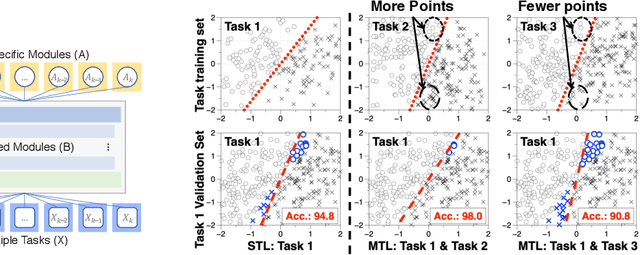

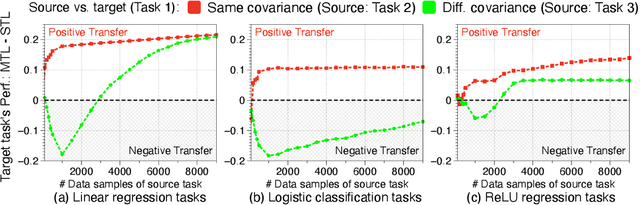
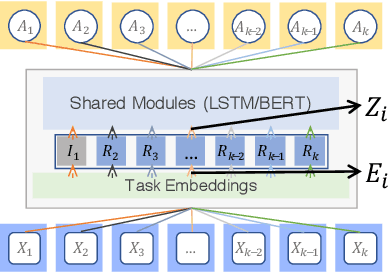
We investigate multi-task learning approaches that use a shared feature representation for all tasks. To better understand the transfer of task information, we study an architecture with a shared module for all tasks and a separate output module for each task. We study the theory of this setting on linear and ReLU-activated models. Our key observation is that whether or not tasks' data are well-aligned can significantly affect the performance of multi-task learning. We show that misalignment between task data can cause negative transfer (or hurt performance) and provide sufficient conditions for positive transfer. Inspired by the theoretical insights, we show that aligning tasks' embedding layers leads to performance gains for multi-task training and transfer learning on the GLUE benchmark and sentiment analysis tasks; for example, we obtain a 2.35% GLUE score average improvement on 5 GLUE tasks over BERT-LARGE using our alignment method. We also design an SVD-based task reweighting scheme and show that it improves the robustness of multi-task training on a multi-label image dataset.