 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion models meet image counter-forensics
Nov 22, 2023
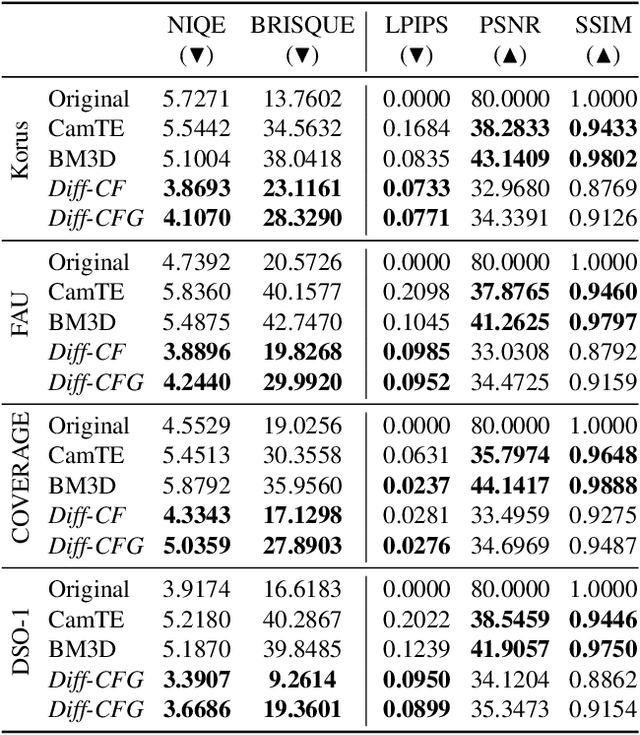

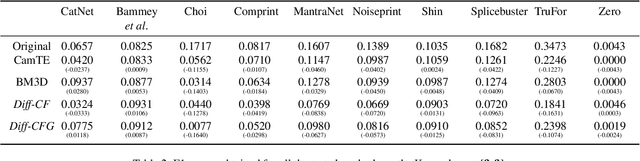

From its acquisition in the camera sensors to its storage, different operations are performed to generate the final image. This pipeline imprints specific traces into the image to form a natural watermark. Tampering with an image disturbs these traces; these disruptions are clues that are used by most methods to detect and locate forgeries. In this article, we assess the capabilities of diffusion models to erase the traces left by forgers and, therefore, deceive forensics methods. Such an approach has been recently introduced for adversarial purification, achieving significant performance. We show that diffusion purification methods are well suited for counter-forensics tasks. Such approaches outperform already existing counter-forensics techniques both in deceiving forensics methods and in preserving the natural look of the purified images. The source code is publicly available at https://github.com/mtailanian/diff-cf.
Enhancing Object Coherence in Layout-to-Image Synthesis
Nov 25, 2023Layout-to-image synthesis is an emerging technique in conditional image generation. It aims to generate complex scenes, where users require fine control over the layout of the objects in a scene. However, it remains challenging to control the object coherence, including semantic coherence (e.g., the cat looks at the flowers or not) and physical coherence (e.g., the hand and the racket should not be misaligned). In this paper, we propose a novel diffusion model with effective global semantic fusion (GSF) and self-similarity feature enhancement modules to guide the object coherence for this task. For semantic coherence, we argue that the image caption contains rich information for defining the semantic relationship within the objects in the images. Instead of simply employing cross-attention between captions and generated images, which addresses the highly relevant layout restriction and semantic coherence separately and thus leads to unsatisfying results shown in our experiments, we develop GSF to fuse the supervision from the layout restriction and semantic coherence requirement and exploit it to guide the image synthesis process. Moreover, to improve the physical coherence, we develop a Self-similarity Coherence Attention (SCA) module to explicitly integrate local contextual physical coherence into each pixel's generation process. Specifically, we adopt a self-similarity map to encode the coherence restrictions and employ it to extract coherent features from text embedding. Through visualization of our self-similarity map, we explore the essence of SCA, revealing that its effectiveness is not only in capturing reliable physical coherence patterns but also in enhancing complex texture generation. Extensive experiments demonstrate the superiority of our proposed method in both image generation quality and controllability.
Enhancing Post-Hoc Explanation Benchmark Reliability for Image Classification
Nov 29, 2023Deep neural networks, while powerful for image classification, often operate as "black boxes," complicating the understanding of their decision-making processes. Various explanation methods, particularly those generating saliency maps, aim to address this challenge. However, the inconsistency issues of faithfulness metrics hinder reliable benchmarking of explanation methods. This paper employs an approach inspired by psychometrics, utilizing Krippendorf's alpha to quantify the benchmark reliability of post-hoc methods in image classification. The study proposes model training modifications, including feeding perturbed samples and employing focal loss, to enhance robustness and calibration. Empirical evaluations demonstrate significant improvements in benchmark reliability across metrics, datasets, and post-hoc methods. This pioneering work establishes a foundation for more reliable evaluation practices in the realm of post-hoc explanation methods, emphasizing the importance of model robustness in the assessment process.
Variational Bayes image restoration with compressive autoencoders
Nov 29, 2023Regularization of inverse problems is of paramount importance in computational imaging. The ability of neural networks to learn efficient image representations has been recently exploited to design powerful data-driven regularizers. While state-of-the-art plug-and-play methods rely on an implicit regularization provided by neural denoisers, alternative Bayesian approaches consider Maximum A Posteriori (MAP) estimation in the latent space of a generative model, thus with an explicit regularization. However, state-of-the-art deep generative models require a huge amount of training data compared to denoisers. Besides, their complexity hampers the optimization of the latent MAP. In this work, we propose to use compressive autoencoders for latent estimation. These networks, which can be seen as variational autoencoders with a flexible latent prior, are smaller and easier to train than state-of-the-art generative models. We then introduce the Variational Bayes Latent Estimation (VBLE) algorithm, which performs this estimation within the framework of variational inference. This allows for fast and easy (approximate) posterior sampling. Experimental results on image datasets BSD and FFHQ demonstrate that VBLE reaches similar performance than state-of-the-art plug-and-play methods, while being able to quantify uncertainties faster than other existing posterior sampling techniques.
Learning Prompt with Distribution-Based Feature Replay for Few-Shot Class-Incremental Learning
Jan 03, 2024Few-shot Class-Incremental Learning (FSCIL) aims to continuously learn new classes based on very limited training data without forgetting the old ones encountered. Existing studies solely relied on pure visual networks, while in this paper we solved FSCIL by leveraging the Vision-Language model (e.g., CLIP) and propose a simple yet effective framework, named Learning Prompt with Distribution-based Feature Replay (LP-DiF). We observe that simply using CLIP for zero-shot evaluation can substantially outperform the most influential methods. Then, prompt tuning technique is involved to further improve its adaptation ability, allowing the model to continually capture specific knowledge from each session. To prevent the learnable prompt from forgetting old knowledge in the new session, we propose a pseudo-feature replay approach. Specifically, we preserve the old knowledge of each class by maintaining a feature-level Gaussian distribution with a diagonal covariance matrix, which is estimated by the image features of training images and synthesized features generated from a VAE. When progressing to a new session, pseudo-features are sampled from old-class distributions combined with training images of the current session to optimize the prompt, thus enabling the model to learn new knowledge while retaining old knowledge. Experiments on three prevalent benchmarks, i.e., CIFAR100, mini-ImageNet, CUB-200, and two more challenging benchmarks, i.e., SUN-397 and CUB-200$^*$ proposed in this paper showcase the superiority of LP-DiF, achieving new state-of-the-art (SOTA) in FSCIL. Code is publicly available at https://github.com/1170300714/LP-DiF.
Brain-Conditional Multimodal Synthesis: A Survey and Taxonomy
Jan 03, 2024In the era of Artificial Intelligence Generated Content (AIGC), conditional multimodal synthesis technologies (e.g., text-to-image, text-to-video, text-to-audio, etc) are gradually reshaping the natural content in the real world. The key to multimodal synthesis technology is to establish the mapping relationship between different modalities. Brain signals, serving as potential reflections of how the brain interprets external information, exhibit a distinctive One-to-Many correspondence with various external modalities. This correspondence makes brain signals emerge as a promising guiding condition for multimodal content synthesis. Brian-conditional multimodal synthesis refers to decoding brain signals back to perceptual experience, which is crucial for developing practical brain-computer interface systems and unraveling complex mechanisms underlying how the brain perceives and comprehends external stimuli. This survey comprehensively examines the emerging field of AIGC-based Brain-conditional Multimodal Synthesis, termed AIGC-Brain, to delineate the current landscape and future directions. To begin, related brain neuroimaging datasets, functional brain regions, and mainstream generative models are introduced as the foundation of AIGC-Brain decoding and analysis. Next, we provide a comprehensive taxonomy for AIGC-Brain decoding models and present task-specific representative work and detailed implementation strategies to facilitate comparison and in-depth analysis. Quality assessments are then introduced for both qualitative and quantitative evaluation. Finally, this survey explores insights gained, providing current challenges and outlining prospects of AIGC-Brain. Being the inaugural survey in this domain, this paper paves the way for the progress of AIGC-Brain research, offering a foundational overview to guide future work.
DemoFusion: Democratising High-Resolution Image Generation With No $$$
Nov 24, 2023High-resolution image generation with Generative Artificial Intelligence (GenAI) has immense potential but, due to the enormous capital investment required for training, it is increasingly centralised to a few large corporations, and hidden behind paywalls. This paper aims to democratise high-resolution GenAI by advancing the frontier of high-resolution generation while remaining accessible to a broad audience. We demonstrate that existing Latent Diffusion Models (LDMs) possess untapped potential for higher-resolution image generation. Our novel DemoFusion framework seamlessly extends open-source GenAI models, employing Progressive Upscaling, Skip Residual, and Dilated Sampling mechanisms to achieve higher-resolution image generation. The progressive nature of DemoFusion requires more passes, but the intermediate results can serve as "previews", facilitating rapid prompt iteration.
Progressive Learning with Visual Prompt Tuning for Variable-Rate Image Compression
Nov 28, 2023In this paper, we propose a progressive learning paradigm for transformer-based variable-rate image compression. Our approach covers a wide range of compression rates with the assistance of the Layer-adaptive Prompt Module (LPM). Inspired by visual prompt tuning, we use LPM to extract prompts for input images and hidden features at the encoder side and decoder side, respectively, which are fed as additional information into the Swin Transformer layer of a pre-trained transformer-based image compression model to affect the allocation of attention region and the bits, which in turn changes the target compression ratio of the model. To ensure the network is more lightweight, we involves the integration of prompt networks with less convolutional layers. Exhaustive experiments show that compared to methods based on multiple models, which are optimized separately for different target rates, the proposed method arrives at the same performance with 80% savings in parameter storage and 90% savings in datasets. Meanwhile, our model outperforms all current variable bitrate image methods in terms of rate-distortion performance and approaches the state-of-the-art fixed bitrate image compression methods trained from scratch.
Soulstyler: Using Large Language Model to Guide Image Style Transfer for Target Object
Nov 29, 2023
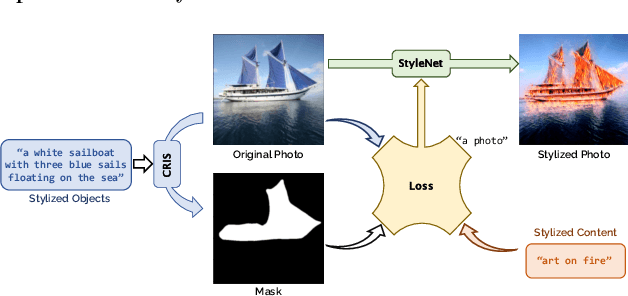
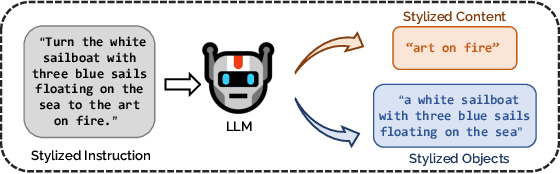
Image style transfer occupies an important place in both computer graphics and computer vision. However, most current methods require reference to stylized images and cannot individually stylize specific objects. To overcome this limitation, we propose the "Soulstyler" framework, which allows users to guide the stylization of specific objects in an image through simple textual descriptions. We introduce a large language model to parse the text and identify stylization goals and specific styles. Combined with a CLIP-based semantic visual embedding encoder, the model understands and matches text and image content. We also introduce a novel localized text-image block matching loss that ensures that style transfer is performed only on specified target objects, while non-target regions remain in their original style. Experimental results demonstrate that our model is able to accurately perform style transfer on target objects according to textual descriptions without affecting the style of background regions. Our code will be available at https://github.com/yisuanwang/Soulstyler.
Advancements and Trends in Ultra-High-Resolution Image Processing: An Overview
Nov 30, 2023Currently, to further improve visual enjoyment, Ultra-High-Definition (UHD) images are catching wide attention. Here, UHD images are usually referred to as having a resolution greater than or equal to $3840 \times 2160$. However, since the imaging equipment is subject to environmental noise or equipment jitter, UHD images are prone to contrast degradation, blurring, low dynamic range, etc. To address these issues, a large number of algorithms for UHD image enhancement have been proposed. In this paper, we introduce the current state of UHD image enhancement from two perspectives, one is the application field and the other is the technology. In addition, we briefly explore its trends.