 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Feedback Recurrent Autoencoder for Video Compression
Apr 09, 2020
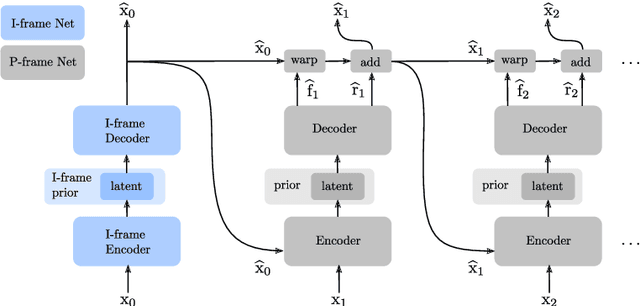
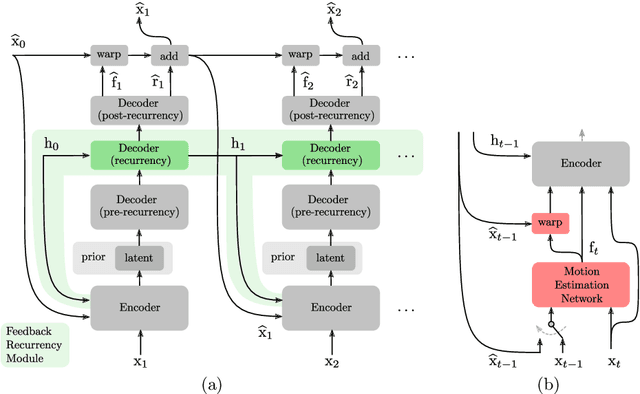
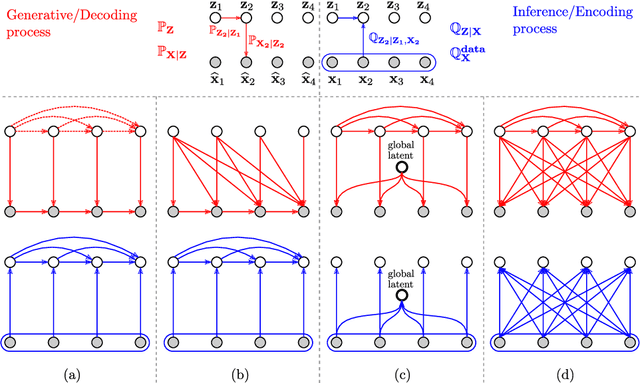
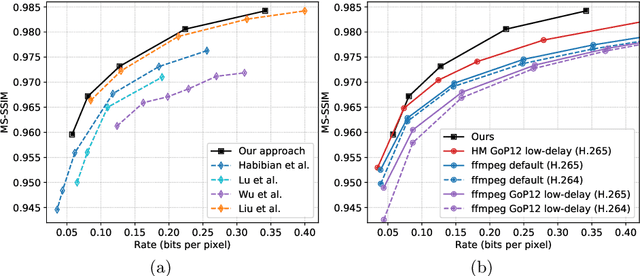
Recent advances in deep generative modeling have enabled efficient modeling of high dimensional data distributions and opened up a new horizon for solving data compression problems. Specifically, autoencoder based learned image or video compression solutions are emerging as strong competitors to traditional approaches. In this work, We propose a new network architecture, based on common and well studied components, for learned video compression operating in low latency mode. Our method yields state of the art MS-SSIM/rate performance on the high-resolution UVG dataset, among both learned video compression approaches and classical video compression methods (H.265 and H.264) in the rate range of interest for streaming applications. Additionally, we provide an analysis of existing approaches through the lens of their underlying probabilistic graphical models. Finally, we point out issues with temporal consistency and color shift observed in empirical evaluation, and suggest directions forward to alleviate those.
A novel and reliable deep learning web-based tool to detect COVID-19 infection form chest CT-scan
Jun 24, 2020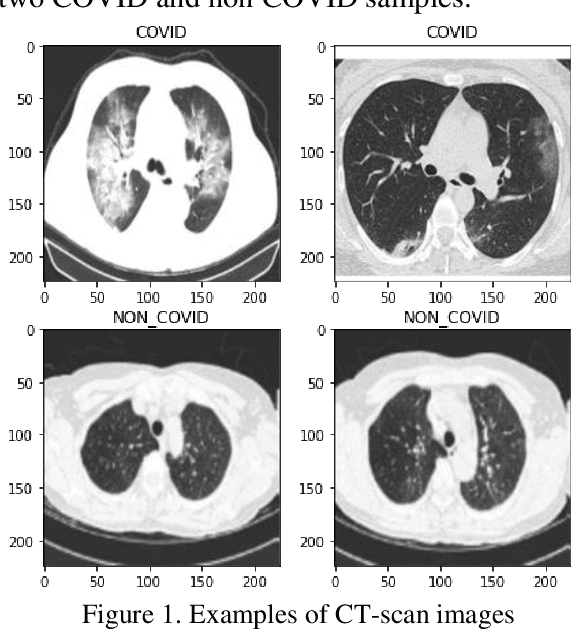
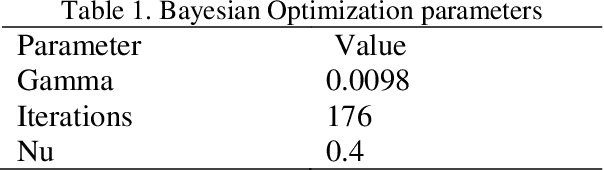
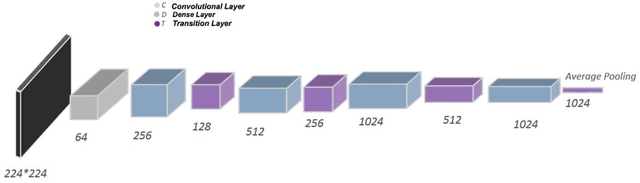
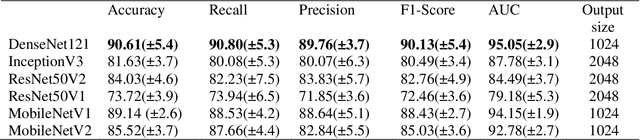
The corona virus is already spread around the world in many countries, and it has taken many lives. Furthermore, the world health organization (WHO) has announced that COVID-19 has reached the global epidemic stage. Early and reliable diagnosis using chest CT-scan can assist medical specialists in vital circumstances. In this study, we introduce a computer aided diagnosis (CAD) web service to detect COVID-19 based on chest CT- scan images and deep learning approach. A public database containing 746 participants were used in this experiment. A novel combination of the Densely connected convolutional network (DenseNet) in order to extract spatial features and a Nu-SVM was applied on the feature maps were implemented to distinguish between COVID-19 and healthy controls. A number of well-known deep neural network architectures consisting of ResNet, Inception and MobileNet were also applied and compared to main model in order to prove efficiency of the hybrid system. The developed flask web service in this research uses the trained model to provide a RESTful COVID-19 detector, which takes only 39 milliseconds to process one image. The source code is also available 2. The proposed methodology achieved 90.80% recall, 89.76% precision and 90.61% accuracy. The method also yields an AUC of 95.05%. Based on the findings, it can be inferred that it is feasible to use the proposed technique as an automated tool for diagnosis of COVID-19.
Characterizing the Variability in Face Recognition Accuracy Relative to Race
May 08, 2019
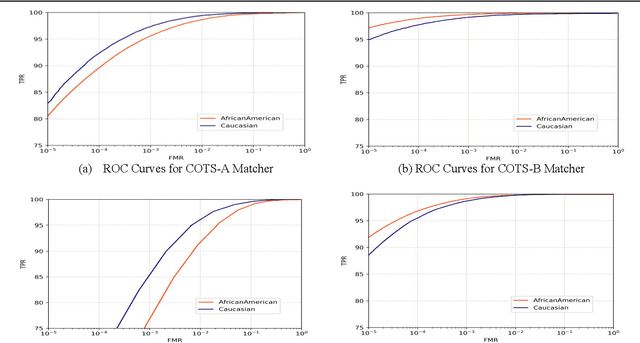
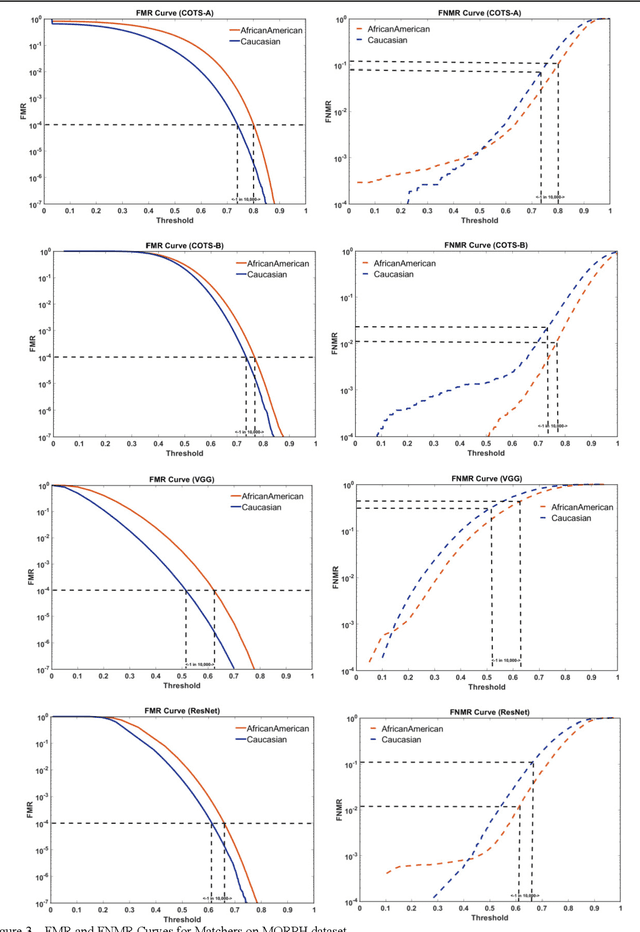
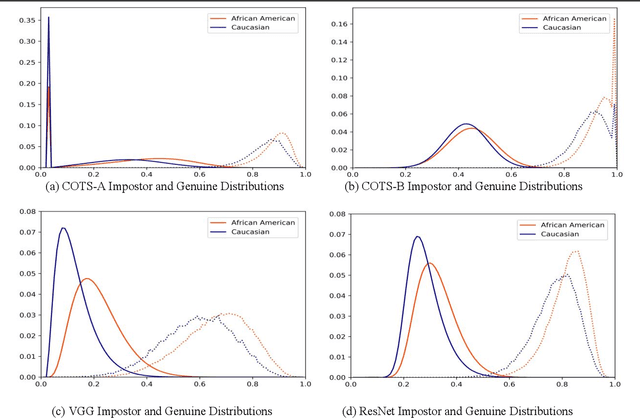
Many recent news headlines have labeled face recognition technology as biased or racist. We report on a methodical investigation into differences in face recognition accuracy between African-American and Caucasian image cohorts of the MORPH dataset. We find that, for all four matchers considered, the impostor and the genuine distributions are statistically significantly different between cohorts. For a fixed decision threshold, the African-American image cohort has a higher false match rate and a lower false non-match rate. ROC curves compare verification rates at the same false match rate, but the different cohorts achieve the same false match rate at different thresholds. This means that ROC comparisons are not relevant to operational scenarios that use a fixed decision threshold. We show that, for the ResNet matcher, the two cohorts have approximately equal separation of impostor and genuine distributions. Using ICAO compliance as a standard of image quality, we find that the initial image cohorts have unequal rates of good quality images. The ICAO-compliant subsets of the original image cohorts show improved accuracy, with the main effect being to reducing the low-similarity tail of the genuine distributions.
Selective Synthetic Augmentation with Quality Assurance
Dec 09, 2019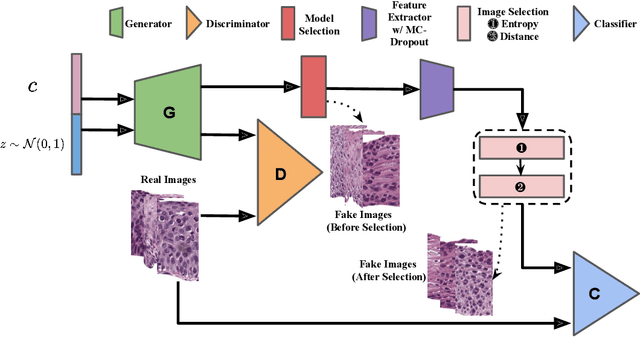
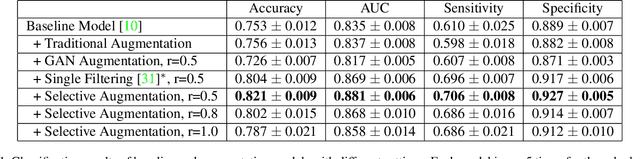

Supervised training of an automated medical image analysis system often requires a large amount of expert annotations that are hard to collect. Moreover, the proportions of data available across different classes may be highly imbalanced for rare diseases. To mitigate these issues, we investigate a novel data augmentation pipeline that selectively adds new synthetic images generated by conditional Adversarial Networks (cGANs), rather than extending directly the training set with synthetic images. The selection mechanisms that we introduce to the synthetic augmentation pipeline are motivated by the observation that, although cGAN-generated images can be visually appealing, they are not guaranteed to contain essential features for classification performance improvement. By selecting synthetic images based on the confidence of their assigned labels and their feature similarity to real labeled images, our framework provides quality assurance to synthetic augmentation by ensuring that adding the selected synthetic images to the training set will improve performance. We evaluate our model on a medical histopathology dataset, and two natural image classification benchmarks, CIFAR10 and SVHN. Results on these datasets show significant and consistent improvements in classification performance (with 6.8%, 3.9%, 1.6% higher accuracy, respectively) by leveraging cGAN generated images with selective augmentation.
Survey on Visual Sentiment Analysis
May 18, 2020
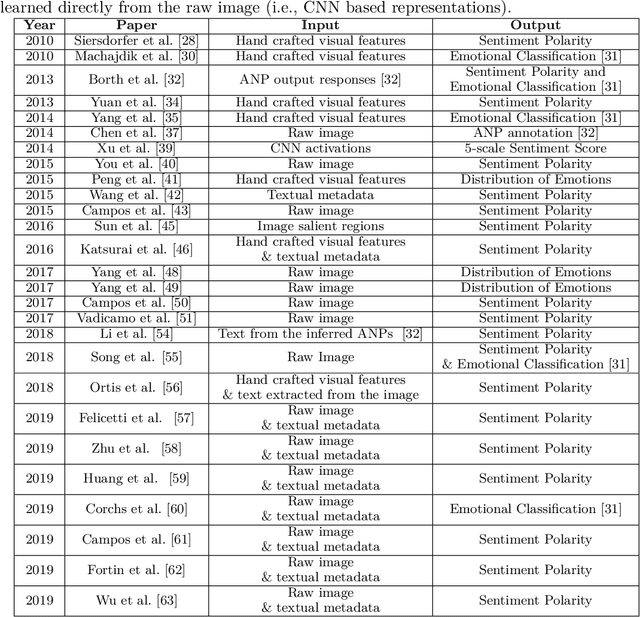
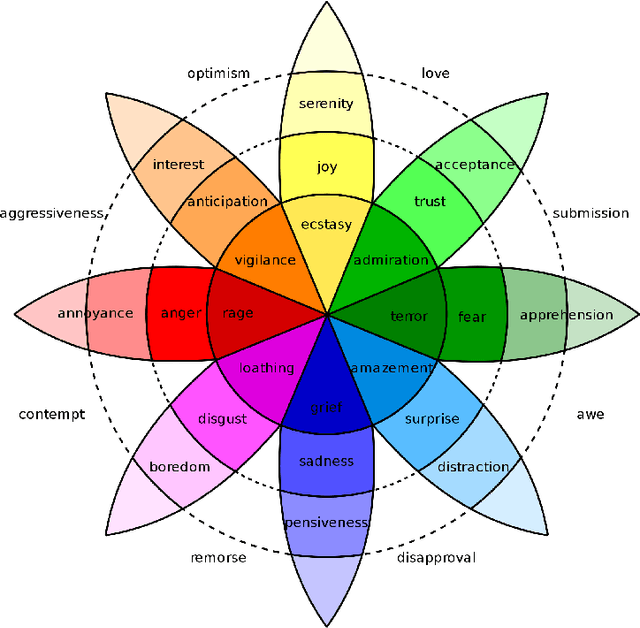
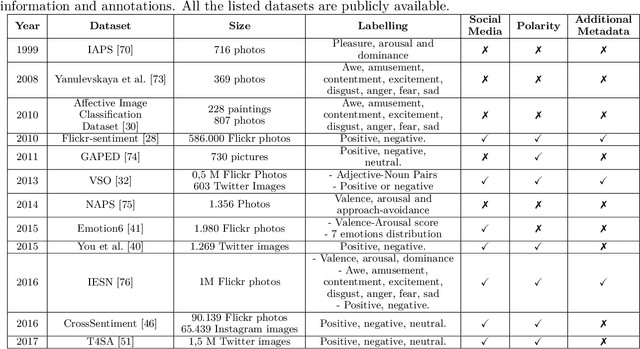
Visual Sentiment Analysis aims to understand how images affect people, in terms of evoked emotions. Although this field is rather new, a broad range of techniques have been developed for various data sources and problems, resulting in a large body of research. This paper reviews pertinent publications and tries to present an exhaustive overview of the field. After a description of the task and the related applications, the subject is tackled under different main headings. The paper also describes principles of design of general Visual Sentiment Analysis systems from three main points of view: emotional models, dataset definition, feature design. A formalization of the problem is discussed, considering different levels of granularity, as well as the components that can affect the sentiment toward an image in different ways. To this aim, this paper considers a structured formalization of the problem which is usually used for the analysis of text, and discusses it's suitability in the context of Visual Sentiment Analysis. The paper also includes a description of new challenges, the evaluation from the viewpoint of progress toward more sophisticated systems and related practical applications, as well as a summary of the insights resulting from this study.
An encoder-decoder-based method for COVID-19 lung infection segmentation
Jul 04, 2020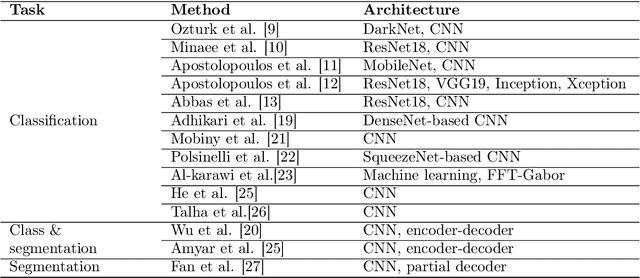
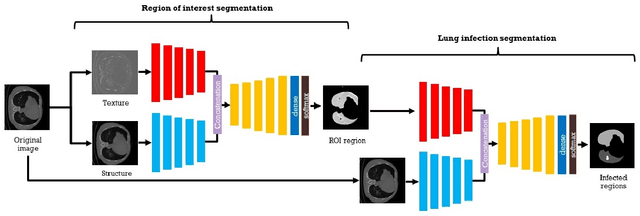
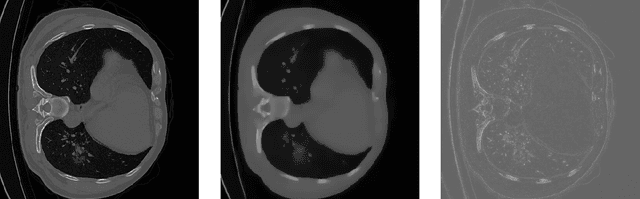
The novelty of the COVID-19 disease and the speed of spread has created a colossal chaos, impulse among researchers worldwide to exploit all the resources and capabilities to understand and analyze characteristics of the coronavirus in term of the ways it spreads and virus incubation time. For that, the existing medical features like CT and X-ray images are used. For example, CT-scan images can be used for the detection of lung infection. But the challenges of these features such as the quality of the image and infection characteristics limitate the effectiveness of these features. Using artificial intelligence (AI) tools and computer vision algorithms, the accuracy of detection can be more accurate and can help to overcome these issues. This paper proposes a multi-task deep-learning-based method for lung infection segmentation using CT-scan images. Our proposed method starts by segmenting the lung regions that can be infected. Then, segmenting the infections in these regions. Also, to perform a multi-class segmentation the proposed model is trained using the two-stream inputs. The multi-task learning used in this paper allows us to overcome shortage of labeled data. Also, the multi-input stream allows the model to do the learning on many features that can improve the results. To evaluate the proposed method, many features have been used. Also, from the experiments, the proposed method can segment lung infections with a high degree performance even with shortage of data and labeled images. In addition, comparing with the state-of-the-art method our method achieves good performance results.
Learning to Predict Context-adaptive Convolution for Semantic Segmentation
Apr 17, 2020
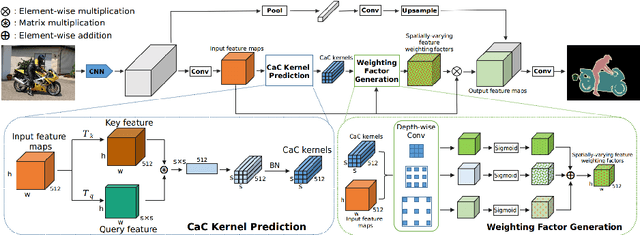
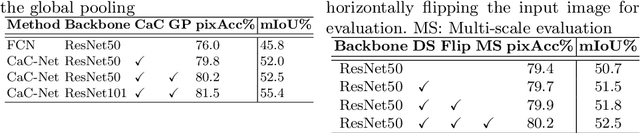

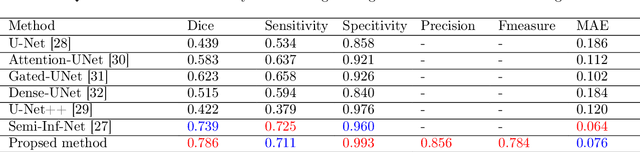
Long-range contextual information is essential for achieving high-performance semantic segmentation. Previous feature re-weighting methods demonstrate that using global context for re-weighting feature channels can effectively improve the accuracy of semantic segmentation. However, the globally-sharing feature re-weighting vector might not be optimal for regions of different classes in the input image. In this paper, we propose a Context-adaptive Convolution Network (CaC-Net) to predict a spatially-varying feature weighting vector for each spatial location of the semantic feature maps. In CaC-Net, a set of context-adaptive convolution kernels are predicted from the global contextual information in a parameter-efficient manner. When used for convolution with the semantic feature maps, the predicted convolutional kernels can generate the spatially-varying feature weighting factors capturing both global and local contextual information. Comprehensive experimental results show that our CaC-Net achieves superior segmentation performance on three public datasets, PASCAL Context, PASCAL VOC 2012 and ADE20K.
Scraping Social Media Photos Posted in Kenya and Elsewhere to Detect and Analyze Food Types
Aug 31, 2019
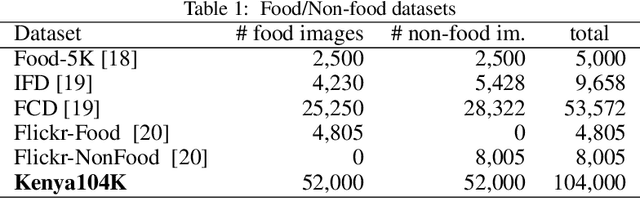

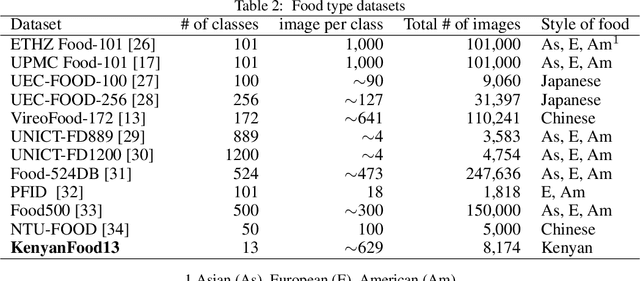
Monitoring population-level changes in diet could be useful for education and for implementing interventions to improve health. Research has shown that data from social media sources can be used for monitoring dietary behavior. We propose a scrape-by-location methodology to create food image datasets from Instagram posts. We used it to collect 3.56 million images over a period of 20 days in March 2019. We also propose a scrape-by-keywords methodology and used it to scrape ~30,000 images and their captions of 38 Kenyan food types. We publish two datasets of 104,000 and 8,174 image/caption pairs, respectively. With the first dataset, Kenya104K, we train a Kenyan Food Classifier, called KenyanFC, to distinguish Kenyan food from non-food images posted in Kenya. We used the second dataset, KenyanFood13, to train a classifier KenyanFTR, short for Kenyan Food Type Recognizer, to recognize 13 popular food types in Kenya. The KenyanFTR is a multimodal deep neural network that can identify 13 types of Kenyan foods using both images and their corresponding captions. Experiments show that the average top-1 accuracy of KenyanFC is 99% over 10,400 tested Instagram images and of KenyanFTR is 81% over 8,174 tested data points. Ablation studies show that three of the 13 food types are particularly difficult to categorize based on image content only and that adding analysis of captions to the image analysis yields a classifier that is 9 percent points more accurate than a classifier that relies only on images. Our food trend analysis revealed that cakes and roasted meats were the most popular foods in photographs on Instagram in Kenya in March 2019.
OrigamiNet: Weakly-Supervised, Segmentation-Free, One-Step, Full Page Text Recognition by learning to unfold
Jun 12, 2020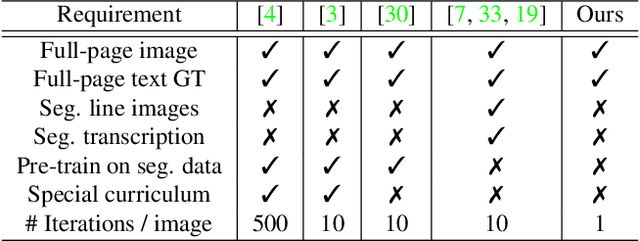
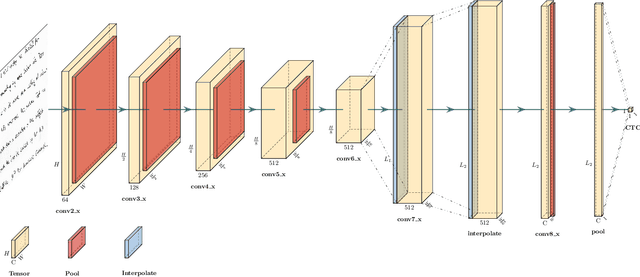
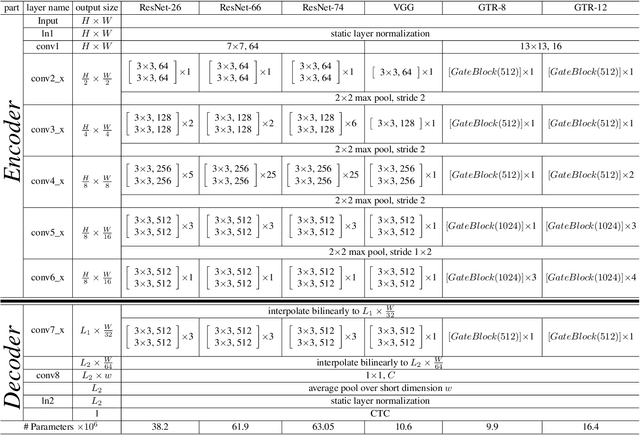

Text recognition is a major computer vision task with a big set of associated challenges. One of those traditional challenges is the coupled nature of text recognition and segmentation. This problem has been progressively solved over the past decades, going from segmentation based recognition to segmentation free approaches, which proved more accurate and much cheaper to annotate data for. We take a step from segmentation-free single line recognition towards segmentation-free multi-line / full page recognition. We propose a novel and simple neural network module, termed \textbf{OrigamiNet}, that can augment any CTC-trained, fully convolutional single line text recognizer, to convert it into a multi-line version by providing the model with enough spatial capacity to be able to properly collapse a 2D input signal into 1D without losing information. Such modified networks can be trained using exactly their same simple original procedure, and using only \textbf{unsegmented} image and text pairs. We carry out a set of interpretability experiments that show that our trained models learn an accurate implicit line segmentation. We achieve state-of-the-art character error rate on both IAM \& ICDAR 2017 HTR benchmarks for handwriting recognition, surpassing all other methods in the literature. On IAM we even surpass single line methods that use accurate localization information during training. Our code is available online at \url{https://github.com/IntuitionMachines/OrigamiNet}.
Beyond Photometric Consistency: Gradient-based Dissimilarity for Improving Visual Odometry and Stereo Matching
Apr 08, 2020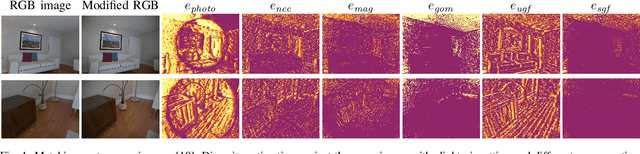
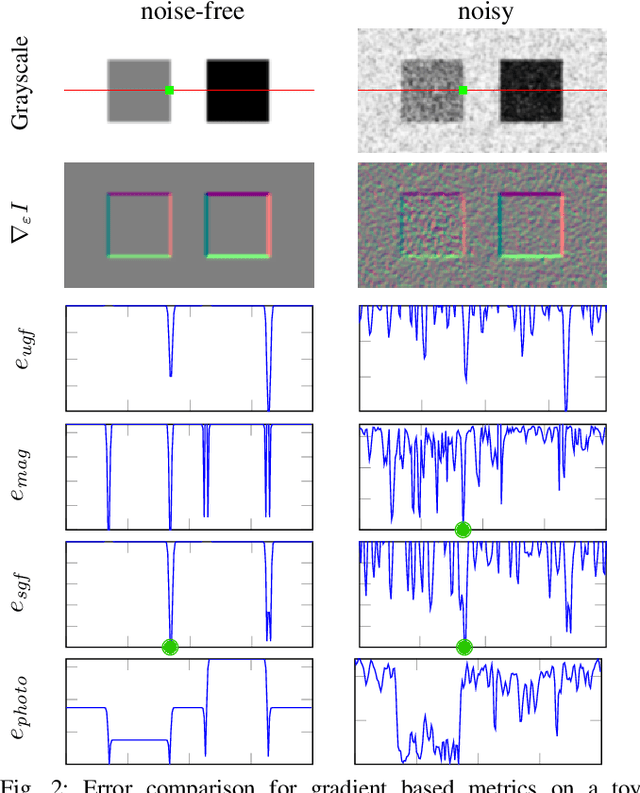
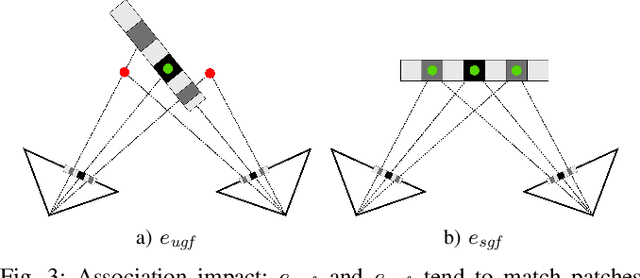
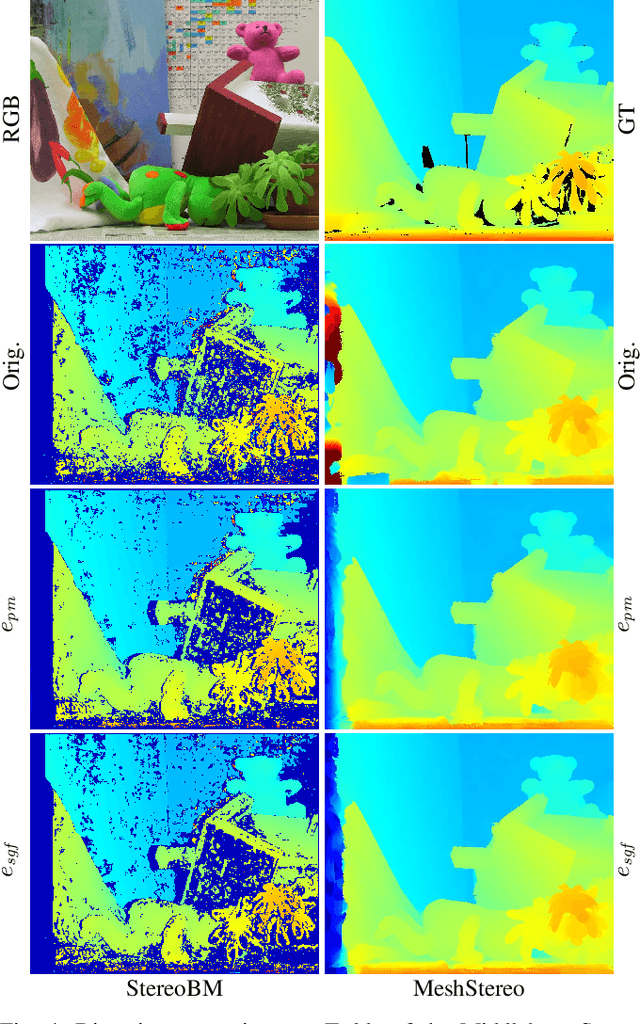
Pose estimation and map building are central ingredients of autonomous robots and typically rely on the registration of sensor data. In this paper, we investigate a new metric for registering images that builds upon on the idea of the photometric error. Our approach combines a gradient orientation-based metric with a magnitude-dependent scaling term. We integrate both into stereo estimation as well as visual odometry systems and show clear benefits for typical disparity and direct image registration tasks when using our proposed metric. Our experimental evaluation indicats that our metric leads to more robust and more accurate estimates of the scene depth as well as camera trajectory. Thus, the metric improves camera pose estimation and in turn the mapping capabilities of mobile robots. We believe that a series of existing visual odometry and visual SLAM systems can benefit from the findings reported in this paper.