 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attention Privileged Reinforcement Learning For Domain Transfer
Nov 19, 2019
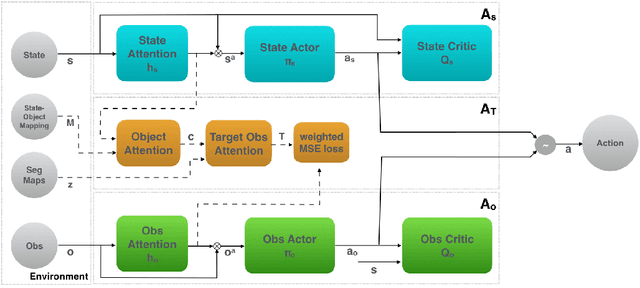
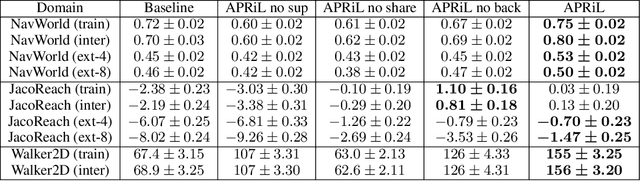
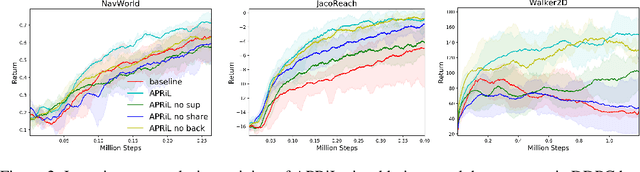
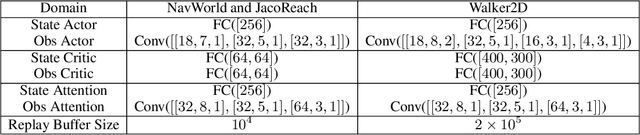
Applying reinforcement learning (RL) to physical systems presents notable challenges, given requirements regarding sample efficiency, safety, and physical constraints compared to simulated environments. To enable transfer of policies trained in simulation, randomising simulation parameters leads to more robust policies, but also significantly extends training time. In this paper, we exploit access to privileged information (such as environment states) often available in simulation, in order to improve and accelerate learning over randomised environments. We introduce Attention Privileged Reinforcement Learning (APRiL), which equips the agent with an attention mechanism and makes use of state information in simulation, learning to align attention between state- and image-based policies while additionally sharing generated data. During deployment we can apply the image-based policy to remove the requirement of access to additional information. We experimentally demonstrate accelerated and more robust learning on a number of diverse domains, leading to improved final performance for environments both within and outside the training distribution.
Answering Questions about Data Visualizations using Efficient Bimodal Fusion
Aug 05, 2019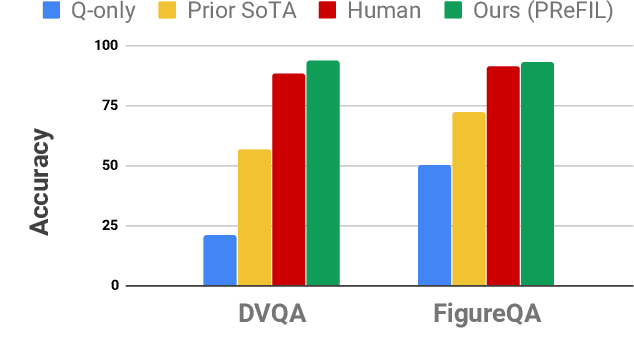

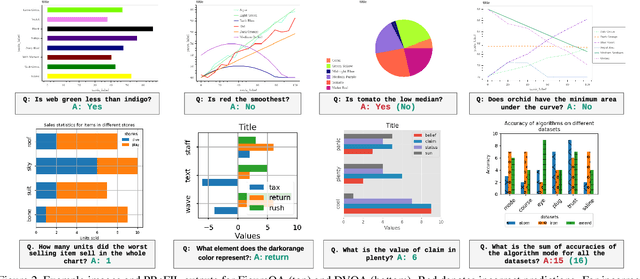
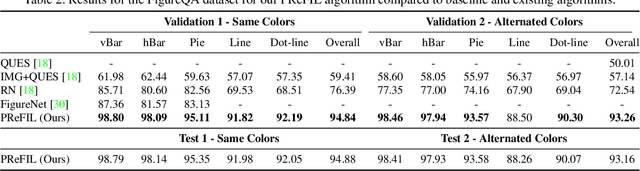
Chart question answering (CQA) is a newly proposed visual question answering (VQA) task where an algorithm must answer questions about data visualizations, e.g. bar charts, pie charts, and line graphs. CQA requires capabilities that natural-image VQA algorithms lack: fine-grained measurements, optical character recognition, and handling out-of-vocabulary words in both questions and answers. Without modifications, state-of-the-art VQA algorithms perform poorly on this task. Here, we propose a novel CQA algorithm called parallel recurrent fusion of image and language (PReFIL). PReFIL first learns bimodal embeddings by fusing question and image features and then intelligently aggregates these learned embeddings to answer the given question. Despite its simplicity, PReFIL greatly surpasses state-of-the art systems and human baselines on both the FigureQA and DVQA datasets. Additionally, we demonstrate that PReFIL can be used to reconstruct tables by asking a series of questions about a chart.
Covariance-engaged Classification of Sets via Linear Programming
Jun 26, 2020
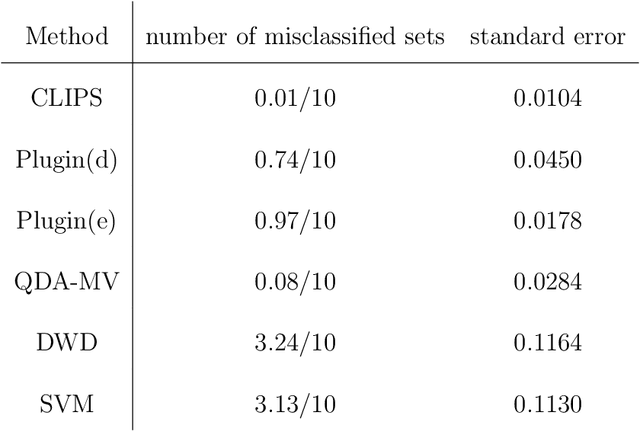
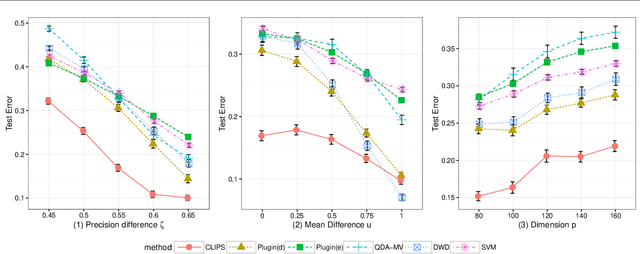
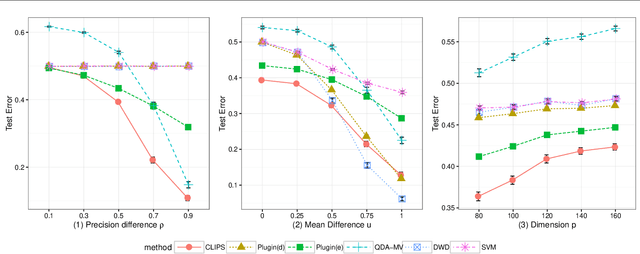
Set classification aims to classify a set of observations as a whole, as opposed to classifying individual observations separately. To formally understand the unfamiliar concept of binary set classification, we first investigate the optimal decision rule under the normal distribution, which utilizes the empirical covariance of the set to be classified. We show that the number of observations in the set plays a critical role in bounding the Bayes risk. Under this framework, we further propose new methods of set classification. For the case where only a few parameters of the model drive the difference between two classes, we propose a computationally-efficient approach to parameter estimation using linear programming, leading to the Covariance-engaged LInear Programming Set (CLIPS) classifier. Its theoretical properties are investigated for both independent case and various (short-range and long-range dependent) time series structures among observations within each set. The convergence rates of estimation errors and risk of the CLIPS classifier are established to show that having multiple observations in a set leads to faster convergence rates, compared to the standard classification situation in which there is only one observation in the set. The applicable domains in which the CLIPS performs better than competitors are highlighted in a comprehensive simulation study. Finally, we illustrate the usefulness of the proposed methods in classification of real image data in histopathology.
Compositional Visual Generation and Inference with Energy Based Models
Apr 13, 2020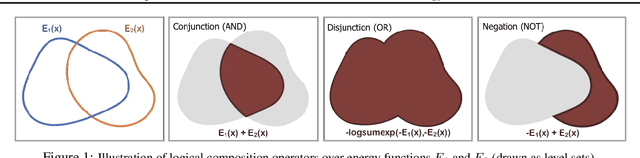
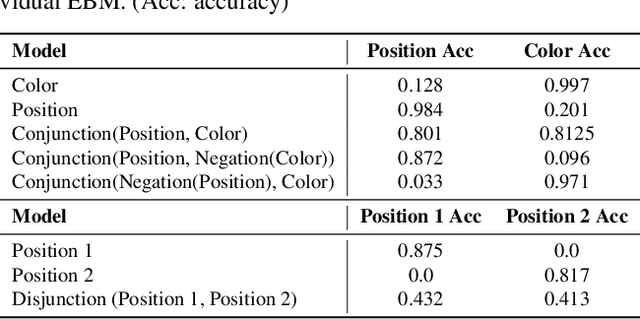
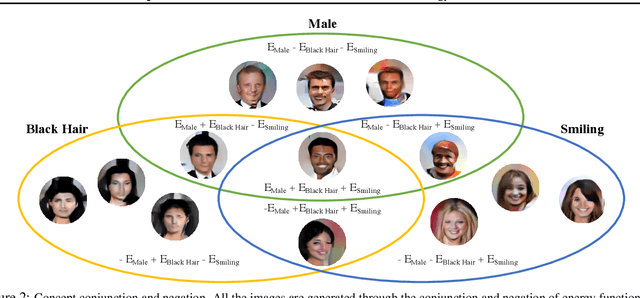
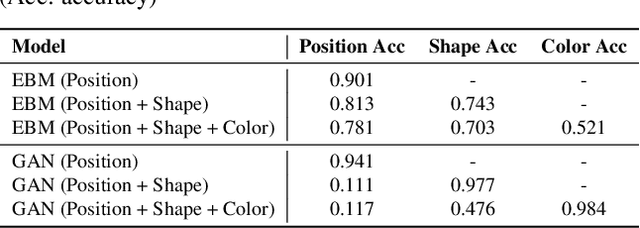
A vital aspect of human intelligence is the ability to compose increasingly complex concepts out of simpler ideas, enabling both rapid learning and adaptation of knowledge. In this paper we show that energy-based models can exhibit this ability by directly combining probability distributions. Samples from the combined distribution correspond to compositions of concepts. For example, given a distribution for smiling faces, and another for male faces, we can combine them to generate smiling male faces. This allows us to generate natural images that simultaneously satisfy conjunctions, disjunctions, and negations of concepts. We evaluate compositional generation abilities of our model on the CelebA dataset of natural faces and synthetic 3D scene images. We also demonstrate other unique advantages of our model, such as the ability to continually learn and incorporate new concepts, or infer compositions of concept properties underlying an image.
Cross-modal Language Generation using Pivot Stabilization for Web-scale Language Coverage
May 01, 2020
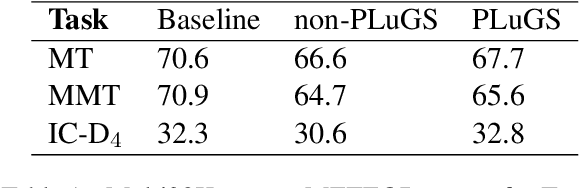
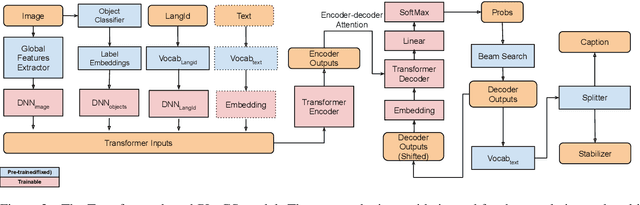
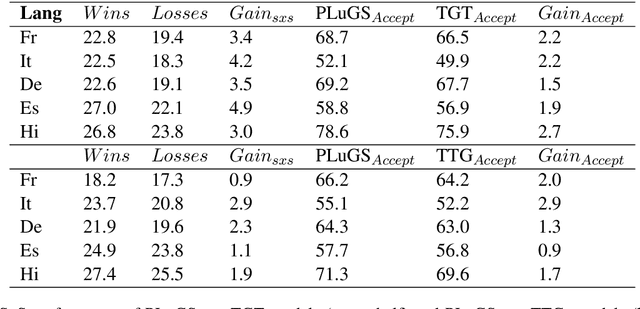
Cross-modal language generation tasks such as image captioning are directly hurt in their ability to support non-English languages by the trend of data-hungry models combined with the lack of non-English annotations. We investigate potential solutions for combining existing language-generation annotations in English with translation capabilities in order to create solutions at web-scale in both domain and language coverage. We describe an approach called Pivot-Language Generation Stabilization (PLuGS), which leverages directly at training time both existing English annotations (gold data) as well as their machine-translated versions (silver data); at run-time, it generates first an English caption and then a corresponding target-language caption. We show that PLuGS models outperform other candidate solutions in evaluations performed over 5 different target languages, under a large-domain testset using images from the Open Images dataset. Furthermore, we find an interesting effect where the English captions generated by the PLuGS models are better than the captions generated by the original, monolingual English model.
A Novel Learnable Gradient Descent Type Algorithm for Non-convex Non-smooth Inverse Problems
Mar 24, 2020
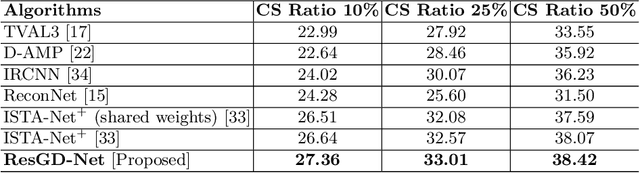


Optimization algorithms for solving nonconvex inverse problem have attracted significant interests recently. However, existing methods require the nonconvex regularization to be smooth or simple to ensure convergence. In this paper, we propose a novel gradient descent type algorithm, by leveraging the idea of residual learning and Nesterov's smoothing technique, to solve inverse problems consisting of general nonconvex and nonsmooth regularization with provable convergence. Moreover, we develop a neural network architecture intimating this algorithm to learn the nonlinear sparsity transformation adaptively from training data, which also inherits the convergence to accommodate the general nonconvex structure of this learned transformation. Numerical results demonstrate that the proposed network outperforms the state-of-the-art methods on a variety of different image reconstruction problems in terms of efficiency and accuracy.
Self-supervised classification of dynamic obstacles using the temporal information provided by videos
Oct 21, 2019



Nowadays, autonomous driving systems can detect, segment, and classify the surrounding obstacles using a monocular camera. However, state-of-the-art methods solving these tasks generally perform a fully supervised learning process and require a large amount of training labeled data. On another note, some self-supervised learning approaches can deal with detection and segmentation of dynamic obstacles using the temporal information available in video sequences. In this work, we propose in addition to classifiy the detected obstacles depending on their motion pattern. We present a novel self-supervised framework consisting of learning offline clusters from temporal patch sequences and using these clusters as pseudo labels to train a real-time image classifier. The presented model outperforms state-of-the-art unsupervised image classification methods on BDD100K dataset.
Augmented Reality on the Large Scene Based on a Markerless Registration Framework
Mar 03, 2020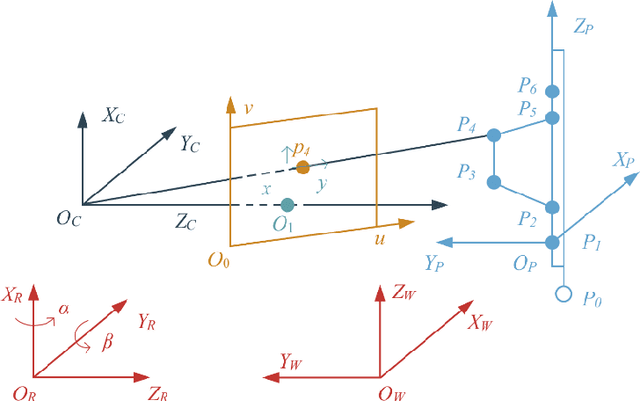

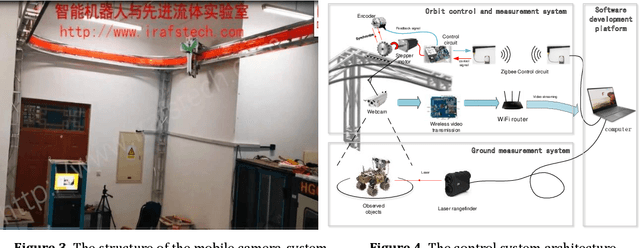
In this paper, a mobile camera positioning method based on forward and inverse kinematics of robot is proposed, which can realize far point positioning of imaging position and attitude tracking in large scene enhancement. Orbit precision motion through the framework overhead cameras and combining with the ground system of sensor array object such as mobile robot platform of various sensors, realize the good 3 d image registration, solve any artifacts that is mobile robot in the large space position initialization problem, effectively implement the large space no marks augmented reality, human-computer interaction, and information summary. Finally, the feasibility and effectiveness of the method are verified by experiments.
Image-based Vehicle Analysis using Deep Neural Network: A Systematic Study
Aug 07, 2016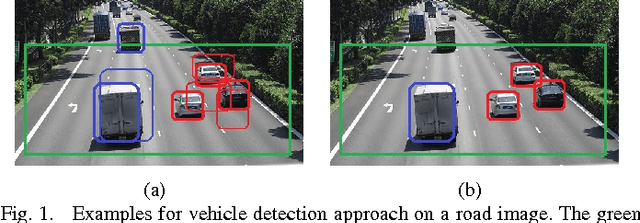

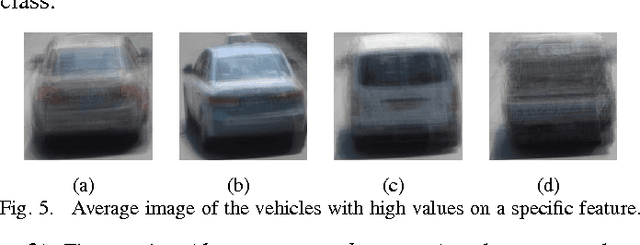

We address the vehicle detection and classification problems using Deep Neural Networks (DNNs) approaches. Here we answer to questions that are specific to our application including how to utilize DNN for vehicle detection, what features are useful for vehicle classification, and how to extend a model trained on a limited size dataset, to the cases of extreme lighting condition. Answering these questions we propose our approach that outperforms state-of-the-art methods, and achieves promising results on image with extreme lighting conditions.
Ricci Curvature Based Volumetric Segmentation of the Auditory Ossicles
Jun 26, 2020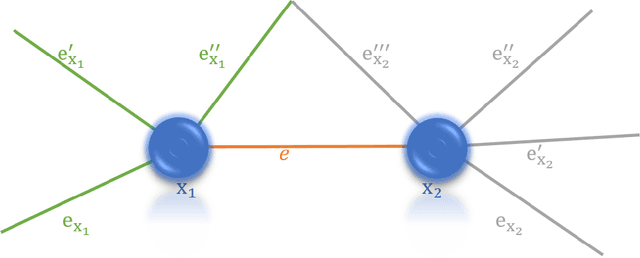
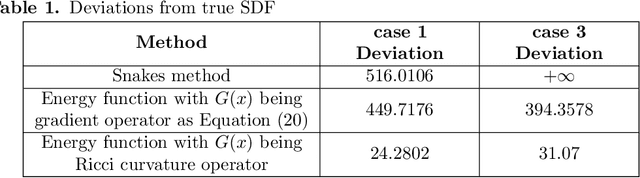
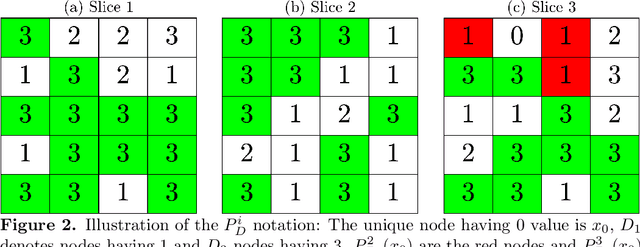
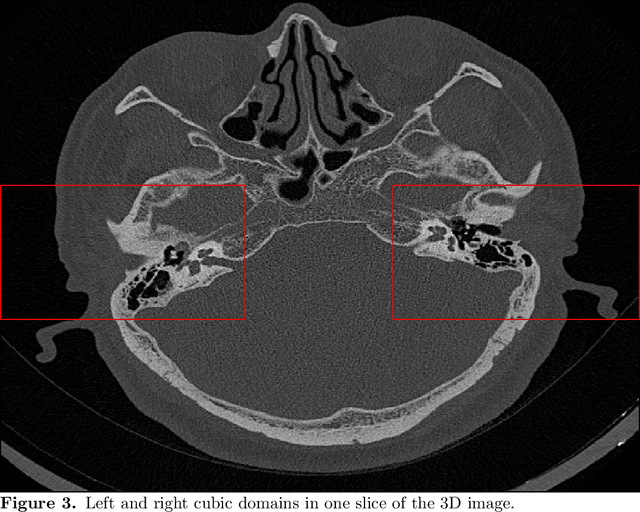
The auditory ossicles that are located in the middle ear are the smallest bones in the human body. Their damage will result in hearing loss. It is therefore important to be able to automatically diagnose ossicles' diseases based on Computed Tomography (CT) 3D imaging. However CT images usually include the whole head area, which is much larger than the bones of interest, thus the localization of the ossicles, followed by segmentation, both play a significant role in automatic diagnosis. The commonly employed local segmentation methods require manually selected initial points, which is a highly time consuming process. We therefore propose a completely automatic method to locate the ossicles which requires neither templates, nor manual labels. It relies solely on the connective properties of the auditory ossicles themselves, and their relationship with the surrounding tissue fluid. For the segmentation task, we define a novel energy function and obtain the shape of the ossicles from the 3D CT image by minimizing this new energy. Compared to the state-of-the-art methods which usually use the gradient operator and some normalization terms, we propose to add a Ricci curvature term to the commonly employed energy function. We compare our proposed method with the state-of-the-art methods and show that the performance of discrete Forman-Ricci curvature is superior to the others.