 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MORPHOLO C++ Library for glasses-free multi-view stereo vision and streaming of live 3D video
Dec 04, 2019
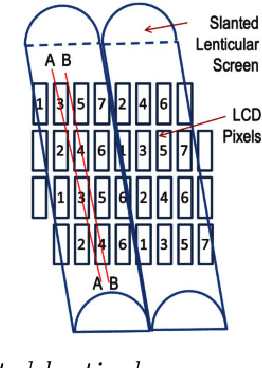

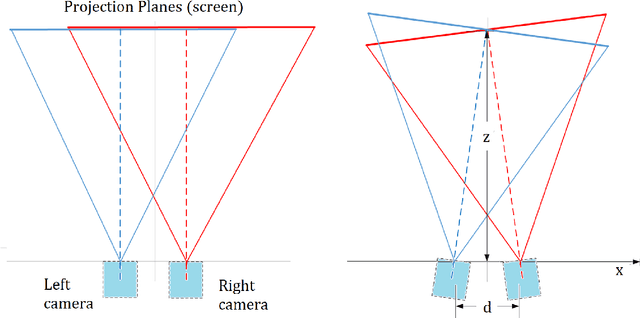
The MORPHOLO C++ extended Library allows to convert a specific stereoscopic snapshot into a Native multi-view image through morphing algorithms taking into account display calibration data for specific slanted lenticular 3D monitors. MORPHOLO can also be implemented for glasses-free live applicatons of 3D video streaming, and for diverse innovative scientific, engineering and 3D video game applications -see http://www.morpholo.it
NAMF: A Non-local Adaptive Mean Filter for Salt-and-Pepper Noise Removal
Oct 17, 2019
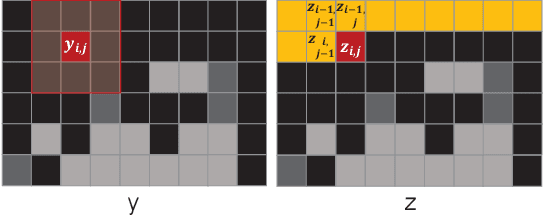

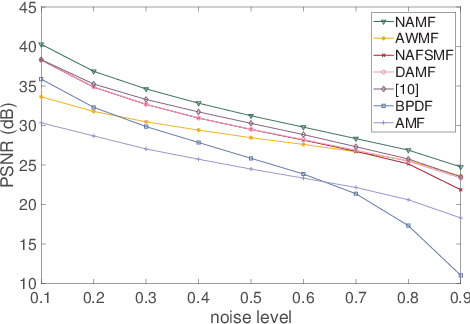
In this paper, a non-local adaptive mean filter (NAMF) is proposed, which can eliminate all levels of salt-and-pepper (SAP) noise. NAMF can be divided into two stages: (1) SAP noise detection; (2) SAP noise elimination. For a given pixel, firstly, we compare it with the maximum or minimum gray value of the noisy image, if it equals then we use a window with adaptive size to further determine whether it is noisy, and the noiseless pixel will be left. Secondly, the noisy pixel will be replaced by the combination of its neighboring pixels. And finally we use a SAP noise based non-local mean filter to further restore it. Our experimental results show that NAMF outperforms state-of-the-art methods in terms of quality for restoring image at all SAP noise levels.
Reducing Overlearning through Disentangled Representations by Suppressing Unknown Tasks
May 20, 2020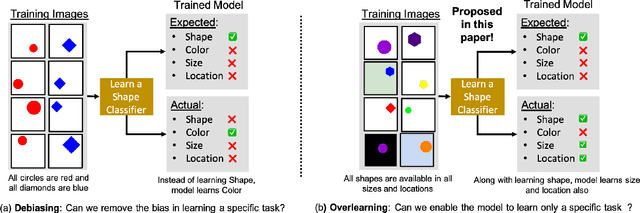
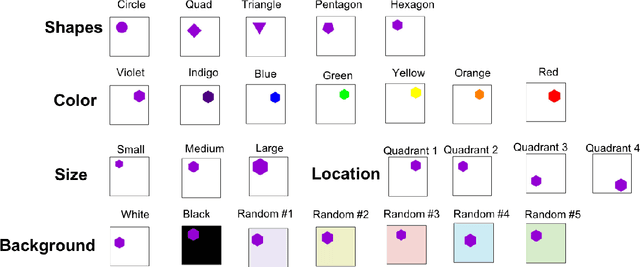
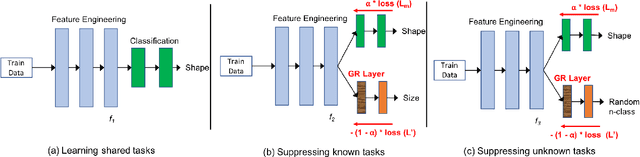
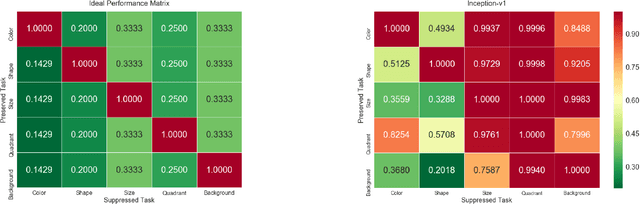
Existing deep learning approaches for learning visual features tend to overlearn and extract more information than what is required for the task at hand. From a privacy preservation perspective, the input visual information is not protected from the model; enabling the model to become more intelligent than it is trained to be. Current approaches for suppressing additional task learning assume the presence of ground truth labels for the tasks to be suppressed during training time. In this research, we propose a three-fold novel contribution: (i) a model-agnostic solution for reducing model overlearning by suppressing all the unknown tasks, (ii) a novel metric to measure the trust score of a trained deep learning model, and (iii) a simulated benchmark dataset, PreserveTask, having five different fundamental image classification tasks to study the generalization nature of models. In the first set of experiments, we learn disentangled representations and suppress overlearning of five popular deep learning models: VGG16, VGG19, Inception-v1, MobileNet, and DenseNet on PreserverTask dataset. Additionally, we show results of our framework on color-MNIST dataset and practical applications of face attribute preservation in Diversity in Faces (DiF) and IMDB-Wiki dataset.
Interpretable Time-series Classification on Few-shot Samples
Jun 03, 2020
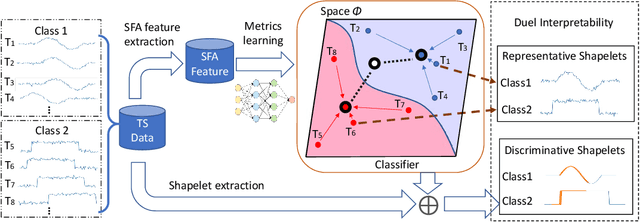
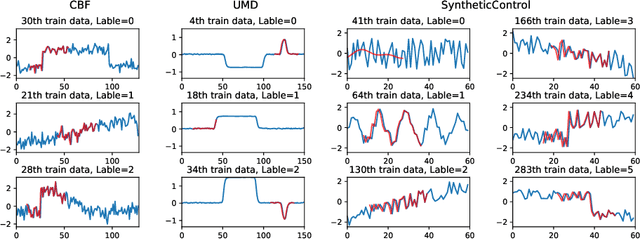
Recent few-shot learning works focus on training a model with prior meta-knowledge to fast adapt to new tasks with unseen classes and samples. However, conventional time-series classification algorithms fail to tackle the few-shot scenario. Existing few-shot learning methods are proposed to tackle image or text data, and most of them are neural-based models that lack interpretability. This paper proposes an interpretable neural-based framework, namely \textit{Dual Prototypical Shapelet Networks (DPSN)} for few-shot time-series classification, which not only trains a neural network-based model but also interprets the model from dual granularity: 1) global overview using representative time series samples, and 2) local highlights using discriminative shapelets. In particular, the generated dual prototypical shapelets consist of representative samples that can mostly demonstrate the overall shapes of all samples in the class and discriminative partial-length shapelets that can be used to distinguish different classes. We have derived 18 few-shot TSC datasets from public benchmark datasets and evaluated the proposed method by comparing with baselines. The DPSN framework outperforms state-of-the-art time-series classification methods, especially when training with limited amounts of data. Several case studies have been given to demonstrate the interpret ability of our model.
SketchGCN: Semantic Sketch Segmentation with Graph Convolutional Networks
Mar 02, 2020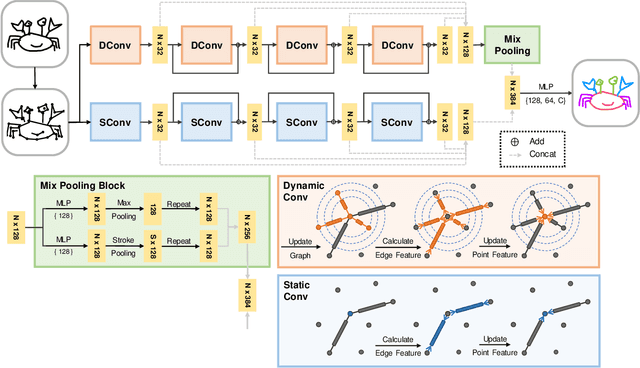
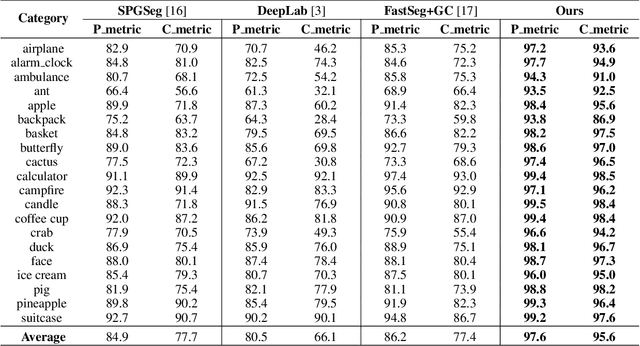
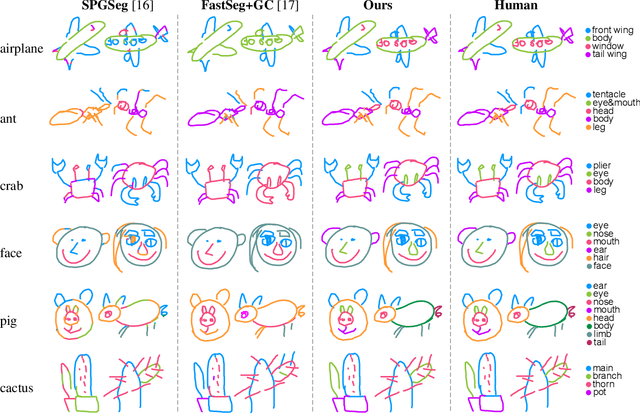
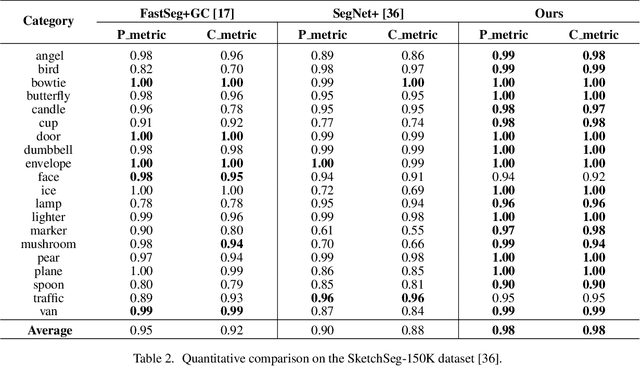
We introduce SketchGCN, a graph convolutional neural network for semantic segmentation and labeling of free-hand sketches. We treat an input sketch as a 2D pointset, and encode the stroke structure information into graph node/edge representations. To predict the per-point labels, our SketchGCN uses graph convolution and a global-local branching network architecture to extract both intra-stroke and inter-stroke features. SketchGCN significantly improves the accuracy of the state-of-the-art methods for semantic sketch segmentation (by 11.4% in the pixel-basedmetric and 18.2% in the component-based metric over a large-scale challenging SPG dataset) and has magnitudes fewer parameters than both image-based and sequence-based methods.
Explanation by Progressive Exaggeration
Nov 05, 2019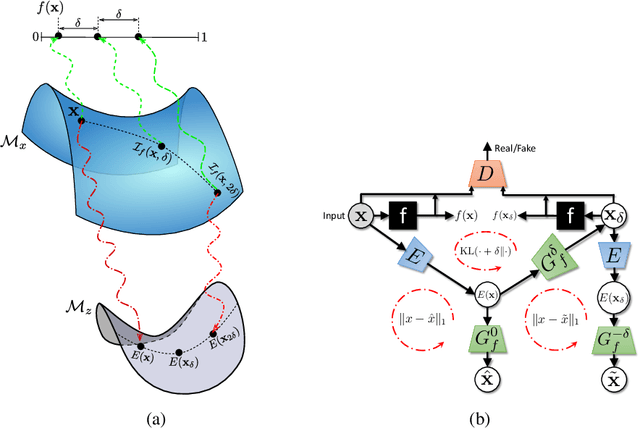

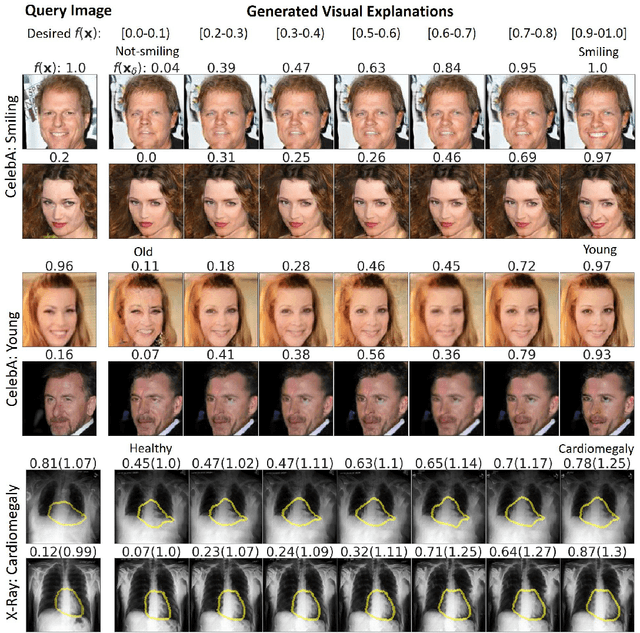

As machine learning methods see greater adoption and implementation in high stakes applications such as medical image diagnosis, the need for model interpretability and explanation has become more critical. Classical approaches that assess feature importance (e.g. saliency maps) do not explain how and why a particular region of an image is relevant to the prediction. We propose a method that explains the outcome of a classification black-box by gradually exaggerating the semantic effect of a given class. Given a query input to a classifier, our method produces a progressive set of plausible variations of that query, which gradually changes the posterior probability from its original class to its negation. These counter-factually generated samples preserve features unrelated to the classification decision, such that a user can employ our method as a "tuning knob" to traverse a data manifold while crossing the decision boundary. Our method is model agnostic and only requires the output value and gradient of the predictor with respect to its input.
Slowing Down the Weight Norm Increase in Momentum-based Optimizers
Jun 15, 2020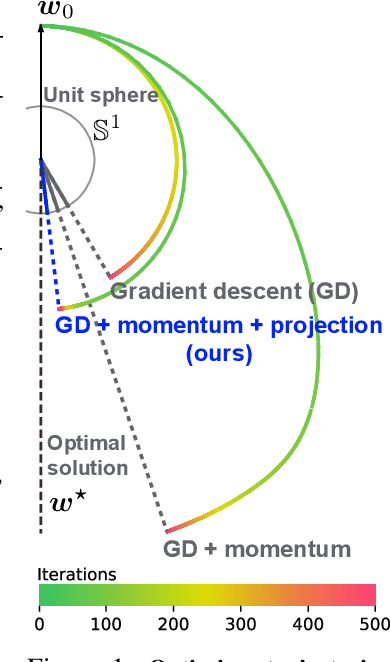

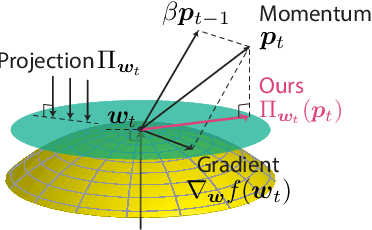
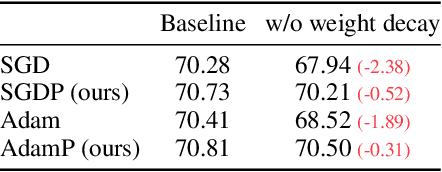
Normalization techniques, such as batch normalization (BN), have led to significant improvements in deep neural network performances. Prior studies have analyzed the benefits of the resulting scale invariance of the weights for the gradient descent (GD) optimizers: it leads to a stabilized training due to the auto-tuning of step sizes. However, we show that, combined with the momentum-based algorithms, the scale invariance tends to induce an excessive growth of the weight norms. This in turn overly suppresses the effective step sizes during training, potentially leading to sub-optimal performances in deep neural networks. We analyze this phenomenon both theoretically and empirically. We propose a simple and effective solution: at each iteration of momentum-based GD optimizers (e.g. SGD or Adam) applied on scale-invariant weights (e.g. Conv weights preceding a BN layer), we remove the radial component (i.e. parallel to the weight vector) from the update vector. Intuitively, this operation prevents the unnecessary update along the radial direction that only increases the weight norm without contributing to the loss minimization. We verify that the modified optimizers SGDP and AdamP successfully regularize the norm growth and improve the performance of a broad set of models. Our experiments cover tasks including image classification and retrieval, object detection, robustness benchmarks, and audio classification. Source code is available at https://github.com/clovaai/AdamP.
MA 3 : Model Agnostic Adversarial Augmentation for Few Shot learning
Apr 10, 2020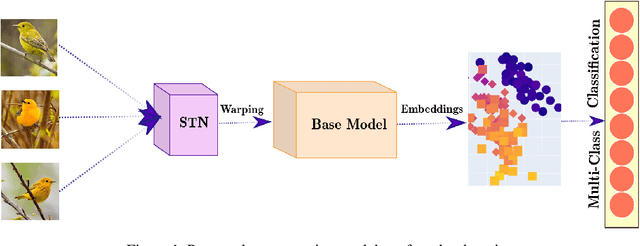
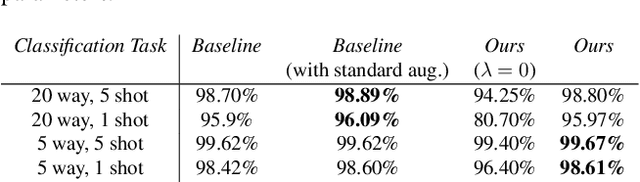
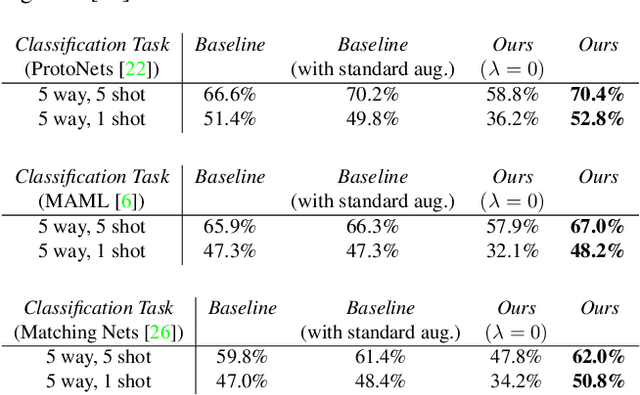
Despite the recent developments in vision-related problems using deep neural networks, there still remains a wide scope in the improvement of generalizing these models to unseen examples. In this paper, we explore the domain of few-shot learning with a novel augmentation technique. In contrast to other generative augmentation techniques, where the distribution over input images are learnt, we propose to learn the probability distribution over the image transformation parameters which are easier and quicker to learn. Our technique is fully differentiable which enables its extension to versatile data-sets and base models. We evaluate our proposed method on multiple base-networks and 2 data-sets to establish the robustness and efficiency of this method. We obtain an improvement of nearly 4% by adding our augmentation module without making any change in network architectures. We also make the code readily available for usage by the community.
AdvGAN++ : Harnessing latent layers for adversary generation
Aug 02, 2019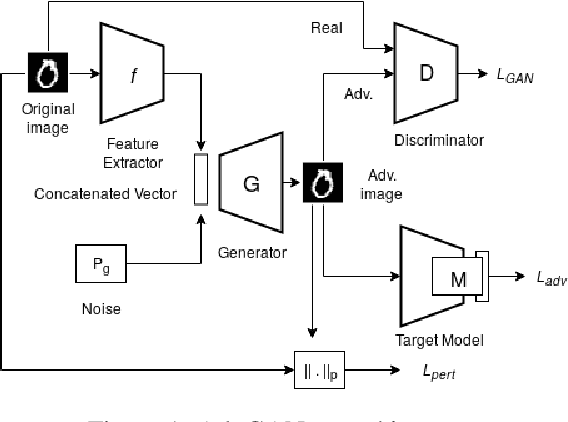
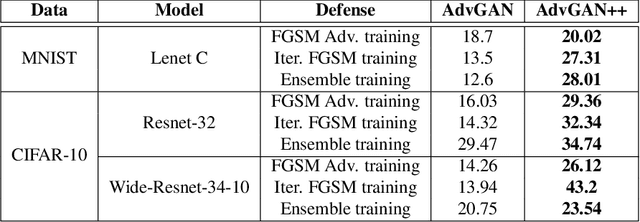
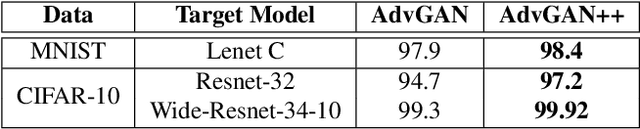

Adversarial examples are fabricated examples, indistinguishable from the original image that mislead neural networks and drastically lower their performance. Recently proposed AdvGAN, a GAN based approach, takes input image as a prior for generating adversaries to target a model. In this work, we show how latent features can serve as better priors than input images for adversary generation by proposing AdvGAN++, a version of AdvGAN that achieves higher attack rates than AdvGAN and at the same time generates perceptually realistic images on MNIST and CIFAR-10 datasets.
Vid2Curve: Simultaneous Camera Motion Estimation and Thin Structure Reconstruction from an RGB Video
May 20, 2020
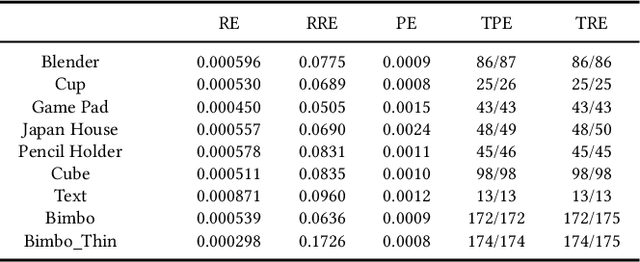
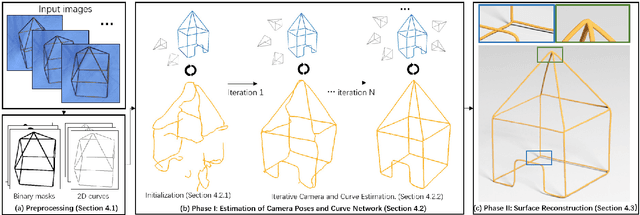
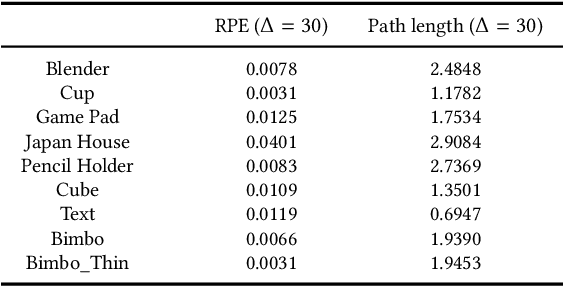
Thin structures, such as wire-frame sculptures, fences, cables, power lines, and tree branches, are common in the real world. It is extremely challenging to acquire their 3D digital models using traditional image-based or depth-based reconstruction methods because thin structures often lack distinct point features and have severe self-occlusion. We propose the first approach that simultaneously estimates camera motion and reconstructs the geometry of complex 3D thin structures in high quality from a color video captured by a handheld camera. Specifically, we present a new curve-based approach to estimate accurate camera poses by establishing correspondences between featureless thin objects in the foreground in consecutive video frames, without requiring visual texture in the background scene to lock on. Enabled by this effective curve-based camera pose estimation strategy, we develop an iterative optimization method with tailored measures on geometry, topology as well as self-occlusion handling for reconstructing 3D thin structures. Extensive validations on a variety of thin structures show that our method achieves accurate camera pose estimation and faithful reconstruction of 3D thin structures with complex shape and topology at a level that has not been attained by other existing reconstruction methods.