 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Energy-Based Processes for Exchangeable Data
Mar 17, 2020
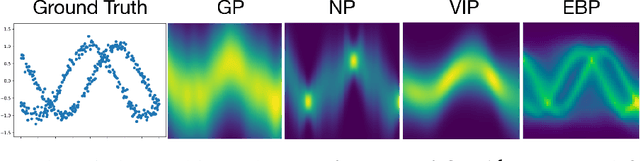
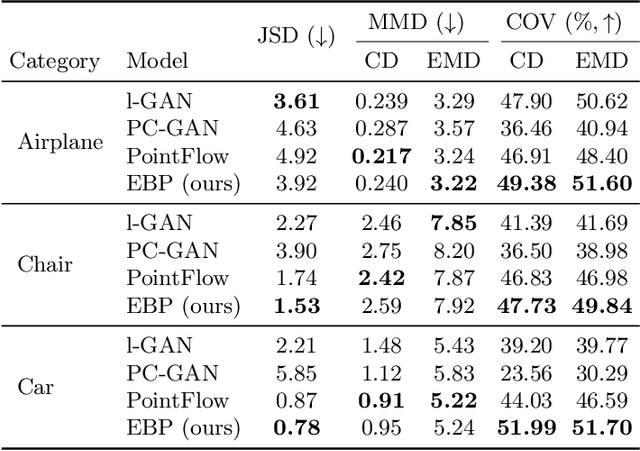


Recently there has been growing interest in modeling sets with exchangeability such as point clouds. A shortcoming of current approaches is that they restrict the cardinality of the sets considered or can only express limited forms of distribution over unobserved data. To overcome these limitations, we introduce Energy-Based Processes (EBPs), which extend energy based models to exchangeable data while allowing neural network parameterizations of the energy function. A key advantage of these models is the ability to express more flexible distributions over sets without restricting their cardinality. We develop an efficient training procedure for EBPs that demonstrates state-of-the-art performance on a variety of tasks such as point cloud generation, classification, denoising, and image completion.
From Real to Synthetic and Back: Synthesizing Training Data for Multi-Person Scene Understanding
Jun 03, 2020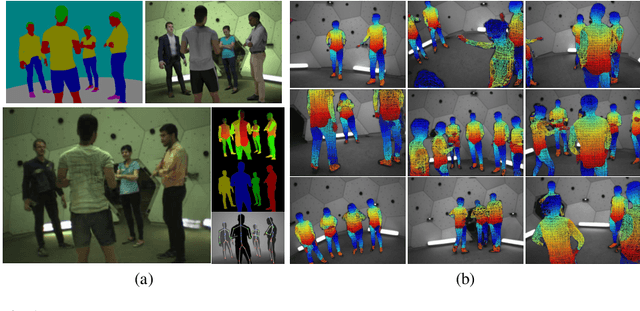
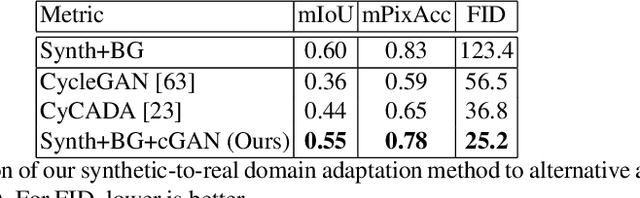
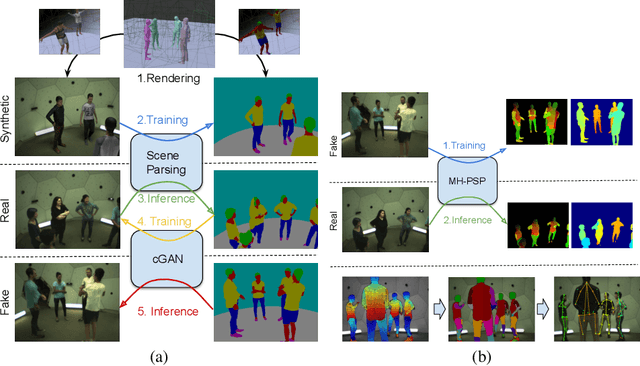
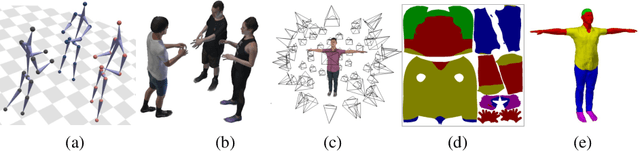
We present a method for synthesizing naturally looking images of multiple people interacting in a specific scenario. These images benefit from the advantages of synthetic data: being fully controllable and fully annotated with any type of standard or custom-defined ground truth. To reduce the synthetic-to-real domain gap, we introduce a pipeline consisting of the following steps: 1) we render scenes in a context modeled after the real world, 2) we train a human parsing model on the synthetic images, 3) we use the model to estimate segmentation maps for real images, 4) we train a conditional generative adversarial network (cGAN) to learn the inverse mapping -- from a segmentation map to a real image, and 5) given new synthetic segmentation maps, we use the cGAN to generate realistic images. An illustration of our pipeline is presented in Figure 2. We use the generated data to train a multi-task model on the challenging tasks of UV mapping and dense depth estimation. We demonstrate the value of the data generation and the trained model, both quantitatively and qualitatively on the CMU Panoptic Dataset.
Deep learning approaches for neural decoding: from CNNs to LSTMs and spikes to fMRI
May 19, 2020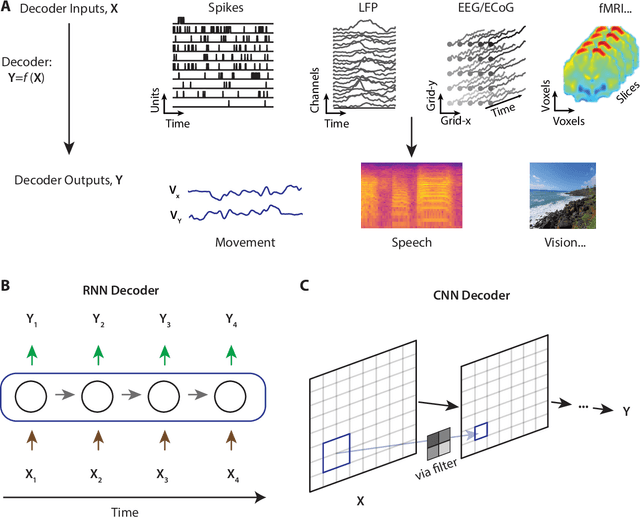
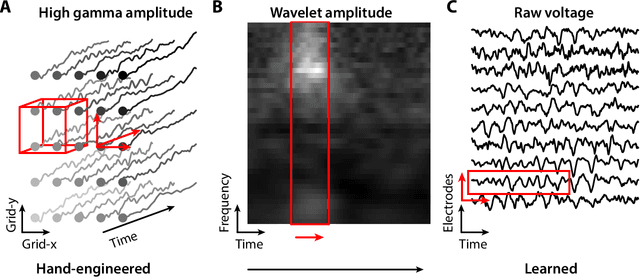
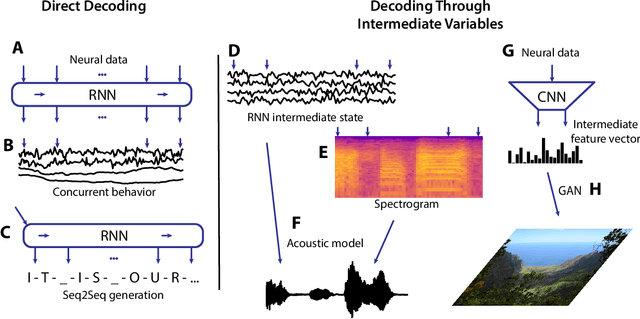
Decoding behavior, perception, or cognitive state directly from neural signals has applications in brain-computer interface research as well as implications for systems neuroscience. In the last decade, deep learning has become the state-of-the-art method in many machine learning tasks ranging from speech recognition to image segmentation. The success of deep networks in other domains has led to a new wave of applications in neuroscience. In this article, we review deep learning approaches to neural decoding. We describe the architectures used for extracting useful features from neural recording modalities ranging from spikes to EEG. Furthermore, we explore how deep learning has been leveraged to predict common outputs including movement, speech, and vision, with a focus on how pretrained deep networks can be incorporated as priors for complex decoding targets like acoustic speech or images. Deep learning has been shown to be a useful tool for improving the accuracy and flexibility of neural decoding across a wide range of tasks, and we point out areas for future scientific development.
Improved Noisy Student Training for Automatic Speech Recognition
May 19, 2020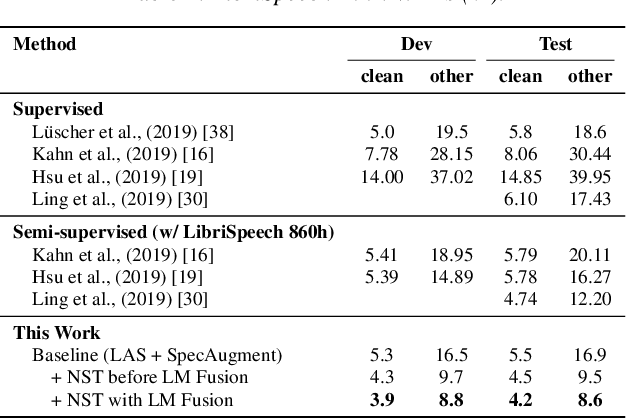
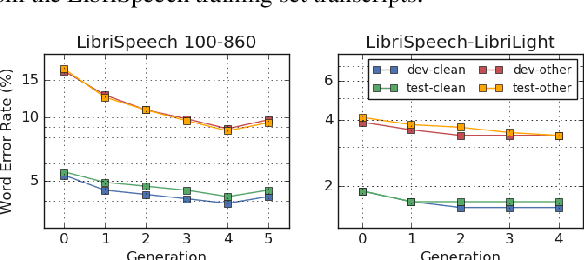
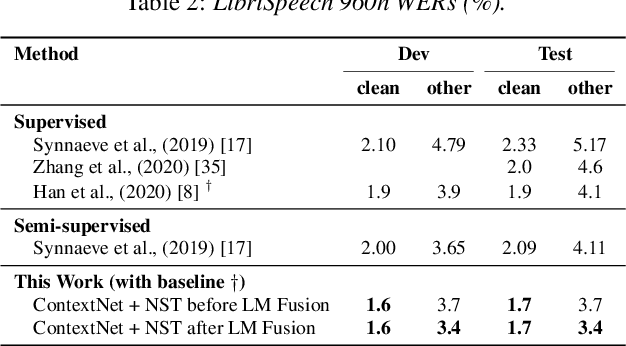
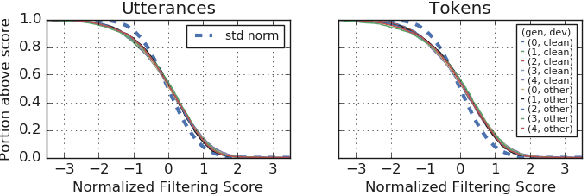
Recently, a semi-supervised learning method known as "noisy student training" has been shown to improve image classification performance of deep networks significantly. Noisy student training is an iterative self-training method that leverages augmentation to improve network performance. In this work, we adapt and improve noisy student training for automatic speech recognition, employing (adaptive) SpecAugment as the augmentation method. We find effective methods to filter, balance and augment the data generated in between self-training iterations. By doing so, we are able to obtain word error rates (WERs) 4.2%/8.6% on the clean/noisy LibriSpeech test sets by only using the clean 100h subset of LibriSpeech as the supervised set and the rest (860h) as the unlabeled set. Furthermore, we are able to achieve WERs 1.7%/3.4% on the clean/noisy LibriSpeech test sets by using the unlab-60k subset of LibriLight as the unlabeled set for LibriSpeech 960h. We are thus able to improve upon the previous state-of-the-art clean/noisy test WERs achieved on LibriSpeech 100h (4.74%/12.20%) and LibriSpeech (1.9%/4.1%).
Guiding Monocular Depth Estimation Using Depth-Attention Volume
Apr 06, 2020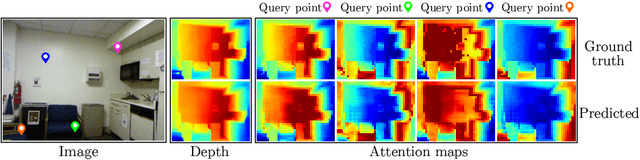
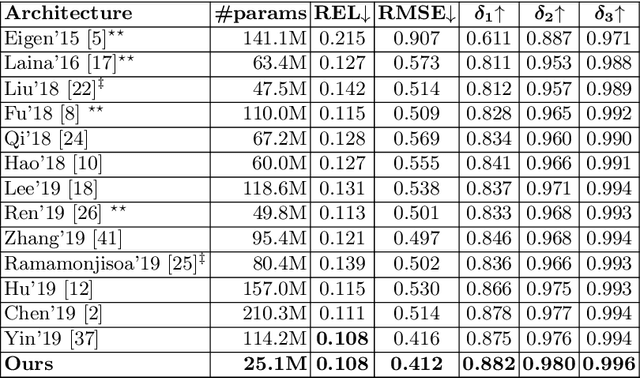
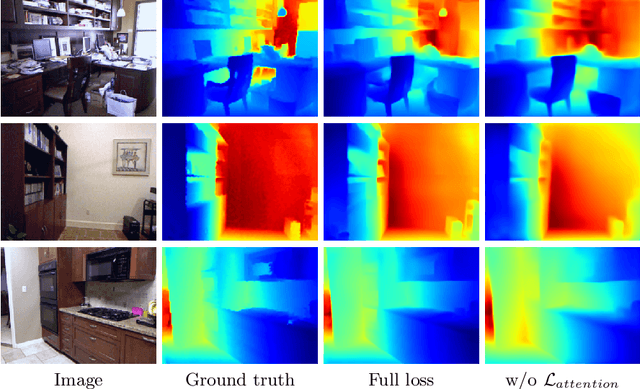
Recovering the scene depth from a single image is an ill-posed problem that requires additional priors, often referred to as monocular depth cues, to disambiguate different 3D interpretations. In recent works, those priors have been learned in an end-to-end manner from large datasets by using deep neural networks. In this paper, we propose guiding depth estimation to favor planar structures that are ubiquitous especially in indoor environments. This is achieved by incorporating a non-local coplanarity constraint to the network with a novel attention mechanism called depth-attention volume (DAV). Experiments on two popular indoor datasets, namely NYU-Depth-v2 and ScanNet, show that our method achieves state-of-the-art depth estimation results while using only a fraction of the number of parameters needed by the competing methods.
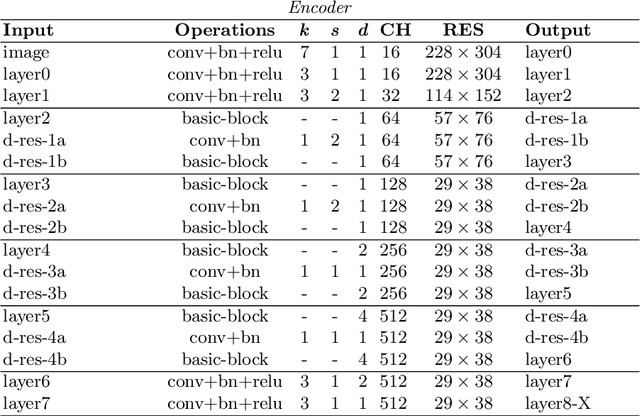
Neural Voxel Renderer: Learning an Accurate and Controllable Rendering Tool
Dec 10, 2019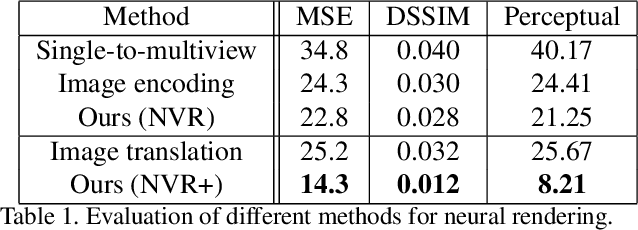
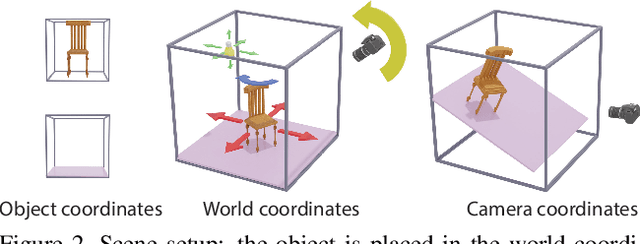

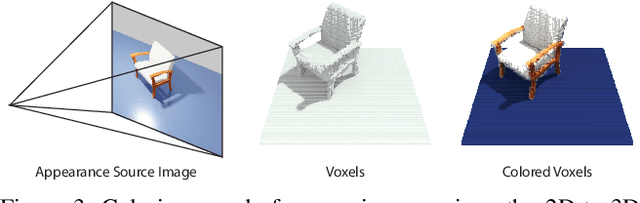
We present a neural rendering framework that maps a voxelized scene into a high quality image. Highly-textured objects and scene element interactions are realistically rendered by our method, despite having a rough representation as an input. Moreover, our approach allows controllable rendering: geometric and appearance modifications in the input are accurately propagated to the output. The user can move, rotate and scale an object, change its appearance and texture or modify the position of the light and all these edits are represented in the final rendering. We demonstrate the effectiveness of our approach by rendering scenes with varying appearance, from single color per object to complex, high-frequency textures. We show that our rerendering network can generate very detailed images that represent precisely the appearance of the input scene. Our experiments illustrate that our approach achieves more accurate image synthesis results compared to alternatives and can also handle low voxel grid resolutions. Finally, we show how our neural rendering framework can capture and faithfully render objects from real images and from a diverse set of classes.
PDCOVIDNet: A Parallel-Dilated Convolutional Neural Network Architecture for Detecting COVID-19 from Chest X-Ray Images
Jul 29, 2020

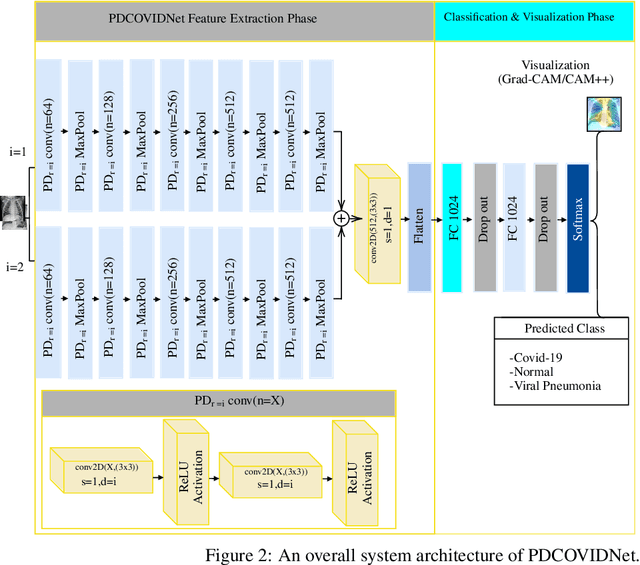
The COVID-19 pandemic continues to severely undermine the prosperity of the global health system. To combat this pandemic, effective screening techniques for infected patients are indispensable. There is no doubt that the use of chest X-ray images for radiological assessment is one of the essential screening techniques. Some of the early studies revealed that the patient's chest X-ray images showed abnormalities, which is natural for patients infected with COVID-19. In this paper, we proposed a parallel-dilated convolutional neural network (CNN) based COVID-19 detection system from chest x-ray images, named as Parallel-Dilated COVIDNet (PDCOVIDNet). First, the publicly available chest X-ray collection fully preloaded and enhanced, and then classified by the proposed method. Differing convolution dilation rate in a parallel form demonstrates the proof-of-principle for using PDCOVIDNet to extract radiological features for COVID-19 detection. Accordingly, we have assisted our method with two visualization methods, which are specifically designed to increase understanding of the key components associated with COVID-19 infection. Both visualization methods compute gradients for a given image category related to feature maps of the last convolutional layer to create a class-discriminative region. In our experiment, we used a total of 2,905 chest X-ray images, comprising three cases (such as COVID-19, normal, and viral pneumonia), and empirical evaluations revealed that the proposed method extracted more significant features expeditiously related to the suspected disease. The experimental results demonstrate that our proposed method significantly improves performance metrics: accuracy, precision, recall, and F1 scores reach 96.58%, 96.58%, 96.59%, and 96.58%, respectively, which is comparable or enhanced compared with the state-of-the-art methods.
Med3D: Transfer Learning for 3D Medical Image Analysis
Apr 09, 2019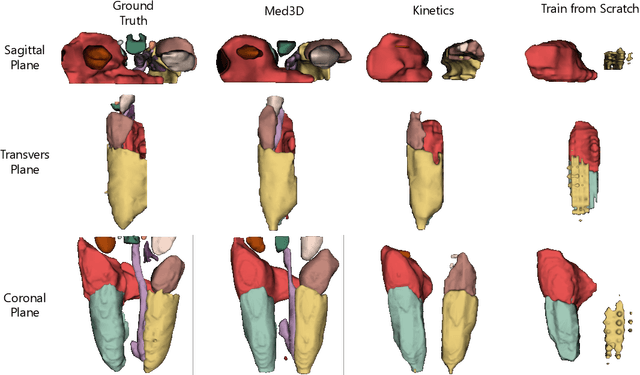
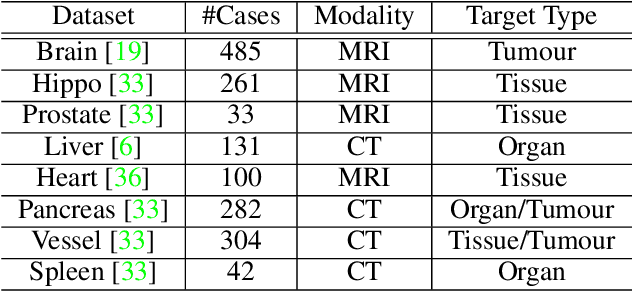
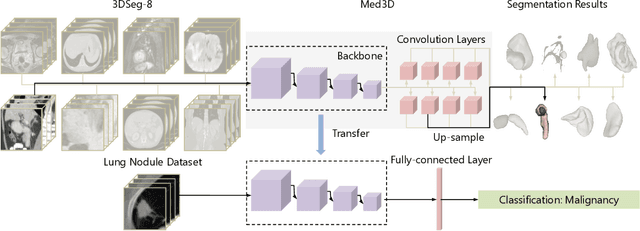
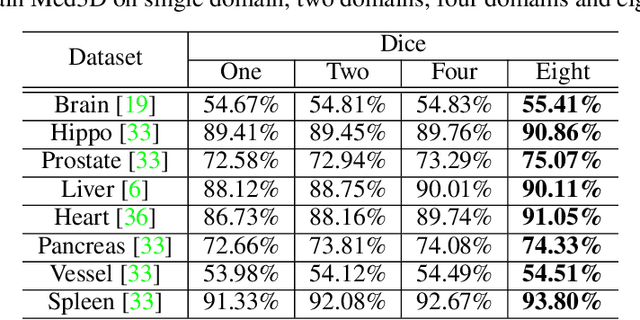
The performance on deep learning is significantly affected by volume of training data. Models pre-trained from massive dataset such as ImageNet become a powerful weapon for speeding up training convergence and improving accuracy. Similarly, models based on large dataset are important for the development of deep learning in 3D medical images. However, it is extremely challenging to build a sufficiently large dataset due to difficulty of data acquisition and annotation in 3D medical imaging. We aggregate the dataset from several medical challenges to build 3DSeg-8 dataset with diverse modalities, target organs, and pathologies. To extract general medical three-dimension (3D) features, we design a heterogeneous 3D network called Med3D to co-train multi-domain 3DSeg-8 so as to make a series of pre-trained models. We transfer Med3D pre-trained models to lung segmentation in LIDC dataset, pulmonary nodule classification in LIDC dataset and liver segmentation on LiTS challenge. Experiments show that the Med3D can accelerate the training convergence speed of target 3D medical tasks 2 times compared with model pre-trained on Kinetics dataset, and 10 times compared with training from scratch as well as improve accuracy ranging from 3% to 20%. Transferring our Med3D model on state-the-of-art DenseASPP segmentation network, in case of single model, we achieve 94.6\% Dice coefficient which approaches the result of top-ranged algorithms on the LiTS challenge.
Coronavirus Detection and Analysis on Chest CT with Deep Learning
Apr 06, 2020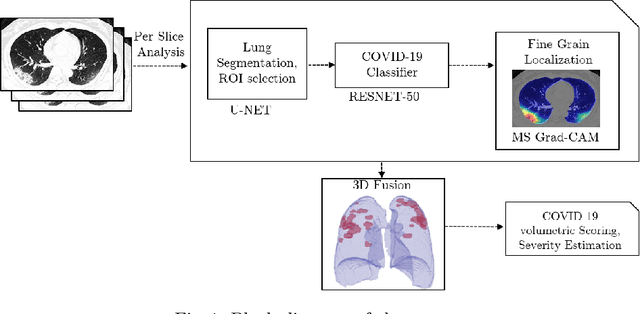


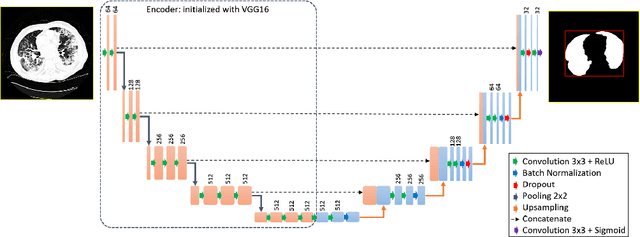
The outbreak of the novel coronavirus, officially declared a global pandemic, has a severe impact on our daily lives. As of this writing there are approximately 197,188 confirmed cases of which 80,881 are in "Mainland China" with 7,949 deaths, a mortality rate of 3.4%. In order to support radiologists in this overwhelming challenge, we develop a deep learning based algorithm that can detect, localize and quantify severity of COVID-19 manifestation from chest CT scans. The algorithm is comprised of a pipeline of image processing algorithms which includes lung segmentation, 2D slice classification and fine grain localization. In order to further understand the manifestations of the disease, we perform unsupervised clustering of abnormal slices. We present our results on a dataset comprised of 110 confirmed COVID-19 patients from Zhejiang province, China.
Guided Super-Resolution as a Learned Pixel-to-Pixel Transformation
Apr 02, 2019
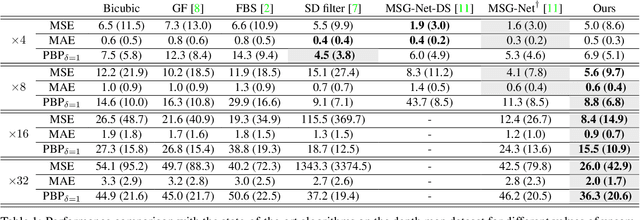
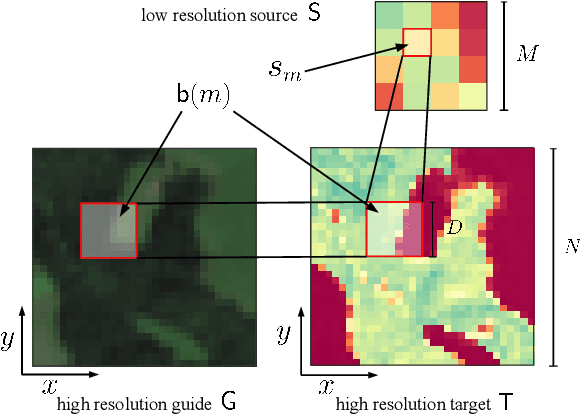
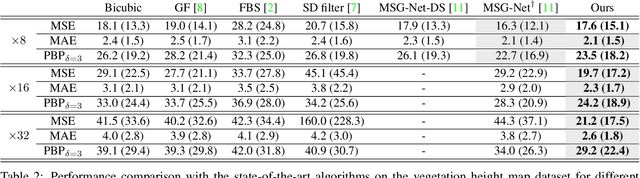
Guided super-resolution is a unifying framework for several computer vision tasks where the inputs are a low-resolution source image of some target quantity (e.g., perspective depth acquired with a time-of-flight camera) and a high-resolution guide image from a different domain (e.g., a gray-scale image from a conventional camera); and the target output is a high-resolution version of the source (in our example, a high-res depth map). The standard way of looking at this problem is to formulate it as a super-resolution task, i.e., the source image is upsampled to the target resolution, while transferring the missing high-frequency details from the guide. Here, we propose to turn that interpretation on its head and instead see it as a pixel-to-pixel mapping of the guide image to the domain of the source image. The pixel-wise mapping is parameterised as a multi-layer perceptron, whose weights are learned by minimising the discrepancies between the source image and the downsampled target image. Importantly, our formulation makes it possible to regularise only the mapping function, while avoiding regularisation of the outputs; Thus producing crisp, natural-looking images. The proposed method is unsupervised, using only the specific source and guide images to fit the mapping. We evaluate our method on two different tasks, super-resolution of depth maps and of tree height maps. In both cases we clearly outperform recent baselines in quantitative comparisons, while delivering visually much sharper outputs.