 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Poly-GAN: Multi-Conditioned GAN for Fashion Synthesis
Sep 05, 2019

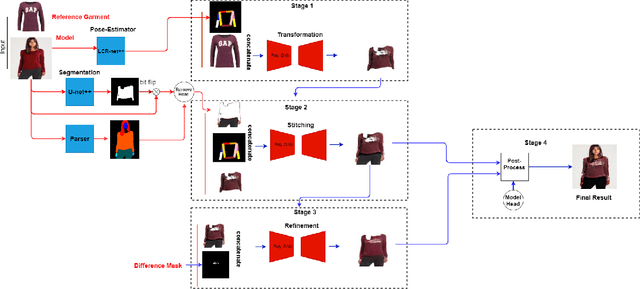
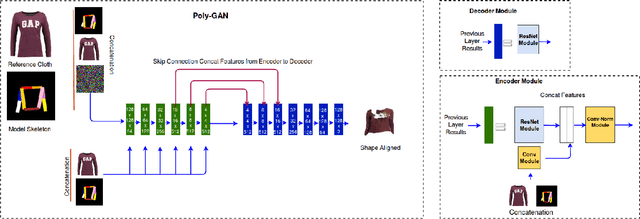

We present Poly-GAN, a novel conditional GAN architecture that is motivated by Fashion Synthesis, an application where garments are automatically placed on images of human models at an arbitrary pose. Poly-GAN allows conditioning on multiple inputs and is suitable for many tasks, including image alignment, image stitching, and inpainting. Existing methods have a similar pipeline where three different networks are used to first align garments with the human pose, then perform stitching of the aligned garment and finally refine the results. Poly-GAN is the first instance where a common architecture is used to perform all three tasks. Our novel architecture enforces the conditions at all layers of the encoder and utilizes skip connections from the coarse layers of the encoder to the respective layers of the decoder. Poly-GAN is able to perform a spatial transformation of the garment based on the RGB skeleton of the model at an arbitrary pose. Additionally, Poly-GAN can perform image stitching, regardless of the garment orientation, and inpainting on the garment mask when it contains irregular holes. Our system achieves state-of-the-art quantitative results on Structural Similarity Index metric and Inception Score metric using the DeepFashion dataset.
UC-Net: Uncertainty Inspired RGB-D Saliency Detection via Conditional Variational Autoencoders
Apr 13, 2020
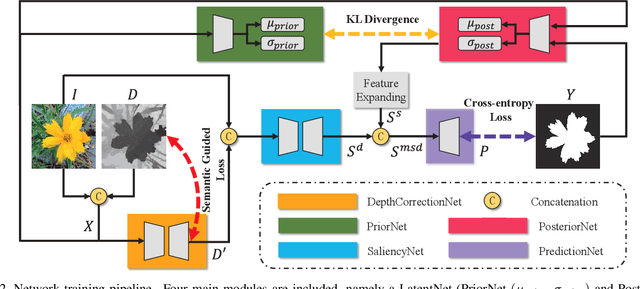
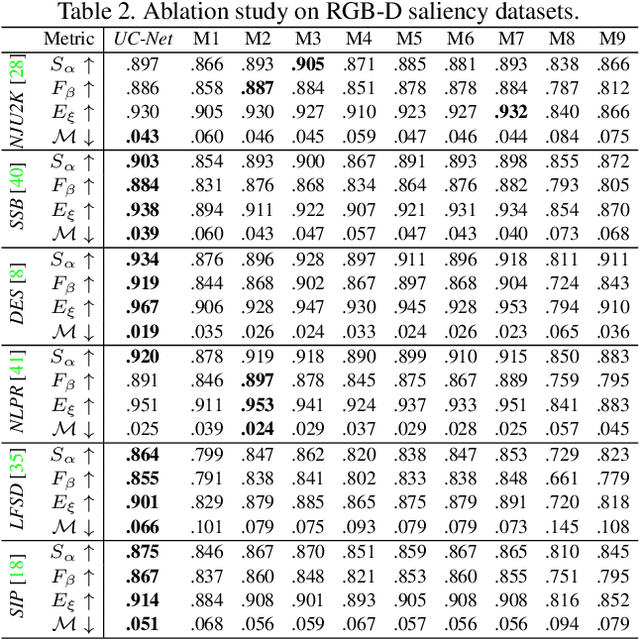
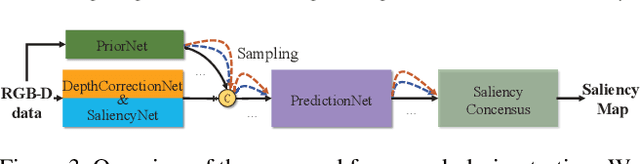
In this paper, we propose the first framework (UCNet) to employ uncertainty for RGB-D saliency detection by learning from the data labeling process. Existing RGB-D saliency detection methods treat the saliency detection task as a point estimation problem, and produce a single saliency map following a deterministic learning pipeline. Inspired by the saliency data labeling process, we propose probabilistic RGB-D saliency detection network via conditional variational autoencoders to model human annotation uncertainty and generate multiple saliency maps for each input image by sampling in the latent space. With the proposed saliency consensus process, we are able to generate an accurate saliency map based on these multiple predictions. Quantitative and qualitative evaluations on six challenging benchmark datasets against 18 competing algorithms demonstrate the effectiveness of our approach in learning the distribution of saliency maps, leading to a new state-of-the-art in RGB-D saliency detection.
A Novel Learnable Gradient Descent Type Algorithm for Non-convex Non-smooth Inverse Problems
Mar 15, 2020
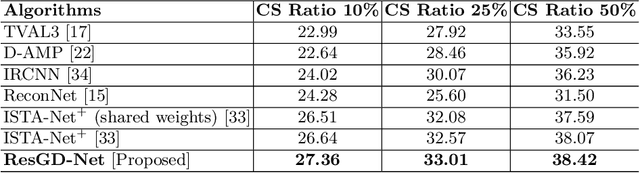


Optimization algorithms for solving nonconvex inverse problem have attracted significant interests recently. However, existing methods require the nonconvex regularization to be smooth or simple to ensure convergence. In this paper, we propose a novel gradient descent type algorithm, by leveraging the idea of residual learning and Nesterov's smoothing technique, to solve inverse problems consisting of general nonconvex and nonsmooth regularization with provable convergence. Moreover, we develop a neural network architecture intimating this algorithm to learn the nonlinear sparsity transformation adaptively from training data, which also inherits the convergence to accommodate the general nonconvex structure of this learned transformation. Numerical results demonstrate that the proposed network outperforms the state-of-the-art methods on a variety of different image reconstruction problems in terms of efficiency and accuracy.
Propagation Channel Modeling by Deep learning Techniques
Aug 19, 2019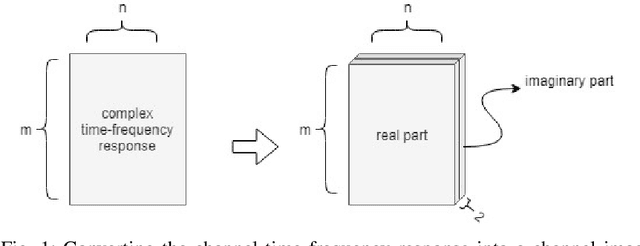
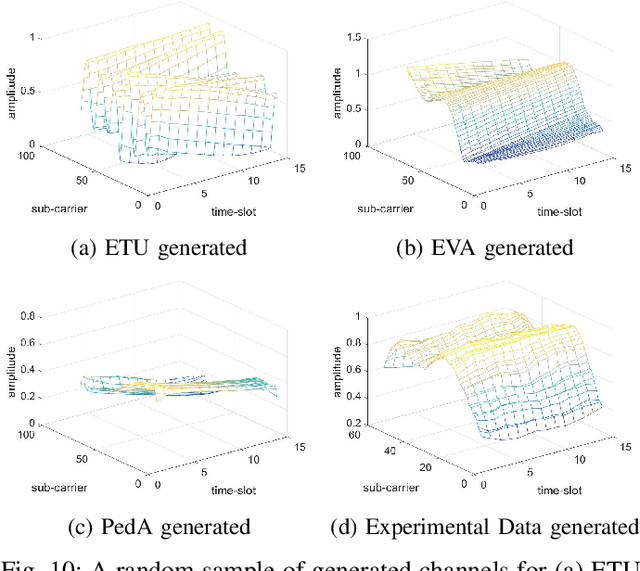
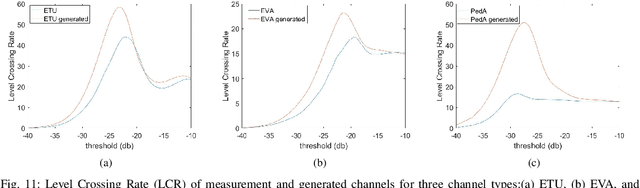
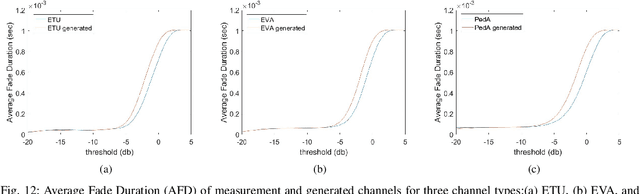
Channel, as the medium for the propagation of electromagnetic waves, is one of the most important parts of a communication system. Being aware of how the channel affects the propagation waves is essential for designing, optimization and performance analysis of a communication system. For this purpose, a proper channel model is needed. This paper presents a novel propagation channel model which considers the time-frequency response of the channel as an image. It models the distribution of these channel images using Deep Convolutional Generative Adversarial Networks. Moreover, for the measurements with different user speeds, the user speed is considered as an auxiliary parameter for the model. StarGAN as an image-to-image translation technique is used to change the generated channel images with respect to the desired user speed. The performance of the proposed model is evaluated using existing metrics. Furthermore, to capture 2D similarity in both time and frequency, a new metric is introduced. Using this metric, the generated channels show significant statistical similarity to the measurement data.
Deep Parametric Indoor Lighting Estimation
Oct 19, 2019

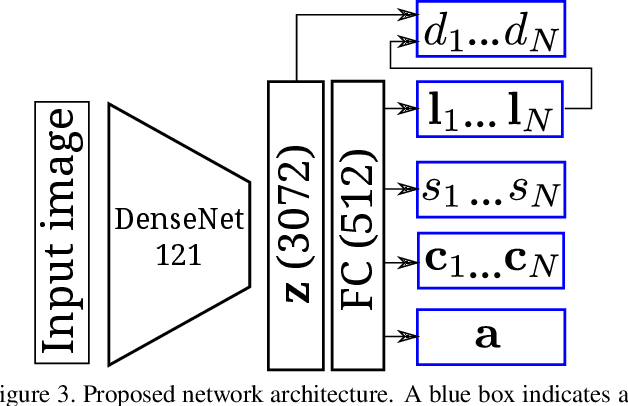

We present a method to estimate lighting from a single image of an indoor scene. Previous work has used an environment map representation that does not account for the localized nature of indoor lighting. Instead, we represent lighting as a set of discrete 3D lights with geometric and photometric parameters. We train a deep neural network to regress these parameters from a single image, on a dataset of environment maps annotated with depth. We propose a differentiable layer to convert these parameters to an environment map to compute our loss; this bypasses the challenge of establishing correspondences between estimated and ground truth lights. We demonstrate, via quantitative and qualitative evaluations, that our representation and training scheme lead to more accurate results compared to previous work, while allowing for more realistic 3D object compositing with spatially-varying lighting.
Extracting 2D weak labels from volume labels using multiple instance learning in CT hemorrhage detection
Nov 13, 2019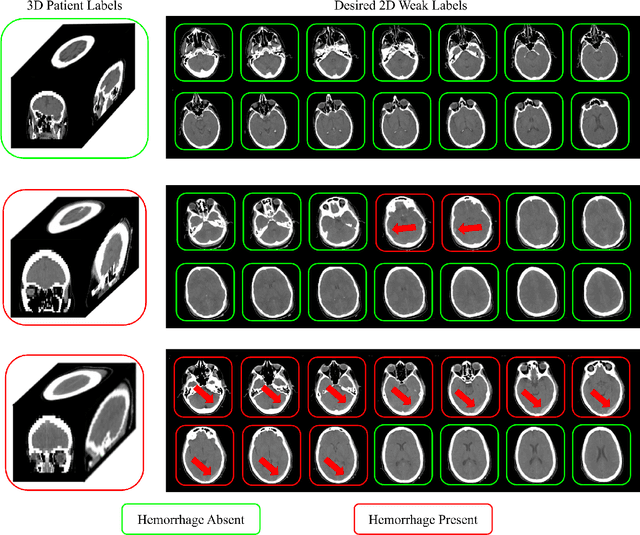

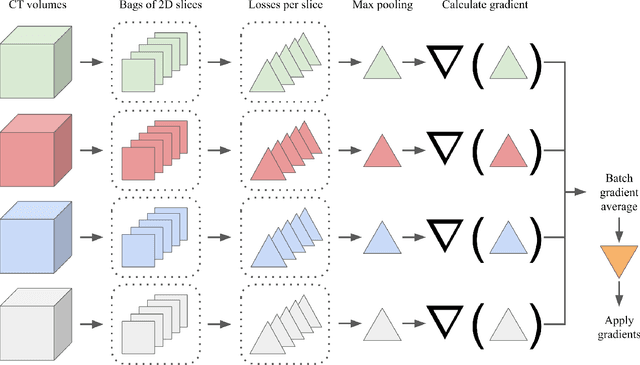
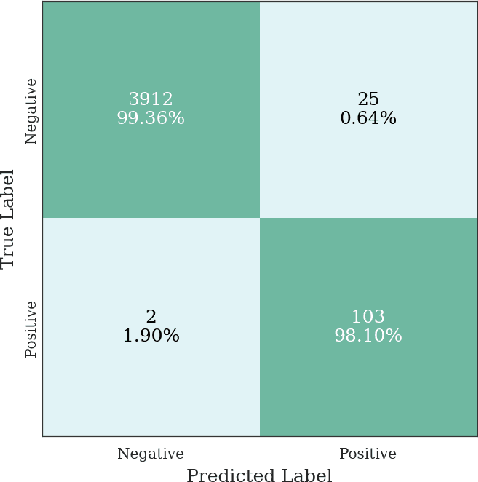
Multiple instance learning (MIL) is a supervised learning methodology that aims to allow models to learn instance class labels from bag class labels, where a bag is defined to contain multiple instances. MIL is gaining traction for learning from weak labels but has not been widely applied to 3D medical imaging. MIL is well-suited to clinical CT acquisitions since (1) the highly anisotropic voxels hinder application of traditional 3D networks and (2) patch-based networks have limited ability to learn whole volume labels. In this work, we apply MIL with a deep convolutional neural network to identify whether clinical CT head image volumes possess one or more large hemorrhages (> 20cm$^3$), resulting in a learned 2D model without the need for 2D slice annotations. Individual image volumes are considered separate bags, and the slices in each volume are instances. Such a framework sets the stage for incorporating information obtained in clinical reports to help train a 2D segmentation approach. Within this context, we evaluate the data requirements to enable generalization of MIL by varying the amount of training data. Our results show that a training size of at least 400 patient image volumes was needed to achieve accurate per-slice hemorrhage detection. Over a five-fold cross-validation, the leading model, which made use of the maximum number of training volumes, had an average true positive rate of 98.10%, an average true negative rate of 99.36%, and an average precision of 0.9698. The models have been made available along with source code to enabled continued exploration and adaption of MIL in CT neuroimaging.
SLAM-based Integrity Monitoring Using GPS and Fish-eye Camera
Oct 04, 2019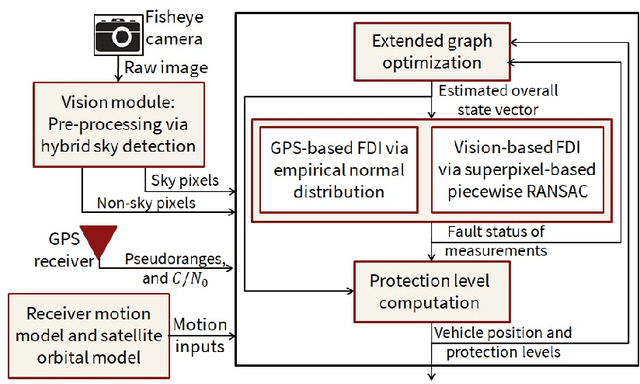
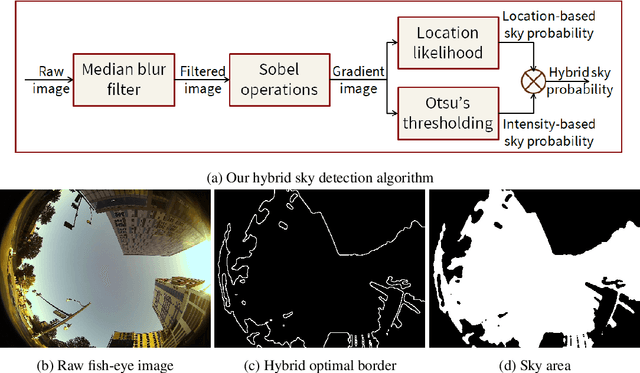
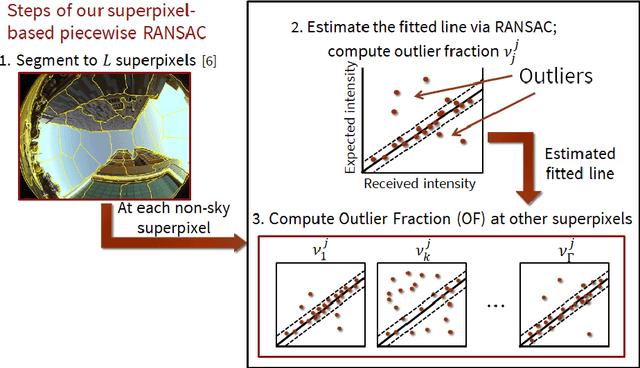
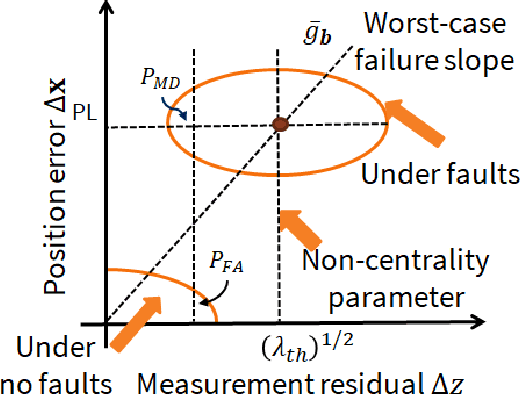
Urban navigation using GPS and fish-eye camera suffers from multipath effects in GPS measurements and data association errors in pixel intensities across image frames. We propose a Simultaneous Localization and Mapping (SLAM)-based Integrity Monitoring (IM) algorithm to compute the position protection levels while accounting for multiple faults in both GPS and vision. We perform graph optimization using the sequential data of GPS pseudoranges, pixel intensities, vehicle dynamics, and satellite ephemeris to simultaneously localize the vehicle as well as the landmarks, namely GPS satellites and key image pixels in the world frame. We estimate the fault mode vector by analyzing the temporal correlation across the GPS measurement residuals and spatial correlation across the vision intensity residuals. In particular, to detect and isolate the vision faults, we developed a superpixel-based piecewise Random Sample Consensus (RANSAC) technique to perform spatial voting across image pixels. For an estimated fault mode, we compute the protection levels by applying worst-case failure slope analysis to the linearized Graph-SLAM framework. We perform ground vehicle experiments in the semi-urban area of Champaign, IL and have demonstrated the successful detection and isolation of multiple faults. We also validate tighter protection levels and lower localization errors achieved via the proposed algorithm as compared to SLAM-based IM that utilizes only GPS measurements.
A Deep learning Approach to Generate Contrast-Enhanced Computerised Tomography Angiography without the Use of Intravenous Contrast Agents
Mar 02, 2020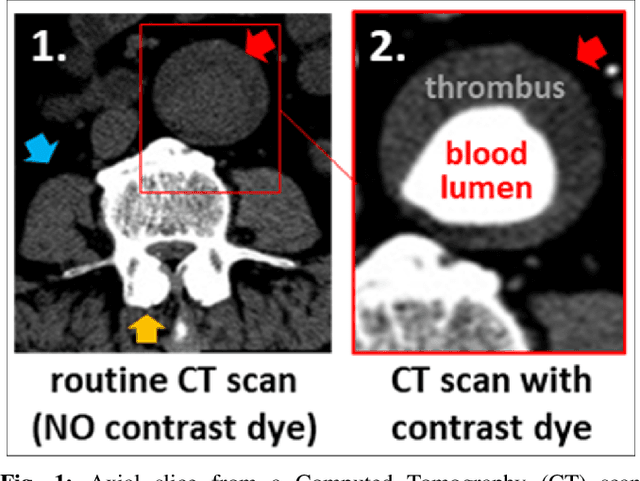
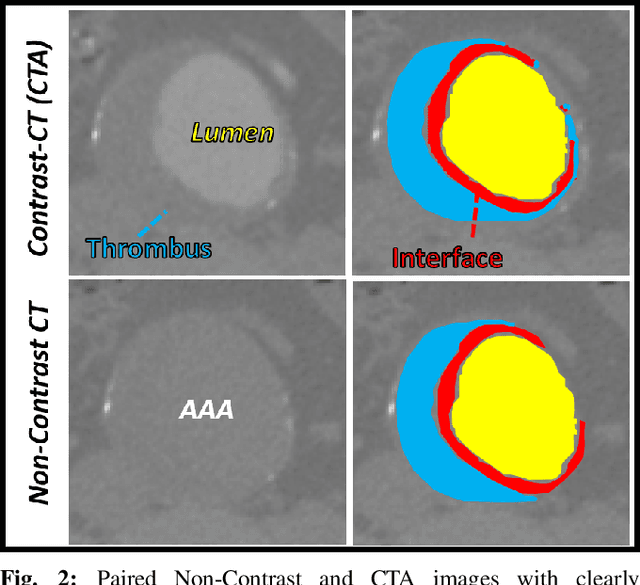
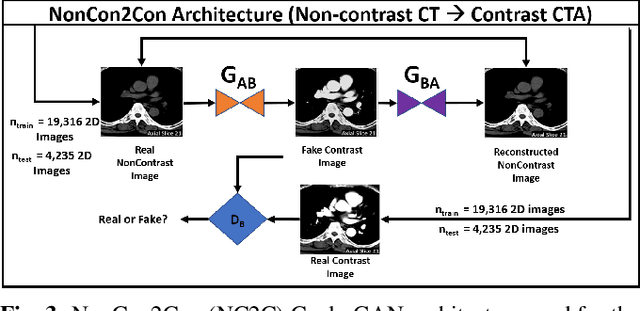
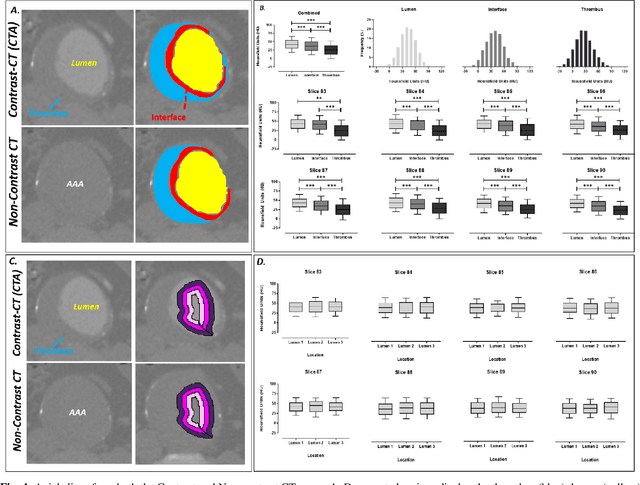
Contrast-enhanced computed tomography angiograms (CTAs) are widely used in cardiovascular imaging to obtain a non-invasive view of arterial structures. However, contrast agents are associated with complications at the injection site as well as renal toxicity leading to contrast-induced nephropathy (CIN) and renal failure. We hypothesised that the raw data acquired from a non-contrast CT contains sufficient information to differentiate blood and other soft tissue components. We utilised deep learning methods to define the subtleties between soft tissue components in order to simulate contrast enhanced CTAs without contrast agents. Twenty-six patients with paired non-contrast and CTA images were randomly selected from an approved clinical study. Non-contrast axial slices within the AAA from 10 patients (n = 100) were sampled for the underlying Hounsfield unit (HU) distribution at the lumen, intra-luminal thrombus and interface locations. Sampling of HUs in these regions revealed significant differences between all regions (p<0.001 for all comparisons), confirming the intrinsic differences in the radiomic signatures between these regions. To generate a large training dataset, paired axial slices from the training set (n=13) were augmented to produce a total of 23,551 2-D images. We trained a 2-D Cycle Generative Adversarial Network (cycleGAN) for this non-contrast to contrast (NC2C) transformation task. The accuracy of the cycleGAN output was assessed by comparison to the contrast image. This pipeline is able to differentiate between visually incoherent soft tissue regions in non-contrast CT images. The CTAs generated from the non-contrast images bear strong resemblance to the ground truth. Here we describe a novel application of Generative Adversarial Network for CT image processing. This is poised to disrupt clinical pathways requiring contrast enhanced CT imaging.
A Smooth Representation of Belief over SO(3) for Deep Rotation Learning with Uncertainty
Jun 17, 2020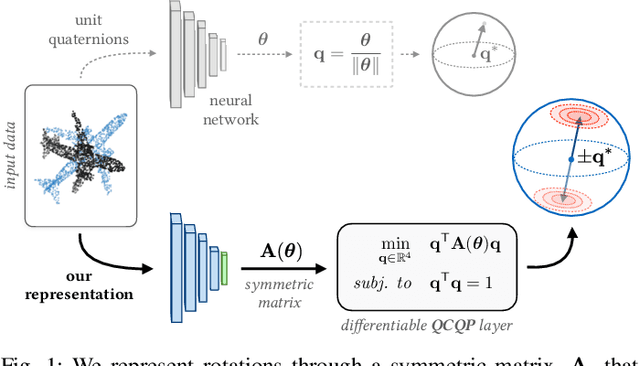

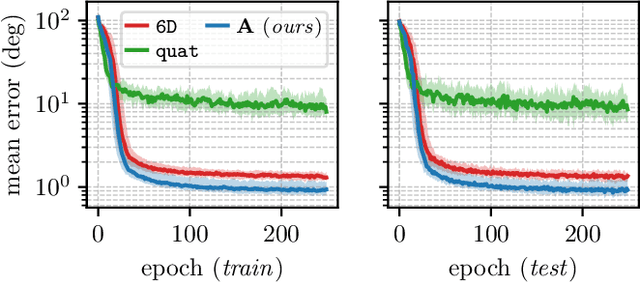
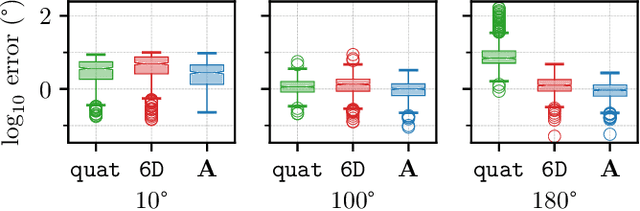
Accurate rotation estimation is at the heart of robot perception tasks such as visual odometry and object pose estimation. Deep neural networks have provided a new way to perform these tasks, and the choice of rotation representation is an important part of network design. In this work, we present a novel symmetric matrix representation of the 3D rotation group, SO(3), with two important properties that make it particularly suitable for learned models: (1) it satisfies a smoothness property that improves convergence and generalization when regressing large rotation targets, and (2) it encodes a symmetric Bingham belief over the space of unit quaternions, permitting the training of uncertainty-aware models. We empirically validate the benefits of our formulation by training deep neural rotation regressors on two data modalities. First, we use synthetic point-cloud data to show that our representation leads to superior predictive accuracy over existing representations for arbitrary rotation targets. Second, we use image data collected onboard ground and aerial vehicles to demonstrate that our representation is amenable to an effective out-of-distribution (OOD) rejection technique that significantly improves the robustness of rotation estimates to unseen environmental effects and corrupted input images, without requiring the use of an explicit likelihood loss, stochastic sampling, or an auxiliary classifier. This capability is key for safety-critical applications where detecting novel inputs can prevent catastrophic failure of learned models.
PAI-GCN: Permutable Anisotropic Graph Convolutional Networks for 3D Shape Representation Learning
Apr 21, 2020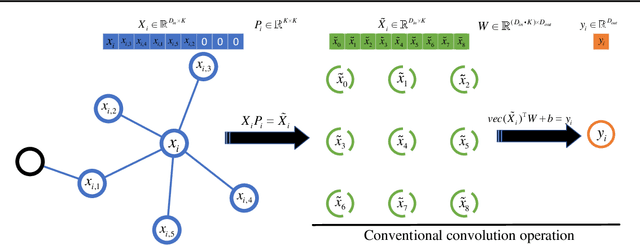
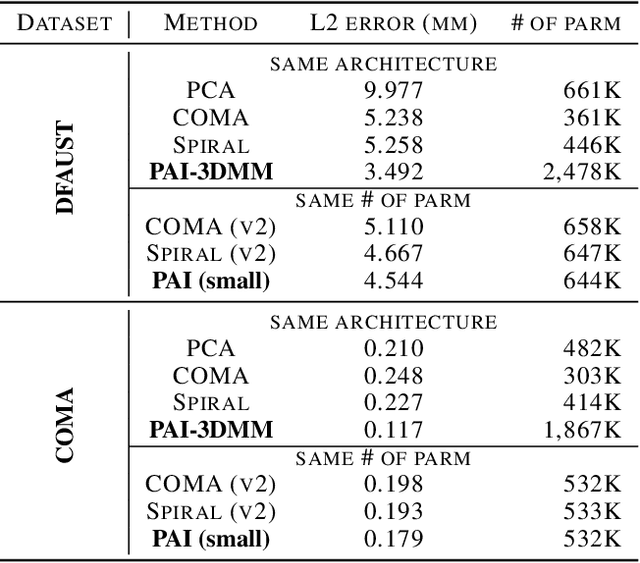
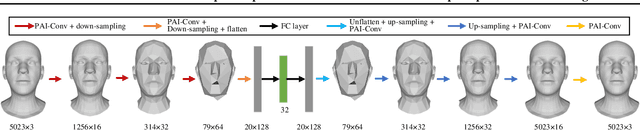
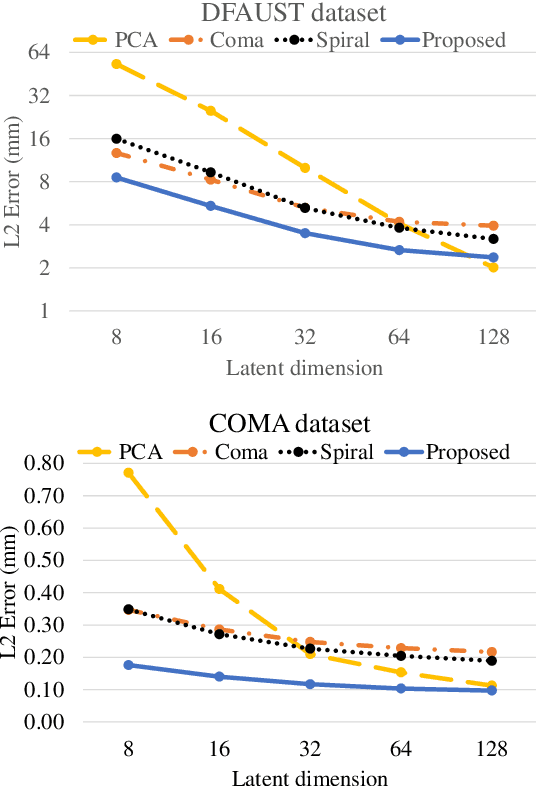
Demand for efficient 3D shape representation learning is increasing in many 3D computer vision applications. The recent success of convolutional neural networks (CNNs) for image analysis suggests the value of adapting insight from CNN to 3D shapes. However, unlike images that are Euclidean structured, 3D shape data are irregular since each node's neighbors are inconsistent. Various convolutional graph neural networks for 3D shapes have been developed using isotropic filters or using anisotropic filters with predefined local coordinate systems to overcome the node inconsistency on graphs. However, isotropic filters or predefined local coordinate systems limit the representation power. In this paper, we propose a permutable anisotropic convolutional operation (PAI-Conv) that learns adaptive soft-permutation matrices for each node according to the geometric shape of its neighbors and performs shared anisotropic filters as CNN does. Comprehensive experiments demonstrate that our model produces significant improvement in 3D shape reconstruction compared to state-of-the-art methods.