 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Query-Based Knowledge Sharing for Open-Vocabulary Multi-Label Classification
Jan 02, 2024
Identifying labels that did not appear during training, known as multi-label zero-shot learning, is a non-trivial task in computer vision. To this end, recent studies have attempted to explore the multi-modal knowledge of vision-language pre-training (VLP) models by knowledge distillation, allowing to recognize unseen labels in an open-vocabulary manner. However, experimental evidence shows that knowledge distillation is suboptimal and provides limited performance gain in unseen label prediction. In this paper, a novel query-based knowledge sharing paradigm is proposed to explore the multi-modal knowledge from the pretrained VLP model for open-vocabulary multi-label classification. Specifically, a set of learnable label-agnostic query tokens is trained to extract critical vision knowledge from the input image, and further shared across all labels, allowing them to select tokens of interest as visual clues for recognition. Besides, we propose an effective prompt pool for robust label embedding, and reformulate the standard ranking learning into a form of classification to allow the magnitude of feature vectors for matching, which both significantly benefit label recognition. Experimental results show that our framework significantly outperforms state-of-the-art methods on zero-shot task by 5.9% and 4.5% in mAP on the NUS-WIDE and Open Images, respectively.
Auffusion: Leveraging the Power of Diffusion and Large Language Models for Text-to-Audio Generation
Jan 02, 2024Recent advancements in diffusion models and large language models (LLMs) have significantly propelled the field of AIGC. Text-to-Audio (TTA), a burgeoning AIGC application designed to generate audio from natural language prompts, is attracting increasing attention. However, existing TTA studies often struggle with generation quality and text-audio alignment, especially for complex textual inputs. Drawing inspiration from state-of-the-art Text-to-Image (T2I) diffusion models, we introduce Auffusion, a TTA system adapting T2I model frameworks to TTA task, by effectively leveraging their inherent generative strengths and precise cross-modal alignment. Our objective and subjective evaluations demonstrate that Auffusion surpasses previous TTA approaches using limited data and computational resource. Furthermore, previous studies in T2I recognizes the significant impact of encoder choice on cross-modal alignment, like fine-grained details and object bindings, while similar evaluation is lacking in prior TTA works. Through comprehensive ablation studies and innovative cross-attention map visualizations, we provide insightful assessments of text-audio alignment in TTA. Our findings reveal Auffusion's superior capability in generating audios that accurately match textual descriptions, which further demonstrated in several related tasks, such as audio style transfer, inpainting and other manipulations. Our implementation and demos are available at https://auffusion.github.io.
Q-Seg: Quantum Annealing-based Unsupervised Image Segmentation
Nov 30, 2023In this study, we present Q-Seg, a novel unsupervised image segmentation method based on quantum annealing, tailored for existing quantum hardware. We formulate the pixel-wise segmentation problem, which assimilates spectral and spatial information of the image, as a graph-cut optimization task. Our method efficiently leverages the interconnected qubit topology of the D-Wave Advantage device, offering superior scalability over existing quantum approaches and outperforming state-of-the-art classical methods. Our empirical evaluations on synthetic datasets reveal that Q-Seg offers better runtime performance against the classical optimizer Gurobi. Furthermore, we evaluate our method on segmentation of Earth Observation images, an area of application where the amount of labeled data is usually very limited. In this case, Q-Seg demonstrates near-optimal results in flood mapping detection with respect to classical supervised state-of-the-art machine learning methods. Also, Q-Seg provides enhanced segmentation for forest coverage compared to existing annotated masks. Thus, Q-Seg emerges as a viable alternative for real-world applications using available quantum hardware, particularly in scenarios where the lack of labeled data and computational runtime are critical.
MobileCLIP: Fast Image-Text Models through Multi-Modal Reinforced Training
Nov 28, 2023Contrastive pretraining of image-text foundation models, such as CLIP, demonstrated excellent zero-shot performance and improved robustness on a wide range of downstream tasks. However, these models utilize large transformer-based encoders with significant memory and latency overhead which pose challenges for deployment on mobile devices. In this work, we introduce MobileCLIP -- a new family of efficient image-text models optimized for runtime performance along with a novel and efficient training approach, namely multi-modal reinforced training. The proposed training approach leverages knowledge transfer from an image captioning model and an ensemble of strong CLIP encoders to improve the accuracy of efficient models. Our approach avoids train-time compute overhead by storing the additional knowledge in a reinforced dataset. MobileCLIP sets a new state-of-the-art latency-accuracy tradeoff for zero-shot classification and retrieval tasks on several datasets. Our MobileCLIP-S2 variant is 2.3$\times$ faster while more accurate compared to previous best CLIP model based on ViT-B/16. We further demonstrate the effectiveness of our multi-modal reinforced training by training a CLIP model based on ViT-B/16 image backbone and achieving +2.9% average performance improvement on 38 evaluation benchmarks compared to the previous best. Moreover, we show that the proposed approach achieves 10$\times$-1000$\times$ improved learning efficiency when compared with non-reinforced CLIP training.
DiffAugment: Diffusion based Long-Tailed Visual Relationship Recognition
Jan 01, 2024The task of Visual Relationship Recognition (VRR) aims to identify relationships between two interacting objects in an image and is particularly challenging due to the widely-spread and highly imbalanced distribution of <subject, relation, object> triplets. To overcome the resultant performance bias in existing VRR approaches, we introduce DiffAugment -- a method which first augments the tail classes in the linguistic space by making use of WordNet and then utilizes the generative prowess of Diffusion Models to expand the visual space for minority classes. We propose a novel hardness-aware component in diffusion which is based upon the hardness of each <S,R,O> triplet and demonstrate the effectiveness of hardness-aware diffusion in generating visual embeddings for the tail classes. We also propose a novel subject and object based seeding strategy for diffusion sampling which improves the discriminative capability of the generated visual embeddings. Extensive experimentation on the GQA-LT dataset shows favorable gains in the subject/object and relation average per-class accuracy using Diffusion augmented samples.
Geometry Depth Consistency in RGBD Relative Pose Estimation
Jan 01, 2024Relative pose estimation for RGBD cameras is crucial in a number of applications. Previous approaches either rely on the RGB aspect of the images to estimate pose thus not fully making use of depth in the estimation process or estimate pose from the 3D cloud of points that each image produces, thus not making full use of RGB information. This paper shows that if one pair of correspondences is hypothesized from the RGB-based ranked-ordered correspondence list, then the space of remaining correspondences is restricted to corresponding pairs of curves nested around the hypothesized correspondence, implicitly capturing depth consistency. This simple Geometric Depth Constraint (GDC) significantly reduces potential matches. In effect this becomes a filter on possible correspondences that helps reduce the number of outliers and thus expedites RANSAC significantly. As such, the same budget of time allows for more RANSAC iterations and therefore additional robustness and a significant speedup. In addition, the paper proposed a Nested RANSAC approach that also speeds up the process, as shown through experiments on TUM, ICL-NUIM, and RGBD Scenes v2 datasets.
C3: High-performance and low-complexity neural compression from a single image or video
Dec 05, 2023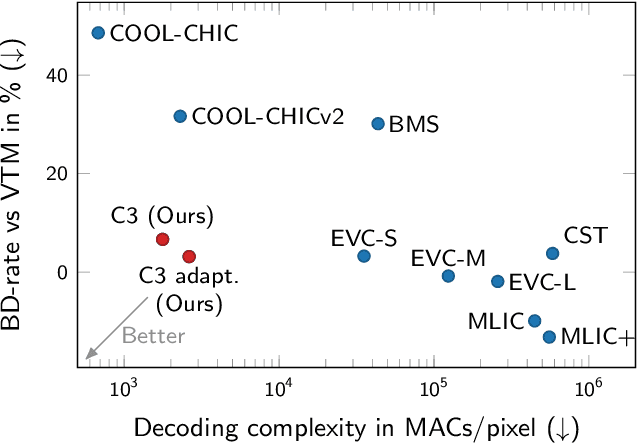
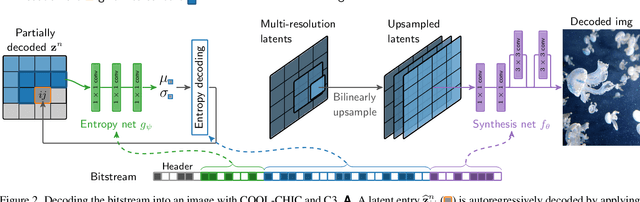

Most neural compression models are trained on large datasets of images or videos in order to generalize to unseen data. Such generalization typically requires large and expressive architectures with a high decoding complexity. Here we introduce C3, a neural compression method with strong rate-distortion (RD) performance that instead overfits a small model to each image or video separately. The resulting decoding complexity of C3 can be an order of magnitude lower than neural baselines with similar RD performance. C3 builds on COOL-CHIC (Ladune et al.) and makes several simple and effective improvements for images. We further develop new methodology to apply C3 to videos. On the CLIC2020 image benchmark, we match the RD performance of VTM, the reference implementation of the H.266 codec, with less than 3k MACs/pixel for decoding. On the UVG video benchmark, we match the RD performance of the Video Compression Transformer (Mentzer et al.), a well-established neural video codec, with less than 5k MACs/pixel for decoding.
Neural Born Series Operator for Biomedical Ultrasound Computed Tomography
Dec 25, 2023Ultrasound Computed Tomography (USCT) provides a radiation-free option for high-resolution clinical imaging. Despite its potential, the computationally intensive Full Waveform Inversion (FWI) required for tissue property reconstruction limits its clinical utility. This paper introduces the Neural Born Series Operator (NBSO), a novel technique designed to speed up wave simulations, thereby facilitating a more efficient USCT image reconstruction process through an NBSO-based FWI pipeline. Thoroughly validated on comprehensive brain and breast datasets, simulated under experimental USCT conditions, the NBSO proves to be accurate and efficient in both forward simulation and image reconstruction. This advancement demonstrates the potential of neural operators in facilitating near real-time USCT reconstruction, making the clinical application of USCT increasingly viable and promising.
HyperDID: Hyperspectral Intrinsic Image Decomposition with Deep Feature Embedding
Nov 25, 2023The dissection of hyperspectral images into intrinsic components through hyperspectral intrinsic image decomposition (HIID) enhances the interpretability of hyperspectral data, providing a foundation for more accurate classification outcomes. However, the classification performance of HIID is constrained by the model's representational ability. To address this limitation, this study rethinks hyperspectral intrinsic image decomposition for classification tasks by introducing deep feature embedding. The proposed framework, HyperDID, incorporates the Environmental Feature Module (EFM) and Categorical Feature Module (CFM) to extract intrinsic features. Additionally, a Feature Discrimination Module (FDM) is introduced to separate environment-related and category-related features. Experimental results across three commonly used datasets validate the effectiveness of HyperDID in improving hyperspectral image classification performance. This novel approach holds promise for advancing the capabilities of hyperspectral image analysis by leveraging deep feature embedding principles. The implementation of the proposed method could be accessed soon at https://github.com/shendu-sw/HyperDID for the sake of reproducibility.
UFOGen: You Forward Once Large Scale Text-to-Image Generation via Diffusion GANs
Nov 29, 2023
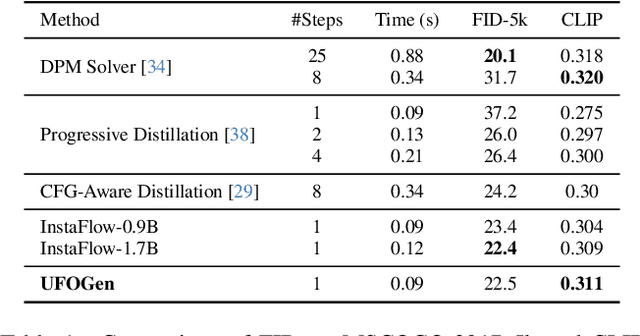
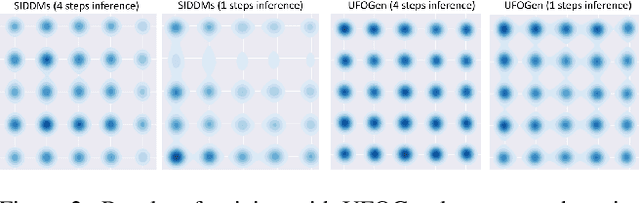
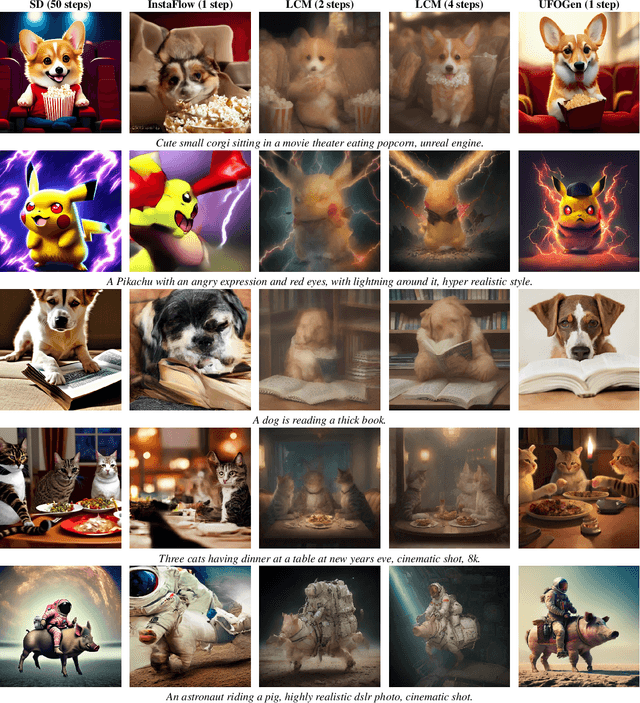
Text-to-image diffusion models have demonstrated remarkable capabilities in transforming textual prompts into coherent images, yet the computational cost of their inference remains a persistent challenge. To address this issue, we present UFOGen, a novel generative model designed for ultra-fast, one-step text-to-image synthesis. In contrast to conventional approaches that focus on improving samplers or employing distillation techniques for diffusion models, UFOGen adopts a hybrid methodology, integrating diffusion models with a GAN objective. Leveraging a newly introduced diffusion-GAN objective and initialization with pre-trained diffusion models, UFOGen excels in efficiently generating high-quality images conditioned on textual descriptions in a single step. Beyond traditional text-to-image generation, UFOGen showcases versatility in applications. Notably, UFOGen stands among the pioneering models enabling one-step text-to-image generation and diverse downstream tasks, presenting a significant advancement in the landscape of efficient generative models.