 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Exposure Interpolation Via Fusing Conventional and Deep Learning Methods
May 09, 2019

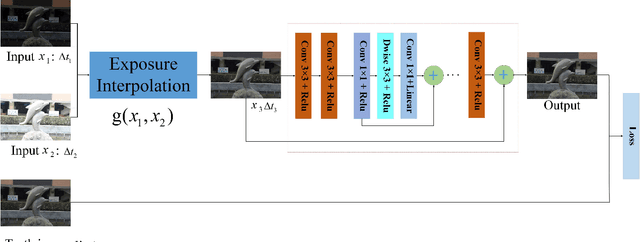


Deep learning based methods have penetrated many image processing problems and become dominant solutions to these problems. A natural question raised here is "Is there any space for conventional methods on these problems?" In this paper, exposure interpolation is taken as an example to answer this question and the answer is "Yes". A framework on fusing conventional and deep learning method is introduced to generate an medium exposure image for two large-exposureratio images. Experimental results indicate that the quality of the medium exposure image is increased significantly through using the deep learning method to refine the interpolated image via the conventional method. The conventional method can be adopted to improve the convergence speed of the deep learning method and to reduce the number of samples which is required by the deep learning method.
Let's Transfer Transformations of Shared Semantic Representations
Mar 02, 2019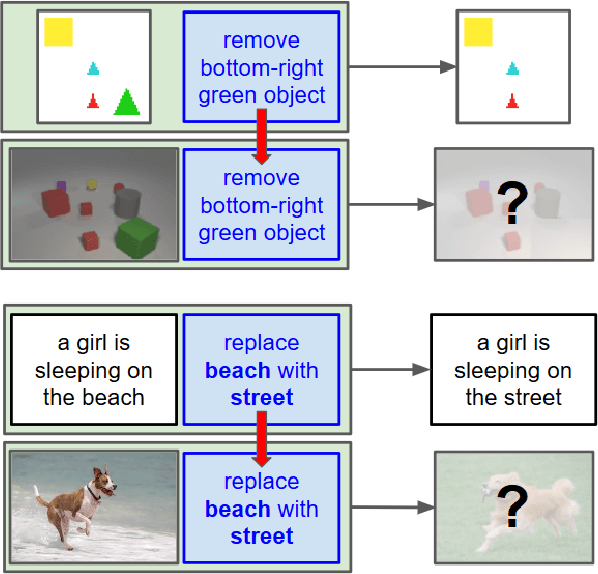

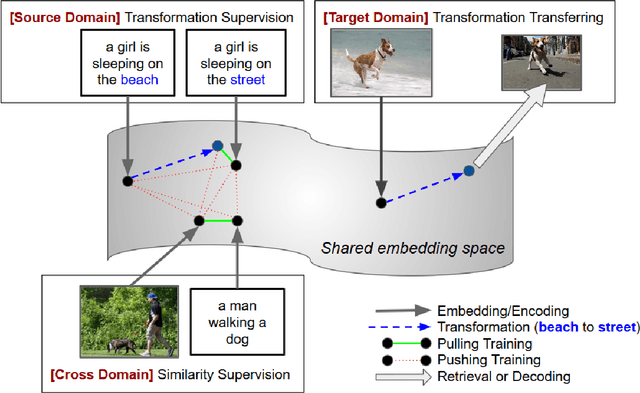

With a good image understanding capability, can we manipulate the images high level semantic representation? Such transformation operation can be used to generate or retrieve similar images but with a desired modification (for example changing beach background to street background); similar ability has been demonstrated in zero shot learning, attribute composition and attribute manipulation image search. In this work we show how one can learn transformations with no training examples by learning them on another domain and then transfer to the target domain. This is feasible if: first, transformation training data is more accessible in the other domain and second, both domains share similar semantics such that one can learn transformations in a shared embedding space. We demonstrate this on an image retrieval task where search query is an image, plus an additional transformation specification (for example: search for images similar to this one but background is a street instead of a beach). In one experiment, we transfer transformation from synthesized 2D blobs image to 3D rendered image, and in the other, we transfer from text domain to natural image domain.
Depth-Preserving Real-Time Arbitrary Style Transfer
Jun 03, 2019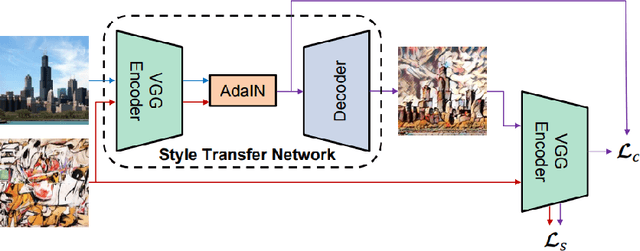

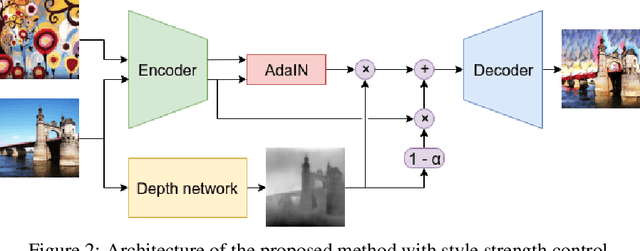

Style transfer is the process of rendering one image with some content in the style of another image, representing the style. Recent studies of Liu et al. (2017) have shown significant improvement of style transfer rendering quality by adjusting traditional methods of Gatys et al. (2016) and Johnson et al. (2016) with regularizer, forcing preservation of the depth map of the content image. However these traditional methods are either computationally inefficient or require training a separate neural network for new style. AdaIN method of Huang et al. (2017) allows efficient transferring of arbitrary style without training a separate model but is not able to reproduce the depth map of the content image. We propose an extension to this method, allowing depth map preservation. Qualitative analysis and results of user evaluation study indicate that the proposed method provides better stylizations, compared to the original style transfer methods of Gatys et al. (2016) and Huang et al. (2017).
Adaptive Weighting Multi-Field-of-View CNN for Semantic Segmentation in Pathology
Apr 12, 2019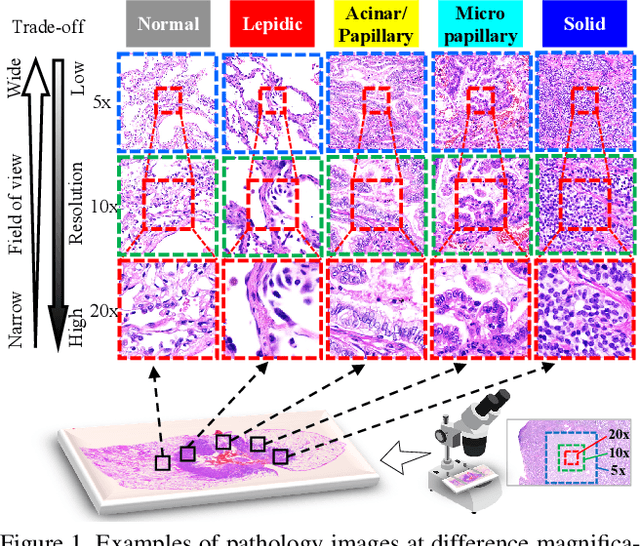
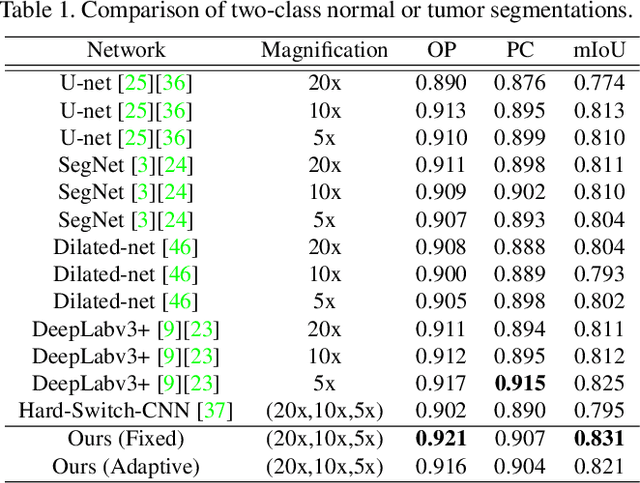
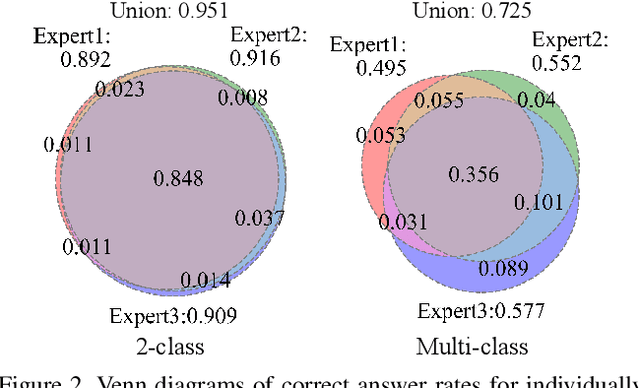
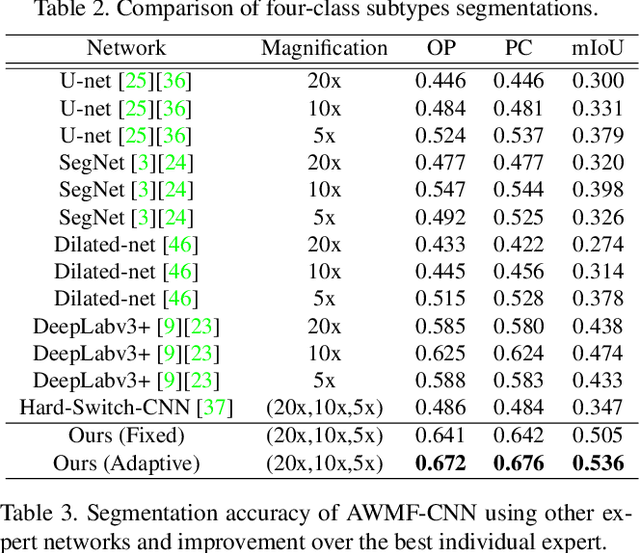
Automated digital histopathology image segmentation is an important task to help pathologists diagnose tumors and cancer subtypes. For pathological diagnosis of cancer subtypes, pathologists usually change the magnification of whole-slide images (WSI) viewers. A key assumption is that the importance of the magnifications depends on the characteristics of the input image, such as cancer subtypes. In this paper, we propose a novel semantic segmentation method, called Adaptive-Weighting-Multi-Field-of-View-CNN (AWMF-CNN), that can adaptively use image features from images with different magnifications to segment multiple cancer subtype regions in the input image. The proposed method aggregates several expert CNNs for images of different magnifications by adaptively changing the weight of each expert depending on the input image. It leverages information in the images with different magnifications that might be useful for identifying the subtypes. It outperformed other state-of-the-art methods in experiments.
A Smooth Representation of Belief over SO(3) for Deep Rotation Learning with Uncertainty
Jun 17, 2020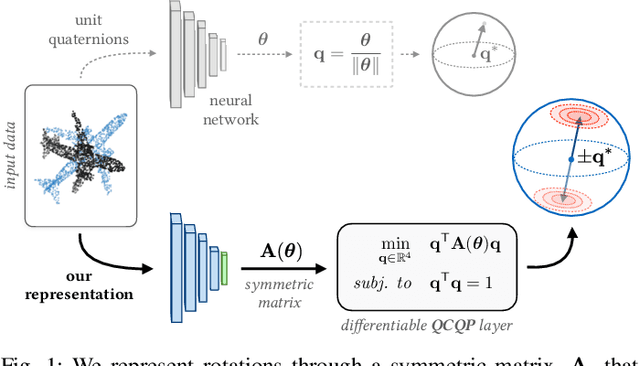

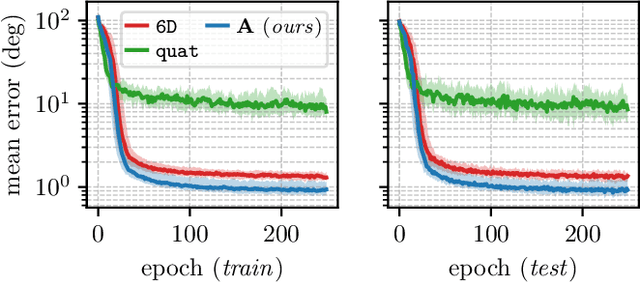
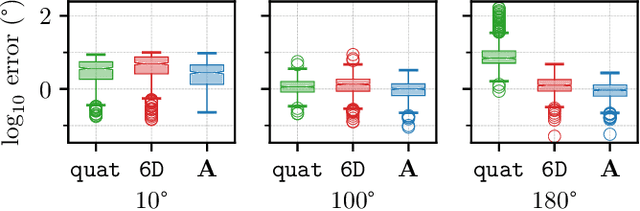
Accurate rotation estimation is at the heart of robot perception tasks such as visual odometry and object pose estimation. Deep neural networks have provided a new way to perform these tasks, and the choice of rotation representation is an important part of network design. In this work, we present a novel symmetric matrix representation of the 3D rotation group, SO(3), with two important properties that make it particularly suitable for learned models: (1) it satisfies a smoothness property that improves convergence and generalization when regressing large rotation targets, and (2) it encodes a symmetric Bingham belief over the space of unit quaternions, permitting the training of uncertainty-aware models. We empirically validate the benefits of our formulation by training deep neural rotation regressors on two data modalities. First, we use synthetic point-cloud data to show that our representation leads to superior predictive accuracy over existing representations for arbitrary rotation targets. Second, we use image data collected onboard ground and aerial vehicles to demonstrate that our representation is amenable to an effective out-of-distribution (OOD) rejection technique that significantly improves the robustness of rotation estimates to unseen environmental effects and corrupted input images, without requiring the use of an explicit likelihood loss, stochastic sampling, or an auxiliary classifier. This capability is key for safety-critical applications where detecting novel inputs can prevent catastrophic failure of learned models.
Discriminative Nonlinear Analysis Operator Learning: When Cosparse Model Meets Image Classification
Apr 30, 2017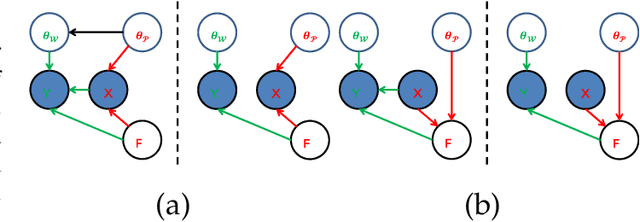
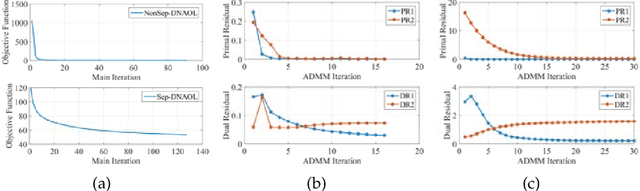
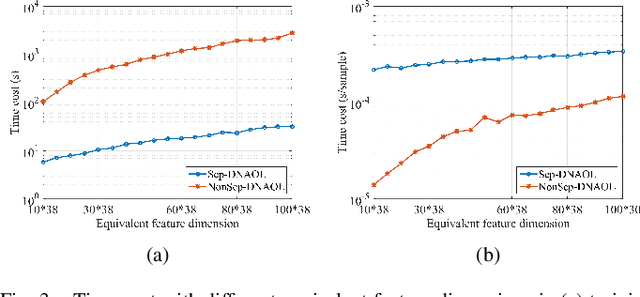
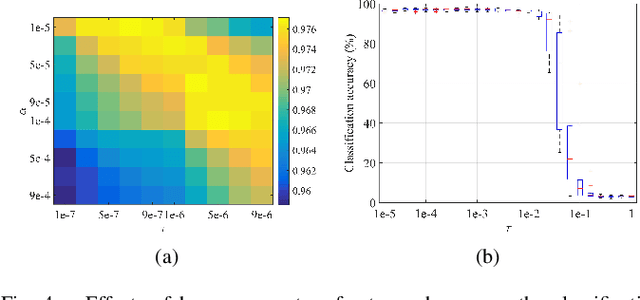
Linear synthesis model based dictionary learning framework has achieved remarkable performances in image classification in the last decade. Behaved as a generative feature model, it however suffers from some intrinsic deficiencies. In this paper, we propose a novel parametric nonlinear analysis cosparse model (NACM) with which a unique feature vector will be much more efficiently extracted. Additionally, we derive a deep insight to demonstrate that NACM is capable of simultaneously learning the task adapted feature transformation and regularization to encode our preferences, domain prior knowledge and task oriented supervised information into the features. The proposed NACM is devoted to the classification task as a discriminative feature model and yield a novel discriminative nonlinear analysis operator learning framework (DNAOL). The theoretical analysis and experimental performances clearly demonstrate that DNAOL will not only achieve the better or at least competitive classification accuracies than the state-of-the-art algorithms but it can also dramatically reduce the time complexities in both training and testing phases.
SLAP: Improving Physical Adversarial Examples with Short-Lived Adversarial Perturbations
Jul 08, 2020
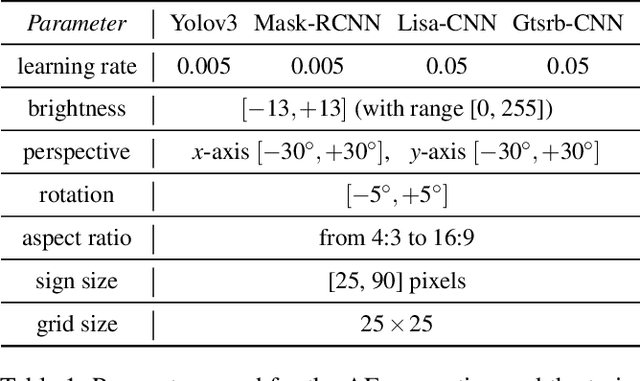

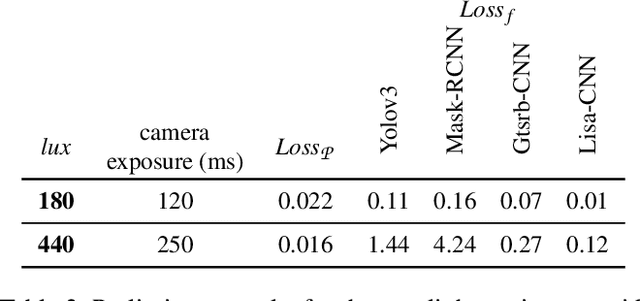
Whilst significant research effort into adversarial examples (AE) has emerged in recent years, the main vector to realize these attacks in the real-world currently relies on static adversarial patches, which are limited in their conspicuousness and can not be modified once deployed. In this paper, we propose Short-Lived Adversarial Perturbations (SLAP), a novel technique that allows adversaries to realize robust, dynamic real-world AE from a distance. As we show in this paper, such attacks can be achieved using a light projector to shine a specifically crafted adversarial image in order to perturb real-world objects and transform them into AE. This allows the adversary greater control over the attack compared to adversarial patches: (i) projections can be dynamically turned on and off or modified at will, (ii) projections do not suffer from the locality constraint imposed by patches, making them harder to detect. We study the feasibility of SLAP in the self-driving scenario, targeting both object detector and traffic sign recognition tasks. We demonstrate that the proposed method generates AE that are robust to different environmental conditions for several networks and lighting conditions: we successfully cause misclassifications of state-of-the-art networks such as Yolov3 and Mask-RCNN with up to 98% success rate for a variety of angles and distances. Additionally, we demonstrate that AE generated with SLAP can bypass SentiNet, a recent AE detection method which relies on the fact that adversarial patches generate highly salient and localized areas in the input images.
DeepFuse: An IMU-Aware Network for Real-Time 3D Human Pose Estimation from Multi-View Image
Dec 09, 2019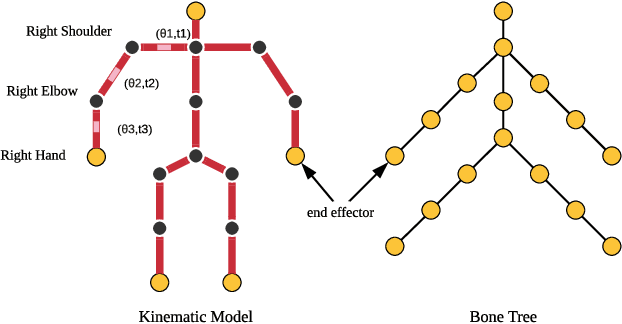

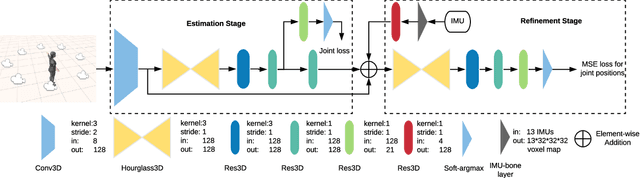
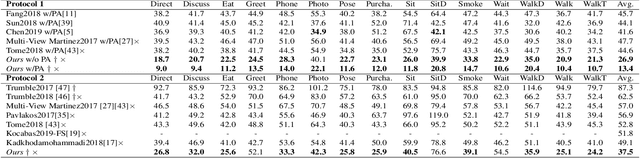
In this paper, we propose a two-stage fully 3D network, namely \textbf{DeepFuse}, to estimate human pose in 3D space by fusing body-worn Inertial Measurement Unit (IMU) data and multi-view images deeply. The first stage is designed for pure vision estimation. To preserve data primitiveness of multi-view inputs, the vision stage uses multi-channel volume as data representation and 3D soft-argmax as activation layer. The second one is the IMU refinement stage which introduces an IMU-bone layer to fuse the IMU and vision data earlier at data level. without requiring a given skeleton model a priori, we can achieve a mean joint error of $28.9$mm on TotalCapture dataset and $13.4$mm on Human3.6M dataset under protocol 1, improving the SOTA result by a large margin. Finally, we discuss the effectiveness of a fully 3D network for 3D pose estimation experimentally which may benefit future research.
Y-Net for Chest X-Ray Preprocessing: Simultaneous Classification of Geometry and Segmentation of Annotations
May 08, 2020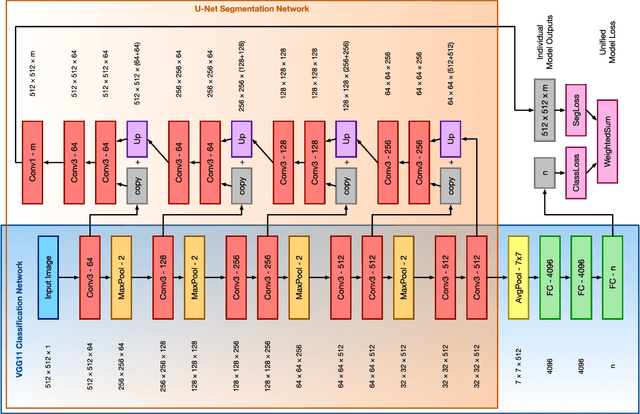
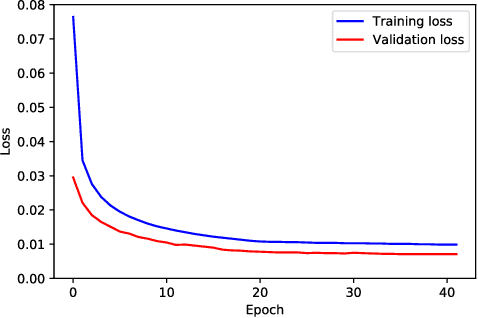
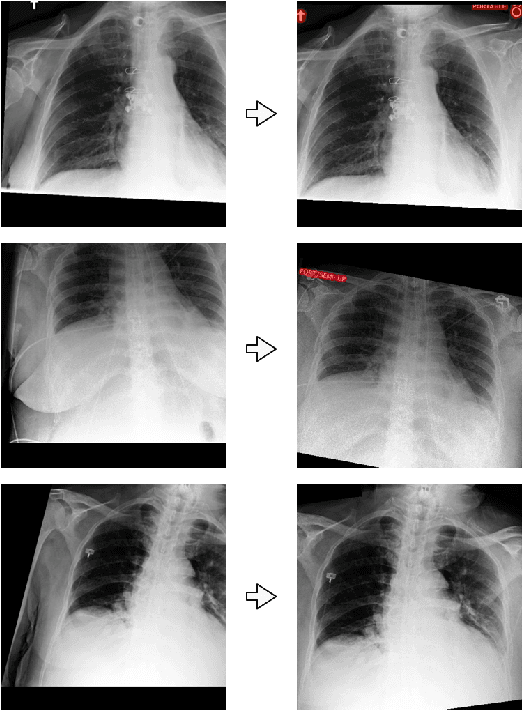
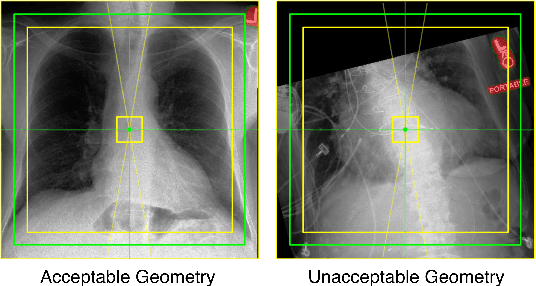
Over the last decade, convolutional neural networks (CNNs) have emerged as the leading algorithms in image classification and segmentation. Recent publication of large medical imaging databases have accelerated their use in the biomedical arena. While training data for photograph classification benefits from aggressive geometric augmentation, medical diagnosis -- especially in chest radiographs -- depends more strongly on feature location. Diagnosis classification results may be artificially enhanced by reliance on radiographic annotations. This work introduces a general pre-processing step for chest x-ray input into machine learning algorithms. A modified Y-Net architecture based on the VGG11 encoder is used to simultaneously learn geometric orientation (similarity transform parameters) of the chest and segmentation of radiographic annotations. Chest x-rays were obtained from published databases. The algorithm was trained with 1000 manually labeled images with augmentation. Results were evaluated by expert clinicians, with acceptable geometry in 95.8% and annotation mask in 96.2% (n=500), compared to 27.0% and 34.9% respectively in control images (n=241). We hypothesize that this pre-processing step will improve robustness in future diagnostic algorithms.
Onion-Peel Networks for Deep Video Completion
Aug 23, 2019
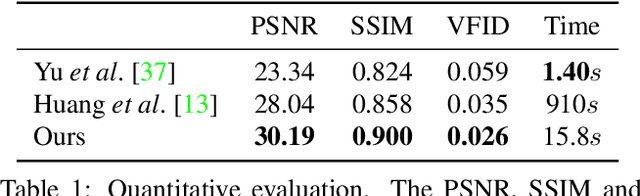
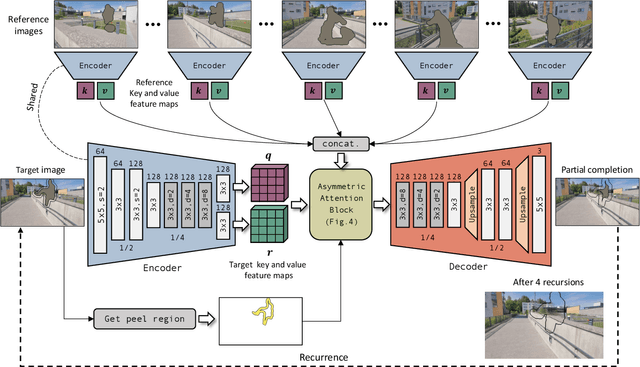
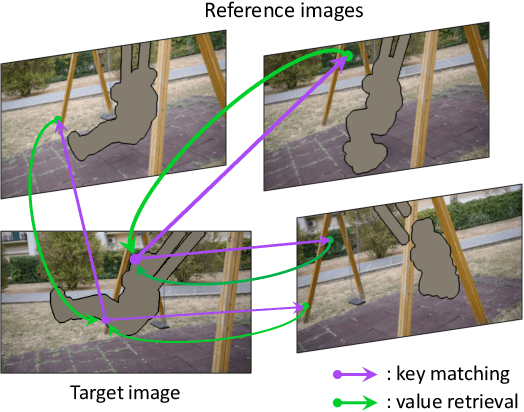
We propose the onion-peel networks for video completion. Given a set of reference images and a target image with holes, our network fills the hole by referring the contents in the reference images. Our onion-peel network progressively fills the hole from the hole boundary enabling it to exploit richer contextual information for the missing regions every step. Given a sufficient number of recurrences, even a large hole can be inpainted successfully. To attend to the missing information visible in the reference images, we propose an asymmetric attention block that computes similarities between the hole boundary pixels in the target and the non-hole pixels in the references in a non-local manner. With our attention block, our network can have an unlimited spatial-temporal window size and fill the holes with globally coherent contents. In addition, our framework is applicable to the image completion guided by the reference images without any modification, which is difficult to do with the previous methods. We validate that our method produces visually pleasing image and video inpainting results in realistic test cases.