 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Developing a Recommendation Benchmark for MLPerf Training and Inference
Apr 14, 2020
Deep learning-based recommendation models are used pervasively and broadly, for example, to recommend movies, products, or other information most relevant to users, in order to enhance the user experience. Among various application domains which have received significant industry and academia research attention, such as image classification, object detection, language and speech translation, the performance of deep learning-based recommendation models is less well explored, even though recommendation tasks unarguably represent significant AI inference cycles at large-scale datacenter fleets. To advance the state of understanding and enable machine learning system development and optimization for the commerce domain, we aim to define an industry-relevant recommendation benchmark for the MLPerf Training andInference Suites. The paper synthesizes the desirable modeling strategies for personalized recommendation systems. We lay out desirable characteristics of recommendation model architectures and data sets. We then summarize the discussions and advice from the MLPerf Recommendation Advisory Board.
Unsupervised Domain Adaptation in the Dissimilarity Space for Person Re-identification
Jul 27, 2020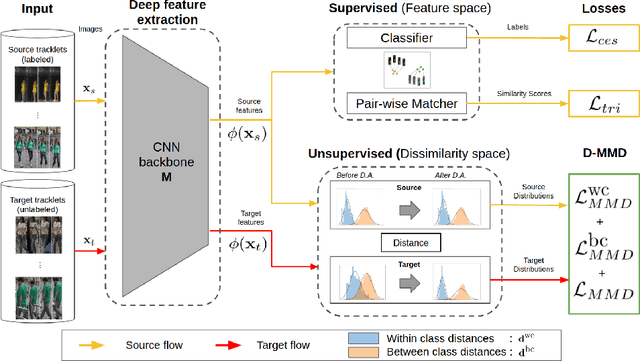
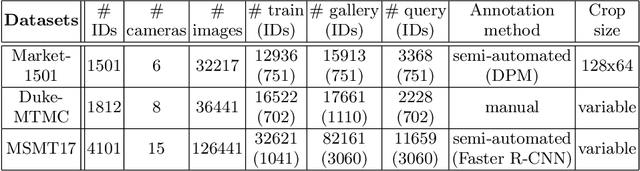
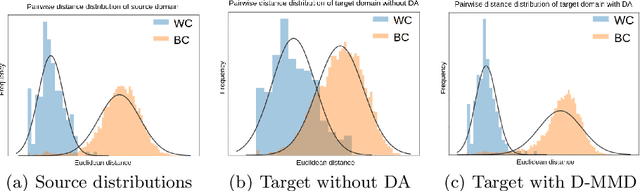
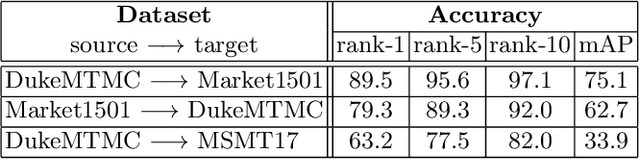
Person re-identification (ReID) remains a challenging task in many real-word video analytics and surveillance applications, even though state-of-the-art accuracy has improved considerably with the advent of deep learning (DL) models trained on large image datasets. Given the shift in distributions that typically occurs between video data captured from the source and target domains, and absence of labeled data from the target domain, it is difficult to adapt a DL model for accurate recognition of target data. We argue that for pair-wise matchers that rely on metric learning, e.g., Siamese networks for person ReID, the unsupervised domain adaptation (UDA) objective should consist in aligning pair-wise dissimilarity between domains, rather than aligning feature representations. Moreover, dissimilarity representations are more suitable for designing open-set ReID systems, where identities differ in the source and target domains. In this paper, we propose a novel Dissimilarity-based Maximum Mean Discrepancy (D-MMD) loss for aligning pair-wise distances that can be optimized via gradient descent. From a person ReID perspective, the evaluation of D-MMD loss is straightforward since the tracklet information allows to label a distance vector as being either within-class or between-class. This allows approximating the underlying distribution of target pair-wise distances for D-MMD loss optimization, and accordingly align source and target distance distributions. Empirical results with three challenging benchmark datasets show that the proposed D-MMD loss decreases as source and domain distributions become more similar. Extensive experimental evaluation also indicates that UDA methods that rely on the D-MMD loss can significantly outperform baseline and state-of-the-art UDA methods for person ReID without the common requirement for data augmentation and/or complex networks.
Let's Transfer Transformations of Shared Semantic Representations
Mar 02, 2019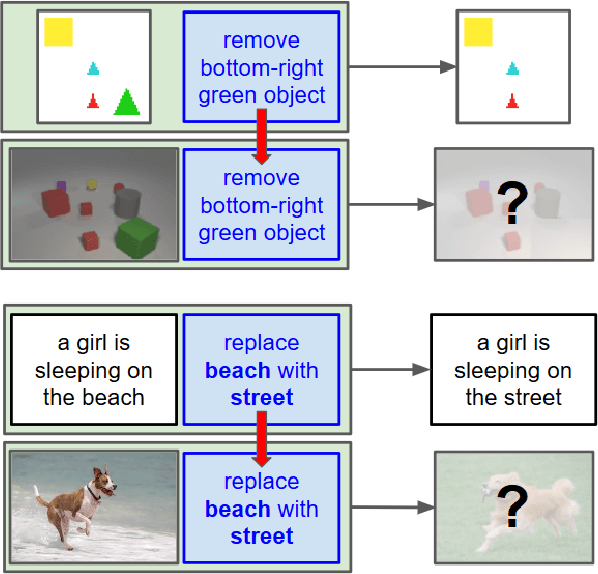

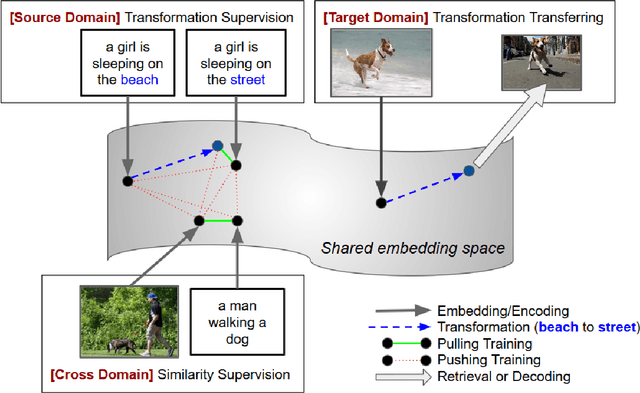

With a good image understanding capability, can we manipulate the images high level semantic representation? Such transformation operation can be used to generate or retrieve similar images but with a desired modification (for example changing beach background to street background); similar ability has been demonstrated in zero shot learning, attribute composition and attribute manipulation image search. In this work we show how one can learn transformations with no training examples by learning them on another domain and then transfer to the target domain. This is feasible if: first, transformation training data is more accessible in the other domain and second, both domains share similar semantics such that one can learn transformations in a shared embedding space. We demonstrate this on an image retrieval task where search query is an image, plus an additional transformation specification (for example: search for images similar to this one but background is a street instead of a beach). In one experiment, we transfer transformation from synthesized 2D blobs image to 3D rendered image, and in the other, we transfer from text domain to natural image domain.
Exposure Interpolation Via Fusing Conventional and Deep Learning Methods
May 09, 2019
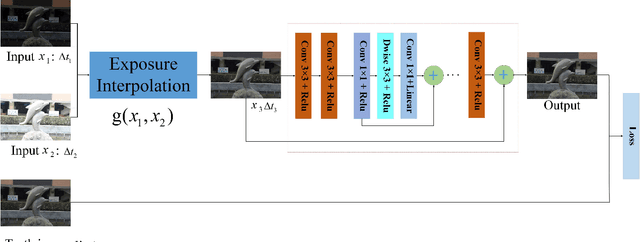


Deep learning based methods have penetrated many image processing problems and become dominant solutions to these problems. A natural question raised here is "Is there any space for conventional methods on these problems?" In this paper, exposure interpolation is taken as an example to answer this question and the answer is "Yes". A framework on fusing conventional and deep learning method is introduced to generate an medium exposure image for two large-exposureratio images. Experimental results indicate that the quality of the medium exposure image is increased significantly through using the deep learning method to refine the interpolated image via the conventional method. The conventional method can be adopted to improve the convergence speed of the deep learning method and to reduce the number of samples which is required by the deep learning method.
Inertial Measurements for Motion Compensation in Weight-bearing Cone-beam CT of the Knee
Jul 09, 2020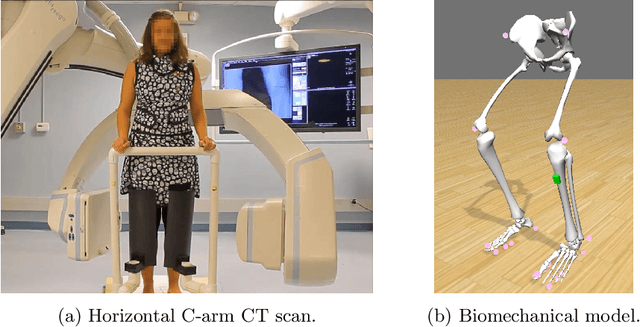
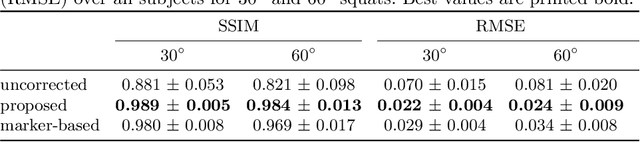
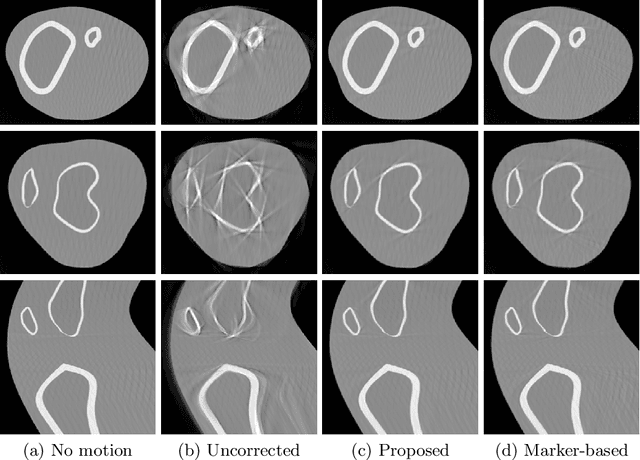

Involuntary motion during weight-bearing cone-beam computed tomography (CT) scans of the knee causes artifacts in the reconstructed volumes making them unusable for clinical diagnosis. Currently, image-based or marker-based methods are applied to correct for this motion, but often require long execution or preparation times. We propose to attach an inertial measurement unit (IMU) containing an accelerometer and a gyroscope to the leg of the subject in order to measure the motion during the scan and correct for it. To validate this approach, we present a simulation study using real motion measured with an optical 3D tracking system. With this motion, an XCAT numerical knee phantom is non-rigidly deformed during a simulated CT scan creating motion corrupted projections. A biomechanical model is animated with the same tracked motion in order to generate measurements of an IMU placed below the knee. In our proposed multi-stage algorithm, these signals are transformed to the global coordinate system of the CT scan and applied for motion compensation during reconstruction. Our proposed approach can effectively reduce motion artifacts in the reconstructed volumes. Compared to the motion corrupted case, the average structural similarity index and root mean squared error with respect to the no-motion case improved by 13-21% and 68-70%, respectively. These results are qualitatively and quantitatively on par with a state-of-the-art marker-based method we compared our approach to. The presented study shows the feasibility of this novel approach, and yields promising results towards a purely IMU-based motion compensation in C-arm CT.
Gaze2Segment: A Pilot Study for Integrating Eye-Tracking Technology into Medical Image Segmentation
Aug 10, 2016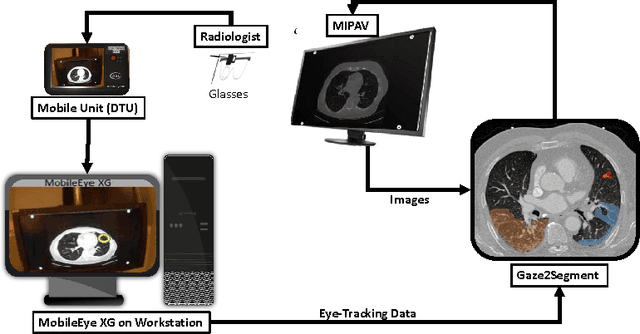
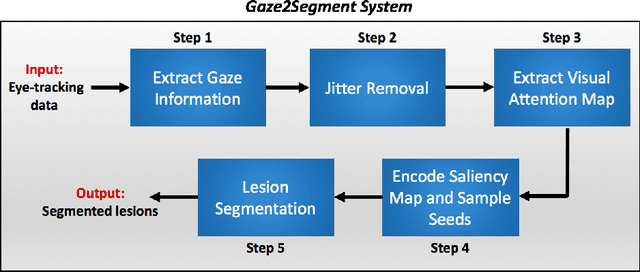
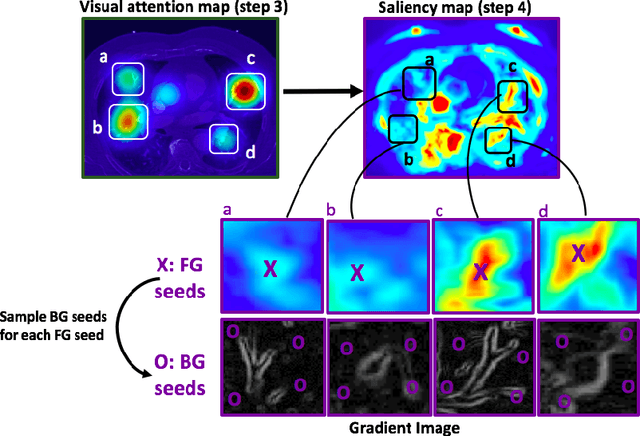
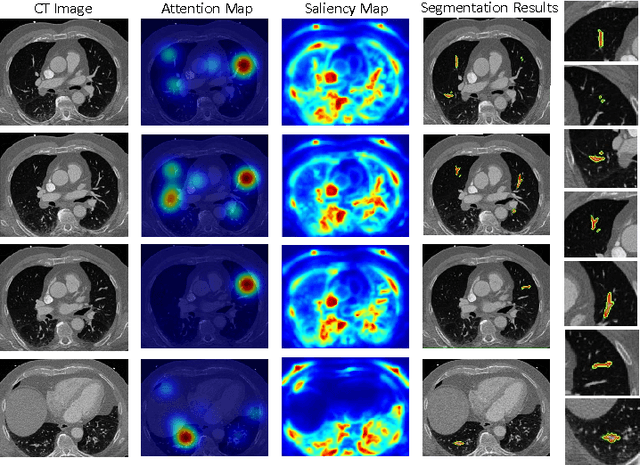
This study introduced a novel system, called Gaze2Segment, integrating biological and computer vision techniques to support radiologists' reading experience with an automatic image segmentation task. During diagnostic assessment of lung CT scans, the radiologists' gaze information were used to create a visual attention map. This map was then combined with a computer-derived saliency map, extracted from the gray-scale CT images. The visual attention map was used as an input for indicating roughly the location of a object of interest. With computer-derived saliency information, on the other hand, we aimed at finding foreground and background cues for the object of interest. At the final step, these cues were used to initiate a seed-based delineation process. Segmentation accuracy of the proposed Gaze2Segment was found to be 86% with dice similarity coefficient and 1.45 mm with Hausdorff distance. To the best of our knowledge, Gaze2Segment is the first true integration of eye-tracking technology into a medical image segmentation task without the need for any further user-interaction.
Adaptive Weighting Multi-Field-of-View CNN for Semantic Segmentation in Pathology
Apr 12, 2019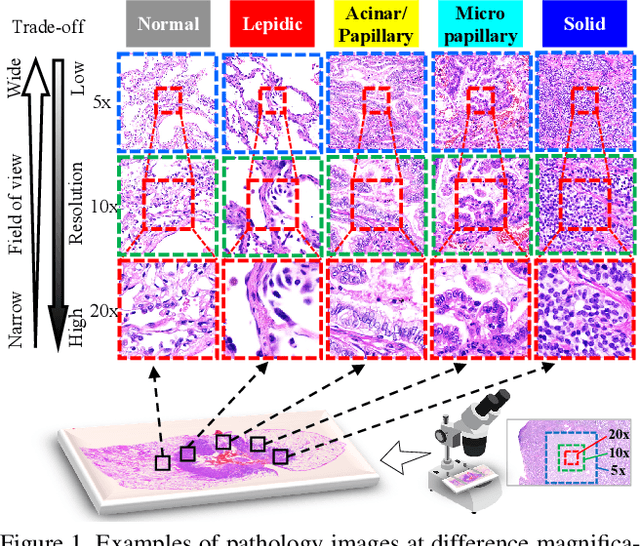
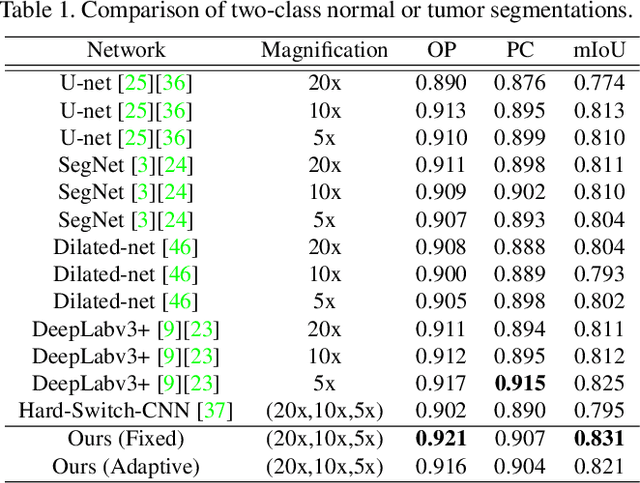
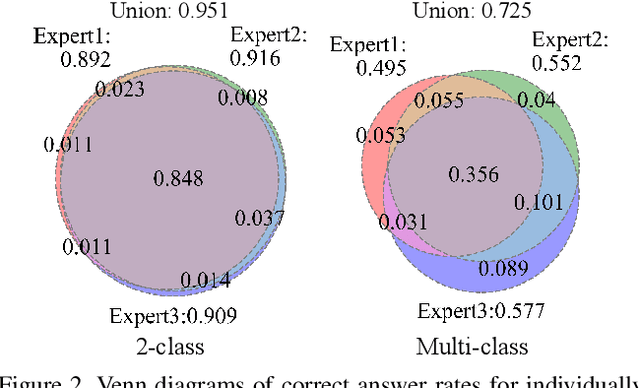
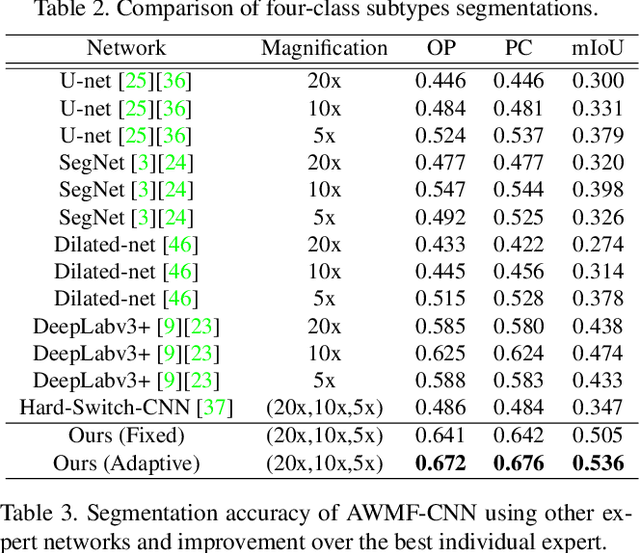
Automated digital histopathology image segmentation is an important task to help pathologists diagnose tumors and cancer subtypes. For pathological diagnosis of cancer subtypes, pathologists usually change the magnification of whole-slide images (WSI) viewers. A key assumption is that the importance of the magnifications depends on the characteristics of the input image, such as cancer subtypes. In this paper, we propose a novel semantic segmentation method, called Adaptive-Weighting-Multi-Field-of-View-CNN (AWMF-CNN), that can adaptively use image features from images with different magnifications to segment multiple cancer subtype regions in the input image. The proposed method aggregates several expert CNNs for images of different magnifications by adaptively changing the weight of each expert depending on the input image. It leverages information in the images with different magnifications that might be useful for identifying the subtypes. It outperformed other state-of-the-art methods in experiments.
Depth-Preserving Real-Time Arbitrary Style Transfer
Jun 03, 2019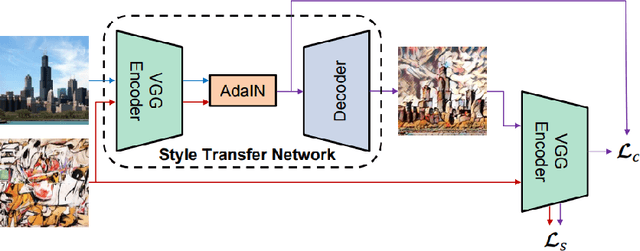

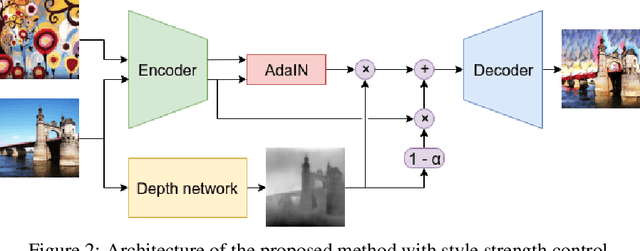

Style transfer is the process of rendering one image with some content in the style of another image, representing the style. Recent studies of Liu et al. (2017) have shown significant improvement of style transfer rendering quality by adjusting traditional methods of Gatys et al. (2016) and Johnson et al. (2016) with regularizer, forcing preservation of the depth map of the content image. However these traditional methods are either computationally inefficient or require training a separate neural network for new style. AdaIN method of Huang et al. (2017) allows efficient transferring of arbitrary style without training a separate model but is not able to reproduce the depth map of the content image. We propose an extension to this method, allowing depth map preservation. Qualitative analysis and results of user evaluation study indicate that the proposed method provides better stylizations, compared to the original style transfer methods of Gatys et al. (2016) and Huang et al. (2017).
Deep Residual Network based food recognition for enhanced Augmented Reality application
May 08, 2020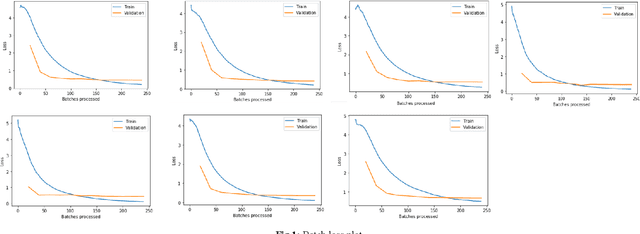
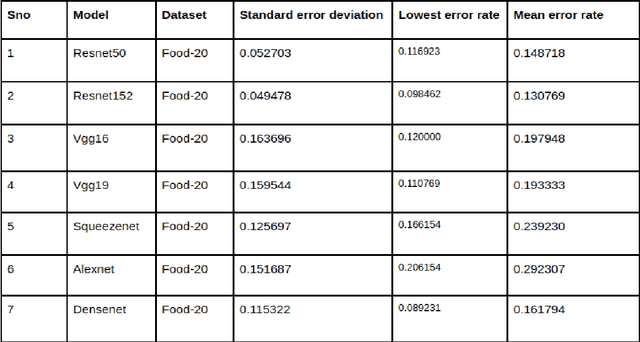
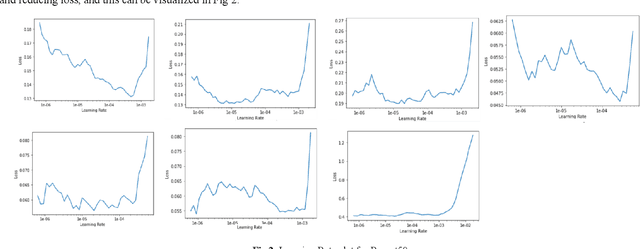
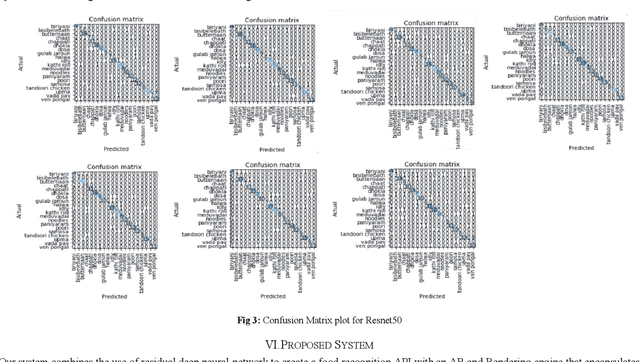
Deep neural network based learning approaches is widely utilized for image classification or object detection based problems with remarkable outcomes. Realtime Object state estimation of objects can be used to track and estimate the features that the object of the current frame possesses without causing any significant delay and misclassification. A system that can detect the features of such objects in the present state from camera images can be used to enhance the application of Augmented Reality for improving user experience and delivering information in a much perceptual way. The focus behind this paper is to determine the most suitable model to create a low-latency assistance AR to aid users by providing them nutritional information about the food that they consume in order to promote healthier life choices. Hence the dataset has been collected and acquired in such a manner, and we conduct various tests in order to identify the most suitable DNN in terms of performance and complexity and establish a system that renders such information realtime to the user.
Semantic-Aware Label Placement for Augmented Reality in Street View
Dec 15, 2019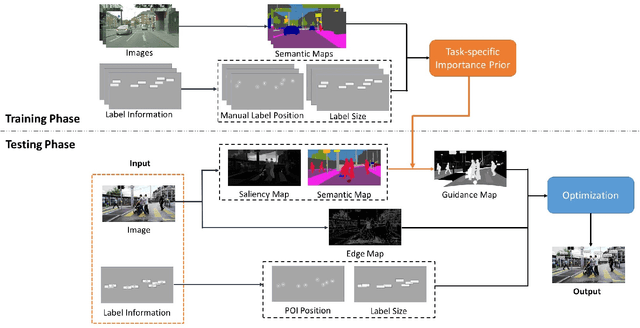
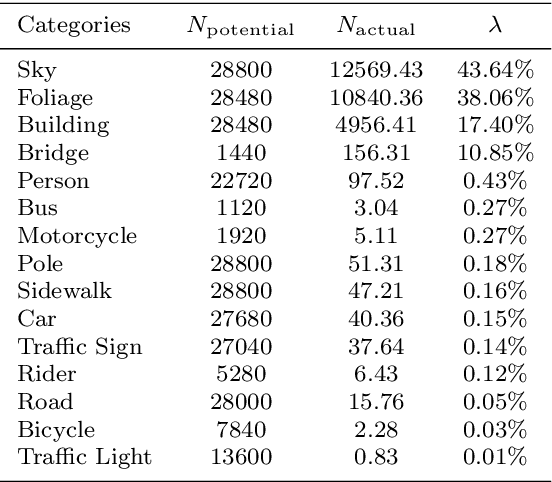
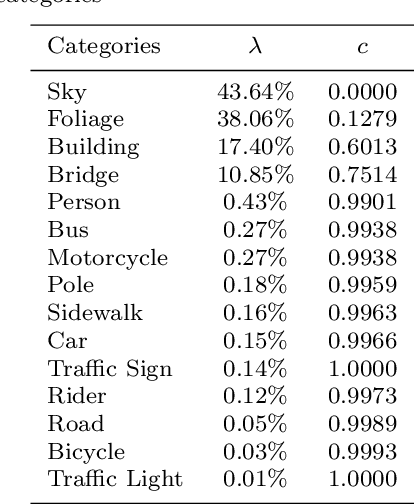
In an augmented reality (AR) application, placing labels in a manner that is clear and readable without occluding the critical information from the real-world can be a challenging problem. This paper introduces a label placement technique for AR used in street view scenarios. We propose a semantic-aware task-specific label placement method by identifying potentially important image regions through a novel feature map, which we refer to as guidance map. Given an input image, its saliency information, semantic information and the task-specific importance prior are integrated into the guidance map for our labeling task. To learn the task prior, we created a label placement dataset with the users' labeling preferences, as well as use it for evaluation. Our solution encodes the constraints for placing labels in an optimization problem to obtain the final label layout, and the labels will be placed in appropriate positions to reduce the chances of overlaying important real-world objects in street view AR scenarios. The experimental validation shows clearly the benefits of our method over previous solutions in the AR street view navigation and similar applications.