 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Erase and Restore: Simple, Accurate and Resilient Detection of $L_2$ Adversarial Examples
Jan 01, 2020

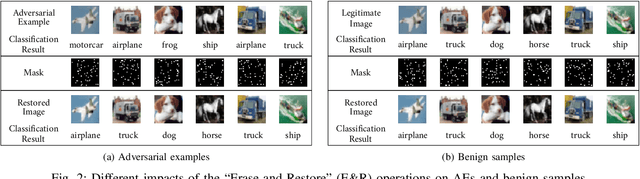
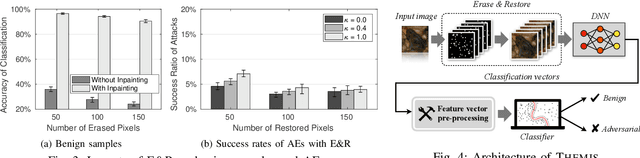
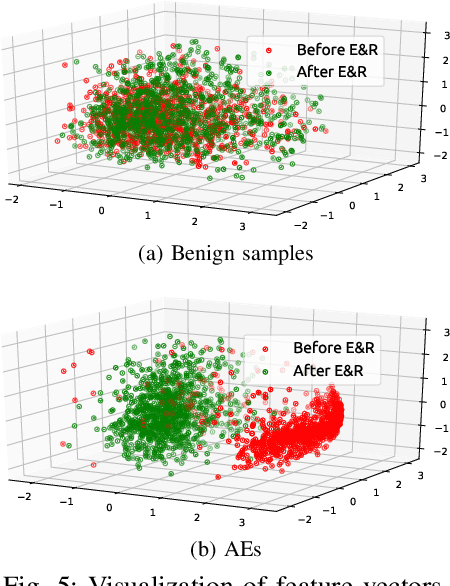
By adding carefully crafted perturbations to input images, adversarial examples (AEs) can be generated to mislead neural-network-based image classifiers. $L_2$ adversarial perturbations by Carlini and Wagner (CW) are regarded as among the most effective attacks. While many countermeasures against AEs have been proposed, detection of adaptive CW $L_2$ AEs has been very inaccurate. Our observation is that those deliberately altered pixels in an $L_2$ AE, altogether, exert their malicious influence. By randomly erasing some pixels from an $L_2$ AE and then restoring it with an inpainting technique, such an AE, before and after the steps, tends to have different classification results, while a benign sample does not show this symptom. Based on this, we propose a novel AE detection technique, Erase and Restore (E\&R), that exploits the limitation of $L_2$ attacks. On two popular image datasets, CIFAR-10 and ImageNet, our experiments show that the proposed technique is able to detect over 98% of the AEs generated by CW and other $L_2$ algorithms and has a very low false positive rate on benign images. Moreover, our approach demonstrate strong resilience to adaptive attacks. While adding noises and inpainting each have been well studied, by combining them together, we deliver a simple, accurate and resilient detection technique against adaptive $L_2$ AEs.
Deep Residual Network based food recognition for enhanced Augmented Reality application
May 08, 2020
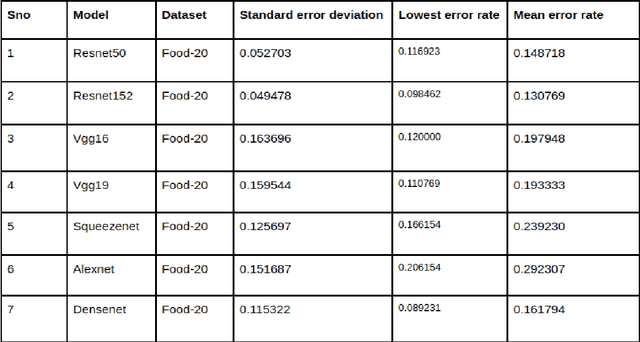
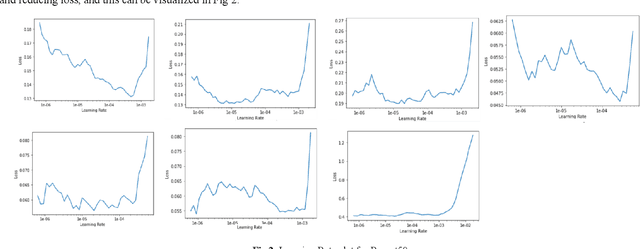
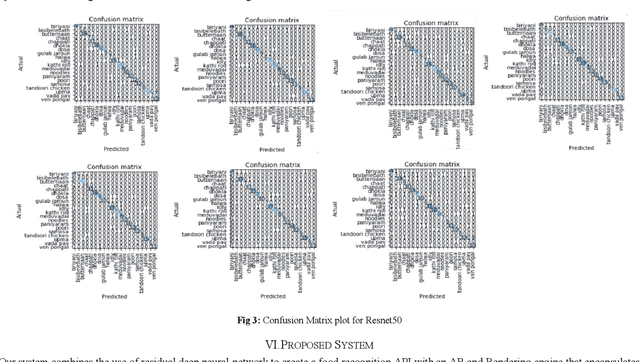
Deep neural network based learning approaches is widely utilized for image classification or object detection based problems with remarkable outcomes. Realtime Object state estimation of objects can be used to track and estimate the features that the object of the current frame possesses without causing any significant delay and misclassification. A system that can detect the features of such objects in the present state from camera images can be used to enhance the application of Augmented Reality for improving user experience and delivering information in a much perceptual way. The focus behind this paper is to determine the most suitable model to create a low-latency assistance AR to aid users by providing them nutritional information about the food that they consume in order to promote healthier life choices. Hence the dataset has been collected and acquired in such a manner, and we conduct various tests in order to identify the most suitable DNN in terms of performance and complexity and establish a system that renders such information realtime to the user.
Stochastic Conditional Generative Networks with Basis Decomposition
Sep 25, 2019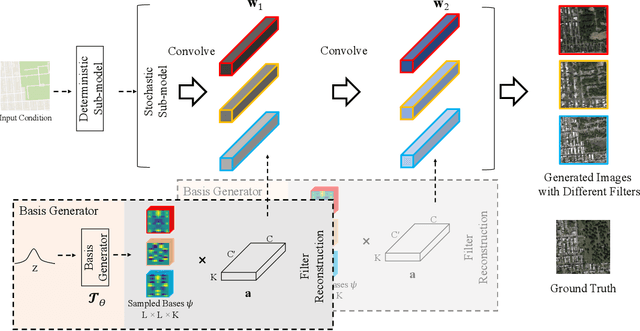
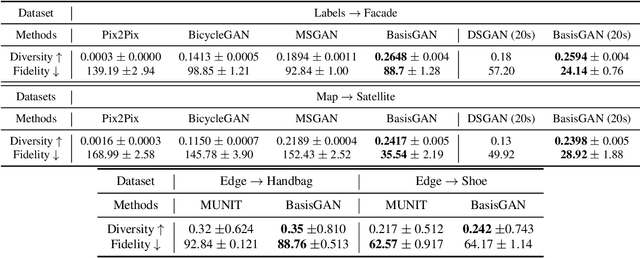


While generative adversarial networks (GANs) have revolutionized machine learning, a number of open questions remain to fully understand them and exploit their power. One of these questions is how to efficiently achieve proper diversity and sampling of the multi-mode data space. To address this, we introduce BasisGAN, a stochastic conditional multi-mode image generator. By exploiting the observation that a convolutional filter can be well approximated as a linear combination of a small set of basis elements, we learn a plug-and-played basis generator to stochastically generate basis elements, with just a few hundred of parameters, to fully embed stochasticity into convolutional filters. By sampling basis elements instead of filters, we dramatically reduce the cost of modeling the parameter space with no sacrifice on either image diversity or fidelity. To illustrate this proposed plug-and-play framework, we construct variants of BasisGAN based on state-of-the-art conditional image generation networks, and train the networks by simply plugging in a basis generator, without additional auxiliary components, hyperparameters, or training objectives. The experimental success is complemented with theoretical results indicating how the perturbations introduced by the proposed sampling of basis elements can propagate to the appearance of generated images.
Structure preserving deep learning
Jun 05, 2020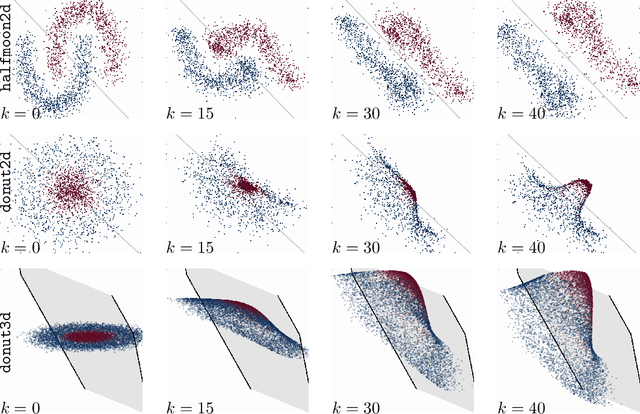
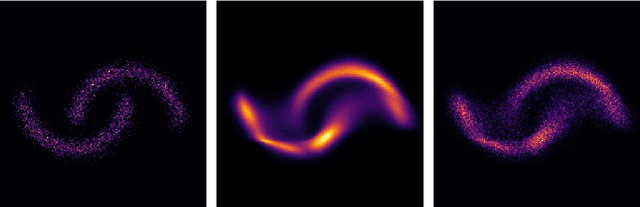
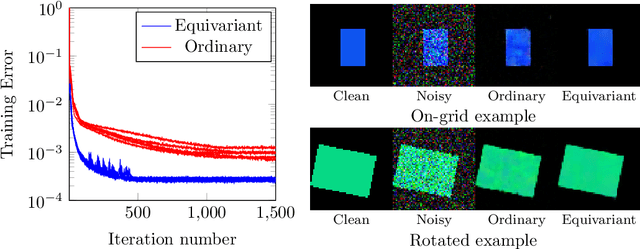
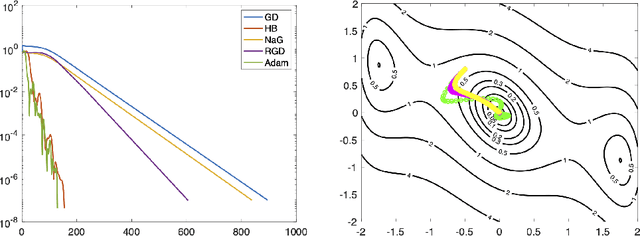
Over the past few years, deep learning has risen to the foreground as a topic of massive interest, mainly as a result of successes obtained in solving large-scale image processing tasks. There are multiple challenging mathematical problems involved in applying deep learning: most deep learning methods require the solution of hard optimisation problems, and a good understanding of the tradeoff between computational effort, amount of data and model complexity is required to successfully design a deep learning approach for a given problem. A large amount of progress made in deep learning has been based on heuristic explorations, but there is a growing effort to mathematically understand the structure in existing deep learning methods and to systematically design new deep learning methods to preserve certain types of structure in deep learning. In this article, we review a number of these directions: some deep neural networks can be understood as discretisations of dynamical systems, neural networks can be designed to have desirable properties such as invertibility or group equivariance, and new algorithmic frameworks based on conformal Hamiltonian systems and Riemannian manifolds to solve the optimisation problems have been proposed. We conclude our review of each of these topics by discussing some open problems that we consider to be interesting directions for future research.
MimickNet, Matching Clinical Post-Processing Under Realistic Black-Box Constraints
Aug 15, 2019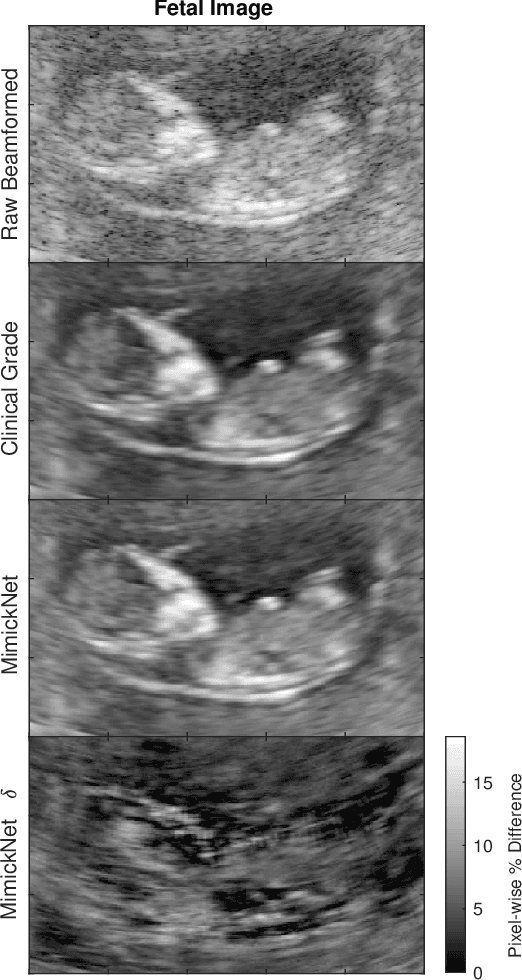
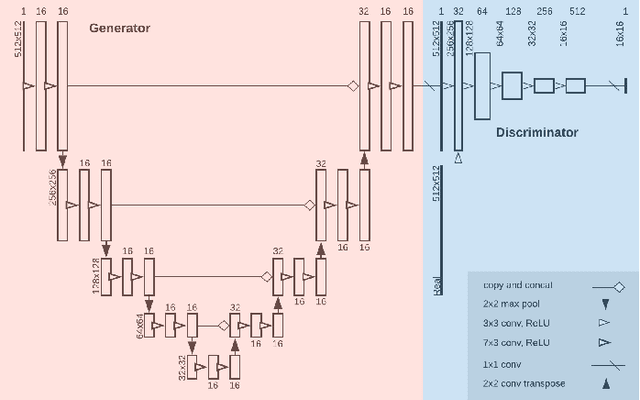
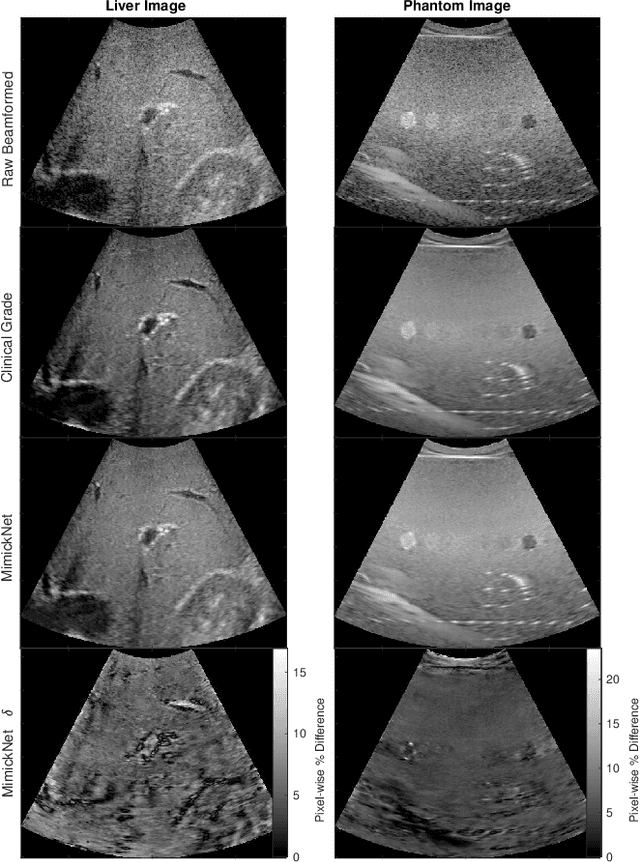
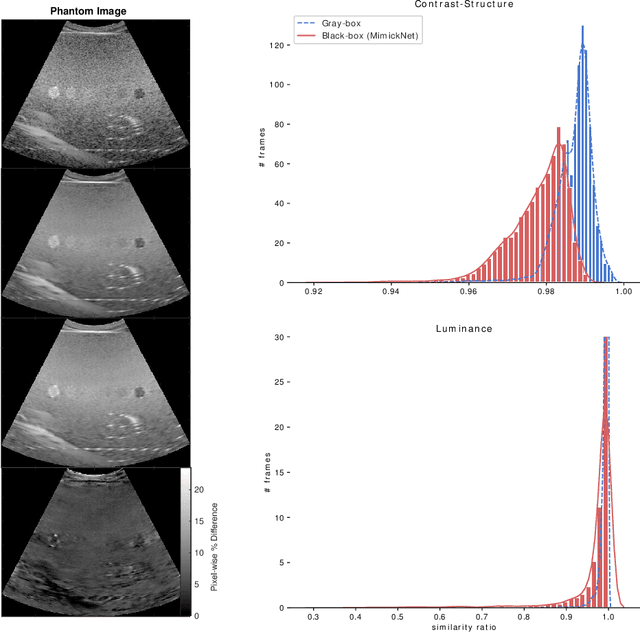
Image post-processing is used in clinical-grade ultrasound scanners to improve image quality (e.g., reduce speckle noise and enhance contrast). These post-processing techniques vary across manufacturers and are generally kept proprietary, which presents a challenge for researchers looking to match current clinical-grade workflows. We introduce a deep learning framework, MimickNet, that transforms raw conventional delay-and-summed (DAS) beams into the approximate post-processed images found on clinical-grade scanners. Training MimickNet only requires post-processed image samples from a scanner of interest without the need for explicit pairing to raw DAS data. This flexibility allows it to hypothetically approximate any manufacturer's post-processing without access to the pre-processed data. MimickNet generates images with an average similarity index measurement (SSIM) of 0.930$\pm$0.0892 on a 300 cineloop test set, and it generalizes to cardiac cineloops outside of our train-test distribution achieving an SSIM of 0.967$\pm$0.002. We also explore the theoretical SSIM achievable by evaluating MimickNet performance when trained under gray-box constraints (i.e., when both pre-processed and post-processed images are available). To our knowledge, this is the first work to establish deep learning models that closely approximate current clinical-grade ultrasound post-processing under realistic black-box constraints where before and after post-processing data is unavailable. MimickNet serves as a clinical post-processing baseline for future works in ultrasound image formation to compare against. To this end, we have made the MimickNet software open source.
Explaining Autonomous Driving by Learning End-to-End Visual Attention
Jun 05, 2020
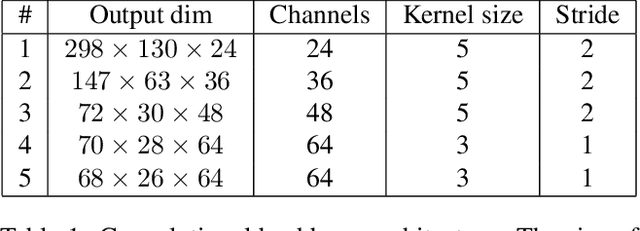
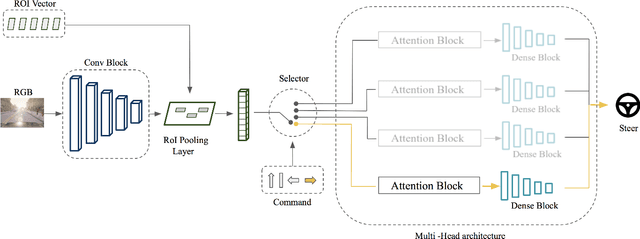

Current deep learning based autonomous driving approaches yield impressive results also leading to in-production deployment in certain controlled scenarios. One of the most popular and fascinating approaches relies on learning vehicle controls directly from data perceived by sensors. This end-to-end learning paradigm can be applied both in classical supervised settings and using reinforcement learning. Nonetheless the main drawback of this approach as also in other learning problems is the lack of explainability. Indeed, a deep network will act as a black-box outputting predictions depending on previously seen driving patterns without giving any feedback on why such decisions were taken. While to obtain optimal performance it is not critical to obtain explainable outputs from a learned agent, especially in such a safety critical field, it is of paramount importance to understand how the network behaves. This is particularly relevant to interpret failures of such systems. In this work we propose to train an imitation learning based agent equipped with an attention model. The attention model allows us to understand what part of the image has been deemed most important. Interestingly, the use of attention also leads to superior performance in a standard benchmark using the CARLA driving simulator.
Risk of Training Diagnostic Algorithms on Data with Demographic Bias
Jun 17, 2020
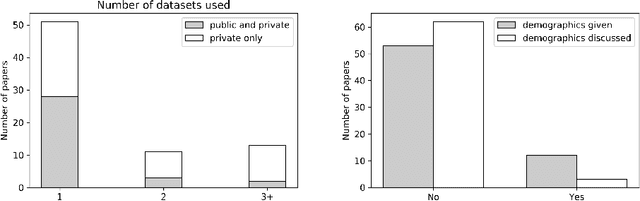
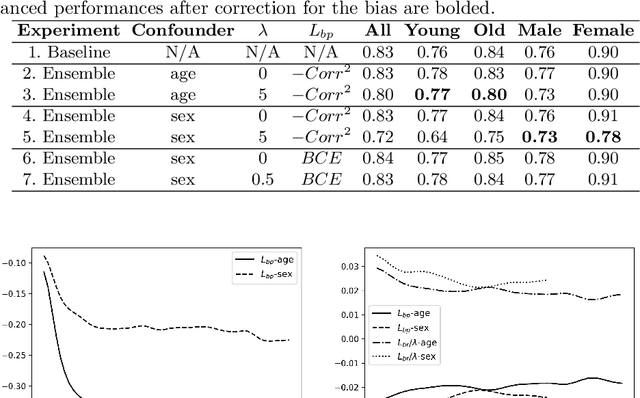
One of the critical challenges in machine learning applications is to have fair predictions. There are numerous recent examples in various domains that convincingly show that algorithms trained with biased datasets can easily lead to erroneous or discriminatory conclusions. This is even more crucial in clinical applications where the predictive algorithms are designed mainly based on a limited or given set of medical images and demographic variables such as age, sex and race are not taken into account. In this work, we conduct a survey of the MICCAI 2018 proceedings to investigate the common practice in medical image analysis applications. Surprisingly, we found that papers focusing on diagnosis rarely describe the demographics of the datasets used, and the diagnosis is purely based on images. In order to highlight the importance of considering the demographics in diagnosis tasks, we used a publicly available dataset of skin lesions. We then demonstrate that a classifier with an overall area under the curve (AUC) of 0.83 has variable performance between 0.76 and 0.91 on subgroups based on age and sex, even though the training set was relatively balanced. Moreover, we show that it is possible to learn unbiased features by explicitly using demographic variables in an adversarial training setup, which leads to balanced scores per subgroups. Finally, we discuss the implications of these results and provide recommendations for further research.
FragNet: Writer Identification using Deep Fragment Networks
Mar 16, 2020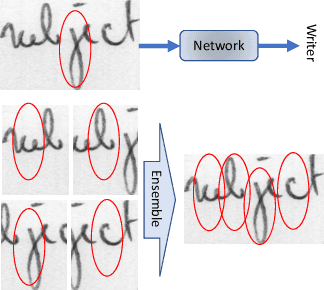
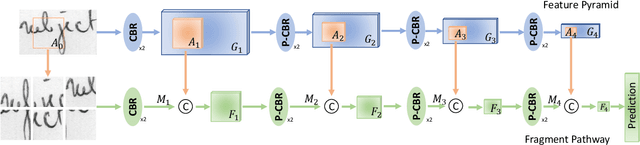
Writer identification based on a small amount of text is a challenging problem. In this paper, we propose a new benchmark study for writer identification based on word or text block images which approximately contain one word. In order to extract powerful features on these word images, a deep neural network, named FragNet, is proposed. The FragNet has two pathways: feature pyramid which is used to extract feature maps and fragment pathway which is trained to predict the writer identity based on fragments extracted from the input image and the feature maps on the feature pyramid. We conduct experiments on four benchmark datasets, which show that our proposed method can generate efficient and robust deep representations for writer identification based on both word and page images.
Granular Multimodal Attention Networks for Visual Dialog
Oct 13, 2019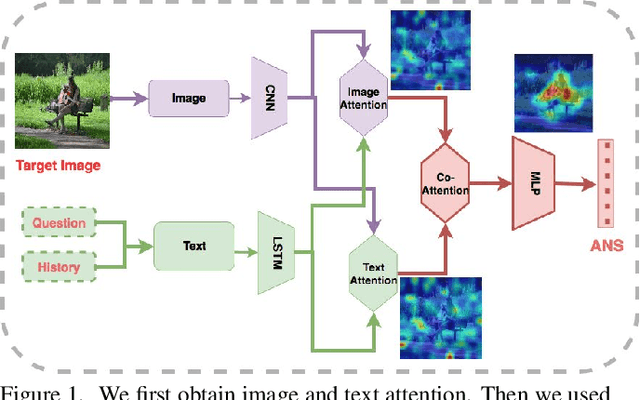
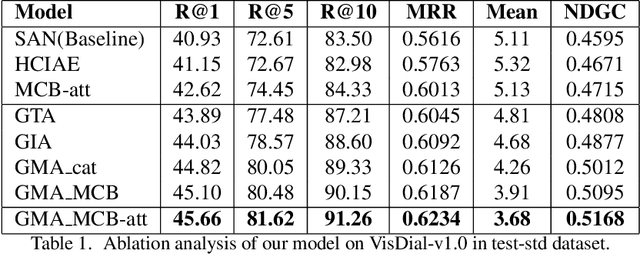
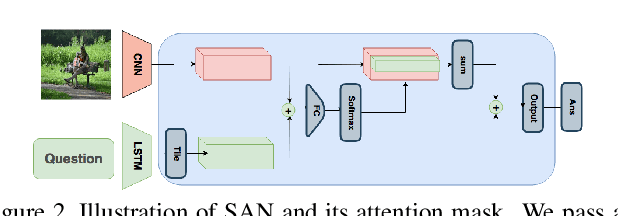
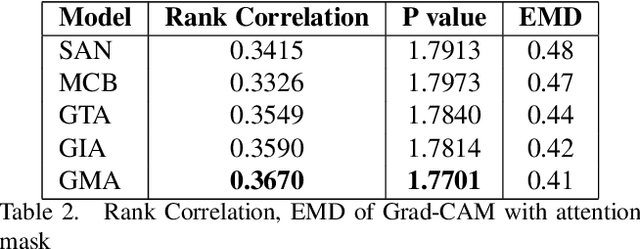
Vision and language tasks have benefited from attention. There have been a number of different attention models proposed. However, the scale at which attention needs to be applied has not been well examined. Particularly, in this work, we propose a new method Granular Multi-modal Attention, where we aim to particularly address the question of the right granularity at which one needs to attend while solving the Visual Dialog task. The proposed method shows improvement in both image and text attention networks. We then propose a granular Multi-modal Attention network that jointly attends on the image and text granules and shows the best performance. With this work, we observe that obtaining granular attention and doing exhaustive Multi-modal Attention appears to be the best way to attend while solving visual dialog.
Real-time Simultaneous 3D Head Modeling and Facial Motion Capture with an RGB-D camera
Apr 22, 2020
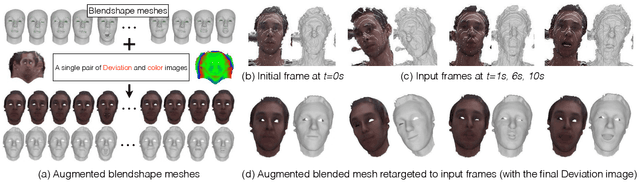
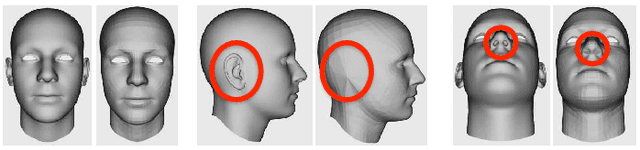

We propose a method to build in real-time animated 3D head models using a consumer-grade RGB-D camera. Our proposed method is the first one to provide simultaneously comprehensive facial motion tracking and a detailed 3D model of the user's head. Anyone's head can be instantly reconstructed and his facial motion captured without requiring any training or pre-scanning. The user starts facing the camera with a neutral expression in the first frame, but is free to move, talk and change his face expression as he wills otherwise. The facial motion is captured using a blendshape animation model while geometric details are captured using a Deviation image mapped over the template mesh. We contribute with an efficient algorithm to grow and refine the deforming 3D model of the head on-the-fly and in real-time. We demonstrate robust and high-fidelity simultaneous facial motion capture and 3D head modeling results on a wide range of subjects with various head poses and facial expressions.